


An Objective and Robust Bayes Factor for the Hypothesis Test One Sample and Two Population Means


Abstract
1. Introduction
2. Methodology
2.1. One-Sample Mean Hypothesis Testing
Robust Bayes Factor for the One-Sample Test for the Mean
- , where
- has a density on .
2.2. Two-Sample Mean Hypothesis Test
2.2.1. Intrinsic Bayes Factor for Two-Sample Means
2.2.2. Robust Bayes Factor for the Comparison of Two-Sample Means
2.2.3. The Effective Sample Size Bayesian Information Criterion (BIC-TESS)
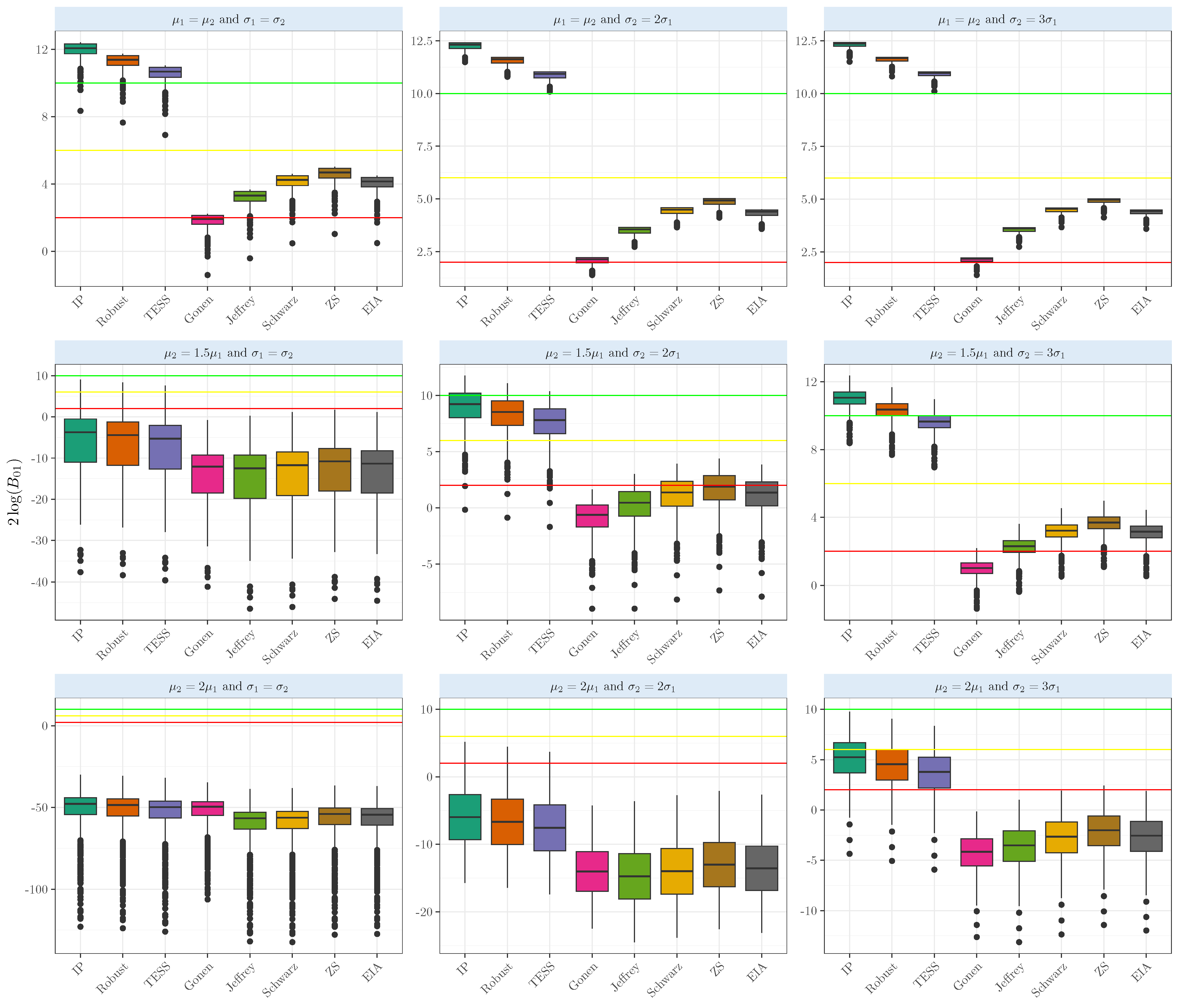
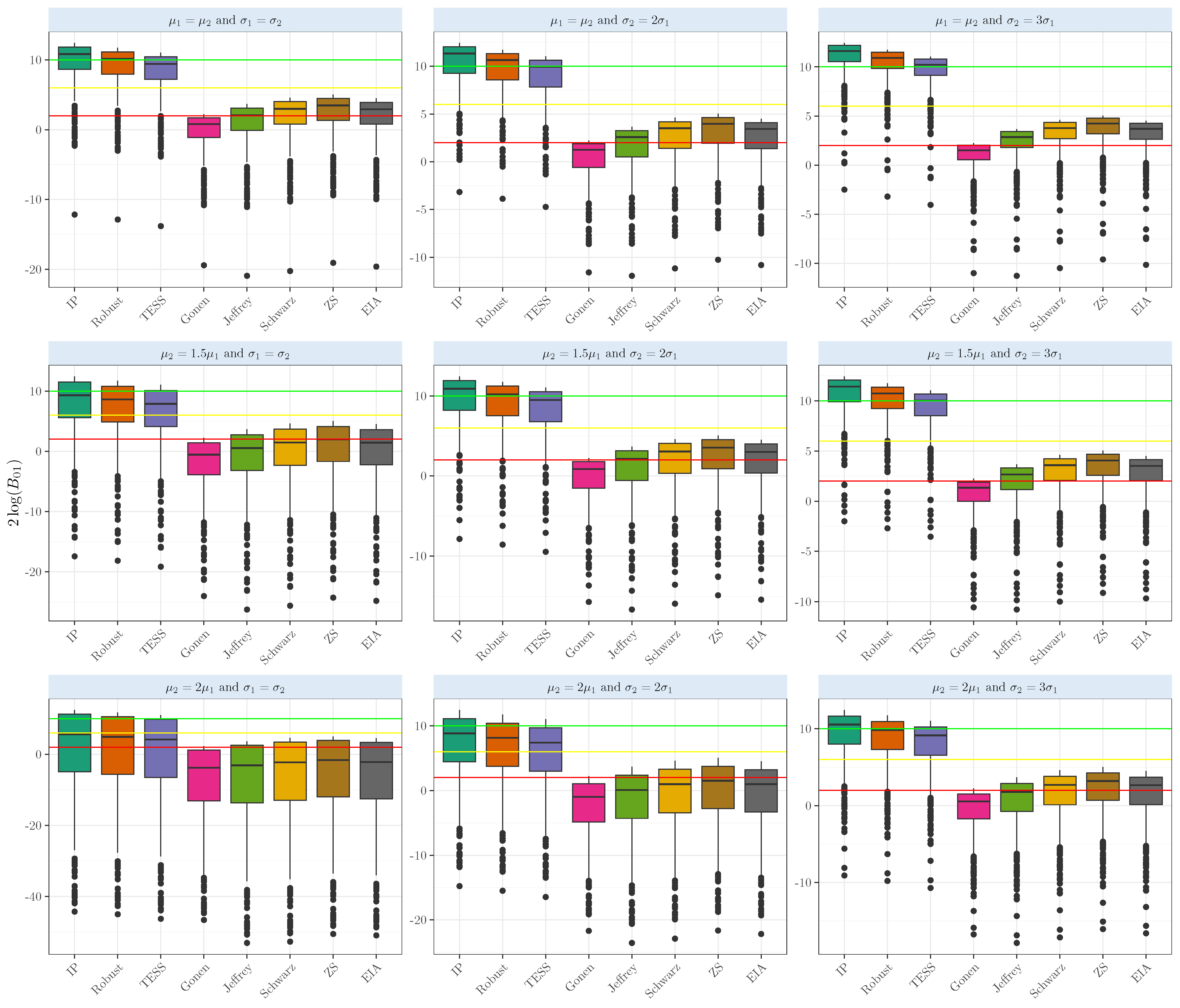
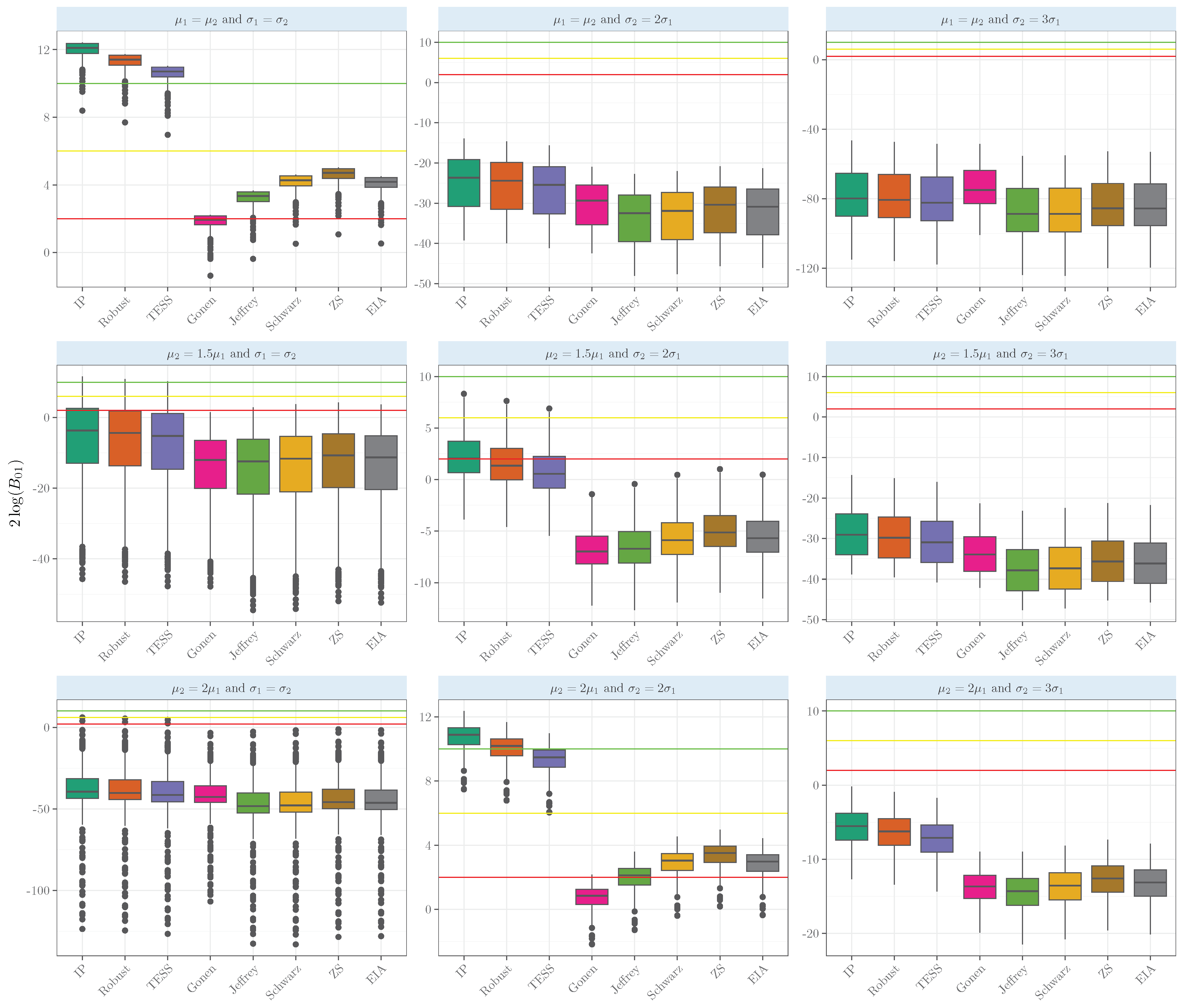
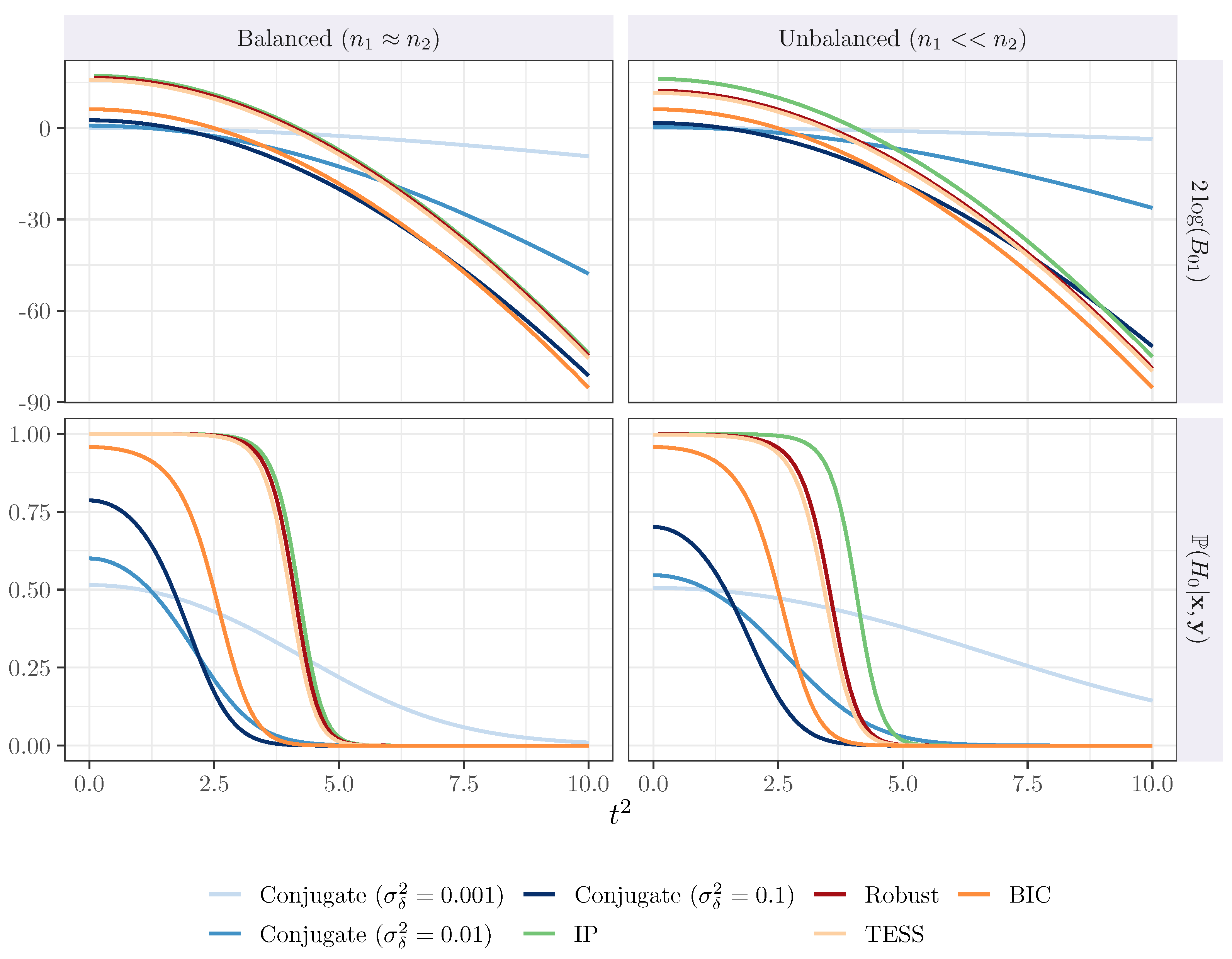
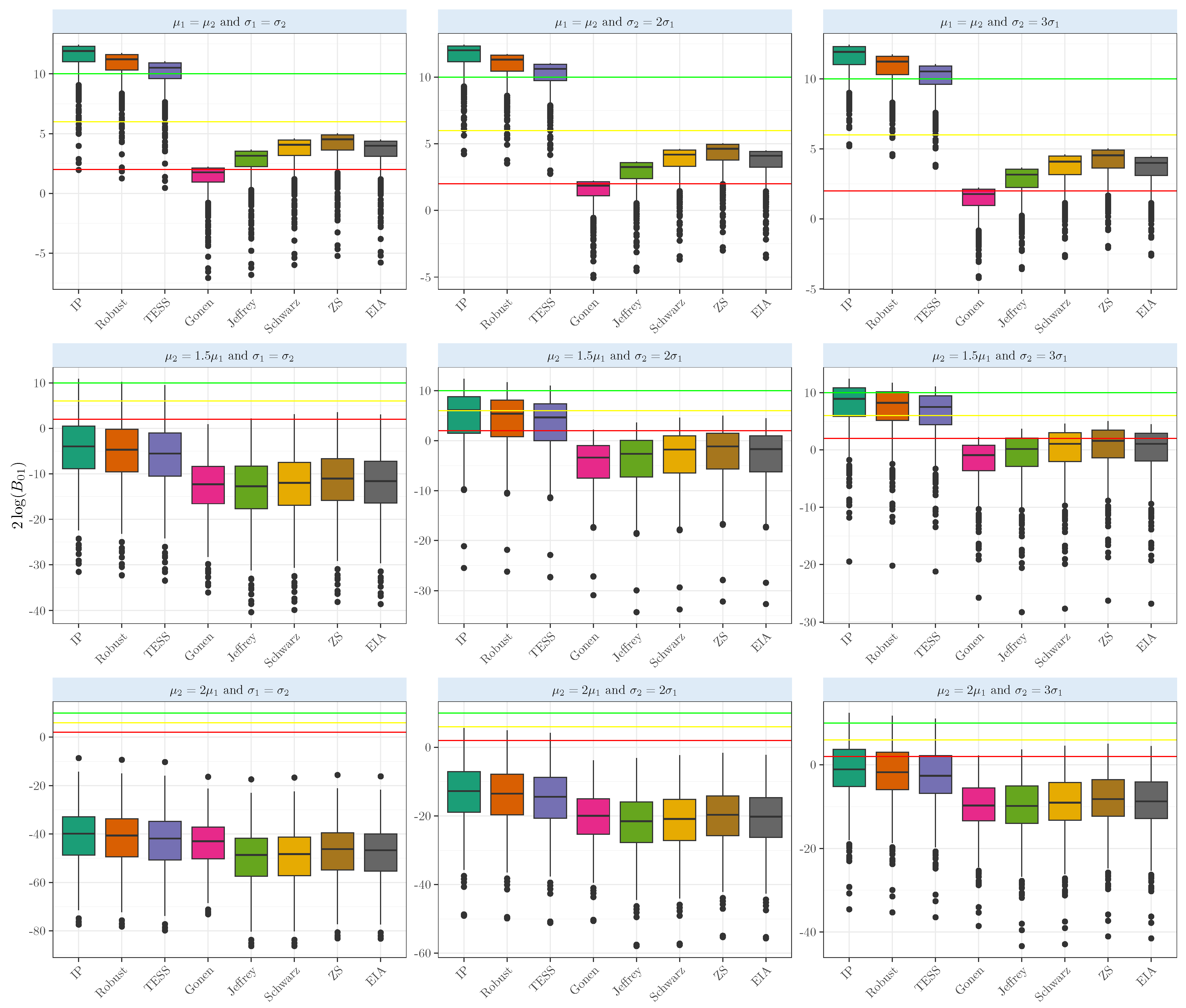
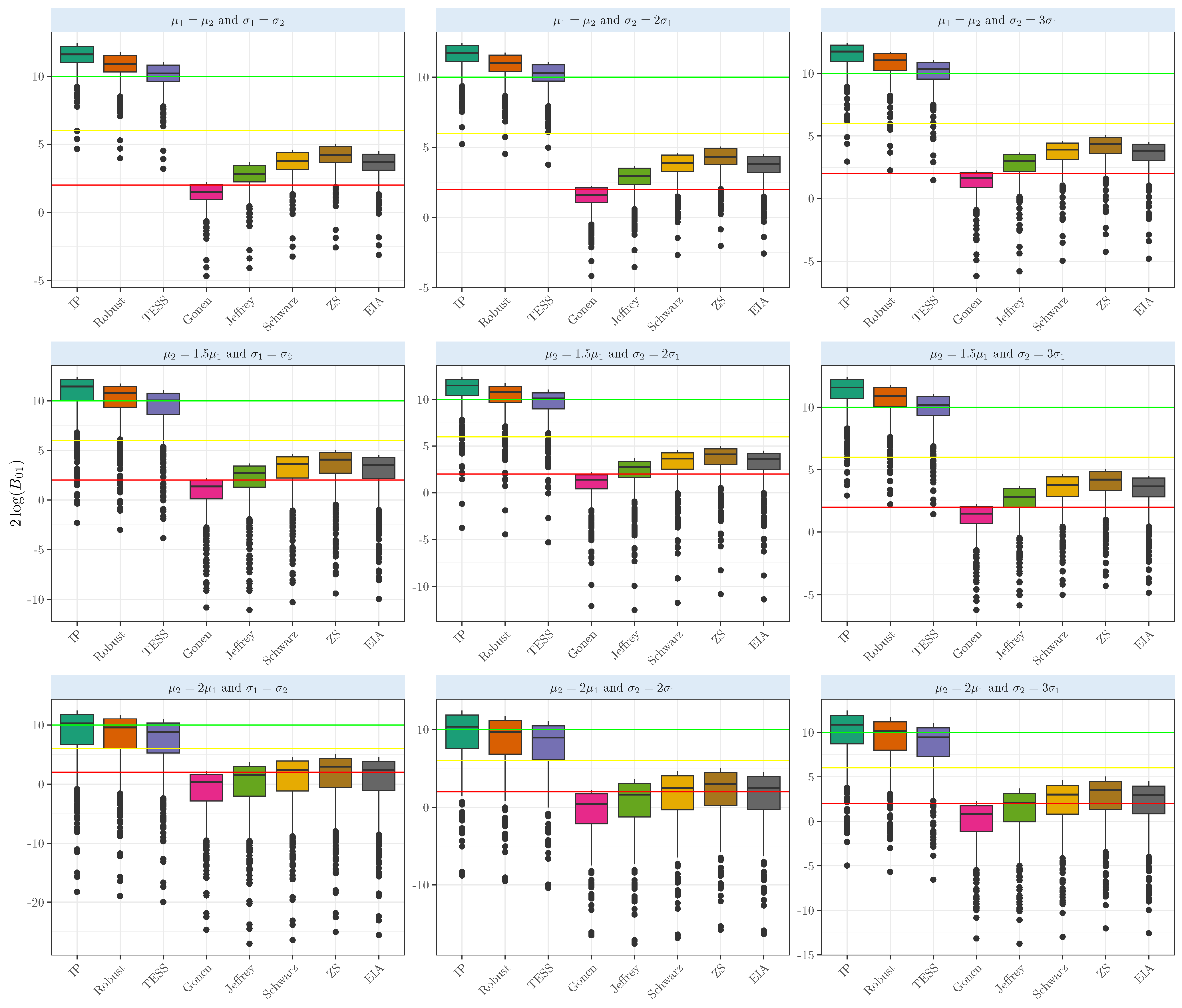
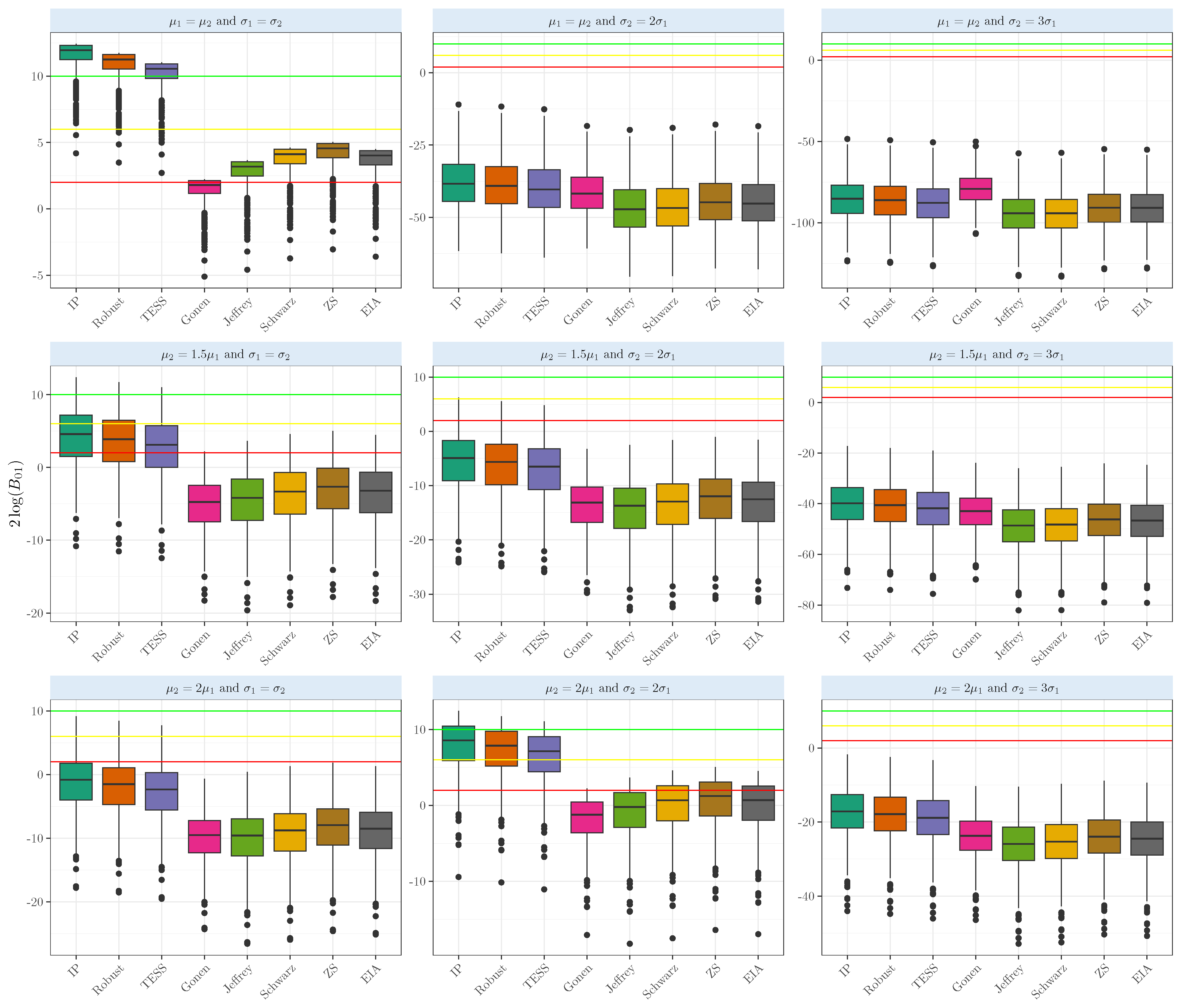
3. Simulation Experiments
Experiments for the One- and Two-Sample Mean Comparisons
4. Application in Real Dataset
4.1. Gosset Original Dataset
4.2. Induced Hypertension on Mice According to Diet
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TESS | The effective sample size |
| BIC | Bayesian Information Criterion |
| Bayes Factor based on the intrinsic prior for measuring vs. | |
| Bayes Factor based on the Berger’s Robust prior for measuring vs. | |
| Corrected BIC using the effective sample size for measuring vs. | |
| Bayes Factor based on Jeffreys’s prior for measuring vs. | |
| Bayes Factor based on the conjugate prior for measuring vs. | |
| Bayes Factor based on the Zellner and Siow prior for measuring vs. | |
| Bayes Factor expected arithmetic intrinsic prior for measuring vs. |
Appendix A
Appendix A.1. Calculation of the Effective Sample Size
Appendix A.2. Simulation Experiments

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Normal | IP | |||||||||
| Robust | ||||||||||
| TESS | ||||||||||
| Conjugate | ||||||||||
| Jeffrey’s | ||||||||||
| Schwarz’s | ||||||||||
| ZS | ||||||||||
| EIA | ||||||||||
| Student-t(1) | IP | |||||||||
| Robust | ||||||||||
| TESS | ||||||||||
| Conjugate | ||||||||||
| Jeffrey’s | ||||||||||
| Schwarz’s | ||||||||||
| ZS | ||||||||||
| EIA | ||||||||||
| Gamma | IP | |||||||||
| Robust | ||||||||||
| TESS | ||||||||||
| Conjugate | ||||||||||
| Jeffrey’s | ||||||||||
| Schwarz | ||||||||||
| ZS | ||||||||||
| EIA |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IP | 434 (86.8%) | 56 (11.2%) | 9 (1.8%) | 1 (0.2%) | 0 (0%) | 439 (87.8%) | 57 (11.4%) | 4 (0.8%) | 0 (0%) | 0 (0%) | 438 (87.6%) | 60 (12%) | 2 (0.4%) | 0 (0%) | 0 (0%) |
