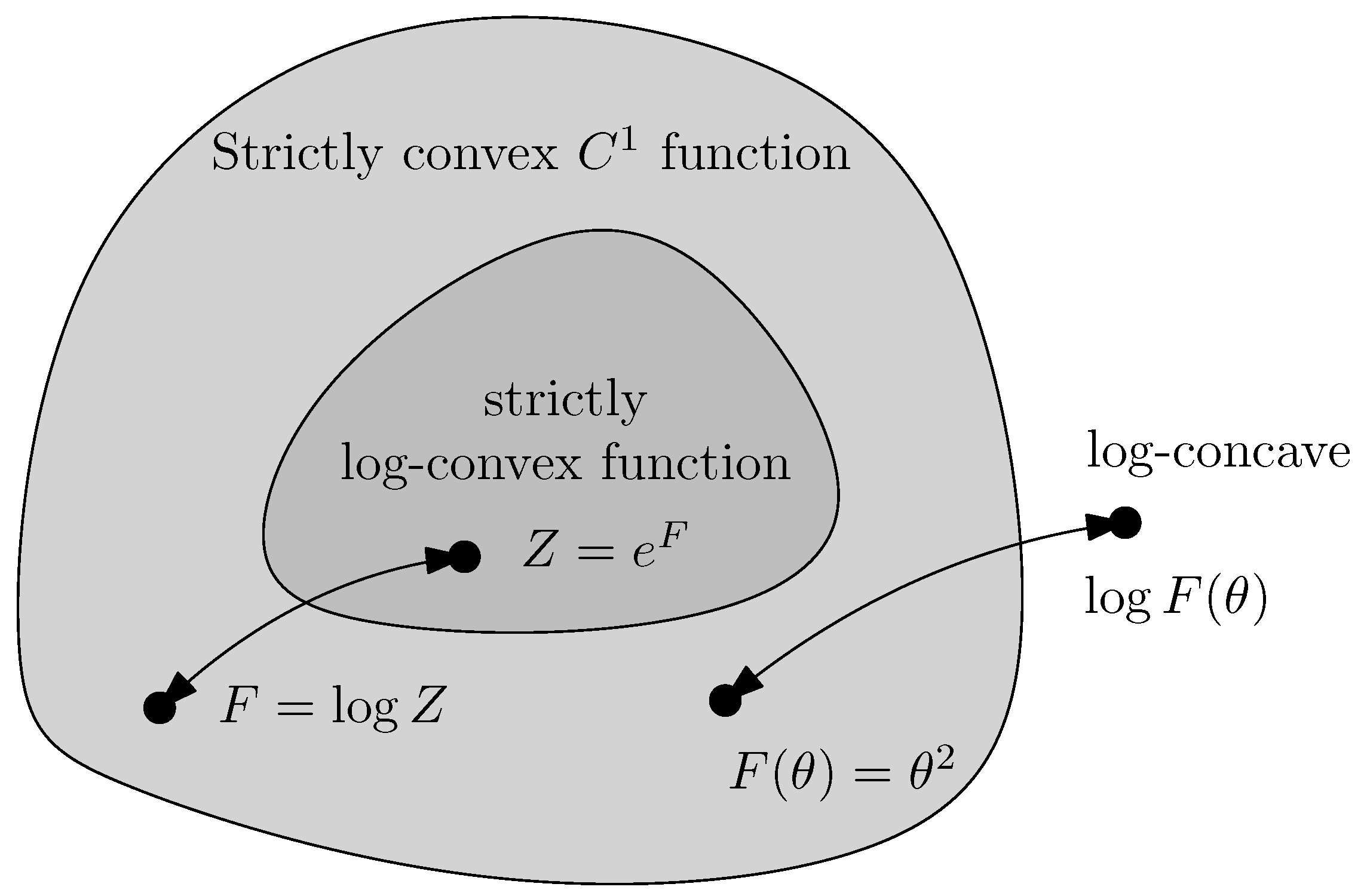
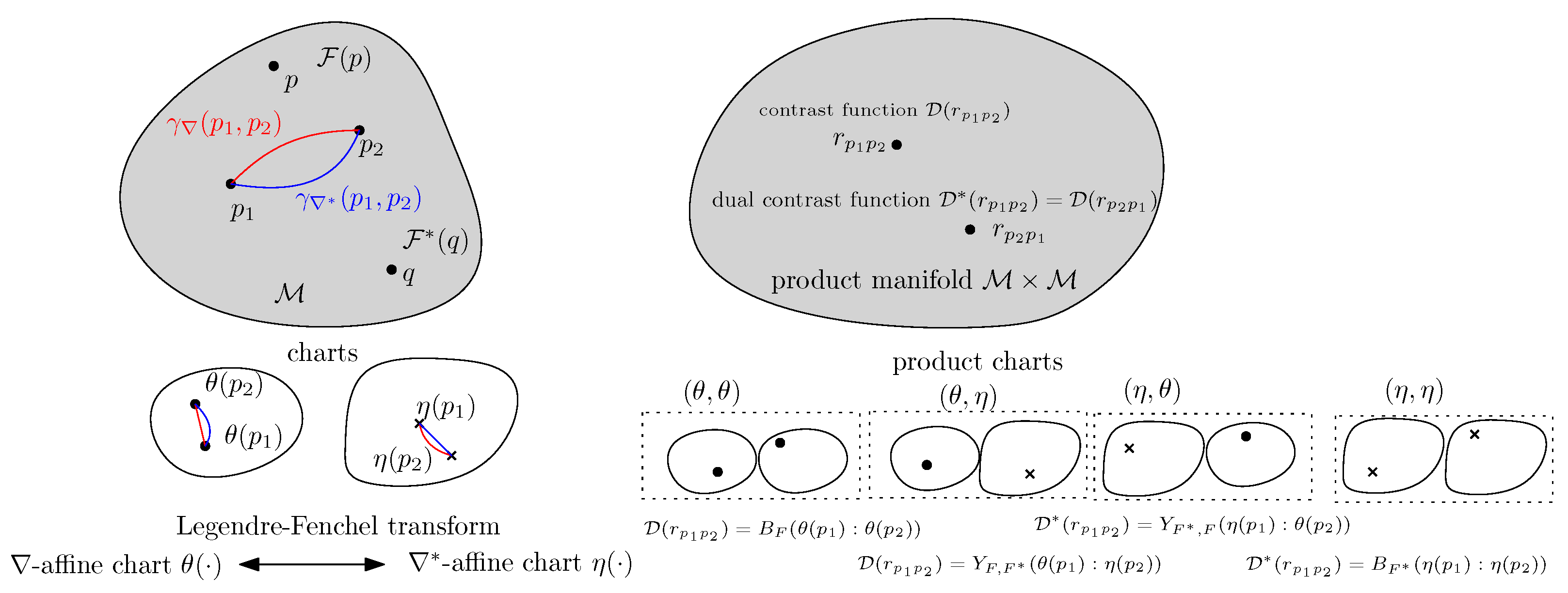
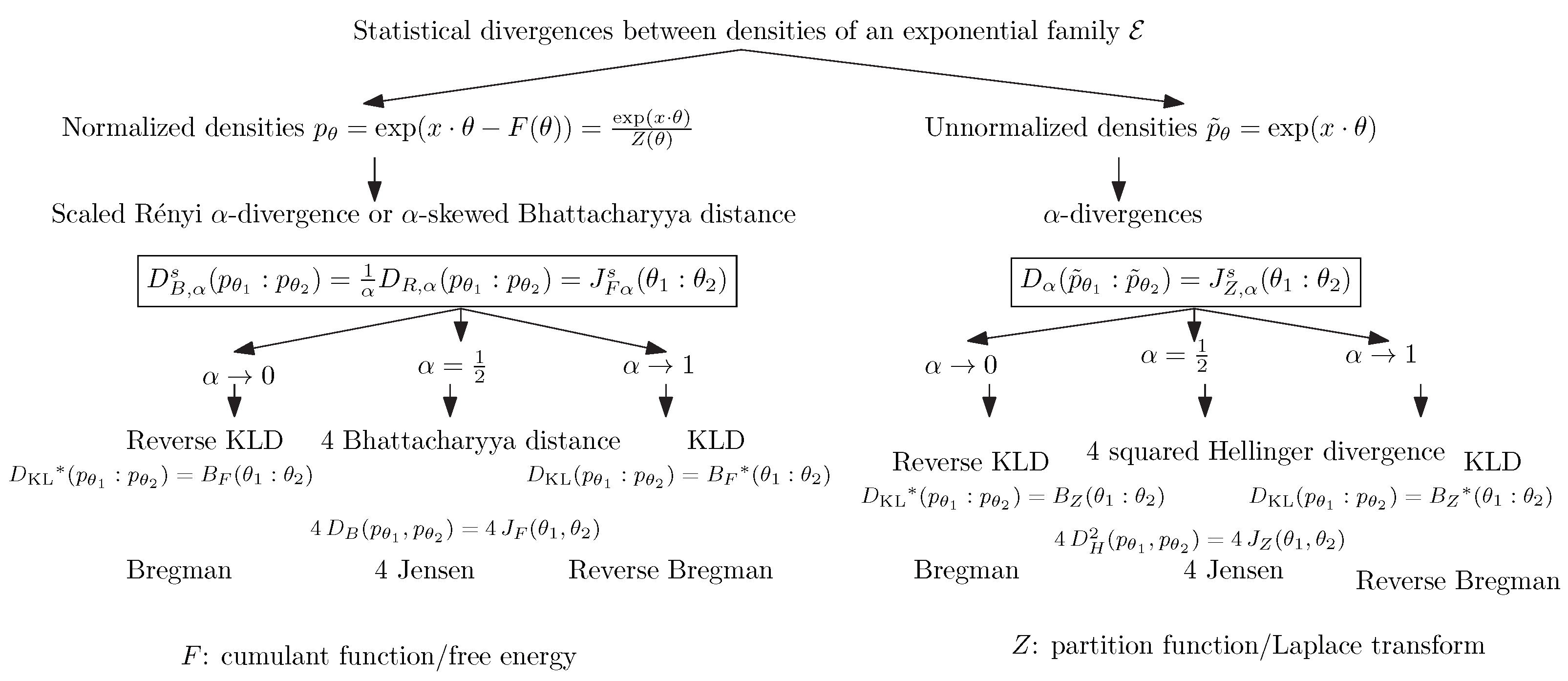
1. Introduction
In information geometry [
1], any strictly convex and smooth function induces a dually flat space (DFS) with a canonical divergence which can be expressed in charts either as dual Bregman divergences [
2] or equivalently as dual Fenchel–Young divergences [
3]. For example, the cumulant function of an exponential family [
4] (also called the free energy) generates a DFS, that is, an exponential family manifold [
5] with the canonical divergence yielding the reverse Kullback–Leibler divergence. Another typical example of a strictly convex and smooth function generating a DFS is the negative entropy of a mixture family, that is, a mixture family manifold with the canonical divergence yielding the (forward) Kullback–Leibler divergence [
3]. In addition, any strictly convex and smooth function induces a family of scaled skewed Jensen divergences [
6,
7], which in limit cases includes the sided forward and reverse Bregman divergences.
In
Section 2, we present two equivalent approaches to normalizing an exponential family: first by its cumulant function, and second by its partition function. Because both the cumulant and partition functions are strictly convex and smooth, they induce corresponding families of scaled skewed Jensen divergences and Bregman divergences, with corresponding dually flat spaces and related statistical divergences.
In
Section 3, we recall the well-known result that the statistical
-skewed Bhattacharyya distances between the
probability densities of an exponential family amount to a scaled
-skewed Jensen divergence between their natural parameters. In
Section 4, we prove that the
-divergences [
8] between the
unnormalized densities of a exponential family amount to scaled
-skewed Jensen divergence between their natural parameters (Proposition 5). More generally, we explain in
Section 5 how to deform a convex function using comparative convexity [
9]: When the ordinary convexity of the deformed convex function is preserved, we obtain new skewed Jensen divergences and Bregman divergences with corresponding dually flat spaces. Finally,
Section 6 concludes this work with a discussion.
