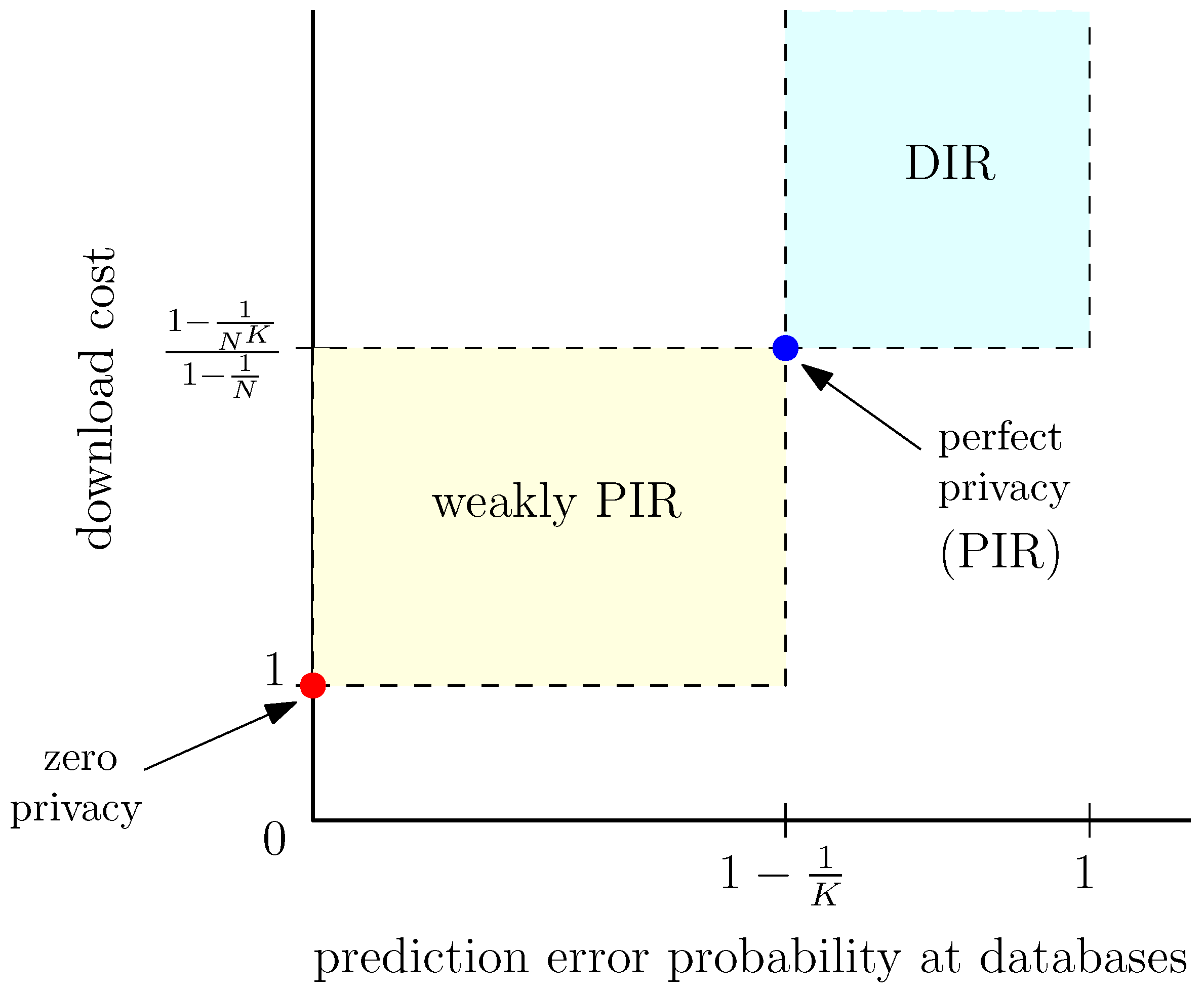
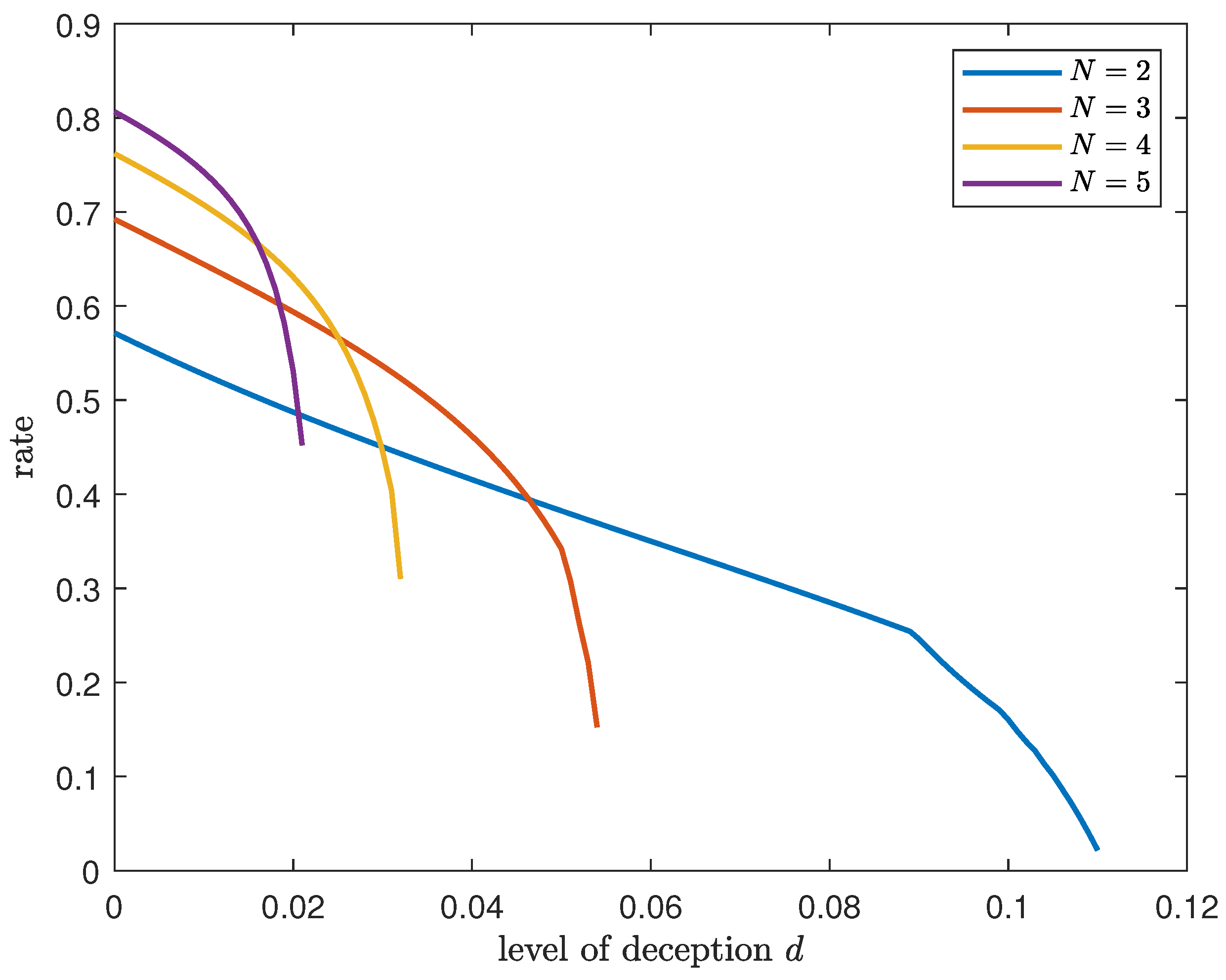
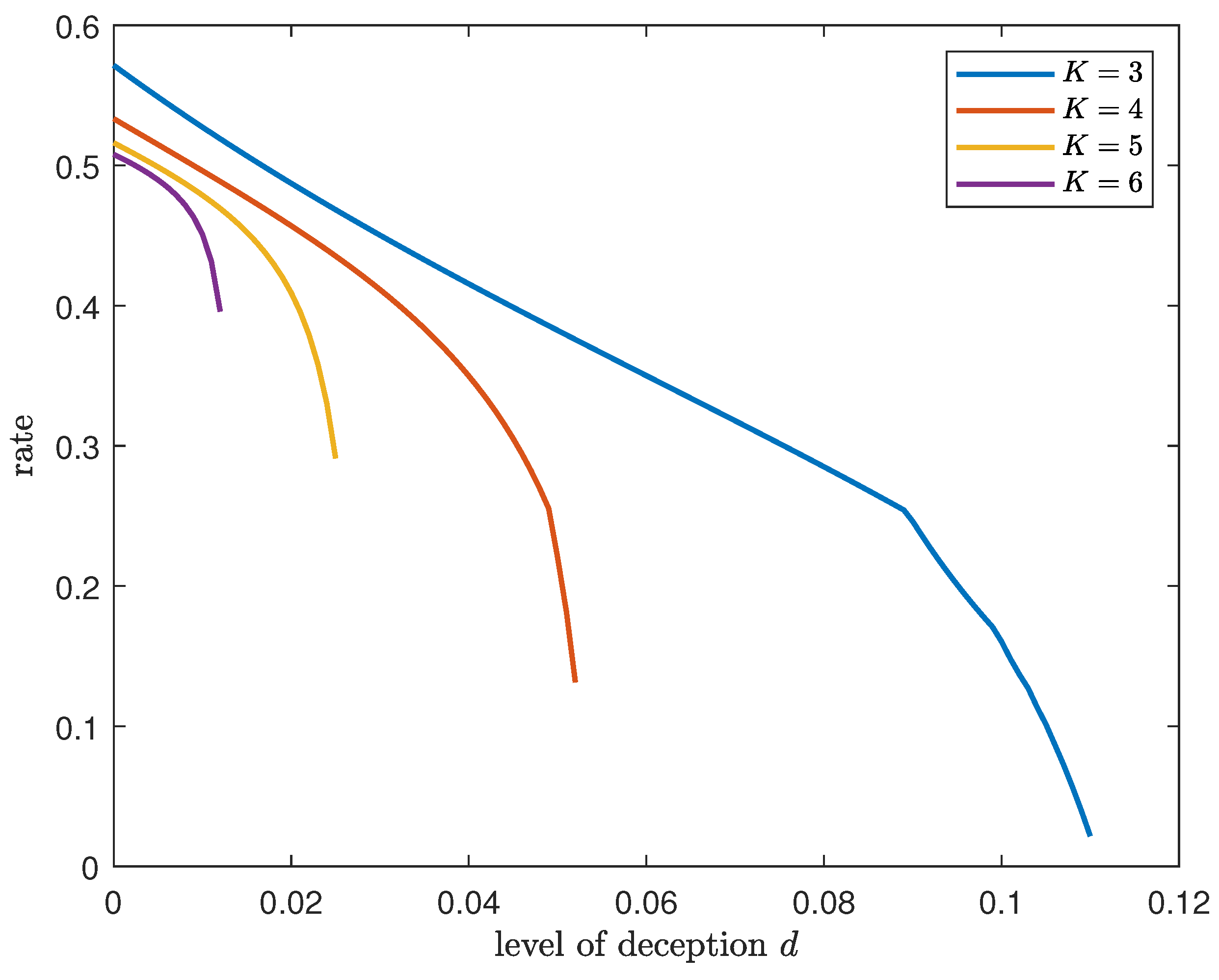
Out of the
different sets of queries described above in the real query table, all queries except
in single blocks, i.e., queries of the form
,
, are chosen as
-deceptive ones with respect to file
k, for each
, and are included in the set of dummy queries sent to databases when the user-required file index is
k. The
-deceptive queries
,
, corresponding to the
kth file requirement, must guarantee the condition in (
11). For that, we assign
and
for each database
n,
. The rest of the queries, i.e.,
and sums of
ℓ blocks where
, are PIR queries in the proposed scheme. Note that the query
is always coupled with the
-deceptive queries with respect to file index
k (required file) for correctness (see
Table 6,
Table 8 and
Table 10). Thus,
is assigned the corresponding probability given by
Similarly, as the rest of the PIR queries are coupled with
-deceptive queries with respect to file indices
j,