| Robust | 400 (80%) | 85 (17%) | 13 (2.6%) | 2 (0.4%) | 0 (0%) | 407 (81.4%) | 85 (17%) | 8 (1.6%) | 0 (0%) | 0 (0%) | 402 (80.4%) | 93 (18.6%) | 5 (1%) | 0 (0%) | 0 (0%) |
| TESS | 339 (67.8%) | 141 (28.2%) | 17 (3.4%) | 3 (0.6%) | 0 (0%) | 344 (68.8%) | 144 (28.8%) | 12 (2.4%) | 0 (0%) | 0 (0%) | 329 (65.8%) | 164 (32.8%) | 7 (1.4%) | 0 (0%) | 0 (0%) |
| Conjugate | 0 (0%) | 0 (0%) | 171 (34.2%) | 264 (52.8%) | 65 (13%) | 0 (0%) | 0 (0%) | 200 (40%) | 241 (48.2%) | 59 (11.8%) | 0 (0%) | 0 (0%) | 182 (36.4%) | 261 (52.2%) | 57 (11.4%) |
| Jeffrey | 0 (0%) | 0 (0%) | 392 (78.4%) | 73 (14.6%) | 35 (7%) | 0 (0%) | 0 (0%) | 402 (80.4%) | 68 (13.6%) | 30 (6%) | 0 (0%) | 0 (0%) | 396 (79.2%) | 78 (15.6%) | 26 (5.2%) |
| Schwarz | 0 (0%) | 0 (0%) | 437 (87.4%) | 40 (8%) | 23 (4.6%) | 0 (0%) | 0 (0%) | 444 (88.8%) | 39 (7.8%) | 17 (3.4%) | 0 (0%) | 0 (0%) | 445 (89%) | 45 (9%) | 10 (2%) |
| ZS | 0 (0%) | 0 (0%) | 452 (90.4%) | 30 (6%) | 18 (3.6%) | 0 (0%) | 0 (0%) | 458 (91.6%) | 31 (6.2%) | 11 (2.2%) | 0 (0%) | 0 (0%) | 459 (91.8%) | 34 (6.8%) | 7 (1.4%) |
| EIA | 0 (0%) | 0 (0%) | 435 (87%) | 42 (8.4%) | 23 (4.6%) | 0 (0%) | 0 (0%) | 444 (88.8%) | 39 (7.8%) | 17 (3.4%) | 0 (0%) | 0 (0%) | 444 (88.8%) | 46 (9.2%) | 10 (2%) |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
| IP | 2 (0.4%) | 19 (3.8%) | 67 (13.4%) | 48 (9.6%) | 364 (72.8%) | 69 (13.8%) | 184 (36.8%) | 110 (22%) | 54 (10.8%) | 83 (16.6%) | 176 (35.2%) | 195 (39%) | 87 (17.4%) | 21 (4.2%) | 21 (4.2%) |
| Robust | 1 (0.2%) | 12 (2.4%) | 60 (12%) | 45 (9%) | 382 (76.4%) | 50 (10%) | 176 (35.2%) | 122 (24.4%) | 52 (10.4%) | 100 (20%) | 137 (27.4%) | 214 (42.8%) | 97 (19.4%) | 23 (4.6%) | 29 (5.8%) |
| TESS | 0 (0%) | 11 (2.2%) | 45 (9%) | 45 (9%) | 399 (79.8%) | 24 (4.8%) | 167 (33.4%) | 137 (27.4%) | 46 (9.2%) | 126 (25.2%) | 76 (15.2%) | 248 (49.6%) | 116 (23.2%) | 26 (5.2%) | 34 (6.8%) |
| Conjugate | 0 (0%) | 0 (0%) | 0 (0%) | 2 (0.4%) | 498 (99.6%) | 0 (0%) | 0 (0%) | 8 (1.6%) | 63 (12.6%) | 429 (85.8%) | 0 (0%) | 0 (0%) | 36 (7.2%) | 147 (29.4%) | 317 (63.4%) |
| Jeffrey | 0 (0%) | 0 (0%) | 1 (0.2%) | 5 (1%) | 494 (98.8%) | 0 (0%) | 0 (0%) | 50 (10%) | 77 (15.4%) | 373 (74.6%) | 0 (0%) | 0 (0%) | 132 (26.4%) | 128 (25.6%) | 240 (48%) |