3. Divergences Related to the Cumulant Function
Consider the scaled
-skewed Bhattacharyya distances [
7,
15] between two probability densities
and
:
The scaled
-skewed Bhattacharyya distances can additionally be interpreted as Rényi divergences [
25] scaled by
:
, where the Rényi
-divergences are defined by
The Bhattacharyya distance
corresponds to one-fourth of
:
. Because
tends to the Kullback–Leibler divergence
when
and to the reverse Kullback–Leibler divergence
when
, we have
When both probability densities belong to the same exponential family with cumulant , we have the following proposition.
Proposition 4 ([
7]).
The scaled α-skewed Bhattacharyya distances between two probability densities and of an exponential family amount to the scaled α-skewed Jensen divergence between their natural parameters: Proof. The proof follows by first considering the
-skewed Bhattacharyya similarity coefficient
.
Multiplying the last equation by
with
, we obtain
Because
, we have
; therefore, we obtain
□
For practitioners in machine learning, it is well known that the Kullback–Leibler divergence between two probability densities
and
of an exponential family amounts to a Bregman divergence for the cumulant generator on a swapped parameter order (e.g., [
26,
27]):
This is a particular instance of Equation (
10) obtained for
:
This formula has been further generalized in [
28] by considering truncations of exponential family densities. Let
and
,
be two truncated families of
with corresponding cumulant functions
and
Then, we have
Truncated exponential families are normalized exponential families which may not be regular [
29], i.e., the parameter space
may not be open.
4. Divergences Related to the Partition Function
Certain exponential families have intractable cumulant/partition functions (e.g., exponential families with sufficient statistics
for high degrees
m [
20]) or cumulant/partition functions which require exponential time to compute [
30] (e.g., graphical models [
16], high-dimensional grid sample spaces, energy-based models [
17] in deep learning, etc.). In such cases, the maximum likelihood estimator (MLE) cannot be used to infer the natural parameter of exponential densities. Many alternative methods have been proposed to handle such exponential families with untractable partition functions, e.g., score matching [
31] or divergence-based inference [
32,
33]). Thus, it is important to consider dissimilarities between non-normalized statistical models.
The squared Hellinger distance [
1] between two positive potentially unnormalized densities
and
is defined by
Notice that the Hellinger divergence can be interpreted as the integral of the difference between the arithmetical mean
minus the geometrical mean
of the densities:
. This further proves that
, as
. The Hellinger distance
satisfies the metric axioms of distances.
When considering unnormalized densities
and
of an exponential family
with a partition function
, we obtain
as
.
The Kullback–Leibler divergence [
1] as extended to two positive densities
and
is defined by
When considering unnormalized densities
and
of
, we obtain
as
. Let
denote the reverse KLD.
More generally, the family of
-divergences [
1] between the unnormalized densities
and
is defined for
by
We now have
, and the
-divergences are homogeneous divergences of degree 1. For all
, we have
. Moreoever, because
can be expressed as the difference of the weighted arithmetic mean minus the weighted geometric mean
, it follows from the arithmetical–geometrical mean inequality that we have
.
When considering unnormalized densities
and
of
, we obtain
Proposition 5. The α-divergences between the unnormalized densities of an exponential family amount to scaled α-Jensen divergences between their natural parameters for the partition functionWhen , the oriented Kullback–Leibler divergences between unnormalized exponential family densities amount to reverse Bregman divergences on their corresponding natural parameters for the partition function Proof. For
, consider
Here, we have
,
and
. It follows that
□
Notice that the KLD extended to unnormalized densities can be written as a generalized relative entropy, i.e., it can be obtained as the difference of the extended cross-entropy minus the extended entropy (self cross-entropy):
with
and
Remark 4. In general, we can consider two unnormalized positive densities and . Let and denote their corresponding normalized densities (with normalizing factors and ); then, the KLD between and can be expressed using the KLD between their normalized densities and normalizing factors, as follows:Similarly, we have and .
Notice that Equation (
17) allows us to derive the following identity between
and
:
Let
be the scalar KLD for
and
. Then, we can rewrite Equation (
17) as
and we have
In addition, the KLD between the unnormalized densities
and
with support
can be written as a definite integral of a scalar Bregman divergence:
where
. Because
, we can deduce that
with equality iff
almost everywhere.
Notice that can be interpreted as the sum of two divergences, that is, a conformal Bregman divergence with a scalar Bregman divergence.
