
Information-Theoretic Generalization Bounds for Batch Reinforcement Learning


{kind=link}
Abstract
1. Introduction
2. Preliminaries
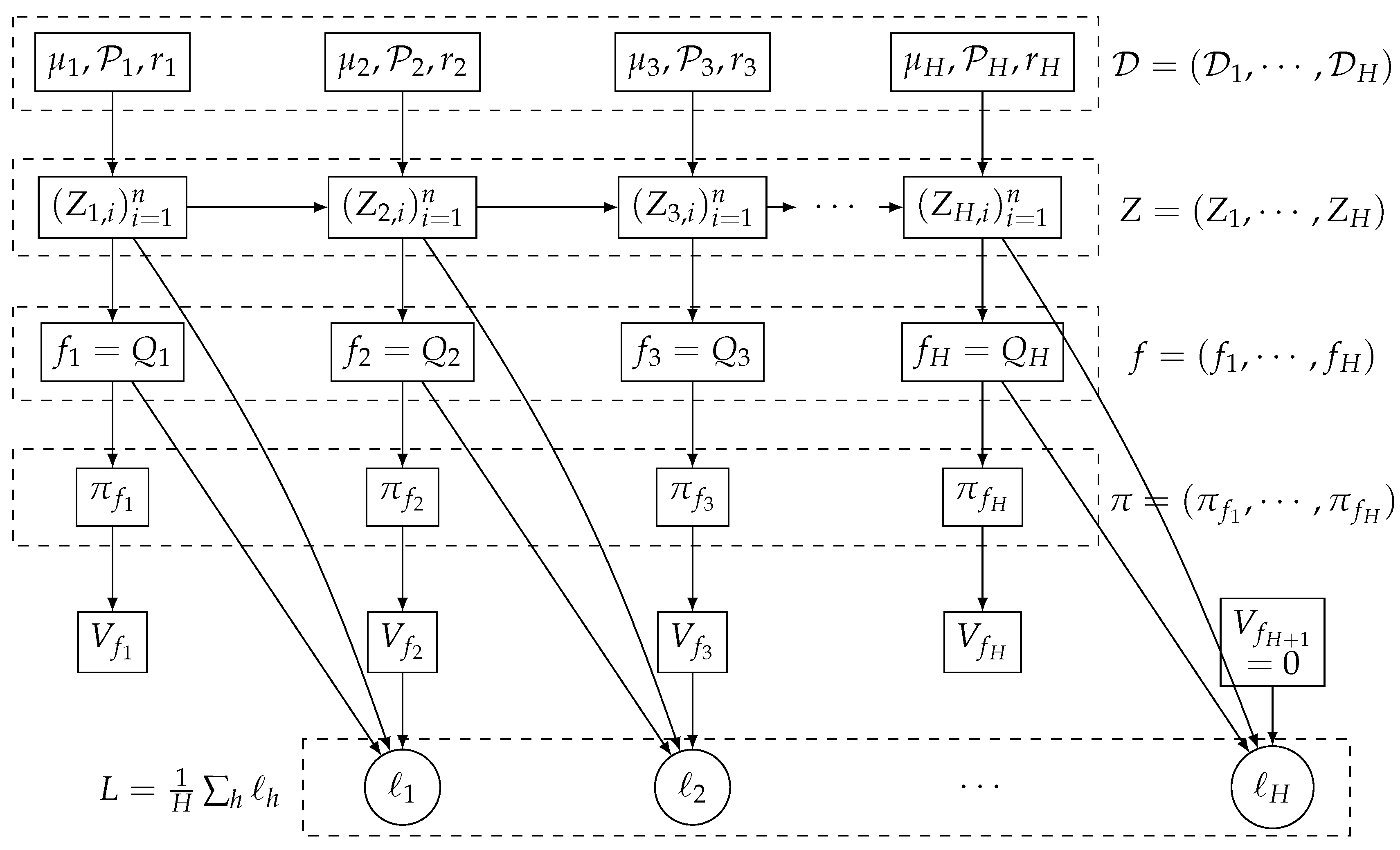
2.1. Batch Reinforcement Learning with Function Approximation
2.2. Generalization Bounds
2.3. Mutual Information
3. Generalization Bounds via Mutual Information
- (i)
- Data Processing Inequality: given , if the Markov chain holds.
- (ii)
- (iii)
- (iv)
- with equality iff X and Y are independent.
4. Information-Theoretic Generalization Bounds for Batch RL
5. Value Functions Under Structural Assumptions
- for every , there exists satisfying for all ,
- , where .
- and for all .
- for any function .
