1. Introduction
The primary objective of complex time series analysis is to classify and identify signals by extracting their distinctive features or patterns. To perform this task, entropy-based methods, which enhance the understanding of underlying dynamics, have garnered more and more attention in recent years [
1,
2]. These methods have been successfully applied across various complex engineering domains, including electrocardiogram (ECG) and electroencephalographic (EEG) records analysis [
3,
4,
5], bearing fault diagnosis [
6], and underwater target recognition [
7,
8].
The prevalent entropy metrics can be broadly classified into two main categories: those that are conditional entropy-based and those that are Shannon entropy-based. The former includes widely used methods such as Approximate Entropy (ApEn) [
9], Sample Entropy (SampEn) [
10], and Fuzzy Entropy (FuzzyEn) [
11]. The core of these measures is to compare the probabilities of similar patterns occurring in
dimensional and
dimensional phase spaces to infer the emergence of new patterns. Pattern similarity is determined by whether the distance between vectors falls below a predefined threshold. For example, if
and
, where
represents the distance between
and
, and
is a constant, it suggests the emergence of a new pattern when the embedding dimension is enlarged from
to
. Generally, the more components and complexity within a time series, the higher the probability of new patterns emerging, resulting in a higher entropy value. The main drawback of the aforementioned methods lies in their requirement for extensive distance calculation within the phase space, which results in high computational complexity. Furthermore, when dealing with short data sequences, these methods are prone to generate undefined entropy values.
Without being exhaustive, Shannon entropy-based approaches include Permutation Entropy (PE) [
12], Distribution Entropy (DistEn) [
13], Weighted Permutation Entropy (WPE) [
14], Modified Permutation Entropy (mPE) [
15], Dispersion Entropy (DispEn) [
16], Slope entropy (SlopEn) [
17], and Attention Entropy (AE) [
18], among others. Permutation entropy, introduced by Bandt et al. [
12] estimates probability density based on the frequency of ordinal patterns (OP). Its conceptual simplicity and computational efficiency have quickly made it one of the most prominent entropy algorithms [
2,
17,
19,
20]. Subsequently, WPE was proposed to address the limitation of PE in neglecting absolute amplitude information. In WPE, weights are assigned to each OP to calculate the weighted probability density [
14]. Bian and the coauthors addressed the distortion in PE estimation that can occur under low-resolution conditions. They accomplished this by mapping equal values within sub-sequences to the same symbol and then calculating the probability distribution of the resulting symbolic patterns [
15]. In 2016, Rostaghi et al. [
16] developed DispEn, which estimates entropy by calculating the probability density of newly designed symbolic patterns known as dispersion patterns. Compared to PE and its variants, DispEn demonstrates a superior ability to distinguish complex time series [
16,
19,
20]. In 2019, Cuesta-Frau invented SlopEn, which utilizes a new encoding technique based on the gradient between two consecutive sample points [
