Abstract
The information bottleneck (IB) framework formalises the essential requirement for efficient information processing systems to achieve an optimal balance between the complexity of their representation and the amount of information extracted about relevant features. However, since the representation complexity affordable by real-world systems may vary in time, the processing cost of updating the representations should also be taken into account. A crucial question is thus the extent to which adaptive systems can leverage the information content of already existing IB-optimal representations for producing new ones, which target the same relevant features but at a different granularity. We investigate the information-theoretic optimal limits of this process by studying and extending, within the IB framework, the notion of successive refinement, which describes the ideal situation where no information needs to be discarded for adapting an IB-optimal representation’s granularity. Thanks in particular to a new geometric characterisation, we analytically derive the successive refinability of some specific IB problems (for binary variables, for jointly Gaussian variables, and for the relevancy variable being a deterministic function of the source variable), and provide a linear-programming-based tool to numerically investigate, in the discrete case, the successive refinement of the IB. We then soften this notion into a quantification of the loss of information optimality induced by several-stage processing through an existing measure of unique information. Simple numerical experiments suggest that this quantity is typically low, though not entirely negligible. These results could have important implications for the structure and efficiency of incremental learning in biological and artificial agents, the comparison of IB-optimal observation channels in statistical decision problems, and the IB theory of deep neural networks.
1. Introduction
1.1. Conceptualisation and Organisation Outline
Consider the problem, for an information-processing system, of extracting relevant information about a target variable Y within a correlated source variable X, under constraints on the cost of the information processing needed to do so—yielding a compressed representation T. This situation can be formalised in an information-theoretic language, where the information-processing cost is measured with the mutual information between the source X and the representation T of it, while the relevancy about Y of the information extracted by T is measured by . The problem thus becomes that of maximising the relevant information under bounded information-processing cost , i.e., we are interested in the information bottleneck (IB) problem [1,2], which, in primal form, can be formulated as
Here, the trade-off parameter controls the bound on the permitted information-processing cost and thus, intuitively, the resulting representation’s granularity. The Markov chain condition ensures that any information that the bottleneck T extracts about the relevancy variable Y can only come from the source X. The solutions to (1) for varying trace the so-called information curve, i.e., the -parameterised curve
where and are defined by a bottleneck T of parameter (see the black curve in the first figure in Section 2 below). This curve indicates the informationally optimal bounds on the feasible trade-offs between relevancy and complexity of the representation T. In this sense, the IB method provides a fundamental understanding of the informationally optimal limits of information-processing systems.
These limits are crucial for both understanding and building adaptive behaviour. For instance, choosing X to be an agent’s past and Y to be its future leads it to extract the most relevant features of its environment [3,4,5,6]. More generally, the IB point of view on modelling embodied agents’ representations has been leveraged for unifying efficient and predictive coding principles in theoretical neuroscience—at the level of single neurons [3,7,8,9] and neuronal populations [9,10,11,12,13]—but also for studying sensor evolution [14,15,16], the emergence of common concepts [17] and of spatial categories [18], the evolution of human language [19,20,21], or for implementing informationally efficient control in artificial agents [22,23,24]. This line of research brings increasing support to the hypothesis that, particularly for evolutionary reasons, biological agents are often poised close to optimality in the IB sense. It also provides a framework for both measuring and improving artificial agents’ performance.
However, one aspect of the IB framework conflicts with a crucial feature of real-world systems: the informationally optimal limits that it describes only consider a given representation T taken in isolation from any other one in the system. This point of view a priori disregards the relationship between representations, which is crucial in real-world information-processing systems. Thus, it is crucial to consider the following question: does the relationship between a set of internal representations impact their individual information optimality? In this paper, we are mostly interested in a specific kind of relationship: when are successively produced in this order, and each new builds on both the previous representation and new information from the fixed source X to extract information about the fixed relevancy Y. This scenario formalises the incorporation of information into already learned representations—as is the case in developmental learning, or, more generally, any kind of learning process that goes through identifiable successive steps.
More precisely, consider an informationally bounded agent that extracts information about a relevant variable Y within an environment X. If the agent is informationally optimal, given an affordable complexity cost , it must maximise the relevant information that it extracts from the environment—resulting in a bottleneck representation , i.e., a solution to (1) with parameter . Then, assume that at, a later stage, the complexity cost that the agent can afford increases to , while the goal is still to extract information about the same relevant feature Y within the same environment X. To keep being informationally optimal, the agent should thus update its representation so it becomes a bottleneck of parameter . Given this setting, the question we ask is: to which extent can the content learned into be leveraged for the production of ? It is indeed not intuitively clear that should keep all the information from . An informal example is the fact that most pedagogical curricula teach knowledge via successive approximations, where, at a more advanced level, the content learned at the beginner level must sometimes be unlearned to successively proceed further, even though it was perfectly reasonable—in our language, informationally optimal—to deliver the first beginner sketch to students that would never progress to learn the expert level.
This question has been formalised, in the rate-distortion literature, with the notion of successive refinement (SR) [25,26,27,28,29], which, in short, refers to the situation where several-stage processing does not incur any loss of information optimality. More precisely, in the context outlined above, there is successive refinement if the processing cost of first producing a coarse bottleneck of parameter and then refining it to a finer bottleneck of parameter is no larger than the processing cost of directly producing a bottleneck of parameter without any intermediary bottleneck (see Section 2.1 and Appendix B.2 for formal definitions). The aim of this work is to push the understanding of successive refinement in the IB framework [30,31,32] further, as well as to expand the analysis to a quantification of the lack of SR, in cases where the latter does not hold exactly. We start by leveraging general results in existing IB literature [33,34] to prove that successive refinement always holds for jointly Gaussian , and when Y is a deterministic function of X. However, it is seems crucial, for further progress on more general scenarios, to design specifically tailored mathematical and numerical tools. In this regard, we provide two main contributions.
First, we present a simple geometric characterisation of SR, in terms of convex hulls of the decoder symbol-wise conditional probabilities , for t varying in the bottleneck alphabet . This characterisation is proven in the discrete case under an additional but mild assumption of injectivity of the decoder . This new point of view fits well with an ongoing convexity approach to the IB problem [35,36,37,38,39] and might thus help develop a new geometric perspective on the successive refinement of the IB. As an example, we use this geometric characterisation to prove that SR always holds for binary source X and binary relevancy Y. Moreover, this characterisation makes it straightforward to numerically assess, with a linear program checking convex hull inclusions, whether or not two discrete bottlenecks and achieve successive refinement. As we demonstrate with minimal numerical examples, this can help in investigating the SR structure of any given IB problem, i.e., how successive refinement depends on the particular combination of trade-off parameters and .
Second, we soften [18] the traditional notion of successive refinement and study the extent to which several-stage processing incurs a loss of information optimality. More precisely, we propose to measure soft successive refinement with the unique information [40] (UI) that the coarser bottleneck holds about the source X, as compared to the finer one . Explicitly, this UI is defined as the minimal value of over all distributions whose marginals and coincide with the corresponding bottleneck distributions (see Section 3.1 for details). As a first exploration of soft SR’s qualitative features, we investigate the landscapes of unique information over trade-off parameters, for again some simple example distributions . These landscapes seem to unveil a rich structure, which was largely hidden by the traditional notion of SR, that only distinguished between SR being present or absent. Among the general features suggested by these experiments, the most significant are that soft SR seems strongly influenced by the trajectories of the decoders over ; the UI often goes through sharp variations at the bifurcations [41,42,43,44] undergone by the bottlenecks (in a fashion compatible with the presence of discontinuities of either the UI itself, or its differential, with regard to trade-off parameters); and the loss of information optimality seems always small—more precisely, the global bound on the UI was observed to be typically one or two orders of magnitude lower than the system’s globally processed information (see Section 3.2 for formal statements). These three conclusions are phenomenological and limited to our minimal examples, but they shed light on the kind of structure that can be investigated by further research. They also suggest the relevance that developing this theoretical framework might have for the scientific question that motivates it. In particular, the link with IB bifurcations and the overall small loss of information optimality would, if generalisable, have interesting consequences for the structure and efficiency of incremental learning.
As a side contribution, we draw along the paper formal equivalences between our framework and other notions proposed in the literature, thus making the formal framework also relevant to decision problems [40,45] and to the information-theoretic approach to deep learning [46]. This flexibility of interpretation stems from the fact that even though our formal framework crucially depends on the order of the bottleneck representations’ trade-off parameters, it does not depend on the order in which these representations are produced. Thus, a sequence of bottlenecks can be equally well interpreted as produced from coarsest to finest—as is the case for the information incorporation interpretation outlined above—or from finest to coarsest—as is the case in feed-forward processing. This conceptual unity sheds light on the common formal structure shared by these diverse phenomena.
In the next Section 1.2, we review related work. After having established notations and recalled some general notions in Section 1.3, we formally introduce the notion of the successive refinement of the IB in Section 2.1, where we also prove successive refinability in the case of Gaussian vectors and deterministic channel . We then present the convex hull characterisation in Section 2.2, before using it to prove successive refinement for the case of binary source and relevancy variables. The following Section 2.3 leverages the convex hull characterisation to gather some first insights from minimal experiments. These experiments suggest an intuition for defining soft successive refinement, which we formalise in Section 3.1 through a measure of unique information [40], where we provide theoretical motivations for our choice. This new measure is explored in Section 3.2 with additional numerical experiments that highlight the general features described above. The alternative interpretations of both exact and soft SR, in terms of decision problems and feed-forward deep neural networks, are developed in Section 4.1 and Section 4.2, respectively. We then describe the limitations and potential future work in Section 5, and conclude in Section 6.
1.2. Related Work
The notion of successive refinement has been long studied in the rate-distortion literature [25,26,27,28,29]. However, classic rate-distortion theory [47] usually considers distortion functions defined on the random variables’ alphabets, whereas the IB framework can be regarded as a rate-distortion problem only if one allows the distortion to be defined on the space of probability distributions [48]. Successive refinement thus needed to be adapted to the IB framework, which was achieved starting from various perspectives.
In [30,31], successive refinement is formulated within the IB framework. Then, Ref. [32] goes further by considering the informationally optimal limits of several-stage processing in general, without comparing it to single-stage processing. In both these works, the problem is initially defined in asymptotic coding terms, and only then given a single-letter characterisation. On the contrary, we will directly define successive refinement from a single-letter perspective. It turns out that our single-letter definition and the operational multi-letter definition from [30,31] are equivalent. The two latter works—as well as [32]—thus provide our single-letter definition with an operational interpretation that also formalises the intuition of an informationally optimal incorporation of information (see Proposition 1 and Appendix B.2).
Another notion named “successive refinement” as well can be found in [46]. This work, instead of modelling information incorporation, rather considers the successive processing of data along a feed-forward pipeline—which encompasses the example of deep neural networks. Fortunately, the “successive refinement” defined in [46] happens to encompass the notion we develop here; more precisely, in [46], the relevancy variable is allowed to vary across processing stages, but if we choose it to be always the same, then “successive refinement” as defined in [46] and “successive refinement” as defined here are formally equivalent (see Section 4.2). In other words, the situation considered in this paper is a particular case of [46], so our results, methods, and phenomenological insights are directly relevant to [46]. For instance, our proof of SR for binary X and Y (see Proposition 5) is a generalisation of Lemma 1 in [46], which proves SR when X is a Bernoulli variable of parameter and is a binary symmetric channel.
More generally speaking, the link between successive refinement and the IB theory of deep learning [49,50,51,52,53,54,55,56] has been noted since the inception of the latter research agenda [49], and, besides in [46], it was also further developed in [57]. Section 4.2 makes clear in which sense our results are relevant to this line of research. In particular, our minimal experiments suggest (if they are scalable to the much richer deep learning setting) that trained deep neural networks should lie close to IB bifurcations: i.e., if X is the network’s input, Y the feature to be learnt and the network’s successive layers, the points should lie close to points of the information curve corresponding to IB bifurcations. This feature was already suggested in [49,50], but for reasons not explicitly related to successive refinement. Note that while the phenomenon of IB bifurcations has been studied from a variety of perspectives (see, e.g., [41,42,43,44]), here, we adopt that of [43], which frames IB bifurcations as parameter values where the minimal number of symbols required to represent a bottleneck increases.
In [58], successive refinability is proved for discrete source X and relevancy . Our Proposition 3 generalises this result to either discrete or continuous source X, with relevancy Y being an arbitrary function of X, with a similar argument as that in [58].
In [33], links between the IB framework and renormalisation group theory are exhibited. Even though the questions addressed in the latter work are thus distinct from those addressed here, the Gaussian IB’s semigroup structure defined and proven in [33] implies the successive refinability of Gaussian vectors (see Proposition 2, and see Appendix 2 for more details on the semigroup structure). This generalises Lemma 3 in [46], which proves SR when X and Y are jointly Gaussian, but each one-dimensional (see Section 4.2 for the relevance of [46] to our framework).
The geometric approach in which we propose to study the successive refinement of the IB is closely related to the convexity approach to the IB [35,36,37,38,39], which frames the IB problem as that of finding the lower convex hull of a well-chosen function. This formulation happens to fit neatly with our convex hull characterisation of successive refinement; we use it to apply the characterisation to proving successive refinability in the case of a binary source and relevancy. Moreover, it is worth noting that our convex hull characterisation makes successive refinement tightly related to the notion of input-degradedness [59], through which additional operational interpretations can be given to successive refinement, particularly in terms of randomised games.
The loss of information optimality induced by several-stage processing has already been studied in [60] (see next paragraph), but a quantification of it based on soft Markovianity was, to the best of our knowledge, only considered in [18]. Here, we take inspiration in the latter work to quantify soft successive refinement, but we explicitly address the problem that joint distributions over distinct bottlenecks are not uniquely defined. This leads us to use the unique information defined in [40] within the context of partial information decomposition [61,62,63,64] as our measure of soft SR. This unique information has tight links with the Blackwell order [45,65], which allows us in Section 4.1 to provide a second alternative interpretation of (exact and soft) successive refinement in terms of decision problems.
Ref. [60] proves the near-successive refinability of rate-distortion problems when the distortion measure is the squared error. However, the latter work’s approach is different from ours in two respects. First, the distortion measures are different: in particular, as mentioned above, the IB distortion is defined over the space of probability distributions on symbols, unlike the squared error, which is defined on the space of symbols itself. Second, Ref. [60] quantifies the lack of SR as the respective differences between sequences of optimal rates (for given distortion sequences) of a several-stage processing system and the corresponding optimal rates (for the same distortions) of a single-stage processing system. Here, we quantify the lack of SR with a single quantity: the unique information defined by bottlenecks with different granularities. We are, at this stage, not aware of a link between this value of unique information and differences in one-stage and several-stage optimal rates.
1.3. Technical Preliminaries
In this section, we fix the notations and conventions that we will use along the paper and recall some general notions that we will need.
