1. Introduction
Conducting tests under normal operating conditions (NOCs) for obtaining information on the lifetimes of highly reliable products is unrealistic, since they require a very long duration, which is usually not possible or economical. For this, accelerated life testing (ALT) experiments are designed and applied to obtain information about the data in a reasonable time frame. With ALT, the test units are exposed to a specific failure-relevant stress (e.g., temperature, pressure, or use rate) and operate in an environment with stronger testing conditions than NOCs. The increased stress reduces the time to failure and produces more observations during the conducted life test. The data collected with an ALT test and the corresponding inferential results have to be eventually extrapolated to NOCs to estimate the lifetime distribution of interest. For some references and the introduction of ALT, see Nelson [
1], Meeker and Escobar [
2], and Bagdonavicius and Nikulin [
3]. The most commonly used, in-practice type of ALT experiment is constant stress ALT (CSALT), under which independent samples of testing units are exposed to different levels of the stress factor and held constant during the whole duration of the experiment (see, for instance, Nelson [
4] and Yang [
5]). An alternative type of ALT experiment is step-stress ALT (SSALT). A SSALT experiment uses a single sample, and all test units are exposed to exactly the same experimental conditions, which vary (usually in an increasing manner) during the test procedure. In particular, all items are exposed to the same stress level, which is increased once or several times, after a prefixed time or upon the occurrence of a predetermined number of failures. SSALT experiments lead to quicker results than CSALT (see Miller and Nelson [
6] and Han and Ng [
7]). SSALT tests that involve only a single stress-change point are called simple SSALT.
Statistical inference for SSALT models has been developed for various modeling setups and underlying distributional assumptions, mainly through maximum likelihood or Bayesian procedures. The approaches discussed here are frequentist approaches. For Bayesian treatments of SSALT models, we refer to [
8,
9,
10,
11,
12,
13] and the references cited therein. It is worth noting that the first Bayesian analysis of SSALT models was by DeGroot and Goel [
14]. SSALT models are analyzed in terms of the cumulative density function (CDF), the probability density function (PDF), the survival function (SF), and the hazard rate (HR). In reliability context, the concept of aging intensity (AI) has been introduced by Jiang et al. [
15] as the ratio of the instantaneous hazard rate and a baseline hazard rate. It is a useful tool to describe reliability properties of a random variable, and it is also used in order to make comparisons among different distributions. However it has never been considered in the SSALT context.
In this work, we introduced an AI function for SSALT and explored its properties and utility. Comparing the cumulative exposure (CE) and tampered failure rate (TFR) models for SSALT through AI, we gained a deeper understanding of their differences in terms of their aging effects on test units. In
Section 2, we provide the preliminaries of the SSALT models and set notation. The AI function for SSALT models is introduced and explored for common families of lifetime distributions in
Section 3. An AI-based estimation procedure for SSALT models is discussed in
Section 4, along with examples, while the AI-based estimation is compared to the maximum likelihood estimation using Kullback–Leibler and cumulative Kullback–Leibler divergence in
Section 5. The final section,
Section 6, summarizes our findings.
2. Preliminaries of SSALT
Consider an SSALT experiment with
m stress levels,
, and
n units being tested. The stress levels are changed from
to
,
, at pre-specified time points
. In case of simple SSALT (
), the single
is for simplicity and is denoted by
. Different distributions are assumed in the steps, corresponding to units of behavior under different stress levels, which are, nonetheless, linked in a manner so that the compound CDF is absolutely continuous over all stress levels. Thus, the units’ failure times
are described by the order statistics (OSs)
from an absolutely continuous CDF
G. The model usually employed for ensuring the continuity of
G is the cumulative exposure (CE) model (see, for instance, Nelson [
1,
16], Meeker and Escobar [
2], Gouno and Balakrishnan [
17], Bagdonavicius and Nikulin [
3], and Balakrishnan [
18]). Furthermore, ALT experiments are frequently censored, with Type-I and Type-II censoring being the most commonly considered censoring schemes. For simplicity of presentation, we restricted the presentation to simple SSALT models and complete observed sample, but our results are extendable to models with
and under censoring.
The CE simple SSALT model is defined by the following CDF:
where
and
are the lifetime CDFs under stress levels
and
, respectively, and the constant
c is chosen so that
, i.e., it ensures the continuity of
G. Then, the corresponding PDF and HR function are given by
and
respectively.
A common distributional assumption for the lifetimes under each stress level is the family of exponential distributions, which leads to explicit maximum likelihood estimators (MLEs) for the model parameters. Consider, thus, the CE SSALT model for an exponential distribution, i.e., let
,
. Then,
, and the CDF of the model is as follows:
For this model, the maximum likelihood estimators (MLE) for the parameters
and
have been derived and studied, as reviewed and discussed by Balakrishnan [
18] and Kateri and Kamps [
19], where the unbiasedness of the estimator for
was also proved.
Suppose we have a random sample of lifetimes under (
2) of size
n, with the corresponding OSs
, such that
failures are realized in the first stress level, i.e.,
, and the remaining
(
) in the second one. Then, the MLEs for
and
are given by
and
respectively.
For a simple SSALT model, Bhattacharyya and Soejoeti [
20] were the first to consider a model assumption, alternative to CE, in which the increase in stress level from
to
has a multiplicative effect on the subsequent HR, i.e.,
This model is known as the tampered failure rate model (TFR), and its CDF is expressed as follows:
while the corresponding PDF is given by
From the expressions in (
6) and (
7), it is easy to verify that
represents the proportionality constant between the hazard on the first and the second level, i.e., the derivation of (
5).
