



A Probabilistic Result on Impulsive Noise Reduction in Topological Data Analysis through Group Equivariant Non-Expansive Operators



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Mathematical Setting
2.1. Representing Data as Real Functions
2.2. GENEOs as Operators Acting on Data
- 1.
- (Group Equivariance) for every ;
- 2.
- (Non-Expansivity) for every .
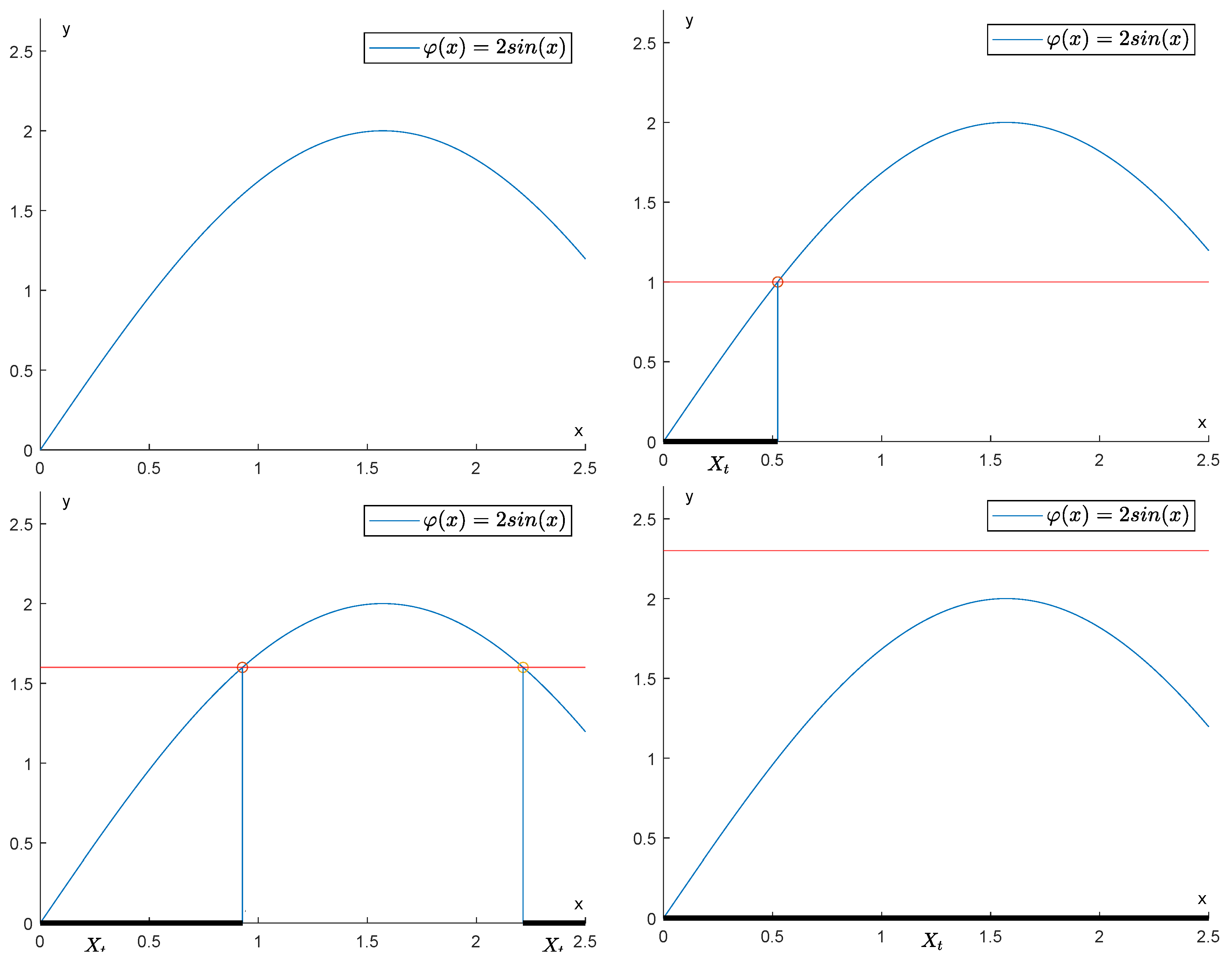
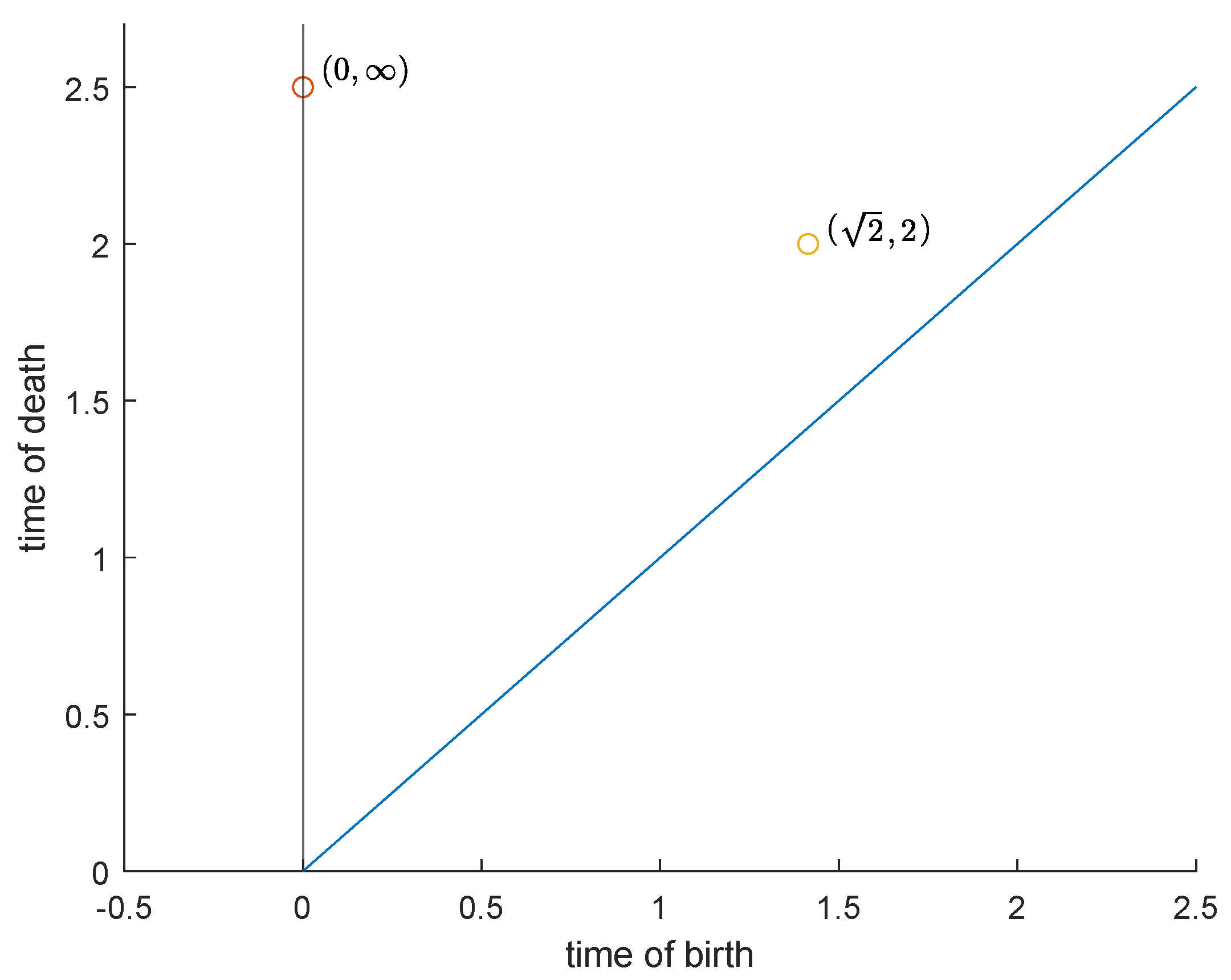
2.3. Persistence Diagrams
2.4. Comparing Persistence Diagrams
3. Our Model
4. Cutting Off the Noise by GENEOs
- 1.
