1. Introduction
Is causation in the external, physical world or in our heads? Russell [
1] famously denied the former, while the latter seems unacceptably subjective. The interventionist account of causation [
2,
3], especially when interpreted along perspectival lines [
4], seems to be somewhere in between, “an irenic third way”, in the words of Price [
5]. We demonstrate here a plausible physical schema within which causal claims depend for their truth on the internal physical states of a special kind of machine, a causal agent. We take this to be an exemplification of a perspectival view of causation that is not anthropocentric and is dependent on the laws of physics, especially thermodynamics. Our objective is to give empirical support to Price’s “causal viewpoint” as “a distinctive mix of knowledge, ignorance and practical ability that a creature must apparently exemplify, if it is to be capable of employing causal concepts” [
5]. In Cartwright’s terms, we physically “ground the distinction between effective strategies and ineffective ones” [
6]. Or, as Ismael writes, “Causes appear in mature science not as necessary connections written into the fabric of nature, but robust pathways that can be utilised as strategic routes to bringing about ends” [
7]. We seek these “robust pathways” in the physical structure of learning machines.
We take it as given that causal concepts find no application in the fundamental physics of closed systems. This is, we think, precisely what Russell [
1] had in mind when denying the physical reality of causation. A system is closed if it cannot interact with anything outside itself. The physical dynamical laws of a closed system are reversible in time. In contrast, how we define an open system depends on where we draw the boundary. We call a system ‘open’ if its internal interactions are much stronger than any interactions with systems external to it. Of course, such a characterisation is highly contextual, and is dependent on, say, the nature of our experimental access to the system and the time scale of such access: in the long run, even small interactions will matter. The dynamical laws that describe open systems are irreversible and stochastic. It is our contention that casual relations can only be understood in terms of open systems.
We describe a special kind of open system—a causal agent (CA)—which we take to be maintained in a
non-thermal-equilibrium steady state. A CA contains specialised subsystems: sensors, actuators, and learning machines. The external world does work on the CA through special subsystems called
sensors. The CA does work on the world through special subsystems called
actuators. There is an essential thermodynamic asymmetry to sensors and actuators: in both cases, the operation of the subsystem dissipates energy. The learning machine is an irreversible physical system that exploits functional relations inherent in correlations between sensor and actuator states in order to optimise the use of thermodynamic resources. These ‘causal relations’ become embodied in the bias settings of the learning machine. As above, learning machines are necessarily dissipative and noisy [
8,
9].
We make a distinction between two ways one can describe the irreversible dynamics of an open system, which we call the
Langevin and
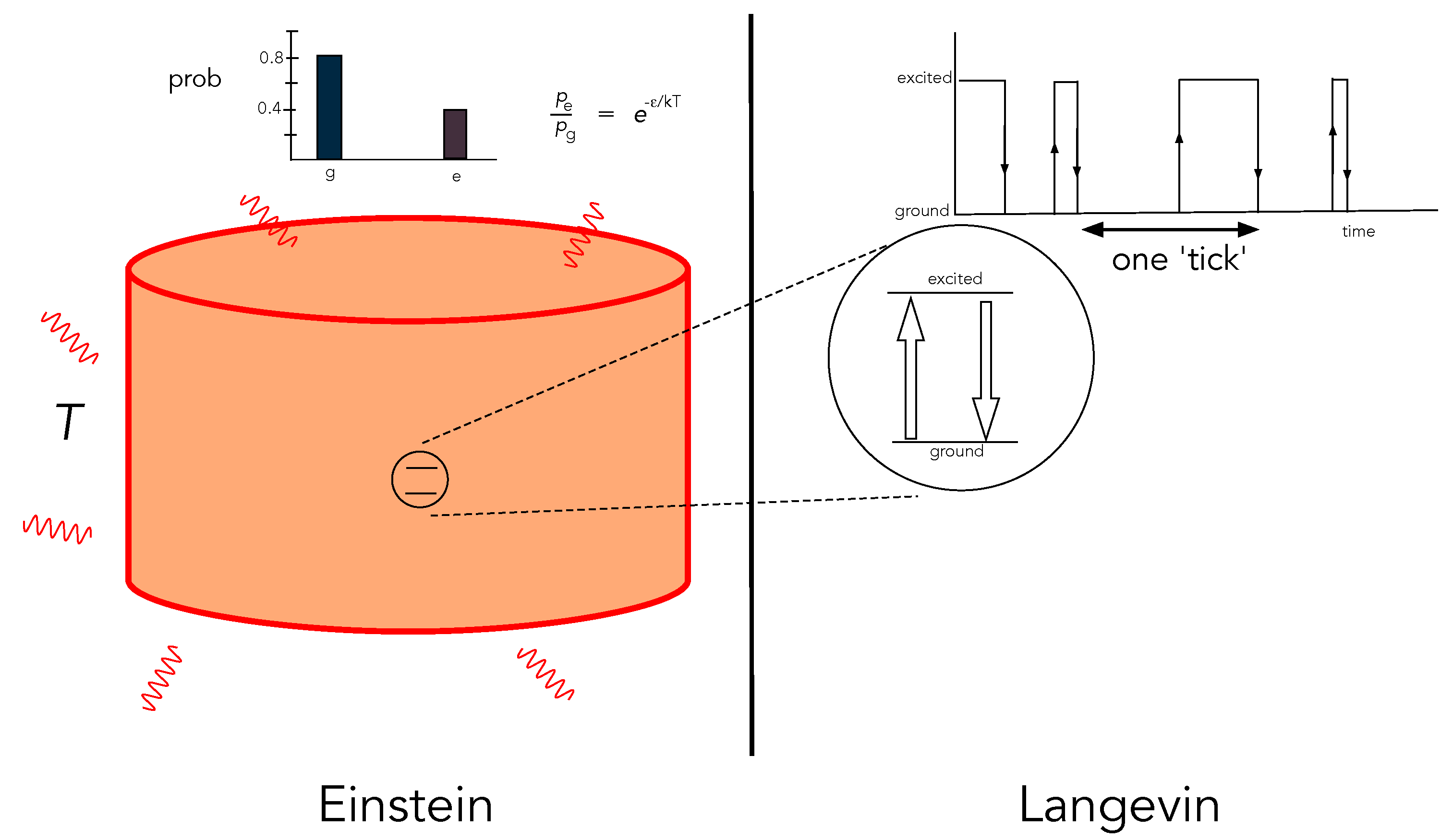
Einstein descriptions. The Langevin description of an open system is a fine-grained description that provides a complete specification of the values of the stochastic physical states of a single system as a function of time. The Einstein description of an open system is a coarse-grained description in terms of the probability distribution of internal physical states or, equivalently, average values of physical quantities. While the probability distributions of the Einstein description can be stationary, the Langevin description of physical states is stochastic. For example, a single two-level atom interacting with a thermal radiation field at fixed temperature may be described in terms of its stationary Boltzman distribution—the Einstein description—or in terms of a stochastic switching between its internal states at rates determined by the temperature of the environment—the Langevin description (
Figure 1).
The two descriptions we highlight are based on the two equivalent ways of describing diffusion given by Langevin and Einstein. Importantly, the Langevin and Einstein descriptions both refer to objective physical states as seen from a ‘third person’ perspective with different levels of grain and different epistemic access to those states.
One of our primary goals in this work is to show how causal relations can be defined in terms of the physical states of the learning machine of the CA. In terms of the Langevin description, the stochastic record of sensations and actions of the CA are coupled by feedback to the irreversible process of the learning machine. The effect is to drive the learning machine stochastically to a new state in which various internal settings are fixed by implicit correlations between sensor and actuator records. The internal settings (weights and biases) of the learning machine continue to fluctuate once the leaning is complete; nonetheless, they enable prediction of the sensations that follow an action with little probability of error. On this view, the causal relations just are the internal settings of the learning machine. (We might imagine that these internal settings are simply the modelling parameters of the causal model constructed by the CA).
In the Einstein description, the probability distribution over the internal settings of the learning machine evolves by feedback to a new stationary distribution centred on particular domains in the state space of the learning machine. While the probability distributions over sensor and actuator records can remain completely random, the probability distribution of the settings of the learning machine are ‘cooled’ to particular steady-state distributions that correspond to the learned causal relation implicit in the correlations between sensor and actuator records. We use the term ‘cooled’ to emphasise that the dynamics of the learning machine are dissipative. It lowers its entropy at the expense of increasing the entropy of its environment.
We wish to note at this point that our construction of a causal agent has considerable overlap with similar constructs by other authors. The importance of sensors and actuators for artificial agents is a staple of textbooks on artificial intelligence [
10] that provide the raw data for learning algorithms. Briegel [
11] also stresses the importance of sensors and actuators for embodied agents. His novel concept of ‘projective simulations’ plays the role of a learning machine in our model. He emphasises the role of stochasticity for creative learning agents and possible quantum enhancements. In elucidating his concept of action-based semantics, Floridi [
12] describes a two-machine artificial agent (AA). The ‘two machines’ of his scheme roughly correspond to the actuator/sensor machines and the learning machine in our model. Our model of a prediction/correction learning machine is close to the agent model introduced in a biological setting by Friston [
13] and subsequent developments [
14]. Lastly, Freeman [
15] and Llinas [
16] link causation directly to learning and motor processes in central nervous systems. We take our model to be in the spirit of these approaches to agency and learning.
Our argument proceeds as follows. In
Section 2, we discuss a very simple classical dynamical model of a causal agent and illustrate the distinction between the Langevin and Einstein descriptions of the CA. In
Section 3, we discuss the thermodynamics of sensors and actuators and the fundamental asymmetry between them. In
Section 4, we introduce the concept of a learning machine (not a machine learning algorithm!) as an irreversible physical system coupled by feedback to the sensors and actuators. We give a simple example of how a learning system can embody causal concepts in its physical steady states. In
Section 5, we discuss the thermodynamic constraints on learning machines, and in
Section 6, we discuss how learning machines based on prediction and correction feedback can learn causal relations. In
Section 7, we make explicit how our model of learning in a CA is an exemplification of causal perspectivalism.
2. A Simple Physical Model
In this section, we begin to develop our model of a causal agent (CA) using a simple example. The objective of the example is to introduce the three essential components of a CA—sensors, actuators, and learning machine—in terms of a simple physical system. We first give the Einstein description of each component followed by the Langevin description. This highlights key thermodynamic processes and irreversibility. The learning machine component can be described both in terms of a physical feedback process and in terms of learning a causal functional relation.