1.3.1. Notations and Conventions
The random variables are denoted by capital letters, e.g., X, their alphabets by calligraphic ones, e.g., , and their symbols by lower-case letters, e.g., x. Sometimes, we will mix upper- and lower-case notations to denote a family where some symbols vary, while others are fixed, e.g., , or . Throughout the whole paper, X is the fixed source and Y the fixed relevancy of the IB problem. The variable T defined by the solution to the primal IB problem (1) is called a primal bottleneck. We use the same symbol T for Lagrangian bottlenecks, i.e., variables defined by solutions to the Lagrangian bottleneck problem (see Equation (3) below). By “bottleneck” without further specification, we refer to either a primal or Lagrangian bottleneck. The fixed source-relevancy distribution is denoted , and any distribution involving at least one bottleneck is denoted with the letter q, e.g., . When it is necessary to make the trade-off parameter explicit, we index the corresponding objects by , e.g., or . Unless explicitly stated otherwise, the source X, relevancy Y, and any considered bottleneck T are defined as either all discrete or all continuous. Probability simplices, and sometimes some of their subsets are written using the generic symbol ; for instance, the source simplex is denoted by .
Without loss of generality, we always restrict X, Y, and the bottleneck T to their respective supports so that, in particular, all the conditional distributions are unambiguously well-defined, both in the discrete and the continuous case.
1.3.2. General Facts and Notions
The following properties of the IB framework will be useful [35,37]:
- A bottleneck must saturate the information constraint, i.e., solutions T to (1) must satisfy . In other words, the primal trade-off parameter is the complexity cost of the corresponding bottleneck.
- The function is constant for . We will thus always assume, without loss of generality, that .
- In the discrete case, choosing a bottleneck cardinality is enough to obtain optimal solutions. Thus, we always assume, without loss of generality, that , where might occur if needed to make T full support.
To compute bottleneck solutions, instead of directly solving the primal problem (1), following common practice, we will solve its Lagrangian relaxation [66]:
where the complexity-relevancy trade-off is now parameterised by , which corresponds to the inverse of the information curve’s slope [41]. As the information curve is known to be concave, the Lagrangian parameter is an increasing function of the primal parameter . Moreover, we can, without loss of generality, assume that [43]. (Note that when the information curve is not strictly concave, the Lagrangian formulation does not allow one to obtain all the solutions to the primal problem [39,67]. However, in our simple numerical experiments, we always obtained strictly concave information curves.)
We will also need the following concepts [43]:
Definition 1.
Let T be a (primal or Lagrangian) discrete bottleneck. The effective cardinality is the number of distinct pointwise conditional probabilities for varying t.
Definition 2.
A discrete (primal or Lagrangian) bottleneck T is a canonical bottleneck, or is in canonical form, if all the pointwise conditional probabilities are distinct, i.e., equivalently, if , where is the effective cardinality of T.
Our definition of effective cardinality, even though slightly different from the original one in [43], is equivalent to the latter for Lagrangian bottlenecks. And, importantly, every (primal or Lagrangian) bottleneck can be reduced to its canonical form by merging the symbols with identical (see Appendix A.1 for more details). We will be particularly interested in the change of effective cardinality, which has been identified in [43] as characterising the bottleneck phase-transitions, or bifurcations.
In Figure 1, we present examples of bottleneck conditional distributions , visualised as the family of points on the source simplex , where, here, , and the bottleneck is computed with in both examples. However, in Figure 1 (left), there are only two distinct , so there must be two equal pointwise probabilities and ; thus, and the canonical form of T is obtained by merging and . On the contrary, in Figure 1 (right), there are three distinct , so, here, and the bottleneck is already in canonical form.
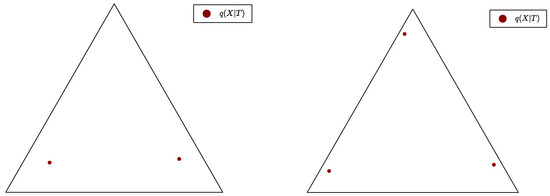
Figure 1.
Examples of distributions , visualised as families of points on the source simplex , where, here, . Each of the triangle’s vertices represents the Dirac probability of some . The bottleneck’s effective cardinality is on the left and on the right.
Eventually, the notions of consistency and extension will be crucial to us.
Definition 3.
Let be a Cartesian product of (continuous or discrete) alphabets. For a subset of coordinates, we write
For each , we consider a subset of coordinates and a probability distribution over . The distributions are said to be consistent if, for every , the respective marginals of and on their common coordinates are equal.
For instance, if and are two bottlenecks, they define consistent distributions and because, by definition, their respective marginals on their common coordinates are .
Definition 4.
Let be a Cartesian product of (continuous or discrete) alphabets, and be consistent probability distributions over distinct but potentially overlapping coordinates of . A distribution q over the whole is called an extension of the family of distributions if it is consistent with each .
Consider bottlenecks of same source X and relevancy Y for resp. parameters . They define a consistent family of distributions . One of the central mathematical objects of this work is the set of their extensions into joint distributions :
Notation 1.
For given bottlenecks of respective parameters , we denote by the set of extensions of the family of distributions .
In general, for a fixed family of bottlenecks, there is a multitude of possible ways to extend them into a joint distribution; indeed, traces a polytope on the simplex of joint distributions (see Appendix A in [40]). This feature is the formal version of our previous statement that the IB framework does not entirely specify the relationship between representations : it only constrains it through the set . Questions about possible relationships between IB representations are thus questions about properties of the set .
2. Exact Successive Refinement of the IB
2.1. Formal Framework and First Results
Here, we formally describe, within the IB framework, the rate-distortion-theoretic notion of successive refinement (SR) [25,26,27,29]. We propose a purely single-letter definition (i.e., we only consider single source, relevancy, and bottleneck variables), which makes the presentation simpler but still conveys the intuition of information incorporation. After having presented the notion of SR in the IB framework, we describe its Markov chain characterisation (see Proposition 1), which mirrors the characterisation of SR for classic rate-distortion problems [26], and makes our formulation equivalent to previous multi-letter operational definitions, which also formalise the intuition of information incorporation [30,31,32]. We then leverage this characterisation to prove SR in the case of Gaussian vectors and deterministic channel .
Intuitively, there is successive refinement when a finer bottleneck does not discard any of the information extracted by a coarser bottleneck . This can be imposed by requiring that for some variable , which encodes the “supplement” of information that “refines” into . In the general case:
Definition 5.
Let , and a discrete or continuous be given. There is successive refinement (SR) for parameters if there exist variables such that
- is a bottleneck with parameter ;
- For every , the variable is a bottleneck with parameter .
Note that even though it does not appear explicitly in this definition, the relevancy variable Y is indeed crucial to it, as it defines what a bottleneck is (see Equation (1)). If the conditions of Definition 5 hold, we will also say that the IB problem defined by is -refinable. If bottlenecks satisfy the definition’s conditions, we will say that they achieve successive refinement, or, simply, that there is successive refinement between these bottlenecks. If there is successive refinement for all combinations of trade-off parameters, we will say that the corresponding IB problem is successively refinable. Eventually, when it will be needed in later sections to contrast this notion with that of soft successive refinement, we will refer to it as exact successive refinement.
For instance, let and . We consider , where ⊕ denotes the modulo-2 addition, and X and Z are Bernouilli variables with parameters and a, respectively, for an arbitrary . In this case, it is proven in Lemma 1 of [46] that, for well-chosen binary variables and , we have that X, , and are mutually independent, and the variables and are bottlenecks of resp. parameters and . Moreover, using the independence of with and the assumed Markov chain , a straightforward computation shows that to get a bottleneck of parameter , the variable can be replaced by . Thus, here, the IB problem is -refinable, where successive refinement is achieved by and .
It is helpful to visualise SR on the information plane, i.e., that on which lies the information curve. Indeed, successive refinement can be understood in terms of specific translations on the information plane: those resulting from concatenating an already existing variable with a new variable —let us call them “accumulative translations” because they result from a processing that does not discard any of the information already collected. Let us focus on the case and first note that, whether or not is a bottleneck, we have
and, similarly,
In other words, the measure of both the complexity cost and relevance for can be decomposed into the same measures first for and then for the “supplement” of information , conditionally on the “already collected” information . In Figure 2 (left and right), we first fix a coarse bottleneck , understood here as a point on the information curve. Once is known, we supplement it with a new variable , which incurs both an additional complexity cost and an additional relevant information gain . The question of successive refinement is that of whether the additional complexity cost can be leveraged enough for the resulting relevant information gain to take “up to the information curve”, i.e., to be such that is on the information curve. This is the case in Figure 2, right, and not the case in Figure 2, left. In short, there is successive refinement between two points on the information curve if and only if there exists an “accumulative translation” from the coarser one to the finer one.
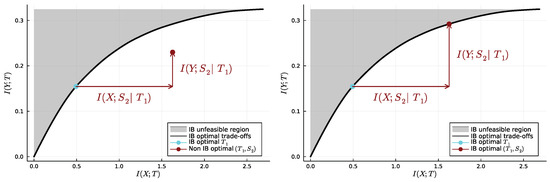
Figure 2.
Successive refinement visualised on the information plane. On the left, adding the information from the variable (the supplement variable) is not efficient enough to achieve successive refinement. On the right, it is. See main text for details (the values of and have been chosen arbitrarily to illustrate each case).
Let us now describe a more formal characterisation, where point will mirror the characterisation of SR for classic rate-distortion problems [26].
Proposition 1.
Let . The following are equivalent:
- (i)
- There is successive refinement for parameters ;
- (ii)
- There exist bottlenecks , of common source X and relevancy Y, with respective parameters , and an extension of the , such that, under q, we have the Markov chain
- (iii)
- There exist bottlenecks , of common source X and relevancy Y, with respective parameters , and an extension of the , such that, under q, we have the Markov chain
Proof.
See Appendix B.1. It is relatively straightforward because we started directly from a single-letter definition. □
Proposition 1 was already known to be a characterisation of SR of the IB [30,31,32]. However, as the latter references start from an operational problem in terms of asymptotic rates and distortions for multi-letter systems, here, Proposition 1 shows that our single-letter Definition 5 is equivalent to the operational definitions in [30,31,32]. See Appendix B.2 for more details.
Remark 1.
Crucially, the order of the indexing in (4) and (5) depends only on the order of the trade-off parameters , and not on the order in which the bottlenecks are produced, which is just the interpretation we started from. In particular, Proposition 1 makes equally legitimate the interpretation of bottlenecks produced from the finest one to the coarsest one, each new bottleneck thus implementing a further coarsening of the source X. This alternative interpretation renders successive refinement relevant to feed-forward processing, including in particular the Blackwell order (see Section 4.1) and deep neural networks (see Section 4.2). For ease of presentation, though, we will stick to the information incorporation interpretation along most of the paper.
Moreover, from Proposition 1, we can leverage existing IB literature to prove the successive refinability of two specific settings. (For an explicit definition of what we mean, in Proposition 2, by successive refinement in the case of the Lagrangian IB problem, see Appendix B.3.)
Proposition 2.
If are jointly Gaussian vectors, then the Lagrangian IB problem defined by is -refinable for all .
This result is a direct consequence of a property named a semigroup structure, and is proven for the Gaussian IB framework in [33], which relates the latter framework with renormalisation group theory. The semigroup structure denotes, in short, the situation where iterating the operation of coarse graining a variable by computing a bottleneck—where, at each iteration, the previous bottleneck becomes the source of the next IB problem—still outputs a bottleneck for the original problem. This semigroup structure is a stronger property than successive refinement and, as it is satisfied in the Gaussian case, this implies the successive refinability of Gaussian vectors (see Appendix B.3 for more details). Beyond Proposition 2, this relationship between successive refinement and the semigroup structure hints at potentially interesting links between the composition of coarse-graining operators and successive refinement. In this respect, note that our numerical results below (see Section 2.3 and Section 3.2) suggest that, for non-Gaussian vectors, successive refinement does not always hold and thus, a fortiori, that the semigroup structure might not always be satisfied in the IB framework—or at least not perfectly.
Eventually, in the case of deterministic channel , an explicit solution to the IB problem (1) is known [34]: with probability , and with probability , for e a dummy symbol, and some well-chosen . This specific solution allows one to address successive refinement for the deterministic case:
Proposition 3.
Let X be a discrete or continuous variable, and Y be a deterministic function of X. Then, the IB problem defined by is successively refinable for all trade-off parameters .
Proof.
See Appendix B.4. A proof was already proposed, from an asymptotic coding perspective, for discrete X and , in [58]. We use a similar argument here. □
Note, though, that the solution used here to prove successive refinement is, as noted in [34], not very interesting: it is nothing more than an increasingly noisy version of Y. It is not clear whether or not there exists more interesting bottleneck solutions in the deterministic case, and if so, whether these other solutions are successively refinable. Proposition 3 will in any case be useful for our own purposes: we will use it to set aside the deterministic case in the proof of SR for binary X and Y (Proposition 5 below).
Until now, we used existing results from the IB literature that, even though not originally aimed at it, happen to yield interesting consequences for the problem of the successive refinement of the IB. However, it seems crucial, for further progress on the latter topic, to design specifically tailored mathematical and numerical tools. This is the purpose of the following sections of this paper; in particular, in the next section, we present a simple geometric characterisation of the IB’s successive refinability.
2.2. The Convex Hull Characterisation and the Case
In this section, we present our convex hull characterisation of successive refinement. We then show its relevance both to numerical computations—thanks to a linear program for checking the condition—and to proving new mathematical results—which we exemplify by proving, thanks to this new characterisation, the successive refinability of binary variables. Here, as in our subsequent numerical experiments in Section 2.3, we will focus on discrete variables and processing stages, even though our results are thought of as a first step towards a generalisation to continuous variables and an arbitrary number of processing stages.
The convexity approach that we propose hinges upon changing the perspective on the IB problem (1) from an optimisation over the encoder channels to an optimisation over the decoder channels ; indeed, (1) can be equivalently presented as the “reversed” optimisation problem
Formulations (1) and (6) yield the same solutions because, through the Markov chain , the joint distribution is equivalently determined by specifying some or specifying some pair that satisfies the consistency condition . This condition says that the source distribution must be retrievable as a convex combination of the , where the weights are given by the .
Moreover, this formulation leads to a crucial intuition concerning the relationship between successive refinement and the set , where, for a set , we denote by the convex hull of E, i.e., the set of points obtained as convex combinations of points in E. First, note that, for a bottleneck T, the set is reduced to a single point if and only if T is independent from the source X. Conversely, coincides with the whole source simplex if and only if T captures all the information from the source, i.e., if . Generalising these extreme cases suggests the intuition that describes the information content held by the bottleneck T about the source X. Now, let us recall that successive refinement from a coarse bottleneck to a finer bottleneck means intuitively that can be obtained without discarding any of the information extracted by about the source X; in other words, that the information content of about the source Xis included in that of . Combining this latter intuition with the one about being the information content of a bottleneck T suggests the following characterisation of successive refinement:
where and are bottlenecks of parameters , respectively. This condition is visualised in Figure 3. The characterisation indeed holds, at least for the discrete case and under a mild assumption of injectivity of the finer bottleneck’s decoder:
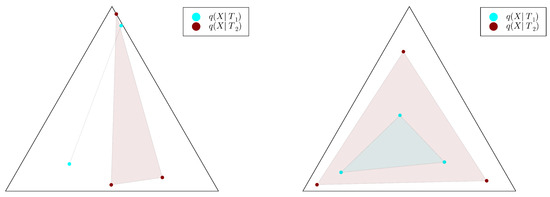
Figure 3.