- for all h, where .
6. Discussion
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Related Work
Appendix A.1. Batch Reinforcement Learning
Appendix A.2. Structural Conditions for Efficient RL
Appendix A.3. Information-Theoretic Study of Generalization
References
- Russo, D.; Zou, J. Controlling bias in adaptive data analysis using information theory. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 1232–1240. [Google Scholar]
- Xu, A.; Raginsky, M. Information-theoretic analysis of generalization capability of learning algorithms. Adv. Neural Inf. Process. Syst. 2017, 30, 2521–2530. [Google Scholar]
- Duan, Y.; Jin, C.; Li, Z. Risk bounds and rademacher complexity in batch reinforcement learning. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 2892–2902. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement learning: An introduction. Robotica 1999, 17, 229–235. [Google Scholar] [CrossRef]
- Antos, A.; Szepesvári, C.; Munos, R. Learning near-optimal policies with Bellman-residual minimization based fitted policy iteration and a single sample path. Mach. Learn. 2008, 71, 89–129. [Google Scholar] [CrossRef]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Verdú, S. α-mutual information. In Proceedings of the 2015 Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 1–6 February 2015; pp. 1–6. [Google Scholar]
- Van Erven, T.; Harremos, P. Rényi divergence and Kullback-Leibler divergence. IEEE Trans. Inf. Theory 2014, 60, 3797–3820. [Google Scholar] [CrossRef]
- Csiszár, I. Generalized cutoff rates and Rényi’s information measures. IEEE Trans. Inf. Theory 1995, 41, 26–34. [Google Scholar] [CrossRef]
- Mironov, I. Rényi differential privacy. In Proceedings of the 2017 IEEE 30th Computer Security Foundations Symposium (CSF), Santa Barbara, CA, USA, 21–25 August 2017; pp. 263–275. [Google Scholar]
- Esposito, A.R.; Gastpar, M.; Issa, I. Generalization error bounds via Rényi-, f-divergences and maximal leakage. IEEE Trans. Inf. Theory 2021, 67, 4986–5004. [Google Scholar] [CrossRef]
- Steinke, T.; Zakynthinou, L. Reasoning about generalization via conditional mutual information. In Proceedings of the Conference on Learning Theory, Graz, Austria, 9–12 July 2020; pp. 3437–3452. [Google Scholar]
- Boucheron, S.; Lugosi, G.; Massart, P. Concentration Inequalities: A Nonasymptotic Theory of Independence; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Jiang, N.; Krishnamurthy, A.; Agarwal, A.; Langford, J.; Schapire, R.E. Contextual decision processes with low bellman rank are pac-learnable. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1704–1713. [Google Scholar]
- Sun, W.; Jiang, N.; Krishnamurthy, A.; Agarwal, A.; Langford, J. Model-based rl in contextual decision processes: Pac bounds and exponential improvements over model-free approaches. In Proceedings of the Conference on Learning Theory, Phoenix, AZ, USA, 25–28 June 2019; pp. 2898–2933. [Google Scholar]
- Wang, R.; Salakhutdinov, R.R.; Yang, L. Reinforcement learning with general value function approximation: Provably efficient approach via bounded eluder dimension. Adv. Neural Inf. Process. Syst. 2020, 33, 6123–6135. [Google Scholar]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Haussler, D. Decision theoretic generalizations of the PAC model for neural net and other learning applications. Inf. Comput. 1992, 100, 78–150. [Google Scholar] [CrossRef]
- Haussler, D. Sphere packing numbers for subsets of the Boolean n-cube with bounded Vapnik-Chervonenkis dimension. J. Comb. Theory Ser. A 1995, 69, 217–232. [Google Scholar] [CrossRef]
- Du, S.; Kakade, S.; Lee, J.; Lovett, S.; Mahajan, G.; Sun, W.; Wang, R. Bilinear classes: A structural framework for provable generalization in rl. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 2826–2836. [Google Scholar]
- Jin, C.; Liu, Q.; Miryoosefi, S. Bellman eluder dimension: New rich classes of rl problems, and sample-efficient algorithms. Adv. Neural Inf. Process. Syst. 2021, 34, 13406–13418. [Google Scholar]
- Wei, R.; Lambert, N.; McDonald, A.; Garcia, A.; Calandra, R. A Unified View on Solving Objective Mismatch in Model-Based Reinforcement Learning. arXiv 2023, arXiv:2310.06253. [Google Scholar]