Remark 5. Consider the KLD between the normalized and unnormalized densities of the same exponential family. In this case, we haveThe divergence is a dual Bregman pseudo-divergence [
28]
:for and that are two strictly convex and smooth functions such that . Indeed, we can check that generators and are both Bregman generators; then, we have , as for all x (with equality when ), i.e., . More generally, the α-divergences between and can be written aswith the (signed) α-skewed Bhattacharyya distances provided by Let us illustrate Proposition 5 with some examples.
Example 1. Consider the family of exponential distributions , where is an exponential family with a natural parameter , parameter space , sufficient statistic . The partition function is , with and , while the cumulant function is with moment parameter . The α-divergences between two unnormalized exponential distributions are Example 2. Consider the family of univariate centered normal distributions with and partition function such that . Here, we have a natural parameter and sufficient statistic . The partition function expressed with the natural parameter is , with and (strictly convex on Θ). The unnormalized KLD between and isWe can check that we have . For the Hellinger divergence, we haveand we can check that . Consider the family of the d-variate case of centered normal distributions with unnormalized densityobtained using the matrix trace cyclic property, where Σ is the covariance matrix. Here, we have (precision matrix) and for , with the matrix inner product . The partition function expressed with the natural parameter is . This is a convex function withas using matrix calculus. Now, consider the family of univariate normal distributionsLet andThe unnormalized densities are , and we haveIt follows that . 5. Deforming Convex Functions and Their Induced Dually Flat Spaces
5.1. Comparative Convexity
The log-convexity can be interpreted as a special case of comparative convexity with respect to a pair
of comparable weighted means [
9], as follows.
A function
Z is
-convex if and only if for
we have
and is strictly
-convex iff we have strict inequality for
and
. Furthermore, a function
Z is (strictly)
-concave if
is (strictly)
-convex.
Log-convexity corresponds to -convexity, i.e., convexity with respect to the weighted arithmetical and geometrical means defined respectively by and . Ordinary convexity is -convexity.
A weighted quasi-arithmetical mean [
34] (also called a Kolmogorov–Nagumo mean [
35]) is defined for a continuous and strictly increasing function
h by
We let
. Quasi-arithmetical means include the arithmetical mean obtained for
and the geometrical mean for
, and more generally power means
which are quasi-arithmetical means obtained for the family of generators
with inverse
. In the limit
, we have
for the generator
.
Proposition 6 ([
36,
37]).
A function is strictly -convex with respect to two strictly increasing smooth functions ρ and τ if and only if the function is strictly convex. Notice that the set of strictly increasing smooth functions form a non-Abelian group, with the group operation as the function composition, the neutral element as the identity function, and the inverse element as the functional inverse function.
Because log-convexity is
-convexity, a function
Z is strictly log-convex iff
is strictly convex. We have
Starting from a given convex function , we can deform the function to obtain a function using two strictly monotone functions and : .
For a -convex function which is also strictly convex, we can define a pair of Bregman divergences and with and a corresponding pair of skewed Jensen divergences.
Thus, we have the following generic deformation scheme.
In particular, when the function
Z is deformed by strictly increasing the power functions
and
for
and
in
as
then
is strictly convex when it is strictly
-convex, and as such induces corresponding Bregman and Jensen divergences.
Example 3. Consider the partition function of the exponential distribution family ( with ). Let ; then, we have when . Thus, we can deform Z smoothly by while preserving the convexity by ranging p from to . In this way, we obtain a corresponding family of Bregman and Jensen divergences.
The proposed convex deformation using quasi-arithmetical mean generators differs from the interpolation of convex functions using the technique of proximal averaging [
38].
Note that in [
37] the comparative convexity with respect to a pair of quasi-arithmetical means
is used to define a
-Bregman divergence, which turns out to be equivalent to a conformal Bregman divergence on the
-embedding of the parameters.
