Abstract
Adversarial transfer learning is a machine learning method that employs an adversarial training process to learn the datasets of different domains. Recently, this method has attracted attention because it can efficiently decouple the requirements of tasks from insufficient target data. In this study, we introduce the notion of quantum adversarial transfer learning, where data are completely encoded by quantum states. A measurement-based judgment of the data label and a quantum subroutine to compute the gradients are discussed in detail. We also prove that our proposal has an exponential advantage over its classical counterparts in terms of computing resources such as the gate number of the circuits and the size of the storage required for the generated data. Finally, numerical experiments demonstrate that our model can be successfully trained, achieving high accuracy on certain datasets.
1. Introduction
Machine learning (ML) methods have successfully been applied to various fields such as speech recognition, visual object recognition, and object detection [1,2]. In recent years, ML research has been extended to applications in more complicated but ordinary scenarios, such as situations involving datasets belonging to different domains. The predicament in these scenarios is that the ML model trained on a dataset in one domain does not often work for tasks in a different domain of interest. One resource-consuming strategy used to solve the above issue is transfer learning (TL) [3,4,5,6,7,8], which estimates the usefulness of the knowledge learned in a source domain and transfers it to help the learning task in a target domain. However, conventional TL usually lacks efficiency when the distribution of the target domain data is completely different from the source domain. Recently, an adversarial transfer learning (ATL) method has been proposed to solve the issue. Such an ML scheme has the potential for a broad range of applications; it has been proven to be beneficial in areas such as natural language processing, autonomous cars, robotics, and image understanding [9,10,11,12,13,14,15,16,17,18,19].
The basic idea of the ATL method is to introduce generative models to bridge the gap between the datasets of different domains. This method is a new version of ML and cannot be provided by simply combining methods such as generative adversarial networks (GANs) [20,21,22] and TL. As schematically shown in Figure 1a, ATL controls the samples of a given source domain dataset and a target domain dataset, denoted as and , respectively. A generator is employed to produce a fake sample using and a noise vector . and are then sent to a discriminator to judge the probabilistic likelihood. The general purpose of training and is an adversarial game. Generator is required to generate as close as possible to the target data sample , cheating the discriminator . Discriminator attempts to accurately distinguish from and avoid being cheated. The game finally reaches the Nash equilibrium [23] after the parameters of the model are optimized. In cases of classification, a classifier is correctly applied to label according to the label of . In certain cases, the source domain dataset is also employed as the input of T, which increases the efficiency of the training. The key ingredient in such a scheme is the cost function of the model, which finally converges to an equilibrium point.
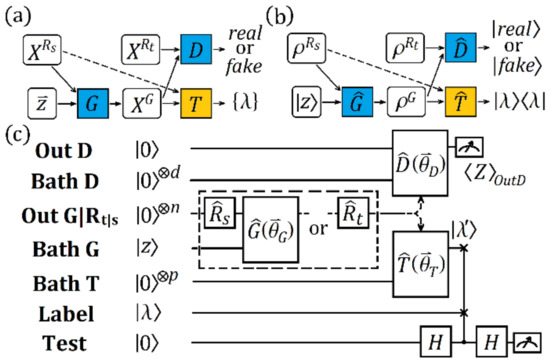
Figure 1.
(a) Model architecture of ATL. The generator produces a data sample on a source data sample and a noise vector . The discriminator distinguishes from the target data sample , assigning the judgement as “real” or “fake”. The classifier assigns task-specific labels to fake data sample XG. Note that source data sample is only accepted into the next step when the efficiency of the training is increased, as marked by the dashed arrow. (b) The corresponding QATL scheme. The data samples (, , and ) are encoded by the quantum state (, , and ), respectively. The functioning of , , and is implemented by the quantum operators , , and , respectively. The judgement of is given by a quantum state ( or ) and the label is also encoded by . (c) The quantum circuit of QATL. The qubit numbers of the registers Bath D, Out G|Rt|s, and Bath T are d, n, and p, respectively. The registers Out D and Test both contain one qubit. Their qubits are initialized as . The register Bath G stores an -qubit random state generated by the environmental coupling. The register Label has the initial state . , , , , and represent the unitary operators. The dashed box marks an option of applying two types of setups. is the Hadamard gate. is the expectation value of operator , as defined in the main text.