Illustration of the convex hull condition. The black triangle represents the source simplex with, here, , and the pointwise bottleneck decoder probabilities are represented on it (in cyan for the coarser bottleneck and in red for the finer one ). The convex hull of the respective families of points are shaded with the corresponding color. On the left, the condition is not satisfied; on the right, it is.
Proposition 4.
Let , and assume that is discrete.
If there is successive refinement for parameters , then there exist bottlenecks of parameters , respectively, such that the convex hull condition (7) is satisfied.
Conversely, if there exist bottlenecks of parameters , respectively, such that the convex hull condition (7) holds and such that the decoder , seen as a probability transition matrix, is injective, then there is successive refinement for parameters . Moreover in this latter case, if , are bottlenecks that achieve successive refinement, the extension of and such that holds is uniquely defined.
Proof.
See Appendix B.5. The idea consists in translating the Markov chain characterisation into the convex hull condition (7). The direct sense is straightforward. For the converse direction, observe that, even though as soon as (7) is satisfied it provides a joint distribution that satisfies the Markov chain , it is not clear whether this distribution is consistent with . The potential problem stems from the fact that must be such that the channel maps the marginal to the marginal . The injectivity assumption, however, provides a sufficient condition for it to be the case. This assumption happens to also imply the uniqueness of the extension, among all those that satisfy the Markov chain . □
Even though the injectivity assumption might seem restrictive, in practice, in our numerical experiments below (see Section 2.3 and Section 3.2), we always found that the decoder channel could be chosen as injective by reducing it to its effective cardinality (see Section 1.3)—a process that leaves the convex hull condition (7) unchanged because it leaves the points unchanged. See also Appendix D for a conjecture that, if true, would simplify our convex hull characterisation in the case of a strictly concave information curve.
Remark 2.
The convex hull condition happens to be equivalent to the input-degradedness pre-order on channels (see Proposition 1 in [59]). Even though we will not develop this point further when considering alternative interpretations of SR (Section 4), it is worth noting that, through input-degradedness, SR can be given additional operational interpretations, particularly in terms of randomised games (see Section IV-C in [59]).
Our new characterisation provides a simple way of checking whether or not two bottlenecks and achieve SR. Recall that the Markov chain characterisation (Proposition 1, point ) shows that SR is a feature of the space of all extensions of individual bottleneck distributions and . While this set might, a priori, be difficult to study directly, our characterisation (7) reduces the problem to a simple geometric property relating only two explicitly given conditional distributions: and . Moreover, note that (7) is equivalent to
and that checking whether a point is in the convex hull of a finite set of other points can be cast as a linear programming problem [68]. As a consequence, one can bound the time complexity of checking condition (7) as , where K is the time complexity bound of a linear program with variables and constraints. As a consequence, using the bound on K proved in [69], the time complexity of checking (7) is no worse that , where corresponds to the complexity of matrix multiplication, is the relative accuracy, and the notation hides polylogarithmic factors (see Appendix B.6 for details).
We deem this convex hull characterisation to be important for theory as well. Indeed, it reduces the question of successive refinement to a question about the structure of the trajectories, on the source probability simplex , of the points for varying . Thus, any theoretical progress on the description of these bottleneck trajectories might lead to theoretical progress on the side of successive refinement. As a first step in this direction, we show that this geometric point of view helps to solve the question of SR in the case of a binary source and relevancy (This result generalises the already known fact that there is always successive refinement when X is a Bernoulli variable of parameter and is a binary symmetric channel (see Lemma 1 in [46] and see Section 4.2 for explanations on why the latter work’s framework encompasses ours). Moreover, a potential generalisation of our result to an arbitrary number of processing stages is left to future work).
Proposition 5.
If , then, for any discrete distribution and any trade-off parameters , the IB problem defined by is -successively refinable.
Proof.
Let us here outline the proof presented in Appendix B.7. The case of deterministic was already dealt with in Proposition 3, so we can assume that is not deterministic. In this case, the IB problem with and has been extensively studied in [35]. In short, the latter approach leverages the fact that a pair is a solution to the IB problem (6) if the convex combination of the points , with weights given by , achieves the lower convex envelope of the function , where is a well-chosen function on the source simplex and is the information curve’s inverse slope. This work, along with considerations from [37], which uses the same convexity approach, yields in particular that the points are the extreme points of a non-empty open segment uniquely defined by , and this latter segments grows as a function of the inverse slope and thus, by concavity, as a function of . This implies that the convex hull condition is always satisfied for . As point also implies that, here, must be injective, Theorem 4 allows us to conclude the successive refinability for processing stages. □
The proof of Proposition 5 exemplifies how our convex hull characterisation interlocks well with the convexity approach to the IB [35,36,37,38,39]. In this sense, our characterisation brings a new theoretical tool to the study of the successive refinement of the IB.
2.3. Numerical Results on Minimal Examples
In this section, we leverage our new convex hull characterisation to investigate successive refinement on minimal numerical examples, i.e., with discrete and low-cardinality distributions . Our experiments suggest that, in general, successive refinement does not always hold exactly. However, they also highlight two other features: first, it seems that successive refinement is often shaped by IB bifurcations [41,42,43,44]. Second, even though successive refinement is often not satisfied exactly, visualisations suggest that it is often “close” to being satisfied. The formalisation of this latter intuition will be the topic of the next section.
We consider the Lagrangian form (3) of the IB problem (see Section 1.3). We compute solutions to it with the Blahut–Arimoto (BA) algorithm [1], combined with reverse deterministic annealing [19,70], starting from (i.e., in practice, ) at the IB solution (we noticed that regular deterministic annealing sometimes yielded sub-optimal solutions because they followed sub-optimal branches at IB bifurcations [1,71], which was not the case for reverse annealing). We always obtained that was a strictly increasing function of the Lagrangian parameter , so it makes sense to index the solutions by rather than ; for instance, in this section and Section 3.2, we will write for our algorithm’s output for a such that .
In all our numerical experiments, after reducing a bottleneck T to its canonical form (see Section 1.3), the decoder channel was injective. Therefore, thanks to Theorem 4, the convex hull condition (7) being satisfied here does imply successive refinement. In the remainder of the paper, we will thus use the convex hull condition as a proxy for numerically assessing successive refinement (see Appendix D for more details on what we mean by “proxy”). This condition can be investigated in two ways. First, for two distinct trade-off parameters , we can compute whether the convex hull condition (7) holds or not with the linear program described in Appendix B.6. Second, for , we can visualise the whole trajectories, for varying , of the points on the source simplex . As we will see, this yields interesting qualitative insights.
As a sanity check for our algorithm, we compute bottleneck solutions for binary X and Y, which we proved in Proposition 5 to be successively refinable for all trade-off parameters. We used the linear program to check the convex hull condition numerically for all pairs and for distributions uniformly sampled on the joint probability simplex . We find that the convex hull condition is indeed always numerically satisfied.
Then, we study the case , once again uniformly sampling example distributions on . Figure 4, Figure 5 and Figure 6 show, for representative examples, visualisations of the trajectories over of the (left)—which we will refer to as the bottleneck trajectories—along with the corresponding computations of the convex hull condition as a function of and (right)—which we will refer to as the SR patterns (The correspodning are plotted in Appendix E, and is shown in Figure 4, Figure 5 and Figure 6 (left). The explicit corresponding to each of these paper’s figures can be found at: https://gitlab.com/uh-adapsys/successive-refinement-ib/(accessed on 12 September 2023).
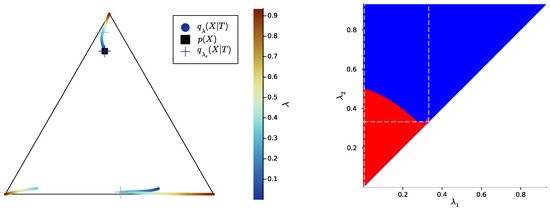
Figure 4.
Left: bottleneck trajectories for an example distribution such that , i.e., trajectory of , represented as the family of points on the source simplex , as a function of (crosses: value of just before a symbol split at a critical parameter , where the crosses’ color corresponds to the value of ). The conditional distribution is defined by the single point when (dark blue cross on the black square), or by two distinct points between the first and second symbol splits (dark blue to cyan), or by three distinct points after the second symbol split (cyan to red). Note the discontinuity of at each symbol split (without the discontinuity, the trajectory around a symbol split would look like a branching). Right: corresponding SR pattern, i.e., corresponding output for the convex hull condition (blue: satisfied; red: not satisfied; dashed white lines: critical values of either or ). For instance, the critical value corresponds, on the bottleneck trajectories (left), to the symbol split from two to three symbols (cyan crosses). Note that . The respective corresponding to this figure and to Figure 5 and Figure 6 are plotted in Appendix E.
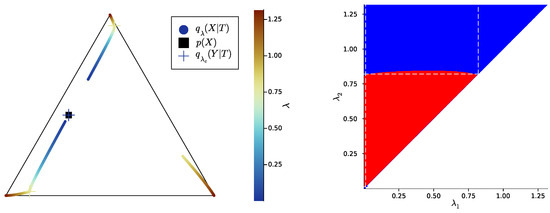
Figure 5.
Same as Figure 4, with a different example distribution such that .
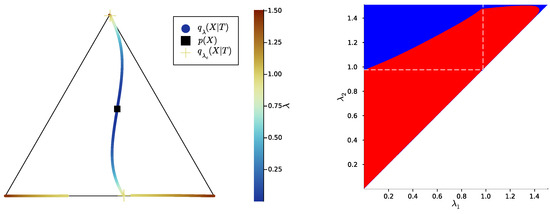
Figure 6.
Same as Figure 4, with a different example distribution such that .
Let us first give a general description of the bottleneck trajectories. For , the all coincide with the source distribution . This should be the case, as, for , the bottleneck T is independent of X. Then, when increases, the trajectories seem piecewise continuous, where each discontinuity corresponds to a symbol split, i.e., a change in effective cardinality (see Section 1.3). We mark with a cross, for each , the located just before such a change in effective cardinality.
In the examples of Figure 4, Figure 5 and Figure 6, as , there are two symbol splits, corresponding to that from one to two and two to three symbols, respectively. Eventually, for large , the last continuous segment of bottleneck trajectories corresponds to effective cardinality , and, for the maximal , each corner of the source simplex is reached by for some . This means that for maximum , there is a deterministic bijective relationship between T and X. The latter is expected: for maximum , bottlenecks are minimal sufficient statistics of X for Y [72]; where for sampled uniformly on the simplex, these minimal sufficient statistics are, with probability 1, just permutations of X.
Definition 6.
In the following, we refer to the piece of trajectory where the bottleneck’s effective cardinality is equal to the integer i as the“segment ”, i.e., it is the segment where corresponds to exactly i distinct points on the source simplex ; for instance, in Figure 4, the segment corresponds to the first piece of trajectory spanning colors from dark blue to cyan.
Notation 2.
We denote by the trade-off parameter’s critical value corresponding to the i-th change in effective cardinality, i.e., the symbol split from i to symbols. Here, we will only need to consider the critical values and , corresponding to the splits from one to two and two to three symbols, respectively.
Let us now come back to the question of successive refinement: for which parameters is the convex hull condition satisfied? The right-hand sides of Figure 4, Figure 5 and Figure 6 provide the answers corresponding to trajectories on the respective left-hand sides—where blue and red mean that the condition is and is not satisfied, respectively. Moreover, we highlight with dashed white vertical and horizontal lines the critical parameter values and , respectively, at which the symbol split occurs (see Appendix B.8 for details on the computation of these symbols splits). Note that we always have , which is expected, as a bottleneck T corresponding to some must necessarily define at least two distinct .
First, in these examples as in most non-reported examples, the convex hull condition (right) breaks as long as , i.e., as long as the finer bottleneck’s effective cardinality is at most . This can also be read from the bottleneck trajectories (left): if the condition was satisfied for all , for instance, then the segment would be a line segment. This is clearly not the case in Figure 4 and Figure 6, and even though visually it virtually seems to be the case in Figure 5, the segment happens to be very slightly curved, which is enough to break the convex hull condition. In other words, for , several-stage processing seems to induce, in these examples, a nonzero loss of information optimality.
Then, for , even though there is no single general pattern, the trajectory’s structure at the bifurcation seems to impact successive refinement. Indeed, at the bifurcation at , the set opens up along a new, third dimension, and keeps widening when increases. This allows it to (gradually in Figure 4 and Figure 6, or virtually straight away in Figure 5) encompass the segment because it “overcomes” the curvature of this piece of trajectory. For instance, in Figure 4, because the segment is strongly curved, the convex hull condition gets satisfied for all only if is significantly larger than . On the contrary, because in Figure 5, the segment is virtually not curved, it is almost as soon as that the convex hull condition is satisfied for all .
In Figure 6, the lack of successive refinement for does not seem to be due to the same phenomenon as the one just described. Generally speaking, we observed a whole variety of SR patterns (see Appendix F for more examples), and our aim here is not to try to interpret all of them. However, despite this diversity, the SR patterns that we studied typically shared a common qualitative feature: the bifurcation structure of the bottleneck trajectories seemingly participates in shaping these SR patterns. Mostly, it seems typically necessary, for SR to hold, that the larger parameter has crossed the bifurcation value , because the non-zero curvature of the segment can only be “overcome” by opening the set along a new dimension, through the symbol split at . This phenomenon will be explored in more details in Section 3.2.
Besides this relationship between SR and the structure of bottleneck bifurcations, this numerical study suggests a generalisation of the notion of successive refinement. Indeed, in Figure 5 for instance, even though the right-hand side asserts that successive refinement does not hold for , the virtually linear piece of trajectory on the left-hand side suggests that this is “almost” the case. In the next section, we formalise this intuition.
3. Soft Successive Refinement of the IB
The minimal experiments from Section 2.3 suggest the intuition that even though successive refinement might not always hold exactly, when broken, it might still be “close” to being satisfied. More generally speaking, let us recall that we are trying here to understand the informationally optimal limits of several-stage information processing. As our numerical experiments suggest that the IB problem is not always successively refinable, it is desirable to quantify the lack of successive refinement—i.e., the lack of informational optimality induced by several-stage processing. These considerations lead to the notion of soft successive refinement [18], which we define and motivate in this section. As we will see, this generalisation of exact SR does not depend on the specific structure of the IB setting; rather, it can also be used as a generalisation of exact SR for any rate-distortion scenario.