| Schwarz | 0 (0%) | 0 (0%) | 2 (0.4%) | 9 (1.8%) | 489 (97.8%) | 0 (0%) | 0 (0%) | 77 (15.4%) | 97 (19.4%) | 326 (65.2%) | 0 (0%) | 0 (0%) | 186 (37.2%) | 117 (23.4%) | 197 (39.4%) |
| ZS | 0 (0%) | 0 (0%) | 3 (0.6%) | 9 (1.8%) | 488 (97.6%) | 0 (0%) | 0 (0%) | 101 (20.2%) | 96 (19.2%) | 303 (60.6%) | 0 (0%) | 0 (0%) | 228 (45.6%) | 99 (19.8%) | 173 (34.6%) |
| EIA | 0 (0%) | 0 (0%) | 2 (0.4%) | 9 (1.8%) | 489 (97.8%) | 0 (0%) | 0 (0%) | 74 (14.8%) | 103 (20.6%) | 323 (64.6%) | 0 (0%) | 0 (0%) | 185 (37%) | 119 (23.8%) | 196 (39.2%) |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
| IP | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 11 (2.2%) | 13 (2.6%) | 476 (95.2%) | 12 (2.4%) | 52 (10.4%) | 109 (21.8%) | 53 (10.6%) | 274 (54.8%) |
| Robust | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 10 (2%) | 9 (1.8%) | 481 (96.2%) | 5 (1%) | 46 (9.2%) | 102 (20.4%) | 54 (10.8%) | 293 (58.6%) |
| TESS | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 5 (1%) | 12 (2.4%) | 483 (96.6%) | 5 (1%) | 38 (7.6%) | 90 (18%) | 53 (10.6%) | 314 (62.8%) |
| Conjugate | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 1 (0.2%) | 11 (2.2%) | 488 (97.6%) |
| Jeffrey | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 5 (1%) | 19 (3.8%) | 476 (95.2%) |
| Schwarz | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 13 (2.6%) | 21 (4.2%) | 466 (93.2%) |
| ZS | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 18 (3.6%) | 25 (5%) | 457 (91.4%) |
| EIA | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 13 (2.6%) | 21 (4.2%) | 466 (93.2%) |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IP | 456 (91.2%) | 41 (8.2%) | 3 (0.6%) | 0 (0%) | 0 (0%) | 455 (91%) | 44 (8.8%) | 1 (0.2%) | 0 (0%) | 0 (0%) | 448 (89.6%) | 49 (9.8%) | 3 (0.6%) | 0 (0%) | 0 (0%) |
| Robust | 410 (82%) | 87 (17.4%) | 3 (0.6%) | 0 (0%) | 0 (0%) | 416 (83.2%) | 82 (16.4%) | 2 (0.4%) | 0 (0%) | 0 (0%) | 410 (82%) | 83 (16.6%) | 7 (1.4%) | 0 (0%) | 0 (0%) |
| TESS | 310 (62%) | 187 (37.4%) | 3 (0.6%) | 0 (0%) | 0 (0%) | 320 (64%) | 178 (35.6%) | 2 (0.4%) | 0 (0%) | 0 (0%) | 310 (62%) | 181 (36.2%) | 8 (1.6%) | 1 (0.2%) | 0 (0%) |
| Conjugate | 0 (0%) | 0 (0%) | 131 (26.2%) | 326 (65.2%) | 43 (8.6%) | 0 (0%) | 0 (0%) | 156 (31.2%) | 301 (60.2%) | 43 (8.6%) | 0 (0%) | 0 (0%) | 155 (31%) | 297 (59.4%) | 48 (9.6%) |
| Jeffrey | 0 (0%) | 0 (0%) | 404 (80.8%) | 85 (17%) | 11 (2.2%) | 0 (0%) | 0 (0%) | 412 (82.4%) | 74 (14.8%) | 14 (2.8%) | 0 (0%) | 0 (0%) | 396 (79.2%) | 86 (17.2%) | 18 (3.6%) |