17]. However, a key challenge with SlopEn is the lack of theoretical guidance for determining certain parameters, which may affect the algorithm’s effectiveness. Unlike PE, DispEn, and SlopEn, AE exclusively focuses on the frequency distribution of intervals between key observations in a time series, such as the intervals between local maxima [
18]. This parameter-free approach demonstrates promising potential in the analysis of heart rate signals. In summary, the primary differences among these Shannon entropy-based algorithms are rooted in their approaches to estimating the probability density distribution of time series.
Entropy metrics are still continually evolving, with researchers exploring various strategies to enhance their capacity to analyze complex time series. Recognizing that real-world data often exhibit intricate structures across multiple temporal scales, Costa et al. proposed integrating entropy quantification methods with coarse-graining techniques, leading to the development of Multiscale Entropy (MSE) [
21]. This innovative approach has been widely adopted by scholars and has become a vital tool for analyzing practical engineering data [
22,
23]. Additionally, some researchers have developed complexity-entropy plane algorithms [
24,
25,
26,
27,
28,
29,
30,
31,
32,
33], which map time series onto a two-dimensional plane as points or curves, thereby improving the discriminability of entropy features. However, it is important to note that the effectiveness of both Multiscale Entropy and complexity-entropy plane approaches is still influenced by the choice of entropy measure employed.
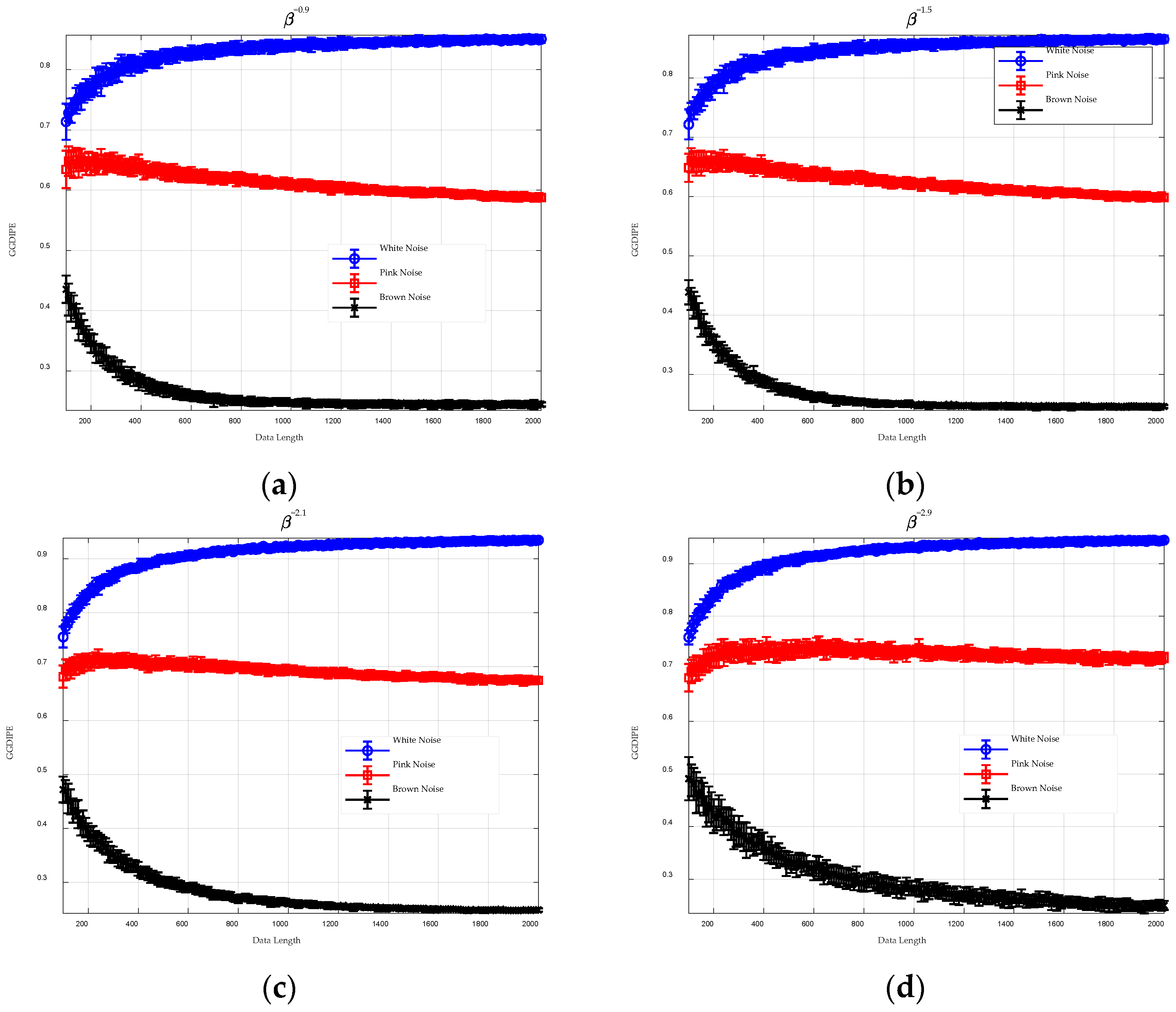
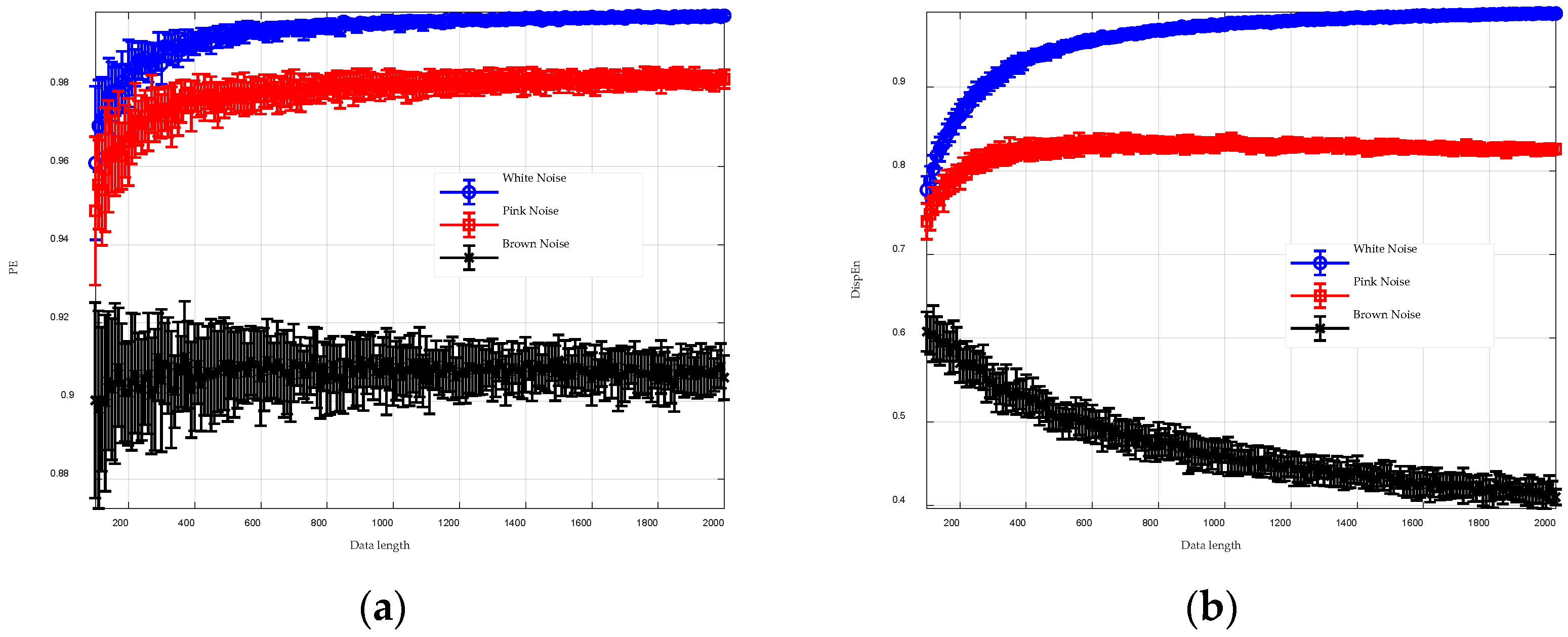
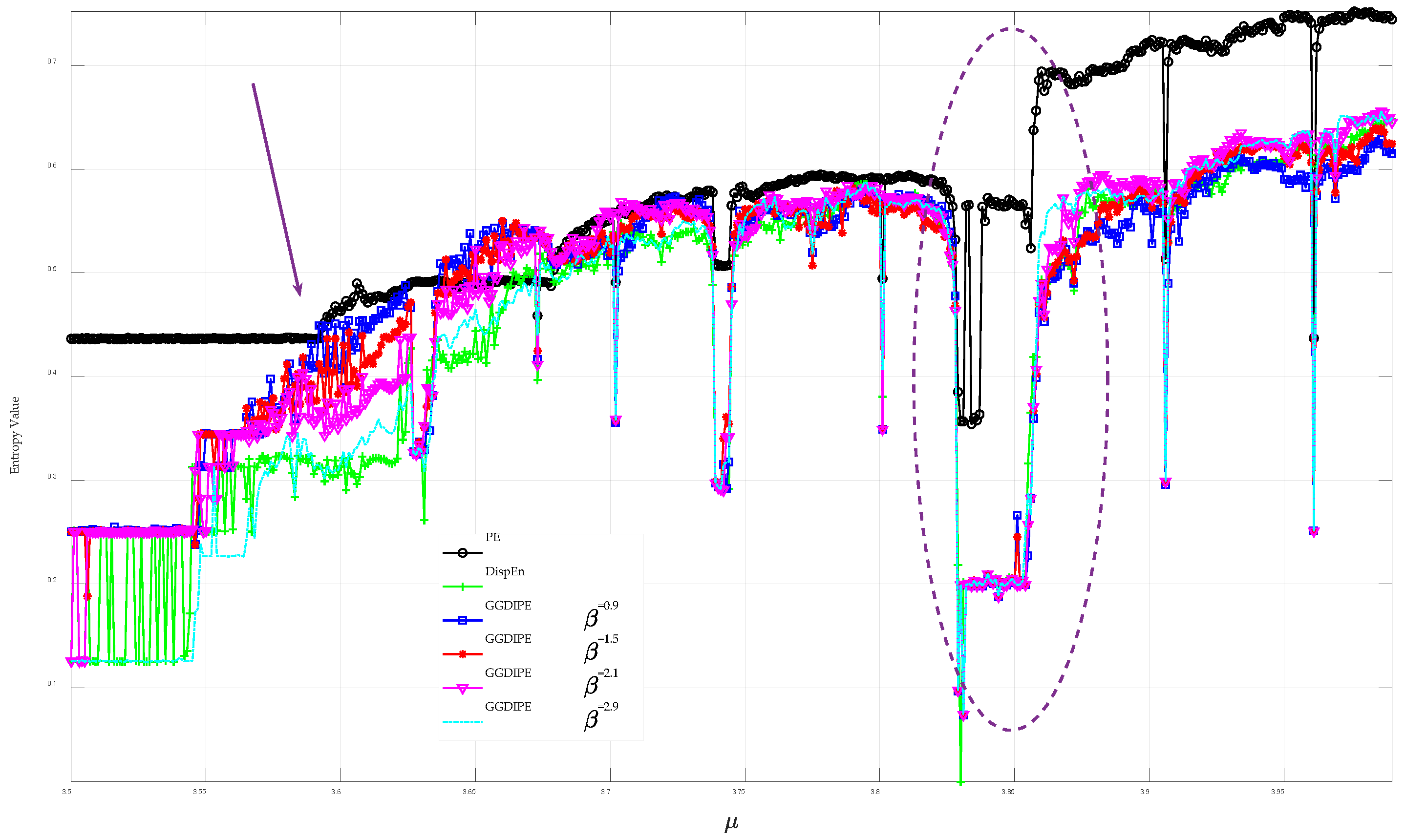
This highlights that traditional entropy algorithms possess unique advantages and limitations. The effectiveness of newer methods, such as DispEn, SlopEn, and AE, in various complex engineering applications has not yet been fully established. To address this gap, this paper presents a new entropy measure known as Generalized Gaussian Distribution Improved Permutation Entropy (GGDIPE). Firstly, the generalized Gaussian distribution cumulative distribution function (GGDCDF) with a specific shape parameter is employed for data normalization. This technique ensures that our method is adaptable to a range of time series with different underlying distributions. Secondly, a new encoding approach for generating symbolic patterns is presented. This strategy combines the strengths of SampEn, PE, and its modifications, effectively preserving both temporal correlation and absolute amplitude information. Moreover, it resolves the issue of equal values that is encountered in PE. Finally, the probability density of our newly designed symbolic patterns is calculated, and the GGDIPE is derived based on Shannon entropy. To enhance the proposed algorithm’s capability in handling complex time series, this paper also introduces a multiscale version of GGDIPE that utilizes the coarse-graining technique.
The remainder of this paper is organized as follows: a detailed description of GGDIPE is provided in
Section 2; synthetic and experimental data processing results are demonstrated and discussed in
Section 3 and
Section 4, respectively; the paper is concluded in
Section 5.
