1. Introduction
The now classic nearest neighbors classification algorithm, introduced in a 1951 technical report by Fix and Hodges (reprinted in [
1]), marked one of the early successes of machine learning research. The basic idea is that, given some notion of proximity between pairs of observations, the class of a new sample unit is determined by majority voting among its
k nearest neighbors in the training sample [
2,
3]. A natural question is whether it is possible to develop a probabilistic model that captures the essence of the mechanism contained in the classic nearest neighbors algorithm while adding proper uncertainty quantification of predictions made by the model. In a pioneering paper, Holmes and Adams [
4] defined a probabilistic nearest neighbors model specifying a set of conditional distributions. A few years later, Cucala et al. [
5] pointed out the incompatibility of the conditional distributions specified by Holmes and Adams, which do not define a proper joint model distribution. As an alternative, Cucala et al. developed their own nearest neighbors classification model, defining directly a proper, Boltzmann-like joint distribution. A major difficulty with the Cucala et al. model is the fact that its likelihood function involves a seemingly intractable normalizing constant. Consequently, in order to perform a Bayesian analysis of their model, the authors engaged in a
tour de force of Monte Carlo techniques, with varied computational complexity and approximation quality.
In this paper, we introduce an alternative probabilistic nearest neighbors predictive model constructed from an aggregation of simpler models whose normalizing constants can be exactly summed in polynomial time. We begin by reviewing the Cucala et al. model in
Section 2, showing by an elementary argument that the computational complexity of the exact summation of its normalizing constant is directly tied to the concept of NP-completeness [
6]. The necessary concepts from the theory of computational complexity are briefly reviewed.
Section 3 introduces a family of nonlocal models, whose joint distributions take into account only the interactions between each sample unit and its
r-th nearest neighbor. For each nonlocal model, we derive an analytic expression for its normalizing constant, which can be computed exactly in polynomial time. The nonlocal models are combined in