| Schwarz | 0 (0%) | 0 (0%) | 459 (91.8%) | 37 (7.4%) | 4 (0.8%) | 0 (0%) | 0 (0%) | 457 (91.4%) | 39 (7.8%) | 4 (0.8%) | 0 (0%) | 0 (0%) | 454 (90.8%) | 36 (7.2%) | 10 (2%) |
| ZS | 0 (0%) | 0 (0%) | 479 (95.8%) | 18 (3.6%) | 3 (0.6%) | 0 (0%) | 0 (0%) | 474 (94.8%) | 24 (4.8%) | 2 (0.4%) | 0 (0%) | 0 (0%) | 474 (94.8%) | 17 (3.4%) | 9 (1.8%) |
| EIA | 0 (0%) | 0 (0%) | 457 (91.4%) | 39 (7.8%) | 4 (0.8%) | 0 (0%) | 0 (0%) | 457 (91.4%) | 39 (7.8%) | 4 (0.8%) | 0 (0%) | 0 (0%) | 454 (90.8%) | 36 (7.2%) | 10 (2%) |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
| IP | 378 (75.6%) | 92 (18.4%) | 22 (4.4%) | 5 (1%) | 3 (0.6%) | 395 (79%) | 88 (17.6%) | 14 (2.8%) | 1 (0.2%) | 2 (0.4%) | 421 (84.2%) | 69 (13.8%) | 10 (2%) | 0 (0%) | 0 (0%) |
| Robust | 327 (65.4%) | 132 (26.4%) | 31 (6.2%) | 5 (1%) | 5 (1%) | 347 (69.4%) | 129 (25.8%) | 19 (3.8%) | 3 (0.6%) | 2 (0.4%) | 375 (75%) | 111 (22.2%) | 14 (2.8%) | 0 (0%) | 0 (0%) |
| TESS | 259 (51.8%) | 187 (37.4%) | 39 (7.8%) | 9 (1.8%) | 6 (1.2%) | 271 (54.2%) | 199 (39.8%) | 23 (4.6%) | 4 (0.8%) | 3 (0.6%) | 284 (56.8%) | 191 (38.2%) | 24 (4.8%) | 1 (0.2%) | 0 (0%) |
| Conjugate | 0 (0%) | 0 (0%) | 125 (25%) | 259 (51.8%) | 116 (23.2%) | 0 (0%) | 0 (0%) | 109 (21.8%) | 289 (57.8%) | 102 (20.4%) | 0 (0%) | 0 (0%) | 139 (27.8%) | 283 (56.6%) | 78 (15.6%) |
| Jeffrey | 0 (0%) | 0 (0%) | 321 (64.2%) | 102 (20.4%) | 77 (15.4%) | 0 (0%) | 0 (0%) | 342 (68.4%) | 100 (20%) | 58 (11.6%) | 0 (0%) | 0 (0%) | 366 (73.2%) | 90 (18%) | 44 (8.8%) |
| Schwarz | 0 (0%) | 0 (0%) | 387 (77.4%) | 53 (10.6%) | 60 (12%) | 0 (0%) | 0 (0%) | 403 (80.6%) | 60 (12%) | 37 (7.4%) | 0 (0%) | 0 (0%) | 424 (84.8%) | 47 (9.4%) | 29 (5.8%) |
| ZS | 0 (0%) | 0 (0%) | 403 (80.6%) | 46 (9.2%) | 51 (10.2%) | 0 (0%) | 0 (0%) | 426 (85.2%) | 44 (8.8%) | 30 (6%) | 0 (0%) | 0 (0%) | 443 (88.6%) | 32 (6.4%) | 25 (5%) |
| EIA | 0 (0%) | 0 (0%) | 387 (77.4%) | 53 (10.6%) | 60 (12%) | 0 (0%) | 0 (0%) | 401 (80.2%) | 63 (12.6%) | 36 (7.2%) | 0 (0%) | 0 (0%) | 423 (84.6%) | 49 (9.8%) | 28 (5.6%) |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
| IP | 264 (52.8%) | 125 (25%) | 60 (12%) | 12 (2.4%) | 39 (7.8%) | 263 (52.6%) | 144 (28.8%) | 64 (12.8%) | 11 (2.2%) | 18 (3.6%) | 324 (64.8%) | 114 (22.8%) | 48 (9.6%) | 7 (1.4%) | 7 (1.4%) |
| Robust | 225 (45%) | 150 (30%) | 65 (13%) | 18 (3.6%) | 42 (8.4%) | 231 (46.2%) | 166 (33.2%) | 72 (14.4%) | 9 (1.8%) | 22 (4.4%) | 270 (54%) | 157 (31.4%) | 55 (11%) | 8 (1.6%) | 10 (2%) |