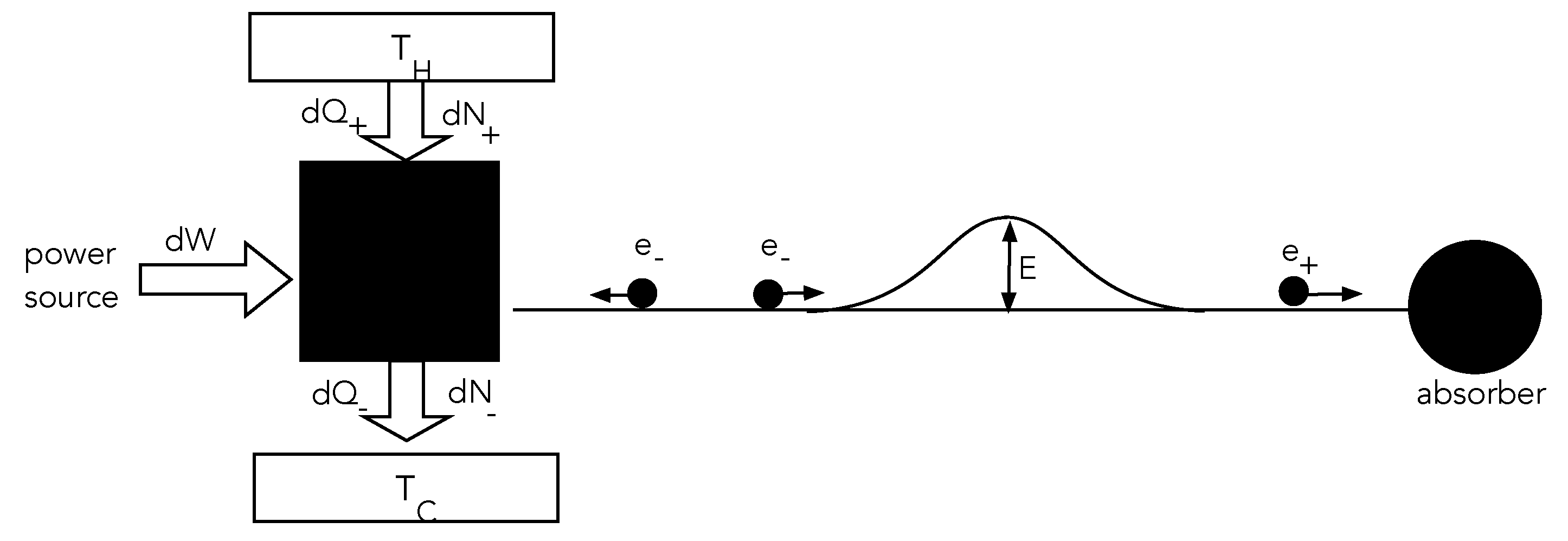
Consider the following simple classical dynamical system (
Figure 2). A local system, the ‘source’, can emit particles of variable kinetic energy. It is driven by an external power supply towards a nonequilibrium steady state by dissipating power into a local environment at temperature
. The emitted particles travel towards a small potential hill. If they have enough kinetic energy, they can surmount the hill and never return to the source. If they do not have sufficient kinetic energy they will be reflected from the potential hill and return to the source. We assume that the motion of the particles once they leave the source is entirely conservative; that is to say, the particles move without friction. As particles that surmount the barrier are lost, we assume that the source is supplied by a particle reservoir such that the average particle number of the source is constant in time. But to make sure that particles with sufficient energy to surmount the barrier do not encounter a yet higher barrier, we add a particle absorber to the right of the potential hill. Overall, this entire physical arrangement is an irreversible system.
Suppose the source initially emits particles which can take one of two possible values of kinetic energy , with equal probability, such that and . All particles that have energy are absorbed at the right, thereby raising the internal energy of the absorber. All particles that have energy are returned to the system and absorbed. The system has access to an environment that emits/absorbs particles locally to keep the average particle number and average energy constant. The entropy of the source is one bit in natural units and its average energy . The average energy of the absorber is steadily increasing as it absorbs particles from the source. This energy is heat-extracted from the source’s environment.
Assume that the CA operates in time steps of duration T. At the nth time step, it emits an particle with probability and an particle with probability . For simplicity, we assume that these are the mutually exclusive events that can happen in each time step so that . This is clearly a Bernoulli process with probabilities that depend on time.
2.1. Einstein Description
According to the Einstein description of the system, the source is simply a source of heat and particles. Since the laws of thermodynamics tell us that there are no perfect absorbers, we know that eventually the absorber will start emitting something—even if ultimately it becomes so massive that it undergoes gravitational collapse to form a black hole and emit Hawking radiation. We can, however, make the general assumption that the absorber is at a lower temperature than the source, and so heat transferred from the source to the absorber raises the overall entropy. As a result, the total system is not in thermal equilibrium. The Einstein description can thus be completely specified in terms of the total average number of particles available at any time and the average number of particles of each species as distinguished by energy corresponding to energies .
At the
th time step, it emits an
particle with probability
and an
particle with probability
and
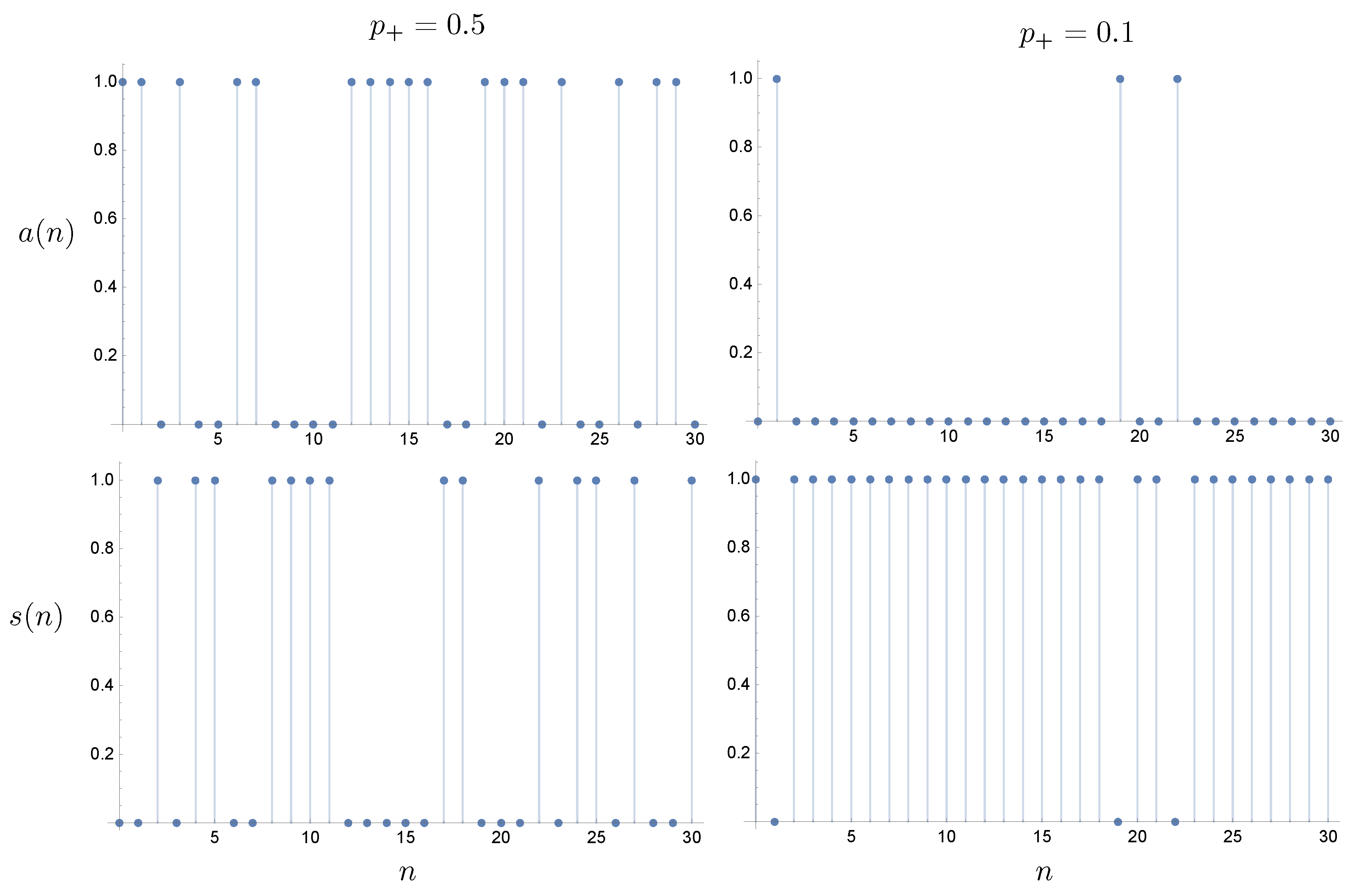
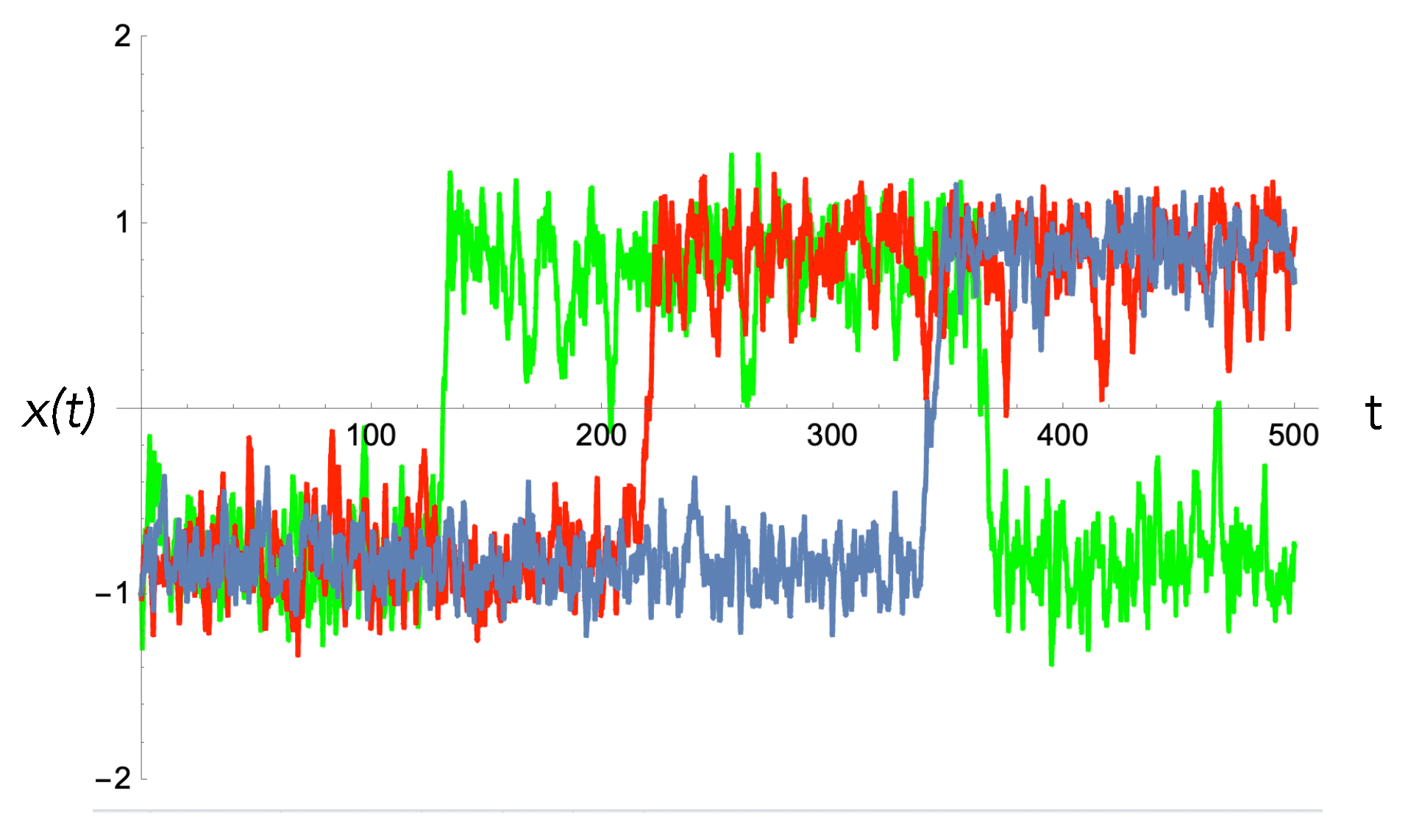
. In
Figure 3, we plot sample trajectories with constant
for the actuator and sensor records, where
if an
particle is emitted and
if an
particle is emitted. For the sensor, we only need that
if a particle is returned; otherwise, it is zero.
