
Causal Structure Learning with Conditional and Unique Information Groups-Decomposition Inequalities



Abstract
1. Introduction
2. Previous Work on Information-Theoretic Measures and Causal Graphs Relevant for Our Derivations
2.1. Mutual Information Inequalities Associated with Independencies
2.2. Definition and Properties of the Unique Information
2.3. Causal Graphs and Conditional Independencies
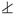 cannot occur. This is because d-separability between node Y and the set of nodes is determined by separately considering the lack of active paths between Y and each node and . Since the set of paths between Y and is the union of the paths between Y and both and , considering jointly does not add new paths that could create a dependence of Y with . A dependence can only be created by conditioning on some other variable, which could activate additional paths by activating a collider.
cannot occur. This is because d-separability between node Y and the set of nodes is determined by separately considering the lack of active paths between Y and each node and . Since the set of paths between Y and is the union of the paths between Y and both and , considering jointly does not add new paths that could create a dependence of Y with . A dependence can only be created by conditioning on some other variable, which could activate additional paths by activating a collider.2.4. Inequalities for Sums of Information Terms from Groups of Variables
3. Results
3.1. Data Processing Inequality for Conditional Unique Information
3.2. Inequalities Involving Sums of Information Terms from Groups
. Augmenting the groups to , , and the conditions of Proposition 3 are fulfilled, as can be verified by d-separation. Coefficients are determined by due to the intersection of the groups in U. Note that hidden variables are not restricted to be hidden common ancestors, and here U is a mediator between and . In Figure 2B, consider groups , , , which do not fulfill the conditions of Proposition 1. Augmenting the groups to , , , , , and the conditions are fulfilled. Maximal intersection values are . In both examples the upper bound is since cannot be estimated due to hidden variables.. Groups can be augmented to , , for . Proposition 3 then holds with for all groups. The pairs of groups contribute to the sum as , which in the testable inequality of the form of Equation (5) reduces to . The upper bound to the sum of terms is . This inequality provides causal inference power because for all j is not directly testable. As previously indicated, the inference power of an inequality emanates from the possibility to discard causal structures that do not fulfill it. Note that for this system an alternative is to define N groups instead of groups, each as . In this case Proposition 1 is already applicable with the coefficients being all 1, since for all . For this inequality, each of the N groups contributes with , and since there are no hidden variables the l.h.s. is . However, this latter inequality holds for any causal structure that fulfills for all . Given that these independencies do not involve hidden variables, they are directly testable from data, so that the latter inequality does not provide additional inference power, in contrast to the former one., for all . However, given that , each can be replaced to build , and since , for all Proposition 3 applies after using Proposition 4 to create . A testable inequality is derived with upper bound and a sum of terms , each being a lower bound of given the data processing inequality that follows from . The coefficients are . Therefore, in this case Proposition 4 results in an inequality when no inequality held for . In Figure 2E, the same procedure relies on and to use to create a testable inequality with l.h.s. and the sum of terms in the r.h.s. with . Note that by U, which has no subindex, we represent in Figure 2E a hidden common driver of all N groups, not only the displayed . In this example Proposition 3 could have been directly applied without using Proposition 4 if augmenting to , with and , since . However, , since all groups intersect in U. Therefore, in this case an inequality already