1. Introduction
The pioneering experiments conducted by Church et al. [
1] demonstrated the feasibility to store data in synthetic deoxyribonucleic acid (DNA), promising a huge data capacity, nil dissipation during storage, and very long-term stability. Natural DNA consists of four types of nucleotides: adenine (‘A’), cytosine (‘C’), guanine (‘G’), and thymine (‘T’). Codes are used for translating user data into sequences of digits in the quaternary alphabet {A, C, G, T} that are suitable for the synthesis of DNA strands. Prior art studies have focused on error-correcting codes for restoring various kinds of defects in DNA [
2,
3,
4] or constrained codes that avoid the generation of vexatious DNA sequences that are prone to error; see, for example, Refs. [
5,
6,
7,
8].
The synthesis of DNA strands is a relative expensive part of the storage chain. In array-based synthesis, multiple DNA strands are synthesized in parallel [
9] by adding in each cycle a single nucleotide to a subset of the DNA strands. Lenz et al. [
10], Makarychev et al. [
11], Elishco and Huleihel [
12], Immink et al. [
13], and Nguyen et al. [
14] presented and analyzed coding techniques for efficiently synthesizing multiple parallel strands so that overall synthesis time can be shortened. Of specific interest in minimizing the synthesis time are sets (codes) of words of low weight, which are dealt with in the next subsection.
1.1. Low-Weight Codes
Although our main interest is in the quaternary DNA case, we will consider
q-ary sequences for generality. For clerical convenience, we assume that the alphabet used is
, where
is a positive integer. For the DNA case, we represent the quaternary alphabet {A, C, G, T} by
. Let
,
, be a sequence of
n symbols, called
word of length
n. The symbol sum
is termed the
weight of the word
a. Clearly,
. A
constant-weight code of length
n, denoted by
, consists of all words of weight
w, that is,
The size of
, denoted by
, is found as the coefficient of
of the
generating function [
15]
For synthesizing multiple words into physical sequences in parallel, we assume the sequences are generated by adding symbols in cycles. In each cycle in the synthesis process, one particular symbol from
is added to the sequences of the words waiting for that symbol. Throughout this paper, we assume the symbol adding in the subsequent cycles is in the order
, which has been shown to be optimal; see [
10,
12]. In order to allow any word from
to be synthesized,
cycles are needed. By restricting the set of words used for representing data, the number of required synthesis cycles can be reduced, as explained next.
Let the
low-weight code be the union of the sets of words of weight
, where the integer
t,
denotes the maximum weight of the codewords. As explained in [
10,
13], low-weight codewords
y can be bijectively mapped to words
,
, by
with
, such that the words
x have a synthesis time of at most
t cycles. Let the low-weight code be denoted as
, where
, and the associated set of words
x as
. From the synthesis perspective, we are interested in properties of the codes
, but because of the bijective mapping we can also study the low-weight codes
.
1.2. Redundancy and Information Rate
The
redundancy (in bits per symbol) of a low-weight code
is defined by
where
Lenz et al. [
10] also introduced the
information rate (in bits per cycle) of a low-weight code
as
Of course,
and
are also the redundancy and information rate, respectively, of
. Note that
is a measure for the synthesis efficiency of the codewords of
.
Using (
3), we can straightforwardly compute
and
versus
.
