1. Introduction
As the most prominent component of the energy system, the production and optimal use of electrical energy is of vital importance, and large steam turbines serve as essential conversion devices in turbine power systems. Therefore, the reliability of large steam turbines is the main maintenance issue of power plants and an important continuous investment project [
1]. During the operation of a steam turbine, a minor blade failure may result in a decrease in operational efficiency, while a significant failure could lead to a catastrophic incident, incurring substantial losses. It is essential that preventive measures are implemented to mitigate such risks and ensure the safe and efficient functioning of turbine systems.
Traditional manual detection relies on experience and subjective judgment, is easily affected by human factors, and has difficulty processing complex nonlinear data. In addition, studies have shown that the interaction between blades will aggravate crack propagation, and most defect-induced failures originate from fatigue crack propagation in stress concentration areas. When analyzing the classification of turbine blade crack failures, it is also necessary to consider the impact of the loading path on the classification results. The study by Y Zhang et al. [
2] explored the interaction between the initial crack size, stress, and cracks in offshore pipelines and emphasized that the interaction between cracks will accelerate crack propagation and lead to larger cracks. This study has important guiding significance for the study of turbine blade cracks.
However, deep learning can adapt to new data patterns and process large-scale high-dimensional data through automatic feature extraction and training, outperforming traditional methods. Therefore, a fault diagnosis method based on deep learning shows great potential in improving the reliability and safety of rotating machinery [
3,
4,
5]. Based on the in-depth analysis of the application value and practical significance of steam turbine blade faults, it is particularly important to optimize the fault classification algorithm and improve the accuracy of fault diagnosis.
Fault classification is a crucial link in the fault diagnosis process, and selecting appropriate classification algorithms is significant for the identification of fault features. In recent years, research on fault identification and classification algorithms has been significantly strengthened [
6]. With the rapid development of artificial intelligence and deep learning technologies, more and more researchers have begun to apply these cutting-edge methods to the field of fault diagnosis. Various neural network-based classification algorithms, such as convolutional neural network (CNN) [
7], long short-term memory network (LSTM) [
8], and Transformer structure [
9], have demonstrated excellent performance in fault classification, significantly improving accuracy and robustness. Particularly, the introduction of the attention mechanism enables the model to effectively capture key features, thereby further improving the effect of fault diagnosis. In addition, as an emerging unsupervised learning method, contrast learning (CL) improves the model’s fault identification ability under complex working conditions by optimizing the similarity and difference between samples.
In deep neural networks, CNNs are favored for their exceptional generalization capabilities and are widely applied across various fields. Originally proposed by LeCun [
10], CNN was designed to process data with grid-like structures. Eren et al. [
11] used CNN for fault diagnosis of gearbox bearings and gears, achieving a 6% improvement in classification accuracy. To overcome the limitations of manual feature extraction, an adaptive deep CNN was developed by Wang et al. [
12] which automatically adjusts model parameters through Particle Swarm Optimization (PSO) to achieve feature learning. t-SNE was utilized for the visualization of hierarchical features, and this approach was applied to rolling bearing fault diagnosis. Dao et al. [
13] proposed a fault diagnosis model based on Bayesian Optimization (BO) which combines CNN and LSTM to diagnose turbine faults. CNN extracts features, which are then used to train LSTM. The BO algorithm is used to optimize the hyperparameter selection of the model, solving the challenge of model parameter adjustment. Although CNN performs well, it encounters the issue of gradient vanishing or exploding during deep convolution, which limits the effectiveness of fault classification. Therefore, the one-dimensional convolutional neural network (1DCNN) was proposed to simplify the architecture of traditional CNNs. It is specifically designed for processing time series data or one-dimensional signals, utilizing convolutional layers for automatic feature extraction. This makes 1DCNN particularly effective for tasks such as classification and anomaly detection, especially in the field of health monitoring. Reference [
14] proposed a rolling bearing fault diagnosis model based on adaptive modified complementary ensemble empirical mode decomposition (AMCEEMD) and 1DCNN. The selected intrinsic mode function (IMF) features were input into 1DCNN for fault classification. The results showed that the classification accuracy of the AMCEEMD-1DCNN method was better than other methods. In addition, Chen et al. [
15] proposed a deep learning model 1DCNN-BiLSTM for detecting small local structural changes of reinforced concrete (RC) beams. They applied the Inception module structure in GoogLeNet to 1DCNN, automatically extracted spatiotemporal features from the signal, and accurately identified the location of local changes. The accuracy rate in the test set reached 98.8%, demonstrating excellent noise resistance and robustness to missing data.