- ;
- 2.
- .
- ;
- ;
- .
- 1.
- , since ;
- 2.
- , since ;
- 3.
- , since ;
- 4.
- , since .
- 1.
- since both terms are negative;
- 2.
- .
5. Our Main Results
6. Examples and Experiments
6.1. Examples
- for
- for
- for .
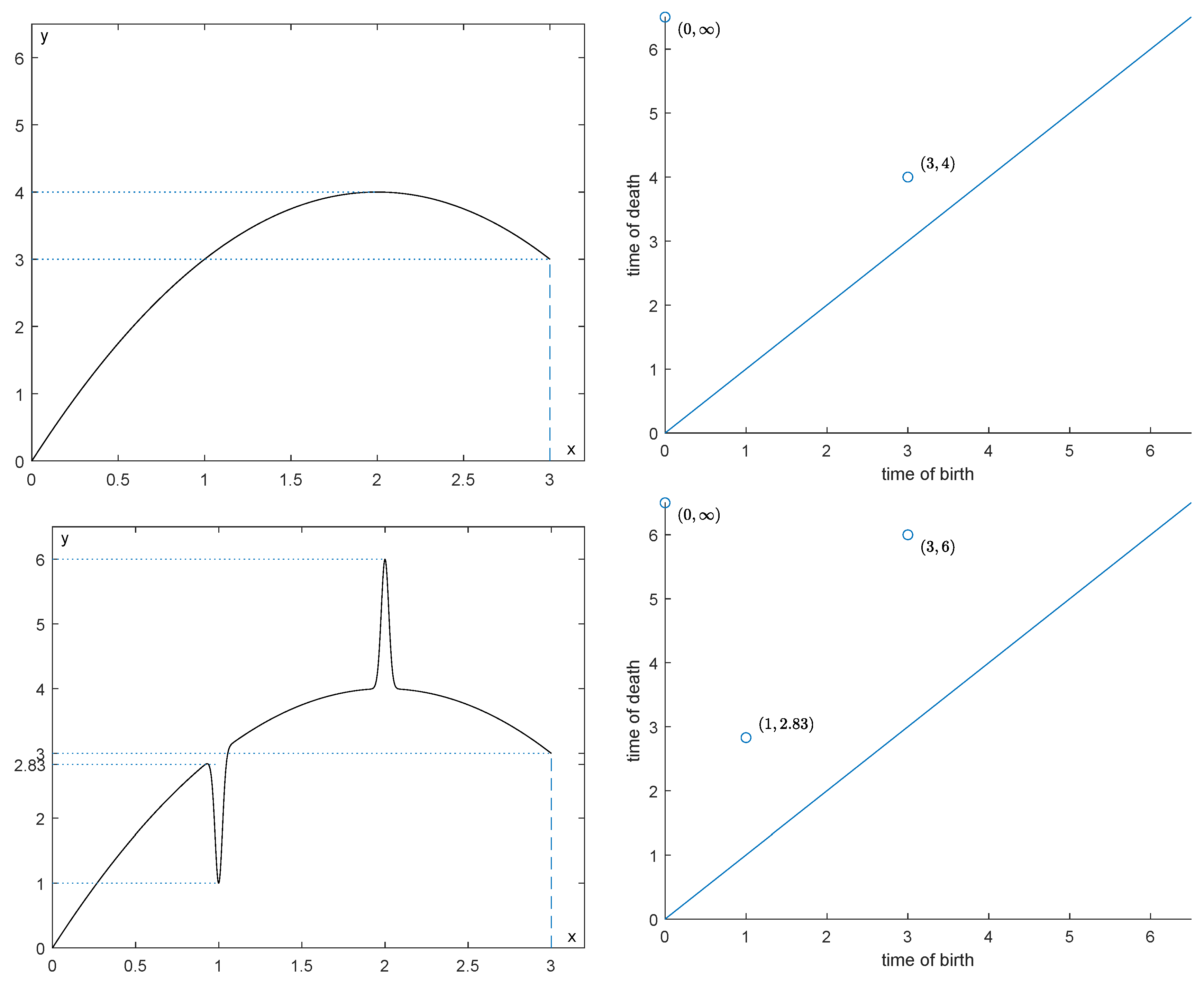
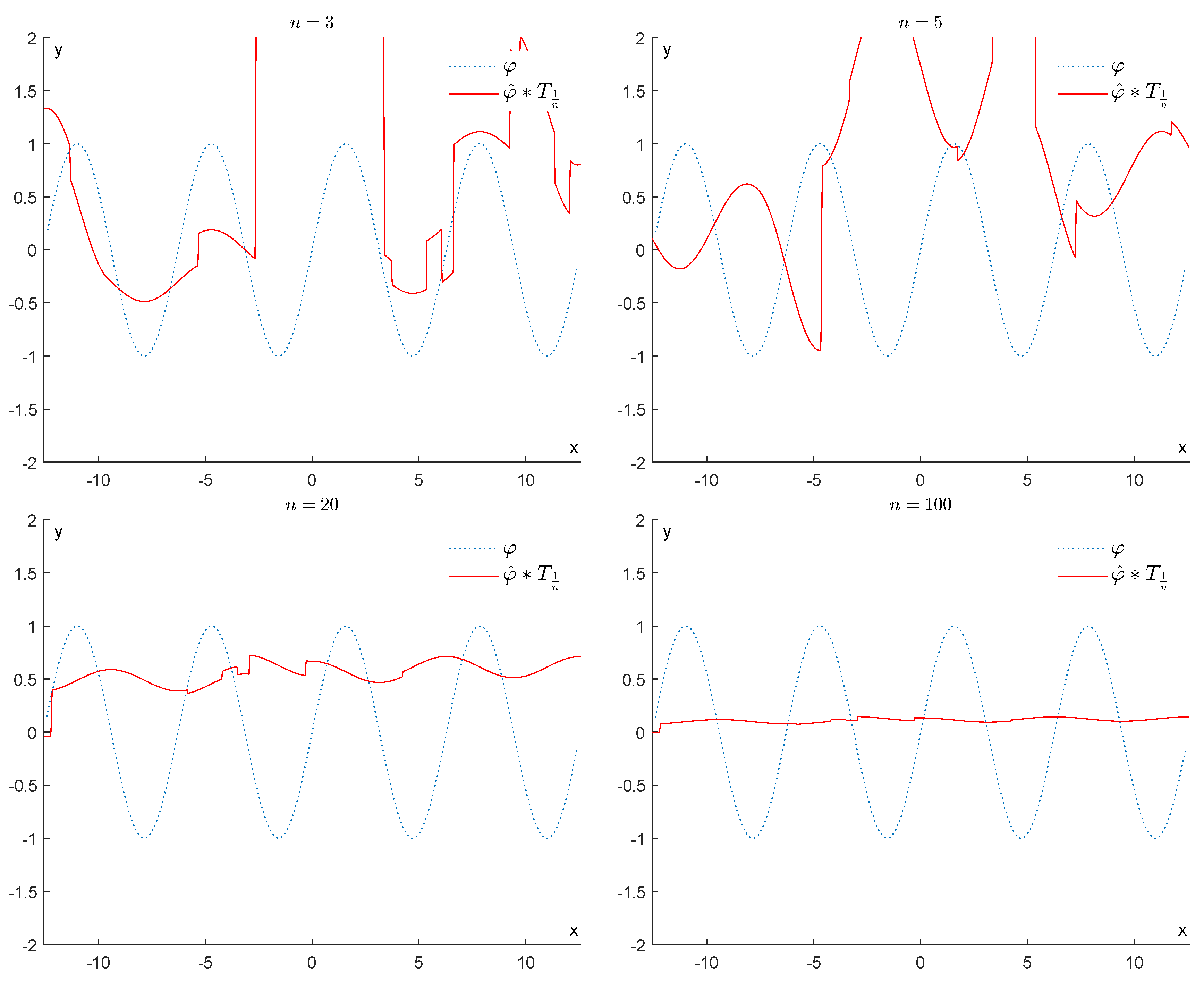
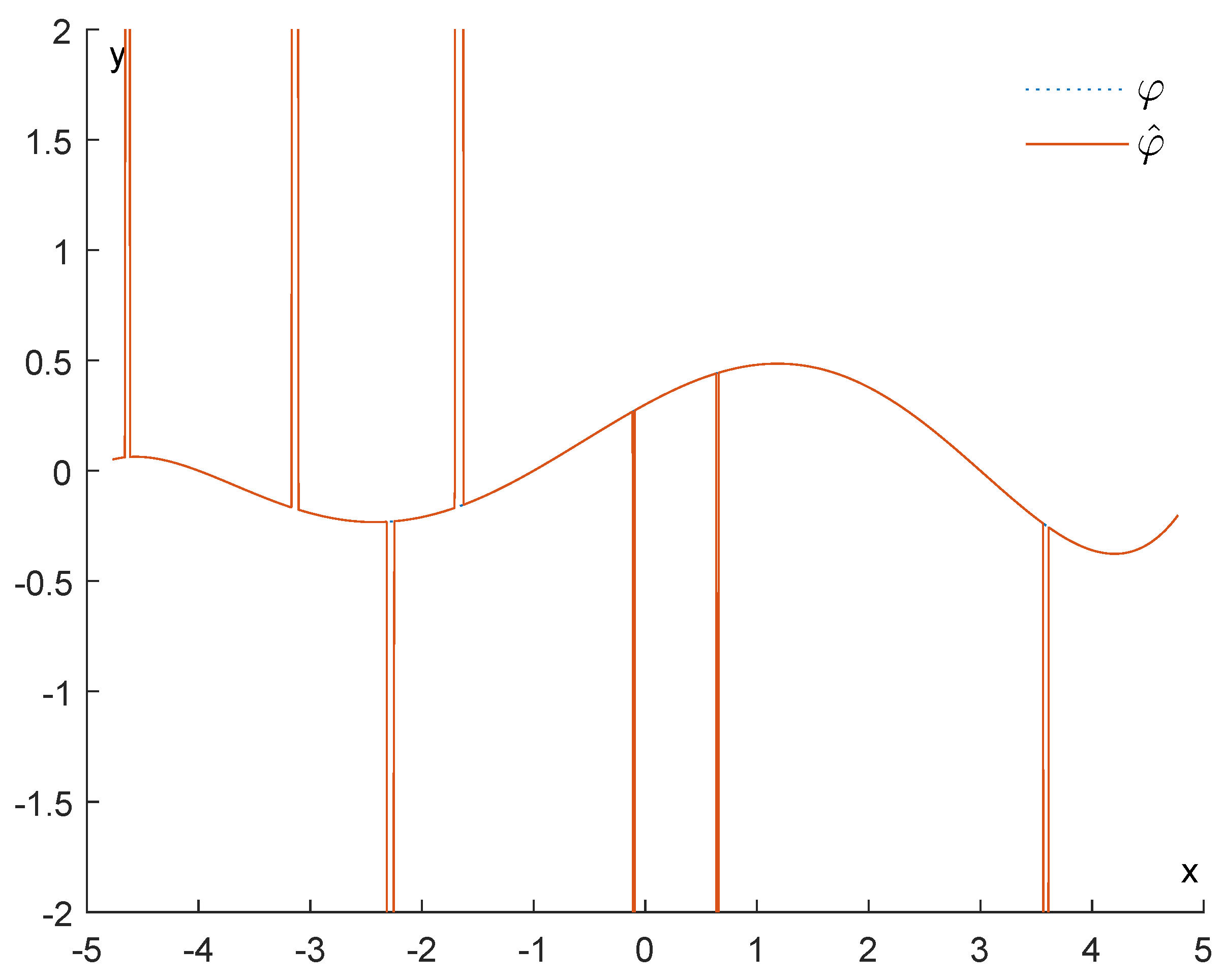