The TFR SSALT model is appealing in a reliability context, being linked through (
5) to Cox’s proportional hazard model. Compared to the CE model, it is more convenient to work with when the underlying distributions are something other than exponential (e.g., Weibull), while the TFR and CE models coincide in the case of exponential distributed lifetimes. For a detailed comparison of these two models, we refer to Kateri and Kamps [
21].
An equivalent expression for the CDF of the TFR simple SSALT model, which is helpful for deriving statistical inference, is
Furthermore, Kateri and Kamps [
21] extended the TFR SSALT models to a generalized failure rate-based family of models by considering a flexible-scale family of distributions for the lifetimes under each stress level
, and it is defined by
where
is strictly increasing and differentiable on
,
and
. Standard families of distributions used for modeling lifetimes (e.g., exponential, Weibull, Lomax, Pareto) are members of this family and can be treated in a unified manner (see Table 1 in [
21]). This model generalizes TFR in the sense that it can consider different distributional families for the stress levels (
), while
in (
5) can be non-constant, i.e, time dependent (
).
3. AI Function for SSALT
For a non-negative and absolutely continuous random variable
X with PDF
, CDF
, survival function (SF)
, and hazard rate function
, the aging intensity (AI) function is defined as
where log denotes the natural logarithm. Thus,
is the ratio of the instantaneous hazard rate
to the average hazard rate in the interval
and expresses the units’ average aging behavior. It analyzes the aging property quantitatively, in the sense that the larger the AI, the stronger the tendency of aging. We remark that the survival and the hazard rate functions uniquely determine the AI function, but the converse does not hold. In fact, the AI function of a non-negative random variable determines a family of survival functions through a relation presented in [
22]. Some properties of AI functions are presented in Nanda et al. [
23], who defined, in particular, a new stochastic order (aging intensity order) based on the AI functions. For further properties, applications, and extensions of the aging intensity functions, see [
24,
25,
26,
27,
28,
29].
So far, the aging intensity has been considered for random variables with an absolutely continuous PDF. In order to extend the notion of the AI function to SSALT models, we need to take into account that the PDF (and consequently the HR function) changes at the stress change point
. Hence, on the first level, the aging intensity function has the same expression as in (
9) but in terms of
, while on the second level, in order to have the average of the hazard rate in the interval
, we need to consider the change of the hazard at
. Thus, the aging intensity function for simple SSALT is
where
and
Consider the CE SSALT model for an exponential distribution with a CDF given in (
2). Hence, the aging intensity function is expressed on the two levels of stress as
Analogously, consider next the CE SSALT model for Weibull-distributed lifetimes, i.e., let
,
, with a common shape parameter
under both levels. Then,
,
, leading to
, and the CDF (
1) takes the form
from which the PDF and the hazard rate function are derived as follows:
and
respectively. Finally, through (
10) and (
11), the AI function on the two stress levels can be expressed as
For the TFR simple SSALT with the scale family of distributions as given in (
8), the AI function terms (
10) and (
11) are simplified to (
10), which simplifies to
and
In particular, at the stress change point
, we have
Hence, if we consider the case in which
, the condition
is equivalent to
which holds if, and only if,
. This is a reasonable assumption representing a higher stress in the second level with respect to the first one. Furthermore, when
and
(i.e., constant stress),
, as expected.
The
and
expressions for some distributions of interest, members of the scale family of distributions (
8), are as follows:
,
:
,
:
,
:
Remark 1. For exponential lifetimes, and (obtained also from (14) for ), obviously coincide with those under the CE model, i.e., (12), as expected, since the TFR and CE are equivalent for exponential distributed lifetimes. For the Weibull distribution, in (14) can be equivalently written as In
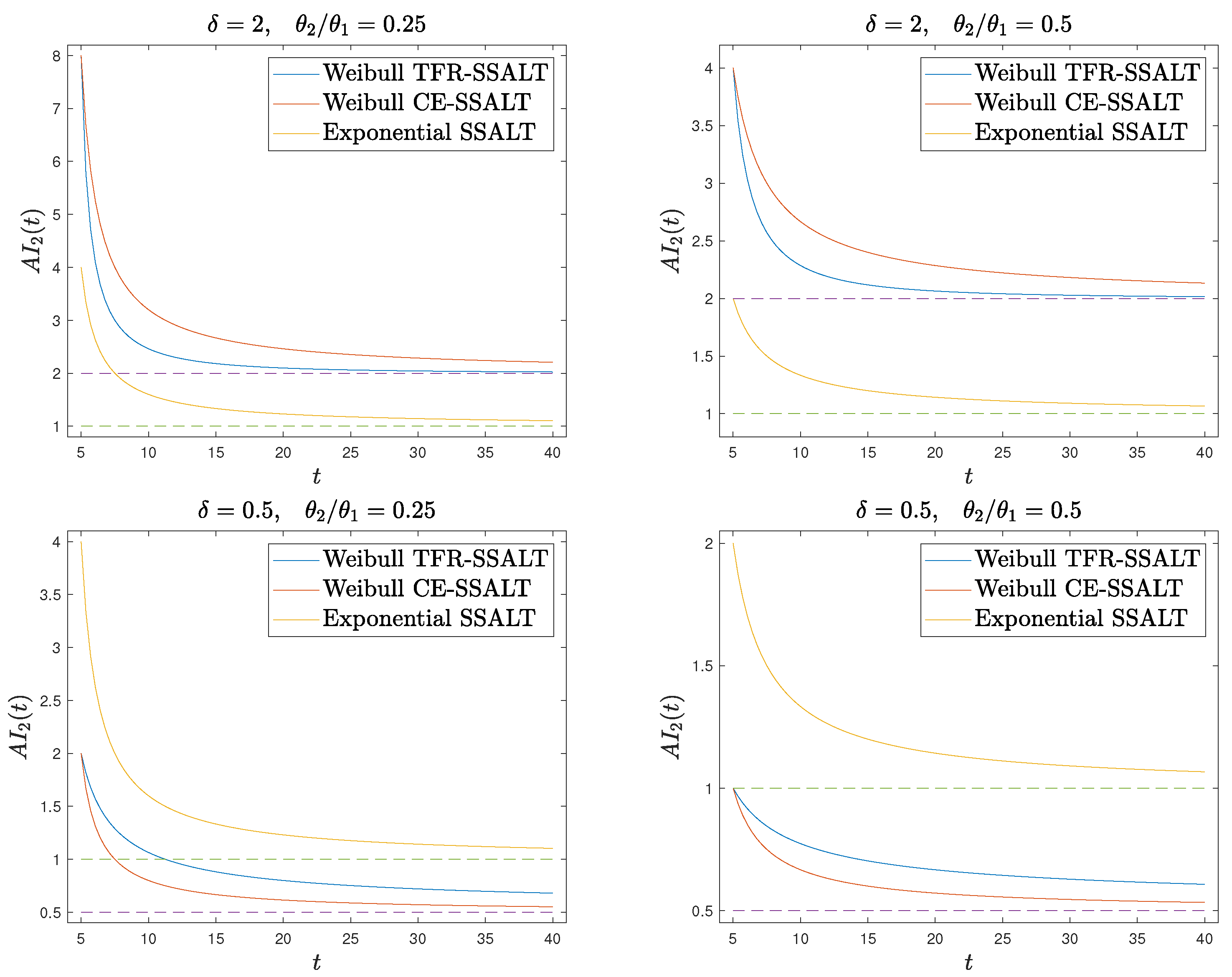
Figure 1, we plot the AI function in the second stress level for the Weibull and the exponential distributions with the TFR and CE SSALT model, for different choices of the parameter
of the Weibull distribution and of the ratio
. Recall that in the case of exponential distributed lifetimes, the TFR and CE models coincide. Moreover, we chose values of
less than one in order to represent the higher stress in the second level.
For Weibull lifetimes,
in (
14) and
in (
13) have the same functional form, but the TFR model is in terms of
,
, while the CE is in terms of
t,
, respectively. This has as a consequence that for
(aging effect of exposure to stress),
, while for
(recovering effect),
(see also
Figure 1). Furthermore, at the time point of stress level change
, we have
. Thus, though the instant stress change effect on the AI is the same for both models, the AI development in time differs. Focusing on the aging case, we realize another qualitative difference between the CE and TFR models. The AI curve under a Weibull TFR model is steeper than that of the corresponding CE model, reaching, after some time, the AI value
of Weibull distributions, which is not the case for the AI under the CE model. For the CE model, AI stabilizes as well but at a higher level. This difference of the two models can motivate the decision for one or the other when modeling SSALT experimental data, depending on the effect that the stress factor has on the aging at a particular application setup.
The AI of a SSALT model can be estimated parametrically. For example, for Weibull lifetimes, we have and , where and are the maximum likelihood estimators (MLEs) of the parameters.
Remark 2. We introduced the AI function and explored it for characteristic families of lifetime distributions under CE and TFR assumptions for simple SSALT models. The discussion can be extended to SSALT models for stress levels. In this case, AI is defined bywhere are the stress change points, and and by convention. For example, in the case of exponential lifetimes, the CDF of a SSALT model with m stress levels takes the formwhere is the exponential parameter under level i, for . The corresponding AI is given byNotice that if , then (15) reduces to (12). 4. AI-Based Estimation
In this section, we propose a method based on the AI function to estimate the parameters and in a CE SSALT model for an exponential distribution and compare the results with the those of MLEs.
Let be the OSs of a sample from a simple SSALT experiment, such that failures are realized at the first stress level, and the remaining (), at the second one (i.e., ). The estimation of the corresponding AI function builds on a kernel-based estimation of the model’s CDF G and PDF g. We proceed by dividing the support in the intervals and . On the first stress level, i.e., for , the CDF is estimated with a kernel approach and the assumption of positive support on the data . The obtained CDF is then scaled by the factor , the proportion of failures in the first stress level, which approximates . The CDF in the second stress level is estimated using the same approach applied on the shifted data , which also have a positive support. The derived CDF is scaled by the factor , representing the proportion of failures on the second stress level, and the term is also added to the estimation of the CDF in order to ensure that it is a CDF, i.e, it fulfills its continuity at and is monotone increasing. Along the same lines, the PDF is estimated by applying a kernel density estimation procedure separately to the data observed under the first stress level and the shifted data of the second, synthesizing the derived PDFs in a mixture weighted by the factors and , respectively.
Denoting the resulting estimators for the PDF and the CDF by
and
, respectively, the estimator for the AI function is
We remark that we do not need a piecewise function to estimate AI since we work directly with
G and
g and not with
, and
.