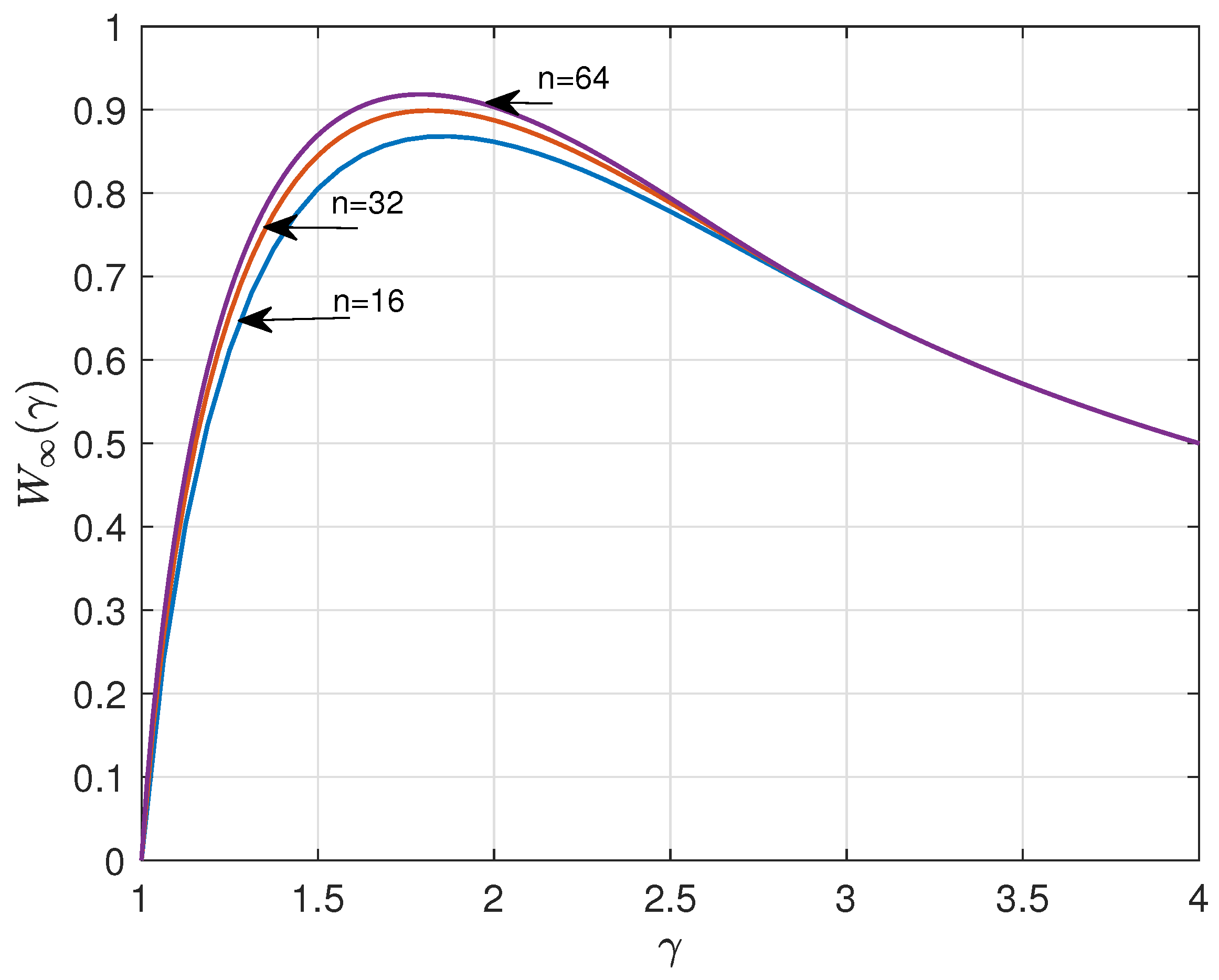
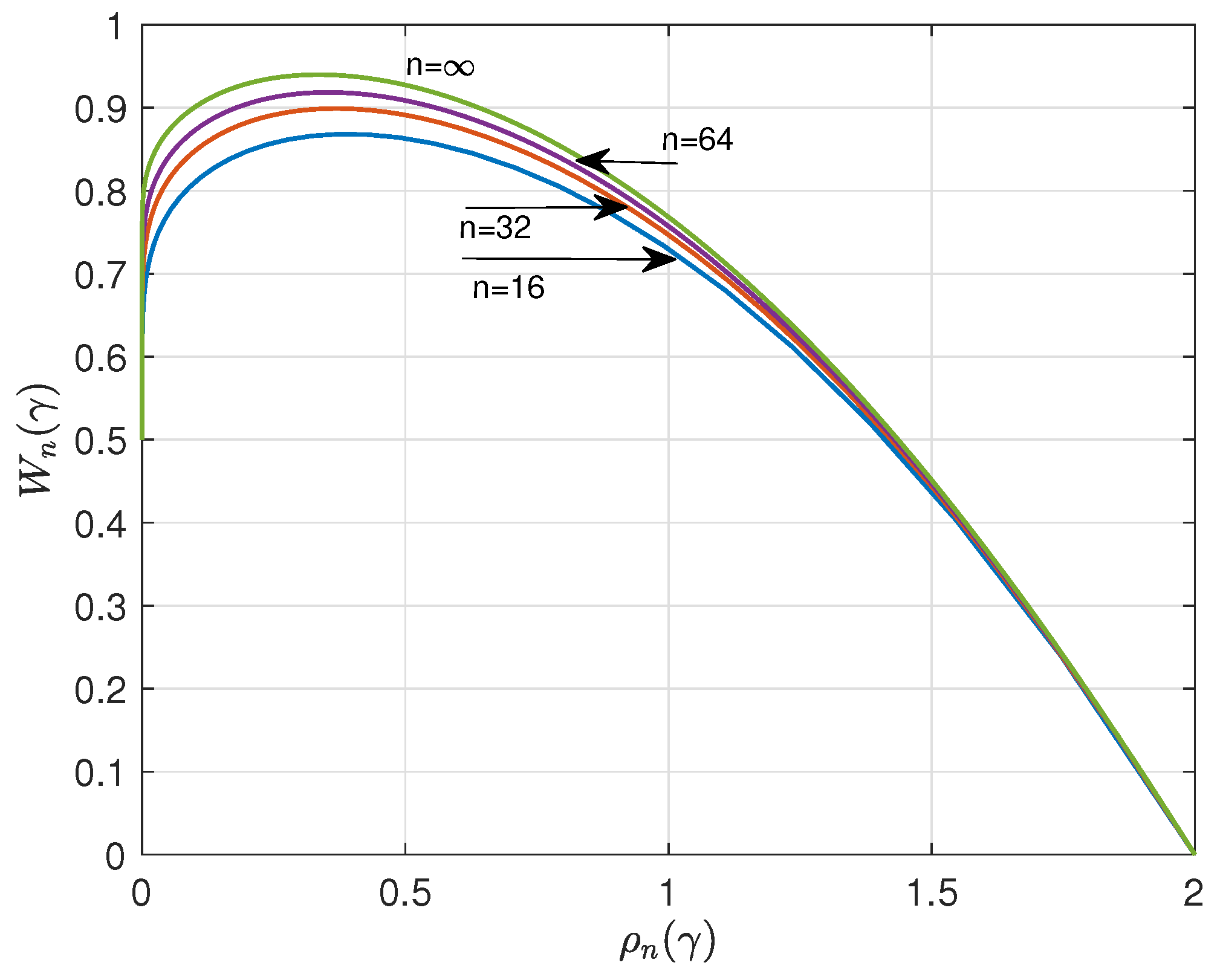
Figure 1 and
Figure 2 show the results for
, 32,
and
. The curves suggest that
and
have a lower bound and upper bound, respectively, for asymptotic large
n. A major goal of this paper is to determine these bounds.
1.3. Contributions and Overview of the Paper
Besides introducing the framework as just described, Lenz et al. [
10] also conducted a brief performance analysis of DNA synthesis codes, mainly based on tools from the theory of cost-constrained channels. Constructions of efficient DNA synthesis codes were further explored in [
13]. Here, in this paper,
Section 2 deals with an extensive asymptotic analysis, with a focus on the trade-off between redundancy and information rate. The results are derived using Jaynes’ maximum entropy principle. In
Section 3, we compare the obtained theoretical optima with the performance of practical nibble replacement codes. Finally, we extend the analysis to codes with a runlength constraint in
Section 4 and conclude the paper in
Section 5.