| TESS | 162 (32.4%) | 190 (38%) | 79 (15.8%) | 22 (4.4%) | 47 (9.4%) | 183 (36.6%) | 196 (39.2%) | 81 (16.2%) | 16 (3.2%) | 24 (4.8%) | 183 (36.6%) | 229 (45.8%) | 64 (12.8%) | 10 (2%) | 14 (2.8%) |
| Conjugate | 0 (0%) | 0 (0%) | 73 (14.6%) | 194 (38.8%) | 233 (46.6%) | 0 (0%) | 0 (0%) | 73 (14.6%) | 193 (38.6%) | 234 (46.8%) | 0 (0%) | 0 (0%) | 82 (16.4%) | 245 (49%) | 173 (34.6%) |
| Jeffrey | 0 (0%) | 0 (0%) | 224 (44.8%) | 87 (17.4%) | 189 (37.8%) | 0 (0%) | 0 (0%) | 229 (45.8%) | 102 (20.4%) | 169 (33.8%) | 0 (0%) | 0 (0%) | 261 (52.2%) | 110 (22%) | 129 (25.8%) |
| Schwarz | 0 (0%) | 0 (0%) | 268 (53.6%) | 77 (15.4%) | 155 (31%) | 0 (0%) | 0 (0%) | 269 (53.8%) | 98 (19.6%) | 133 (26.6%) | 0 (0%) | 0 (0%) | 330 (66%) | 75 (15%) | 95 (19%) |
| ZS | 0 (0%) | 0 (0%) | 287 (57.4%) | 72 (14.4%) | 141 (28.2%) | 0 (0%) | 0 (0%) | 298 (59.6%) | 82 (16.4%) | 120 (24%) | 0 (0%) | 0 (0%) | 349 (69.8%) | 64 (12.8%) | 87 (17.4%) |
| EIA | 0 (0%) | 0 (0%) | 268 (53.6%) | 78 (15.6%) | 154 (30.8%) | 0 (0%) | 0 (0%) | 268 (53.6%) | 100 (20%) | 132 (26.4%) | 0 (0%) | 0 (0%) | 330 (66%) | 77 (15.4%) | 93 (18.6%) |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IP | 449 (89.8%) | 49 (9.8%) | 2 (0.4%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Robust | 417 (83.4%) | 78 (15.6%) | 5 (1%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| TESS | 348 (69.6%) | 139 (27.8%) | 13 (2.6%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Conjugate | 0 (0%) | 0 (0%) | 183 (36.6%) | 268 (53.6%) | 49 (9.8%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Jeffrey | 0 (0%) | 0 (0%) | 412 (82.4%) | 62 (12.4%) | 26 (5.2%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Schwarz | 0 (0%) | 0 (0%) | 452 (90.4%) | 31 (6.2%) | 17 (3.4%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| ZS | 0 (0%) | 0 (0%) | 465 (93%) | 25 (5%) | 10 (2%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| EIA | 0 (0%) | 0 (0%) | 451 (90.2%) | 32 (6.4%) | 17 (3.4%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
