
Ornstein–Uhlenbeck Adaptation as a Mechanism for Learning in Brains and Machines


Abstract
1. Introduction
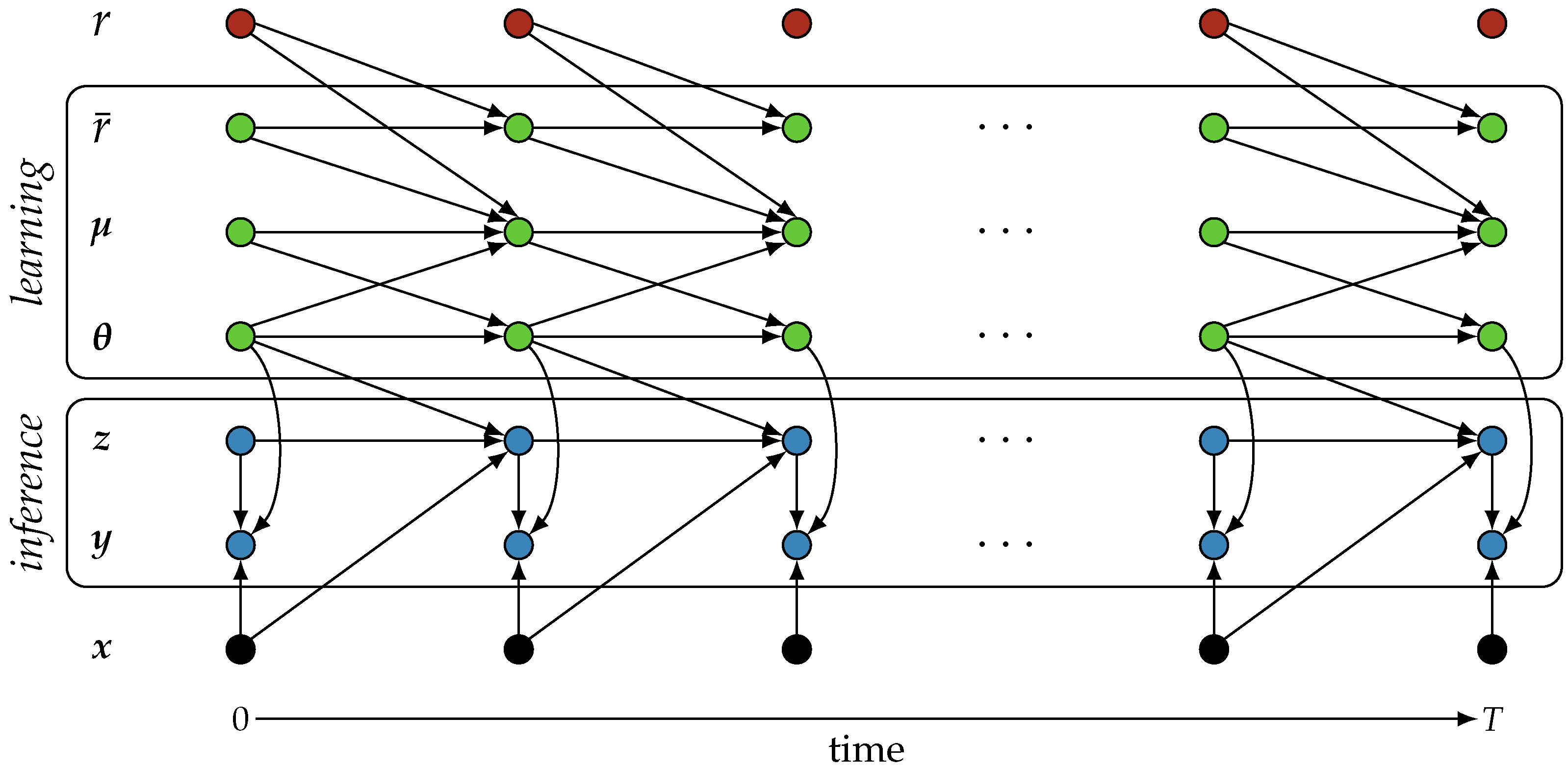
2. Methods
2.1. Inference
2.2. Reward Prediction
2.3. Learning
2.4. Experimental Validation
3. Results
3.1. Learning a Single-Parameter Model
3.2. Learning a Multi-Parameter Model
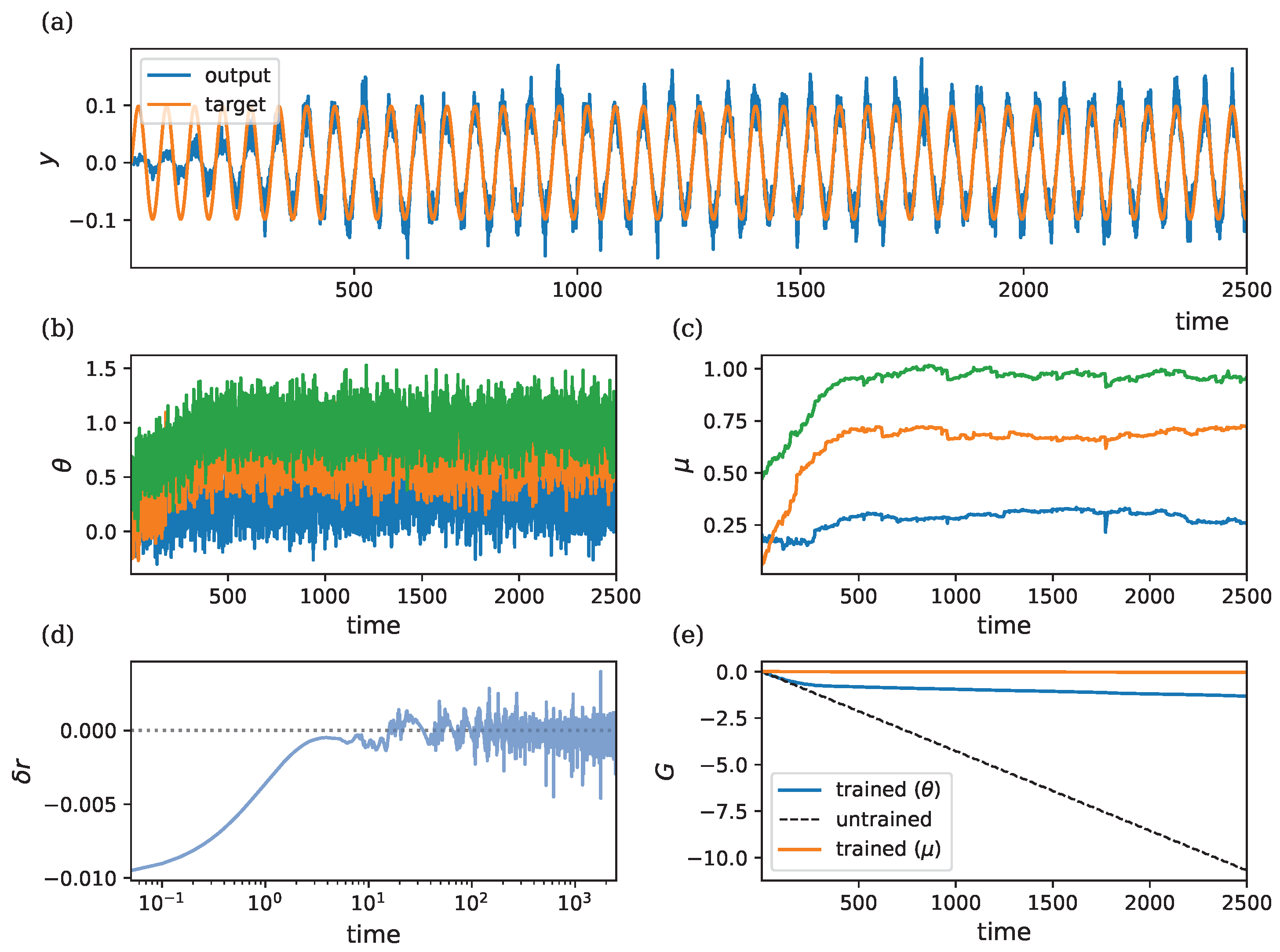
3.3. Weather Prediction Task
3.4. Learning in Recurrent Systems
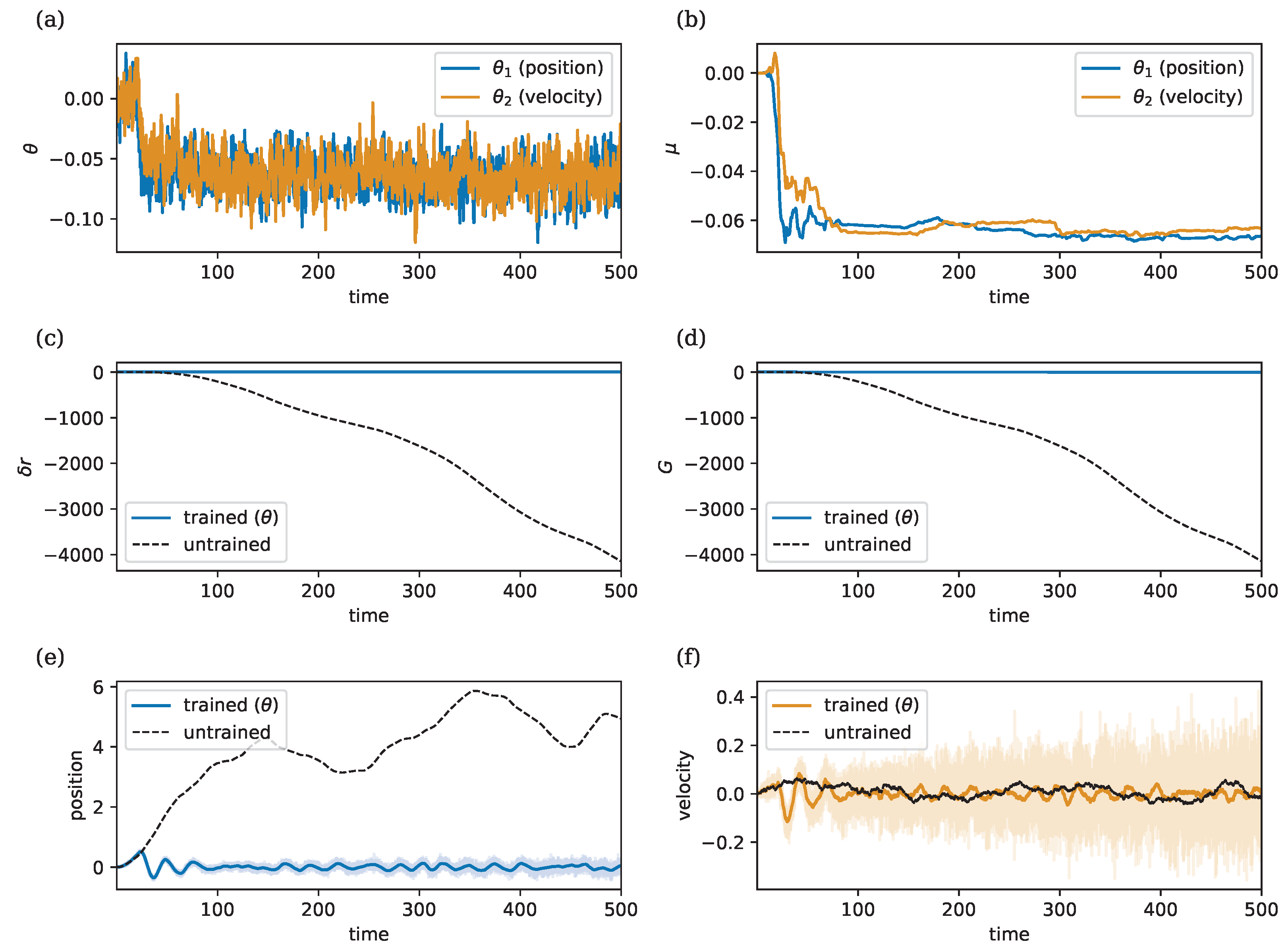
3.5. Learning to Control a Stochastic Double Integrator
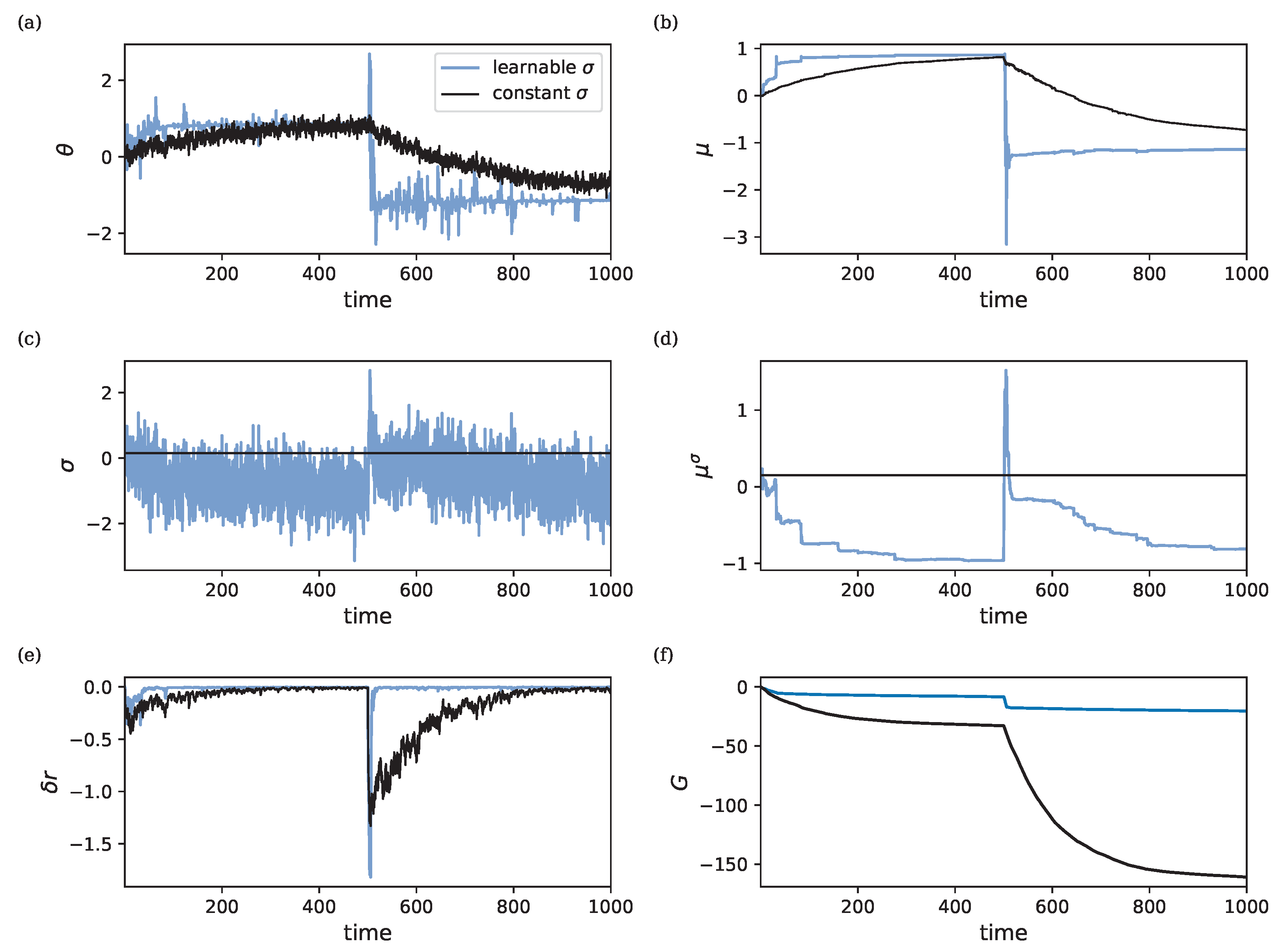
3.6. Meta-Learning
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Fernando, C.T.; Liekens, A.M.; Bingle, L.E.; Beck, C.; Lenser, T.; Stekel, D.J.; Rowe, J.E. Molecular circuits for associative learning in single-celled organisms. J. R. Soc. Interface 2009, 6, 463–469. [Google Scholar] [CrossRef]
- Gagliano, M.; Vyazovskiy, V.V.; Borbély, A.A.; Grimonprez, M.; Depczynski, M. Learning by association in plants. Sci. Rep. 2016, 6, 38427. [Google Scholar] [CrossRef]
- Money, N.P. Hyphal and mycelial consciousness: The concept of the fungal mind. Fungal Biol. 2021, 125, 257–259. [Google Scholar] [CrossRef]
- Sasakura, H.; Mori, I. Behavioral plasticity, learning, and memory in C. Elegans. Curr. Opin. Neurobiol. 2013, 23, 92–99. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S. Reinforcement Learning: An Introduction; A Bradford Book; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Brunton, S.L.; Kutz, J.N. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]
- Linnainmaa, S. The Representation of the Cumulative Rounding Error of an Algorithm as a Taylor Expansion of the Local Rounding Errors. Master’s Thesis, University of Helsinki, Helsinki, Finland, 1970; pp. 6–7. (In Finnish). [Google Scholar]