In order to further enhance the feature extraction capability of complex signals, the attention mechanism enhances the representation capability of key features by weighting them in the channel dimension, thereby significantly improving the classification performance [
16]. Specifically, Channel Attention Mechanism (CAM) focuses on the most informative channels in the feature maps, allowing the model to weigh the importance of different features more effectively, thus improving classification accuracy and enabling better feature representation. In addition, the attention mechanism can dynamically adjust the weight of each feature, allowing the model to focus more accurately on key information, thereby further improving classification accuracy [
17]. Zhang et al. [
18] proposed an electro-hydraulic steer-by-wire (EH-SBW) fault diagnosis method based on 1DCNN-LSTM, combining attention mechanism and transfer learning, using the scaled attention layer to amplify key features and reduce the impact of dual actuator coupling on the diagnosis results. Yao et al. [
19] proposed a data-driven model that uses an Adam optimizer with separate weight decay and a phased learning rate scheduling strategy for training, which accurately reveals the aerodynamic performance of the blade tip and exhibits extremely high reliability. However, in industrial environments, due to safety considerations, it is common for machine owners not to continue operation when equipment fails, resulting in a significantly higher number of healthy samples compared to fault samples [
20]. This data imbalance poses a serious limitation on the performance of deep learning models. Contrast learning, as an unsupervised learning method, has been shown to exhibit significant advantages in addressing data imbalance issues, thus providing a new research direction for further enhancing model performance.
Contrastive learning, as a self-supervised learning method, has attracted widespread attention in recent years. This method generates positive and negative sample pairs through data augmentation techniques and trains the network to enhance the distinction between negative samples while reducing the distance between positive samples, thereby being able to extract discriminative features from unlabeled data [
21]. Supervised Contrastive Learning (SCL), on the other hand, leverages labeled data to learn feature representations by maximizing the agreement between similar samples and minimizing it between dissimilar ones. This approach enhances the model’s ability to distinguish between different classes, improving generalization performance in classification tasks. He et al. [
22] proposed Momentum Contrast (MoCo) in 2020. Self-supervised learning methods represented by contrastive learning have been widely studied in the image field and have shown significant advantages over supervised learning methods. However, to date, the application of contrastive learning methods in the field of fault diagnosis is still relatively rare. Ding et al. [
23] developed MoCo as a detection method for early rolling bearing faults. Liu et al. [
24] proposed a new method based on meta-analogy momentum contrast learning (MA-MoCo). By improving the MoCo method and using the training idea of meta-learning, it was applied to the fault diagnosis of wind turbine transmission systems. An et al. [
25] proposed a domain adaptive network (DACL) based on contrastive learning, aiming to achieve cross-condition fault diagnosis and reduce the classification error of samples near or on the boundaries of various types to improve the diagnosis accuracy. In addition, Zhang et al. [
26] also applied MoCo to the multi-scale convolutional bearing fault diagnosis structure. In the case of limited labeled data, the accuracy of fault diagnosis was significantly improved by suppressing irrelevant information and enhancing the contribution of important features.
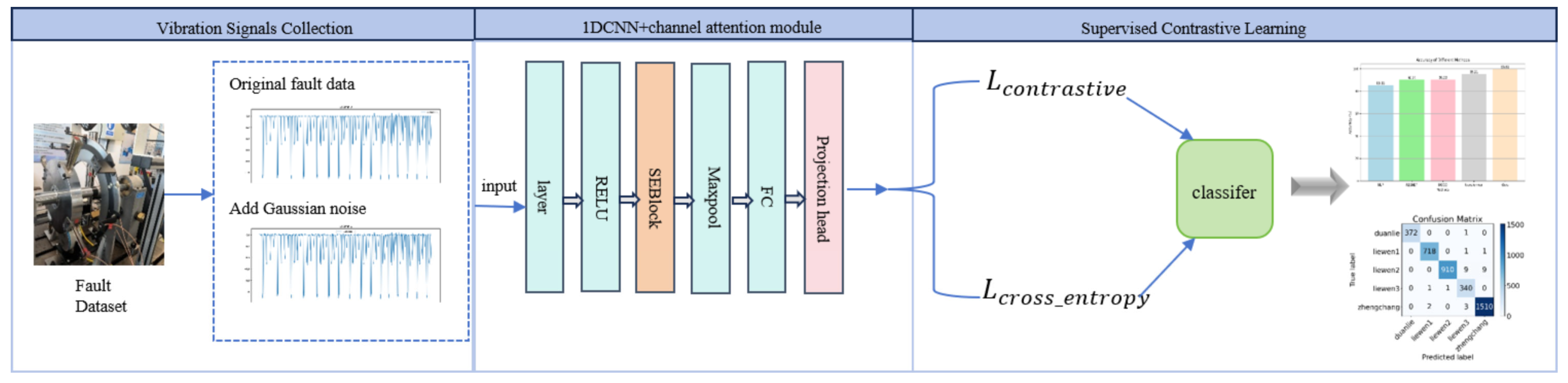
In summary, in order to effectively solve the problem of imbalanced fault data types, this paper proposes a contrastive learning method that combines one-dimensional CNN with an attention mechanism. The effectiveness of the proposed method is verified using blade crack fault data collected in a laboratory environment. The framework is shown in
Figure 1.