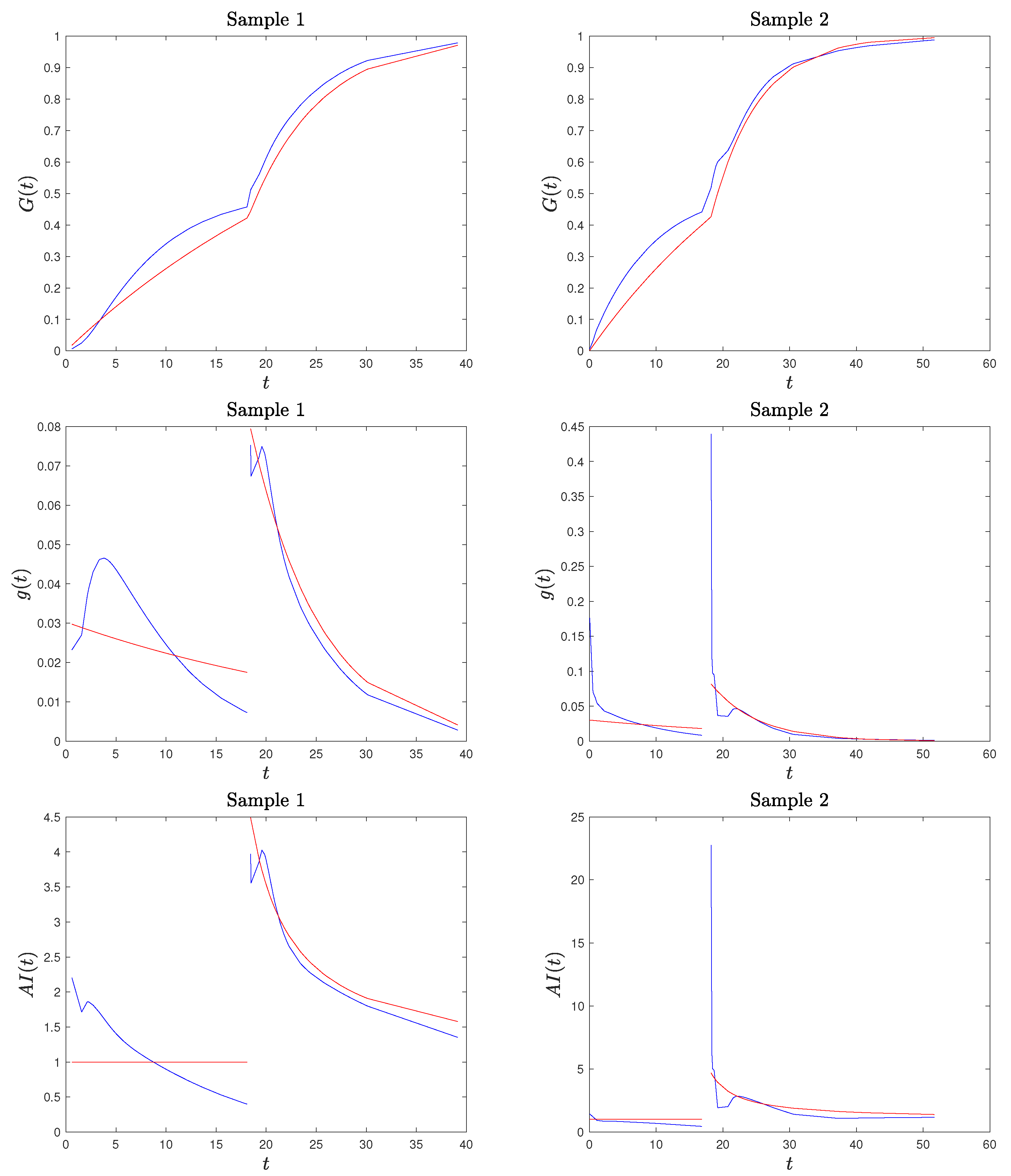
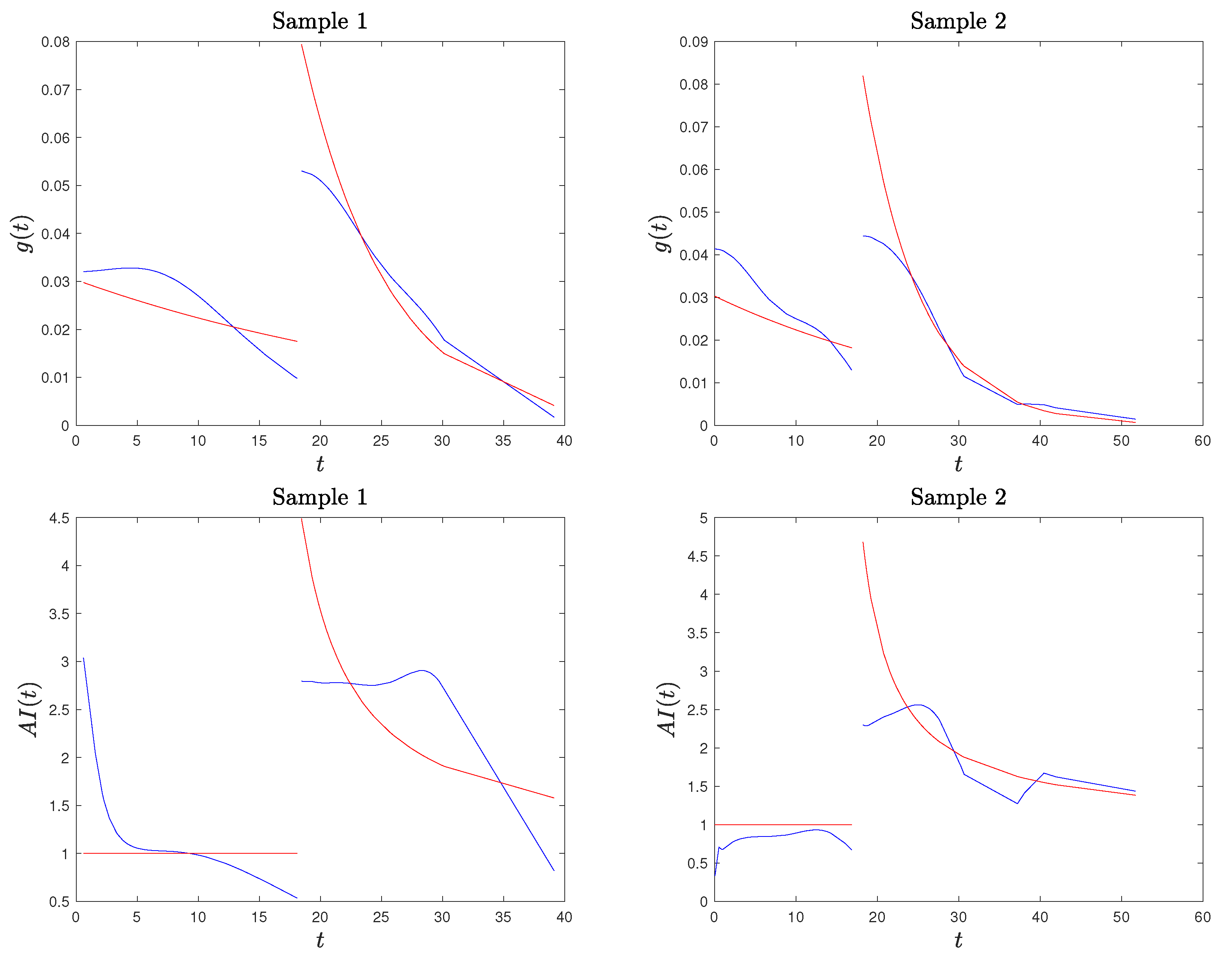
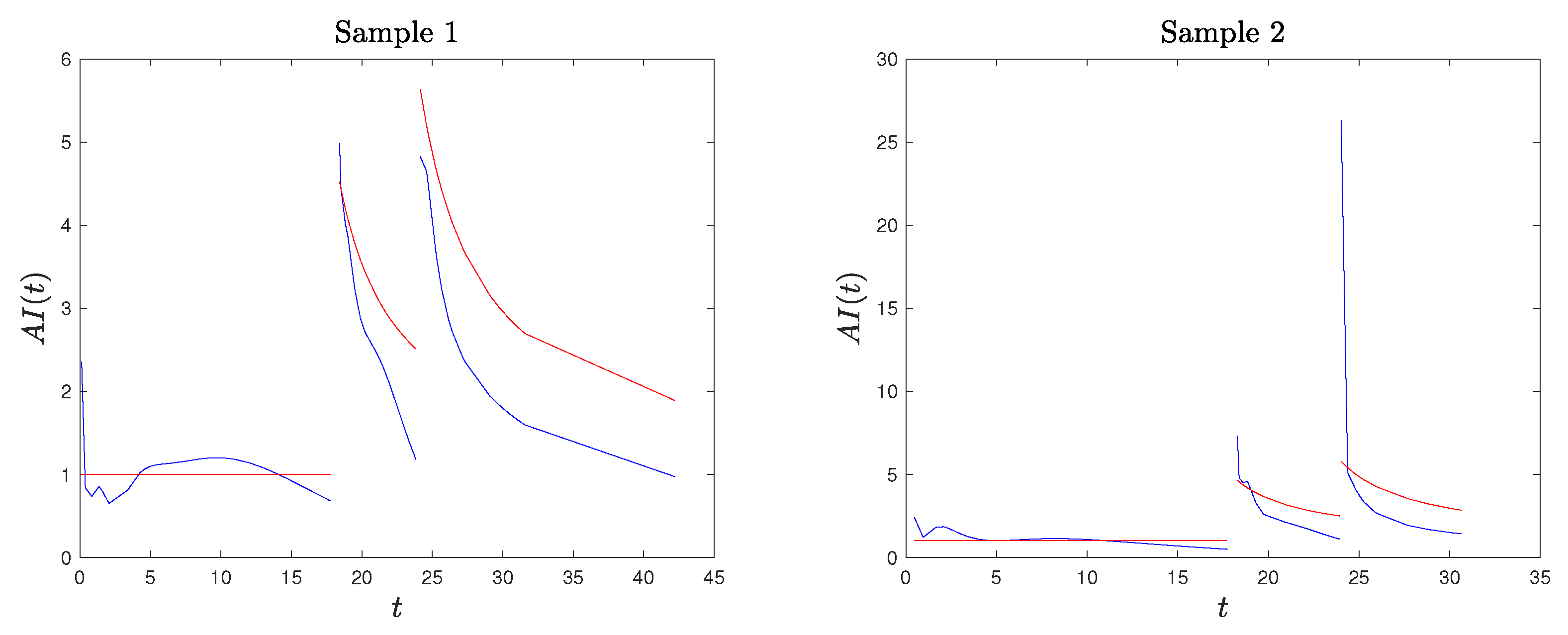
Example 1. We applied the procedure described above to two randomly generated sample from model (2), with stress change point and parameters and , both of sample size . We present the results in Figure 2 where we compare the kernel-based estimated CDF and PDF and the AI function with the true ones. We consider two generated samples to highlight that the proposed method provides a good estimation of the true functions, but, especially for the PDF and the AI function (see Sample 2), it may have a considerable local error right after the stress change point. Based on this observation, in our procedure described below, we excluded the estimate of the AI function at , as it may cause misleading results (confirmed by our simulation studies). Remark 3. Based on our simulation studies, and also supported by Figure 2, the kernel density estimation of the PDF is not fully satisfactory, confirming the well-known problem of kernel density estimation with bounded supports (especially on the lower bound of the second stress level). A method to deal with the problem of bounded support S is the reflection technique for kernel density estimation (see Silverman [30], chapter 2.10). The method consists of augmenting the data by adding the reflections of all points in the boundary, deriving the PDF estimation on an unbounded support and based on data points, and then obtaining the estimated PDF for the original data on S as twice the above-derived PDF. We adapted this method to a SSALT model by dividing the