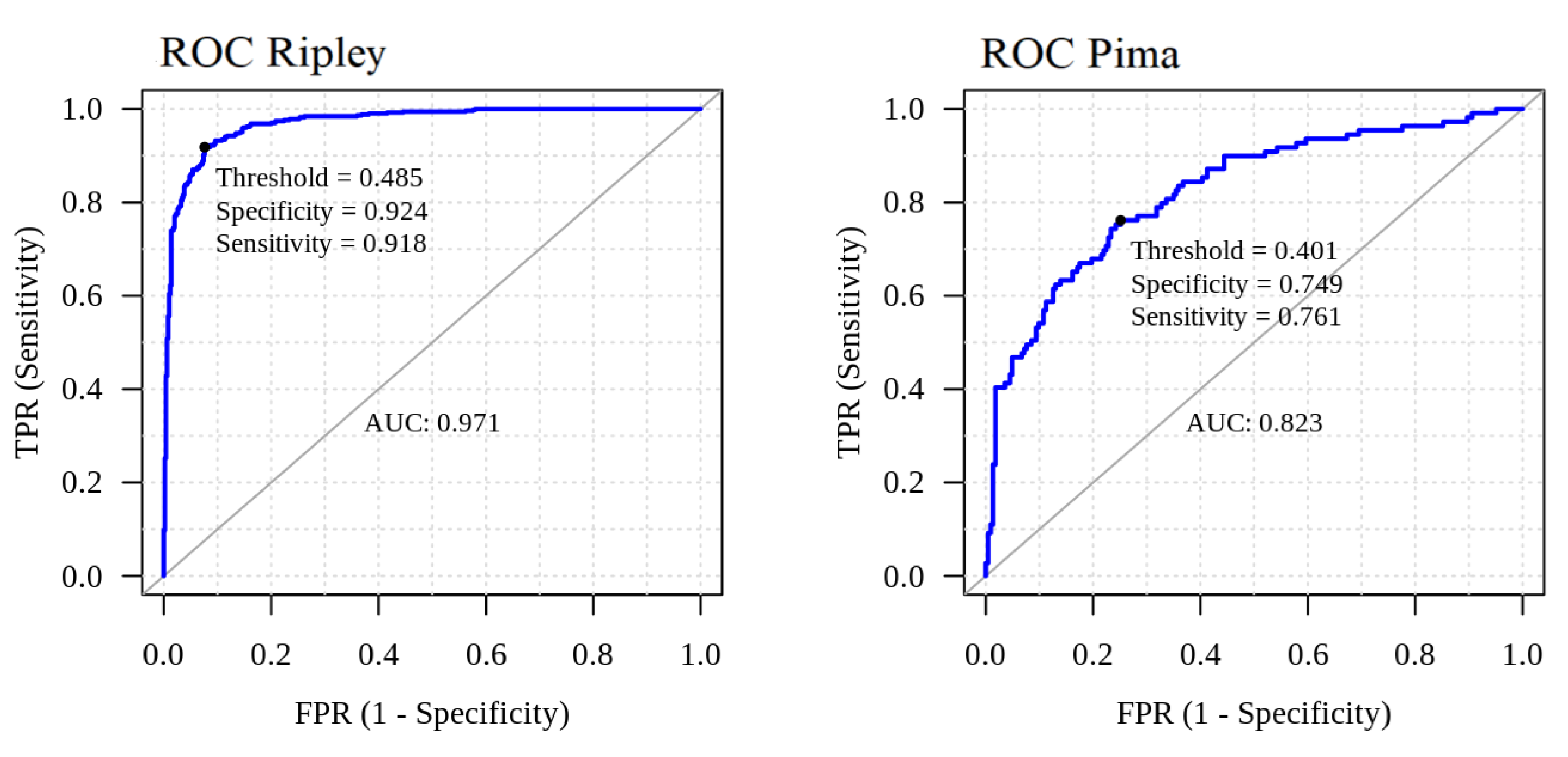
Section 4, yielding a predictive distribution that does not rely on costly Monte Carlo approximations. We run experiments with synthetic and real datasets, showing that our model achieves the predictive performance of the Cucala et al. model, with a more manageable computational cost. We present our conclusions in
Section 5.
2. A Case of Intractable Normalization
This section sets the environment for the general classification problem discussed in this paper. We begin in
Section 2.1 with the definition of the Cucala et al. Bayesian nearest neighbors classification model, whose normalizing constant requires an exponential number of operations for brute force calculation. We indicate the Monte Carlo techniques used by the authors to sample from the model posterior distribution, as well as the approximations made to circumvent the computational complexity issues.
Section 2.2 reviews briefly the fundamental concepts of the theory of computational complexity, ending up with the characterization of NP-complete decision problems, which are considered intractable.
Section 2.3 establishes by an elementary argument a connection between the summation of the normalizing constant appearing on the likelihood of the Cucala et al. model and one of the classical NP-complete problems. In a nutshell, we show that the availability of an algorithm to exactly compute the normalizing constant of the Cucala et al. model in polynomial time in an ordinary computer would imply that all so-called NP problems could also be solved in polynomial time under equivalent conditions.
2.1. The Cucala et al. Model
Suppose that we have a size n training sample such that for each sample unit we know the value of a vector of predictor variables and a response variable belonging to a set of class labels . Some notion of proximity between training sample units is given in terms of the corresponding vectors of predictors. For example, we may use the Euclidean distance between the vectors of predictors of every pair of training sample units to establish a notion of neighborhood in the training sample. Given this neighborhood structure, let the brackets denote the index of the sample unit in the training sample that is the r-th nearest neighbor of the i-th sample unit, for , and .