- Werbos, P. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. Ph.D. Thesis, Harvard University, Cambridge, MA, USA, 1974. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; Technical Report; California Univ San Diego La Jolla Inst for Cognitive Science: La Jolla, CA, USA, 1985. [Google Scholar]
- Lillicrap, T.P.; Santoro, A.; Marris, L.; Akerman, C.J.; Hinton, G. Backpropagation and the brain. Nat. Rev. Neurosci. 2020, 21, 335–346. [Google Scholar] [CrossRef]
- Whittington, J.C.; Bogacz, R. Theories of error back-propagation in the brain. Trends Cogn. Sci. 2019, 23, 235–250. [Google Scholar] [PubMed]
- Mead, C. Neuromorphic Electronic Systems. Proc. IEEE 1990, 78, 1629–1636. [Google Scholar] [CrossRef]
- Modha, D.S.; Ananthanarayanan, R.; Esser, S.K.; Ndirango, A.; Sherbondy, A.J.; Singh, R. Cognitive computing. Commun. ACM 2011, 54, 62–71. [Google Scholar] [CrossRef]
- Jaeger, H.; Noheda, B.; van der Wiel, W.G. Toward a formal theory for computing machines made out of whatever physics offers. Nat. Commun. 2023, 14, 4911. [Google Scholar] [CrossRef]
- Davies, M.; Wild, A.; Orchard, G.; Sandamirskaya, Y.; Guerra, G.A.F.; Joshi, P.; Plank, P.; Risbud, S.R. Advancing neuromorphic computing with loihi: A survey of results and outlook. Proc. IEEE 2021, 109, 911–934. [Google Scholar] [CrossRef]
- Oja, E. Simplified neuron model as a principal component analyzer. J. Math. Biol. 1982, 15, 267–273. [Google Scholar] [CrossRef]
