
Thompson Sampling for Non-Stationary Bandit Problems


Abstract
1. Introduction
2. Related Works
3. Problem Formulation
Abruptly Changing Setting
4. Algorithms
4.1. DS-TS
| Algorithm 1 DS-TS |
|
4.2. SW-TS
| Algorithm 2 SW-TS |
|
4.3. Results
5. Proofs of Upper Bounds
5.1. Challenges in Regret Analysis
5.2. Proofs of Theorem 1
5.3. Proofs of Theorem 2
6. Experiments
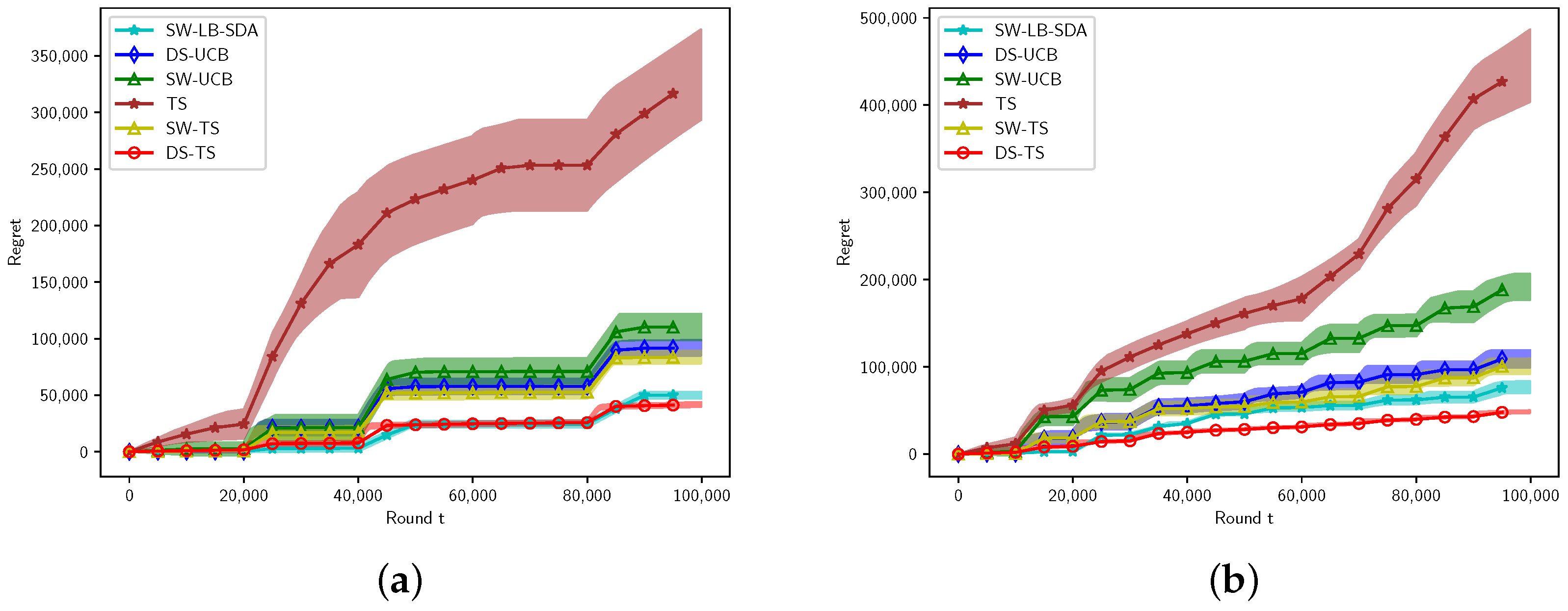
6.1. Gaussian Arms
6.1.1. Experimental Setting for Gaussian Arms
6.1.2. Results
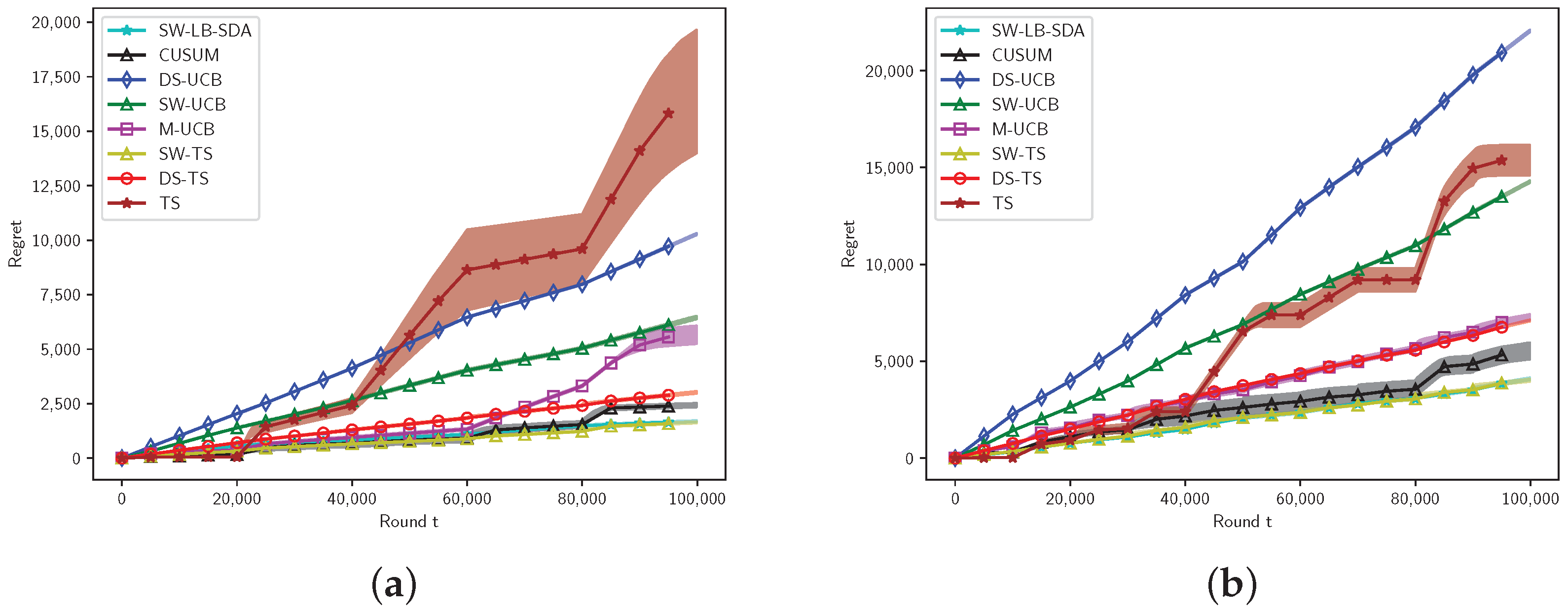
6.2. Bernoulli Arms
6.2.1. Experimental Setting for Bernoulli Arms
6.2.2. Results
6.2.3. Storage and Compute Cost
6.3. Different Variance
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Facts and Lemmas
Appendix B. Detailed Proofs of Lemmas and Theorems
Appendix B.1. Proof of Lemma 1
Appendix B.2. Proof of Lemma 2
Appendix B.3. Proof of Lemma 3
Appendix B.4. Larger Variance
Appendix B.5. Proof of Lemma 4
Appendix B.6. Proof of Lemma 5
References
- Robbins, H. Some aspects of the sequential design of experiments. Bull. Am. Math. Soc. 1952, 58, 527–535. [Google Scholar] [CrossRef]
- Li, L.; Chu, W.; Langford, J.; Wang, X. Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms. In Proceedings of the fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 297–306. [Google Scholar]
- Bouneffouf, D.; Bouzeghoub, A.; Ganarski, A.L. A contextual-bandit algorithm for mobile context-aware recommender system. In Neural Information Processing, Proceedings of the International Conference, ICONIP 2012, Doha, Qatar, 12–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 324–331. [Google Scholar]
- Li, S.; Karatzoglou, A.; Gentile, C. Collaborative filtering bandits. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 539–548. [Google Scholar]
- Schwartz, E.M.; Bradlow, E.T.; Fader, P.S. Customer acquisition via display advertising using multi-armed bandit experiments. Mark. Sci. 2017, 36, 500–522. [Google Scholar] [CrossRef]