exists without applying Proposition 4, but its use allows replacing by , hence creating a tighter inequality with higher causal inference power.. The data processing inequality of conditional mutual information does not hold with . This data processing inequality could be used adding to the latent common parent in , but this variable would be shared by all augmented groups , leading to an intersection of all N groups. Alternatively, the data processing inequality holds for the unique information with , and for all . Proposition 5 is applied with , , and , . This leads to an inequality with as upper bound and the sum of terms at the r.h.s. with coefficients determined by . In Figure 3B, taking and defining the conditioning set , we have and . On the other hand, , so that the data processing can be applied with the unique information and Proposition 5 is applied with , and . An inequality exists given that , and the testable inequality has an upper bound and at the r.h.s. the sum of terms , with . for all . The mutual information data processing inequality is not applicable to substitute because . However, for the M groups like i, the independence leads to the data processing inequality . For these groups, and . For the groups like k, the independence leads to . For these groups and . In all cases the modified groups are , which fulfill the requirement for all needed to apply Proposition 3. The testable inequality that follows from Proposition 5 has upper bound and in the sum at the r.h.s. has M terms of the form and terms of the form . The coefficients are determined by . for all within the M groups, and for all within the groups. Proposition 6 applies as follows. For the groups, with , , , and . The independencies for correspond in this case to , for . For the other M groups, with , , , , , , , and . The independencies involved are , for , and , for .3.3. Inequalities Involving Sums of Information Terms from Ancestral Sets
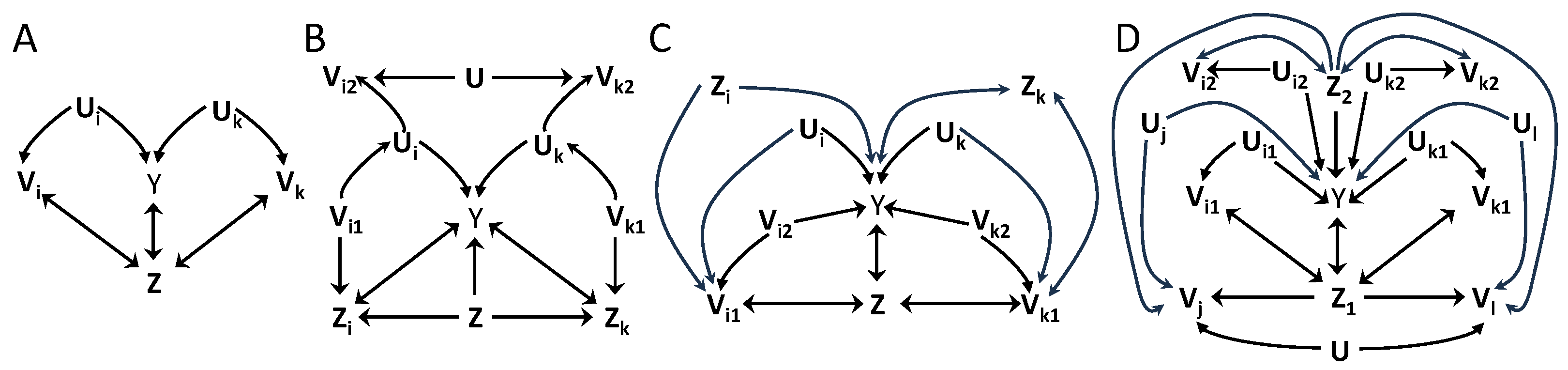
, and no data processing inequalities help to substitute these variables. On the other hand, Theorem 2 can be applied with , leading to , , and , for all . The augmented ancestral sets are , and , also for all , resulting in . Focusing on the case of , or any subset of it, in all cases the associated testable inequality has as upper bound and in the r.h.s. the sum of terms , . Alternatively, defining and , Proposition 3 is applicable with the two groups intersecting in and . The associated testable inequality has the same upper bound and in the r.h.s. the sum of terms and . In this case, which inequality has more causal inferential power will depend on the exact distribution of the data.4. Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A. Proofs of Propositions 1, 3, and 6
Appendix B. Proof of Theorem 2
. Under the faithfulness assumption, we examine the four different types of paths in G that could create a dependence. First, there is a variable and a variable with an active directed path in G from to , not blocked by . If this path is active in G conditioning on , it also exists in any , with , since the removal of outgoing arrows has the same effect as conditioning for the paths in which the conditioning variables are noncolliders (i.e., do not have two incoming arrows). This active directed path means that would be an ancestor of in . Therefore, given and , itself would be part of . However, as argued above, an intersection of and is contradictory with . Second, there is a variable and a variable with an active directed path in G from to , not blocked by . Again, this path being active in G when conditioning on , means that it also exists in any , with . Therefore, would be an ancestor of in . This is again a contradiction with the definition of because it could be redefined to include groups, since would be an ancestor of all groups intersecting in . Third, there is a variable , a variable , and another variable that is not part of nor with an active directed path in G from to and an active directed path from to , both not blocked by . This would also imply that these directed paths exist in , with , and hence is an ancestor of and in . Since is an ancestor of but