It is clear that energy is lost whenever an
particle is emitted, so clearly a mechanism needs to be implemented such that this becomes increasing unlikely based on past experience of the CA. In the Einstein description, this requires changing the discrete stochastic process governing particle emission as a function of time. This turns the Bernoulli process into a nonlinear discrete process. We assume that the fractional change in
from one time step to the next is decreasing,
where
is a constant that depends on the feedback circuit. This may be written as
This is related to the logistic map and has an attractor at
given the restrictions on
, at which point
, exactly as required.
2.2. Langevin Description
The Langevin description is given in terms of a history of actions and sensations. We first define a binary record for actions, , and sensations, . In each time step, the actuator record tracks the energy of each emitted particle: if an particle was emitted and if an particle was emitted. In each time step, the sensor record tracks whether a particle was received back: if no particle is received back and if a particle is received back. The logical relation of the sensations as a function of actions is binary NOT. One way that we can imagine the operation of the machine is that it is required to simulate the NOT function with small probability of error.
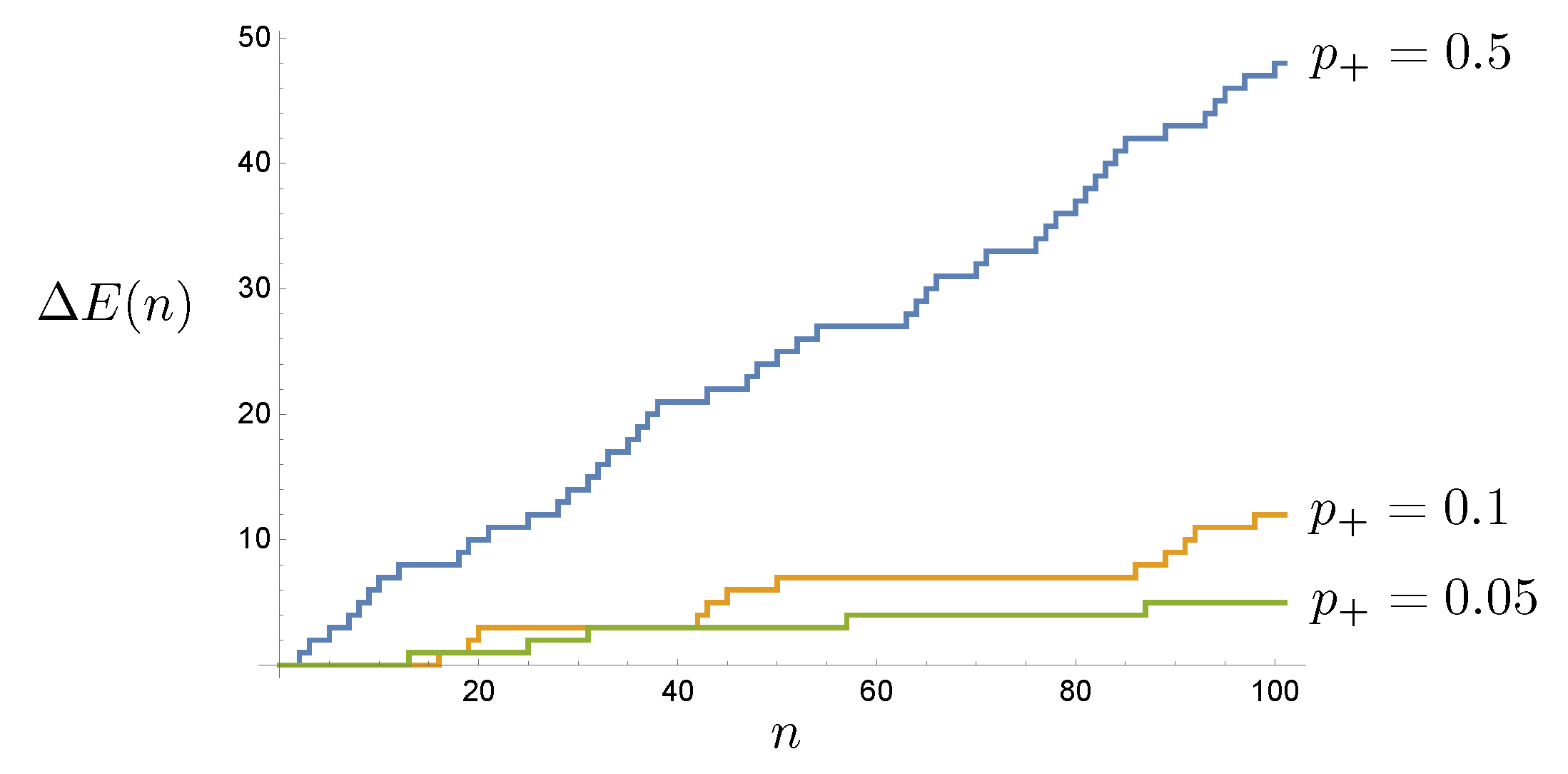
The energy lost at each time step is a random variable given by
as every
particle is returned and counted by the sensor. In
Figure 4 we plot
for three sample trajectories.
It is clear now what needs to happen in order to reduce the energy dissipated, thereby learning the correlation between actions and sensations. The machine needs to reduce the probability that it emits a high-energy particle; that is to say,
is a decreasing function of
n. The simplest way to do this is to add a feedback process from sensor to actuator record at each time step conditioned on the sensor record at that step, as the sensor only records a
if a particle is returned, and that only happens for low-energy particles. A simple feedback protocol is
where
is the sensor record at the
nth time step, and
is a feedback parameter, and we have explicitly acknowledged that these probabilities are conditioned on the sensor records. These equations ensure that
. Keep in mind that
is a random variable, so these equations are intrinsically stochastic. As we have defined
, we can write these equations as
Averaging over an ensemble of actuator histories, this reduces to the nonlinear stochastic map of the Einstein description.
We assume the initial conditions
. The solution to these equations for
is given by
where
is the total count for the actuator over this time interval and is also a random variable. Clearly,
goes to zero and
goes to one. It is important to note that the conditional probabilities entering into Equation (
8) are conditioned on the entire stochastic history,
, which is a particular kind of non-Markovian behaviour. This is analogous to the Bellman equation [
17] in stochastic control theory.
The energy lost per step is the given by
where
indicates an ensemble average over the random variable
. Evaluating this ensemble average is equivalent to deriving a stochastic fluctuation identity for this model [
18]. We see that the average energy dissipated per step decreases exponentially at a rate that depends on the strength of the feedback
. This can be regarded as the learning rate.
In what sense is this kind of feedback described as learning? The answer takes us to the connection between learning and thermodynamics, or between information and physics. The objective of the machine is to minimise energy cost operating in its environment. At each time step, the sensor record as a function of the action record can be described as a binary NOT. But the machine knows nothing about Boolean functions. All it has access to are its sensor and actuator records and an imperative to minimise the energy dissipated in its interactions with the world. If it can find a way to do this, it will have learned correlations implicit in its actuator and sensor records. We return to this question in
Section 5.
In reality, both actuators and sensors have a small error probability, so that the record does not exactly match what actually happened in the actuator and sensor devices. Due to such errors, it is impossible to reach a state in which the sensor record is composed entirely of s. That is an unphysical state of zero entropy. All that is required is that the probability of finding a zero in the sensor record is very small.
This example is very simple, so the causal law it discovers is also simple: if it emits a particle with low energy, it is most likely to be returned, otherwise not. This is the ‘law of physics’ from the perspective of this CA. Emitting a particle is an intervention. The sensor responds accordingly, and the agent learns the causal relation as a result of its intervention. The internal records of the CA are completely contingent. As the actuator/sensor records are random binary strings, every CA will, almost certainly, have different records. The physical internal state of each CA is unique but, according to the Einstein description, the internal records are unknown (by definition), and every CA of this type behaves as an equivalent thermodynamic machine minimising average thermodynamic cost and thereby lowering its average entropy.