Introducing the notations
and
, the Cucala et al. model [
5] is defined by the joint distribution
in which
and
are model parameters and
denotes an indicator function. Notice that dependence on the predictors occurs through the neighborhood brackets
, which are determined by the
’s. The model normalizing constant is given by
From this definition, we see that direct (brute force) summation of
would involve an exponential number of operations (
). The much more subtle question about the possible existence of an algorithm that would allow us to exactly compute
in polynomial time is addressed in
Section 2.3.
In their paper [
5], the authors relied on a series of techniques to implement Markov Chain Monte Carlo (MCMC) frameworks in the presence of the seemingly intractable model normalizing constant
. They developed solutions based on pseudo-likelihood [
7], path sampling [
8,
9] (which essentially approximates
using a computationally intensive process, for each value of the pair
appearing in the iterations of the underlying MCMC procedure) and the Møller et al. auxiliary variable method [
10]. Although there is currently no publicly available source code for further experimentation, at the end of Section 3.4 the authors report computation times ranging from twenty minutes to more than one week for the different methods using compiled code. We refer the reader to [
5] for the technical details.
2.2. Computational Complexity
Informally, by a deterministic computer we mean a device or process that executes the instructions in a given algorithm one at a time in a single-threaded fashion. A decision problem is one whose computation ends with a “yes” or “no” output after a certain number of steps, which is referred to as the running time of the algorithm. The class of all decision problems, with the input size measured by a positive integer n, for which there exists an algorithm whose running time on a deterministic computer is bounded by a polynomial in n, is denoted by P. We think of P as the class of computationally “easy” or tractable decision problems. Notable P problems are the decision version of linear programming and the problem of determining if a number is prime.
A nondeterministic computer is an idealized device whose programs are allowed to branch the computation at each step into an arbitrary number of parallel threads. The class of nondeterministic polynomial (NP) decision problems contains all decision problems for which there is an algorithm or program that runs in polynomial time on a nondeterministic computer. An alternative and equivalent view is that NP problems are those decision problems whose solution is difficult to find but easy to verify. We think of NP problems as the class of computationally “hard” or intractable decision problems. Notable NP problems are the Boolean satisfiability (SAT) problem and the travelling salesman problem. Every problem in P is obviously in NP. In principle, for any NP problem, it could be possible to find an algorithm solving the problem in polynomial time on a deterministic computer. However, a proof for a single NP problem that there is no algorithm running on a deterministic computer that could solve it in polynomial time would establish that the classes P and NP are not equal. The problem of whether P is or is not equal to NP is the most famous open question of theoretical computer science.
Two given decision problems can be connected by the device of polynomial reduction. Informally, suppose that there is a subroutine that solves the first problem. We say that the first problem is polynomial time reducible to the second if both the time required to transform the first problem into the second and the number of times the subroutine is called are bounded by a polynomial in n.
In 1971, Stephen Cook [
11] proved that all NP problems are polynomial-time-reducible to SAT, meaning that 1) no NP problem is harder than SAT and 2) a polynomial time algorithm that solves SAT on a deterministic computer would give a polynomial time algorithm solving every other NP problem on a deterministic computer, ultimately implying that P is equal to NP. In general terms, a problem is said to be NP-complete if it is NP and all other NP problems can be polynomial-time reduced to it, and SAT was the first ever problem proven to be NP-complete. In a sense, each NP-complete problem encodes the quintessence of intractability.
2.3. and NP-Completeness
Let
be an undirected graph, in which
V is a set of vertices and
E is a set of edges
, with
. Given a function
, we refer to
as the weight of the edge
. A cut of
G is a partition of
V into disjoint sets
and
. The size of the cut is the sum of the weights of the edges in
E with one endpoint in
and one endpoint in
. The decision problem known as the
maximum cut can be stated as follows: for a given integer
m, is there a cut of
G with size at least
m? Karp [
12] proved that the general maximum cut problem is NP-complete. In what follows, we point to an elementary link between the exact summation of the normalizing constant
of the Cucala et al. model and the decision of an associated maximum cut problem.