- Wu, Q.; Iyer, N.; Wang, H. Learning contextual bandits in a non-stationary environment. In Proceedings of the The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 495–504. [Google Scholar]
- Liu, F.; Lee, J.; Shroff, N. A change-detection based framework for piecewise-stationary multi-armed bandit problem. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Cao, Y.; Wen, Z.; Kveton, B.; Xie, Y. Nearly optimal adaptive procedure with change detection for piecewise-stationary bandit. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Okinawa, Japan, 16–18 April 2019; pp. 418–427. [Google Scholar]
- Auer, P.; Gajane, P.; Ortner, R. Adaptively tracking the best bandit arm with an unknown number of distribution changes. In Proceedings of the Conference on Learning Theory, Phoenix, AZ, USA, 25–28 June 2019; pp. 138–158. [Google Scholar]
- Chen, Y.; Lee, C.W.; Luo, H.; Wei, C.Y. A new algorithm for non-stationary contextual bandits: Efficient, optimal and parameter-free. In Proceedings of the Conference on Learning Theory, Phoenix, AZ, USA, 25–28 June 2019; pp. 696–726. [Google Scholar]
- Besson, L.; Kaufmann, E.; Maillard, O.A.; Seznec, J. Efficient Change-Point Detection for Tackling Piecewise-Stationary Bandits. J. Mach. Learn. Res. 2022, 23, 1–40. [Google Scholar]
- Garivier, A.; Moulines, E. On upper-confidence bound policies for switching bandit problems. In Algorithmic Learning Theory, Proceedings of the 22nd International Conference, ALT 2011, Espoo, Finland, 5–7 October 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 174–188. [Google Scholar]
- Raj, V.; Kalyani, S. Taming non-stationary bandits: A Bayesian approach. arXiv 2017, arXiv:1707.09727. [Google Scholar]
- Trovo, F.; Paladino, S.; Restelli, M.; Gatti, N. Sliding-window thompson sampling for non-stationary settings. J. Artif. Intell. Res. 2020, 68, 311–364. [Google Scholar] [CrossRef]
- Baudry, D.; Russac, Y.; Cappé, O. On Limited-Memory Subsampling Strategies for Bandits. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 727–737. [Google Scholar]