2. Asymptotic Analysis of Low-Weight Codes
In order to evaluate the sizes of large low-weight codes, we use the following approach. Let
be the set of compositions
of
n, where
are nonnegative integers such that
subject to the constraint
. The number of
q-ary words of length
n with
symbols equal to
i,
, denoted by
, equals
The constant-weight code size,
, is found by summing
for all possible compositions
so that
2.1. Asymptotic Analysis of
We are specifically interested in
for asymptotically large
n. So, let
and
for all
i, while keeping
,
, the distribution of the symbol values, fixed. It then follows (see Wallis argument in Section 11.4 of [
16]), using Stirling’s approximation, that
and thus
where
In a similar vein, we find
Since
is monotonically increasing with
w,
, if
, with a maximum
at
, we infer
The problem of determining
, and thus the asymptotic redundancy
and the asymptotic information rate
, is now a matter of finding, for asymptotically large
n, a
in
that maximizes
. The composition
in
is characterized by
which can be conveniently rewritten as
In the next subsection, we maximize by a judicious choice of the distribution of the symbol values, , under these conditions.
2.2. Principle of Maximum Entropy
We change the above setting of finite-length codewords and now assume a stationary information source that transmits symbols of (integer) magnitude
i,
, with probability distribution
, where
and
. The information content per symbol sent, or
entropy, denoted by
H, defined by Shannon [
17], is
Although the variable
in (
12) and Shannon’s entropy
H share the same expression in
p, the background of the expressions is different [
16]. Note that in (
12), the
’s are rational numbers, while in (
17) the
’s are assumed to be real numbers.
We are interested in maximizing the entropy
H. Define
, where the maximization over the
is under the conditions (
16). Jaynes [
18] concluded that the entropy,
H, is maximized subject to these constraints by the maxentropic probability distribution
where the parameters
and
,
, satisfy the conditions
and
After substituting (
19) to (
21) into (
17), we find
For the case
, we may easily find that
and
, so that
,
, and
For
, no simple closed-form expression could be found, and we use numerical methods for solving (
20) and (
21).
2.3. Asymptotic Redundancy and Information Rate
As a result, the asymptotic redundancy is
Figure 3 depicts, for
, and 6, the relationship between the asymptotic redundancy
and
.
The asymptotic information rate,
, equals
Figure 4 shows
versus
for
and 6.
The maximum asymptotic information rate, denoted by
can be found after an analysis of (
22). We write (
22), using (
20) and (
21), as a function of
and conclude that the largest (real) root of
denoted by
, maximizes
. We obtain, see (
20),
and hence, see (
22), we infer that
where
and
Note that Equation (
27) is equivalent to the characteristic equation
of a binary source under the constraint that the maximum runlength is
q [
19]. The capacity of binary sequences with a maximum runlength constraint of
q equals
, where
is largest (real) root of the characteristic equation [
17]. Hence, the maximum asymptotic information rate
of
q-ary low-weight codes is equal to this capacity. Numerical values of the latter have been listed for selected values of
q in [
19]. Since the capacity approaches unity for increasing values of
q, the same holds for the information rate
, which is achieved for
. In other words, for large values of
n and
q, the maximum information rate is achieved by setting the maximum weight of the low-weight code equal to (roughly)
. The corresponding redundancy is
. For any
q, the asymptotic redundancy can be lowered from
to zero by increasing
from
to
, which implies that the asymptotic information rate decreases from
to
. This trade-off between redundancy and information rate is further explored for the case
in the next subsection.
2.4. Case Study for
In this subsection, we consider the case
, which is of particular interest since it is the alphabet size for DNA synthesis codes. For
, we find using numerical methods that
,
, and
. The probability distribution at maximum entropy is
(0.519, 0.269, 0.140, 0.072).
Figure 5 shows the parametric representation of
versus
with
as a parameter for the case
. The curve is a typical price/performance curve, where we may observe that a higher
comes with a higher penalty in redundancy
.