Without a loss of generality, suppose that we are dealing with a binary classification problem in which the response variable
, for
. Define the
matrix
by
if
j is one of the
k nearest neighbors of
i, and
otherwise. Letting
, this is the adjacency matrix of a weighted undirected graph
G, whose vertices represent the training sample units, and the edges connecting these vertices may have weights zero, one, or two, based on whether the corresponding training sample units do not belong to each other’s
k-neighborhoods, just one belongs to the other’s
k-neighborhood, or both are part of each other’s
k-neighborhoods, respectively. The double sum in the exponent of
can be rewritten as
for every
. Furthermore, each
corresponds to a cut of the graph
G if we define the disjoint sets of vertices
and
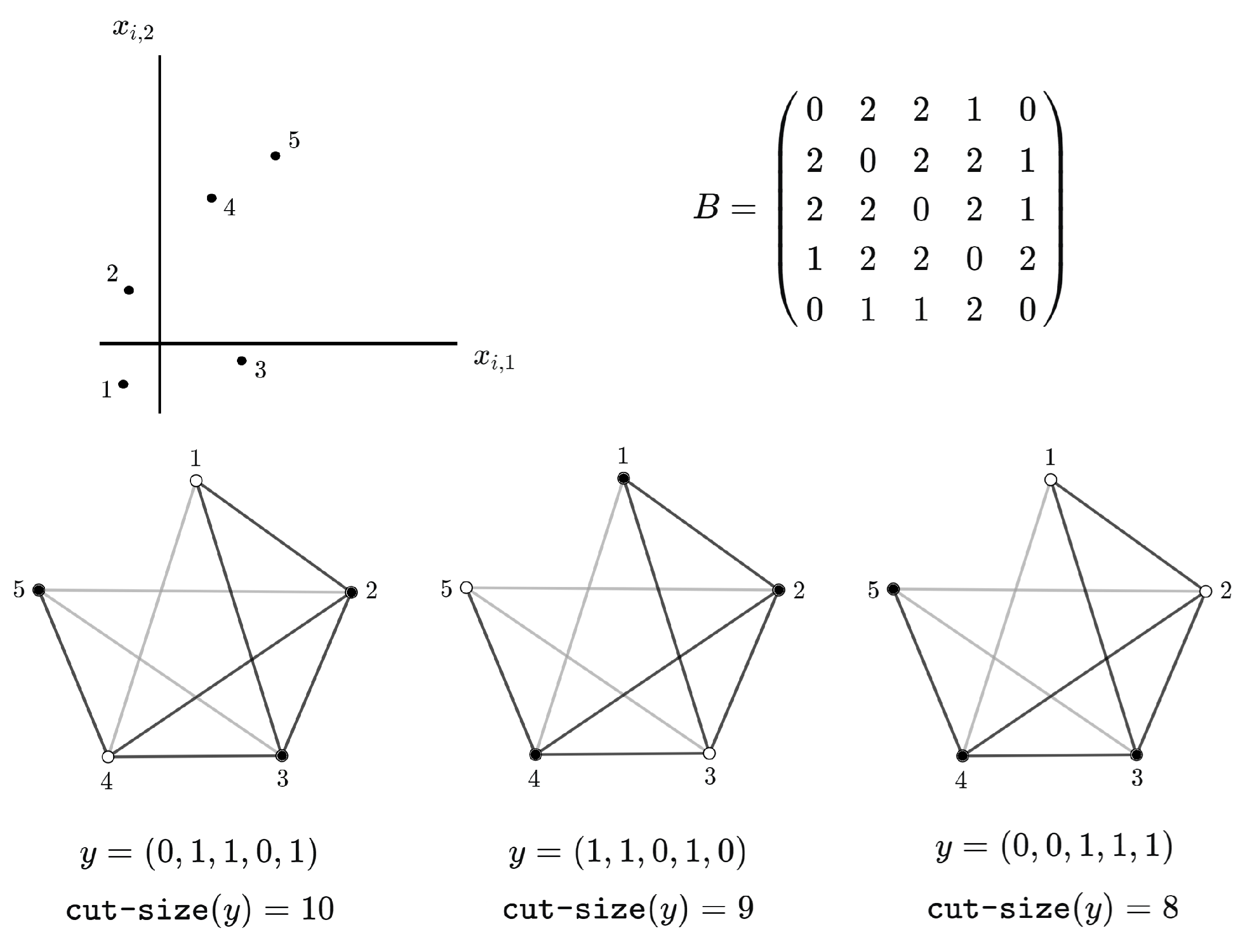
. The respective cut size is given by:
Since for every
we have that
it follows that
Figure 1 gives an example for a specific neighborhood structure involving the three nearest neighbors with respect to Euclidean distance.
