3.2. Sufficiency
From the above discussion on the necessity, it is not difficulty to see that if f is a solution to M such that the conditions in Theorem 1 hold, then any CWF g resulted from a series of the swap operations between satisfies . Therefore, the sufficiency of the conditions follows if one can further show that any solution to M can be obtained from repeated applications of the swap operation between . However, it is, in general, not obvious to establish such a connection between f and an arbitrary solution to M. Thus, we take a different approach to showing the sufficiency. Our main idea is to translate the conditions in Theorem 1 to properties shared by all solutions to M and utilize these properties to establish the sufficiency of the conditions.
As mentioned before, the CWF f induced by h strings of length n and weight is determined by the behaviors of the functions on because of the constant weight. Based on the values that the functions take at , i.e., the median weight , the functions can be formed into groups . In the following, we analyze the behaviors of the functions according to their membership in these groups. Let us first rephrase the conditions for in Theorem 1 using their rotational symmetry.
Proposition 5. Let f be a solution that satisfies the conditions in Theorem 1. Then the following holds:
- (i)
For any , either or there are exactly two maximal intervals between and , and exactly one of the two intervals is contained in .
- (ii)
For any , there is exactly one maximal interval between and .
Proof. As mentioned previously, for any , we have if and only if . For any with , since f satisfies the conditions in Theorem 1, there is either one maximal interval or two maximal intervals between and . Since , it follows that at least one of the maximal intervals is contained in or . Suppose there is only one maximal interval between and . Then, the maximal interval is contained in or , but by Proposition 1, there are two maximal intervals between and , which is a contradiction. So, there are exactly two maximal intervals. Now, suppose the two intervals are both in or both in . Then, by Proposition 1, there are more than two maximal intervals between and , which is a contradiction. It follows that exactly one of the two intervals is contained in .
For any , we have ; so, by Proposition 1, there exists one maximal interval between and that contains . Furthermore, if there is another maximal interval contained in or , by Proposition 1, there are at least three maximal intervals between and , which is a contradiction to the conditions in Theorem 1. Therefore, there is exactly one maximal interval between and . □
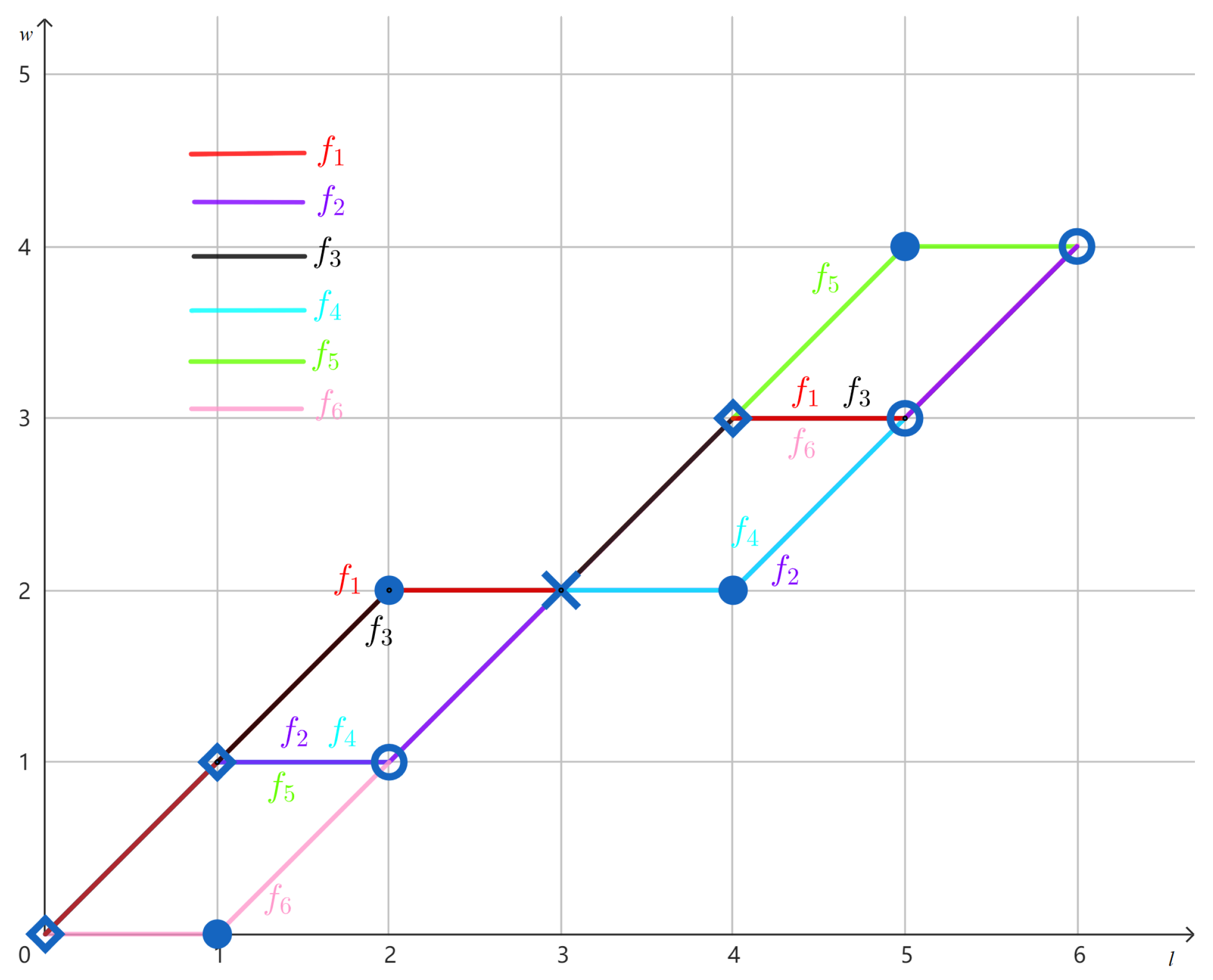
Example 5. Consider the set of strings . The CWF g induced by V is given by Table 3. One can check that g satisfies the conditions in Theorem 1. Below, let us verify what Proposition 5 claims. Note that the strings in V have the same weight and . From Table 3, we can observe that , and and are the only two maximal intervals between and . At the same time, . From Table 3, we can observe that there is exactly one maximal interval between and , and the same holds for and . Below, we introduce two more definitions that are helpful for discussing the behaviors of the functions in this subsection.