3. Thermodynamic Constraints on Sensors and Actuators
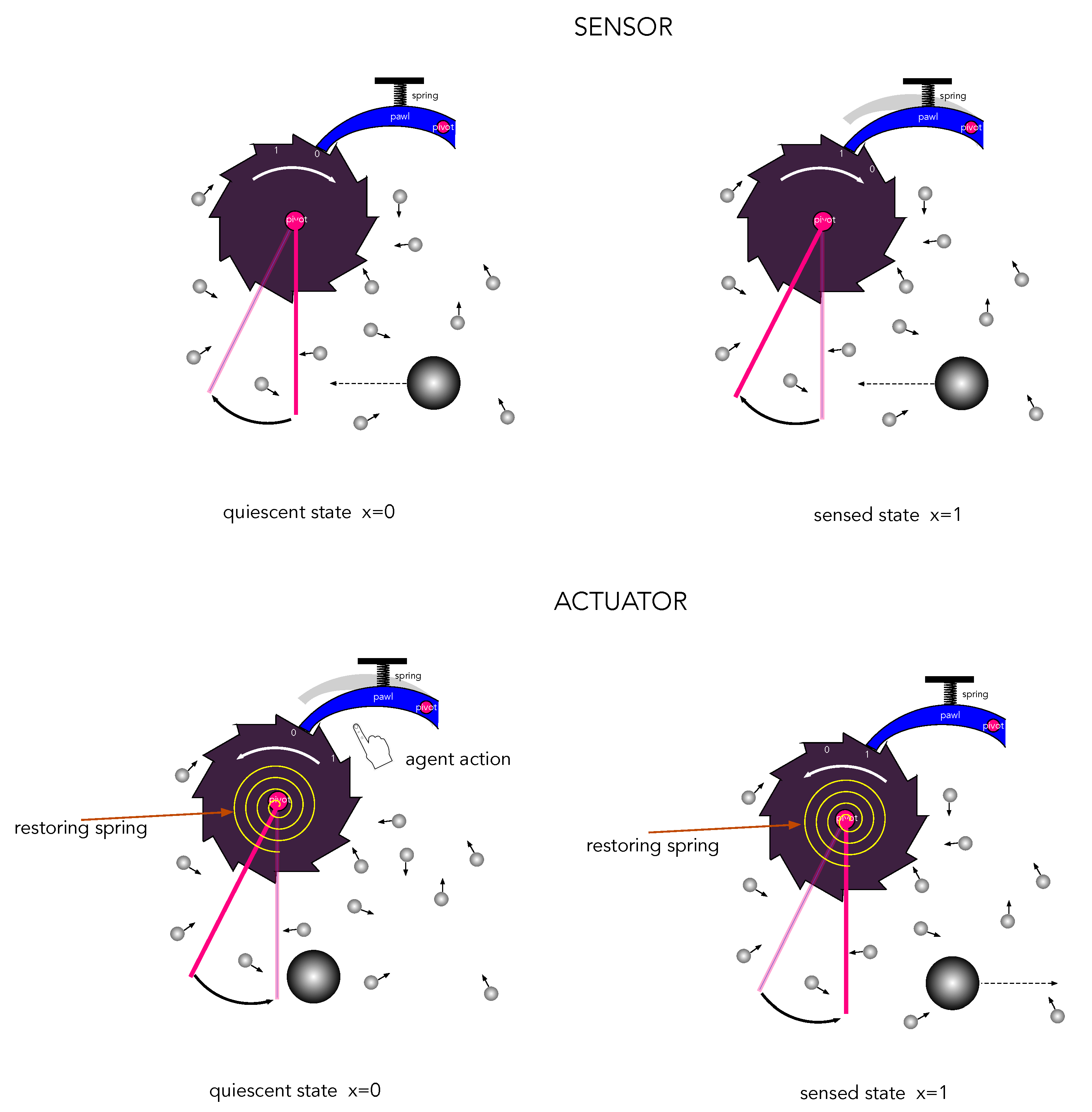
In this section, we formulate general principles that capture key features of the simple example introduced in the previous section. There is a thermodynamic asymmetry between sensors and actuators. Actuators do work on the world, whereas the world does work on sensors. Work done on/by a system is constrained by the change in the free energy (Helmholtz or Gibbs). The change in the free energy constrains the work done on/by the sensors and actuators of a CA. The average work done by a CA must be less than the decrease in free energy. Physical changes to the sensors increase the free energy of the CA, while actuators decrease the free energy of the CA. These thermodynamic asymmetries must be built into the physical construction of sensors and actuators and are a defining feature of a causal agent.
Average work, and corresponding changes in free energy, are part of the Einstein description of a CA. To provide the Langevin stochastic description of the process, we make use of the Jarzynski equality [
18]. On this account, work is a random variable conditioned on contingent physical processes inside the agent. The Jarzynski equality relates the statistics of this stochastic process to changes in free energy.
A mechanical example of the thermodynamic asymmetry of actuators and agents is given in
Figure 5. The objective of the sensor is to detect a collision of a large ‘signal’ particle, while the objective of the actuator is to eject a large ‘probe’ particle. The dissipation and noise is represented by a large number of much smaller particles colliding with the mechanism.
Let us assume for simplicity that both actuator and sensors have only two physically distinguishable states labelled by a binary variable and that the energies of each state are such that . We assume that in the absence of actions and sensations, each system is highly likely to be found in an initial ‘ready’ state. In the case of a sensor, the ready state is the lower energy state, and in the case of an actuator, the ready state is the high-energy state. In the Einstein description, the system is described by a probability distribution . In the Langevin description, the system is described by the value of a binary stochastic variable .
We use a two-state birth–death master equation model to give the Einstein description of sensors and actuators. In the absence of interactions between the agent and the external world, the occupation probability for each state is the stationary solution to the two-state Markov process of the form
where
corresponds to a transition
and
corresponds to the transition
. The corresponding stationary distributions are then given by
The conditions that distinguish the quiescent state of sensors and actuators (the ‘ready’ state for sensations and actions) are
In the case of a sensor, prior to a sensation, it is more likely to be found in the lower energy state
than the higher energy state
. In the case of an actuator, prior to an action, it is more likely to be found in the higher energy state
than the low-energy state
.
It is important to stress, however, that neither the sensor nor the actuator are in thermal equilibrium with their environment. They are actually in nonequilibrium steady states due to external driving of a dissipative system, which in this case is the causal agent itself. In classical physics, the rates
go to zero as the temperature goes to zero. In the quantum case, they may not go to zero at zero temperature due to dissipative quantum tunnelling (as in optical bistability, for example [
19]).
The stationary distributions give the time-independent Einstein description, but an individual system is certainly not stationary in the Langevin description; it is switching between the two states at rates determined by
. The two descriptions are connected by time averaging. In a long time average, the ratio of the times spent in each state is given by the ratio of the transition probabilities
in the limit that the total time
. Thus, prior to actions and sensations, the sensor spends more time in the lower energy state
, while the actuator spends more time in the higher energy state
.
On the stochastic Langevin account, we are interested in describing the energy of a single system. In the current example,
is a stochastic process (a random telegraph signal). We define two Poisson processes
(
) that can take the values
in a small time interval
t to
. In most small time intervals, the state of the system does not change, but every now and then, the system can jump from one state to the other. If a jump does happen, one or the other of
in the infinitesimal time interval
. The probability to take the value 1 in time interval
is then simply
where
defines the average. These equations imply that the continuous record of the state label
satisfies the stochastic differential equation,
The internal states of other components in the agent are responding to these fluctuating signals at all times. The agent is said to be in a ready state, or
quiescent state, if the time average of the signal corresponds to the stationary states in Equation (
13).
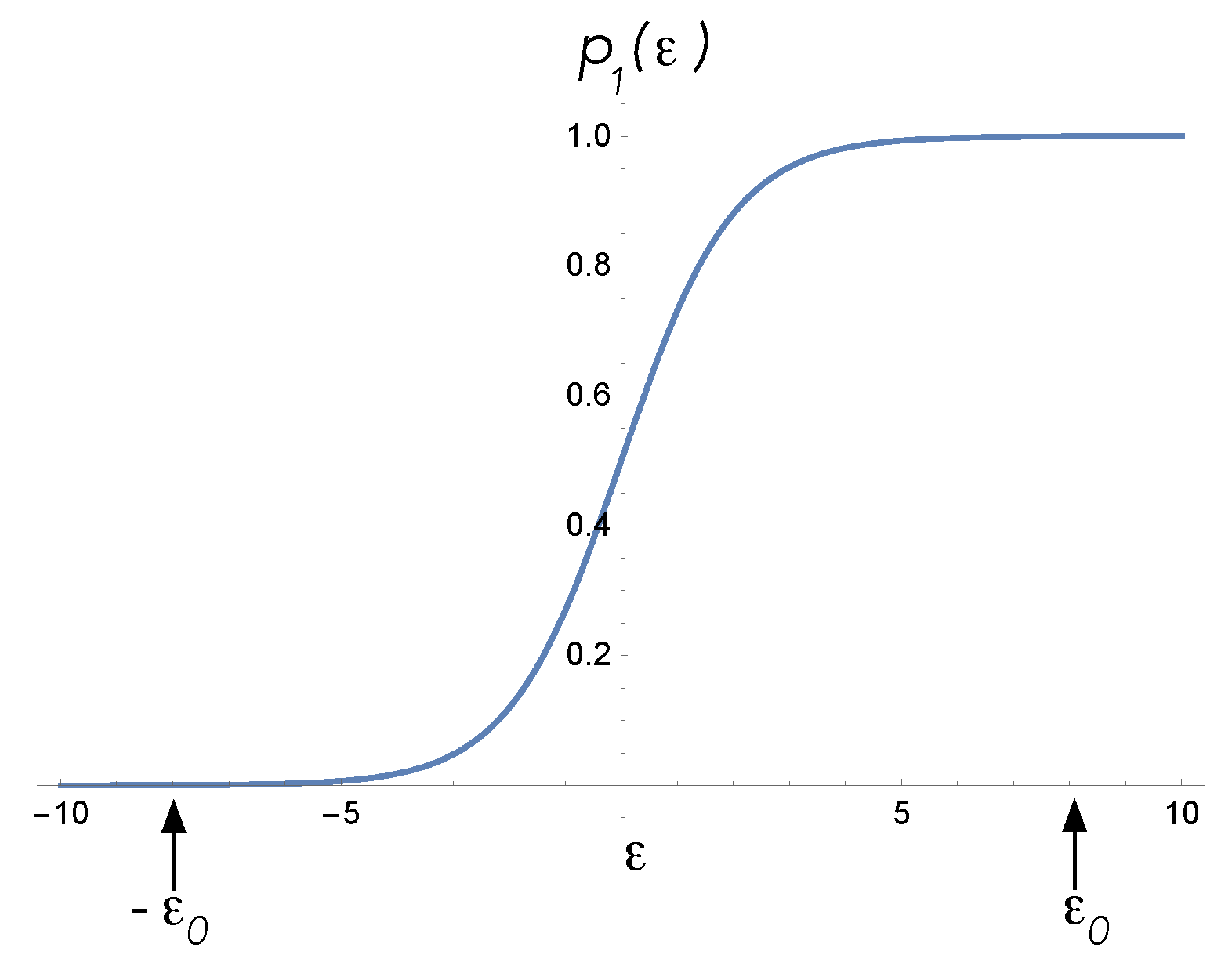
We now describe how these devices respond to internal (actuator) and external (sensor) inputs. In both cases, bias forces act on sensors and actuators in such a way as to make the transition rates time-dependent. This is how work is done on/by the system, during which time heat is dissipated as they are pushed away from their quiescent steady states. We refer to these inputs as the control functions. To show this, first we define
where we refer to
as the bias. If
is a constant, the steady-state average energy is
This function is plotted in
Figure 6. To set the devices to their quiescent state, a particular bias value
is chosen. In the case of a sensor,
and
is small, while in the case of an actuator,
and
approaches
E.
Physical forces inside (actions) or outside (sensations) the CA change the value of from the quiescent state bias, , at time to a final value, , at time . We assume that the irreversible dynamics of the devices is sufficiently fast enough that at each time step they rapidly relax to new steady states. The occupation probabilities then adiabatically change from initial values to final values, . In the case of a sensor, the bias forces are external to the CA, while for the case of an actuator, the bias forces are internal to the CA.