3.1. Formalism
Let us first focus on the case : we thus want to quantify the amount of information captured by a coarse bottleneck and then discarded by a finer bottleneck . Let us recall that, from Proposition 1, bottlenecks and achieve successive refinement if there exists an extension of and such that, under q, we have the Markov chain , which is equivalent to . It thus seems natural to quantify soft successive refinement with the conditional mutual information . However, the IB method does not entirely define the relationship between distinct bottlenecks; formally, there is a whole polytope of possible extensions of and (see Section 1.3). Among these possible extensions, it seems natural to search for those that minimise the violation of the SR condition . This leads us to use the unique information [40]
This quantity was already defined in [40] in the context of partial information decomposition [61,62,63,64], and it happens to be relevant to us for several reasons.
First of all, it depends only on the distributions and , which are indeed the only distributions provided by the IB framework. Second, from Proposition 1, there is successive refinement if and only if there are two bottlenecks and such that . Third, it is thoroughly argued in [40] that (8) is a good measure of the information that only , and not , has about X, which is an interpretation that coincides neatly with the intuition that we want to operationalise here. Eventually, Proposition 6 below, which first requires some definitions, provides an information-geometric justification.
Definition 7.
For Δ a probability simplex and , we define
where is the Kullback–Leibler divergence: , if the probability distributions and are defined on the discrete alphabet .
Definition 8.
The successive refinement set is the set of distributions r on such that, under r, the Markov chain holds.
Note that does not require its elements to be extensions of any fixed bottleneck distributions but imposes the Markov chain that characterises SR (see Proposition 1). SR is achieved for bottlenecks if and only if the successive refinement set and the extension set share a common distribution . In general (for ), the following proposition can easily be derived:
Proposition 6.
For fixed distributions , , we have
Proof.
See Appendix C.1. □
In this sense, quantifies “how far” the joint distributions extending the bottlenecks and are from making the successive refinement condition hold true, where the “distance” is understood as a minimised Kullback–Leibler divergence.
Our new measure of soft SR is continuous:
Proposition 7
([73], Property P.7). The unique information is a continuous function of the probabilities and .
Remark 3.
In particular, if has a discontinuity as a function of the parameter or , which define the bottleneck distribution or , respectively, then this can only be a consequence of a discontinuity of the probability as a function of or as a function of , itself, respectively. This consideration will be useful for analysing our numerical experiments in Section 3.2.
Moreover, the formulation (9) of unique information suggests a natural generalisation to an arbitrary number of processing stages:
Definition 9.
Let be bottlenecks with respective parameters , and their respective individual distributions. One can quantify soft successive refinement, or, equivalently, the lack of successive refinement, through the divergence .
While [74] proposes a provably convergent algorithm to compute , to the best of our knowledge, there currently exists no provably convergent algorithm to compute for . Our numerical investigations (see Section 3.2) will stick to the case , but this generalisation makes soft SR in particular, at least conceptually for now, more relevant to deep learning (see Section 4.2).
For the sake of completeness, let us point out that for each , there is a whole set of solutions —or, equivalently, —to the IB problem (1). Thus, the unique information, which is defined as a function of specific bottleneck distributions and , could a priori not be uniquely defined by the corresponding trade-off parameters and . This subtlety is further explained in Appendix D, where we also formulate a conjecture that would prove that, at least in the case of a strictly concave information curve, the trade-off parameters do uniquely define the unique information.
3.2. Numerical Results on Minimal Examples
A provably convergent algorithm that computes, in the discrete case, the unique information (8), was provided in [74]. In this section, we use the authors’ implementation of this algorithm (https://github.com/infodeco/computeUI, accessed on 12 September 2023) to qualitatively investigate, on minimal examples, the landscapes of unique information (UI) and their relationship to the bottleneck trajectories on the simplex.
In Figure 7, Figure 8 and Figure 9 (left), we plot again the same bottlenecks trajectories as in Figure 4, Figure 5 and Figure 6 (left), but compare them this time with the unique information , plotted as a function of and (right). We also plot, in Figure 10, Figure 11 and Figure 12, some representative examples of the exact SR patterns (left) and UI landscapes (right) for slightly larger source and relevancy cardinalities, where is, as above, uniformly sampled — the explicit distributions corresponding to Figure 10, Figure 11 and Figure 12 can be found at https://gitlab.com/uh-adapsys/successive-refinement-ib/. (see Appendix F for additional examples of comparison of the UI landscapes with bottleneck trajectories, and with the exact SR patterns.) Once again, we highlight with dashed white vertical and horizontal lines the critical parameter values and , respectively, where, as expected, . We will first describe, for a fixed , the relative variations in unique information as a function of and . Then, we will compare the absolute values of unique information to the information globally processed by the system.
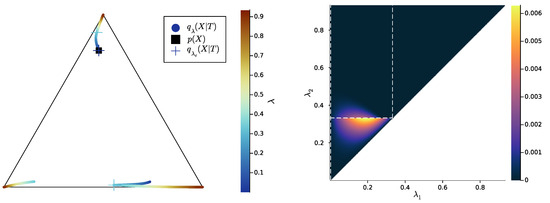
Figure 7.
Left: example trajectory of as a function of (crosses: value of just before a symbol split at a critical parameter ). Right: corresponding unique information, in bits (color), expressed as a function of the pair of trade-off parameters (white dashed lines indicate critical values of either or .). For instance, the critical value (right) corresponds, on the bottleneck trajectories (left), to the symbol split from two to three symbols (cyan crosses). The respective corresponding to this figure and to Figure 8 and Figure 9 are plotted in Appendix E.
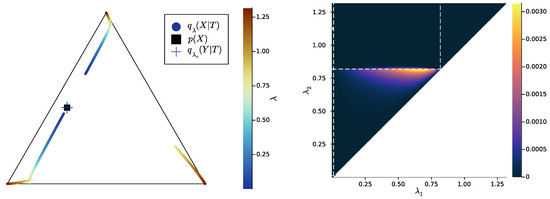
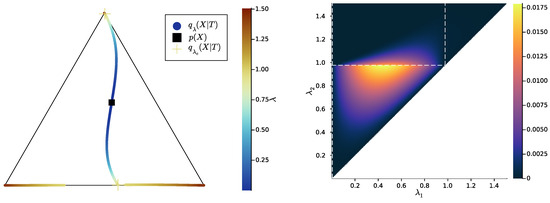
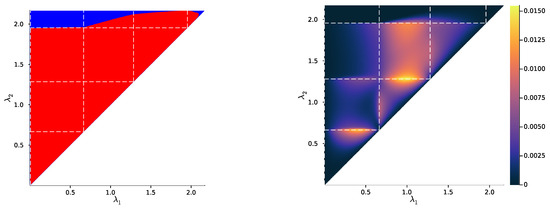
Figure 10.
New example of an exact SR pattern and the corresponding UI landscape over trade-off parameters , where, here, and . Left: exact SR pattern, i.e., output for the convex hull condition (blue: satisfied, red: not satisfied). Right: corresponding UI landscape, in bits (color). White dashed lines indicate critical values of either or . Note that the binary notion of exact SR (left) filters out most of the structure unveiled by UI (right), the UI landscape seems highly impacted by IB bifurcations, and the UI is in any case always small, even though not entirely negligible. See main text for more details.
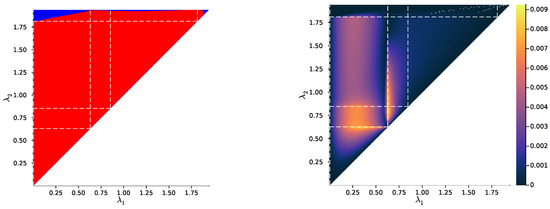
Figure 11.
Same as Figure 10, with a new example distribution , where, here, and . Besides the white orthogonal dashed lines, other white dots correspond to values of for which the algorithm did not converge (see main text for a comment on this lack of convergence).
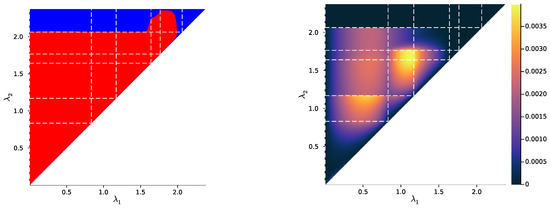
Figure 12.
Same as Figure 10, with a new example distribution , where, here, and .
For all Figures from Figure 7 to Figure 9, the UI landscape partly mirrors the respective exact SR pattern of Figure 4, Figure 5 and Figure 6 (right). However, within the region where these latter figures answered a binary “no” to the question of exact SR, Figure 7, Figure 8 and Figure 9 reveal a sharply uneven variation in the violation of SR, where, for important ranges of trade-off parameters, the unique information is negligible comparative to others. For instance, even though Figure 5 (right) seems to indicate that SR does not hold for , the corresponding UI in Figure 8 (right) is virtually zero on a large part of this set of parameters, while still peaking for close to . This richer structure of the unique information landscape is further evidenced by Figure 10, Figure 11 and Figure 12.
Moreover, the unique information landscapes seem shaped by the bottleneck trajectories. Most importantly, the influence of IB bifurcations on SR can be seen even more clearly with soft than with exact SR. In particular, in Figure 10, Figure 11 and Figure 12, it seems that along the lines where one of the trade-off parameters crosses a critical value, the UI often goes through discontinuities, or at least sharp variations in either , , or both directions. In particular, even though patterns widely vary across different example distributions , unique information can significantly drop when crosses a critical value from below—a feature observed in both shown and non-shown examples. As we know that the unique information is continuous, the apparent discontinuity should be one of the bottleneck probability itself (see Proposition 7 and Remark 3). This is consistent with the observation from Section 2.3 that, at symbol splits, the trajectory of often seems to go through a discontinuity. Further, the fact that the sharp variation in UI is a decrease in this quantity (in increasing order of ) is intuitively consistent with the fact that the bottleneck trajectory’s discontinuity often induces a sudden “widening” (in increasing order of ) of
Indeed, for fixed , when crosses a critical value from below, the corresponding symbol split means that “widens” by opening up a new dimension, so it “more easily” encompasses , yielding as a consequence a drop in unique information. Recalling our intuition (see Section 2.2) that describes the information content that a bottleneck T contains about the source X, the feature just described can be interpreted in the following way: the IB bifurcations seem to induce a sudden “expansion” (in increasing order of ) of the information content carried by the bottleneck about the source, which makes the latter’s content more easily contain the information content of coarser bottlenecks.
Note, however, that these simple numerical results do not allow one to discriminate between the interpretation of the UI’s sharp variations at bifurcations as a discontinuity with regard to trade-off parameters, or a discontinuity of the UI’s differential. For instance, if the derivative with regard to discontinuously takes a value close to for slightly larger than some , then the UI graph can seem discontinuous at finite numerical resolution, even if, formally, only the UI’s differential is so. On the other hand, as an example, bifurcations can be characterised precisely as points of discontinuities of the derivatives, with regard to the trade-off parameter, of and [43,75], even though the functions themselves are continuous [2,75]. A more involved analysis distinguishing discontinuities of UI from those of its differential is left to future work. In any case, the interpretation as a discontinuity of the differential rests on a weaker assumption, which is still sufficient for explaining the numerical results.
More generally, these results suggest that for a several-stage processing that is IB-optimal at each stage, to minimise the information discarded along stages, the trade-off parameters should rather lie close to well-chosen IB bifurcations. If this happens to be a general feature of the IB framework, it would have implications for incremental learning. Indeed, coming back to the modelling of embodied agents (see Section 1), for instance, it would mean that organisms that are poised close to information optimality by evolution should have a very specific structure of developmental learning, where the stages of learning should be discrete and determined by the right trade-off parameters.
Eventually, a last crucial feature was also satisfied on these minimal examples: whatever the structure of bottleneck trajectories, the maximal UI was significantly lower than the mutual information between the external source X and the system’s internal representations . More precisely, for an extension of and that achieves the minimum in (8), let us define
Note that decomposing , where , with the chain rule for mutual information shows that this quantity only depends on and : thus here, is indeed well-defined by and . The maximum ratio over all trade-off parameters was typically of the order of in our minimal experiments; for instance, it was , , , , , and for the IB problems corresponding to Figure 7, Figure 8, Figure 9, Figure 10, Figure 11 and Figure 12, respectively. Among all the (shown and non-shown) studied examples, it never exceeded , and we did not notice an increase in this maximum ratio when the source or relevancy cardinalities were increased (the largest cardinalities that we experimented with were , ). In short, even though several-stage processing might incur a non-negligible loss of information optimality in the IB sense, these results suggest that this loss could often be significantly limited. Of course, here as in Section 2.3, on the one hand, the numerical results are purely phenomenological, and, on the other, it is at this stage far from being clear that the qualitative insights brought by these minimal experiments generalise well to more complex situations. However, they exhibit the potentially crucial qualitative features of exact and soft successive refinement in the IB framework, which can be targeted by further theoretical research.
4. Alternative Interpretations: Decision Problems and Deep Learning
The notion of successive refinement presented in this work builds on the intuition of the optimal incorporation of information. However, alternative interpretations can be given to the very same mathematical notion. First, thanks to the Sherman–Stein–Blackwell theorem [45,65], the rate-distortion-theoretic notion of SR can be shown to be equivalent to a specific order relation between the encoder of the finer bottleneck and that of the coarser one , namely the Blackwell order. This point of view turns SR into an operational decision-theoretic statement; in short, there is SR when, for any task and any source distribution , the optimal performance is better (or at least as good) when decisions are based on the output of than when they are based on the output of . Second, the Markov chain (4) characterising successive refinement makes it directly relevant [46] to the IB analysis of deep neural networks [49,50,51,52,53,54,55,56]. In the next two sections, we make these connections explicit and relate them to this paper’s investigations.
4.1. Successive Refinement, Decision Problems, and Orders on Encoder Channels
Here, we show that exact and soft successive refinement can be, in the discrete case at least, understood in terms of optimally solving decision problems on arbitrary tasks, through orders on the encoder channels (or more precisely, pre-orders: i.e., we will consider binary relations that are reflexive and transitive). We will rely on [45], where these orders were considered.
Let us first make clear what we mean here by a decision problem. Consider a state variable X over a finite set , another finite set of possible actions, and a reward function that depends on both the value x of the state X, and the chosen action . The agent’s observation is not the state X itself, but only the output T of X through some stochastic channel (where we assume here that the observation space is finite). To each observation-dependent policy corresponds an expected reward
where is determined from , through the Bayes rule, and denotes the product measure of and . Solving the decision problem for the observation channel means choosing a policy that yields an optimal expected reward
For instance, any Markov decision process can be seen as a decision problem as defined above (for discrete time and finite state-space, number of possible actions at each state, and horizon). In this case, and are the spaces of state trajectories and observation trajectories, respectively, that an agent can go through along one episode; is the space of action sequences that can be chosen along the episode; and u is the cumulative reward, i.e., the (potentially discounted) sum of rewards obtained at each time-step in the episode. (See, e.g., [76] for more details on the terminology used in this example.)
We can now define the following order [45]:
Definition 10.
For two channels κ and μ, we write , if, for any decision problem , we have
In short, means that, for any conceivable task based on any data distribution over the fixed data space , the observation channel can yield a performance at least as good as that of the observation channel —if combined with a well-chosen policy. The second order is the Blackwell order [65]:
Definition 11.