Definition 14. For and , let be the graph of over I and denote .
Definition 15. An element is called a branching point if and . An element is called a merging point if and . The branching and merging points are so named because we would like to visualize the graphs evolving from to .
Example 6. Let and as given in Examples 1 and 5. In Figure 2, we depict and by writing the non-zero numbers on top of the points . The numbers and can be determined by (3) and (4) in Remark 3, from which branching and merging points can be identified using Definition 15. Using Proposition 5, we examine the conditions in Theorem 1 in terms of the branching points and merging points on in a series of lemmas below. Lemma 3 first examines the functions for which .
Lemma 3. Let f be a solution to M that satisfies the conditions in Theorem 1 and let . If is a merging point, then there are no branching points in .
Proof. If is a merging point, there exists such that and . We claim . Indeed, if then there is at least one maximal interval between and contained in , in addition to the one contained in . Since f satisfies the conditions in Theorem 1, we must have . However, by Proposition 5, if there should be only one maximal interval between and , leading to a contradiction. Hence, .
Suppose is a branching point. Then there exists such that and . Since is a merging point and we have , there must exist such that and . It follows that there are two maximal intervals between and , and therefore, by the conditions in Theorem 1, we have .
If , then by Proposition 5, there should be exactly one maximal interval between , which is a contradiction.
If , then and . Therefore, the median weights of are different from that of and there exists such that . Since , we have . It follows that . So there exists a maximal interval between that is contained in , in addition to the one contained in . Since we have , and therefore, by the conditions in Theorem 1, there should be only one maximal interval between , which is a contradiction.
Thus, there are no branching points in . □
Remark 4. One can also verify that if is a branching point, where , then has no merging points.
Example 7. Continuing Example 5, let us use the CWF g to verify Lemma 3 and Remark 4. In this case, . Note thatcontains two branching points , and two merging points , , as shown in Figure 2. The next three lemmas examine the behaviors of for which . In particular, the discussion is based on whether are all the same or not.
Lemma 4. Let f be a solution to M that satisfies the conditions in Theorem 1. If are all the same, then there are no branching points in for all .
Proof. Suppose there exist branching points in for some and let be a branching point. Since for any , there must exist such that and . Moreover, since , we have for some . It follows that there exist two maximal intervals between and . This is a contradiction to Item (ii) in Theorem 1 by noticing since for all . □
If
are not all the same, Lemma 5 shows that graphs of
over
are essentially of two kinds. The proof of Lemma 5 is presented in
Appendix A.
Lemma 5. Let f be a solution to M that satisfies the conditions in Theorem 1. If are not all the same, then there exists such that there are exactly two maximal intervals between and , and are all the same. Moreover, it holds that for all or for all .
Using Lemma 5, we can further deduce the property of the branching points and merging points on .
Example 8. Let g be the CWF induced by as in Example 5. In this case, . Note that are not all the same (see Figure 3). As pointed out by Lemma 5, there exists , such that there are exactly two maximal intervals ( and ) between and . Moreover, and it holds that . In addition, observe in Figure 3 that is the only branching point with on the graph of , as asserted in the next lemma. Lemma 6. Let f be a solution to M that satisfies the conditions in Theorem 1. If are not all the same, then there exists such that there is a maximal interval between and , where . Moreover, is the only branching point in and there is no merging point in for all .
Proof. By Lemma 5 and Proposition 5, there exists such that there is a maximal interval between and , where . In addition, by Lemma 5, we have that is a merging point in for all . In what follows, let .