It is the difficult task of a system designer to trade the costs and benefits of the conflicting parameters. Note that in the range
we have
, a zero-redundant system, while in the range
we may achieve the same information rate
with a smaller redundancy. For example, we may notice that we can achieve
for zero redundancy cost or for roughly 0.9. In practice, we prefer the smaller redundancy alternative so that in this range of practical interest, we have
and
.
Figure 6 displays
versus
in the range of practical interest
.
3. Comparison with Implemented Codes
In this section, we compare the performance of implemented codes with that of maxentropic low-weight codes. In [
13], various code implementations have been assessed. Here, we focus on the
nibble replacement (NR) algorithm [
13,
20], which is an efficient method for encoding/decoding with small complexity and redundancy.
In the NR format, an
n-symbol strand is divided into
L subwords of length
m, so that
. Let
be the maximum allowed cycle count of an
m-symbol
q-ary word, then the maximum cycle count of the
n-symbol
q-ary word is
. Let
denote the number of low-weight
m-symbol codewords. Define
and
The NR algorithm translates
source bits into
L -bit words. Each
-bit word is translated, using a look-up table, into a
q-ary
m-symbol word that satisfies the
-cycle count constraint. The NR encoding method requires data storage of
L -bit words, the execution of the encoding algorithm [
13], and a look-up table for translating an
-bit wide word into a word of
m q-ary symbols so that very large,
n-symbol wide, look-up tables are avoided. The overall redundancy per symbol,
, and information rate,
, of the
n-symbol word are
and
Table 1 shows numerical results selected from Table I in [
13].
The scattered points (black circles) in
Figure 6 are found by plotting the redundancy,
, and information rate,
, of the NR codes shown in
Table 1.
4. Runlength Limitation
It is known that homopolymer runs, i.e., adjacent repetitions of the same nucleotide, make DNA-based data storage more error prone [
12]. Therefore, it could be advantageous to use strands in which long runs are avoided. Of course, this comes at the expense of an increased redundancy. In this section, we perform an asymptotic analysis of codes aiming at (i) small redundancy, (ii) high information rate, and (iii) small maximum runlength. These are conflicting goals resulting into trade-off considerations. Again, we start by investigating
q-ary codes and then focus on the
case.
We say that a code is r-RLL (runlength limited) if within any codeword any run of identical symbols is of length at most r, where . When , there is actually no constraint with respect to the runlength. Here, we focus on the other extreme, ; i.e., we consider codewords in which any two adjacent symbols are different. We investigate the asymptotic redundancy and information rate of q-ary 1-RLL codes. The same notation as before is used, where we indicate with a tilde that the constraint is in place.
Let
denote the
q-ary code consisting of all 1-RLL sequences that can be synthesized in at most
cycles. The codewords
of the associated low-weight code
are obtained from the codewords
of
by the bijective mapping
with
. Note that due to the 1-RLL property of
, it holds that
and thus
for all
. Hence,
, where
and the range for
is in this case
, since the maximum number of cycles is
rather than
due to the runlength constraint.
Similarly to what we did before, we next evaluate
Since the symbol distribution
satisfies, for any codeword in the low-weight code,
as
, we can conclude that the value of
in the
q-ary case is equal to the value of
in the
-ary case. Hence, it easily follows that
The asymptotic redundancy in the q-ary 1-RLL case equals plus the asymptotic redundancy in the -ary case without runlength restriction;
The asymptotic information rate in the q-ary 1-RLL case equals the asymptotic information rate in the -ary case without runlength restriction.