by construction , this means that has to be part of or of , since any ancestor of is part of . If , conditioning on would prevent from having active directed paths from to and from to , leading to a contradiction. We now consider the case . Since is an ancestor of , by construction of , is an ancestor of . This means that includes which, given Equation (A11), is in contradiction with the criterion for selection of reference groups such that . In these three types of cases, an active path would exist despite conditioning on . In the last type, a path would be activated by conditioning on . At least one variable has to be a collider or a descendant of a collider along the path that conditioning activates. Consider first that a single collider is involved. For the collider to activate the path, it must exist an active directed subpath to from a variable that is part of or part of its ancestor set in . Since this directed subpath is active in G when conditioning on , it is also active in . This means that would be an ancestor of in . If is part of or part of , then being an ancestor of means that it is part of . Accordingly, by definition of , would be part of or of . The former option leads to a contradiction because has already been removed from and is part of the conditioning variables, so that the subpath from to could not be part of the path activated by conditioning on the collider. The latter option, being part of , is in contradiction with it being an ancestor of , since this means being an ancestor of the group taken as reference to build , which by construction is chosen from . We continue considering that is part of , for . In this case, being an ancestor of would mean that either is in or it would have been possible to define to include . In the former case, this leads to a contradiction because for all have been constructed taking as reference a group belonging to . In the latter case, this leads to a contradiction because is constructed to include all variables in the intersection with the maximum number of groups. The same reasoning holds if the activated path contains more than one collider from , by selecting the collider closest to a variable in along the path. Since for all four types of paths that could lead to we reach a contradiction, holds and Lemma 1(ii) can be applied to obtain the inequality in Equation (A15). Combining Equations (A14) and (A15) with the r.h.s. of Equation (A13), we obtain that
Appendix C. On Required Assumptions Relating Independencies and d-Separation
References
- Spirtes, P.; Glymour, C.N.; Scheines, R. Causation, Prediction, and Search, 2nd ed.; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Pearl, J. Causality: Models, Reasoning, Inference, 2nd ed.; Cambridge University Press: New York, NY, USA, 2009. [Google Scholar]
- Peters, J.; Janzing, D.; Schölkopf, B. Elements of Causal Inference: Foundations and Learning Algorithms; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Malinsky, D.; Danks, D. Causal discovery algorithms: A practical guide. Philos. Compass 2018, 13, e12470. [Google Scholar] [CrossRef]
- Verma, T. Graphical Aspects of Causal Models; Technical Report R-191; Computer Science Department, UCLA: Los Angeles, CA, USA, 1993. [Google Scholar]
- Zhang, J. On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias. Artif. Intell. 2008, 172, 1873–1896. [Google Scholar] [CrossRef]
- Tian, J.; Pearl, J. On the testable implications of causal models with hidden variables. In Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence, San Francisco, CA, USA, 1–4 August 2002. [Google Scholar]
- Verma, T.; Pearl, J. Equivalence and synthesis of causal models. In Proceedings of the Sixth Conference on Uncertainty in Artifial Intelligence, Cambridge, MA, USA, 27–29 July 1990; pp. 220–227. [Google Scholar]
- Chicharro, D.; Besserve, M.; Panzeri, S. Causal learning with sufficient statistics: An information bottleneck approach. arXiv 2020, arXiv:2010.05375. [Google Scholar]
- Parbhoo, S.; Wieser, M.; Wieczorek, A.; Roth, V. Information bottleneck for estimating treatment effects with systematically missing covariates. Entropy 2020, 22, 389. [Google Scholar] [CrossRef]