Suppose there exists such that is a branching point. By Lemma 5, there exist such that and . It follows that there are two maximal intervals between : one is contained in and the other is contained in (since the median weight of is different from that of ). However, we have , which is a contradiction to the conditions in Theorem 1. Therefore, is the only branching point in .
Suppose there exists such that is a merging point. By Lemma 5, there exists such that and . Since is the only branching point in for all , it follows from Lemma 5 that there exists such that . Therefore, there exist two maximal intervals between : one contained in and the other is contained in . However, we have , which is a contradiction to the conditions in Theorem 1. Thus, there is no merging point in . □
So far, we have translated the conditions in Theorem 1 to properties of the branching points and merging points on . The advantage of doing so is that properties of branching points and merging points are shared by all solutions to M. Let be two solutions to M. As a result of Remarks 2 and 3, is a branching point in for some if and only if is a branching point in for some . In particular, there is no branching point in for if and only if there is no branching point in . The same statements hold for merging points. In view of this, we can then facilitate the description of the conditions in Theorem 1 in terms of branching points and merging points to establish the sufficiency of the conditions in Theorem 1.
Let us present two simple propositions that relate using branching points and merging points.
Proposition 6. Let f, be two solutions to M and . If there is no branching point in and for some , then for any it holds that .
Proof. Suppose there exist such that . Let be such that and . Let . Since are solutions to M, it follows that the number of pairs in M is at least 2, i.e., . Moreover, we have . Thus, by Definition 15, is a branching point in , resulting in a contradiction. □
Proposition 7. Let f, be two solutions to M and . If and , there must be a branching point in . Similarly, if and , there must be a merging point in .
Proof. The first part of the statement is a direct consequence of Proposition 6. For the second part, we observe that there exists such that and . Without loss of generality, assume and . These two equations imply and , respectively. Thus, by Definition 15, is a merging point in . □
In the next two lemmas, we show that if are two solutions to M with f satisfying the conditions in Theorem 1, then the multiset equality must hold, thereby proving the sufficiency of the conditions in Theorem 1 for unique reconstruction up to reversal.
Lemma 7. Let f, be two solutions to M, with f satisfying the conditions in Theorem 1. Let be a multiset and define accordingly. Then, .
Proof. Let
. Note that
since their median weights are different. Thus, there are branching points in
. Let
be the branching point in
such that
for any branching point
. Let
In other words,
r is an indicator of the behavior of
to the left of the branching point
. By definition of
r, we have
.
Let and . In the following, we will show . Since there is no branching point in and , by Proposition 6, we have for any . Suppose for some . Then by Proposition 7, there is a merging point in . But then by Lemma 3, there are no branching points in , contradicting that is a branching point. Thus, for all . It follows that for any .
Next, let us show that . Toward a contradiction, suppose that there exists . Then, and . Note that . If , by Proposition 7, there must be a branching point in , contradicting the assumption that for any branching point . If , there must be a merging point in , but by Lemma 3 there should be no branching points in , contradicting that is a branching point. We thus conclude , and so, .
Note that for any , we have . Therefore, the multiplicity of in is . Taking , one can repeat the above arguments to show that for any and the multiplicity of in is .
Since are solutions to M, , i.e., the multiplicity of in equals the multiplicity of in . Furthermore, this holds for distinct . Since , i.e., , we obtain . □
Lemma 8. Let f, be two solutions to M with f satisfying the conditions in Theorem 1. Let be a multiset and define accordingly. Then, .
The idea of the proof for Lemma 8 is similar to that for Lemma 7, whereas it relies on Lemmas 4 and 6 instead of Lemma 3. The complete proof is given in
Appendix B.
It follows from Lemmas 7 and 8 that the conditions in Theorem 1 are sufficient for unique reconstruction up to reversal.
Example 9. Let us use Theorem 1 to determine whether the multiset given in Example 1 can be uniquely reconstructed up to reversal. The CWF f induced by U is given in Example 2. As shown in Figure 1, there are two maximal intervals ( and ) between and . This violates Item (ii) of Theorem 1, so we conclude that U cannot be uniquely reconstructed from up to reversal. Indeed, in Example 4, we found multisets not equivalent to U but compatible with . 


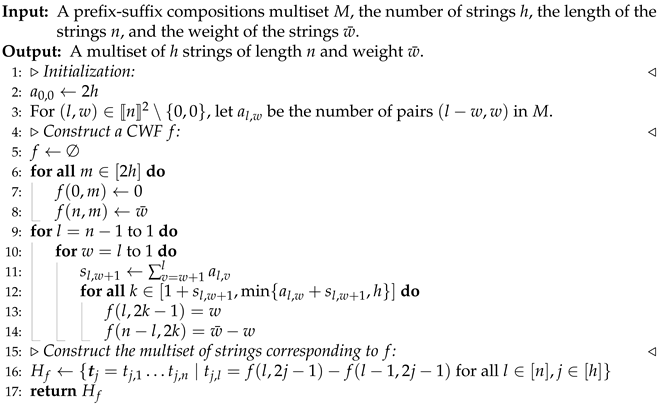



{kind=link}
{kind=link}
{kind=link}