- Farahmand, A.M.; Barreto, A.; Nikovski, D. Value-aware loss function for model-based reinforcement learning. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1486–1494. [Google Scholar]
- Farahmand, A.M. Iterative value-aware model learning. Adv. Neural Inf. Process. Syst. 2018, 31, 9090–9101. [Google Scholar]
- Abachi, R. Policy-Aware Model Learning for Policy Gradient Methods; University of Toronto (Canada): Toronto, ON, Canada, 2020. [Google Scholar]
- Janner, M.; Fu, J.; Zhang, M.; Levine, S. When to trust your model: Model-based policy optimization. Adv. Neural Inf. Process. Syst. 2018, 32, 12519–12530. [Google Scholar]
- Ji, T.; Luo, Y.; Sun, F.; Jing, M.; He, F.; Huang, W. When to update your model: Constrained model-based reinforcement learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23150–23163. [Google Scholar]
- Wang, X.; Zheng, R.; Sun, Y.; Jia, R.; Wongkamjan, W.; Xu, H.; Huang, F. Coplanner: Plan to roll out conservatively but to explore optimistically for model-based RL. arXiv 2023, arXiv:2310.07220. [Google Scholar]
- Neu, G.; Dziugaite, G.K.; Haghifam, M.; Roy, D.M. Information-theoretic generalization bounds for stochastic gradient descent. In Proceedings of the Conference on Learning Theory, Boulder, CO, USA, 15–19 August 2021; pp. 3526–3545. [Google Scholar]
- Negrea, J.; Haghifam, M.; Dziugaite, G.K.; Khisti, A.; Roy, D.M. Information-theoretic generalization bounds for SGLD via data-dependent estimates. Adv. Neural Inf. Process. Syst. 2019, 32, 11015–11025. [Google Scholar]
- Haghifam, M.; Dziugaite, G.K.; Moran, S.; Roy, D. Towards a unified information-theoretic framework for generalization. Adv. Neural Inf. Process. Syst. 2021, 34, 26370–26381. [Google Scholar]
- Du, S.S.; Kakade, S.M.; Wang, R.; Yang, L.F. Is a good representation sufficient for sample efficient reinforcement learning? arXiv 2019, arXiv:1910.03016. [Google Scholar]
- Weisz, G.; Amortila, P.; Szepesvári, C. Exponential lower bounds for planning in mdps with linearly-realizable optimal action-value functions. In Proceedings of the Algorithmic Learning Theory, Virtual, 16–19 March 2021; pp. 1237–1264. [Google Scholar]
- Wang, Y.; Wang, R.; Kakade, S. An exponential lower bound for linearly realizable mdp with constant suboptimality gap. Adv. Neural Inf. Process. Syst. 2021, 34, 9521–9533. [Google Scholar]
- Munos, R.; Szepesvári, C. Finite-Time Bounds for Fitted Value Iteration. J. Mach. Learn. Res. 2008, 9, 815–857. [Google Scholar]
- Farahmand, A.; Ghavamzadeh, M.; Mannor, S.; Szepesvári, C. Regularized policy iteration. Adv. Neural Inf. Process. Syst. 2008, 21, 441–448. [Google Scholar]
- Zanette, A.; Lazaric, A.; Kochenderfer, M.; Brunskill, E. Learning near optimal policies with low inherent bellman error. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 10978–10989. [Google Scholar]
- Lazaric, A.; Ghavamzadeh, M.; Munos, R. Finite-sample analysis of least-squares policy iteration. J. Mach. Learn. Res. 2012, 13, 3041–3074. [Google Scholar]
- Farahm, A.M.; Ghavamzadeh, M.; Szepesvári, C.; Mannor, S. Regularized policy iteration with nonparametric function spaces. J. Mach. Learn. Res. 2016, 17, 1–66. [Google Scholar]
- Le, H.; Voloshin, C.; Yue, Y. Batch policy learning under constraints. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 3703–3712. [Google Scholar]
- Chen, J.; Jiang, N. Information-theoretic considerations in batch reinforcement learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 1042–1051. [Google Scholar]
- Wang, R.; Foster, D.P.; Kakade, S.M. What are the statistical limits of offline RL with linear function approximation? arXiv 2020, arXiv:2010.11895. [Google Scholar]
- Xie, T.; Jiang, N. Batch value-function approximation with only realizability. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11404–11413. [Google Scholar]
- Foster, D.J.; Kakade, S.M.; Qian, J.; Rakhlin, A. The statistical complexity of interactive decision making. arXiv 2021, arXiv:2112.13487. [Google Scholar]