- Hoyer, P.O.; Janzing, D.; Mooij, J.M.; Peters, J.; Schölkopf, B. Nonlinear causal discovery with additive noise models. In Proceedings of the 21st Conference on Advances in Neural Information Processing Systems (NIPS 2008), Vancouver, BC, Canada, 8–11 December 2008; pp. 689–696. [Google Scholar]
- Zhang, K.; Hyvärinen, A. On the identifiability of the post-nonlinear causal model. In Proceedings of the 25th Annual Conference on Uncertainty in Artificial Intelligence (UAI), Montreal, QC, Canada, 18–21 June 2009; pp. 647–655. [Google Scholar]
- Chicharro, D.; Panzeri, S.; Shpitser, I. Conditionally-additive-noise models for structure learning. arXiv 2019, arXiv:1905.08360. [Google Scholar]
- Shimizu, S.; Inazumi, T.; Sogawa, Y.; Hyvärinen, A.; Kawahara, Y.; Washio, T.; Hoyer, P.O.; Bollen, K. DirectLiNGAM: A direct method for learning a linear non-Gaussian structural equation model. J. Mach. Learn. Res. 2011, 12, 1225–1248. [Google Scholar]
- Evans, R.J. Graphs for margins of Bayesian networks. Scand. J. Stat. 2015, 43, 625. [Google Scholar] [CrossRef]
- Weilenmann, M.; Colbeck, R. Analysing causal structures with entropy. Proc. Roy. Soc. A 2017, 473, 20170483. [Google Scholar] [CrossRef]
- Bell, J.S. On the Einstein-Podolsky-Rosen paradox. Physics 1964, 1, 195–200. [Google Scholar] [CrossRef]
- Clauser, J.F.; Horne, M.A.; Shimony, A.; Holt, R.A. Proposed experiment to test local hidden-variable theories. Phys. Rev. Lett. 1969, 23, 880. [Google Scholar] [CrossRef]
- Pearl, J. On the testability of causal models with latent and instrumental variables. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–20 August 1995; pp. 435–443. [Google Scholar]
- Bonet, B. Instrumentality tests revisited. In Proceedings of the 17th Conference on Uncertainty in Artificial Intelligence (UAI), San Francisco, CA, USA, 2–5 August 2001; pp. 48–55. [Google Scholar]
- Kang, C.; Tian, J. Inequality constraints in causal models with hidden variables. In Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence, Cambridge, MA, USA, 13–16 July 2006; pp. 233–240. [Google Scholar]
- Chaves, R.; Luft, L.; Gross, D. Causal structures from entropic information: Geometry and novel scenarios. New J. Phys. 2014, 16, 043001. [Google Scholar] [CrossRef]
- Fritz, T.; Chaves, R. Entropic inequalities and marginal problems. IEEE Trans. Inf. Theory 2013, 59, 803–817. [Google Scholar] [CrossRef]
- Chaves, R.; Luft, L.; Maciel, T.O.; Gross, D.; Janzing, D.; Schölkopf, B. Inferring latent structures via information inequalities. In Proceedings of the 30th Conference on Uncertainty in Artificial Intelligence, Quebec City, QC, Canada, 23–27 July 2014; pp. 112–121. [Google Scholar]
- Dougherty, R.; Freiling, C.; Zeger, K. Six new non-Shannon information inequalities. In Proceedings of the IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 233–236. [Google Scholar]
- Weilenmann, M.; Colbeck, R. Non-Shannon inequalities in the entropy vector approach to causal structures. Quantum 2018, 2, 57. [Google Scholar] [CrossRef]
- Steudel, B.; Ay, N. Information-theoretic inference of common ancestors. Entropy 2015, 17, 2304–2327. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley and Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Ince, R.A.A. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- James, R.G.; Emenheiser, J.; Crutchfield, J.P. Unique Information via dependency constraints. J. Phys. A Math. Theor. 2019, 52, 014002. [Google Scholar] [CrossRef]
- Ay, N.; Polani, D.; Virgo, N. Information decomposition based on cooperative game theory. Kybernetika 2020, 56, 979–1014. [Google Scholar] [CrossRef]
- Kolchinsky, A. A novel approach to the partial information decomposition. Entropy 2022, 24, 403. [Google Scholar] [CrossRef]
- Pearl, J. Fusion, propagation, and structuring in belief networks. Artif. Intell. 1986, 29, 241–288. [Google Scholar] [CrossRef]
- Geiger, D.; Verma, T.; Pearl, J. d-Separation: From theorems to algorithms. In Proceedings of the Fifth Annual Conference on Uncertainty in Artificial Intelligence, Amsterdam, The Netherlands, 18–20 August 1989; pp. 118–125. [Google Scholar]