sample data from the first and second level. For the first stress level and its lower bound of 0, the reflections of are , the kernel density estimator is constructed using points, and the estimated PDF for the original data is given by , where is the indicator function. For the second level, we reflect the data with respect to τ, consider, additionally, the points , , derive the kernel density estimated , and set . Then, the PDF of the SSALT model is estimated by . The results obtained in this way seem to be much better with regard to the PDF, but they are not satisfying when considering the corresponding estimated AI function (which depends also on the estimated CDF). In Figure 3, we present the plots for the estimated PDF and AI function for the same two samples of Example 1. Hence, we decided to proceed with the PDF estimated using the classical kernel approach and excluding the AI estimate at point . We now introduce new estimators for the parameters
and
, alternative to the MLEs, that are based on the kernel-based estimated AI function. They are derived by minimizing the distance between the estimated AI (
16), evaluated at the order statistics of the sample,
, by excluding
, and the theoretical values of the aging intensity at these points given in (
12) by assuming a SSALT model for exponential distributed lifetimes with parameters
and
. More precisely, the function to be minimized is
Hence, we need to solve the system
where
Note that the first sum in (
17) is constant with respect to
and
, so it may seem that
(and also
, excluded from the second sum) are not involved in the derivation of the estimators, but they actually influence the values of the aging intensity estimates in
through the estimated PDF and CDF. Moreover, the system in (
18) is not analytically solvable, and numerical methods have to be applied. Hence, we minimize (
17) numerically by choosing as initial values for
and
the maximum likelihood estimates given in (
3) and (
4). The estimators obtained in this way are denoted by
and
.
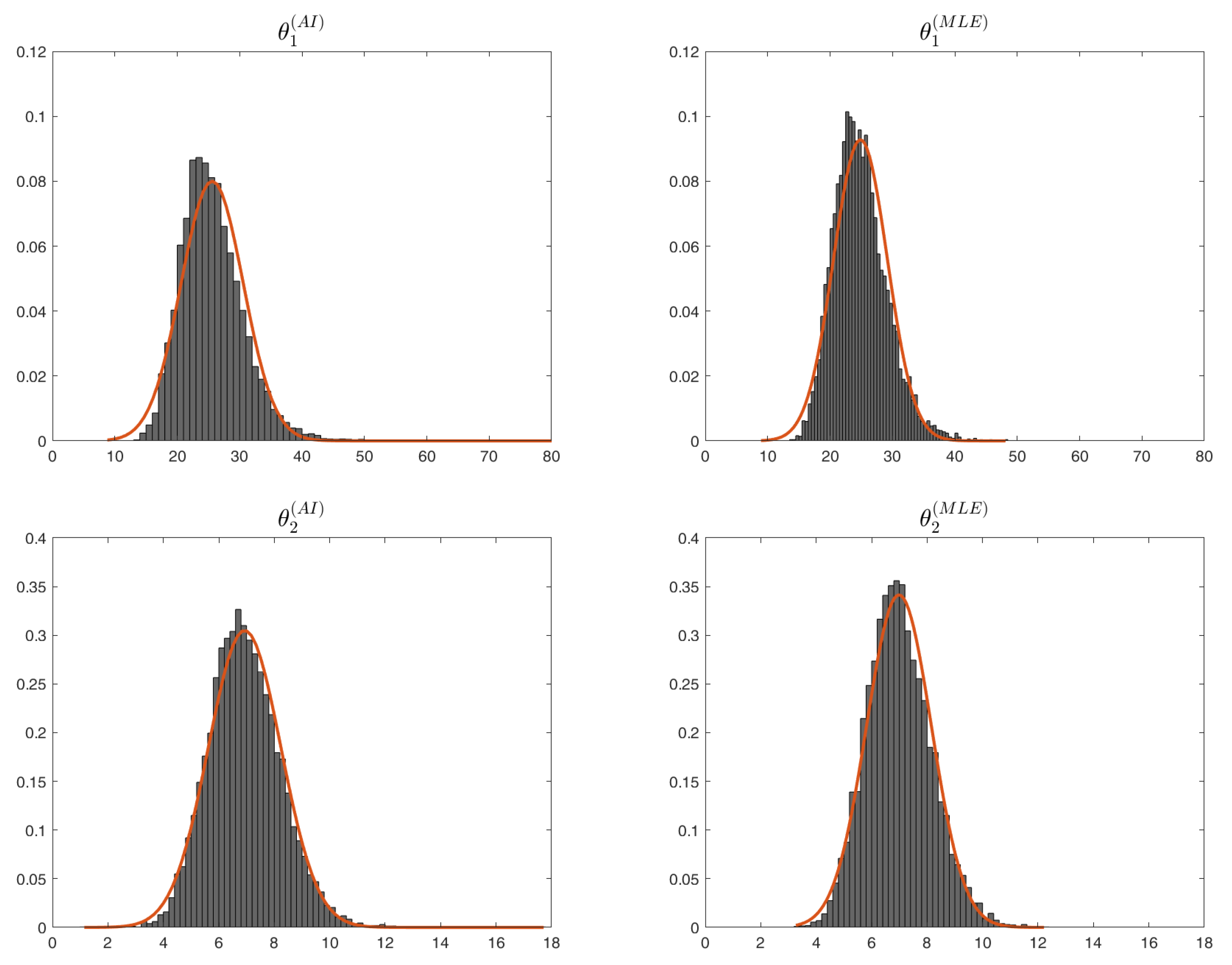
Example 2. Consider the setup described in Example 1 with , , , and . We performed a simulation study and derive the estimates for and based on the AI function and the MLEs for simulated samples. We observed that the ’s estimates of based on the AI are closer than the corresponding MLEs’ to the real value of in of the cases, while this holds for in of the simulated samples. In order to perform a comparison based on both and , we checked that the following inequality based on relative errors is satisfied in of the samples:The mean observed bias for the estimates of based on the AI function and the maximum likelihood are given by and , respectively, while for , we have (AI) and (MLE). Recall that the is unbiased. In Figure 4, we plot the histograms with the estimates for and , both based on AI and MLE, showing also the PDF of the corresponding fitted normal distributions. The estimated means and standard deviations of the fitted normal distributions are given in Table 1. Next, we consider an example of a SSALT model with
, and we derive new estimators for the parameters
,
, and
based on the AI function and on minimizing a function analogous to
in (
17) for the case of
.