- Ghatak, G. A change-detection-based Thompson sampling framework for non-stationary bandits. IEEE Trans. Comput. 2020, 70, 1670–1676. [Google Scholar] [CrossRef]
- Alami, R.; Azizi, O. Ts-glr: An adaptive thompson sampling for the switching multi-armed bandit problem. In Proceedings of the NeurIPS 2020 Challenges of Real World Reinforcement Learning Workshop, Virtual, 6–12 December 2020. [Google Scholar]
- Viappiani, P. Thompson sampling for bayesian bandits with resets. In Algorithmic Decision Theory, Proceedings of the Third International Conference, ADT 2013, Bruxelles, Belgium, 12–14 November 2013; Proceedings 3; Springer: Berlin/Heidelberg, Germany, 2013; pp. 399–410. [Google Scholar]
- Gupta, N.; Granmo, O.C.; Agrawala, A. Thompson sampling for dynamic multi-armed bandits. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; Volume 1, pp. 484–489. [Google Scholar]
- Cavenaghi, E.; Sottocornola, G.; Stella, F.; Zanker, M. Non stationary multi-armed bandit: Empirical evaluation of a new concept drift-aware algorithm. Entropy 2021, 23, 380. [Google Scholar] [CrossRef]
- Liu, Y.; Van Roy, B.; Xu, K. Nonstationary bandit learning via predictive sampling. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 25–27 April 2023; pp. 6215–6244. [Google Scholar]
- Fiandri, M.; Metelli, A.M.; Trovò, F. Sliding-Window Thompson Sampling for Non-Stationary Settings. arXiv 2024, arXiv:2409.05181. [Google Scholar]
- Qi, H.; Wang, Y.; Zhu, L. Discounted thompson sampling for non-stationary bandit problems. arXiv 2023, arXiv:2305.10718. [Google Scholar]
- Kocsis, L.; Szepesvári, C. Discounted ucb. In Proceedings of the 2nd PASCAL Challenges Workshop, Venice, Italy, 10–12 April 2006; Volume 2, pp. 51–134. [Google Scholar]
- Auer, P.; Cesa-Bianchi, N.; Freund, Y.; Schapire, R.E. The nonstochastic multiarmed bandit problem. SIAM J. Comput. 2002, 32, 48–77. [Google Scholar] [CrossRef]