5.2. Dually Flat Spaces
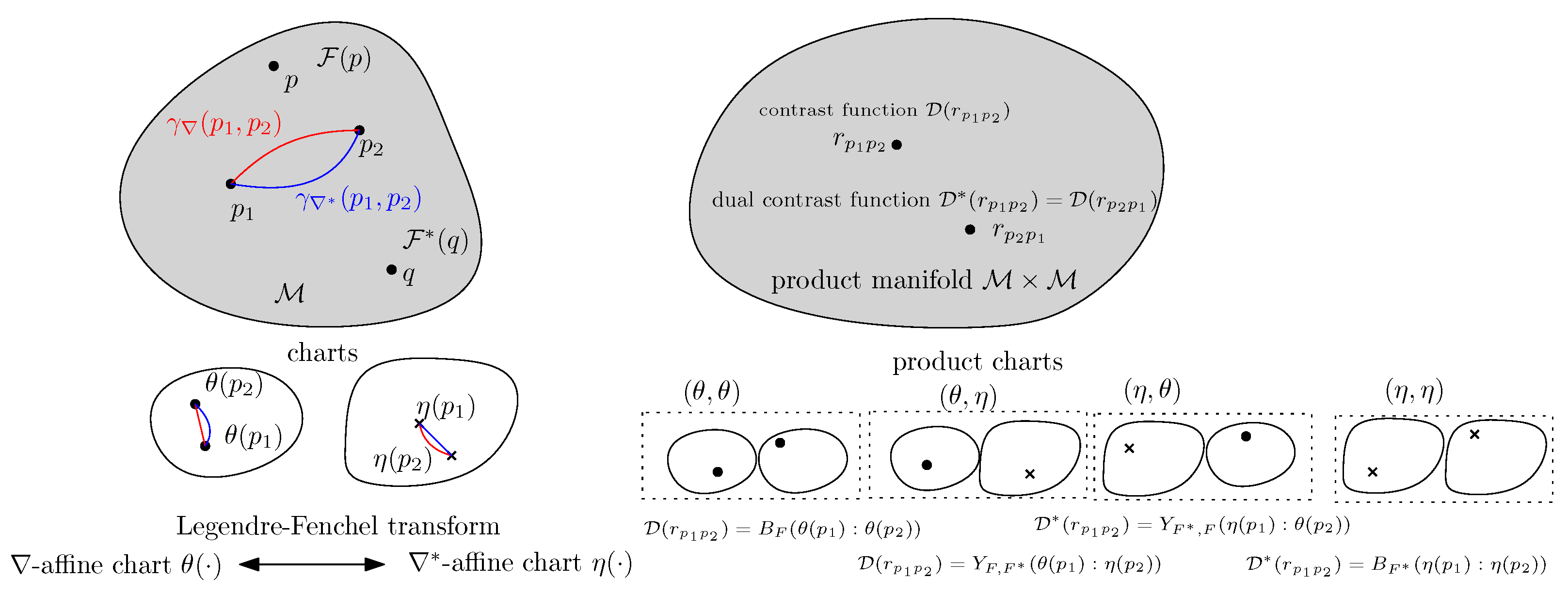
We start with a refinement of the class of convex functions used to generate dually flat spaces.
Definition 2 (Legendre type function [
39]).
is of Legendre type if the function is strictly convex and differentiable with and Legendre-type functions
admit a convex conjugate
via the Legendre transform
:
A smooth and strictly convex function
of Legendre type induces a dually flat space [
1]
, i.e., a smooth Hessian manifold [
40] with a single global chart
[
1]. A canonical divergence
between two points
p and
q of
is viewed as a single-parameter contrast function [
41]
on the product manifold
. The canonical divergence and its dual canonical divergence
can be expressed equivalently as either dual Bregman divergences or dual Fenchel–Young divergences (
Figure 2):
where
is the Fenchel–Young divergence:
We have the dual global coordinate system
and the domain
which defines the dual Legendre-type potential function
. The Legendre-type function ensures that
(a sufficient condition is to have
F be convex and lower semi-continuous [
42]).
A manifold
is called dually flat, as the torsion-free affine connections ∇ and
induced by the potential functions
and
linked with the Legendre–Fenchel transformation are flat [
1], that is, their Christoffel symbols vanishes in the dual coordinate system:
and
.
The Legendre-type function
is not defined uniquely; the function
with
for
A and
C invertible matrices and
b and
d vectors defines the same dually flat space with the same canonical divergence
:
Thus, a log-convex Legendre-type function induces two dually flat spaces by considering the DFSs induced by and . Let the gradient maps be and .