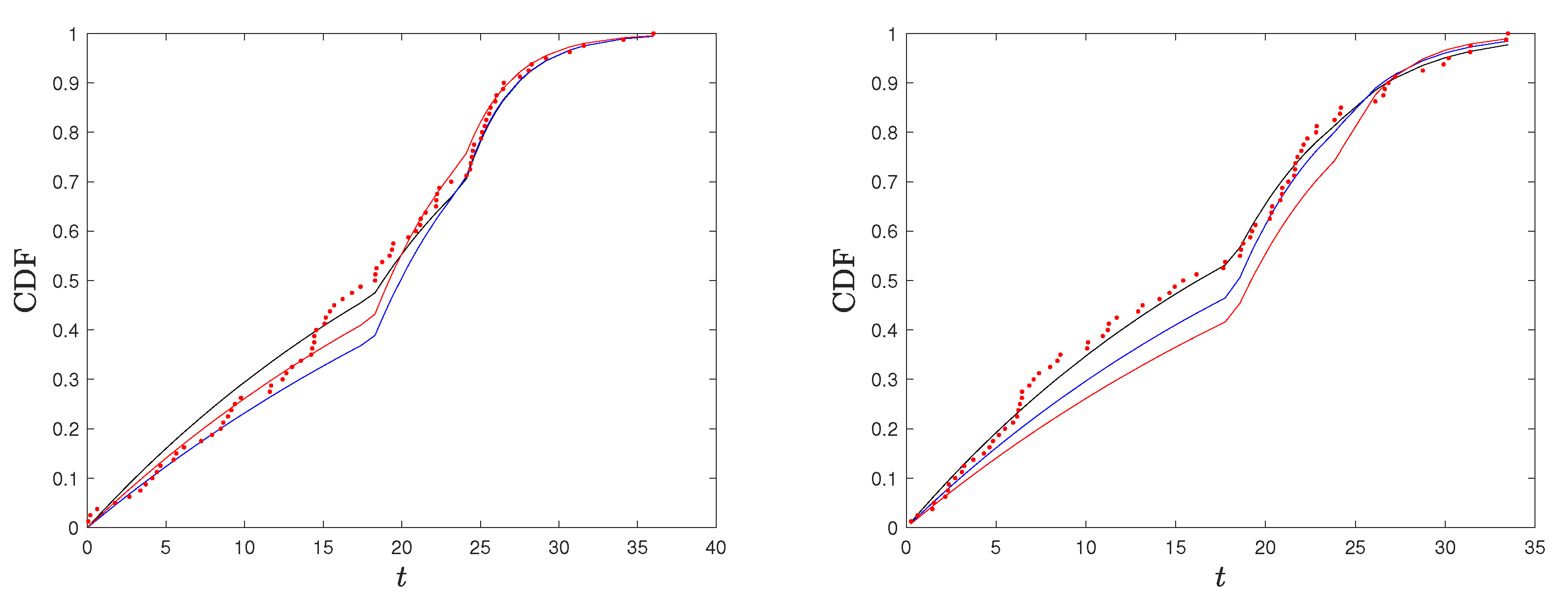
Example 3. Consider a CE SSALT model for exponential lifetimes under each stress level, with stress change points and , parameters , , and , and with sample size . First, we compare the kernel-based estimated AI function with the true one given in (15) in the case of . We show the results for two generated samples to remark that the proposed method provides a good estimation of the true function, but it may have a considerable local error right after the second stress change point (see Sample 2). The results are shown in Figure 5. Based on this observation, which is analogous to the observation made in Example 1 for the corresponding simple SSALT, in our procedure, described below, we excluded the estimate of the AI function at one point () as it may cause misleading results ( and represent the number of failures in the first and second stress levels, respectively). Next, we performed a simulation study and derived the estimates for , , and based on the AI function and the MLEs for 10.000 simulated samples. In of the cases (103 over 10.000), the optimization procedure did not converge. For those cases, we applied a constrained optimization procedure to our function. We observed that the ’s estimates of based on the AI are closer than the corresponding MLEs’ to the real value of in of the cases, and this holds for and in and of the simulated samples, respectively. In order to perform a comparison based on the three parameters, , , and , we checked that the following inequality based on relative errors was satisfied in 45.7% of the samples:The estimated means and standard deviations of the fitted normal distributions are given in Table 2. Notice that compared to , has a higher standard deviation but is of reduced bias. For the other two stress levels, the maximmum likelihood estimation seems to behave slightly better for this example (in terms of bias and standard deviation) than the AI based estimation. Finally, to compare the two different estimation approaches to the true distribution, in Figure 6, we plot the true CDF jointly with the maximum likelihood and AI-based estimated CDFs, along with the points corresponding to the empirical CDF for two of the simulated samples. In Figure 6 (left), we have a case in which the estimated CDF based on the AI and the one based on the MLE are both close to the underlying true distribution. They are indistinguishable on the third level, while the one based on AI (MLE) performs slightly better on the first (second) level. In Figure 6 (right), we have a case in which the simulated data are far from the true distribution, and the estimated CDF based on the AI is closer to the true CDF compared with the one based on the MLE, seeming to be more robust to outliers. 5. Goodness-of-Fit Testing for SSALT
In this section, we cover the goodness-of-fit testing for the SSALT model with exponential distributed lifetimes based on the Kullback–Leibler (KL) divergence. The Kullback–Leibler divergence between two probability density functions
f and
g with non-negative support is defined as follows (see Kullback and Leibler [
31]):
It is non-negative and equal to 0 if, and only if,
almost everywhere. The KL divergence is not symmetric in
f and
g so that
.