According to the Einstein description, the average energy and average entropy of a sensor and actuator will change over this time. The change in average energy is
. For example, if
, the change in average energy is
In the case of a sensor,
and the average energy increases, while in the case of an actuator,
and the average energy decreases. In this example, the average entropy does not change as the probabilities for each state are exchanged. Thus, the change in the Helmholtz free energy is equal to the change in the average energy. This implies that work is done on the sensor while the actuator does work on the world.
According to the Langevin description of the system, the internal state is a stochastic variable. The sensor spends most of its time in the low-energy state and the actuator in a high-energy state. As the bias forces act, this will change, and the most likely state will switch. The time for the system to switch is a random variable: some change their state early in the control pulse and some change their state late in the control pulse. Some may not change at all. This implies that the work done by/on the external world, w, is in fact a random variable according to the Langevin description.
This scenario is typical of problems addressed in the field of stochastic thermodynamics [
20]. As bias forces change, and control pulses act over some time, the switching probabilities change. Some of the key results in stochastic thermodynamics relate the probability distribution for the work done to the changes between the initial and final stationary occupation probabilities. The surprising fact is that these relations can be independent of how the bias forces vary in time. Some examples for finite-state Markov models are given in [
21].
As an example, suppose that at the start of a control pulse, the sensor is in the state of zero energy and the actuator is in a state of high energy —the most likely configuration. For an actuator, the probability for the actuator to change its state and be found in the low-energy state at the end of the control pulse is , and the change in the internal energy is . The probability that the device remains in its high-energy state is the error probability . In that case, the change in the internal energy is 0. So, there are two possible values for the change in the energy of the system, 0 and , with probability distributions, and . The work w done by the system on the outside world is one of these two values, , fluctuating between the two values from trial to trial. Similar statements can be made for the sensor. The error probability is now , and the the work done on the system is a random variable .
The Jarzynski equality [
18] is a relation between the ensemble averaged values of
w over many trials and the change in free energy corresponding to the two distributions
, before and after the control, for systems in contact with a heat bath. The equality thus relates the Langevin (stochastic) description to the Einstein (thermodynamic) description. It is given by
where
and
,
E is the average energy, and
S the average entropy (in natural units) for each of the distributions
. In our presentation, there is no requirement for the sensors and actuators to be thermal systems: they are maintained in arbitrary nonequilibrium steady states. Nonetheless, a Jarzynski-type equality holds (see [
20]).
Even given this analysis of sensors and actuators, these components alone are not sufficient to define a causal agent. There needs additionally to be an interaction between the states of sensors and actuators and an internal learning machine. This is a physical, irreversible process coupling the fluctuating energy states of the sensor/actuator, on the basis of time spent in the high/low energy state, to physical states of the learning machine. Let us now describe this process in more detail.
4. Learning in a Causal Agent
In our model, the only data a CA has access to is the content of its sensor and actuator records. In order to learn causal relations, we grant the machine some additional systems that can implement learning based on this data. In this section, we describe a model for this process.
Before we do so, however, let us first consider a simple but thermodynamically expensive way in which a CA could learn, employing a device that uses “memory plus look-up” [
10]. In this model, the CA simply keeps its entire record of sensor and actuator data. In order to produce a particular sensation, the CA scans the data until it finds the appropriate subset of actions to produce a sensation with high probability. This requires storing an immense amount of information and scanning it quickly. The average number of bits to store that data is given by the Shannon information of the record. If the functional relation to be learned is simple enough (a few-bit Boolean function, for example), this could be an effective strategy. In general, however, the function may require many real-valued inputs,
. In that case, a very large number of trials will need to be stored: the number grows exponentially with
n, which is known as the “curse of dimensionality” in machine learning. The point of learning is to compress this into a much smaller set of functional relations
, where the long-time values of the weights label the functions that are learned. We now describe how this can be done in an autonomous machine.
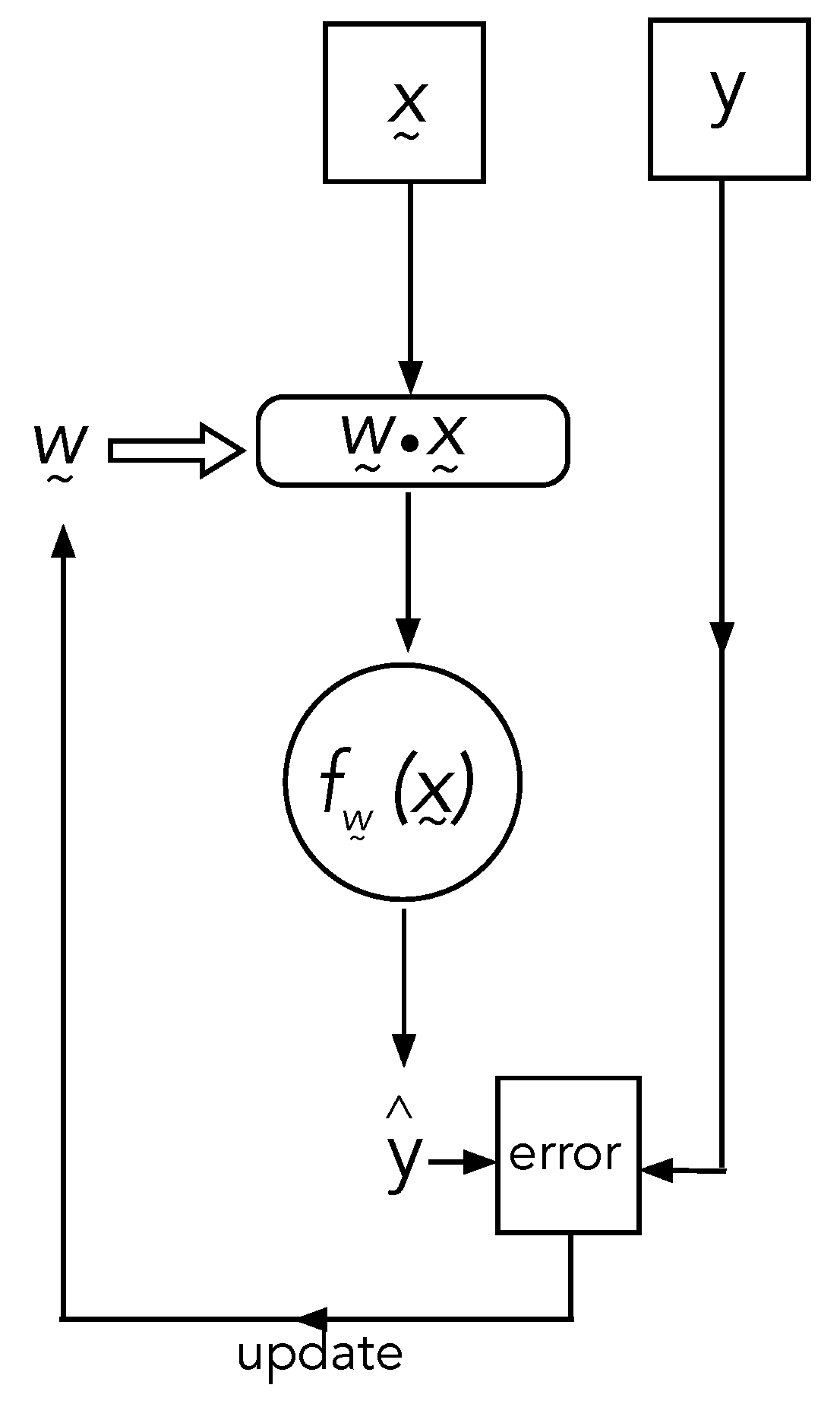
We need to make a distinction between machine learning algorithms and machines that learn. The latter are computer programs that change the parameterisation of a set of functions of an extremely large number of variables according to trial and error training. While the function itself is unknown, a sampled set of known values of the function
is known. The inputs,
, are the training data, and
is called the true label (for example, in binary classification,
). In the first trial, the algorithm computes a different function, parameterised by a set of real numbers
,
on the training data. The value
is compared with the true value
, and if they are not the same, the parameters
are changed according to some fixed algorithm (for example, back propagation) that ensures that the values converge probabilistically to the true labels. In neural networks, the functions are generated by nesting a large number of elementary functions (for example, sigmoidal functions). These are called activation functions. In
Figure 7, we give an example of the steps in the algorithm.
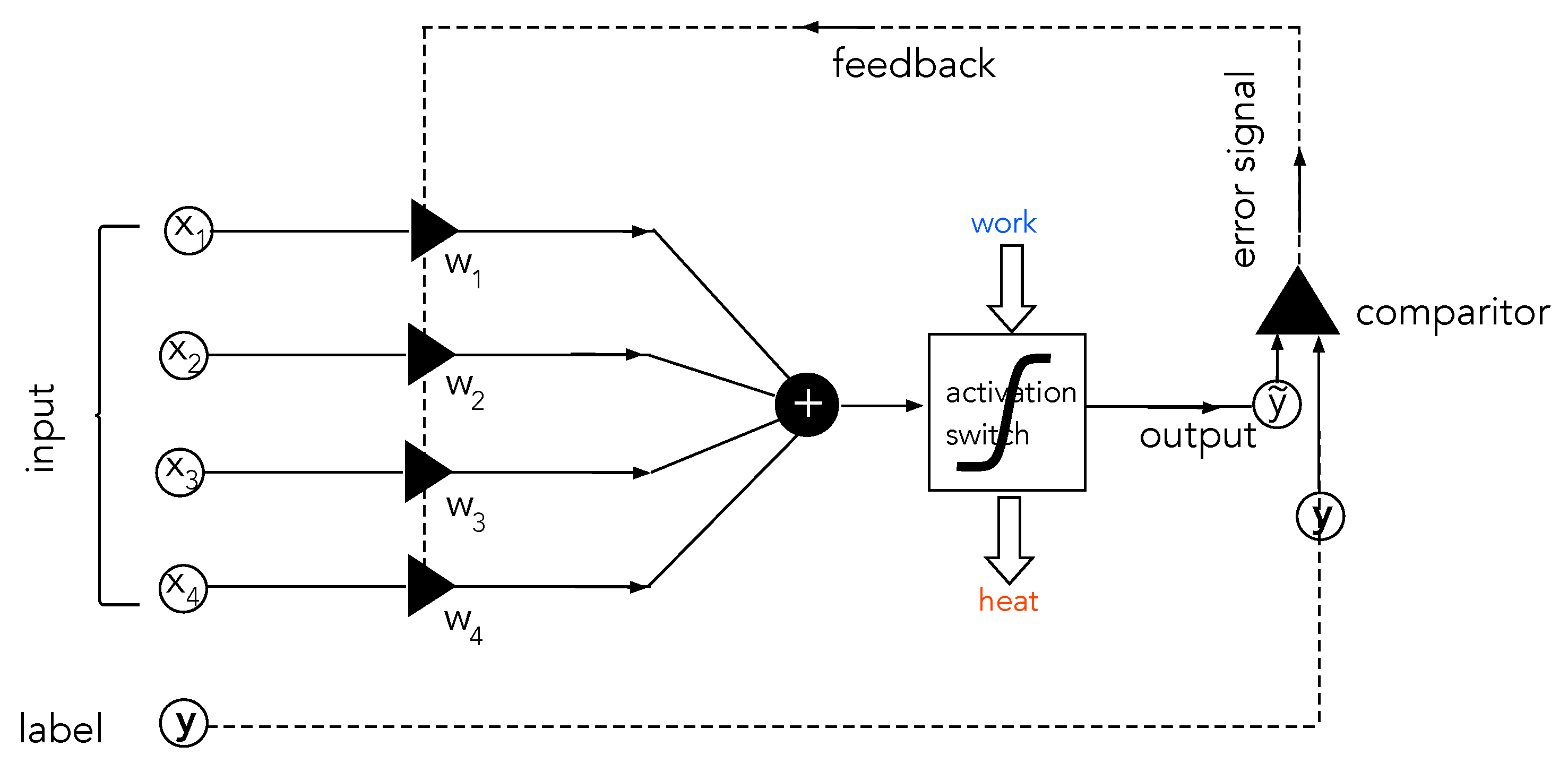
A learning machine is not an algorithm but an open irreversible dynamical system. We assume for now that it is described by a discrete dynamical map. The input is a set of signals and y, which we call the ‘training signal’ and the ‘label signal’, respectively. The signals are physical quantities, such as a voltage or a current. In each time step, the set of input training signals, , is fed into a nonlinear dissipative device that is biased using a set of physical parameters, the weights (for instance, the bias voltages in an analogue circuit). The output signal, here taken to be a single binary-valued physical quantity , is then compared with the label signal, and an error signal is used to feed back and control the weight settings according to a specific control scheme, which we can call ‘cooling’, before the process repeats in the next time step.