- Bienenstock, E.L.; Cooper, L.N.; Munro, P.W. Theory for the development of neuron selectivity: Orientation specificity and binocular interaction in visual cortex. J. Neurosci. 1982, 2, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Scellier, B.; Bengio, Y. Equilibrium propagation: Bridging the gap between energy-based models and backpropagation. Front. Comput. Neurosci. 2017, 11, 24. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y. How auto-encoders could provide credit assignment in deep networks via target propagation. arXiv 2014, arXiv:1407.7906. [Google Scholar]
- Whittington, J.C.; Bogacz, R. An approximation of the error backpropagation algorithm in a predictive coding network with local Hebbian synaptic plasticity. Neural Comput. 2017, 29, 1229–1262. [Google Scholar] [CrossRef]
- Markram, H.; Lübke, J.; Frotscher, M.; Sakmann, B. Regulation of synaptic efficacy by coincidence of postsynaptic APs and EPSPs. Science 1997, 275, 213–215. [Google Scholar] [CrossRef] [PubMed]
- Bellec, G.; Scherr, F.; Subramoney, A.; Hajek, E.; Salaj, D.; Legenstein, R.; Maass, W. A solution to the learning dilemma for recurrent networks of spiking neurons. Nat. Commun. 2020, 11, 3625. [Google Scholar] [CrossRef]
- Haider, P.; Ellenberger, B.; Kriener, L.; Jordan, J.; Senn, W.; Petrovici, M.A. Latent equilibrium: A unified learning theory for arbitrarily fast computation with arbitrarily slow neurons. Adv. Neural Inf. Process. Syst. 2021, 34, 17839–17851. [Google Scholar]
- Payeur, A.; Guerguiev, J.; Zenke, F.; Richards, B.A.; Naud, R. Burst-dependent synaptic plasticity can coordinate learning in hierarchical circuits. Nat. Neurosci. 2021, 24, 1010–1019. [Google Scholar] [CrossRef] [PubMed]
- Spall, J.C. Multivariate stochastic approximation using a simultaneous perturbation gradient approximation. IEEE Trans. Autom. Control 1992, 37, 332–341. [Google Scholar] [CrossRef]