- Besbes, O.; Gur, Y.; Zeevi, A. Stochastic multi-armed-bandit problem with non-stationary rewards. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Combes, R.; Proutiere, A. Unimodal bandits: Regret lower bounds and optimal algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 521–529. [Google Scholar]
- Mellor, J.; Shapiro, J. Thompson sampling in switching environments with Bayesian online change detection. In Proceedings of the Artificial Intelligence and Statistics, Scottsdale, AZ, USA, 29 April–1 May 2013; pp. 442–450. [Google Scholar]
- Suk, J.; Kpotufe, S. Tracking Most Significant Arm Switches in Bandits. In Proceedings of the Conference on Learning Theory, London, UK, 2–5 July 2022; pp. 2160–2182. [Google Scholar]
- Qin, Y.; Menara, T.; Oymak, S.; Ching, S.; Pasqualetti, F. Non-stationary representation learning in sequential multi-armed bandits. In Proceedings of the ICML Workshop on Reinforcement Learning Theory, Virtual, 18-24 July 2021. [Google Scholar]
- Qin, Y.; Menara, T.; Oymak, S.; Ching, S.; Pasqualetti, F. Non-stationary representation learning in sequential linear bandits. IEEE Open J. Control Syst. 2022, 1, 41–56. [Google Scholar] [CrossRef]
- Agrawal, S.; Goyal, N. Further optimal regret bounds for thompson sampling. In Proceedings of the Artificial Intelligence and Statistics, Scottsdale, AZ, USA, 29 April–1 May 2013; pp. 99–107. [Google Scholar]
- Jin, T.; Xu, P.; Shi, J.; Xiao, X.; Gu, Q. Mots: Minimax optimal thompson sampling. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 5074–5083. [Google Scholar]
- Jin, T.; Xu, P.; Xiao, X.; Anandkumar, A. Finite-time regret of thompson sampling algorithms for exponential family multi-armed bandits. In Proceedings of the Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, 28 November–9 December 2022; pp. 38475–38487. [Google Scholar]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables; US Government Printing Office: Washington, DC, USA, 1964; Volume 55.