When is chosen as the cumulant function of an exponential family, the Bregman divergence can be interpreted as a statistical divergence between corresponding probability densities, meaning that the Bregman divergence amounts to the reverse Kullback–Leibler divergence: , where is the reverse KLD.
Notice that deforming a convex function
into
such that
remains strictly convex has been considered by Yoshizawa and Tanabe [
43] to build a two-parameter deformation
of the dually flat space induced by the cumulant function
of the multivariate normal family. Additionally, see the method of Hougaard [
44] for obtaining other exponential families from a given exponential family.
Thus, in general, there are many more dually flat spaces with corresponding divergences and statistical divergences than the usually considered exponential family manifold [
5] induced by the cumulant function. It is interesting to consider their use in information sciences.
6. Conclusions and Discussion
For machine learning practioners, it is well known that the Kullback–Leibler divergence (KLD) between two probability densities
and
of an exponential family with cumulant function
F (free energy in thermodynamics) amounts to a reverse Bregman divergence [
26] induced by
F, or equivalently to a reverse Fenchel–Young divergence [
27]
where
is the dual moment or expectation parameter.
In this paper, we have shown that the KLD as extended to positive unnormalized densities
and
of an exponential family with a convex partition function
(Laplace transform) amounts to a reverse Bregman divergence induced by
Z, or equivalently to a reverse Fenchel–Young divergence
where
.
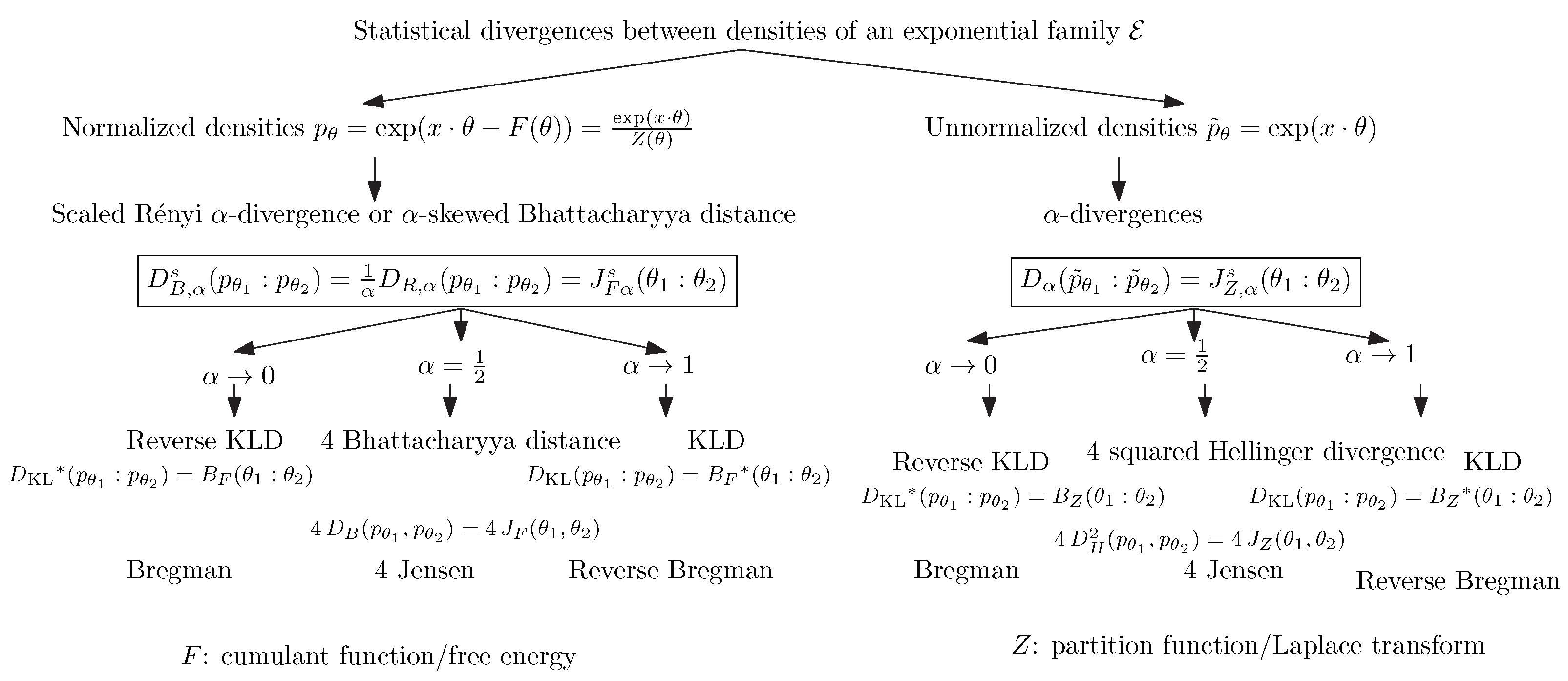
More generally, we have shown that the scaled
-skewed Jensen divergences induced by the cumulant and partition functions between natural parameters coincide with the scaled
-skewed Bhattacharyya distances between probability densities and the
-divergences between unnormalized densities, respectively:
We have noted that the partition functions
Z of exponential families are both convex and log-convex, and that the corresponding cumulant functions are both convex and exponentially convex.