Despite the success of the above-mentioned method, the increasing requirements of data processing present a significant challenge to all computing strategies, including ML. As quantum computing provides an opportunity to overcome this challenge, researchers have considered addressing ML tasks using quantum machines [24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57]. Proposed quantum machine learning algorithms include quantum support vector machines [29,30], quantum deep learning [32,33,34,35,36,37,38], quantum Boltzmann machines [39,40], quantum generative adversarial learning [41,42,43,44,45], and quantum transfer learning (QTL) [47,48,49,50,51]. A quantum counterpart of ATL has not yet been provided; this could exhibit an advantageous performance in cross-domain learning tasks. To propose such a counterpart is complex because a suitable quantum cost function must be established so that the quantum adversarial game for knowledge transfer can finally converge to an equivalent point, as in classical cases. How to develop such a function in the quantum regime and how to obtain a quantum version of ATL remain unknown.
In this paper, we demonstrate how we solved the above problem, and we propose quantum adversarial transfer learning (QATL) schemes. The training process of our QATL was equivalent to an adversarial game of a quantum generator and a quantum discriminator, and we demonstrate that an equilibrium point also existed in the model. Specifically, a quantum cost function for adversarial training is provided; a measurement-based judgment of the data label and a quantum subroutine to compute the gradients are also discussed in detail. We prove that our proposal has an exponential advantage over classical counterparts in terms of computing resources such as the gate number of the circuits and the size of the storage for the generated data. This is of benefit to the transfer of complicated knowledge, during which a module is extensively called upon and a large amount of data are generated. We applied this scheme to a classification task based on the Iris dataset and the states on a Bloch sphere to prove that an extremely high classification accuracy could be achieved using this method.
2. Materials and Methods
Our QATL scheme is shown in Figure 1b. Here, the density matrix of the state that encodes a source (target) domain data sample is denoted by (). A unitary operator is employed as the quantum generator , whose parameters are denoted by a vector . It operates on the state and a quantum noise state , outputting a fake data sample . Another unitary operator, parameterized by vector , is used as the quantum discriminator . It operates on the state generated by and the state ; it then outputs the state . If it operates on , the state is . As with ATL, the general training purpose of QATL is to maximize the probability of passing the test of discriminator , simultaneously minimizing the probability of being cheated if is fake. The optimization of the parameters and are addressed when the above quantum adversarial game reaches the Nash equilibrium. We considered the classification task and applied a unitary operator parameterized by as a quantum classifier [58,59,60,61]. This provided a mapping of the data sample ( or ) to a label state ; was updated during the training.
Next, we discuss the state evolution of the above scheme on a circuit and demonstrate how an equilibrium point of the game was reached. The quantum circuit of Figure 1b is displayed in Figure 1c. The whole circuit ran on seven quantum registers. The register Out G|Rt|s containing n qubits encoded the target data, source data, or the generated data. The encoding of the target (source) data was described by the operator (), which acted on the register Out G|Rt|s. The register Bath G, containing m qubits, encoded the quantum noise state . The generator operated on Out G|Rt|s and Bath G, producing the generated data. The register Bath D, containing d qubits, was employed as the internal workspace of the discriminator , whose outputs ( or ) were stored by the register Out D. The register Bath T contained p qubits and was employed as the workspace of the classifier . The label state outputted by was compared with the single qubit label state stored by the register Label. The register Test was used to perform the estimation of the likelihood of and , so that could be properly labeled. All qubits were initialized to be , except for those in Bath G and Label. The initial state of the quantum circuit shown in Figure 1c could then be denoted by
where is the tensor product and is the tensor product of p s; this was also applicable for other similar terms. The unitary operators of such a state encoding the source domain data, target domain data, and generated data were denoted by , , and , respectively. They were given by
where represents the identity matrix. The states and were then given by
We set Bath G to be instead of rotating it to a random quantum state with extra control. A random quantum state can naturally be generated by the entanglement of the register state and environmental degrees [44]. After was generated according to the requirements, the state could be expressed by
The discriminator was applied to estimate the likelihood of and . The unitary operator of was given by
Therefore, the resultant states of and after being operated by were given by
The expectation value of operator could be measured on the register Out D. Such a value was close to 1 when generated the state ; it was close to −1 when outputted the state .