For two channels κ and μ, we write if there exists a channel η such that , where “∘” denotes the composition of channels, i.e., such that , where , , and are the column transition matrices corresponding to μ, η, and κ.
It turns out that successive refinement can be characterised by either of these two orders, thanks to the Sherman–Stein–Blackwell theorem [45,65]. In other words, SR, which is a priori not a decision-theoretic statement, turns into one through its equivalence with the Blackwell order:
Proposition 8.
Let . The following are equivalent:
- (i)
- There is successive refinement for parameters .
- (ii)
- There are bottlenecks of respective parameters such that
- (iii)
- There are bottlenecks of respective parameters such that
Proof.
Using the Markov chain characterisation (point in Proposition 1), the result is nothing more than a reformulation of Theorem 4 in [45] in the language of the present paper. Note that, to use this theorem, we need to assume that the source X is fully supported, but this is indeed an assumption that we are using along the whole paper because it does not incur any loss of generality (see Section 1.3). □
Let us highlight the intuitive meaning of Proposition 8. Point means that there is SR when the coarse representation can be retrieved by post-processing the finer representation —which has implications in terms of feed-forward processing (see Section 4.2).
Now, the equivalence of SR with point relies on the mathematically deep part of the Sherman–Stein–Blackwell theorem [45], and provides a new operational meaning to SR. Namely, there is SR when, for any distribution on the source, and any reward function, the optimal performance is at least as good when the decisions are based on the output of , seen as an observation channel, than when they are based on the output of . Let us stress that the fact that defines a finer bottleneck than crucially depends on , i.e., on the specific source distribution , and on how the latter relates to the specific relevancy variable through . Proposition 8 shows that SR describes a much more “universal” relation between the channels and .
For example, assume that evolution poises the sensors of a given biological organism at optimality in the IB sense [10,16], i.e., if X is the environment, S some sensor’s output (e.g., a retina’s ganglion cells activation), and Y a behaviourally relevant feature (e.g., the edibility of food), then S is a bottleneck for . Successive refinement here means that if the sensor is finer than as a bottleneck for the fixed feature Y relevant to a particular task, then will afford to the organism—if combined with the right decision making—better performances than on any other task, for any other input distribution . In other words, is then “universally better” than , which is a very strong (and somewhat unexpected) generalisation.
Eventually, the unique information that we chose as our measure of soft SR has initially been thought precisely as measuring the deviation from the order “” (see arguments in [45]). Unique information can thus, for instance, be understood as quantifying the deviation from a finer IB-optimal sensor to be “universally better” than a coarser one.
4.2. Successive Refinement and Deep Learning
As suggested by Remark 1 and Proposition 8-, successive refinement can be equally well understood in terms of feed-forward processing, an interpretation which is particularly relevant to deep neural networks. Indeed, while the information bottleneck theory of deep learning [49,50,51] is still under debate [52,53,54,55,56], our results can be connected to some of this theory’s specific claims concerning the benefits of hidden and output layers’ IB-optimality.
Let denote the successive layers of a feed-forward deep neural network (DNN), which is fed with an input X and attempts to extract, within it, information about a target variable Y,thus satisfying the Markov chain [49]
One of the claims of the IB theory of DNNs [49,50,51] is that, once converged, a DNN’s hidden and output layers lie close to the information curve of the IB problem defined by , with each new layer corresponding to a coarser trade-off parameter. The performance and generalisation abilities of DNNs would rely on this IB-optimality of networks after training. While these claims have been challenged [52,77], the identified caveats have sparked a still ongoing line of research [54,55,56], which suggests that more nuanced versions of the initial claims might still hold. Most importantly for us here, numerical results suggest that layer-by-layer training with the IB Lagrangian as the loss function induces a performance on par with end-to-end training with cross-entropy loss [54], while recent theoretical work proved that the IB trade-off optimises a bound on the generalisation error [56]. In other words, the IB method seems to be relevant at least as a normative, if not descriptive, framework for DNNs. Thus, an interesting informationally optimal limit to compare a given DNN to is a sequence of variables that
- (i)
- Satisfy the Markov chain (10); and
- (ii)
- Are each bottlenecks with source X and relevancy Y, for respective trade-off parameters .
However, it is not clear that variables satisfying those conditions even exist; actually, it is the case if and only if the IB problem is -successively refinable. Indeed, points and are exactly the conditions of point in Proposition 1, with , and the order of trade-off parameters reversed as well. In this sense, the notion of exact successive refinement is relevant to deep learning; in particular—as suggested by the numerical results from Section 2.3—it might well be the case that there is successive refinement only for well-chosen combinations of trade-off parameters. In this case, an IB-optimal DNN should be designed and trained in such a way that its successive layers implement a compression corresponding to these well-chosen trade-off parameters.
Remark 4.
The single-letter formulation above mirrors, in large part, the asymptotic coding version of [46]. More precisely, Ref. [46] defines in asymptotic coding terms a feed-forward processing pipeline where each layer tries to extract, from the input coming from the previous layer, information about a potentially distinct relevancy . Theorem 2 in [46] shows that, for constant relevancy , the notion of “successive refinement” defined there by the authors happens to be equivalent to points and above, and thus to our notion of “successive refinement”. In particular, the deep learning interpretation presented in this section also has an operational formulation in terms of asymptotic coding.
Now, if exact SR describes the situation where each layer of a DNN can potentially reach the information curve, is our notion of soft SR also relevant to deep learning? Note that, here,
- We know that the variables must satisfy , i.e., we know that the joint distribution must be in ;
- And we want to know “how close” we can choose this joint distribution q to one whose marginals coincide with bottleneck distributions , respectively, of parameters , respectively, i.e., we want to know how close we can choose q to the set .
Thus, the quantity can also be interpreted as a measure of the deficiency of a DNN’s layers from all those simultaneously being bottlenecks. Note, however, that, in previous sections, we knew that any joint distribution had to be in the extension set , and wanted to know “how close” to the successive refinement set , in the KL sense, we could choose it. On the contrary, in the case of DNNs, we know that any must be in —because the bottlenecks correspond to a DNN’s layer—and want to know “how close” to we can choose it.
From this perspective, the numerical results of Section 3.2 suggest interesting properties, or at least desirable features, of DNNs. First, if the fact that the UI is typically low generalises well from our minimal investigation to the much richer deep learning setting, this would imply that even in situations where a DNN’s successive layers cannot all lie exactly along the information curve, they might still be able to remain reasonably close to it. Second, the fact that UI (or its differential) seems to go through a discontinuity close to well-chosen bifurcations—such that the UI sharply drops when crosses the bifurcation from below—suggests that, for each layer of the DNN to be individually as IB-optimal as possible, their corresponding trade-off parameters should each lie close to these IB bifurcations. This resonates with previous considerations suggesting that DNNs’ hidden layers should [49] or might indeed do [50] lie at IB bifurcations.
5. Limitations and Future Work
Our convex hull characterisation intertwines the question of exact SR with the more fundamental question of the structure of decoder curves
on the source simplex , a question for which the convexity approach to the IB problem [35,36,37,38,39] seems promising. In short, this approach reformulates the IB problem to that of finding the lower convex envelope of a well-chosen function , defined on the source simplex , and parameterised by the information curve’s inverse slope (see Appendix B.7). More precisely, bottlenecks are essentially characterised by the fact that the lower convex envelope must be achieved by convex combinations of the points ; this approach thus provides analytical tools for proving key properties of the set of trajectories (11), which would then have consequences for SR through the convex hull condition. Despite the limited scope of the result itself, the proof of Proposition 5 gives an example of such a fruitful interaction, thus suggesting a way forward for further theoretical progress. As a first step, one could try to use the convexity approach to the IB to prove our Conjecture 1 about the unicity, up to permutations and injectivity of , for canonical bottlenecks and the strictly concave information curve. This would both simplify our convex hull characterisation of SR for the case of the strictly concave information curve (see Appendix D) and provide in itself a crucial property of the curves (11). Generally speaking, leveraging, through our convex hull characterisation, the convexity approach to the IB problem might allow one to identify new wholly refinable IB problems, but also produce general methods to identify, for a given distribution , the combination of parameters for which exact SR holds.
It must be stressed that even though we motivate the successive refinement of the IB by diverse scientific questions in Section 2 and Section 4, in this work, we do not model any concrete system. Rather, our minimal numerical experiments target the qualitative exploration of the formalised problem. Our results might in turn be relevant for future modelling work (see the last paragraph of this section), but the most pressing aspect is to first develop further the theoretical and computational framework. In particular, it seems important to describe formally the apparent discontinuity of UI (or its differential) as a function of the trade-off parameters and at IB bifurcations (through that of the as functions of ); to describe more formally why the UI tends to peak and then drop close to IB bifurcations; to provide global bounds on UI in general or as functions of the source and relevancy distribution ; or to make formal the informal relationship between the “extent to which” the convex hull condition is broken, and variations in UI. Another interesting contribution would be to provide an asymptotic coding interpretation to unique information; indeed, the deviation from successive refinement is more classically quantified as a difference between asymptotic rates or distortions (see, e.g., [60]), and it is not clear whether or not this interpretation can be made for UI. Numerically speaking, one could design algorithms allowing for the computation of UI for continuous and/or more than two processing stages. Indeed, the algorithm from [74] only encompasses the case of discrete variables and two processing stages. One could, for instance, take inspiration from [74] to formulate the quantity as a double minimisation problem over separate parameters, allowing for an alternating optimisation algorithm.
The deep learning interpretation of (exact and soft) SR depends crucially on some aspects of the ongoing debate on the IB theory of deep learning [49,50,51,52,54,55,56]. In this regard, it would be interesting to directly measure the unique information between different layers of a DNN or determine whether or not having the layers lying close to IB bifurcations does induce better performance or generalisation capabilities.
Let us point out that our framework considers that the source of information X and the target variable Y are the same along all processing stages. More general frameworks could allow for variations in either the source of information (as in the case in temporal series) or the target variable (as is the case in transfer learning). Frameworks for both these kinds of extensions have already been proposed [46,78], and it would be interesting to study if, in these cases as well, the specific nature of the IB problem imprints the informationally optimal limits of several-stage processing.
Eventually, we deem the interpretation in terms of the incorporation of information to be particularly relevant to modelling adaptive behaviour. For instance, for a given developmental or skill-learning problem on a given task, our framework could help in distinguishing situations where the choice of the successive representations’ complexity along incrementally learning the task does not matter (i.e., when there is successive refinement) from situations where these complexities must be minutely weighed, so as to avoid as much as possible the “waste” of cognitive work along the way (i.e., when the unique information is not negligible and unevenly distributed). In the latter case, our framework, once mature, might precisely describe those sequences of representations’ complexity that minimise the “waste” of cognitive work from one learning stage to another, thereby potentially identifying key stages of skill or developmental learning. Future work should keep in mind the horizon of identifying such qualitative features and producing measures capturing the relevant phenomena for experimental research in these areas.
6. Conclusions
Our approach in this paper is three-fold: to bring together in a common framework existing work on the exact successive refinement of the IB and related topics; to develop further this common framework, particularly through a geometric approach to the problem; and to then open up a line of research on the soft successive refinement of the IB.
The formal unity that we make explicit in this paper is mainly that between these three scientific questions: that of informationally optimal incorporation of information—relevant in particular to developmental and skill learning; that of informationally optimal feed-forward processing—relevant in particular to describing and designing deep neural networks (DNNs); and that of channel order in statistical decision theory—which provides clear interpretations of distinct bottlenecks’ comparison in terms of universal informativeness of an agent’s sensor. Indeed, while we focused for most of the paper on the information incorporation interpretation, we saw in Section 4 that the two other ones are as legitimate as the first one.
Once the formal problem is motivated and set, we turn to the mathematical analysis of it. We first note that, for jointly Gaussian vectors or for deterministic , successive refinability can be easily drawn from existing IB literature [33,34]. Then, we propose a new geometric characterisation of SR, which builds on the intuition that what is “known” by a bottleneck is the convex hull of its decoder conditional probabilities. This new point of view, associated with an active approach that reformulates the IB problem as that of finding the lower convex envelope of a well-chosen function [35,36,37,38,39], provides a new tool for theoretical research on this topic. We exemplify this potential fertility by proving, thanks to the combination of our convex hull characterisation with the convexity approach to the IB, the successive refinability of binary source X and binary relevancy Y (Proposition 5). This convex hull characterisation also allows one to numerically investigate SR with a linear program, which can be helpful for computational studies on this topic. Our own minimal numerical experiments suggest that successive refinement does not always hold for the IB, the successive refinement patterns are shaped by IB bifurcations, and even when successive refinement seems to break, sometimes it is “close” to being satisfied, in the sense of the convex hull condition being only “slightly” violated.
To formalise this latter intuition, we propose to soften the traditional notion of SR into a quantification of the loss of information optimality incurred by several-stage processing. For that purpose, we call on the measure of unique information (UI) used in [40]. Intuitively, this quantity measures the information that only the coarser bottleneck , and not the finer one , holds about the source X, and it can be generalised to an arbitrary number of processing stages. Our minimal experiments, in the case of two processing stages, unveil a rich structure of soft SR that was partially hidden by exact SR, which only makes the distinction between vanishing UI (if there is SR) and positive UI (if there is no SR). Even though the UI landscapes depend strongly on the distribution that defines the IB problem, some qualitative features seem to emerge: the “more” the convex hull condition is broken, the higher the unique information; the IB bifurcations crucially shape the UI landscape, with sharp decreases in unique information in particular when the finer trade-off parameter crosses a bifurcation critical value; and in any case, this violation of successive refinement seems to always be mild compared to the system’s globally processed information.
The features exhibited by these numerical experiments offer a “first outlook” of potentially general properties of exact and soft successive refinement for the IB problem, thus providing a guide for future theoretical research. These potential properties might provide interesting perspectives on the scientific questions that motivate the formalism, particularly in terms of the incorporation of fresh information into already learned models, and deep learning. For instance, the apparently important role of bifurcations in exact and soft successive refinement suggests that informationally optimal several-stage learning or processing should ideally be organised along well-chosen “checkpoints” on the information plane. Moreover, if the loss of information optimality induced by this sequential processing is indeed typically low (even though not entirely negligible) for the IB framework, this could be taken as an indication that incremental learning might be made highly efficient. These potential features thus provide a strong incentive to bring the formal framework presented here closer to maturity—for instance, along the lines of research proposed in Section 5.
Author Contributions
Conceptualisation, H.C., N.C.V. and D.P.; methodology, H.C., N.C.V. and D.P.; software, H.C.; validation, H.C., N.C.V. and D.P.; formal analysis, H.C., N.C.V. and D.P.; investigation, H.C., N.C.V. and D.P.; resources, N.C.V. and D.P.; writing—original draft preparation, H.C.; writing—review and editing, H.C., N.C.V. and D.P.; visualisation, H.C.; supervision, N.C.V. and D.P.; project administration, D.P.; funding acquisition, D.P. All authors have read and agreed to the published version of the manuscript.