2. GGDIPE
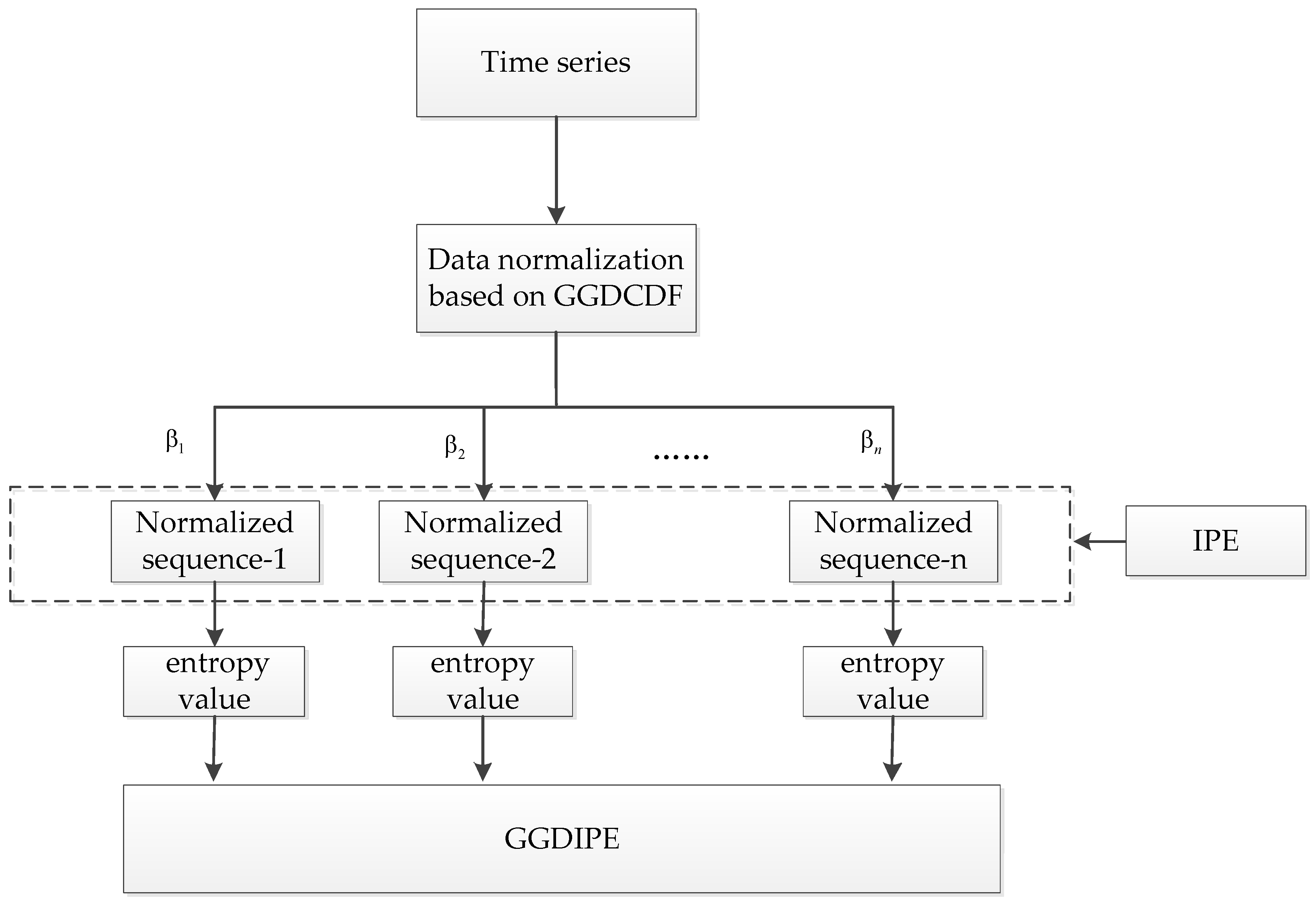
As illustrated in
Figure 1, the proposed GGDIPE is developed through a series of steps: data normalization, improved permutation entropy (IPE) calculation, and the integration of entropy feature vectors. Each of these processes is described in detail in the following subsections. Additionally, a numerical example is provided in
Appendix B to enhance clarity.
2.1. Data Normalization
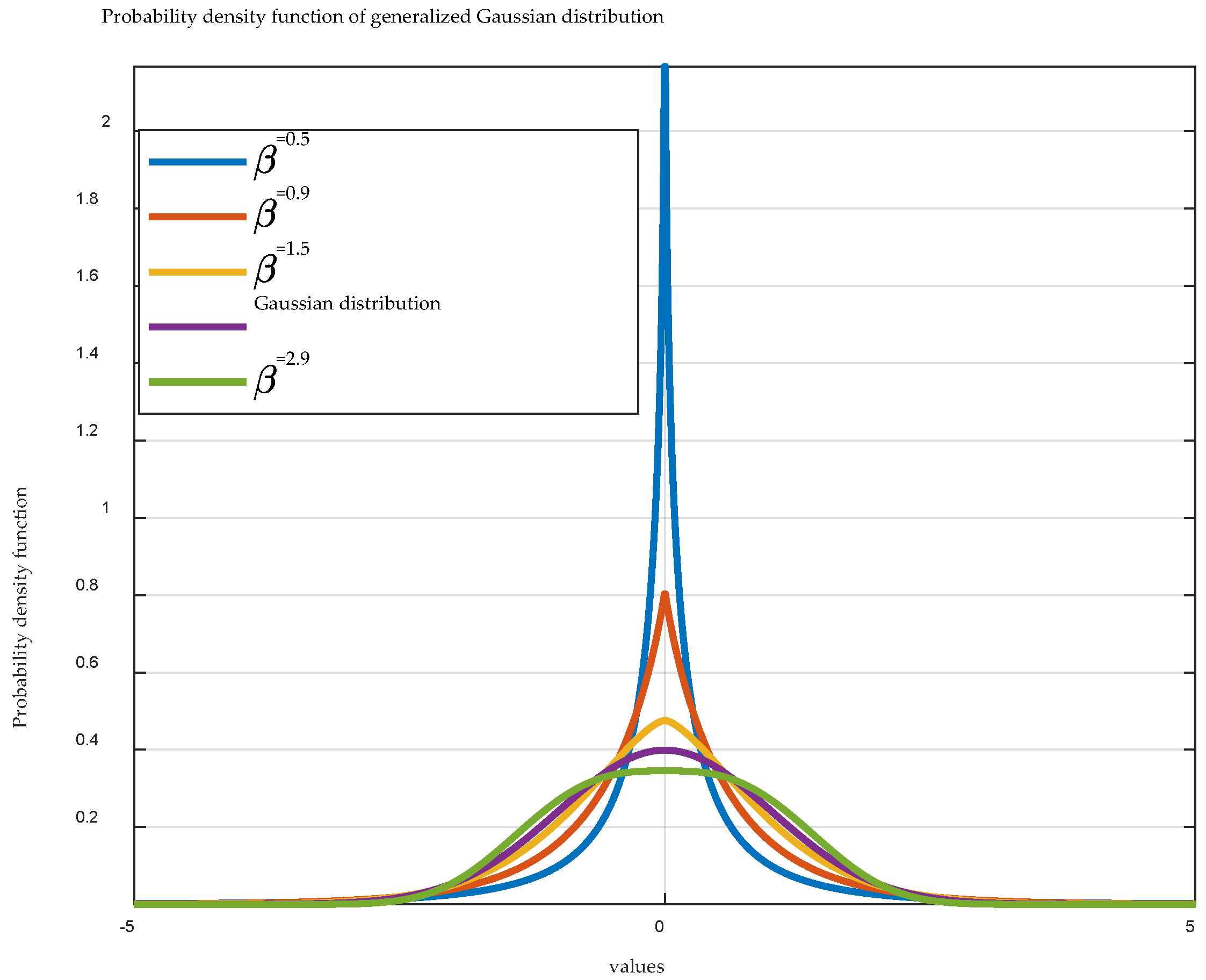
The benefits of data normalization are well established in numerous engineering applications. DispEn’s strong data processing capabilities can be partially attributed to its use of the Gaussian cumulative distribution function for normalization. However, real-world data often deviates from Gaussian distributions. To address this issue, the GGDCDF with various shape parameters are employed for data normalization in this paper. This approach ensures that our method is adaptable to a wide range of time series with different underlying distributions.
As shown in Equation (1), given a shape parameter
and a time series
, the GGDCDF will transform
into a new sequence
, where the elements of
range from 0 to 1.
In Equation (1),
represents the Sign Function, as shown in Equation (2).
denotes the average of
;
stands for the famous gamma function;
, with
the standard deviation of
; and
denotes the lower incomplete gamma function. Obviously, an element
represents the probability that a random variable from the Generalized Gaussian Distribution (GGD) is less than
. The GGD can be tailored to different forms by varying the shape parameter
. Specifically, when
, the GGD approximates a normal distribution, whereas when
, it transforms into a uniform distribution [
34]. A brief introduction to GGD can be found in
Appendix B.
2.2. IPE
The IPE employs a new encoding strategy for generating symbolic patterns. Let be the normalized time series under , the data is first segmented into several dimensional vectors, with the j-th vector denoted as , . This process is also known as phase space reconstruction, and is called the embedding dimension.
To incorporate the absolute amplitude information of
, the first element of the
j-th
dimensional vector
is symbolized using a Linear partition operator (LPO), as shown in Equation (3), yielding
. Herein,
and
represent the minimum and maximum values of
, respectively.