The quantum classifier we considered was forced to output the label of according to its closeness to . We also introduced this method to judge whether the label was correct. The unitary operator of was defined by
where and are two unitary operators on Out G|Rt|s and Bath T, respectively. Their parameters were denoted by and correspondingly. Thus, . The resultant states of and after being operated by were given by
One qubit of the above output state was the predicted label by . When comparing it with the label of the input by the swap test circuit [62] (which was composed of two Hadamard gates and one Fredkin gate, as shown in Figure 1c), the label of was set to be if and were close enough. The closeness of and could be estimated by the measurement of the register Test. The probability of the register Test being in state was given by
where is the overlap of and , defined by . Therefore, could be estimated by . In specific cases, we could set a suitable boundary for accepting to be the label of (see the example below). Finally, the training of the quantum model could be performed by finding the following minimax point of the quantum cost function , given by
The minimax point of was obtained by tuning and to the minimum and tuning to the maximum. The subscript represents the different samples fed into the model. The number of the samples is denoted by . is the label state outputted by when the input was the source domain data sample . Such a term provides a bias; this could increase the training efficiency. The angle is the parameter used to adjust the weight of the target domain data and the generated data in the cost function, and it could be set according to the requirements of the specific tasks. A usual form was given by considering that they were equally weighted. By setting , we obtained
The minimax optimization problem of Equation (16) was implemented by alternating between two steps. In the first step, we updated the discriminator and the classifier parameters and whilst keeping the generator parameter fixed. In the second step, we fixed and and updated . We used the gradient descent method to update parameters , and , respectively. The values of , and given by the th update were denoted by , , and , respectively, with integer ; , , and as the initial values. Hence, the update rule was expressed by
where , , and are the learning rates. In the above scheme, we used the variational quantum circuit in [44] and [58] to implement the generator , the discriminator and the classifier , as shown in Figure 1c. In [44], each quantum gate of a quantum circuit corresponded with a parameter of the quantum circuit. The number of quantum gates was polynomial in the number of qubits; that is, 3/2Lq. L was the number of layers of quantum circuits and q was the number of qubits. Therefore, the number of parameters was also 3/2Lq. In [58], each quantum gate of the circuit had three parameters. The number of quantum gates was polynomial in the number of qubits, which was 2Lq + 1. Therefore, the number of parameters was 6Lq + 3. In our scheme, the total number of quantum gates was bound by those operating on the register Out G|Rt|s, which was the sum of the number of quantum gates employed by the generator–discriminator sequence or the classifier. Based on the gate number of the above two circuits for the unitary operations we considered, the sum of the number of quantum gates remained polynomial in the number of qubits. We added two registers, Label and Test. Their gate number was constant and their impact on the complexity was negligible. In the process of obtaining the quantum cost function, the number of gates and the number of parameters of our scheme were polynomial in their number of qubits, which required exponentially fewer resources than the classical counterparts [10]. This property potentially benefits future applications for tasks involving complicated data structures. In general, if the information in a target dataset is insufficient, a large amount of data must be generated to effectively transfer the knowledge required to improve the training of the target dataset. This indicates a large storage requirement for the data and extensive calls of the modules. Otherwise, the gap between the features of different datasets is not bridged and the helpful information required to improve the training process is not captured and transferred. The improvement in computing resources by our QATL could loosen the requirements on storage and boost the efficiency of running the subroutines of the module, facilitating the execution of tasks.