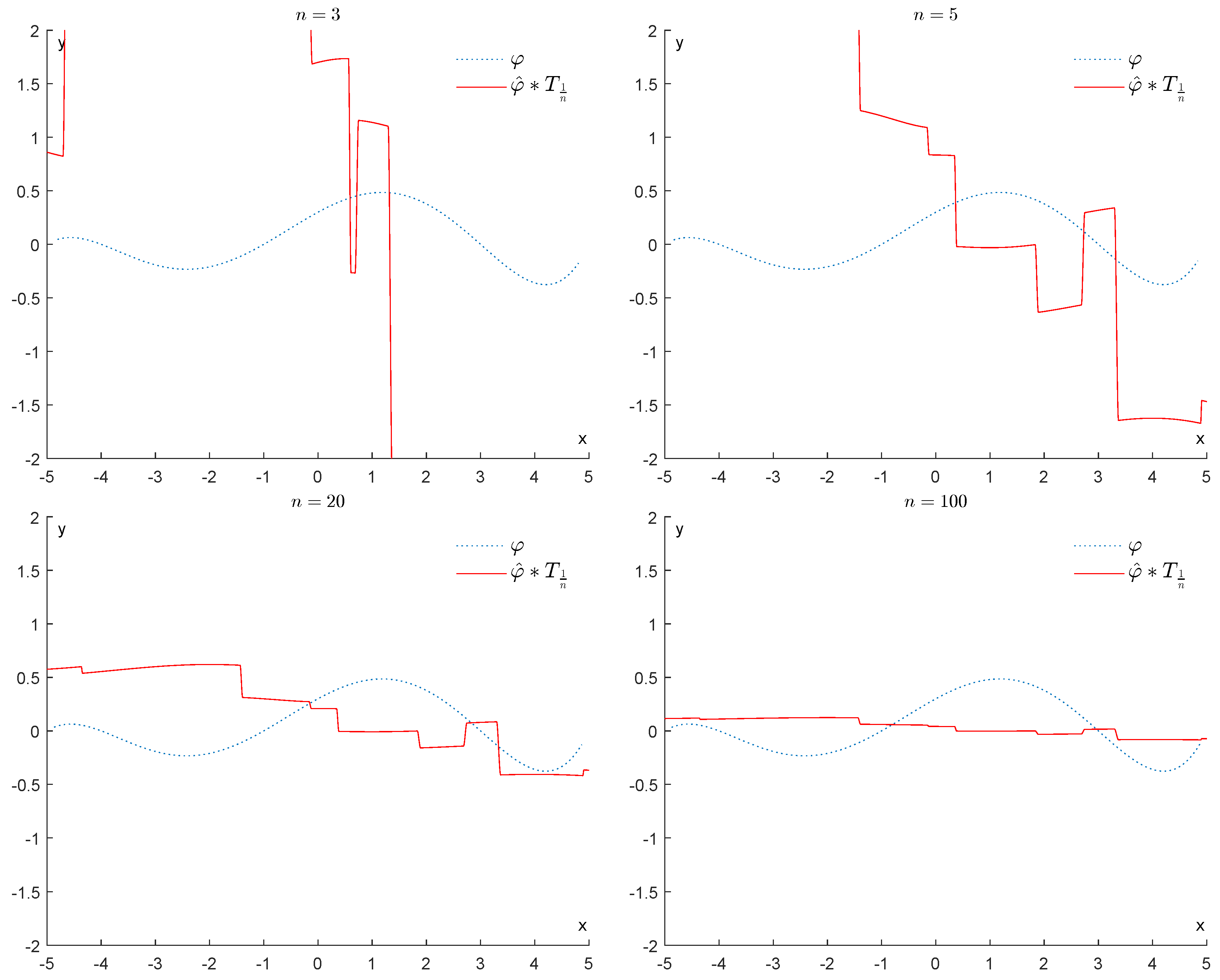
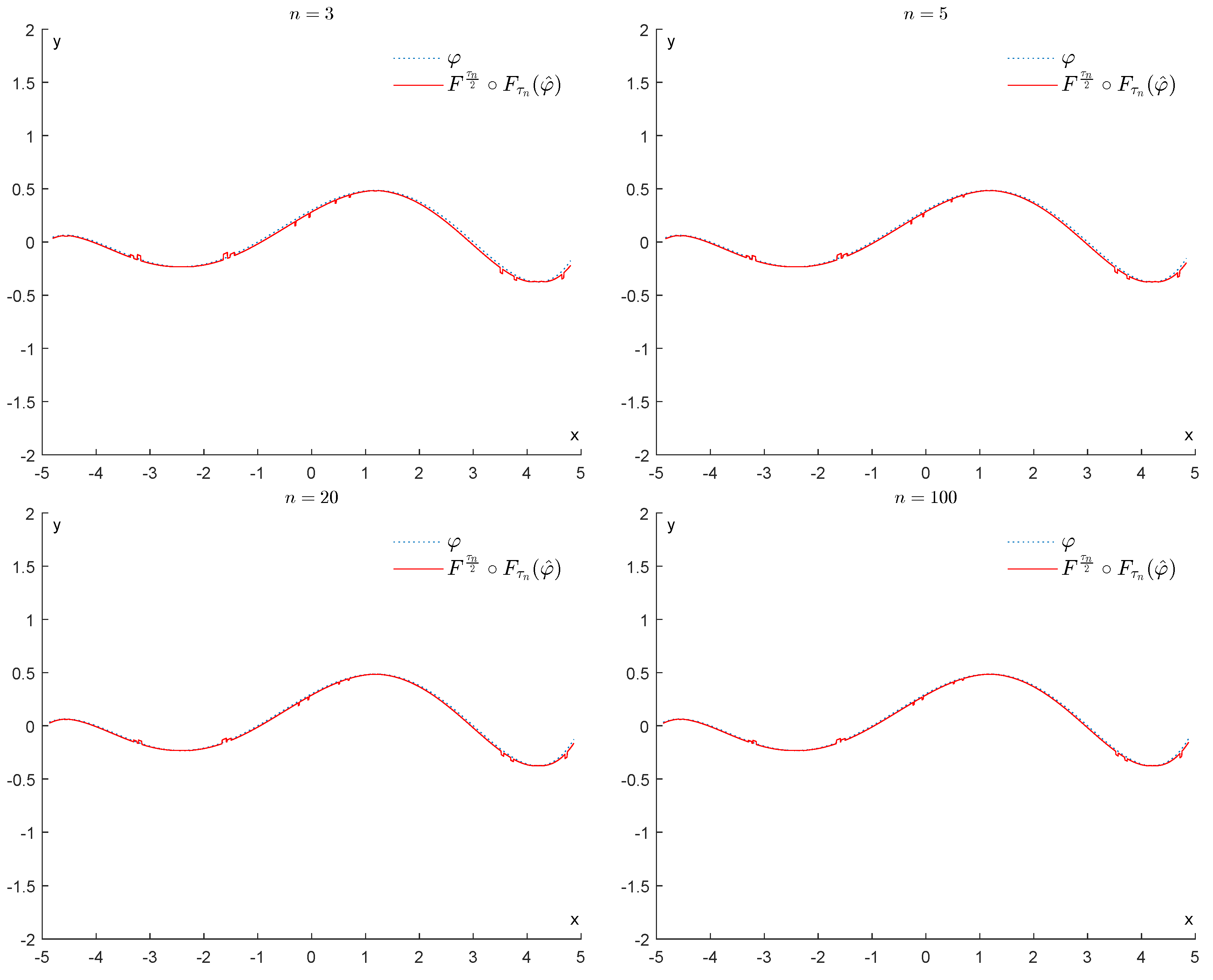
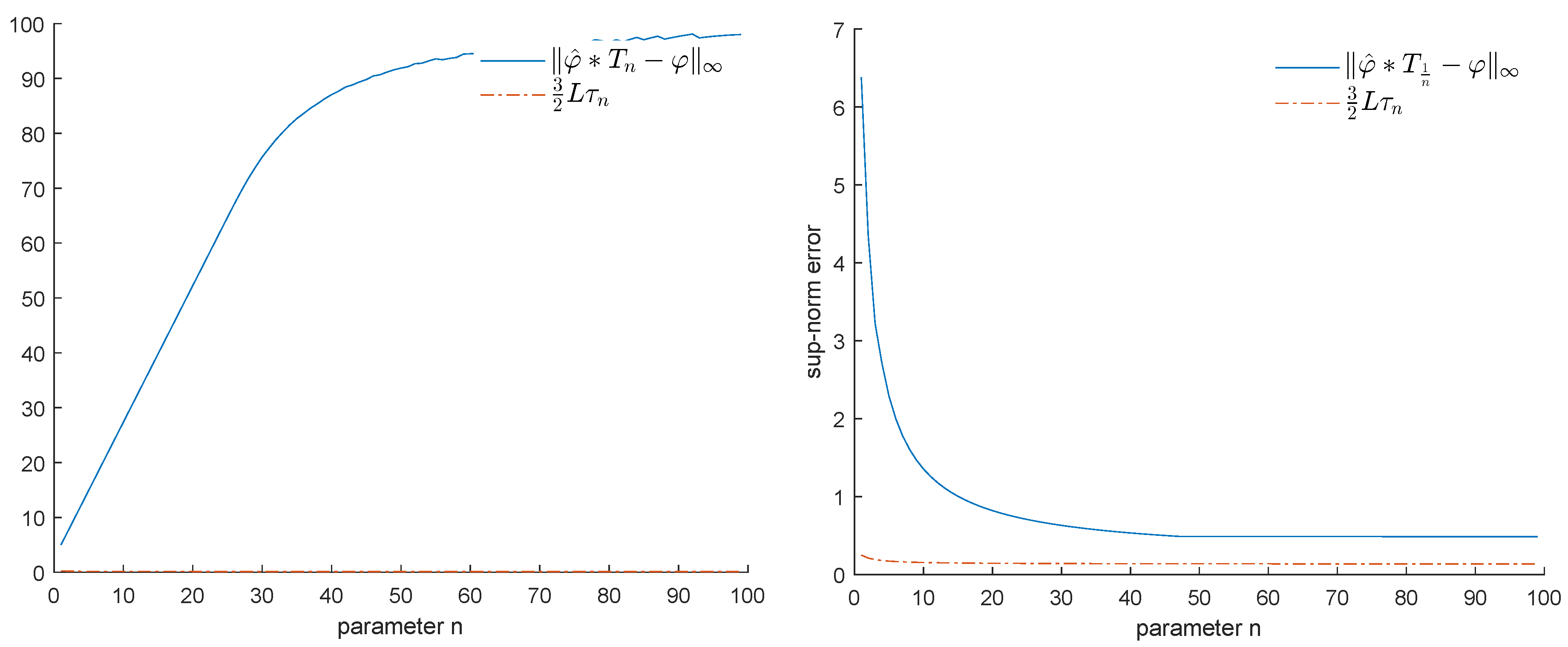