The main contributions of this paper are as follows:
The blade crack fault data collected in the laboratory were processed to generate fault datasets at three different speeds. The fault samples were augmented using data enhancement techniques and other methods to address the data imbalance issue, thereby enhancing the model’s capacity to classify and identify faults effectively.
We introduce the Channel Attention Mechanism (CAM), assigning different weights to each channel, highlighting important features, and improving the overall performance of the model;
By introducing contrastive learning and combining 1DCNN and CAM with the original cross entropy loss function, the model can better capture the subtle differences between different types of faults, further improving the performance of the model.
The rest of this article is organized as follows:
Section 2 provides a detailed introduction to the research methodology.
Section 3 demonstrates the superiority of the proposed method through experimental comparisons. Finally,
Section 4 presents the conclusions and discusses future development prospects.
2. Method
This paper primarily integrates 1DCNN, CAM, and SCL method to process vibration signals for the classification of turbine blade crack faults. Specifically, the 1DCNN is utilized to capture local features within the vibration signals, while CAM enhances attention to crucial features. By combining these approaches with SCL, we improve the model’s classification capability for complex fault modes. The integration of CAM with 1DCNN has been effectively applied in health monitoring, significantly enhancing the model’s ability to focus on key features in time-series data. This integration not only improves classification accuracy but also enhances feature representation, particularly in anomaly detection tasks. Prior studies have demonstrated the effectiveness of CAM in improving model performance in health monitoring applications.
This paper proposes a novel methodology that combines SCL with CAM and 1DCNN. This combination effectively addresses challenges associated with data imbalance, as SCL enhances the model’s ability to differentiate between categories by maximizing similarity among similar samples while minimizing it among dissimilar ones. The proposed method not only boosts classification performance in fault diagnosis but also provides a robust solution for tackling data imbalance, a common challenge in health monitoring. Additionally, data augmentation techniques, such as the addition of Gaussian noise, are employed to expand the dataset, further enhancing the model’s robustness and generalization capabilities. The following sections provide a detailed description and parameter settings for each method.
2.1. DCNN
CNN is a deep learning model particularly well-suited for processing time series and spatial data, efficiently extracting local features from the input. In one-dimensional signal processing tasks, the core of the 1D CNN lies in the convolution operation, which performs sliding window scanning on the input vibration signal. By utilizing local receptive fields and parameter sharing, it effectively captures local features of the input data. The mathematical expression for the convolution operation is as follows:
represents the output feature at position ; is the number of weights in the convolution kernel; is the mth weight in the convolution kernel; is the value of the input signal at position ; is the bias term. Through the convolution operation, the model can effectively extract local features, and by superimposing multiple layers of convolution in the entire network, 1DCNN can capture deeper abstract features.
The first convolutional layer in this paper processes the raw vibration data of the input signal, featuring 1 input channel, 64 output channels, 3 convolution kernels, a padding of 1, and a ReLU activation function. The second convolutional layer consists of 64 input channels, 128 output channels, and also utilizes 3 convolution kernels with a ReLU activation function. This layer further extracts higher-level features. After each convolutional layer, a max pooling operation is applied, which reduces the dimensionality of the feature map by selecting the maximum value within a local area. This process decreases computational complexity while preserving the essential features.
Output size calculation after convolution operation:
This formula is used to calculate the size of the output feature map after the convolution operation.
represents the width of the output feature map;
represents the width of the input feature map;
represents the padding added to the edge of the input feature map, which is used to control the spatial size of the output;
is the size of the convolution kernel;
is the stride, which determines the distance the convolution kernel moves each time. The CNN back-propagation algorithm uses gradient information to optimize the network weights, minimize the loss function on the training data, and reduce the difference between the predicted value and the true value. The back-propagation weight is updated as follows:
represents the weight matrix of the lth layer after update; represents the weight matrix of the lth layer before update; represents the learning rate; is the gradient of the loss function with respect to the weight matrix , indicating the direction and magnitude of weight adjustment required to reduce the loss; represents the regularization term used to prevent overfitting; is the regularization parameter, whose purpose is to control the intensity of this penalty.