corresponds to the number of symbols used to characterize the time series, and
. In fact, the role of
in our algorithm is analogous to the tolerance
in SampEn. In SampEn, two vectors are considered similar if
. Similarly, in our algorithm,
and
are assigned the same symbol if they fall within the same region. For example, if
and
, the symbol 0 will be assigned to both
and
. As will be shown in
Section 3, a smaller
increases information loss during symbolization, reducing the precision of entropy estimation but enhancing noise resistance. Conversely, a larger
minimizes information loss and leads to more accurate entropy estimation. In summary, selecting
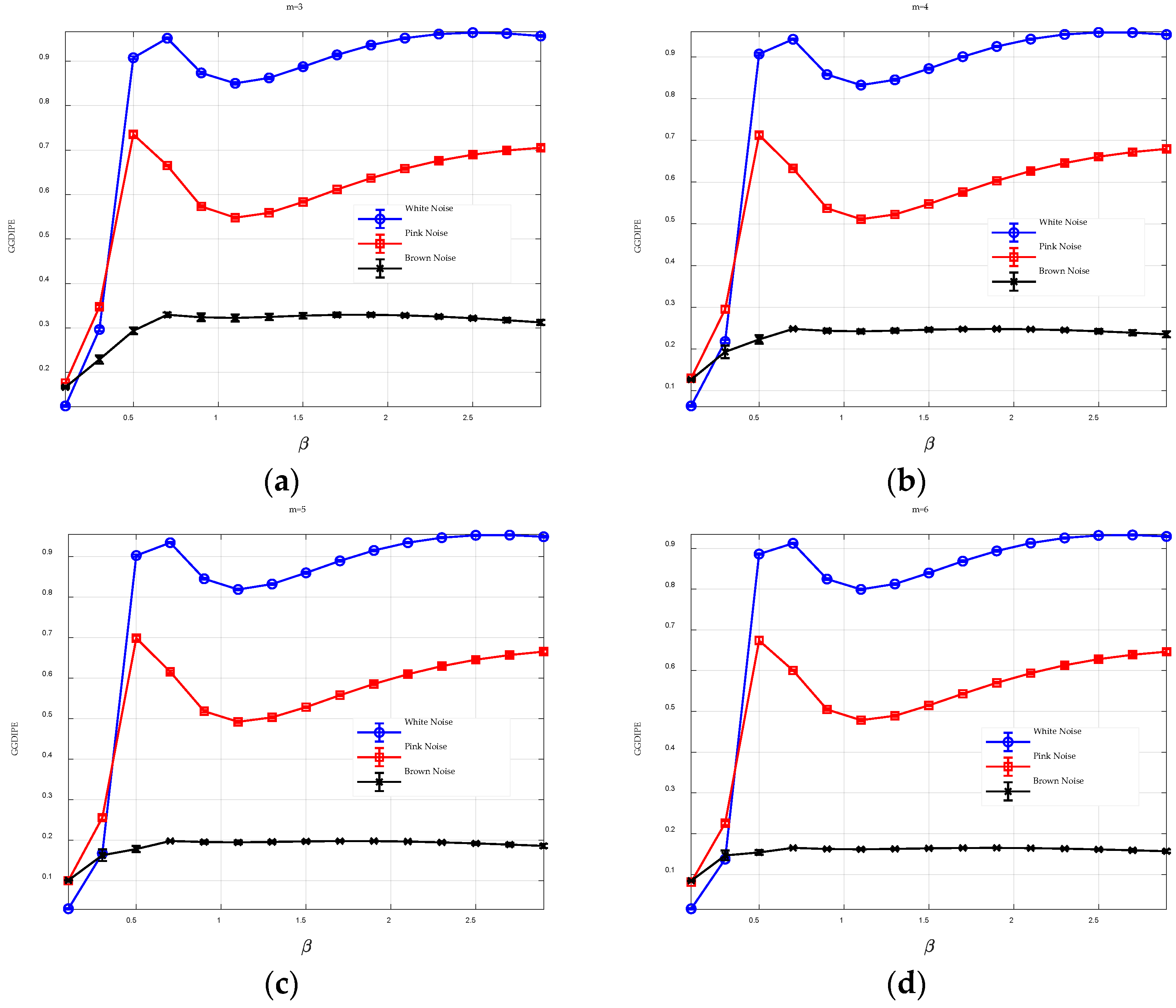
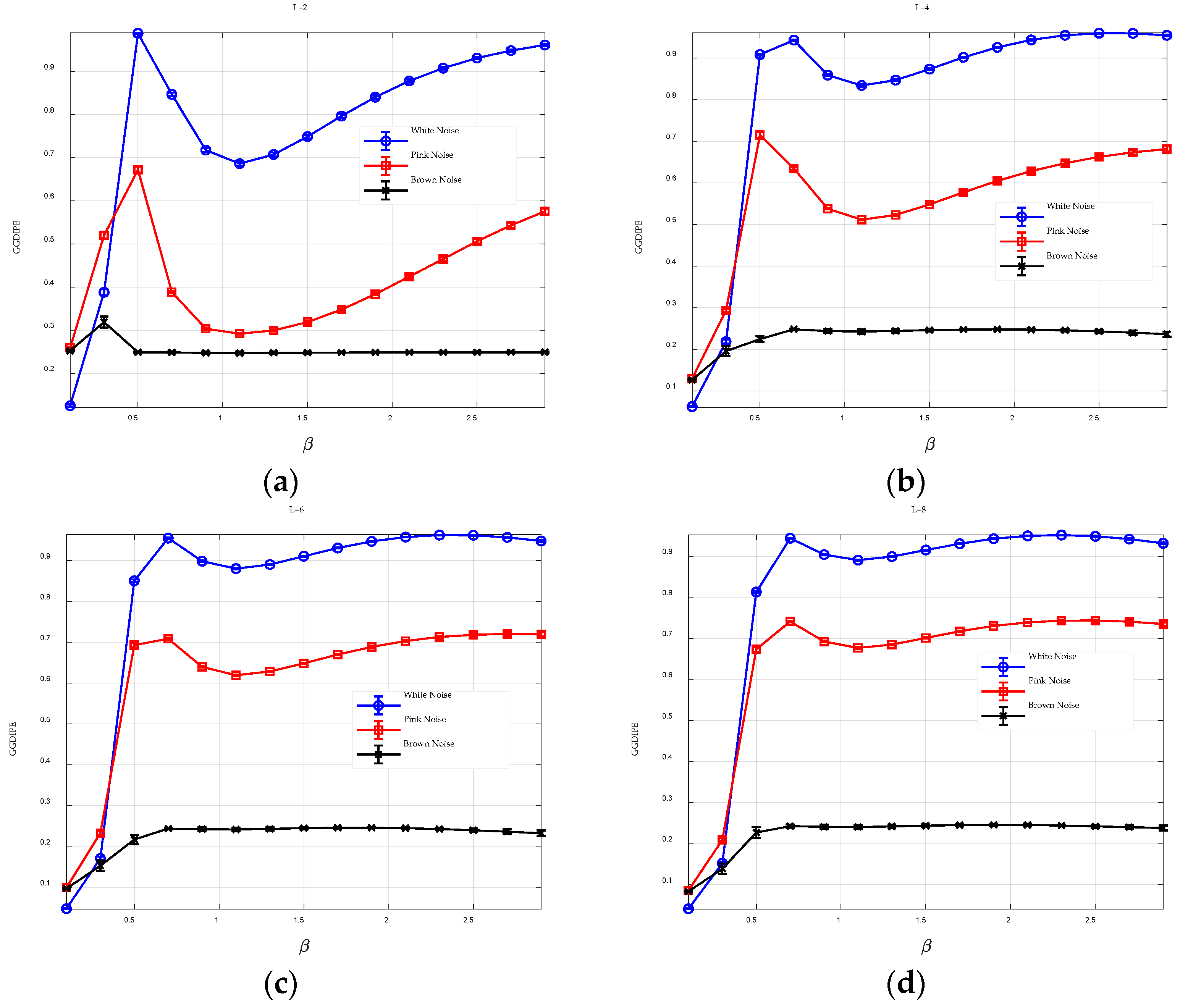
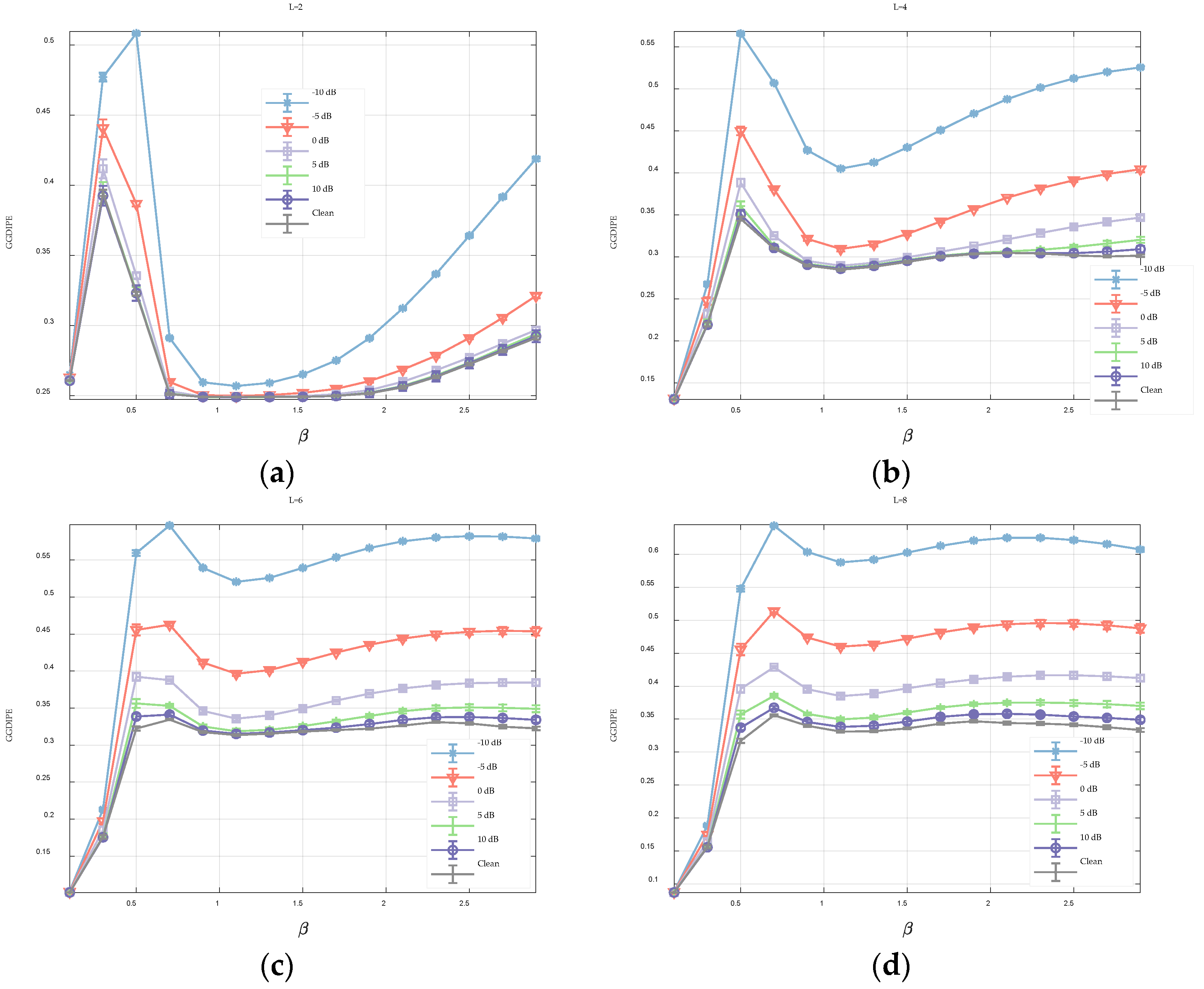
requires a balance between the accuracy of entropy estimation and the robustness to noise.