As an illustration, we consider the case
. By applying the results from (
25) and (
26) for
, we find
and
for
. These 1-RLL results are compared to the corresponding results without runlength limitation from
Section 2 in
Figure 7,
Figure 8 and
Figure 9. Results for
r-RLL codes,
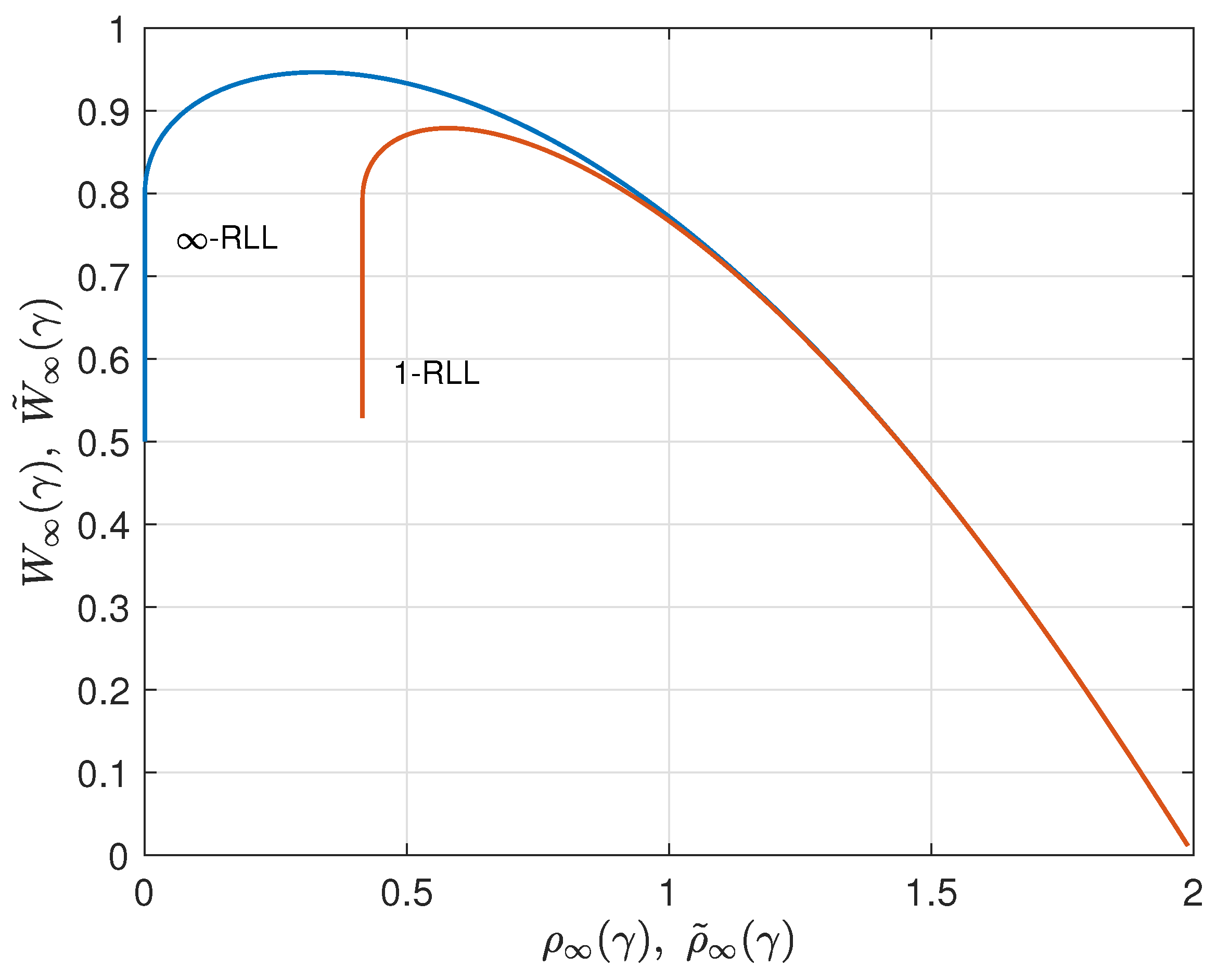
, will be in between the lower and the upper curves in these figures. Various trade-off possibilities can be considered. Note that, for small values of
, imposing the runlength limitation comes at hardly any price, but that for larger values of
we considerably pay in terms of redundancy and information rate. Fixing the asymptotic redundancy at, e.g.,
, it follows from
Figure 9 that the asymptotic information rate drops from about 0.93 (
∞-RLL, i.e., no runlength limitation) to about 0.87 (1-RLL).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}