By grouping each possible value of
in the sum over
appearing in the definition of
, we obtain the alternative polynomial representation
in which
and
, for
. Note that
is the number of vectors
such that
, and from
we have that
is also the number of possible cuts of the graph
G with size
.
Suppose that we have found a way to sum
in polynomial time on a deterministic computer, for every possible value of
and
k and any specified neighborhood structure. By polynomial interpolation (see [
13]), we would be able to compute the value of each coefficient
in polynomial time, thus determining the number of cuts of
G with all possible sizes, thereby solving any maximum cut decision problem associated with the graph
G. In other words: the existence of a polynomial time algorithm to sum
for an arbitrary neighborhood structure on a deterministic computer would imply that P is equal to NP.
3. Nonlocal Models Are Tractable
This section introduces a family of models that are related to the Cucala et al. model but differ in two significant ways. First, making use of a physical analogy, while the likelihood function of the Cucala et al. model is such that each sampling unit “interacts” with all of its
k nearest neighbors, for the models introduced in this section each sampling unit interacts only with its
r-th nearest neighbor, for some
. Keeping up with the physical analogy, we say that we a have a family of nonlocal models (for the sake of simplicity, we are abusing terminology a little bit here, since the model with
is perfectly “local”). Second, the nice fact about the nonlocal models is that their normalizing constants are tractable; the main result of this section being an explicit analytic expression for the normalizing constant of a nonlocal model that is computable in polynomial time. The purpose of these nonlocal models is to work as building blocks for our final aggregated probabilistic predictive model in
Section 4.
For
, the likelihood of the
r-th nonlocal model is defined as
in which the normalizing constant is given by
with parameter
.
In line with what was pointed out in our discussion of the normalizing constant of the Cucala et al. model, brute force computation of is also hopeless for the nonlocal models, requiring the summation of an exponential number of terms (). However, the much simpler topology associated with the neighborhood structure of a nonlocal model can be exploited to give us a path to sum analytically, resulting in an expression that can be computed exactly in polynomial time on an ordinary computer.
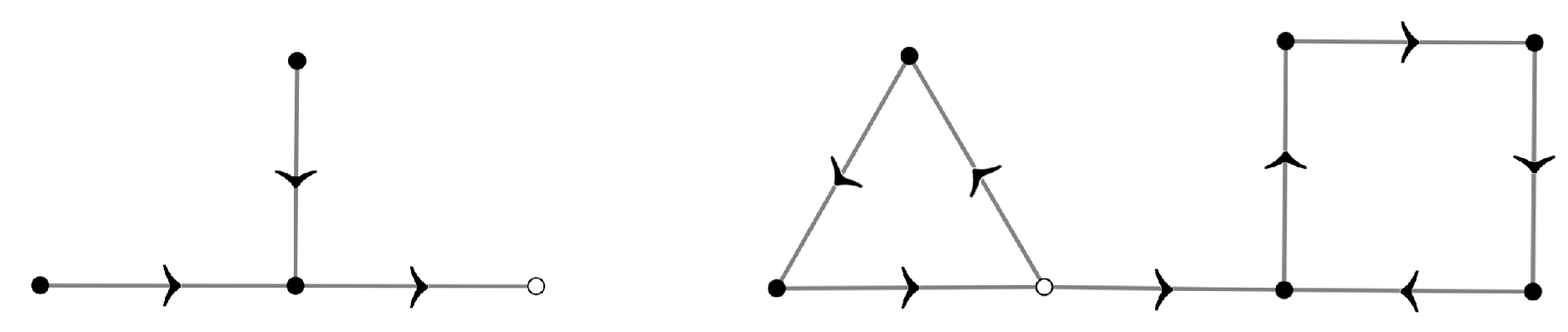
Throughout the remainder of this section, our goal is to derive a tractable closed form for the normalizing constant . For the r-th nonlocal model, consider the directed graph representing the associated neighborhood structure of a given training sample. For , each vertex corresponds to one training sample unit, and the existence of an oriented edge , represented pictorially by an arrow pointing from i to j, means that the j-th sample unit is the r-th nearest neighbor of the i-th sample unit.