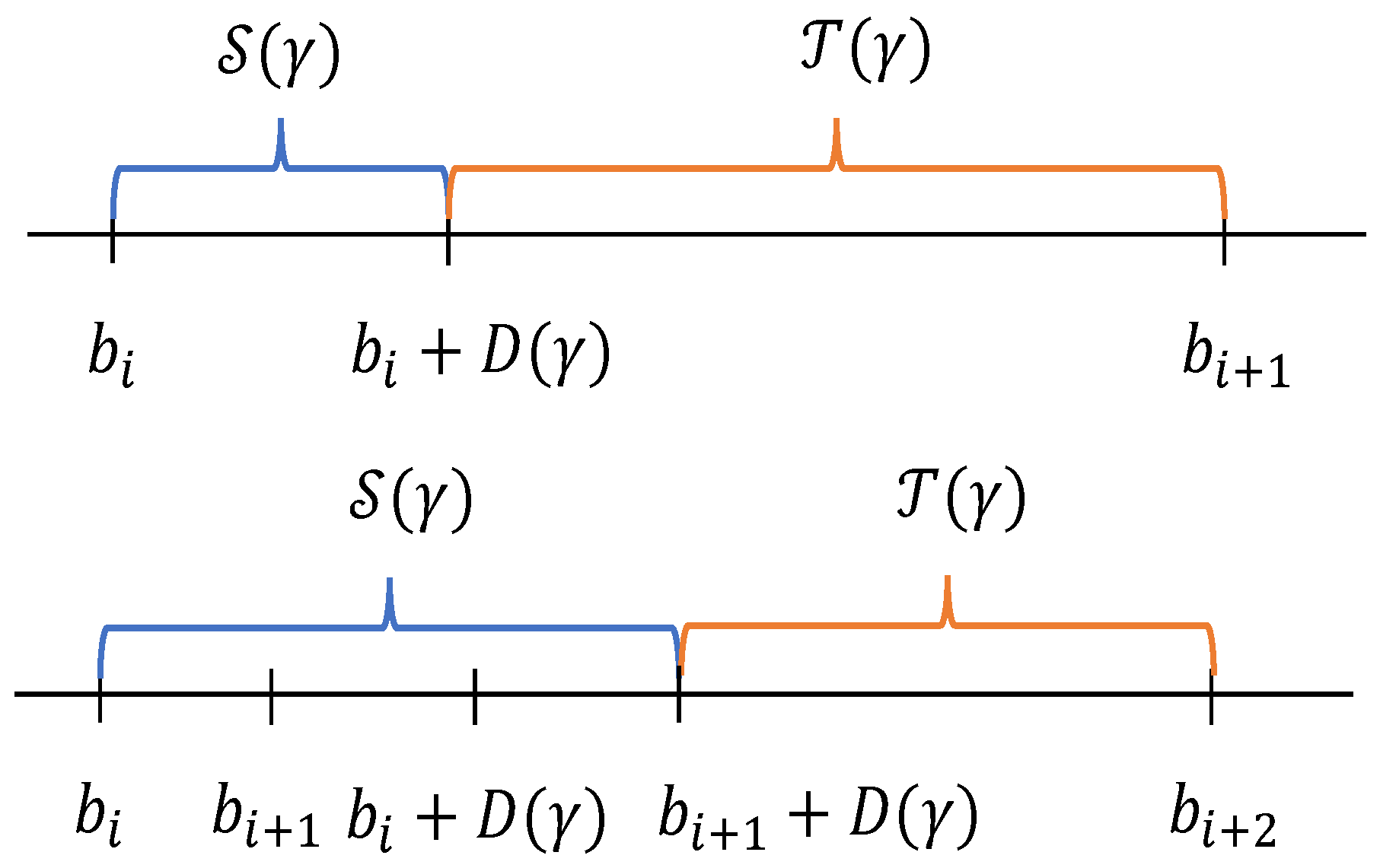


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | TS | DS-TS | SW-TS | |||
|---|---|---|---|---|---|---|
| std | ||||||
| Regret | 333,835 | 305,064 | 41,790 | 52,909 | 83,731 | 83,150 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, H.; Guo, F.; Zhu, L. Thompson Sampling for Non-Stationary Bandit Problems. Entropy 2025, 27, 51. https://doi.org/10.3390/e27010051
Qi H, Guo F, Zhu L. Thompson Sampling for Non-Stationary Bandit Problems. Entropy. 2025; 27(1):51. https://doi.org/10.3390/e27010051
Chicago/Turabian StyleQi, Han, Fei Guo, and Li Zhu. 2025. "Thompson Sampling for Non-Stationary Bandit Problems" Entropy 27, no. 1: 51. https://doi.org/10.3390/e27010051
APA StyleQi, H., Guo, F., & Zhu, L. (2025). Thompson Sampling for Non-Stationary Bandit Problems. Entropy, 27(1), 51. https://doi.org/10.3390/e27010051