| IP | 30 (6%) | 141 (28.2%) | 186 (37.2%) | 63 (12.6%) | 80 (16%) | 0 (0%) | 3 (0.6%) | 33 (6.6%) | 35 (7%) | 429 (85.8%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Robust | 21 (4.2%) | 119 (23.8%) | 191 (38.2%) | 68 (13.6%) | 101 (20.2%) | 0 (0%) | 0 (0%) | 22 (4.4%) | 39 (7.8%) | 439 (87.8%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| TESS | 8 (1.6%) | 109 (21.8%) | 186 (37.2%) | 72 (14.4%) | 125 (25%) | 0 (0%) | 0 (0%) | 16 (3.2%) | 33 (6.6%) | 451 (90.2%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Conjugate | 0 (0%) | 0 (0%) | 2 (0.4%) | 32 (6.4%) | 466 (93.2%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Jeffrey | 0 (0%) | 0 (0%) | 19 (3.8%) | 49 (9.8%) | 432 (86.4%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Schwarz | 0 (0%) | 0 (0%) | 36 (7.2%) | 63 (12.6%) | 401 (80.2%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| ZS | 0 (0%) | 0 (0%) | 50 (10%) | 73 (14.6%) | 377 (75.4%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| EIA | 0 (0%) | 0 (0%) | 35 (7%) | 64 (12.8%) | 401 (80.2%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | Very Strong | Strong | Positive | Weak | Negative | |
| IP | 0 (0%) | 19 (3.8%) | 103 (20.6%) | 86 (17.2%) | 292 (58.4%) | 148 (29.6%) | 218 (43.6%) | 103 (20.6%) | 17 (3.4%) | 14 (2.8%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Robust | 0 (0%) | 13 (2.6%) | 87 (17.4%) | 73 (14.6%) | 327 (65.4%) | 111 (22.2%) | 229 (45.8%) | 122 (24.4%) | 16 (3.2%) | 22 (4.4%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| TESS | 0 (0%) | 6 (1.2%) | 71 (14.2%) | 66 (13.2%) | 357 (71.4%) | 73 (14.6%) | 239 (47.8%) | 140 (28%) | 21 (4.2%) | 27 (5.4%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Conjugate | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) | 0 (0%) | 0 (0%) | 28 (5.6%) | 124 (24.8%) | 348 (69.6%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Jeffrey | 0 (0%) | 0 (0%) | 0 (0%) | 2 (0.4%) | 498 (99.6%) | 0 (0%) | 0 (0%) | 107 (21.4%) | 130 (26%) | 263 (52.6%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| Schwarz | 0 (0%) | 0 (0%) | 0 (0%) | 5 (1%) | 495 (99%) | 0 (0%) | 0 (0%) | 157 (31.4%) | 139 (27.8%) | 204 (40.8%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| ZS | 0 (0%) | 0 (0%) | 0 (0%) | 7 (1.4%) | 493 (98.6%) | 0 (0%) | 0 (0%) | 200 (40%) | 115 (23%) | 185 (37%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
| EIA | 0 (0%) | 0 (0%) | 0 (0%) | 5 (1%) | 495 (99%) | 0 (0%) | 0 (0%) | 154 (30.8%) | 143 (28.6%) | 203 (40.6%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 500 (100%) |
References
- Student. The probable error of a mean. Biometrika 1908, 6, 1–25. [Google Scholar] [CrossRef]