- Widrow, B.; Lehr, M.A. 30 years of adaptive neural networks: Perceptron, madaline, and backpropagation. Proc. IEEE 1990, 78, 1415–1442. [Google Scholar] [CrossRef]
- Werfel, J.; Xie, X.; Seung, H. Learning curves for stochastic gradient descent in linear feedforward networks. Adv. Neural Inf. Process. Syst. 2003, 16, 1197–1204. [Google Scholar] [CrossRef] [PubMed]
- Flower, B.; Jabri, M. Summed weight neuron perturbation: An O(n) improvement over weight perturbation. Adv. Neural Inf. Process. Syst. 1992, 5, 212–219. [Google Scholar]
- Hiratani, N.; Mehta, Y.; Lillicrap, T.; Latham, P.E. On the stability and scalability of node perturbation learning. Adv. Neural Inf. Process. Syst. 2022, 35, 31929–31941. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Fiete, I.R.; Seung, H.S. Gradient learning in spiking neural networks by dynamic perturbation of conductances. Phys. Rev. Lett. 2006, 97, 048104. [Google Scholar] [CrossRef]
- Dalm, S.; Offergeld, J.; Ahmad, N.; van Gerven, M. Efficient deep learning with decorrelated backpropagation. arXiv 2024, arXiv:2405.02385. [Google Scholar]
- Fernández, J.G.; Keemink, S.; van Gerven, M. Gradient-free training of recurrent neural networks using random perturbations. Front. Neurosci. 2024, 18, 1439155. [Google Scholar] [CrossRef]
- Kirk, D.B.; Kerns, D.; Fleischer, K.; Barr, A. Analog VLSI implementation of multi-dimensional gradient descent. Adv. Neural Inf. Process. Syst. 1992, 5, 789–796. [Google Scholar]
- Lippe, D.; Alspector, J. A study of parallel perturbative gradient descent. Adv. Neural Inf. Process. Syst. 1994, 7, 803–810. [Google Scholar]
- Züge, P.; Klos, C.; Memmesheimer, R.M. Weight versus node perturbation learning in temporally extended tasks: Weight perturbation often performs similarly or better. Phys. Rev. X 2023, 13, 021006. [Google Scholar] [CrossRef]