Initially, the weights are randomly distributed but, as the machine evolves in time, the distribution of weights converges to a narrow distribution on specific values that represent the unknown function inherent in the correlation between training signal and label signal.
We wish to make clear here that the essential difference between a machine learning (ML) algorithm and a learning machine (LM) is that an ML algorithm must be programmed into a suitable computational device by choosing a particular cost function, whereas an LM leverages the dynamics of its systems to learn—nature does all the work, and the cost function is a physical thermodynamic cost. In particular, (i) the ML algorithm processes numbers, while the LM processes physical input signals; (ii) the ML algorithm acts on numbers through a conventional digital computational process running on a universal computer, while the LM is a physical machine with feedback control of irreversible dynamics; and (iii) the role of data and labels in an ML algorithm is played by the values of physical signals input to the LM, and model parameters (such as weights) are played by physical parameters that control the operation of the LM’s internal dynamics.
Our concept of a learning machine has more in common with analogue computers, such as the differential analyser from the middle of the last century, than it does with the standard von Neumann paradigm for numerical computation. However, unlike a differential analyser, the friction and noise that accompany it are essential for the operation of a learning machine. Considering learning machines along these lines as a model of learning offers us a richer, and more biologically relevant, route to the design of machines that learn. It also enables us to ground causal claims as relations between the physical states of learning machines. We now describe how a machine can learn through a natural process to efficiently exploit thermodynamic resources.
5. Thermodynamic Constraints on Learning Machines
Our goal in this section is to explicitly establish the link between learning in a machine and thermodynamics. To motivate the discussion, we begin with a general argument that suggests why learning machines necessarily dissipate heat and generate entropy.
Suppose we desire a learning machine that will distinguish images of sheep from images of goats (
Figure 8). In the training phase, a well-labelled image of a sheep or a goat is selected with equal probability and input to the machine. The output has two channels corresponding to the true labels of the input images. At the beginning, the image comes out in either channel with equal probability: roughly 50% of the outputs match the true label and come out in the correct channel, but about the same percentage of outputs do not. These are errors.
Whenever an error occurs, feedback conditionally changes the internal biases in the learning machine to try to decrease the error probability . Eventually, the machine gets the true labels right, and images almost always come out in the right channel. But, it can never be perfect. To see this, let us look at the entropy of the records at input and output.
The entropy at the input is clearly in natural units. Initially, the output has the same entropy but, at the end of training, the entropy of the output records is reduced to the order of . This must be paid for by an overall increase in the entropy of the machine’s environment through heat dissipation that arises every time work is done in the feedback steps. How does this arise in a physical learning machine?
At the most elementary level, neural network algorithms make use of a threshold, or
activation function. In learning machines, the activation function becomes an
activation switch: a dissipative, stochastic system with a nonlinear relationship between input signals and output signals (
Figure 9). The operation of the switch depends on setting bias parameters, similar to sensors and actuators. The biases represent physical states of the switch. The switch’s bias parameters, which we refer to as weights, are changed by feedback in the process of learning.
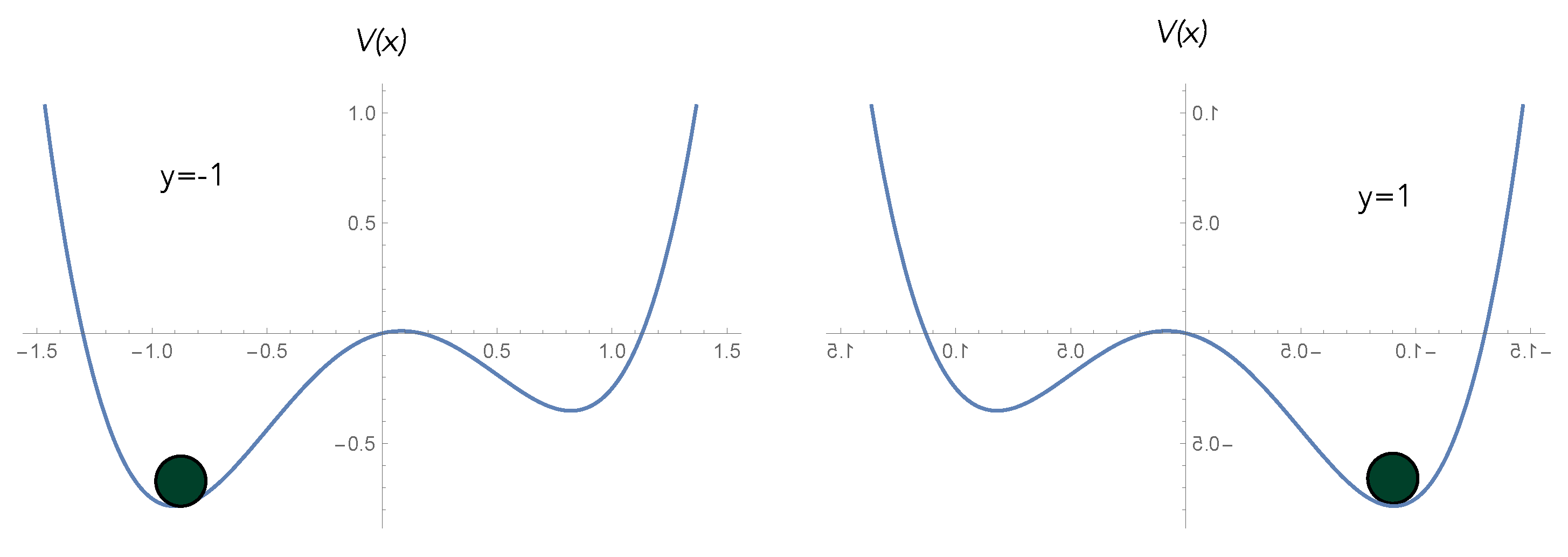
An example of an activation switch is shown in
Figure 10. The potential function is
. Including frictional damping and accompanying noise, the displacement
and momentum
obey the Ito stochastic differential equations ([
22] p. 197),
where
is a the frictional damping rate,
is the diffusion rate for momentum at temperature
T, and
is the Wiener increment. These equations constitute the Langevin description. The Einstein description is given in terms of the stationary probability density. For a one-dimensional system of this kind, the stationary distribution is given by [
22]
Clearly, the steady state is peaked where the potential is at a minimum, with broadening determined by the temperature.
In a deep learning algorithm, weights parameterise functions and are changed according to the back propagation algorithm. In the case of a physical neural network, this becomes a physical feedback of signals from the output to the bias conditions. When we change the bias condition of a switch, we change the probability for the output to switch from one state to another. Changing the bias condition does work on the switch, and that work is dissipated as heat. As for actuators and sensors, the work done and the heat dissipated in each trial is a random variable. Averages over these random variables are constrained by the fluctuation theorems of stochastic thermodynamics [
20].
Clearly, such a system has strongly dissipative nonlinear dynamics and, by the fluctuation–dissipation theorem, must necessarily be intrinsically noisy. We must thus distinguish the ensemble average behaviour of the output—as per the Einstein description—from the single-trial output—as per the Langevin description. This important distinction is explained in
Figure 10,
Figure 11 and
Figure 12 with reference to a biased double well. In a single trial, the output of an activation switch is a random variable. This means that in some cases, the output will not switch when it should, corresponding to an error (
Figure 12). The objective of learning is to minimise this error by changing the biases/weights of the activation switch.
We contend that a further key feature that distinguishes an ML algorithm from a LM is the essential relation in an LM between the minimisation of error and the minimisation of the thermodynamic cost of learning. Moreover, this relation connects an information-theoretical concept—error—to a thermodynamic quantity—heat dissipated. We set out a justification of this claim across the remainder of this section, where, following Goldt and Seifert [
9], we base our discussion on the perceptron learning machine. We begin by describing a device that can take any number of binary input signals but produces a single binary signal at output. Our model is based on the two-state birth–death master equation system discussed in
Section 3 and is thus intrinsically stochastic.
Consider a single system with one output signal labelled by . This is a binary signal. Suppose that there are K binary input signals described by a data vector, ), where . We set the LM the objective to learn a binary-valued function of the K input signals, , where is the true signal label. The training data thus consist of the inputs . As we discuss in more detail below, in the context of a CA, the inputs to the learning machine are supplied as internal actuator records in the CA, and the true signal labels, , are supplied by the world via the CA sensors.
There are
such functions [
23], and there are many supervised machine learning algorithms that can achieve this, for example, Valiant’s PAC algorithm [
24]. However, our interest is in designing a single machine that is able to learn any such function depending on the choice of
. To keep it simple, we discuss the case of
. There are four such functions: two constant functions, the identity function, and the NOT function. Let us consider the NOT function. The example discussed in
Figure 2 can easily be framed in terms of learning a binary function of a single binary variable.