- Greenland, S.; Senn, S.J.; Rothman, K.J.; Carlin, J.B.; Poole, C.; Goodman, S.N.; Altman, D.G. Statistical tests, p values, confidence intervals, and power: A guide to misinterpretations. Eur. J. Epidemiol. 2016, 31, 337–350. [Google Scholar] [CrossRef] [PubMed]
- Wasserstein, R.L.; Lazar, N.A. The ASA statement on p-values: Context, process, and purpose. Am. Stat. 2016, 70, 129–133. [Google Scholar] [CrossRef]
- Vidgen, B.; Yasseri, T. p-values: Misunderstood and misused. Front. Physics 2016, 4, 6. [Google Scholar] [CrossRef]
- Held, L.; Ott, M. On p-values and Bayes factors. Annu. Rev. Stat. Its Appl. 2018, 5, 393–419. [Google Scholar] [CrossRef]
- Dienes, Z. How Bayes factors change scientific practice. J. Math. Psychol. 2016, 72, 78–89. [Google Scholar] [CrossRef]
- Marden, J.I. Hypothesis testing: From p values to Bayes factors. J. Am. Stat. Assoc. 2000, 95, 1316–1320. [Google Scholar] [CrossRef]
- Page, R.; Satake, E. Beyond p Values and Hypothesis Testing: Using the Minimum Bayes Factor to Teach Statistical Inference in Undergraduate Introductory Statistics Courses. J. Educ. Learn. 2017, 6, 254–266. [Google Scholar] [CrossRef]
- Lavine, M.; Schervish, M.J. Bayes factors: What they are and what they are not. Am. Stat. 1999, 53, 119–122. [Google Scholar]
- Berger, J.O.; Mortera, J. Default Bayes factors for nonnested hypothesis testing. J. Am. Stat. Assoc. 1999, 94, 542–554. [Google Scholar] [CrossRef]
- Berger, J.; Pericchi, L. Bayes factors. In Wiley StatsRef: Statistics Reference Online; John Wiley & Sons: Hoboken, NJ, USA, 2014; pp. 1–14. [Google Scholar]
- Jeffreys, H. The Theory of Probability; OuP Oxford: Oxford, UK, 1998. [Google Scholar]
- Kass, R.E.; Raftery, A.E. Bayes factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Gönen, M.; Johnson, W.O.; Lu, Y.; Westfall, P.H. The Bayesian two-sample t test. Am. Stat. 2005, 59, 252–257. [Google Scholar] [CrossRef]
- Berger, J.O.; Pericchi, L.R.; Ghosh, J.; Samanta, T.; De Santis, F.; Berger, J.; Pericchi, L. Objective Bayesian Methods for Model Selection: Introduction and Comparison; Lecture Notes-Monograph Series; Institute of Mathematical Statistics: Beachwood, OH, USA, 2001; pp. 135–207. [Google Scholar]
- Berger, J.O.; Pericchi, L.R. The intrinsic Bayes factor for linear models. Bayesian Stat. 1996, 5, 25–44. [Google Scholar]
- Berger, J.O.; Pericchi, L.R. The intrinsic Bayes factor for model selection and prediction. J. Am. Stat. Assoc. 1996, 91, 109–122. [Google Scholar] [CrossRef]