Funding
H.C. and D.P. were funded by the Pazy Foundation under grant ID 195.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The code that we used for this work can be found at https://gitlab.com/uh-adapsys/successive-refinement-ib/, along with the explicit values of the example distributions that we used to generate our figures.
Acknowledgments
Thanks to Johannes Rauh and Pradeep Banerjee for insightful comments on unique information [40] and the iterative algorithm proposed to compute it in [74].
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| IB | Information Bottleneck |
| SR | Successive Refinement |
| UI | Unique Information |
| DNN | Deep Neural Network |
Appendix A. Section 1 Details
Appendix A.1. Effective Cardinality
In [43], the effective cardinality of a Lagrangian bottleneck T is defined as the number of distinct , whereas it is defined as that of distinct in our Definition 1. However, as mentioned in Section 1.3, both choices happen to be equivalent:
Proposition A1.
Let be a fixed solution to the Lagragian IB problem (3) for some β, where is discrete. The number of distinct and that of distinct are equal.
Proof.
It is proven in [1] that a solution to the Lagrangian IB must satisfy for all , the self-consistent equation
where is the normalisation factor, and
with
Crucially, it is proven in [43] that a given Lagrangian bottleneck T can be reduced to effective cardinality while still being a bottleneck for the same trade-off parameter by merging all bottleneck symbols with equal decoder distributions into a new symbol defined by
Moreover, this merging can also be carried out for primal bottlenecks (this is not a direct consequence of Proposition A1, as it is known that when the information curve is not strictly concave, the primal and Lagrangian problems might not be exactly equivalent [39,67]).
Proposition A2.
Proof.
We thus consider the bottleneck T from Proposition A2’s statement as defined by a pair satisfying . Now, assume that there exist such that . Then,
so that
where . Moreover,
so that, similarly,
Eventually,
where the first equality comes from the fact that is a solution to (A5) (so, in particular, it must satisfy the hard constraints required in the optimisation problem). Let us define the bottleneck on by
and, for all ,
The last line of (A6) can then be rewritten as
Similarly, from (A7), we obtain , while from (A8), we have . In other words, is also a solution to the reparametrised primal bottleneck problem (A5), for the same parameter . Moreover, it is clear that our definition of implies that and for , so is the variable obtained from T by merging the symbols and . The result follows by iterating this argument until all the are distinct. □
Appendix B. Section 2 Details
Appendix B.1. Proof of Proposition 1
: Suppose that there are variables and for such that each is a bottleneck with parameter . Unrolling the iterative definitions of the , we obtain
which implies that, if , then is a deterministic function of ; in other words, given , the variable is independent of any other variable. So, first, we have . Now, assume that for a given i, we have
Given , the variable is independent of any other variable, so, in particular,
Thus, a recurrence from to proves that we do have , where, by assumption, each is indeed a bottleneck of parameter .
: For all i, the Markov chain (5) implies that
where . The Markov chain (5) also implies that these satisfy . Thus, the are also bottlenecks with respective trade-off parameters . But, by construction, they satisfy , where, here, .
. We merely define through the density
From this construction and the fact that each individual bottleneck must by definition satisfy , it is clear that is indeed an extension of the individual bottleneck probabilities . Moreover, by construction, we have
Appendix B.2. Operational Interpretation of Successive Refinement
This section describes the operational interpretation—for the case of discrete variables X, Y—of successive refinement, which was already proposed in [30,31], as well as, in a slightly more general fashion, in [32]. We will here rely on the content from the latter work (even though our notations will be different). We will denote, for a variable Z, by , the concatenation of l i.i.d. variables with the same law as Z.
Definition A1.
For , ann-stage -code consists of n encoder functions
and n decoder functions
For a given source X, the i-th output of the -code will be written
Intuitively, each new encoder extracts additional information from the same source, and, crucially, each new decoder is allowed to rely on all the information encoded until the i-th stage. Note that the output space of the decoder is modelled on that of the relevancy variable because this is the one about which one wants to extract information.
Definition A2.
The relevance-complexity region is the set of tuples such that there exists a sequence of n-stage -codes for all ,
and
Intuitively, for a tuple to be in the relevance-complexity region, there must be an n-stage code such that the i-th encoder adds information at a rate no larger than , and the i-th decoder yields information about the target variable Y no lower than . In other words, the relevance-complexity region is made of all the tuples that are achievable by n-stage codes.
Now, let us give the operational definition of successive refinement. We will denote, for a parameter , by , the maximum value of in the primal IB problem (1).
Definition A3.
Let . An IB problem defined by is said to be operationally successively refinable, or O-SR, for rates , if the tuple
is in the relevance-complexity region.
Intuitively, in the case , assume one is given a total rate to “spend” on encoding a source X. One can choose to encode the source in a single processing stage, yielding at best, after decoding, asymptotic relevant information (see [2]). Alternatively, one can choose to break up the total rate into two rates and , and successively encode potentially different aspects of the source at these rates. Operational SR means that even though this second alternative “spends” the total rate along two distinct stages, it can still, after decoding, also yield asymptotic relevant information of . Naturally, in this case, the relevant information decodable from only the first stage must also be the optimal one, i.e., —otherwise, the “waste” in spending the rate would prevent the second-stage decoder, which partially relies on the information encoded at the first stage, from ever achieving the optimal relevant information .
We then have the following single-letter characterisation:
Proposition A3.
The IB problem defined by is O-SR for rates if and only if there exist variables such that
- We have the Markov chain ;
- The variables are each bottlenecks with respective parameters .
Proof.
This single-letter characterisation is a consequence of Remark 1 in [32], which states the following: a tuple is in the relevance-complexity region if and only if there exist variables such that the Markov chain holds, and such that, for all ,
By simplifying the left-hand side in (A11) through the chain rule for mutual information, defining , and applying the statement with , we obtain that the IB problem is O-SR for rates if and only if there exist variables such that
- We have the Markov chain ; and
- We have, for all ,
However, if point 1 above holds, then, particularly for all , we have the Markov chain . As a consequence, by definition of the primal IB problem (1), the inequality in (A14) can be replaced by an equality, and thus point 2 as a whole can be replaced by the condition that is a bottleneck of parameter for the IB problem defined by . Hence, we are left with points and of Theorem A3’s statement. □
It is worth mentioning that our Proposition A3 is also essentially Theorem 7 in [30], which proves the same single-letter characterisation for the same operational problem—up to the difference that the result is limited to , and that the latter work does not consider any decoder functions . Moreover, Proposition A3 is a consequence of Lemma 4 in [31].
It is clear that the conditions of Theorem A3 are exactly those of Proposition 4-, so the operational Definition A3 and the single-letter Definition 5 are equivalent; in other words, the notion studied in our work does have an operational interpretation. Crucially, the operational construction of Definitions A1–A3 also goes clearly along the interpretation in terms of the successive incorporation of information.
Appendix B.3. Proof of Proposition 2
First of all, note that even though in the Definition 5 of successive refinement, the term “bottleneck” refers to a solution to the primal problem (1), the definition makes as much sense if now by “bottleneck” we mean a solution to the Lagrangian problem (3). This is, therefore, what we will be speaking about in this section. With this Lagrangian version, the Markov chain characterisation given by Proposition 1 still holds. More precisely:
Proposition A4.
Let be jointly Gaussian, and . The following are equivalent:
- (i)
- There is successive refinement for Lagrangian parameters .
- (ii)
- There exist Lagrangian bottlenecks , of common source X and relevancy Y, with respective parameters , and an extension of the , such that, under q, we have the Markov chain
Proof.
One can directly verify that the proof given for Proposition 1 (see Appendix B.1) does not involve the explicit form of the IB problem, so the very same proof can be used for the Lagrangian formulation. □
The statement of Proposition 2 is now fully explicit.
(Proof of Proposition 2).
For the case of the Lagrangian IB problem with jointly Gaussian source X and relevancy Y, an analytic solution was given in [75], which proves among other things that the functions and are continuous and increasing, where and are defined by bottlenecks T of Lagrangian trade-off parameter . Let us define
where we must have (see Section 1.3). Moreover, from the continuity of the function , this supremum is a maximum, and from the monotonicity of the latter function, for all , whereas, by definition of , we have for all . Thus, delimits trivial from non-trivial solutions, and we can, without loss of generality, choose .
Let us now turn to the semigroup structure of the Gaussian IB problem, which was both defined and proved in [33]. In short, this structure means that one can compose two Gaussian bottlenecks, while still obtaining a Gaussian bottleneck for the original problem. More precisely, let , and define as the analytical solution to the Lagrangian IB from [75]. This provides one with a joint distribution , which, importantly for us here, happens to define a Gaussian vector as well. Then, we consider a new IB problem with still the same relevancy variable Y, but now with as the source, i.e.,
where . As and Y are jointly Gaussian, the problem above is again a Gaussian IB problem, so we can again analytically define a solution with the formulas from [75], yielding a distribution . The semigroup structure proven in [33] refers to the following feature:
Proposition A5.
Assume that and are built as above, and define the extension of and through
Then, the marginal defines a Lagrangian bottleneck of source X and relevancy Y for some parameter uniquely defined, with .
Thus, we can define a binary operator “∘”, which, for every and , provides the parameter defined by Proposition A5. Ref. [33] gives an explicit formula for this binary operator:
which is well-defined for and , because and imply that . This formula implies the following:
Proposition A6.
Let . For any such that , there exists a such that .
Proof.
Let f denote the function , which is well-defined and continuous on the interval . It is clear from formula (A18) that
On the other hand, note first that as delimits trivial from non-trivial solutions, we have . But, by construction, under q given by Equation (A17), we have the Markov chain . Thus, , i.e., . So, by definition of , we have
i.e.,
Now, Equations (A19) and (A21), combined with the continuity of f, imply that
which yields the result. □
Now let us consider a family of parameters . By iterating Propositions A5 and A6 used together, we obtain that there exist bottlenecks of common source X and relevancy Y, with respective parameters , and an extension of these bottlenecks defined by
By construction, under q, the Markov chain holds. In other words, condition from Proposition A4 is satisfied, which proves the successive refinability of jointly Gaussian vectors for the Lagrangian IB problem.
Appendix B.4. Proof of Proposition 3
Here, for , we denote by the variable defined by
where e denotes a dummy symbol not pertaining to either or . It was proven in [67] that, for every primal parameter , there exists an such that is a bottleneck of parameter . Note that we must have
where the first equality comes the general fact that a bottleneck must saturate the information constraint in (1) (see Section 1.3), and the second equality is a direct computation from (A22). Thus, is a bijective and increasing function of , and it is sufficient, for proving successive refinement, to prove that, for , we can design a joint distribution such that we have the Markov chain
Let us first focus on the case . We define a bottleneck , i.e, we set and then a distribution through
We then define an extension of and through
which implies by construction the Markov chain . But it also implies that
and thus, necessarily, . So, . Thus, we built a joint law such that , which proves successive refinement for the case . The case of arbitrary n follows by direct iteration of the previous reasoning, where one starts from defining through , and then iteratively defines through a well-chosen and the Markov chain condition .
Appendix B.5. Proof of Proposition 4
The result is a consequence of the following general fact, where we will eventually set , , and .
Proposition A7.
Let and be full-support consistent distributions, defined on discrete alphabets and , respectively. Consider the following properties:
- (i)
- There exists an extension of and under which the Markov chain holds.
- (ii)
- For each , there exists a family of convex combination coefficients such that
Then, we always have and, if, moreover, the channel is injective, then we also have , and the extension is uniquely defined.
Note the abuse of notations in the statement of Proposition A7: we write q for both and , which are distinct distributions on partially distinct alphabets, even though they are consistent; in addition, along the proof, context, if not explicit statements, will make clear which distribution we are referring to.
Proof.
Along the proof, we will be using the fact that a probability distribution is equivalent to a family of convex combination coefficients several times; indeed, both notions define a family of non-negative numbers such that their sum equals one.
For all , assumption provides a such that
where the first and fourth equalities use the fact that is an extension of and , and the third equality uses the fact that, under , the Markov chain holds. Let us define . For each , the family is a probability distribution, and thus a family of convex combination coefficients.
We want to design a distribution that is both consistent with and , and satisfies . Thus, such a distribution is wholly defined by , because it must satisfy
where is obtained by marginalising , whereas is obtained from . Assumption provides a candidate: let us define , which makes sense because, for each u, the family is made of convex combination coefficients. From assumption , for all ,
and the corresponding defined through Equation (A24) satisfies the Markov chain .
To prove that is an extension of and , let us prove first that is consistent with . We have
where the first equality is the definition of the marginal ; the second equality uses Equation (A24); and the fourth equality uses (A25). Thus, is consistent with .
Now, let us prove that . This is equivalent to the channel sending the marginal on the marginal :
Lemma A1.
We have if and only if
where and are the column vectors defined by and , respectively, and is the column transition matrix defined by .
Proof.
For all ,
where the first equality is the definition of the marginal , and the second one uses Equation (A24). Thus, for all ,
and, eventually, for all ,
Let us momentarily fix . Since is a probability, there must be some such that . Choosing that , we find that, for the given v, the vector equality implies, through Equation (A27), that the scalar equality . By now applying this reasoning to each , we obtain that implies that
whose matrix formulation is precisely (A26). Conversely, if (A28) holds, then Equation (A27) shows that . □
We now prove that Equation (A26) indeed holds. Let us also write and for the column transition matrices defined by and , respectively. Then, Equation (A25), which, here, is our assumption, can be rewritten as
Thus,
where is the column vector defined by , and the second and third equalities are the matrix versions of the decompositions and , respectively. In other words,
The injectivity of implies that (A26) indeed holds, so, from Lemma A1, we have . We have thus proven that extends both and , so point holds.
Eventually, let us prove the uniqueness. Let be another extension of and such that, under , the Markov chain holds. For the same reasons as above, must satisfy Equation (A24) with replaced by , so is wholly specified by , and is enough to prove that . Now, using the assumptions of consistency and the Markov chain for , we obtain
i.e., in matrix terms, if is the column transition matrix representing ,
Combining this with Equation (A29), we have . In other words, if is the i-th column of , then , which, by injectivity of , means that . Thus, , i.e., .
This ends the proof of Proposition A7.
Now, first of all, note that if we set , and , then point in Proposition A7 is equivalent to the convex hull condition (7).
If there is successive refinement for parameters , then, from Proposition 1, there are bottlenecks of parameters , respectively, such that ; and the direction of Proposition A7 implies that the convex hull condition (7) is satisfied.
Conversely, assume that the convex hull condition is satisfied for some bottlenecks of parameters , respectively, such that is injective. Then, the sense of Proposition A7 shows that there exists a unique extension of and such that we have . We then conclude with the Markov chain characterisation of successive refinement (Proposition 1).
Appendix B.6. Linear Program Used to Compute the Convex Hull Condition (7)
Consider, for points , the condition
A linear program can be used to check whether this condition holds or not; in short, it consists of the first step of the simplex method (see, e.g., [68], Section 5.6), which asserts the existence or not of an initial feasible basis, and computes this basis if it exists. More precisely, let us first note V the matrix whose columns are the points , and define
Then, condition (A32) can be reformulated as
We now consider the linear program defined for the augmented variable
as
where is obtained by appending the identity matrix to M to the right. It can be directly verified that (A33), and thus, equivalently, (A32), holds if and only if the minimum is 0 in the linear program (A34), and that if this is the case, then the first k coordinates of any of the program’s solutions provide coefficients for obtaining u as a convex combination of the .