2.2. CAM
The attention mechanism is a dynamic weighting process that optimizes the network’s feature acquisition by assigning weights to the extracted feature maps, thereby enhancing recognition accuracy. CAM is a technique designed to improve the performance of CNN models. It primarily applies weighting to the channel dimension of feature maps to emphasize key features, thus increasing the model’s expressiveness and classification performance. The fundamental idea of CAM is to enable the model to automatically learn and identify which feature channels are more relevant to the current task, assigning these channels higher weights [
27,
28].
CAM includes the following steps:
First, perform a global average pooling operation on the input feature map to generate a channel-level global feature vector, where
is the global feature of channel
,
is the value of the input feature map
at channel
and spatial position
, and
and
are the height and width of the feature map, respectively.
is the attention weight of channel
,
is the activation function that limits the weight range to between 0 and 1, and
is the fully connected layer.
The channel attention weight is multiplied by the corresponding channel of the input feature map to complete the feature recalibration. is the output feature of channel after recalibration. The introduction of CAM enables the model to capture meaningful features more effectively when processing data with high dimensions and complex structures, thereby improving the overall performance of the model.
2.3. SCL
SCL is a deep learning method that applies contrastive learning to supervised tasks. It leverages the benefits of both supervised and contrastive learning to enhance the classification performance of the model. This approach is especially effective for tasks involving labeled data, such as image classification and text classification [
29,
30]. The loss function of contrastive learning is expressed as follows:
is a set of sample indices; is a set of positive samples belonging to the same category as sample ; is a set of all samples related to sample (including positive and negative samples); is a feature representation of sample ; represents the similarity between sample and positive sample ; is a temperature parameter; converts the similarity value into a probability value through an exponential function to calculate the contrast loss.
Cross-entropy loss is integrated into contrastive learning, directly utilizing category labels to optimize the model. The optimization process involves calculating the difference between the category probability distribution predicted by the model and the true label distribution, enabling the model to more accurately predict the category of each sample.
represents the number of samples, indicating the total number of samples in the dataset, while denotes the number of categories, reflecting the total number of categories in the classification task. The variable serves as an indicator for the true label; specifically, if the true category of sample is , then ; otherwise, . The variable represents the predicted probability of sample belonging to category , which is typically obtained from the model’s output layer.
This paper also introduces the projection head, a network component designed to embed data into the feature space. Its primary function is to map the original features into a new space, facilitating improved contrastive learning and classification tasks [