The two output states are described by the Markov process
and
. The transition rates,
, are nonlinear functions of a weighted sum
of the components of the training vector,
, and the weight vectors
. The training of the device is performed by changing the transition rates between states by changing the weights
at each trial. If the two states represent, say, a coarse graining of an underlying double-well potential, the transition probabilities reflect thermal activation over a barrier depending on the bias forces applied [
25]. We assume that the dynamical properties of the switch are such that whenever the weights change the transition probabilities, it rapidly relaxes to the new steady-state probabilities given by
We choose
to model a particular kind of activation switch described by a function called a sigmoidal perceptron [
10],
where
is a constant fixed by experimental design. In a thermally activated device, it would be given by the temperature as
. In a quantum tunnelling device, it is some function of tunnelling rates. Note that
and can be positive or negative.
At this point, we pause to make note of an important difference between a physical sigmoidal perceptron and a sigmoidal function used in machine learning algorithms. In the latter, the output is a real number, while in the physical device, the output is always a binary number, . It is the probability distribution over these values that is sigmoidal. However, we can make a direct connection by evaluating the average output . Normalisation then implies that , or . Thus, we can sample by running many trials with the same value of and recording the average output . This set of trials is called an epoch. It is a time average over many identical trials. Another way to think of the averaging process is to imagine that we replace the single physical perceptron with a large number of identical perceptrons and only look at the average of n over all of them. Whichever way we look at it, we assume that the feedback control is based on computing the average output signal over many identical trials.
Before we can proceed with a description of the feedback process used to change the weights to implement optimal learning, we consider the thermodynamics of the perceptron activation switch. This enables us to define a thermodynamic cost function that controls the rate of learning.
When the weights change from one epoch to the next, what is the average work done on/by the device and what is the average heat dissipated? Let
denote the weights and input signals at the
j-epoch. We assume that the energies of each state of the two-state device are
. This is equivalent to the simple model in
Figure 2 with a shift in the baseline energy. The change in the average internal energy between two successive epochs is [
8]
where
, and
is the change in the weight vector between two successive epochs. We now impose the thermodynamic constraint that the objective of feedback is to change the weights in such a way as to minimise the average energy change per epoch.
As it stands, this does not easily compare with the usual way of implementing learning, in which the focus is on minimising a cost function (for example, the average error between the output
and the true label
). A simple way to relate the two approaches is presented in [
8].
We define the error per trial as
where
is the value of the random variable at the output of that trial. Averaging this over an epoch gives
The change in the average error due to a variation in the weights is given by
We need this to decrease as much as possible per trial, so we set
where
is a positive scaling constant. Thus,
Hence, the feedback rule is
With the choice of Equation (
29), we find that
where
x is the training data, and
The change in the weights depends on both the training data and the corresponding true labels. Note that this goes to zero as
, corresponding to learning the required function. With this choice, we find
This is always negative, and has a maximum when
. At the start of training, this is typically the case, and the change in the average error is large. As training proceeds, it decreases. Using Equation (
30), we find
We see that the average change in energy per trial will be a minimum when the average change in error per trial is a minimum. Thus, the cost function is equivalent to minimising a thermodynamic cost. This relates an information-theoretical quantity, average error in learning, to a physical thermodynamic quantity, heat dissipation. This is similar to Landauer’s principle [
26] that relates the energy cost to an information-theoretical quantity: decrease in entropy by erasure of information. A different thermodynamic constraint on learning is given by Goldt and Seifert [
9]. They show that the mutual information between the true labels and the learned labels is constrained by heat dissipated and entropy production.
The discrete dynamical process induced on the space of weights by feedback is stochastic, because in each epoch, the output probability distribution needs to be sampled (Equation (
38)). However, this is a highly nonlinear stochastic process. When learning is complete, the weights reach a new stationary distribution on weight space that has much less entropy than the distribution used at the start of learning.
If we initialise the weights by a random vector, then the average output over an epoch,
, is close to zero, and the average error is large. The steady-state distribution of the perceptron is uniform, and its entropy is a maximum. The learning proceeds by feeding back onto the
until
. We can also relate the change in average entropy of the perceptron per epoch to the change in average error per epoch [
8]. The result is that the decrease in average entropy per step is also proportional to the change in average error per step.
Stepping back, it is clear that a learning machine is a dissipative, driven, nonequilibrium system with highly nonlinear dynamics and many variables. Betti and Gori [
27] have made a similar claim. Like all such systems, learning machines have nonequilibrium steady states and corresponding basins of attraction in weight space [
20]. Initial high-entropy distributions over weight space are ‘cooled’ into the basins of attraction that characterise the learned function. The learning is driven by an imperative to optimise the use of thermodynamic resources. Where does that imperative originate? It might be the case that in an open, far-from-equilibrium system of sufficient complexity, the evolution of learning machines is a direct consequence of thermodynamics and evolution [
28,
29,
30].
The function that the machine learns is labelled by the weights that it converges to in training. These are not deterministic but, after training, they are sharply peaked around particular values that label the function learned, . These labels are physical variables that define the bias parameters of the learning machine. This is how learning machines come to represent functions in terms of physical variables.
6. Learning and Causal Relations
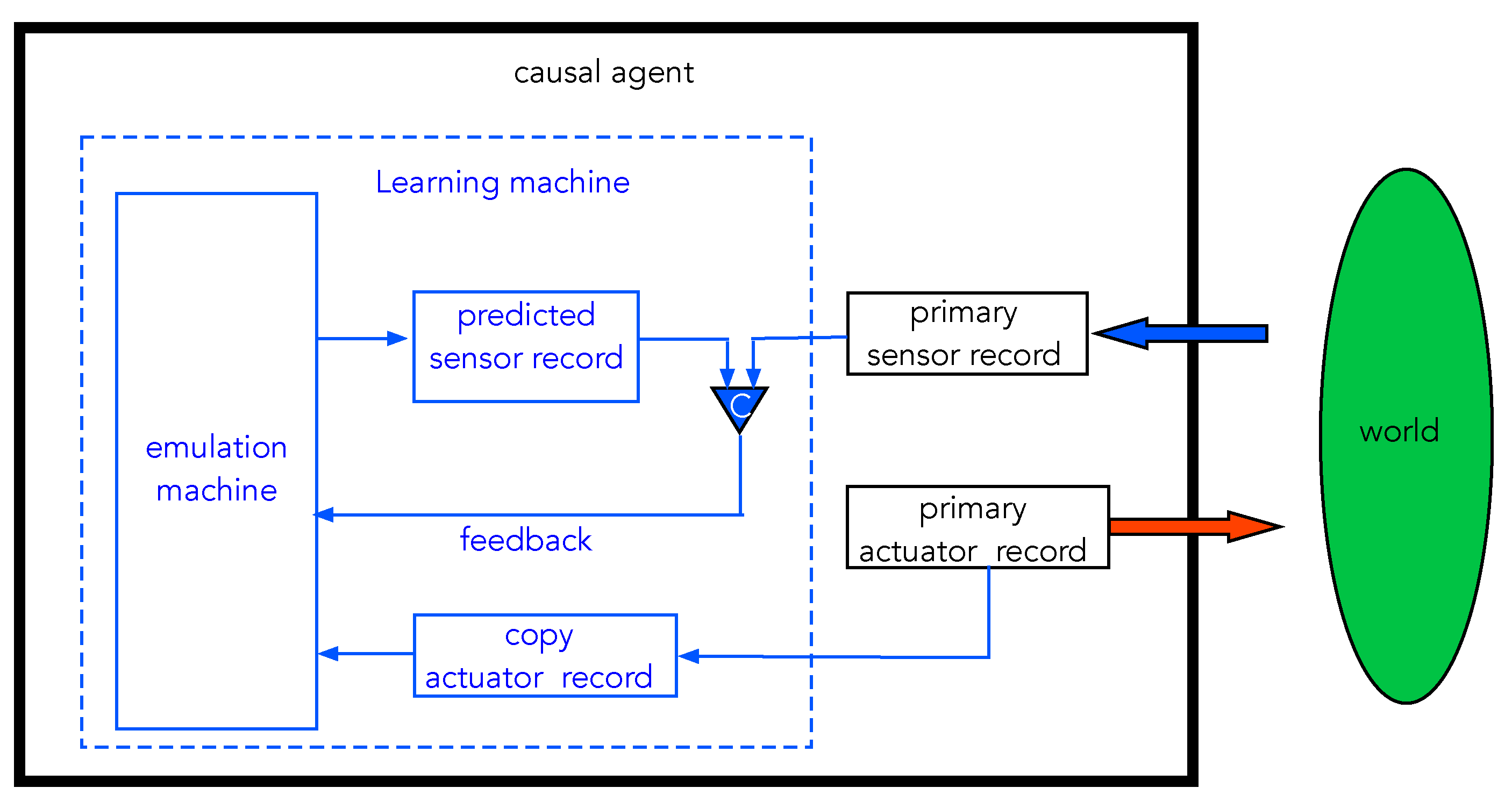
We now return to the discussion of a causal agent that incorporates sensors, actuators, and learning machines. The model, which we refer to here as the emulator model (EM), is summarised in
Figure 13. This model is inspired by models now common in neuroscience that treat the brain primarily as a prediction machine [
31,
32,
33]. The core idea originated in the corollary discharge model of Sperry [
34], but it is a general model for a learning machine.
The goal of the learning machine is to take actuator records and predict sensor records. The predictions are then compared with actual sensor records and feedback is used to modify the settings of the learning machine dynamics so as to minimise the error probability, that is to say, the probability that predictions do not match actual sensor records. As we have already seen, this abstract informational goal can be made equivalent to a physical goal: minimise thermodynamic cost as measured by power dissipated by the CA as it interacts with its environment.
There are no doubt many ways to engineer a learning machine along these general lines. We use the physical neural network (PNN) model described in the previous section. In terms of that model, the actual sensor records coming from the external world play the role of true labels in supervised learning. We can think of nature as a function oracle to which actuators pass arguments, to use the PAC language of Valiant [
24]. The input to the PNN emulator is the actuator records that record sequences of interventions taken by the machine on the external world. The outputs of the PNN are predicted sensor records, and these are compared with the true labels provided by the actual sensors acted on by the world. The previous discussion shows that minimising error predictions is equivalent to minimising the thermodynamic cost of the CA interacting with the world.