Now, consider two bottleneck distributions and such that is injective. We want to check the convex hull condition (7), which holds if and only if for every , we have
This condition can be checked, for every fixed , with the linear program described above, where if the condition holds, the algorithm also outputs a family of coefficients such that
Let us define and a joint distribution through
By construction, under q, we have the Markov chain . Moreover thanks to Equation (A36) and the injectivity of , Proposition A7 shows that q is indeed an extension of and . Thus, the linear program above allows one both to check whether or not the convex hull condition holds and, when it does, to obtain Theorem 4’s unique extension such that .
Let us turn to considering the algorithm’s complexity. For each , we want to know if the point , which is made of coordinates, is in the convex hull of points, where we can always choose (see Section 1.3). One can directly verify that the linear program (A34) thus consists of at most variables and equality and inequality constraints. Moreover, we want to check condition (A35) for every , where we can always choose . As a consequence, the time complexity of checking the convex hull condition (7) can be bounded as , where K is the complexity bound of a linear program with variables and constraints. By changing the multiplicative constant in the definition of the notation, the bound clearly simplifies to . Eventually, Ref. [69] shows that
where corresponds to the complexity of matrix multiplication and is the relative accuracy. Here the notation hides polylogarithmic factors: i.e., for two functions f and g defined over positive integers, means that there exists some such that . Overall, the convex hull condition (7) can thus be checked with an algorithm of time complexity no worse than .
Note that as the convex hull condition holds if and only if the linear program’s output is 0 for all , in numerical computations, the threshold for rounding the program’s output impacts the answer. In our numerical experiments, we chose the threshold .
Appendix B.7. Proof of Proposition 5
We will first present the framework developed in [35,37] and the original content of this proof, which starts with Lemma A4 below. A full plan of this proof is presented in the main text.
We already noticed (in Section 2.2) that the primal IB problem (1) can be reformulated as an optimisation over the pairs , i.e., Equation (6). Using the identity , and recalling that a bottleneck T must satisfy [37], we can further reformulate the problem (6) as
where . In particular, we can assume, without loss of generality, that (see Section 1.3), where corresponds to . Similarly as we denoted before by the maximum in the classic IB problem (1), here, we denote by the minimum in (A38). Rather than considering the information curve, i.e., the graph of , and following [35] upon which we rely, here, we consider the graph of , which we will refer to as the conditional entropy (CE) curve. This curve is convex [35], and it is just an affine translation of the information curve. Let us now define, for , the function
where is the column transition matrix defined by the conditional probability . Note that, for , we have . (In this section, we choose notations close to those from [37], as long as they do not clash with the ones we already established; most notably, what we denote here by would correspond to in [37].)
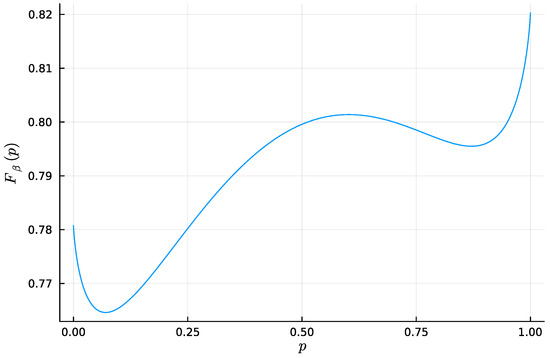
Figure A1.
The function for example values of and , where the source and relevancy are binary. Here, on the x-axis, p parameterises the binary distribution .
The function is plotted in Figure A1 for example values of and , where the source and relevancy are binary. As a difference in concave functions, the function is a priori neither concave nor convex, but we can define its lower convex envelope, i.e., the largest convex function, which is still inferior or equal to everywhere: we will denote it by . In Section IV in [35], through convex duality arguments, the following relationship between bottlenecks and was proven:
Proposition A8.
for some such that is the slope of a tangent to the CE curve at the point .
Let us also define the set of points where differs from its lower convex envelope:
which will happen to be crucial for our considerations on successive refinement. As already noted (see [37], Section II.B), this set grows when increases:
Lemma A2.
If , then .
Proof.
For the sake of self-containedness, we reproduce the computation from [37]. Let , which means that . For all ,
so
where the last equality comes from the convexity of the function . Thus,
But, by definition, we have , so ; in other words, . Thus, we have proved that , which is equivalent to . □
Let us now assume that . As we already proved successive refinability for deterministic in Proposition 3, we can assume that is not deterministic. But, the case of and non-deterministic is exhaustively studied in [35] (Section IV.A, IV.B and IV.D). The latter work implies that, in this case:
Lemma A3.
Let , let be a a solution to (A38) with parameter ν, and let β be given by Proposition A8. Then, the set is a non-empty open interval and, for a pair to satisfy (A39), the set of points
must coincide with the extreme points of the interval .
Equipped with these previously established facts, we can leverage them to prove successive refinement when and is not deterministic. Note that the computations from [35] that yield Lemma A3 extract crucial information from the fact that the sign of is given here by a quadratic polynomial. These computations are not straightforwardly generalisable to larger source and relevancy cardinalities—even though they might serve as inspiration for potential generalisations. Let us start with the following lemma.
Lemma A4.
Let . Then, we can assume, without loss of generality, that . Moreover, in this case, a solution to the reformulated IB problem (A38) is such that , seen as a probability transition matrix, is injective.
Proof.
Let be a solution to (A38) for parameter , and let be given by Proposition A8. From Lemma A3, each must correspond to one of the two extreme points of the interval . Moreover, Proposition A2 ensures that, for any primal bottleneck (or equivalently, any solution to (A38)), we still obtain a bottleneck for the same parameter if we merge symbols t with identical . Thus, we can assume, without loss of generality, that , and, in this case, the decoder is, up to permutation of bottleneck symbols, uniquely defined by .
Moreover, as is open and non-empty, these extreme points are distinct; in other words, the column transition matrix Q defined by has its columns made of two distinct points on the simplex . These points must thus be linearly independent as vectors in , so the rank of Q is 2. By the null rank theorem and as , this implies that Q is injective. □
Let us now first consider SR for the case of processing stages. Let , and let be solutions to the primal IB problem (1) of respective parameters . Equivalently, and are solutions to the reformulated IB problem (A38) with resp. parameters , where . From Lemma A4, we can assume that is injective. Moreover, from Proposition A8, the bottleneck pairs and are solutions to (A39) for parameters , respectively, which correspond to inverse slopes of the CE curve at and , respectively. By convexity of the CE curve [35], we have . Thus, from Lemma A2,
This is equivalent to
where denotes the closure of a set E, so, here, and only differ by taking or not taking the segment’s extreme points, and the equalities come from the convexity of this segment. From Lemma A3, this can be rewritten as
But this is exactly the convex hull condition (7). As we chose an injective , we can use the convex hull characterisation (Theorem 4) to conclude that and achieve successive refinement. Thus, we have proved SR for stages.
Appendix B.8. Computation of Bifurcations Values
In this work, we compute the bottlenecks’ bifurcation parameters as the values where the effective cardinality changes [43]: i.e., a bifurcation is a trade-off parameter value for which the number of distinct changes in a neighborhood of (see Section 1.3). With this naive method, the threshold chosen to numerically equate points impacts the computed critical values, which could be avoided by using more sophisticated methods for computing these bifurcation values [42,43,71]. However, the bifurcation values computed by our naive method did correspond, on our minimal examples, to parameters where the smoothness of the functions and breaks. Thus, our method seemingly identifies discontinuities of the first-order derivative of and , which are those of second-order derivatives of the Lagrangian in (3) (see Corollary 1 in [43]). In this sense, our naive method still identifies the IB bifurcations, if defined as second-order bifurcations of the IB Lagragian as in, e.g., [42,43].
Appendix C. Section 3 Details
Appendix C.1. Proof of Proposition 6
We recall that is the space of extensions of and , and that is the space of all distributions (not necessarily consistent with and ) under which the Markov chain holds. We write the proof for discrete variables for ease of presentation, but the very same proof works for continuous variables if we replace sums by integrals. For and ,
The last term is , with
because, under , the Markov chain holds. So, from the last inequality in (A41),
But, the last term of (A41) is also . Thus,
Appendix D. The Unicity and Injectivity Conjecture, and Technical Subtleties It Would Solve
In this section, we describe in more details some technical subtleties encountered in the main text, and present a conjecture that, if true, would make them fade away in cases where the information curve is strictly concave. Let us start by stating the conjecture, which is also interesting in itself. We recall that a bottleneck T is in canonical form when all the pointwise conditional probabilities are distinct (see Section 1.3), and that every primal bottleneck can be reduced to canonical form (see Proposition A2).
Conjecture 1.
Let be such that the information curve is strictly concave. Then, the set of solutions to the primal IB problem (6) that are expressed in canonical form is such that
- (i)
- The pair is, up to permuting bottleneck symbols, uniquely determined.
- (ii)
- The channel , seen as a linear operator on probability distributions, is injective.
Note that point in the conjecture was always numerically satisfied in our minimal numerical experiments, where we also always observed a strictly concave information curve. The strict concavity assumption is necessary for this conjecture to be possibly true, because it has been shown that for a non-strictly concave information curve, the channel can be non-injective [39].
The convex hull characterisation of exact SR, i.e., Theorem 4, would, with Conjecture 1, be made more complete for the strictly concave case. Indeed, one can prove that the conjecture would imply the following one (Conjecture 2 can be obtained by combining Theorem 4 and Conjecture 1; as the latter is in any case not a statement for now, we omit the details):
Conjecture 2.
Let X and Y be discrete variables, let , and assume that the information curve is strictly concave. Then, there is successive refinement for parameters if and only if, equivalently:
In particular, assuming that the information curve is strictly concave and that Conjecture 1 is true, then if the convex hull condition breaks for some bottlenecks and of parameters and , respectively, this is enough to conclude that there is not SR for parameters . Recalling that, in our numerical experiments, we observed strictly concave information curves, this would make the exact SR patterns in Figure 4, Figure 5 and Figure 6 (right), Figure 10, Figure 11 and Figure 12 (left), and Figure A3 (middle) exact characterisations of successive refinement. On the contrary, with Theorem 4 in its current state, in the latter figures, we are indeed guaranteed that SR holds in the blue areas where the convex hull condition is satisfied, but we are not formally guaranteed that SR does not hold in the red areas where the convex hull condition breaks. This is the reason for why, in the main text, we refer to these figures as mere numerical proxies for successive refinement.
Conjecture 1 being true would also, in the strictly concave case, solve a potential ambiguity in the definition of soft SR. Indeed, we do not provide, in Section 3.1, any formal guarantee that the quantity does not depend on the choice of the bottlenecks and , among all those that solve the IB problems with respective trade-off parameters and . To make sure that there is no such dependency, we should rather consider
where, here, denotes the set of distributions that solve the IB problem (1) with trade-off parameter . In practice, there currently exists, to the best of our knowledge, no algorithm to compute, for a given bottleneck problem, all the solutions in . This is the reason for why, in this paper, we stick to computing for fixed bottlenecks and . Careful readers should take this number to be, a priori, only an upper bound on the true measure of soft successive refinement .
However, one can directly verify that either permuting bottleneck symbols t or merging those with identical —so as to obtain a canonical bottleneck—leaves the unique information invariant. Thus, if Conjecture 1- is true, it proves that, for a strictly concave information curve, is actually uniquely defined by the trade-off parameters , , because any pair of corresponding bottlenecks and results in the same unique information.
Eventually, Conjecture 1 seems interesting in itself. Indeed, it would provide crucial information on the trajectory of the bottlenecks’ pointwise decoders over , which could then help for theoretical advances on the successive refinement of the IB.
Appendix E. Sample Used in Section 2.3 and Section 3.2
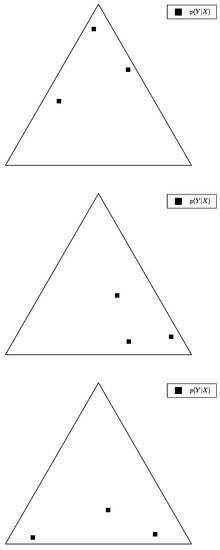
Figure A2.
Plot of the sample distributions used in, respectively, from top to bottom: Figure 4 and Figure 7; Figure 5 and Figure 8; Figure 6 and Figure 9. The simplex depicted here is , where , and each black square corresponds to a symbol-wise conditional probability . Note that the corresponding is shown in the left parts of Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9, which depict the simplex , where, here, we also have . The explicit values of the corresponding can be found at: https://gitlab.com/uh-adapsys/successive-refinement-ib/.
Appendix F. Additional Plots for Exact and Soft Successive Refinement
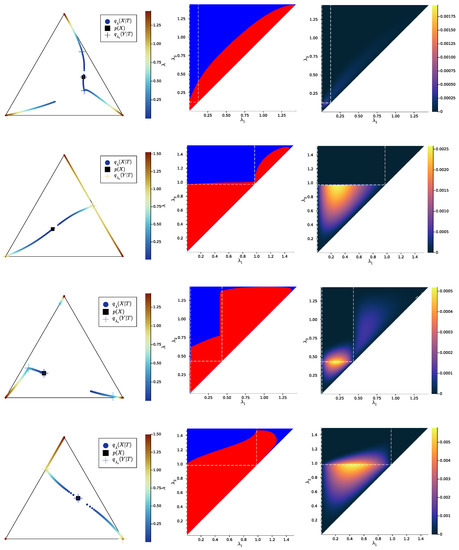
Figure A3.
Additional examples for : comparison of bottleneck trajectories (left) with exact SR patterns (center) and unique information landscapes (right). See Figure 4 and Figure 7 for more details on the legends. The conditional distributions corresponding to each row in this figure are plotted in Figure A4. The explicit values of the corresponding can be found at: https://gitlab.com/uh-adapsys/successive-refinement-ib/.
Figure A4.
Sample distributions used in Figure A3, where the vertical order here corresponds to that of Figure A3. The simplex depicted here is , where , and each black square corresponds to a symbol-wise conditional probability . Note that the corresponding is shown in the left parts of each row in Figure A3, which depict the simplex , where, here, we also have . The explicit values of the corresponding can be found at: https://gitlab.com/uh-adapsys/successive-refinement-ib/.