- Cauwenberghs, G. A fast stochastic error-descent algorithm for supervised learning and optimization. Adv. Neural Inf. Process. Syst. 1992, 5, 244–251. [Google Scholar]
- Dembo, A.; Kailath, T. Model-free distributed learning. IEEE Trans. Neural Netw. 1990, 1, 58–70. [Google Scholar] [CrossRef] [PubMed]
- Legenstein, R.; Chase, S.M.; Schwartz, A.B.; Maass, W. A reward-modulated hebbian learning rule can explain experimentally observed network reorganization in a brain control task. J. Neurosci. 2010, 30, 8400–8410. [Google Scholar] [CrossRef]
- Miconi, T. Biologically plausible learning in recurrent neural networks reproduces neural dynamics observed during cognitive tasks. eLife 2017, 6, e20899. [Google Scholar] [CrossRef] [PubMed]
- Uhlenbeck, G.E.; Ornstein, L.S. On the theory of the Brownian motion. Phys. Rev. 1930, 36, 823–841. [Google Scholar] [CrossRef]
- Doob, J.L. The Brownian movement and stochastic equations. Ann. Math. 1942, 43, 351–369. [Google Scholar] [CrossRef]
- Schultz, W.; Dayan, P.; Montague, P.R. A neural substrate of prediction and reward. Science 1997, 275, 1593–1599. [Google Scholar]
- Kudithipudi, D.; Aguilar-Simon, M.; Babb, J.; Bazhenov, M.; Blackiston, D.; Bongard, J.; Brna, A.P.; Raja, S.C.; Cheney, N.; Clune, J.; et al. Biological underpinnings for lifelong learning machines. Nat. Mach. Intell. 2022, 4, 196–210. [Google Scholar] [CrossRef]
- Tzen, B.; Raginsky, M. Neural stochastic differential equations: Deep latent Gaussian models in the diffusion limit. arXiv 2019, arXiv:1905.09883. [Google Scholar]
- Wan, Y.; Naik, A.; Sutton, R.S. Learning and planning in average-reward Markov decision processes. In Proceedings of the International Conference on Machine Learning, PMLR, 18–24 July 2021; pp. 10653–10662. [Google Scholar]