- Rauh, J.; Bertschinger, N.; Olbrich, E.; Jost, J. Reconsidering unique information: Towards a multivariate information decomposition. In Proceedings of the IEEE International Symposium on Information Theory (ISIT 2014), Honolulu, HI, USA, 29 June–4 July 2014; pp. 2232–2236. [Google Scholar]
- Banerjee, P.K.; Olbrich, E.; Jost, J.; Rauh, J. Unique Informations and Deficiencies. arXiv 2019, arXiv:1807.05103v3. [Google Scholar]
- Chicharro, D.; Panzeri, S. Synergy and redundancy in dual decompositions of mutual information gain and information loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef]
- Chicharro, D. Quantifying multivariate redundancy with maximum entropy decompositions of mutual information. arXiv 2017, arXiv:1708.03845. [Google Scholar]
- Pica, G.; Piasini, E.; Chicharro, D.; Panzeri, S. Invariant components of synergy, redundancy, and unique information among three variables. Entropy 2017, 19, 451. [Google Scholar] [CrossRef]
- Chicharro, D.; Pica, G.; Panzeri, S. The identity of information: How deterministic dependencies constrain information synergy and redundancy. Entropy 2018, 20, 169. [Google Scholar] [CrossRef]
- Chicharro, D.; Ledberg, A. Framework to study dynamic dependencies in networks of interacting processes. Phys. Rev. E 2012, 86, 041901. [Google Scholar] [CrossRef]
- Lütkepohl, H. New Introduction to Multiple Time Series Analysis; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Geweke, J.F. Measurement of linear dependence and feedback between multiple time series. J. Am. Stat. Assoc. 1982, 77, 304–313. [Google Scholar] [CrossRef]
- Chicharro, D. On the spectral formulation of Granger causality. Biol. Cybern. 2011, 105, 331–347. [Google Scholar] [CrossRef]
- Chicharro, D. Parametric and non-parametric criteria for causal inference from time-series. In Directed Information Measures in Neuroscience; Wibral, M., Vicente, R., Lizier, J.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 195–223. [Google Scholar]
- Brovelli, A.; Ding, M.; Ledberg, A.; Chen, Y.; Nakamura, R.; Bressler, S.L. Beta oscillations in a large-scale sensorimotor cortical network: Directional influences revealed by Granger causality. Proc. Natl. Acad. Sci. USA 2004, 101, 9849–9854. [Google Scholar] [CrossRef] [PubMed]
- Brovelli, A.; Chicharro, D.; Badier, J.M.; Wang, H.; Jirsa, V. Characterization of cortical networks and corticocortical functional connectivity mediating arbitrary visuomotor mapping. J. Neurosci. 2015, 35, 12643–12658. [Google Scholar] [CrossRef] [PubMed]
- Celotto, M.; Bím, J.; Tlaie, A.; De Feo, V.; Toso, A.; Lemke, S.M.; Chicharro, D.; Nili, H.; Bieler, M.; Hanganu-Opatz, I.L.; et al. An information-theoretic quantification of the content of communication between brain regions. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Granger, C.W.J. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Hiemstra, C.; Jones, J.D. Testing for linear and nonlinear Granger causality in the stock price-volume relation. J. Financ. 1994, 49, 1639–1664. [Google Scholar]
- Hlaváčková-Schindler, K.; Paluš, M.; Vejmelka, M.; Bhattacharya, J. Causality detection based on information-theoretic approaches in time-series analysis. Phys. Rep. 2007, 441, 1–46. [Google Scholar] [CrossRef]
- Geweke, J.F. Measures of conditional linear dependence and feedback between time series. J. Am. Stat. Assoc. 1984, 79, 907–915. [Google Scholar] [CrossRef]
- Caporale, M.C.; Hassapis, C.; Pittis, N. Unit roots and long-run causality: Investigating the relationship between output, money and interest rates. Econ. Model. 1998, 15, 91–112. [Google Scholar] [CrossRef]
- Caporale, M.C.; Pittis, N. Efficient estimation of cointegrating vectors and testing for causality in vector auto-regressions. J. Econ. Surv. 1999, 13, 3–35. [Google Scholar]
- Hacker, R.S.; Hatemi, J.A. Tests for causality between integrated variables using asymptotic and bootstrap distributions: Theory and application. Appl. Econ. 2006, 38, 1489–1500. [Google Scholar] [CrossRef]
- Massey, J.L. Causality, feedback and directed information. In Proceedings of the 1990 IEEE International Symposium Information Theory and Its Applications, Honolulu, HI, USA, 10–15 June 1990; Volume 27, pp. 303–305. [Google Scholar]