To provide a more direct connection between the computation of the cost function and the updates of the parameters, we also applied two quantum circuits to calculate the gradients. Their theoretical scheme and circuit design are shown in Section SI of the Supplementary Materials. This scheme could be implemented on the recent quantum experimental platform because it was mainly based on variational quantum algorithms (VQAs) [63,64,65,66].
3. Results
To demonstrate the feasibility of QATLs, we considered their application in cases in which the probability distributions of the data in the two domains were different. The examples used the Iris dataset [67] and the states of the Bloch sphere.
The main task we considered was a classification of the Iris dataset in a numerical simulation. We chose two types of Iris flowers from the Iris dataset: versicolor and virginica. Each type contained 50 data samples. All data samples contained four attributes: sepal length (SL), sepal width (SW), petal length (PL), and petal width (PW). We considered encoding the four attributes based on the amplitudes of a two-qubit state (amplitude-encoding strategy [47]). The source domain dataset was composed of 40 data samples; 20 were picked from the Iris versicolor data samples and labeled . The other 20 were picked from Iris virginica data and labeled . The target domain dataset was also a 20/20 set chosen from samples other than those applied to the source domain dataset and without labeling. The last 10 data samples of both types were used to obtain a test dataset to check the performance of the model. The classification task labeled the target domain data samples using differently distributed source domain data. To enlarge the statistical difference of the source domain dataset and the target domain dataset and to improve the difficulty of classifying Iris flowers, we preprocessed the data samples by reducing the SL by 7 cm, the SW by 3 cm, the PL by 4 cm, and set the value of PW to 0. An illustration of the distribution of the data can be found in [67].
To show the convergence of terms of the cost function on the above datasets, we plotted the cost function and its components as a function of the training step in Figure 2a. The cost function converged to −0.217. The component was defined as , which represented the average probability of being , weighted by . represented the average probability of being , weighted by . ; this reflected the capability of to identify the generated data. , and converged to , and , respectively; thus, could not provide a fair judgement and designate all the density matrices as . The average probability of matching the label with the generated data was given by , which eventually reached −0.739. As Figure 2 clearly demonstrates, the cost function and its components converged to stable values in only 1500 training steps. We tested the trained model on the classification using the test dataset mentioned above. The classification accuracy reached 95%. The results demonstrated that an equilibrium point existed for the proposed cost function and the QATL model was workable on the dataset. Due to the generative model and adversarial training, the gap of knowledge transfer between the differently distributed datasets was effectively bridged; therefore, the accuracy of the classification was largely improved compared with previous quantum algorithms [51]. The method is shown in Appendix A. We also applied our scheme to the classification of the states of the Bloch sphere; detailed descriptions are shown in Section SII of the Supplementary Materials. A high-efficiency classification accuracy was also observed.
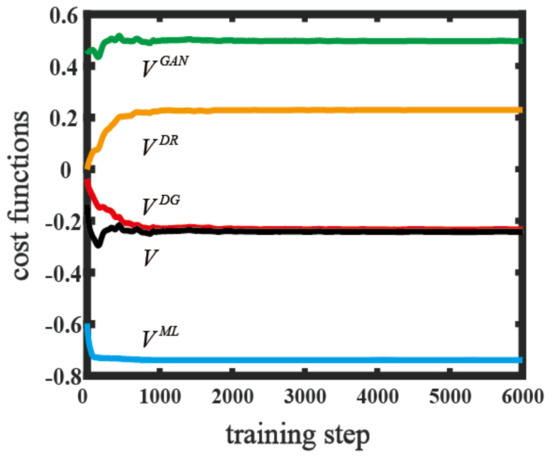
Figure 2.
The values of quantum cost functions as a function of the training step on the Iris dataset. V is the total cost function. VML, VGAN, VDG, and VDR represent various components of the cost function and are indicated by blue, green, red, and orange lines, respectively.