- Berger, J.O. Robust Bayesian analysis: Sensitivity to the prior. J. Stat. Plan. Inference 1990, 25, 303–328. [Google Scholar] [CrossRef]
- Moreno, E. Bayes Factors for Intrinsic and Fractional Priors in Nested Models. Bayesian Robustness; Lecture Notes-Monograph Series; Institute of Mathematical Statistics: Beachwood, OH, USA, 1997; pp. 257–270. [Google Scholar]
- Berger, J.O.; Berger, J. Bayesian Analysis; Springer: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Berger, J.; Bayarri, M.; Pericchi, L. The effective sample size. Econom. Rev. 2014, 33, 197–217. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Zellner, A.; Siow, A. Posterior odds ratios for selected regression hypotheses. Trab. Estad. Investig. Oper. 1980, 31, 585–603. [Google Scholar] [CrossRef]
- Kim, D.H.; Kang, S.G.; Lee, W.D. Intrinsic priors for testing two normal means with intrinsic bayes factors. Commun. Stat. Methods 2006, 35, 63–81. [Google Scholar] [CrossRef]
- Cushny, A.R.; Peebles, A.R. The action of optical isomers: II. Hyoscines. J. Physiol. 1905, 32, 501. [Google Scholar] [CrossRef]
- Senn, S.; Richardson, W. The first t-test. Stat. Med. 1994, 13, 785–803. [Google Scholar] [CrossRef]
- Senn, S. A century of t-tests. Significance 2008, 5, 37–39. [Google Scholar] [CrossRef]
- Falk, J.L.; Tang, M.; Forman, S. Schedule-induced chronic hypertension. Psychosom. Med. 1977, 39, 252–263. [Google Scholar] [CrossRef]
| One Sample | - | ||
| - | |||
| Two Samples | |||
| ∞ | |||
| ∞ | |||
| - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almodóvar-Rivera, I.A.; Pericchi-Guerra, L.R. An Objective and Robust Bayes Factor for the Hypothesis Test One Sample and Two Population Means. Entropy 2024, 26, 88. https://doi.org/10.3390/e26010088
Almodóvar-Rivera IA, Pericchi-Guerra LR. An Objective and Robust Bayes Factor for the Hypothesis Test One Sample and Two Population Means. Entropy. 2024; 26(1):88. https://doi.org/10.3390/e26010088
Chicago/Turabian StyleAlmodóvar-Rivera, Israel A., and Luis R. Pericchi-Guerra. 2024. "An Objective and Robust Bayes Factor for the Hypothesis Test One Sample and Two Population Means" Entropy 26, no. 1: 88. https://doi.org/10.3390/e26010088
APA StyleAlmodóvar-Rivera, I. A., & Pericchi-Guerra, L. R. (2024). An Objective and Robust Bayes Factor for the Hypothesis Test One Sample and Two Population Means. Entropy, 26(1), 88. https://doi.org/10.3390/e26010088