6.1.1. First Example
6.1.2. Second Example
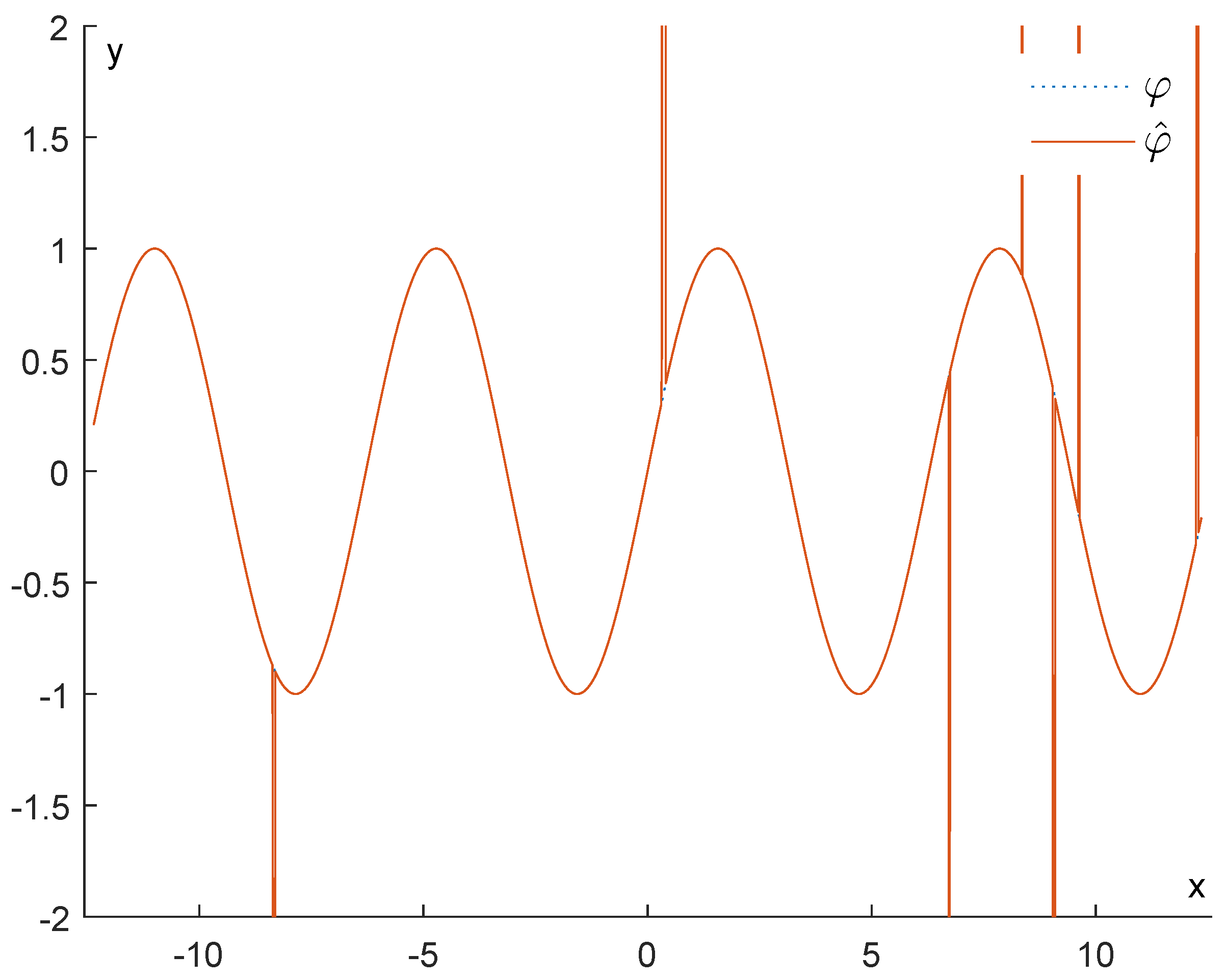
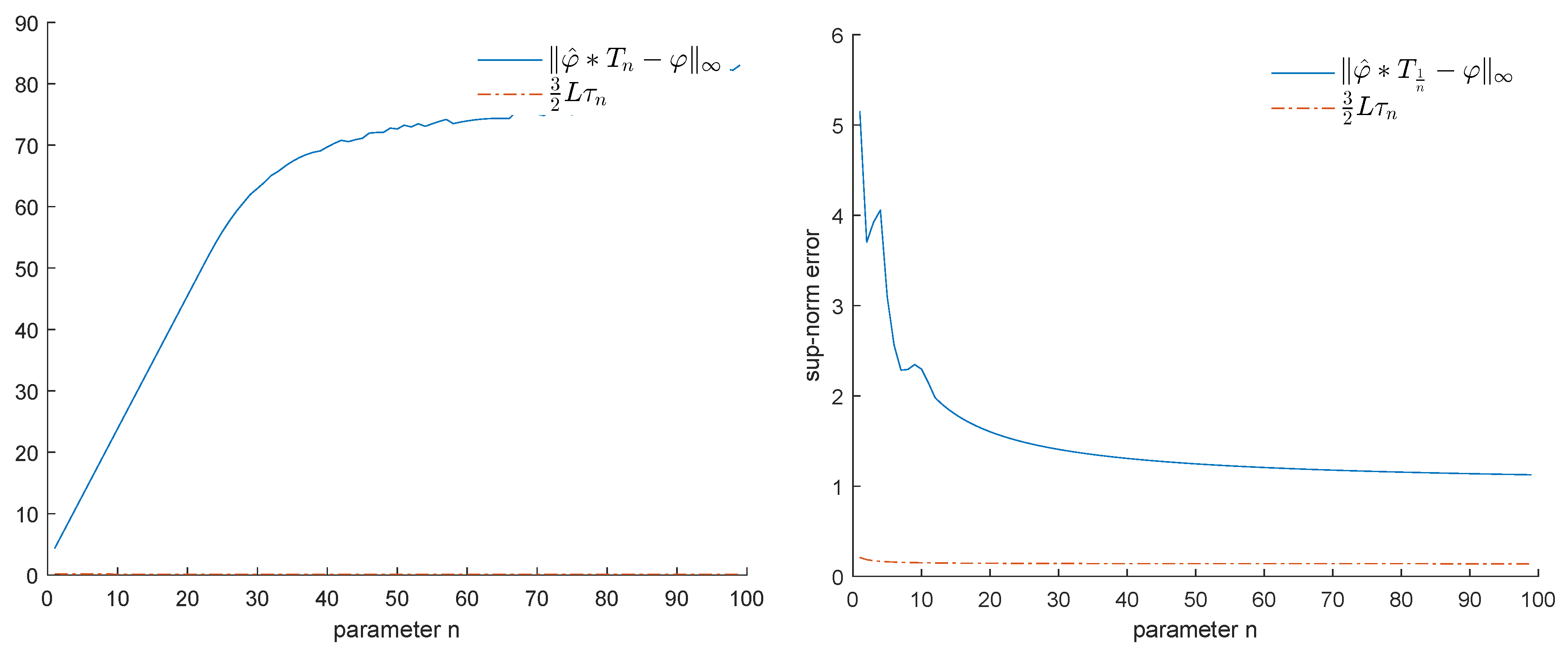