4. Conclusions
We demonstrated an efficient quantum machine learning scheme for cross-domain learning problems—QATL—which was a quantum counterpart of the recent and well-received ATL. Using the well-defined quantum cost function, an adversarial training process was applied to the transfer of knowledge, which was independent of specific tasks. Our numerical experiments demonstrated that the QATL model could successfully be trained and outperformed state-of-the-art algorithms in the same tasks. The complexity of the algorithm was logarithmic in terms of the number of quantum gates and training parameters, showing an advance over ATL.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/e25071090/s1. References [44,58,62] have been cited in the Supplementary Materials.
Author Contributions
Conceptualization, L.W., Y.S. and X.Z.; methodology and software, L.W.; validation, L.W., Y.S. and X.Z.; formal analysis and investigation, L.W.; writing—original draft preparation, L.W.; writing—review and editing, L.W., Y.S. and X.Z.; supervision, Y.S. and X.Z.; project administration, X.Z.; funding acquisition, Y.S. and X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China, grant no. 2017YFA0303800, and the National Natural Science Foundation of China, grant nos. 91850205 and 11904022.
Data Availability Statement
The Irish dataset, accessed 8 February 2023, used in our work can be downloaded from https://archive-beta.ics.uci.edu/.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
To complete the numerical simulation task of the theoretical scheme, we used a variational quantum circuit with eight entangled qubits from [58] to implement , , and . The quantum circuit is shown in Supplementary Materials Section S1. In our task, the register Out G|Rt|s required two qubits. As the data sample was encoded by a pure state, Bath G did not need to generate entropy. The generator , involving 15 variational parameters, could generate the data for this task. The register Bath D was not necessary. Therefore, , involving 42 variational parameters, operated on three qubits; one qubit served as Out D and the other two belonged to Out G|Rt|s. For the classifier , we noted that Bath T was not necessary. Thus, , which had 15 variational parameters, only operated on two qubits of Out G|Rt|s. The registers Label and Test required only one qubit, respectively. An additional qubit was employed to store the information of the gradient. Therefore, the workspace of the whole scheme was composed of five qubits in total.
In this scenario, we trained the gradient steps for this scheme according to the updated rules of Equation (17). At the beginning of the training sequence, the parameters were randomly chosen. Similarly, we adopted RMSProp [68] to update the learning rate. The idea of RMSProp is to divide the learning rate of a weight by a running average of the magnitudes of recent gradients for that weight. With the help of RMSProp, the learning rate is largely updated in flat directions and finely tuned in steep directions. This speeds up the training process; it has shown a good adaptation of learning rates in different applications. Here, the initial learning rates of , , and were set to 0.001, 0.001, and 0.005, respectively. The training progress terminated; after that, the cost function converged at an equilibrium point. The numerical simulation results are shown in Figure 2.
References
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2016. [Google Scholar]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Zhang, Y.; Dai, W.; Pan, S.J. Transfer Learning, 1st ed.; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; IEEE: New York, NY, USA, 2019; pp. 4171–4186. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 1–24 September 2017; IEEE: New York, NY, USA, 2017; pp. 31–36. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; Van der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; IEEE: New York, NY, USA, 2018; pp. 185–201. [Google Scholar]