To take into account the temporal correlation information, the
k-th (
) element of the
j-th vector, represented by
, is symbolized by Equation (4), yielding
. The function ⌊ ⌋ returns the largest integer less than or equal to the input. Evidently,
is derived from
and the difference between
and
. Similar to OP, temporal correlation information is encoded into
through comparing the two points.
After symbolization, each
dimensional vector is mapped to a symbol pattern, denoted as
,
,
. There are
underlying symbol patterns in the IPE algorithm. The probability of each symbol pattern
(
) is then counted, and the IPE is finally calculated using Equation (5), where
denotes the largest IPE value.
In comparison to PE and its variants, IPE preserves both absolute amplitude and temporal correlation information and utilizes a larger set of potential symbolic patterns to characterize the signal. This suggests that IPE is likely to achieve better signal differentiation. Additionally, the symbolization process described in Equations (3) and (4) minimizes the need for extensive handling of equal values in the sequence, effectively addressing the equal value issue present in PE.
2.3. Entropy Feature Vector Integration
Section 2.2 outlines the process for calculating IPE with a specific shape parameter
. As previously mentioned, the shape parameter determines the form of the GGD, enabling it to adapt to signals with varying distributions. In accordance with the recommendations in [
34], in this paper,
is incremented from 0.1 to 2.9 in steps of 0.2. The IPE is computed for each value of
, and the resulting entropy values are combined into a 1 × 15 entropy feature vector, yielding the GGDIPE.
2.4. Multiscale GGDIPE
To enhance GGDIPE’s capability in handling complex time series, a multiscale version of GGDIPE is also proposed. Let
be the time series to be analyzed. The coarse-graining technique is employed to decompose the signal into multiple subsequences, as shown in Equation (6), where
denotes the scale factor,
represents the
i-th element of the subsequence under scale
, and
. It is important to note that as the scale factor increases, the length of subsequence decreases to