31].
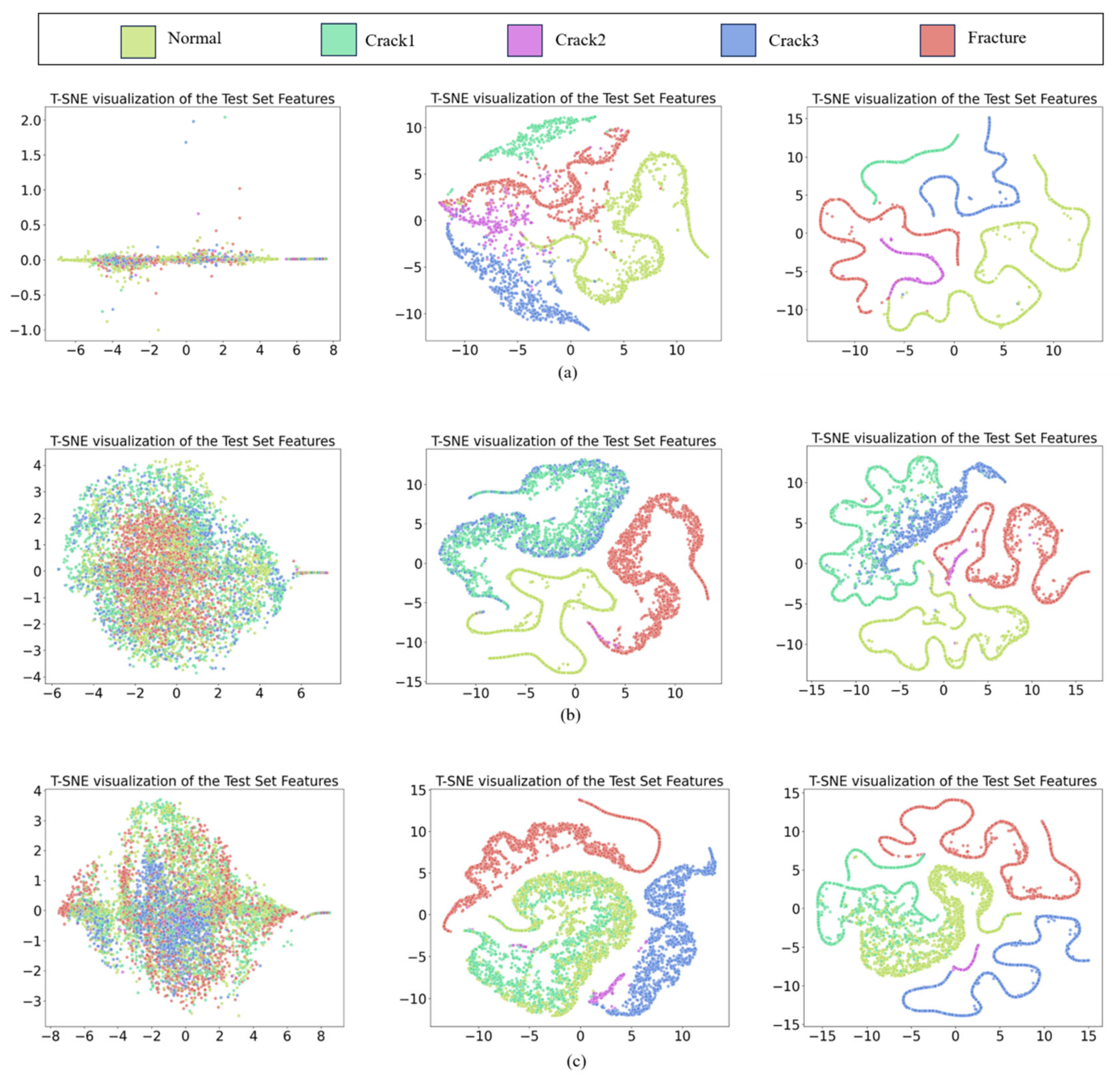
In this paper, we propose a model based on 1DCNN and CAM. The model structure includes two convolutional layers with 64 and 128 filters, respectively, with a kernel size of 3, and a ReLU activation function and SE module are added after each convolutional layer. A 2 × 2 max pooling layer is applied after each convolutional layer to reduce the size of the feature map. Regarding the fully connected layers, the first layer maps the feature dimension from 128 times 45 to 128 dimensions according to the specific feature length of the input data. Subsequently, we introduce a projection head, and two fully connected layers map the features from 128 dimensions to 256 dimensions and then to 512 dimensions, respectively. Finally, a fully connected layer maps the features to the corresponding number of categories.
We use the Adam optimizer to train the model with a learning rate set to 0.001. In addition, the cross entropy loss function is used for loss calculation of classification tasks, combined with the supervised contrast loss function to enhance the ability of feature representation. The specific training process includes forward propagation of each batch of input data, and backpropagation after calculating the loss to update the model parameters. In the experiment, the calculations include training loss, test loss, training accuracy, F1 score, precision, and recall. These indicators help evaluate the performance of the model in the time series classification task and provide a basis for subsequent optimization.
3. Data Augmentation
Data Augmentation is one type of data augmentation, which is currently one of the most advanced data augmentation methods. A primary objective is to expand the scale of the training dataset, enhance the model’s generalization ability, and reduce the risk of overfitting. In the field of image processing, data augmentation has been proven effective; techniques such as random cropping, resizing, and color distortion can significantly improve model performance [
32]. However, many methods used for augmenting two-dimensional image data are not entirely applicable to one-dimensional vibration signals, necessitating careful selection of appropriate augmentation strategies when handling different types of data.
Researchers have explored some data augmentation methods suitable for one-dimensional signals [
33], such as Gaussian noise, amplitude scaling, X-Y flipping, generative adversarial networks, DC offset, etc. Gaussian noise, as a common natural noise model, plays an important role in enhancing the robustness of the model. By adding Gaussian noise to the input data or features during training, the smoothness of the data can be broken, preventing the model from overfitting, thereby forcing the model to learn more generalized feature representations. In addition, Gaussian noise can also be used to generate diverse training samples, especially when data is scarce, to effectively expand the size of the data set and improve the performance of the model. For applications that require capturing subtle differences, such as fault diagnosis, the addition of Gaussian noise can enhance the model’s ability to effectively manage small perturbations in the input data.