In this model, we take the correlations between sensor and actuator records learned by the CA to be causal relations. Thus, a causal relation is a learned function,
, mapping actions to predicted sensations and parameterised by the physical quantities that represent the weights,
w, inside the learning machine. As an example, let us return to the model in
Figure 2. It is clear that the function to be learned is a one-bit Boolean function. Two of these are constant functions that always give either 1 or 0. These give the same result regardless of the input. In terms of the physical model, this would correspond to a bump that is high enough to reflect every particle or low enough to transmit every particle. The other two are the identity function and its complement, the NOT function. In both of these, the output depends on the input. Up to a relabelling of the states of the source, these are the same physical process. In particular, they are the only ones that can be the basis of an effective strategy (to use Cartwright’s term [
6]) as far as the CA is concerned. A one-bit Boolean function can be learned by a single perceptron [
8]. The probability function is given by a single weight
w and single bias
b,
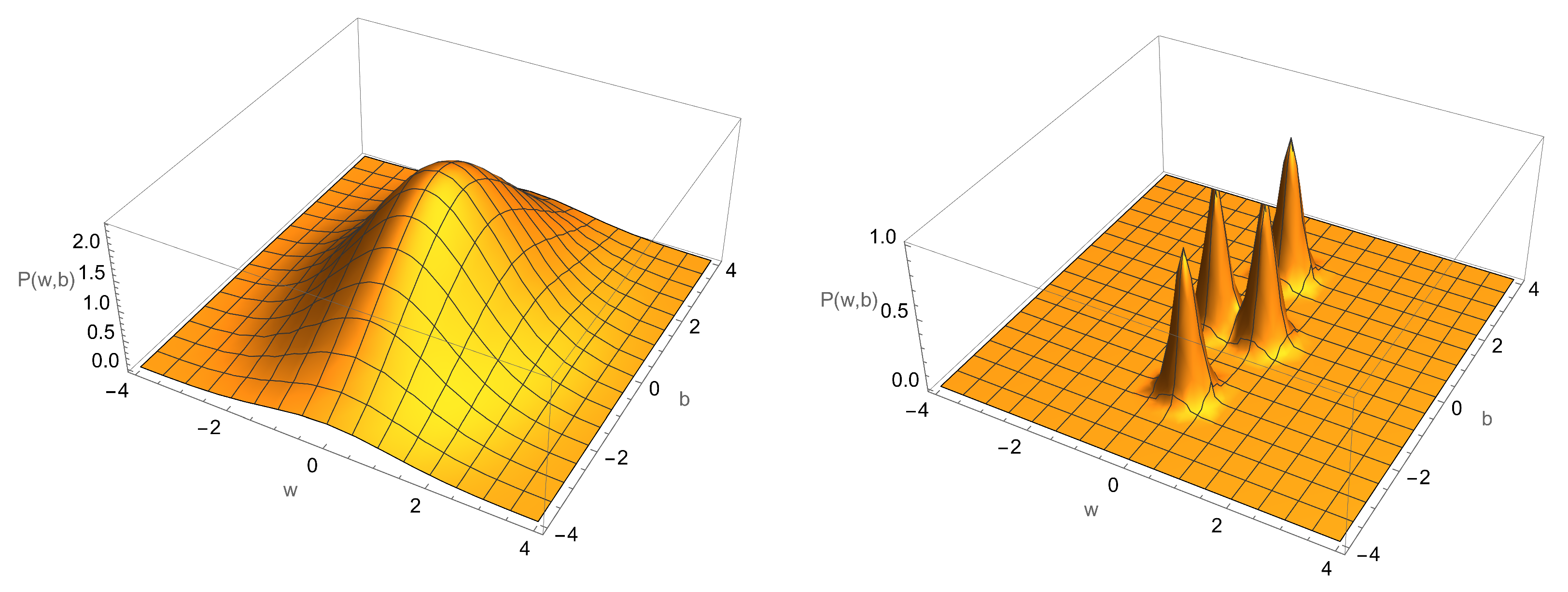
The NOT function corresponds to
, and the identity function to
. The two constant functions correspond to
. In
Figure 14, we schematically indicate the four possible distributions for the weights (
w) and bias (
b) after learning has reached minimum error. The initial distribution of the
is very broad. After learning, they are localised in the space as four distinct distributions, corresponding to the functions learned.
It is important to keep in mind that the physical machine ‘knows’ no more about the causal relations than the settings of its weights and bias. These label the function learned in a probabilistic sense: there is not a unique label, only a region of likely labels for a given function. Can one build a learning machine that learns which function the machine has learned?
To answer this question, we need to introduce the idea of a nested hierarchy of learning machines, wherein each level learns some feature of the functions learned at the lower level by learning some feature of the weights learned at the lower level (for example, which of the four regions in
Figure 14 have been reached).
Suppose we have a learning machine with two actuators and one sensor. This could learn an arbitrary two-bit function with a single binary output. There are 16 such functions. These functions could be classified by a property, and that property can be learned. For example, suppose the classification is simply the answer to the question “is the learned function balanced or constant?” A balanced function is one that takes the same value on half of the input domain and zero on the other half. An example of this is XOR.
The 16 possible functions can be labelled by a binary string of length 4. There are 256 binary functions with 4 inputs, so the higher learning machine will need more perceptrons or more layers, or both. It is know that a binary-valued function of n binary variables can be learned with a single hidden layer of perceptrons.
Thermodynamic constraints will continue to apply when learning machines are nested in this way. At each level, optimal learning will correspond to optimal thermodynamic efficiency given a particular cost function. What sets the cost function? To answer this question, we need to ask: Why learn anything at all?
One answer that is relevant for an interventionist characterisation of causation [
2,
3] is the following: a machine learns causal correlations between sensations and actions so as to act effectively in the world. An effective learning strategy is one that enables effective control of some system external to the CA. This insight shifts the question somewhat: What is an effective control strategy? This question is addressed in the field of optimal stochastic control [
17], which explicitly addresses the question of what an optimal control
policy is, that is to say, how best to act.
The simplest example of an optimal policy would seek to minimise the energy used to change the state of a physical system [
17]. It seems likely that, in an evolutionary setting, such a cost function will be selected spontaneously. An old result of cybernetics is the
good controller theorem [
36], according to which the best stochastic controller is a replica of the system to be controlled. In our model of emulation learning, the learning machine does indeed seek to replicate the dynamics of the external world in a simpler device, so far as it can ‘see’ it through actions and sensations. As we discussed in
Section 5, the free energy cost per learning step is minimised as the error change per step is minimised. This enables a physical grounding of the free energy principle of Friston [
13]. Learning machines are thermodynamically optimal controllers of the external world, and the cost function is ultimately thermodynamic in origin. It is not imposed from the outside. Effective strategies are grounded in thermodynamics.
7. Discussion and Conclusions
Let us finally return to the question of causal asymmetry in the context of our approach. A response to this question crucially depends upon whether causation is an objective feature of the world, or whether it is grounded in the perspective of certain special kinds of physical systems, such as ourselves, that learn and act. One of our primary goals in this work has been to demonstrate how causal relations can be defined in terms of the physical states of a special kind of physical machine, a casual agent. The sole purpose of such physical states is to enable prediction of the sensations that follow an action, within some error bound. Thus, we take these physical states, which are characterised by the internal weights and biases of the learning machine of the CA, to encode a custom-built causal model of the CA’s environment (where the internal weights and biases are simply the modelling parameters of the causal model).
On this view, the causal relations just are the internal settings of the physical states of the learning machine, which are no less physical than those in the world outside. As such, we have argued that causal relations are nothing more than learned relations between sensor and actuator records inside the learning machine of the CA. What is more, we have demonstrated the close connection between the operation of a physical learning machine, and so also the causal agent, and the laws of thermodynamics and energy dissipation. We argue that efficient learning, in the sense of minimising error, is equivalent to thermodynamic efficiency, in the sense of minimising power dissipation. Along with the thermodynamics of sensors and actuators, this renders any such causal agent inherently ‘directed’, and we take this fact to underpin the asymmetry of causation.
We treat the consequences of our approach in greater philosophical depth in [
37]. Briefly, however, let us outline the way in which we take the above considerations to exemplify a perspectival approach to the interventionist account of causation [
4,
5].
Our account is explicitly interventionist due to the necessity of actuators in a CA. These are physical subsystems in a CA that do work on the external world. Sensors alone are not enough to build a CA. Certainly, one could easily build a CA with an algorithm to find patterns in its sensor records (a Bayesian network, say), especially with time series data from multiple sensor types. It is easy to see that correlations could be found between records from different types of sensors. But would any extant correlation in the records indicate a causal relation? Such a claim would be open to Hume’s objection: patterns or ‘regularities’ do not ground causal claims. It is only through intervening on the world that agents can confidently discriminate cause from effect.
Moreover, our model of a CA demonstrates how the asymmetry between exogenous and endogenous variables in the interventionist account of causation has its origin in the thermodynamic asymmetry of the CA itself. Since the causal model that the CA learns is underpinned by its own mechanisms of intervention, detection, and learning, then the thermodynamic directedness of its actuators, sensors, and learning machine dictate that its causal model must also be ‘directed’ in the same way. That is, the CA must be modelling its environment with itself embedded at the heart of the model, such that effects in the world must be thermodynamically downstream from its actuators and thermodynamically upstream from its sensors, and any modelled causal relations must be directed from variables manipulable by the actuator (exogenous) and detectable by the sensor (endogenous). Thus, in a sense, this directedness constrains the agent to be able to act only towards the ‘thermodynamic future’ and to gain knowledge only of the ‘thermodynamic past’.
We take this to be a clear demonstration of what Price [
5] calls a causal perspective: agents who are situated and embedded ‘in time’ in this way are constrained with respect to the actions they can perform and the functional relations they can exploit. Moreover, it is clear that this perspective is inescapable by the CA—it is a function of its own internal constitution. What is more, a CA is also constrained to model its environment exclusively in terms of the set of dynamical variables that are manipulable-and-detectable by the actuator and sensor system. As such, the causal model learned by the CA will only contain functional relations that are exploitable according to the physical constitution of its sensors and actuators. This is then a further sense in which the CA is situated and embedded in an inescapable environment, again as a function of the physical constitution of its own network of actuators, sensors, and learning machines. There is an obvious connection between this latter situatedness and Kirchoff’s [
35] notion of an agent’s own “Markov blanket” as an environment of sorts with which its internal states must contend. Once again, this situatedness defines a causal perspective.
As a final speculative suggestion, we wish to note that CAs that inescapably share a functionally similar constitution of actuators, sensors, and learning machines will share a ‘perspective’ with respect to the causal models they learn. Thus, a shared physical constitution ensures the stability of a casual perspective across a class of CAs, and this then defines an equivalence class of agents that shares a perspective. It is in this way, then, that learned causal relations are shared by all CAs with the same hardware embedded in the same environment. We think the ramifications of this sort of multiagent learning are ripe for further investigation.
Our approach here shows that we can define causal relations independently of human agency, giving a perspectival interventionist account that avoids the charge of anthropocentrism. Instead, we define causal relations as learned relations between internal physical states of a special kind of open system, one with special physical subsystems—actuators, sensors, and learning machines—operating in an environment with access to a large amount of free energy. Even though such open systems need not necessarily be human, it is their ability to model the causal relations in their environment, and exploit such relations as effective strategies, that makes them causal agents.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