, leading to potential instability in entropy estimation. Therefore, the scale factor should be carefully chosen based on the length of the original time series being analyzed.
After coarse-graining, GGDIPE is applied to each subsequence. Assuming the maximum scale factor is
, the Multiscale Generalized Gaussian Distribution Improved Permutation Entropy (MGGDIPE) is ultimately represented as a
entropy feature matrix.
5. Conclusions
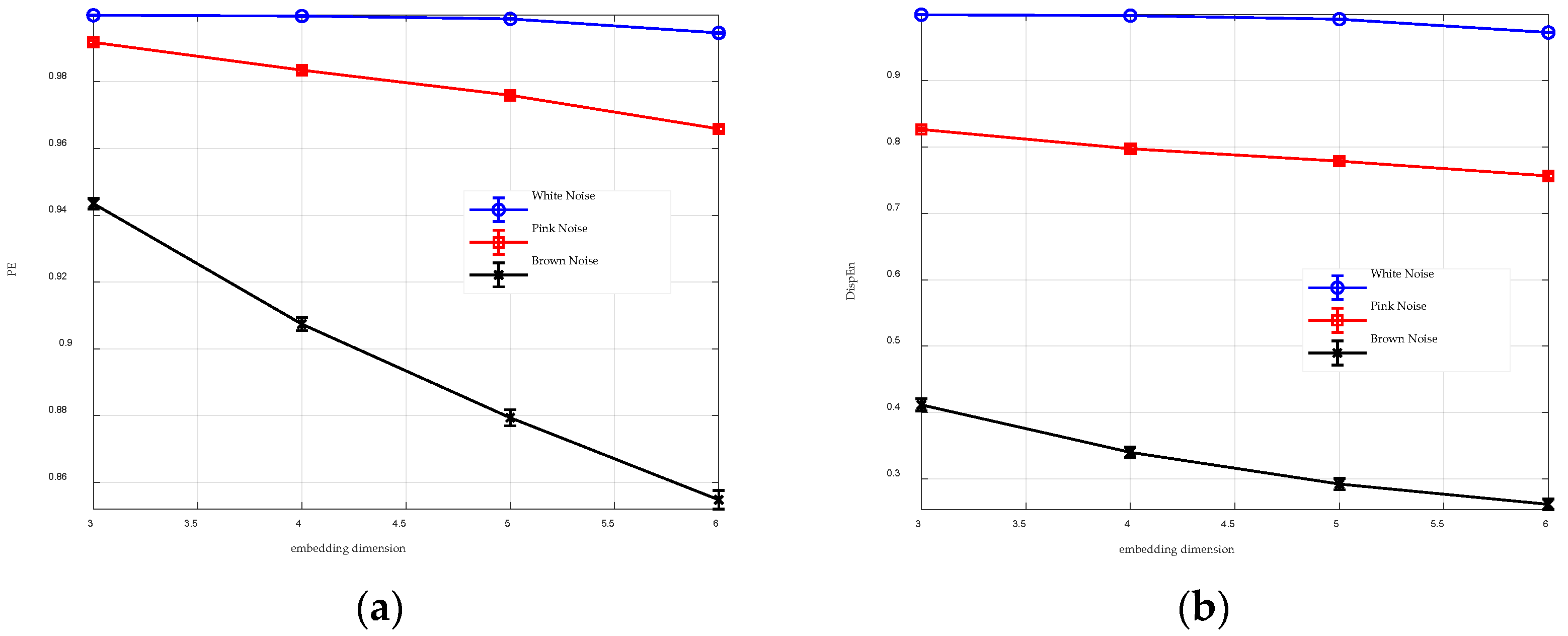
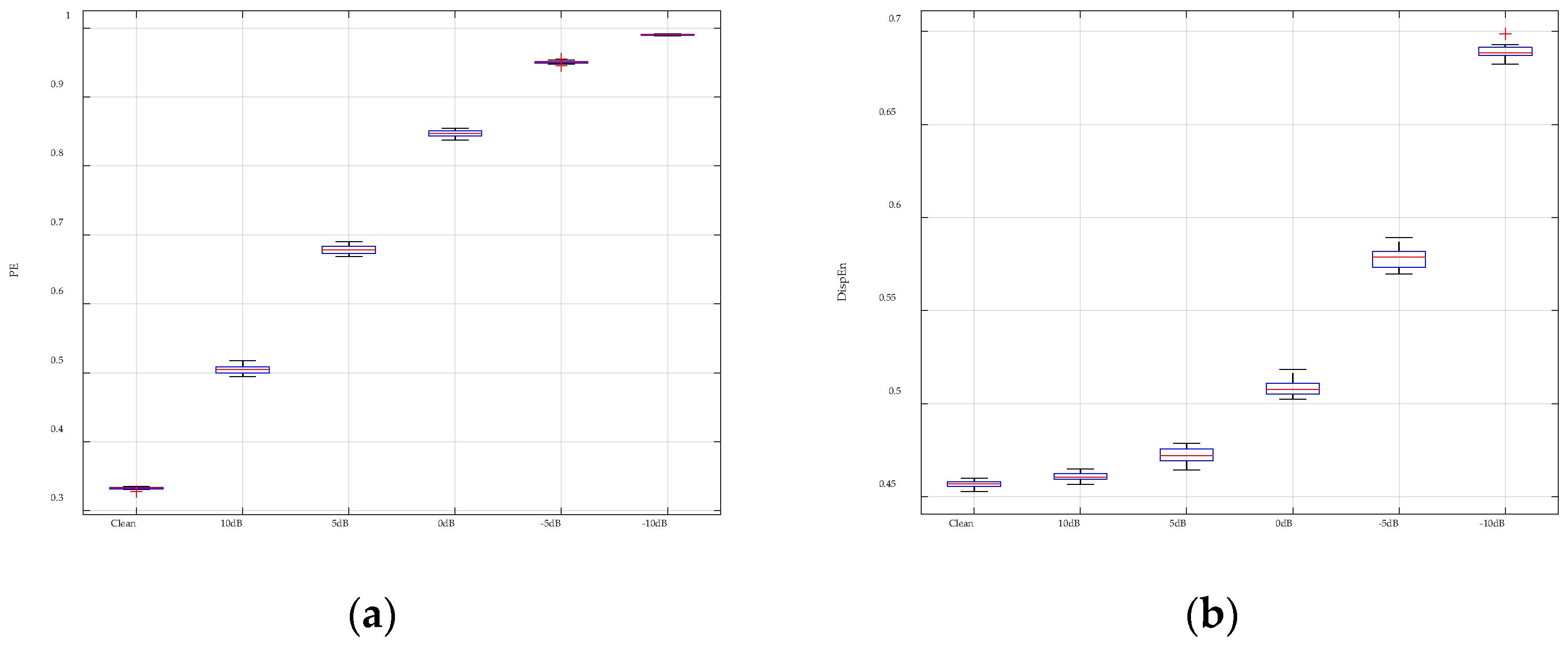
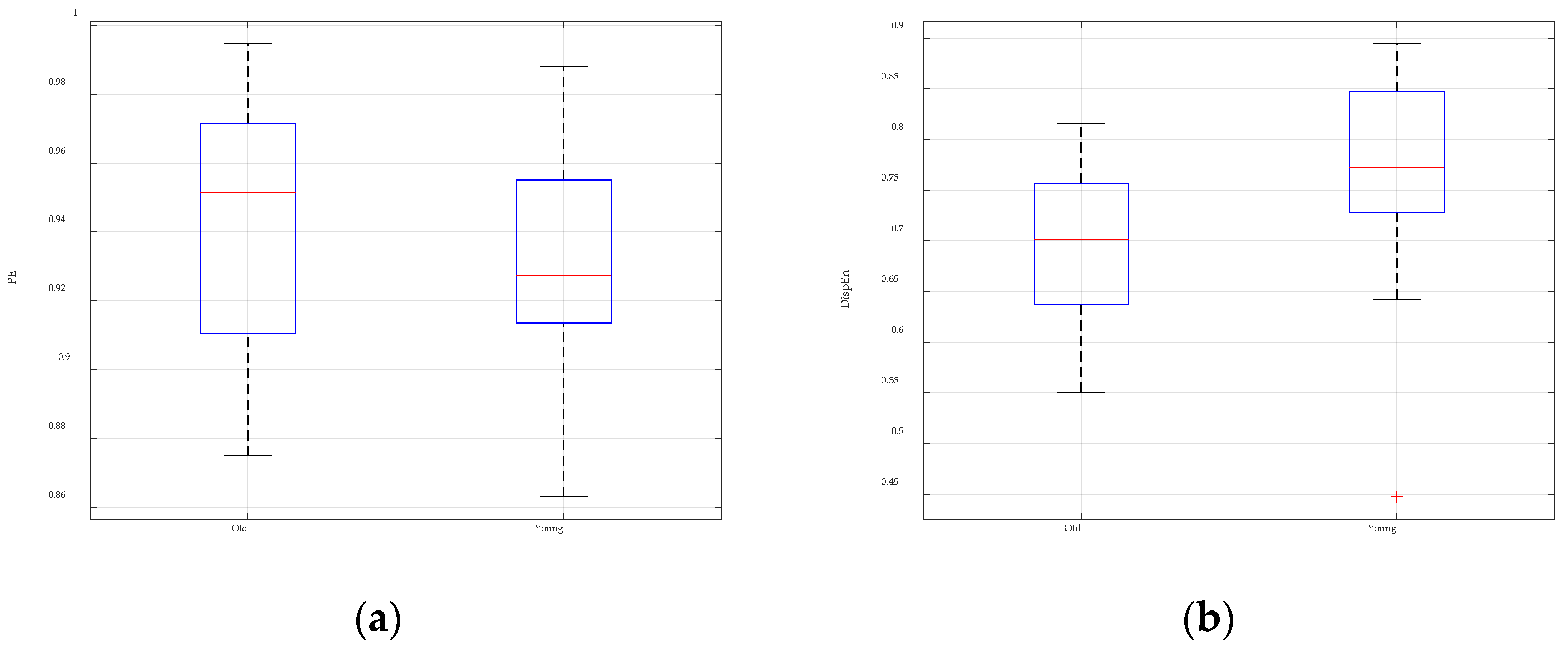
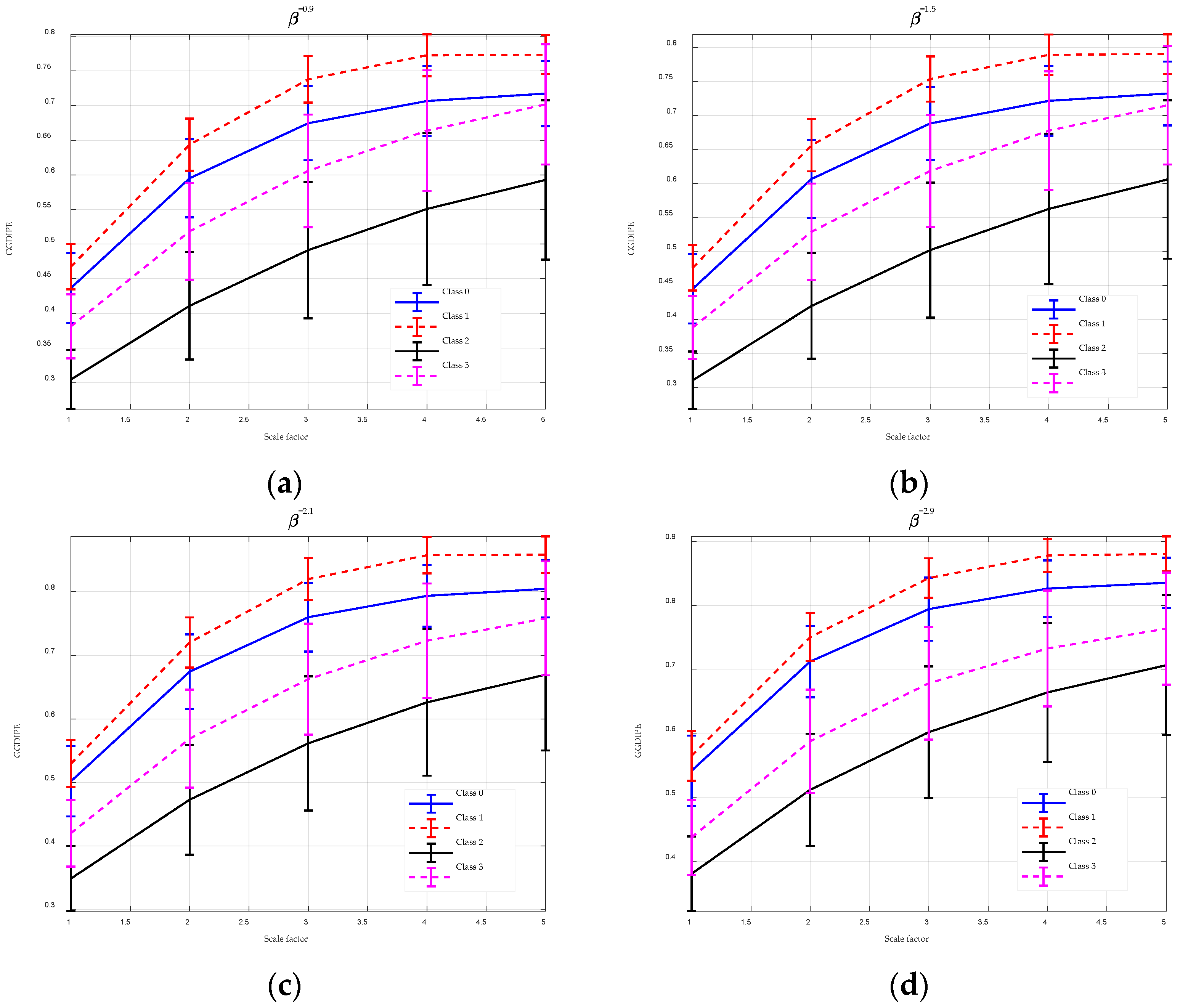
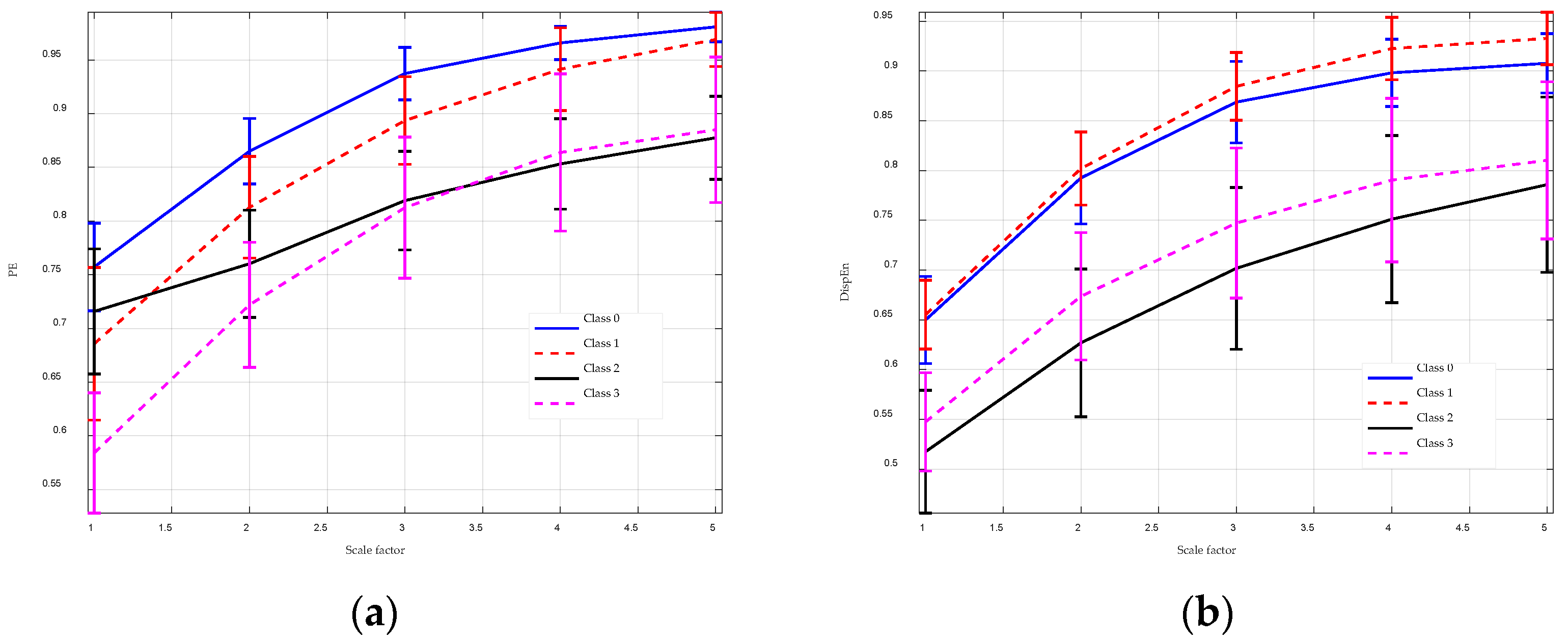
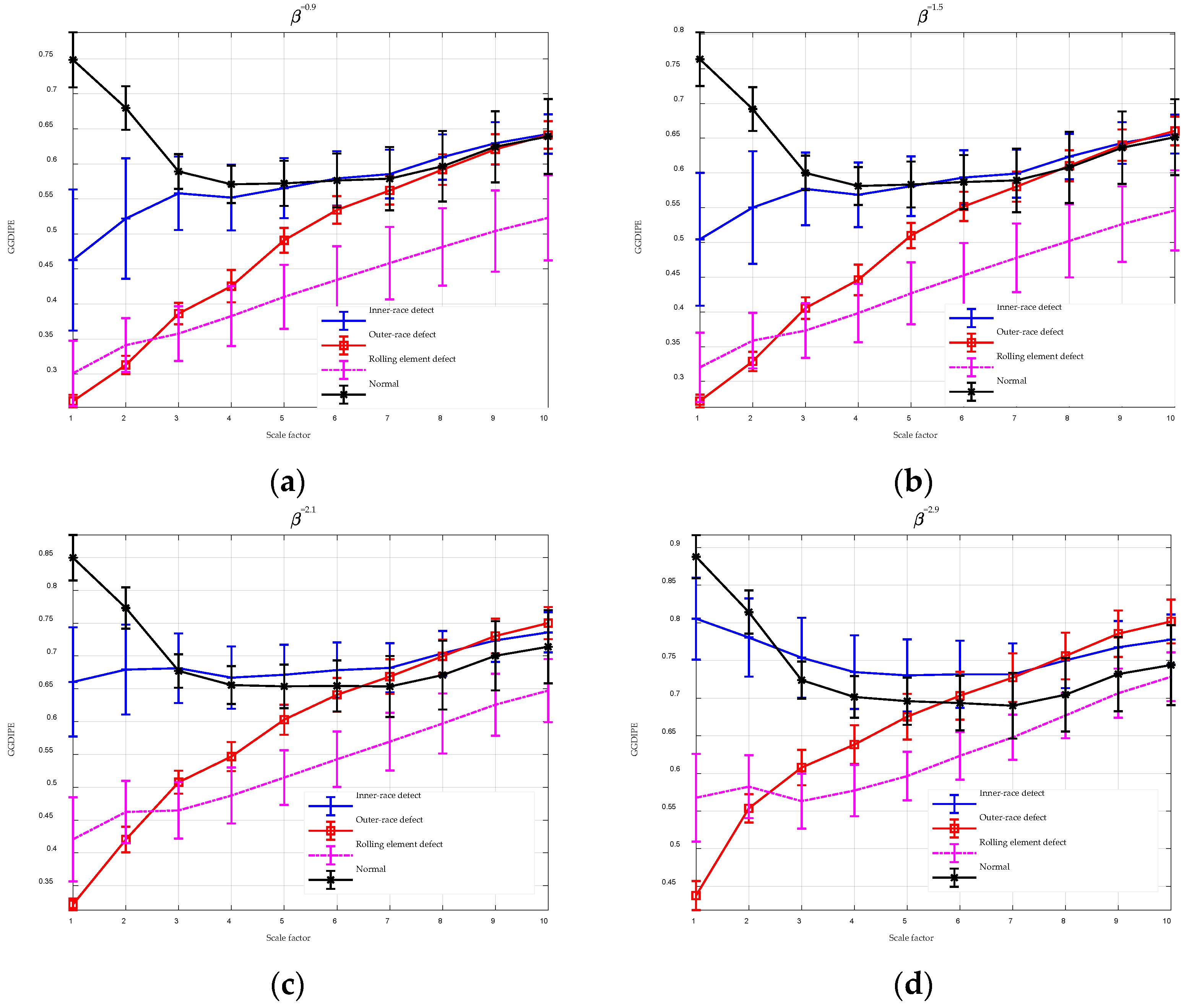
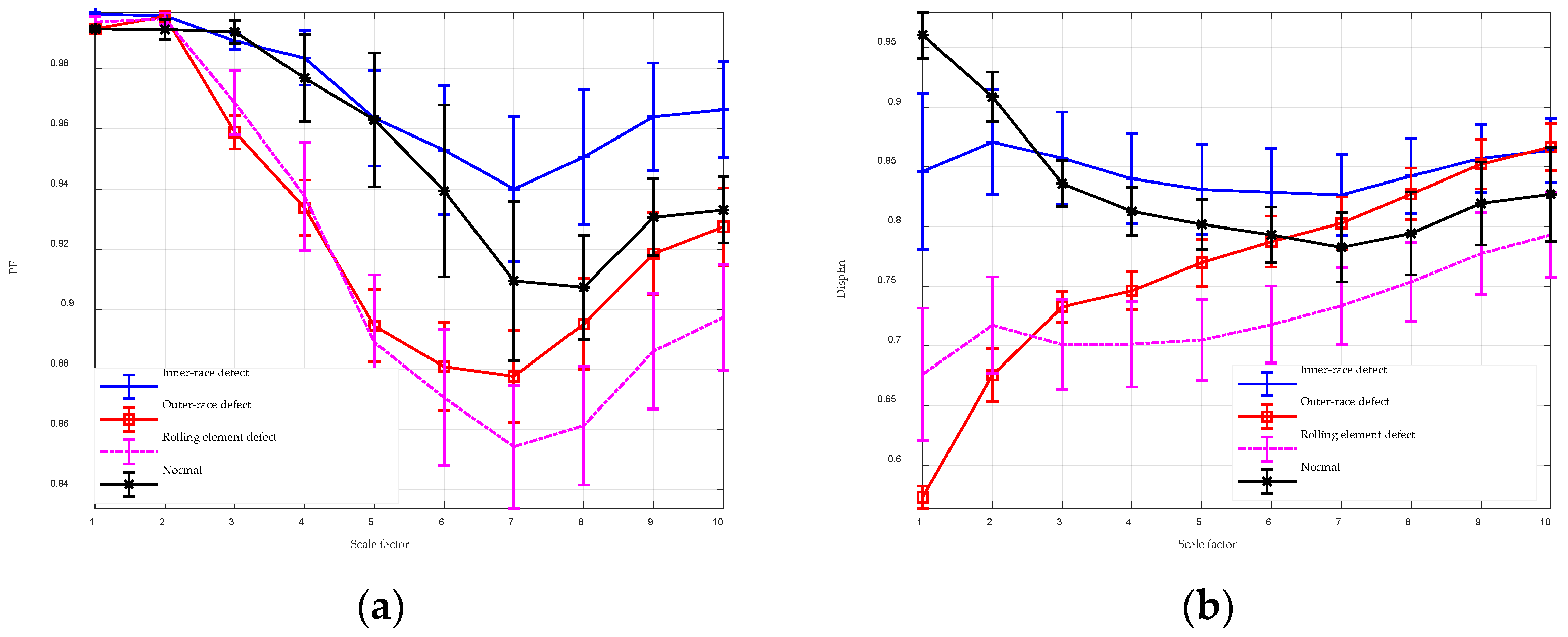
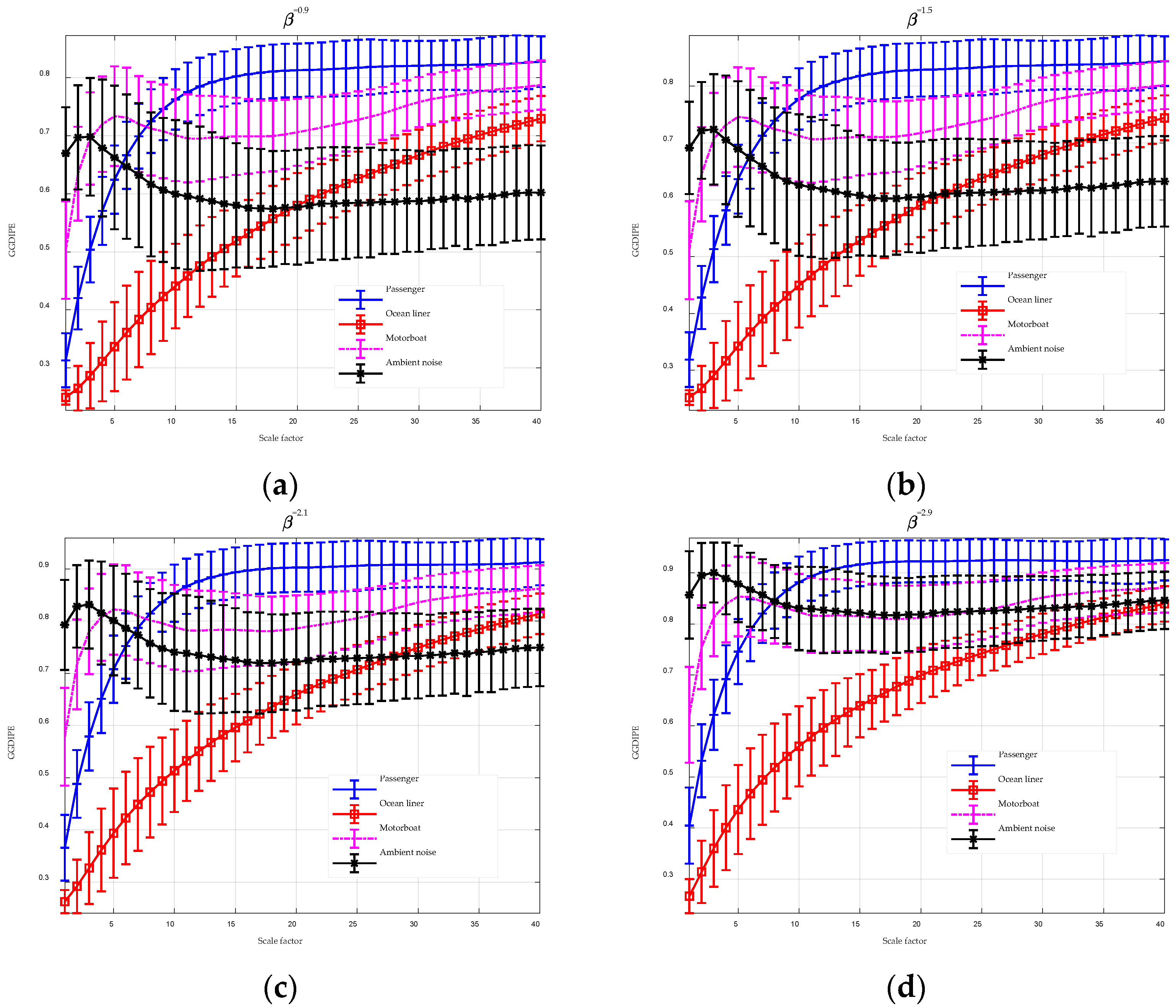
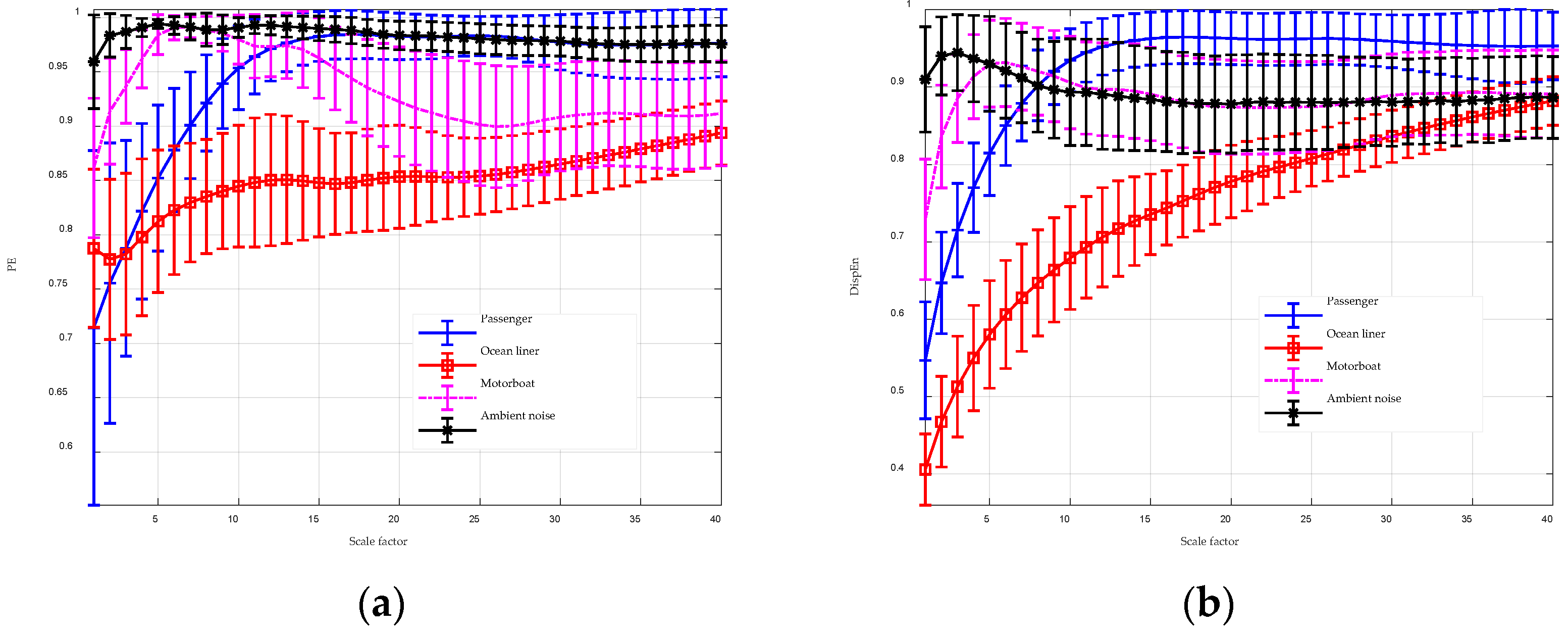
To enhance the performance of entropy algorithms in analyzing complex time series, this paper introduces the GGDIPE algorithm and its multiscale variant. GGDIPE employs the GGDCDF for data normalization, making it versatile across various distributions. The algorithm further processes the normalized data with the IPE approach, which maintains both the absolute magnitude and temporal correlations of the signals, overcoming the equal value issue found in traditional PE. Simulation results indicate that GGDIPE is less sensitive to parameter variations, exhibits strong noise resistance, accurately reveals the dynamic behavior of chaotic systems, and operates significantly faster than PE, with speed comparable to DispEn. Real-world data analysis shows that MGGDIPE provides markedly better separability for RR interval signals, EEG signals, bearing fault signals, and underwater acoustic signals compared to conventional MPE and the recently proposed MDE algorithm. Notably, in underwater target recognition tasks, MGGDIPE achieved a classification accuracy of 97.5% across four types of acoustic signals, substantially surpassing the performance of MDE (70.5%) and MPE (62.5%). Thus, the proposed method demonstrates exceptional capability in processing complex time series data.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}