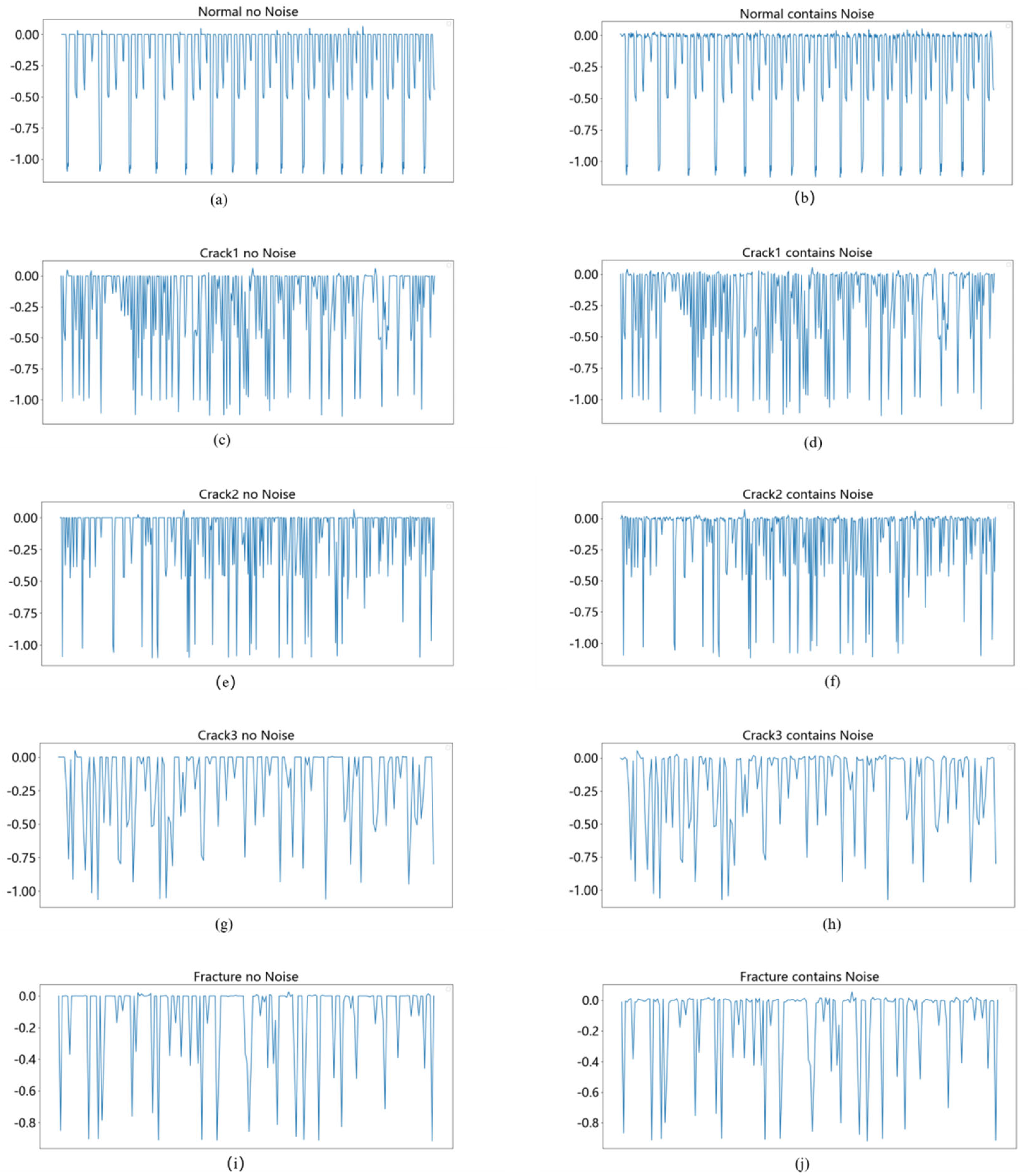
As shown in
Figure 2, this paper adopts a data enhancement method of adding Gaussian noise. Given a vibration signal
, noise
with Gaussian distribution is added to the original signal. The length of the noise is equal to the original signal,
,
is the original signal;
is the noise, which obeys the Gaussian distribution
with mean 0 and variance
. The standard deviation
of the noise determines the intensity of the noise, and
is the signal after adding noise.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}