References
- Tishby, N.; Pereira, F.; Bialek, W. The Information Bottleneck Method. In Proceedings of the 37th Allerton Conference on Communication, Control and Computation, Monticello, IL, USA, 22–24 September 1999; Volume 49. [Google Scholar]
- Gilad-Bachrach, R.; Navot, A.; Tishby, N. An Information Theoretic Tradeoff between Complexity and Accuracy. In Learning Theory and Kernel Machines; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar] [CrossRef]
- Bialek, W.; De Ruyter Van Steveninck, R.R.; Tishby, N. Efficient representation as a design principle for neural coding and computation. In Proceedings of the 2006 IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 659–663. [Google Scholar] [CrossRef]
- Creutzig, F.; Globerson, A.; Tishby, N. Past-future information bottleneck in dynamical systems. Phys. Rev. E 2009, 79, 041925. [Google Scholar] [CrossRef]
- Amir, N.; Tiomkin, S.; Tishby, N. Past-future Information Bottleneck for linear feedback systems. In Proceedings of the 2015 54th IEEE Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015; pp. 5737–5742. [Google Scholar] [CrossRef]
- Sachdeva, V.; Mora, T.; Walczak, A.M.; Palmer, S.E. Optimal prediction with resource constraints using the information bottleneck. PLoS Comput. Biol. 2021, 17, e1008743. [Google Scholar] [CrossRef] [PubMed]
- Klampfl, S.; Legenstein, R.; Maass, W. Spiking Neurons Can Learn to Solve Information Bottleneck Problems and Extract Independent Components. Neural Comput. 2009, 21, 911–959. [Google Scholar] [CrossRef] [PubMed]
- Buesing, L.; Maass, W. A Spiking Neuron as Information Bottleneck. Neural Comput. 2010, 22, 1961–1992. [Google Scholar] [CrossRef]
- Chalk, M.; Marre, O.; Tkačik, G. Toward a unified theory of efficient, predictive, and sparse coding. Proc. Natl. Acad. Sci. USA 2018, 115, 186–191. [Google Scholar] [CrossRef]
- Palmer, S.E.; Marre, O.; Berry, M.J.; Bialek, W. Predictive information in a sensory population. Proc. Natl. Acad. Sci. USA 2015, 112, 6908–6913. [Google Scholar] [CrossRef]
- Wang, S.; Segev, I.; Borst, A.; Palmer, S. Maximally efficient prediction in the early fly visual system may support evasive flight maneuvers. PLoS Comput. Biol. 2021, 17, e1008965. [Google Scholar] [CrossRef] [PubMed]
- Buddha, S.K.; So, K.; Carmena, J.M.; Gastpar, M.C. Function Identification in Neuron Populations via Information Bottleneck. Entropy 2013, 15, 1587–1608. [Google Scholar] [CrossRef]
- Kleinman, M.; Wang, T.; Xiao, D.; Feghhi, E.; Lee, K.; Carr, N.; Li, Y.; Hadidi, N.; Chandrasekaran, C.; Kao, J.C. A cortical information bottleneck during decision-making. bioRxiv 2023. [Google Scholar] [CrossRef]
- Nehaniv, C.L.; Polani, D.; Dautenhahn, K.; te Beokhorst, R.; Cañamero, L. Meaningful Information, Sensor Evolution, and the Temporal Horizon of Embodied Organisms. In Artificial life VIII; ICAL 2003; MIT Press: Cambridge, MA, USA, 2002; pp. 345–349. [Google Scholar]
- Klyubin, A.; Polani, D.; Nehaniv, C. Organization of the information flow in the perception-action loop of evolved agents. In Proceedings of the 2004 NASA/DoD Conference on Evolvable Hardware, Seattle, WA, USA, 24–26 June 2004; pp. 177–180. [Google Scholar] [CrossRef]
- van Dijk, S.G.; Polani, D.; Informational Drives for Sensor Evolution. Vol. ALIFE 2012: The Thirteenth International Conference on the Synthesis and Simulation of Living Systems, ALIFE 2022: The 2022 Conference on Artificial Life. 2012. Available online: https://direct.mit.edu/isal/proceedings-pdf/alife2012/24/333/1901044/978-0-262-31050-5-ch044.pdf (accessed on 12 September 2023). [CrossRef]
- Möller, M.; Polani, D. Emergence of common concepts, symmetries and conformity in agent groups—An information-theoretic model. Interface Focus 2023, 13, 20230006. [Google Scholar] [CrossRef]
- Catenacci Volpi, N.; Polani, D. Space Emerges from What We Know-Spatial Categorisations Induced by Information Constraints. Entropy 2020, 20, 1179. [Google Scholar] [CrossRef]
- Zaslavsky, N.; Kemp, C.; Regier, T.; Tishby, N. Efficient compression in color naming and its evolution. Proc. Natl. Acad. Sci. USA 2018, 115, 201800521. [Google Scholar] [CrossRef]
- Zaslavsky, N.; Garvin, K.; Kemp, C.; Tishby, N.; Regier, T. The evolution of color naming reflects pressure for efficiency: Evidence from the recent past. bioRxiv 2022. [Google Scholar] [CrossRef]
- Tucker, M.; Levy, R.P.; Shah, J.; Zaslavsky, N. Trading off Utility, Informativeness, and Complexity in Emergent Communication. Adv. Neural Inf. Process. Syst. 2022, 35, 22214–22228. [Google Scholar]
- Pacelli, V.; Majumdar, A. Task-Driven Estimation and Control via Information Bottlenecks. arXiv 2018, arXiv:1809.07874. [Google Scholar] [CrossRef]
- Lamb, A.; Islam, R.; Efroni, Y.; Didolkar, A.; Misra, D.; Foster, D.; Molu, L.; Chari, R.; Krishnamurthy, A.; Langford, J. Guaranteed Discovery of Control-Endogenous Latent States with Multi-Step Inverse Models. arXiv 2022, arXiv:2207.08229. [Google Scholar] [CrossRef]
- Goyal, A.; Islam, R.; Strouse, D.; Ahmed, Z.; Larochelle, H.; Botvinick, M.; Levine, S.; Bengio, Y. Transfer and Exploration via the Information Bottleneck. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Koshelev, V. Hierarchical Coding of Discrete Sources. Probl. Peredachi Inf. 1980, 16, 31–49. [Google Scholar]
- Equitz, W.; Cover, T. Successive refinement of information. IEEE Trans. Inf. Theory 1991, 37, 269–275. [Google Scholar] [CrossRef]
- Rimoldi, B. Successive refinement of information: Characterization of the achievable rates. IEEE Trans. Inf. Theory 1994, 40, 253–259. [Google Scholar] [CrossRef]
- Tuncel, E.; Rose, K. Computation and analysis of the N-Layer scalable rate-distortion function. IEEE Trans. Inf. Theory 2003, 49, 1218–1230. [Google Scholar] [CrossRef]
- Kostina, V.; Tuncel, E. Successive Refinement of Abstract Sources. IEEE Trans. Inf. Theory 2019, 65, 6385–6398. [Google Scholar] [CrossRef]
- Tian, C.; Chen, J. Successive Refinement for Hypothesis Testing and Lossless One-Helper Problem. IEEE Trans. Inf. Theory 2008, 54, 4666–4681. [Google Scholar] [CrossRef]
- Tuncel, E. Capacity/Storage Tradeoff in High-Dimensional Identification Systems. In Proceedings of the 2006 IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 1929–1933. [Google Scholar] [CrossRef]
- Mahvari, M.M.; Kobayashi, M.; Zaidi, A. On the Relevance-Complexity Region of Scalable Information Bottleneck. arXiv 2020, arXiv:2011.01352. [Google Scholar] [CrossRef]
- Kline, A.G.; Palmer, S.E. Gaussian information bottleneck and the non-perturbative renormalization group. New J. Phys. 2022, 24, 033007. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Tracey, B.D.; Van Kuyk, S. Caveats for information bottleneck in deterministic scenarios. arXiv 2018, arXiv:1808.07593. [Google Scholar] [CrossRef]
- Witsenhausen, H.; Wyner, A. A conditional entropy bound for a pair of discrete random variables. IEEE Trans. Inf. Theory 1975, 21, 493–501. [Google Scholar] [CrossRef]
- Hsu, H.; Asoodeh, S.; Salamatian, S.; Calmon, F.P. Generalizing Bottleneck Problems. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 531–535. [Google Scholar] [CrossRef]
- Asoodeh, S.; Calmon, F. Bottleneck Problems: An Information and Estimation-Theoretic View. Entropy 2020, 22, 1325. [Google Scholar] [CrossRef]
- Dikshtein, M.; Shamai, S. A Class of Nonbinary Symmetric Information Bottleneck Problems. arXiv 2021, arXiv:cs.IT/2110.00985. [Google Scholar]
- Benger, E.; Asoodeh, S.; Chen, J. The Cardinality Bound on the Information Bottleneck Representations is Tight. arXiv 2023, arXiv:cs.IT/2305.07000. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Ay, N. Quantifying Unique Information. Entropy 2013, 16, 2161–2183. [Google Scholar] [CrossRef]
- Parker, A.E.; Gedeon, T.; Dimitrov, A. The Lack of Convexity of the Relevance-Compression Function. arXiv 2022, arXiv:2204.10957. [Google Scholar] [CrossRef]
- Wu, T.; Fischer, I. Phase Transitions for the Information Bottleneck in Representation Learning. arXiv 2020, arXiv:2001.01878. [Google Scholar]
- Zaslavsky, N.; Tishby, N. Deterministic Annealing and the Evolution of Information Bottleneck Representations. 2019. Available online: https://www.nogsky.com/publication/2019-evo-ib/2019-evo-IB.pdf (accessed on 12 September 2023).
- Ngampruetikorn, V.; Schwab, D.J. Perturbation Theory for the Information Bottleneck. Adv. Neural Inf. Process. Syst. 2021, 34, 21008–21018. [Google Scholar]
- Bertschinger, N.; Rauh, J. The Blackwell relation defines no lattice. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 2479–2483. [Google Scholar] [CrossRef]
- Yang, Q.; Piantanida, P.; Gündüz, D. The Multi-layer Information Bottleneck Problem. arXiv 2017, arXiv:1711.05102. [Google Scholar] [CrossRef]
- Cover, T.; Thomas, J. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Zaidi, A.; Estella-Aguerri, I.; Shamai (Shitz), S. On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views. Entropy 2020, 22, 151. [Google Scholar] [CrossRef] [PubMed]
- Tishby, N.; Zaslavsky, N. Deep Learning and the Information Bottleneck Principle. In Proceedings of the 2015 IEEE Information Theory Workshop, ITW 2015, Jerusalem, Israel, 26 April–1 May 2015. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Tishby, N. Opening the Black Box of Deep Neural Networks via Information. 2017. Available online: http://xxx.lanl.gov/abs/1703.00810 (accessed on 12 September 2023).
- Shwartz-Ziv, R.; Painsky, A.; Tishby, N. Representation Compression and Generalization in Deep Neural Networks. 2019. Available online: https://openreview.net/pdf?id=SkeL6sCqK7 (accessed on 12 September 2023).
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. J. Stat. Mech. Theory Exp. 2019, 2019, 124020. [Google Scholar] [CrossRef]
- Achille, A.; Soatto, S. Emergence of Invariance and Disentanglement in Deep Representations. In Proceedings of the 2018 Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 11–16 February 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Elad, A.; Haviv, D.; Blau, Y.; Michaeli, T. Direct Validation of the Information Bottleneck Principle for Deep Nets. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 758–762. [Google Scholar] [CrossRef]
- Lorenzen, S.S.; Igel, C.; Nielsen, M. Information Bottleneck: Exact Analysis of (Quantized) Neural Networks. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Kawaguchi, K.; Deng, Z.; Ji, X.; Huang, J. How Does Information Bottleneck Help Deep Learning? 2023. Available online: https://proceedings.mlr.press/v202/kawaguchi23a/kawaguchi23a.pdf (accessed on 12 September 2023).
- Yousfi, Y.; Akyol, E. Successive Information Bottleneck and Applications in Deep Learning. In Proceedings of the 2020 54th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 1–4 November 2020; pp. 1210–1213. [Google Scholar] [CrossRef]
- No, A. Universality of Logarithmic Loss in Successive Refinement. Entropy 2019, 21, 158. [Google Scholar] [CrossRef]
- Nasser, R. On the input-degradedness and input-equivalence between channels. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2453–2457. [Google Scholar] [CrossRef]
- Lastras, L.; Berger, T. All sources are nearly successively refinable. IEEE Trans. Inf. Theory 2001, 47, 918–926. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. 2010. Available online: https://arxiv.org/pdf/1004.2515 (accessed on 12 September 2023).
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared Information—New Insights and Problems in Decomposing Information in Complex Systems. In Proceedings of the European Conference on Complex Systems, 2012; Springer International Publishing: Berlin/Heidelberg, Germany, 2013; pp. 251–269. [Google Scholar] [CrossRef]
- Griffith, V.; Koch, C. Quantifying Synergistic Mutual Information. In Guided Self-Organization: Inception; Prokopenko, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 159–190. [Google Scholar] [CrossRef]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Blackwell, D. Equivalent Comparisons of Experiments. Ann. Math. Stat. 1953, 24, 265–272. [Google Scholar] [CrossRef]
- Lemaréchal, C. Lagrangian Relaxation. In Computational Combinatorial Optimization: Optimal or Provably Near-Optimal Solutions; Jünger, M., Naddef, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 112–156. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Tracey, B.; Wolpert, D. Nonlinear Information Bottleneck. Entropy 2017, 21, 1181. [Google Scholar] [CrossRef]
- Matousek, J.; Gärtner, B. Understanding and Using Linear Programming, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- van den Brand, J. A Deterministic Linear Program Solver in Current Matrix Multiplication Time. In Proceedings of the Thirty-First Annual ACM-SIAM Symposium on Discrete Algorithms; Society for Industrial and Applied Mathematics (SODA’20), Salt Lake City, UT, USA, 5–8 January 2020; pp. 259–278. [Google Scholar]
- Rose, K. Deterministic annealing for clustering, compression, classification, regression, and related optimization problems. Proc. IEEE 1998, 86, 2210–2239. [Google Scholar] [CrossRef]
- Gedeon, T.; Parker, A.E.; Dimitrov, A.G. The Mathematical Structure of Information Bottleneck Methods. Entropy 2012, 14, 456–479. [Google Scholar] [CrossRef]
- Shamir, O.; Sabato, S.; Tishby, N. Learning and generalization with the information bottleneck. Theor. Comput. Sci. 2010, 411, 2696–2711. [Google Scholar] [CrossRef]
- Rauh, J.; Banerjee, P.K.; Olbrich, E.; Jost, J. Unique Information and Secret Key Decompositions. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019. [Google Scholar] [CrossRef]
- Banerjee, P.; Rauh, J.; Montufar, G. Computing the Unique Information. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 141–145. [Google Scholar] [CrossRef]
- Chechik, G.; Globerson, A.; Tishby, N.; Weiss, Y. Information bottleneck for Gaussian variables. J. Mach. Learn. Res. 2005, 6, 165–188. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Goldfeld, Z.; Polyanskiy, Y. The Information Bottleneck Problem and its Applications in Machine Learning. IEEE J. Sel. Areas Inf. Theory 2020, 1, 19–38. [Google Scholar] [CrossRef]
- Mahvari, M.M.; Kobayashi, M.; Zaidi, A. Scalable Vector Gaussian Information Bottleneck. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 37–42. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).