, or with other PIR queries, they are assigned the corresponding probability given by
where
is any PIR query in the form of ℓ-sums with
. Since the probabilities of the real queries sent for each file requirement must add up to one, i.e.,
for each
,
p is given by
as there are
N query sets in the real query table with probability
p, and
sets with probability
. Each
-deceptive query with respect to file index
k is chosen with equal probability to be sent to the databases as dummy queries at times
when the file requirement at the corresponding time
is
. Since there are
deceptive queries,
and
for each database
n,
. Therefore, for all
-deceptive queries with respect to file index
k of the form
, the condition in (
12) can be written as
thus,
which characterizes
. The information available to database
n,
, is the overall probability of receiving each query for each file requirement of the user
,
, given by
For
-deceptive queries with respect to file index
k, i.e.,
,
, the overall probability in (
80) from the perspective of database
n,
, is given by
The probability of sending the null query
to database
n,
, for each file requirement
k,
, is
For the rest of the PIR queries denoted by
, i.e., queries of the form
for
, the overall probability in (
80), known by each database
n,
for each file requirement
k,
, is given by
Based on the query received at a given time
t, each database
n,
, calculates the a posteriori probability of the user-required file index being
k,
, using
For all other queries
, the corresponding probability of error is given by
where (
92) follows from the fact that
is conditionally independent of
given
Q from (
5). The probability of error of each database’s prediction is given by
where
in (
94) represents the queries of the form
for
. Note that
is the same for each
as
for each
and all
from (
74). Thus, the amount of deception achieved by this scheme for a given
is given by
Therefore, for a required amount of deception
d, satisfying
, the value of
must be chosen as



{kind=link}
{kind=link}
{kind=link}