Figure 3 summarizes the relationships between statistical divergences and between the normalized and unnormalized densities of an exponential family, as well as the corresponding divergences between their natural parameters. Notice that Brekelmans and Nielsen [
45] considered deformed uni-order likelihood ratio exponential families (LREFs) for annealing paths and obtained an identity for the
-divergences between unnormalized densities and Bregman divergences induced by multiplicatively scaled partition functions.
Because the log-convex partition function is also convex, we have generalized the principle of building pairs of convex generators using the comparative convexity with respect to a pair of quasi-arithmetical means, and have further discussed the induced dually flat spaces and divergences. In particular, by considering the convexity-preserving deformations obtained by power mean generators, we have shown how to obtain a family of convex generators and dually flat spaces. Notice that some parametric families of Bregman divergences, such as the
-divergences [
46],
-divergences [
47], and
V-geometry [
48] of symmetric positive-definite matrices, yield families of dually flat spaces.
Banerjee et al. [
49] proved a duality between regular exponential families and a subclass of Bregman divergences, which they accordingly termed regular Bregman divergences. In particular, this duality allows the Maximum Likelihood Estimator (MLE) of an exponential family with a cumulant function
F to be viewed as a right-sided Bregman centroid with respect to the Legendre–Fenchel dual
. In [
50], the scope of this duality was further extended for arbitrary Bregman divergences by introducing a class of generalized exponential families.
Concave deformations have been recently studied in [
51], where the authors introduced the
-concavity induced by a positive continuous function
generating a deformed logarithm
as the
-comparative concavity (Definition 1.2 in [
51]), as well as the weaker notion of
F-concavity which corresponds to the
-concavity (Definition 2.1 in [
51], requiring strictly increasing functions
F). Our deformation framework
is more general, as it is double-sided. We jointly deform the function
F by
and its argument
by
.
Exponentially concave functions have been considered as generators of
L-divergences in [
24];
-exponentially concave functions
G such that
are concave for
generalize the
L-divergences to
-divergences, which can be expressed equivalently using a generalization of the Fenchel–Young divergence based on the
c-transforms [
24]. When
, exponentially convex functions are considered instead of exponentially concave functions. The information geometry induced by
-divergences are dually projectively flat with constant curvature, and reciprocally possess a dually projectively flat structure with constant curvature, inducing (locally) a canonical
-divergence. Wong and Zhang [
52] investigated a one-parameter deformation of convex duality, called
-duality, by considering functions
f such that
are convex for
. They defined the
-conjugate transform as a particular case of the
c-transform [
24] and studie the information geometry of the induced
-logarithmic divergences. The
-duality yields a generalization of exponential and mixture families to
-exponential and
-mixture families related to the Rényi divergence.
Finally, certain statistical divergences, called projective divergences, are invariant under rescaling, and as such can define dissimilarities between non-normalized densities. For example, the
-divergences [
32]
are such that
(with
-divergences tending to the KLD when
) or the Cauchy–Schwarz divergence [
53].



{kind=link}
{kind=link}
{kind=link}