- Asadi, A.; Abbe, E.; Verdú, S. Chaining mutual information and tightening generalization bounds. Adv. Neural Inf. Process. Syst. 2018, 31, 7245–7254. [Google Scholar]
- Hafez-Kolahi, H.; Golgooni, Z.; Kasaei, S.; Soleymani, M. Conditioning and processing: Techniques to improve information-theoretic generalization bounds. Adv. Neural Inf. Process. Syst. 2020, 33, 16457–16467. [Google Scholar]
- Bu, Y.; Zou, S.; Veeravalli, V.V. Tightening mutual information-based bounds on generalization error. IEEE J. Sel. Areas Inf. Theory 2020, 1, 121–130. [Google Scholar] [CrossRef]
- Lopez, A.T.; Jog, V. Generalization error bounds using Wasserstein distances. In Proceedings of the 2018 IEEE Information Theory Workshop (ITW), Guangzhou, China, 25–29 November 2018; pp. 1–5. [Google Scholar]
- Wang, H.; Diaz, M.; Santos Filho, J.C.S.; Calmon, F.P. An information-theoretic view of generalization via Wasserstein distance. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 577–581. [Google Scholar]
- Aminian, G.; Toni, L.; Rodrigues, M.R. Information-theoretic bounds on the moments of the generalization error of learning algorithms. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Virtual, 12–20 July 2021; pp. 682–687. [Google Scholar]
- Aminian, G.; Masiha, S.; Toni, L.; Rodrigues, M.R. Learning algorithm generalization error bounds via auxiliary distributions. IEEE J. Sel. Areas Inf. Theory 2024, 5, 273–284. [Google Scholar] [CrossRef]
- Pensia, A.; Jog, V.; Loh, P.L. Generalization error bounds for noisy, iterative algorithms. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 546–550. [Google Scholar]
- Haghifam, M.; Negrea, J.; Khisti, A.; Roy, D.M.; Dziugaite, G.K. Sharpened generalization bounds based on conditional mutual information and an application to noisy, iterative algorithms. Adv. Neural Inf. Process. Syst. 2020, 33, 9925–9935. [Google Scholar]
- Harutyunyan, H.; Raginsky, M.; Ver Steeg, G.; Galstyan, A. Information-theoretic generalization bounds for black-box learning algorithms. Adv. Neural Inf. Process. Syst. 2021, 34, 24670–24682. [Google Scholar]
- Wang, H.; Gao, R.; Calmon, F.P. Generalization bounds for noisy iterative algorithms using properties of additive noise channels. J. Mach. Learn. Res. 2023, 24, 1–43. [Google Scholar]
- He, H.; Yu, C.L.; Goldfeld, Z. Information-Theoretic Generalization Bounds for Deep Neural Networks. arXiv 2024, arXiv:2404.03176. [Google Scholar]
- He, H.; Hanshu, Y.; Tan, V. Information-theoretic generalization bounds for iterative semi-supervised learning. In Proceedings of the The Tenth International Conference on Learning Representations, Virtual, 25 April 2022. [Google Scholar]
- Wu, X.; Manton, J.H.; Aickelin, U.; Zhu, J. On the generalization for transfer learning: An information-theoretic analysis. IEEE Trans. Inf. Theory 2024, 70, 7089–7124. [Google Scholar] [CrossRef]
- Jose, S.T.; Simeone, O. Information-theoretic generalization bounds for meta-learning and applications. Entropy 2021, 23, 126. [Google Scholar] [CrossRef]
- Chen, Q.; Shui, C.; Marchand, M. Generalization bounds for meta-learning: An information-theoretic analysis. Adv. Neural Inf. Process. Syst. 2021, 34, 25878–25890. [Google Scholar]
- Chu, Y.; Raginsky, M. A unified framework for information-theoretic generalization bounds. Adv. Neural Inf. Process. Syst. 2023, 36, 79260–79278. [Google Scholar]
- Alabdulmohsin, I. Towards a unified theory of learning and information. Entropy 2020, 22, 438. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X. Information-Theoretic Generalization Bounds for Batch Reinforcement Learning. Entropy 2024, 26, 995. https://doi.org/10.3390/e26110995
Liu X. Information-Theoretic Generalization Bounds for Batch Reinforcement Learning. Entropy. 2024; 26(11):995. https://doi.org/10.3390/e26110995
Chicago/Turabian StyleLiu, Xingtu. 2024. "Information-Theoretic Generalization Bounds for Batch Reinforcement Learning" Entropy 26, no. 11: 995. https://doi.org/10.3390/e26110995
APA StyleLiu, X. (2024). Information-Theoretic Generalization Bounds for Batch Reinforcement Learning. Entropy, 26(11), 995. https://doi.org/10.3390/e26110995