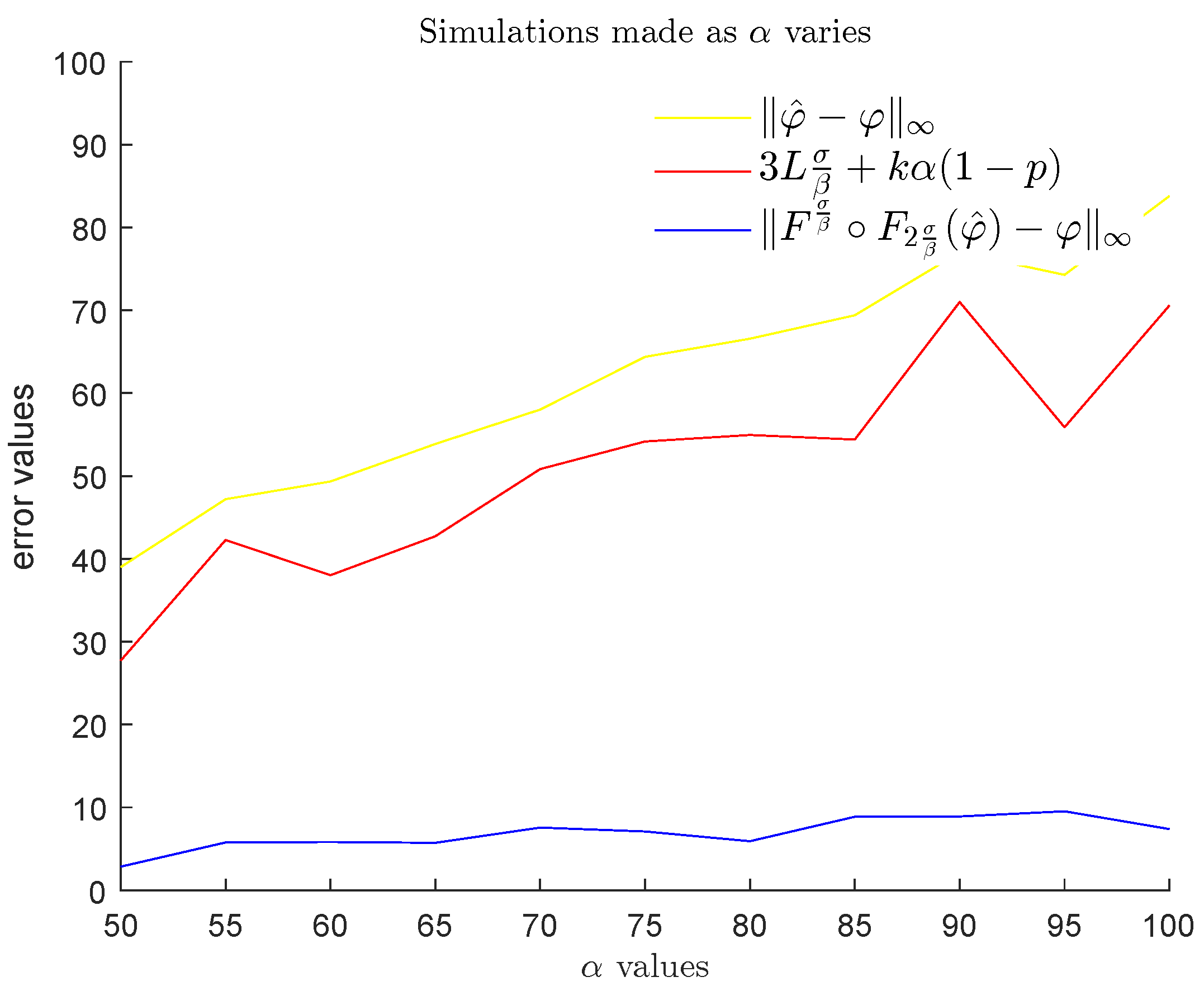
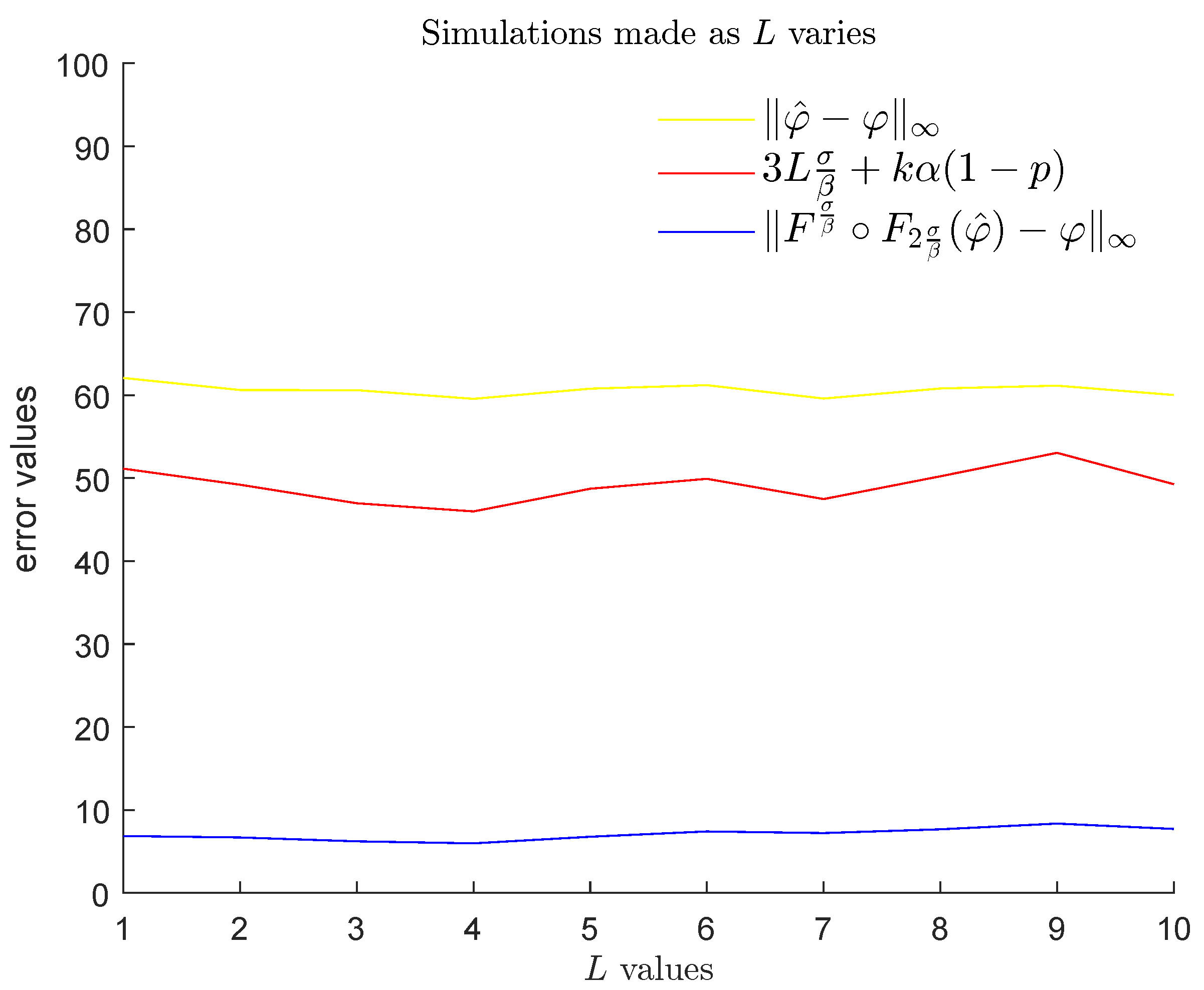
6.2. Experiments
- for
- for
- for .