- Amblard, P.O.; Michel, O. On directed information theory and Granger causality graphs. J. Comput. Neurosci. 2011, 30, 7–16. [Google Scholar] [CrossRef]
- Chaves, R.; Majenz, C.; Gross, D. Information-theoretic implications of quantum causal structures. Nat. Commun. 2015, 6, 5766. [Google Scholar] [CrossRef]
- Wolfe, E.; Schmid, D.; Sainz, A.B.; Kunjwal, R.; Spekkens, R.W. Quantifying Bell: The resource theory of nonclassicality of common-cause boxes. Quantum 2020, 4, 280. [Google Scholar] [CrossRef]
- Tavakoli, A.; Pozas-Kerstjens, A.; Luo, M.; Renou, M.O. Bell nonlocality in networks. Rep. Prog. Phys. 2022, 85, 056001. [Google Scholar] [CrossRef] [PubMed]
- Henson, J.; Lal, R.; Pusey, M.F. Theory-independent limits on correlations from generalized Bayesian networks. New J. Phys. 2014, 16, 113043. [Google Scholar] [CrossRef]
- Wood, C.J.; Spekkens, R.W. The lesson of causal discovery algorithms for quantum correlations: Causal explanations of Bell-inequality violations require fine-tuning. New J. Phys. 2015, 17, 033002. [Google Scholar] [CrossRef]
- Wolfe, E.; Spekkens, R.W.; Fritz, T. The Inflation Technique for causal inference with latent variables. J. Caus. Inf. 2019, 7, 20170020. [Google Scholar] [CrossRef]
- Navascués, M.; Wolfe, E. The Inflation Technique completely solves the causal compatibility problem. J. Causal Infer. 2020, 8, 70–91. [Google Scholar] [CrossRef]
- Boghiu, E.C.; Wolfe, E.; Pozas-Kerstjens, A. Inflation: A Python library for classical and quantum causal compatibility. Quantum 2023, 7, 996. [Google Scholar] [CrossRef]
- Evans, R.J. Graphical methods for inequality constraints in marginalized DAGs. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Santander, Spain, 23–26 September 2012; pp. 1–6. [Google Scholar]
- Fraser, T.C. A combinatorial solution to causal compatibility. J. Causal Inference 2020, 8, 22. [Google Scholar] [CrossRef]
- Finkelstein, N.; Zjawin, B.; Wolfe, E.; Shpitser, I.; Spekkens, R.W. Entropic inequality constraints from e-separation relations in directed acyclic graphs with hidden variables. In Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence, Online, 27–29 July 2021; pp. 1045–1055. [Google Scholar]
- Evans, R.J. Latent-free equivalent mDAGs. Algebr. Stat. 2023, 14, 3–16. [Google Scholar] [CrossRef]
- Khanna, S.; Ansanelli, M.M.; Pusey, M.F.; Wolfe, E. Classifying causal structures: Ascertaining when classical correlations are constrained by inequalities. Phys. Rev. Res. 2024, 6, 023038. [Google Scholar] [CrossRef]
- Rodari, G.; Poderini, D.; Polino, E.; Suprano, A.; Sciarrino, F.; Chaves, R. Characterizing hybrid causal structures with the exclusivity graph approach. arXiv 2023, arXiv:2401.00063. [Google Scholar]
- Treves, A.; Panzeri, S. The upward bias in measures of information derived from limited data samples. Neural Comput. 1995, 7, 399–407. [Google Scholar] [CrossRef]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 17, 1191–1253. [Google Scholar] [CrossRef]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, R.D. Mutual Information Neural Estimation. In Proceedings of the Thirty-Fifth International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 531–540. [Google Scholar]
- Poole, B.; Ozair, S.; van den Oord, A.; Alemi, A.A.; Tucker, G. On Variational Bounds of Mutual Information. In Proceedings of the Thirty-Sixth International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 5171–5180. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chicharro, D.; Nguyen, J.K. Causal Structure Learning with Conditional and Unique Information Groups-Decomposition Inequalities. Entropy 2024, 26, 440. https://doi.org/10.3390/e26060440
Chicharro D, Nguyen JK. Causal Structure Learning with Conditional and Unique Information Groups-Decomposition Inequalities. Entropy. 2024; 26(6):440. https://doi.org/10.3390/e26060440
Chicago/Turabian StyleChicharro, Daniel, and Julia K. Nguyen. 2024. "Causal Structure Learning with Conditional and Unique Information Groups-Decomposition Inequalities" Entropy 26, no. 6: 440. https://doi.org/10.3390/e26060440
APA StyleChicharro, D., & Nguyen, J. K. (2024). Causal Structure Learning with Conditional and Unique Information Groups-Decomposition Inequalities. Entropy, 26(6), 440. https://doi.org/10.3390/e26060440