- Rao, V.G.; Bernstein, D.S. Naïve control of the double integrator. IEEE Control Syst. Mag. 2001, 21, 86–97. [Google Scholar]
- Kidger, P. On Neural Differential Equations. Ph.D. Thesis, University of Oxford, Oxford, UK, 2021. [Google Scholar]
- Morrill, J.; Kidger, P.; Yang, L.; Lyons, T. Neural controlled differential equations for online prediction tasks. arXiv 2021, arXiv:2106.11028. [Google Scholar]
- Ahmad, N.; Schrader, E.; van Gerven, M. Constrained parameter inference as a principle for learning. arXiv 2022, arXiv:2203.13203. [Google Scholar]
- Ahmad, N. Correlations are ruining your gradient descent. arXiv 2024, arXiv:2407.10780. [Google Scholar]
- Bell, A.J.; Sejnowski, T.J. The “independent components” of natural scenes are edge filters. Vis. Res. 1997, 37, 3327–3338. [Google Scholar] [CrossRef]
- Schmidhuber, J. Evolutionary Principles in Self-Referential Learning. Ph.D. Thesis, Technische Universität München, Munich, Germany, 1987. [Google Scholar]
- Feldbaum, A.A. Dual control theory, I. Avtomat. Telemekh. 1960, 21, 1240–1249. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Xu, W.; Chen, R.T.Q.; Li, X.; Duvenaud, D. Infinitely deep Bayesian neural networks with stochastic differential equations. arXiv 2022, arXiv:2102.06559v4. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 25, 2951–2959. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef]
- Beyer, H.G.; Schwefel, H.P. Evolution strategies—A comprehensive introduction. Nat. Comput. 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Faisal, A.A.; Selen, L.P.J.; Wolpert, D.M. Noise in the nervous system. Nat. Rev.. Neurosci. 2008, 9, 292–303. [Google Scholar] [CrossRef] [PubMed]