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Edelsbrunner, H.; Morozov, D. Persistent homology: Theory and practice. In European Congress of Mathematics; European Mathematical Society: Zürich, Germany, 2013; pp. 31–50. [Google Scholar]
- Biasotti, S.; Floriani, L.D.; Falcidieno, B.; Frosini, P.; Giorgi, D.; Landi, C.; Papaleo, L.; Spagnuolo, M. Describing shapes by geometrical-topological properties of real functions. ACM Comput. Surv. 2008, 40, 12:1–12:87. [Google Scholar] [CrossRef]
- Carlsson, G. Topology and data. Bull. Amer. Math. Soc. 2009, 46, 255–308. [Google Scholar] [CrossRef]
- Edelsbrunner, H.; Harer, J. Persistent homology—A survey. In Surveys on Discrete and Computational Geometry; American Mathematical Society: Providence, RI, USA, 2008; Volume 453, pp. 257–282. [Google Scholar]
- Cohen-Steiner, D.; Edelsbrunner, H.; Harer, J. Stability of persistence diagrams. Discrete Comput. Geom. 2007, 37, 103–120. [Google Scholar] [CrossRef]
- Cohen-Steiner, D.; Edelsbrunner, H.; Harer, J.; Mileyko, Y. Lipschitz functions have Lp-stable persistence. Found. Comput. Math. 2010, 10, 127–139. [Google Scholar] [CrossRef]
- Fasy, B.T.; Lecci, F.; Rinaldo, A.; Wasserman, L.; Balakrishnan, S.; Singh, A. Confidence sets for persistence diagrams. Ann. Stat. 2014, 42, 2301–2339. [Google Scholar] [CrossRef]
- Buchet, M.; Chazal, F.; Dey, T.K.; Fan, F.; Oudot, S.Y.; Wang, Y. Topological analysis of scalar fields with outliers. In Proceedings of the 31st International Symposium on Computational Geometry (SoCG 2015), Eindhoven, The Netherlands, 22–25 June 2015; Leibniz International Proceedings in Informatics (LIPIcs). Arge, L., Pach, J., Eds.; Schloss Dagstuhl–Leibniz-Zentrum für Informatik: Dagstuhl, Germany, 2015; Volume 34, pp. 827–841. [Google Scholar]
- Adler, R.J.; Agami, S. Modelling persistence diagrams with planar point processes, and revealing topology with bagplots. J. Appl. Comput. Topol. 2019, 3, 139–183. [Google Scholar] [CrossRef]
- Vishwanath, S.; Fukumizu, K.; Kuriki, S.; Sriperumbudur, B.K. Robust persistence diagrams using reproducing kernels. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 21900–21911. [Google Scholar]
- Bergomi, M.G.; Frosini, P.; Giorgi, D.; Quercioli, N. Towards a topological–geometrical theory of group equivariant non-expansive operators for data analysis and machine learning. Nat. Mach. Intell. 2019, 1, 423–433. [Google Scholar] [CrossRef]
- Conti, F.; Frosini, P.; Quercioli, N. On the construction of Group Equivariant Non-Expansive Operators via permutants and symmetric functions. Front. Artif. Intell. 2022, 5, 786091. [Google Scholar] [CrossRef] [PubMed]
- Bocchi, G.; Botteghi, S.; Brasini, M.; Frosini, P.; Quercioli, N. On the finite representation of linear group equivariant operators via permutant measures. Ann. Math. Artif. Intell. 2023, 1–23. [Google Scholar] [CrossRef]
- Frosini, P.; Jabłoński, G. Combining persistent homology and invariance groups for shape comparison. Discrete Comput. Geom. 2016, 55, 373–409. [Google Scholar] [CrossRef]
- Cerri, A.; Fabio, B.D.; Ferri, M.; Frosini, P.; Landi, C. Betti numbers in multidimensional persistent homology are stable functions. Math. Methods Appl. Sci. 2013, 36, 1543–1557. [Google Scholar] [CrossRef]
- Cerri, A.; Ethier, M.; Frosini, P. On the geometrical properties of the coherent matching distance in 2D persistent homology. J. Appl. Comput. Topol. 2019, 3, 381–422. [Google Scholar] [CrossRef]
- Micheletti, A. A new paradigm for artificial intelligence based on group equivariant non-expansive operators. Eur. Math. Soc. Mag. 2023, 128, 4–12. [Google Scholar] [CrossRef]
- Vaseghi, S.V. Impulsive Noise: Modelling, Detection and Removal; John Wiley and Sons, Ltd.: Chichester, UK, 2008; Chapter 13; pp. 341–358. [Google Scholar]
- Earnest, M. Average Minimum Distance between n Points Generate i.i.d. with Uniform Dist. Mathematics Stack Exchange. Available online: https://math.stackexchange.com/q/2001026 (accessed on 13 July 2021).

























Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frosini, P.; Gridelli, I.; Pascucci, A. A Probabilistic Result on Impulsive Noise Reduction in Topological Data Analysis through Group Equivariant Non-Expansive Operators. Entropy 2023, 25, 1150. https://doi.org/10.3390/e25081150
Frosini P, Gridelli I, Pascucci A. A Probabilistic Result on Impulsive Noise Reduction in Topological Data Analysis through Group Equivariant Non-Expansive Operators. Entropy. 2023; 25(8):1150. https://doi.org/10.3390/e25081150
Chicago/Turabian StyleFrosini, Patrizio, Ivan Gridelli, and Andrea Pascucci. 2023. "A Probabilistic Result on Impulsive Noise Reduction in Topological Data Analysis through Group Equivariant Non-Expansive Operators" Entropy 25, no. 8: 1150. https://doi.org/10.3390/e25081150
APA StyleFrosini, P., Gridelli, I., & Pascucci, A. (2023). A Probabilistic Result on Impulsive Noise Reduction in Topological Data Analysis through Group Equivariant Non-Expansive Operators. Entropy, 25(8), 1150. https://doi.org/10.3390/e25081150