The PDF of the exponential SSALT model is
The AI-based estimated PDF is then
,
, while the maximum likelihood estimated PDF is denoted by
,
. Hence, the KL divergence between the exact theoretical PDF
g and the AI-based estimated
is expressed as follows:
By integrating by parts in the above integrals, we further obtain
which is non-negative and equal to 0 if, and only if,
and
. The KL divergence between
g and the MLE
is defined analogously. We remark that the knowledge of
g and, hence, the evaluations of
and
are obtained only with simulated data.
Considering the simulation study described in Example 2, we have that the inequality
is satisfied in
of cases, but the differences between
and
are small. The histogram of the differences
is provided in
Figure 7. To improve the readability of the figure, a few extreme values on the left are not displayed. From the histogram, we note that, with the exception of the closest regions to 0, the results are symmetric around 0. To compare the two different estimation approaches to the true distribution, we considered the more extreme case on the right, corresponding to a value of
, for the difference. Then, in
Figure 8 (left), we plotted the true CDF, together with the maximum likelihood and AI-based estimated CDFs, along with the points corresponding to the empirical CDF. We note that in this case, the simulated data are far from the true distribution. Hence, the estimated CDF based on the AI, which is closer to the true CDF compared with the one based on MLE, seems to be more robust to outliers. In
Figure 8 (right), we repeated the same analysis with a random selected sample (which is more representative of the underlying true model) and observe that the CDFs estimated using the MLE and AI are indistinguishable.
In case of real data, where the underlying PDF
g is unknown, the goodness of fit for
(maximum likelihood estimated PDF) can be evaluated using
, i.e., by comparing
to the estimated
g based on the kernel density approach of
Section 4. However, this is not a fair tool for comparing
to
, since the AI-based estimated PDF
is based on the kernel-based estimation
. For this reason, we searched for a different comparison tool.
In order to make a non-parametric comparison of the distributions with parameters given by the AI and the MLE, we considered a different type of KL divergence proposed by Park et al. [
32] with properties that have been further studied by Di Crescenzo and Longobardi [
33]. This measure is known as the cumulative Kullback–Leibler divergence, and for two non-negative random variables
X and
Y with cumulative distribution functions
and
, respectively, it is defined by
Hence, we can use this measure to make comparisons using
, the empirical CDF of the data, in place of
, i.e.,
with the corresponding mean given by
In place of
we set the MLE-based or AI-based estimate of the CDF
G of the exponential SSALT model. That is,
,
, with
G defined in (
2), or
, which is defined analogously. The mean of a CE SSALT exponential model is evaluated as follows:
which, after integration by parts, is equal to
Then, denoting by
and
, the cumulative Kullback–Leibler divergence between the considered distribution is evaluated as follows:
Considering again the simulation study described in Example 2, we verify that the inequality
is satisfied in
of the cases.
6. Discussion
In this work, we extended the concept of aging intensity to the setup of SSALT models. This provides new insights to the model and enables a deeper understanding of the aging process of the testing units exposed under a step-stress ALT experiment, as well as further clarification of the differences between the CE and TFR models. Based on the AI function, new estimators for the parameters of a SSALT model were proposed and compared to the MLEs in terms of simulated examples and a simulation study. The models and methods discussed mainly referred to simple SSALT experiments with stress levels, but they are extendable to cases with , as shown in Example 3 for the case .
This approach opens new research directions in SSALT modeling. Additional studies are required to investigate, in depth and with various setups, the performance of the AI-based estimation in comparison to that of the maximum likelihood estimation. Furthermore, alternative estimators could be considered by replacing the distance
used in
Section 4 with another divergence measure, e.g., the KL divergence. Furthermore, one could proceed to interval the estimation of the parameters (asymptotic or bootstrap) and to test the hypothesis on the SSALT model’s parameters (e.g.,
,
, for a fixed
). It is of interest to investigate the robustness of AI-based estimation in comparison to that of the MLE. Finally, it is worth it to explore possible AI-based criteria for optimal SSALT experimental designs.
In summary, further extensive studies are required to investigate the AI-based estimation with various setups.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}