- Engel, T.A.; Chaisangmongkon, W.; Freedman, D.J.; Wang, X.J. Choice-correlated activity fluctuations underlie learning of neuronal category representation. Nat. Commun. 2015, 6, 6454. [Google Scholar] [CrossRef] [PubMed]
- Branco, T.; Staras, K. The probability of neurotransmitter release: Variability and feedback control at single synapses. Nat. Rev. Neurosci. 2009, 10, 373–383. [Google Scholar]
- Rolls, E.T.; Deco, G. The Noisy Brain: Stochastic Dynamics as a Principle of Brain Function; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Schultz, W. Dopamine reward prediction error coding. Dialogues Clin. Neurosci. 2016, 18, 23–32. [Google Scholar] [CrossRef] [PubMed]
- Markovic, D.; Mizrahi, A.; Querlioz, D.; Grollier, J. Physics for neuromorphic computing. Nat. Rev. Phys. 2020, 2, 499–510. [Google Scholar] [CrossRef]
- Stern, M.; Hexner, D.; Rocks, J.W.; Liu, A.J. Supervised learning in physical networks: From machine learning to learning machines. Phys. Rev. X 2021, 11, 021045. [Google Scholar] [CrossRef]
- Nakajima, M.; Inoue, K.; Tanaka, K.; Kuniyoshi, Y.; Hashimoto, T.; Nakajima, K. Physical deep learning with biologically inspired training method: Gradient-free approach for physical hardware. Nat. Commun. 2022, 13, 7847. [Google Scholar] [CrossRef]
- López-Pastor, V.; Marquardt, F. Self-learning machines based on Hamiltonian echo backpropagation. Phys. Rev. X 2023, 13, 031020. [Google Scholar] [CrossRef]
- Momeni, A.; Rahmani, B.; Malléjac, M.; del Hougne, P.; Fleury, R. Backpropagation-free training of deep physical neural networks. Science 2023, 382, 1297–1303. [Google Scholar] [CrossRef] [PubMed]