An example is given in
Figure 2 for the nonlocal models with
and
. We see that in general
G can be decomposed into totally disconnected subgraphs
, meaning that vertices in one subgraph have no arrows pointing to vertices in the other subgraphs. If
, we use the notation for the multiple sum
Since
the normalizing constant
can be factored as a product of summations involving only the
’s associated with each subgraph:
For each subgraph, starting at some vertex and following the arrows pointing to each subsequent vertex, if we return to the first vertex after
m steps, we say that the subgraph has a simple cycle of size
m. The outdegree of a vertex is the number of arrows pointing from it to other vertices; the indegree of a vertex is defined analogously.
Figure 3 depicts the fact that each subgraph has exactly one simple cycle: in a subgraph without simple cycles, there would be at least one vertex with outdegree equal to zero. Moreover, a subgraph with more than one simple cycle would have at least one vertex in one of the simple cycles pointing to a vertex in another simple cycle, implying that such a vertex would have outdegree equal to two. Both cases contradict the fact that every vertex of each subgraph has outdegree equal to one, since each sample unit has exactly one
r-th nearest neighbor.
Figure 4 portrays the reduction process used to perform the summations for one subgraph. For each vertex with indegree equal to zero, we sum over the correspondent
and remove the vertex from the graph. We repeat this process until we are left with a summation over the vertices forming the simple cycle. The summation for each vertex
i with indegree equal to zero in this reduction process gives the factor
because—and this is a crucial aspect of the reduction process—in this sum the indicator is equal to one just for a single term, and it is equal to zero for all the remaining
terms,
whatever the value of . Summation over the vertices forming the simple cycle is performed as follows. Relabeling the indexes of the sample units if necessary, suppose that the vertices forming a simple cycle of size
m are labeled as
. Defining the matrix
by
, we have
By the spectral decomposition [
14], we have that
, with
. Therefore,
, implying that
, in which we used the cyclic property of the trace, and the
’s are the eigenvalues of
S, which are easy to compute: the characteristic polynomial of
S is
yielding
For the
r-th nonlocal model, let
be the number of simple cycles of size
m, considering all the associated subgraphs. Algorithm 1 shows how to compute
, for
and
, in polynomial time. Taking into account all the subgraphs, and multiplying all the factors, we arrive at the final expression:
| Algorithm 1 Count the occurrences of simple cycles of different sizes on the directed subgraphs representing the neighborhood structures of all nonlocal models |
Require: Neighborhood brackets .
|
- 1:
function count_simple_cycles() - 2:
- 3:
for do - 4:
- 5:
for do - 6:
next if - 7:
- 8:
- 9:
while do - 10:
- 11:
- 12:
- 13:
end while - 14:
- 15:
while do - 16:
- 17:
if then - 18:
- 19:
break - 20:
end if - 21:
- 22:
end while - 23:
end for - 24:
end for - 25:
return - 26:
end function
|







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}