- Van Doremaele, E.R.W.; Stevens, T.; Ringeling, S.; Spolaor, S.; Fattori, M.; van de Burgt, Y. Hardware implementation of backpropagation using progressive gradient descent for in situ training of multilayer neural networks. Sci. Adv. 2024, 10, 8999. [Google Scholar] [CrossRef] [PubMed]
- Kaspar, C.; Ravoo, B.J.; van der Wiel, W.G.; Wegner, S.V.; Pernice, W.H. The rise of intelligent matter. Nature 2021, 594, 345–355. [Google Scholar] [CrossRef] [PubMed]
- Shahsavari, M.; Thomas, D.; van Gerven, M.A.J.; Brown, A.; Luk, W. Advancements in spiking neural network communication and synchronization techniques for event-driven neuromorphic systems. Array 2023, 20, 100323. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ZCA Data | Original Data | |||
|---|---|---|---|---|
| MSE | Pearson Corr. | MSE | Pearson Corr. | |
| SGD | 0.21 | 0.871 | 0.21 | 0.874 |
| OUA | 0.22 | 0.871 | 0.22 | 0.871 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García Fernández, J.; Ahmad, N.; van Gerven, M. Ornstein–Uhlenbeck Adaptation as a Mechanism for Learning in Brains and Machines. Entropy 2024, 26, 1125. https://doi.org/10.3390/e26121125
García Fernández J, Ahmad N, van Gerven M. Ornstein–Uhlenbeck Adaptation as a Mechanism for Learning in Brains and Machines. Entropy. 2024; 26(12):1125. https://doi.org/10.3390/e26121125
Chicago/Turabian StyleGarcía Fernández, Jesús, Nasir Ahmad, and Marcel van Gerven. 2024. "Ornstein–Uhlenbeck Adaptation as a Mechanism for Learning in Brains and Machines" Entropy 26, no. 12: 1125. https://doi.org/10.3390/e26121125
APA StyleGarcía Fernández, J., Ahmad, N., & van Gerven, M. (2024). Ornstein–Uhlenbeck Adaptation as a Mechanism for Learning in Brains and Machines. Entropy, 26(12), 1125. https://doi.org/10.3390/e26121125