- Liu, B.; Wei, Y.; Zhang, Y.; Yan, Z.; Yang, Q. Transferable contextual bandit for cross-domain recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Pan, W.; Xiang, E.; Liu, N.; Yang, Q. Transfer learning in collaborative filtering for sparsity reduction. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, NY, USA, 11–15 July 2010. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 95–104. [Google Scholar]
- Bousmalis, K.; Irpan, A.; Wohlhart, P.; Bai, Y.; Kelcey, M.; Kalakrishnan, M.; Downs, L.; Ibarz, J.; Pastor, P.; Konolige, K.; et al. Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE: Brisbane, QLD, Australia, 2018; pp. 4243–4250. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from Simulated and Unsupervised Images through Adversarial Training. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 2242–2251. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 5967–5976. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks; Springer: Cham, Switzerland, 2017; pp. 189–209. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; ACM: Sydney, Australia, 2017; pp. 1857–1865. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 2868–2876. [Google Scholar]
- Bousmalis, K.; Trigeorgis, G.; Silberman, N.; Krishnan, D.; Erhan, D. Domain separation networks. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; ACM: Barcelona, Spain, 2016. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 2962–2971. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; ACM: Sydney, Australia, 2017. [Google Scholar]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-Adversarial Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2018; ACM: New Orleans, LA, USA, 2018. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53. [Google Scholar] [CrossRef]
- Wang, K.; Gou, C.; Duan, Y.; Lin, Y.; Zheng, X.; Wang, F.-Y. Generative adversarial networks: Introduction and outlook. IEEE/CAA J. Autom. Sin. 2017, 4, 588. [Google Scholar] [CrossRef]
- Holt, C.A.; Roth, A.E. The Nash equilibrium: A perspective. Proc. Natl. Acad. Sci. USA 2004, 101, 3999. [Google Scholar] [CrossRef]
- Gu, M.; Wiesner, K.; Rieper, E.; Vedral, V. Quantum mechanics can reduce the complexity of classical models. Nat. Commun. 2012, 3, 762. [Google Scholar] [CrossRef]
- Pudenz, K.L.; Lidar, D.A. Quantum adiabatic machine learning. Quantum Inf. Process. 2013, 12, 2027. [Google Scholar] [CrossRef]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195. [Google Scholar] [CrossRef]
- Cai, X.-D.; Wu, D.; Su, Z.-E.; Chen, M.-C.; Wang, X.-L.; Li, L.; Liu, N.-L.; Lu, C.-Y.; Pan, J.-W. Entanglement-Based Machine Learning on a Quantum Computer. Phys. Rev. Lett. 2015, 114, 110504. [Google Scholar] [CrossRef]
- Hentschel, A.; Sanders, B.C. Machine Learning for Precise Quantum Measurement. Phys. Rev. Lett. 2010, 104, 063603. [Google Scholar] [CrossRef]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum Support Vector Machine for Big Data Classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Xu, N.; Du, J. Experimental Realization of a Quantum Support Vector Machine. Phys. Rev. Lett. 2015, 114, 140504. [Google Scholar] [CrossRef]
- Wossnig, L.; Zhao, Z.; Prakash, A. Quantum Linear System Algorithm for Dense Matrices. Phys. Rev. Lett. 2018, 120, 050502. [Google Scholar] [CrossRef]
- Levine, Y.; Sharir, O.; Cohen, N.; Shashua, A. Quantum Entanglement in Deep Learning Architectures. Phys. Rev. Lett. 2019, 122, 065301. [Google Scholar] [CrossRef]
- Dunjko, V.; Taylor, J.M.; Briegel, H.J. Quantum-Enhanced Machine Learning. Phys. Rev. Lett. 2016, 117, 130501. [Google Scholar] [CrossRef]
- Temme, K.; Bravyi, S.; Gambetta, J.M. Error Mitigation for Short-Depth Quantum Circuits. Phys. Rev. Lett. 2017, 119, 180509. [Google Scholar] [CrossRef]
- Cong, I.; Choi, S.; Lukin, M.D. Quantum convolutional neural networks. Nat. Phys. 2019, 15, 1273. [Google Scholar] [CrossRef]
- Nguyen, N.; Chen, K.-C. Bayesian Quantum Neural Networks. IEEE Access 2022, 10, 54110. [Google Scholar] [CrossRef]
- Zhao, Z.; Pozas-Kerstjens, A.; Rebentrost, P.; Wittek, P. Bayesian deep learning on a quantum computer. Quantum Mach. Intell. 2019, 1, 41. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, R.-G.; Xu, R.; Luo, J.; Hu, W. A quantum deep convolutional neural network for image recognition. Quantum Sci. Technol. 2020, 5, 044003. [Google Scholar] [CrossRef]
- Amin, M.H.; Andriyash, E.; Rolfe, J.; Kulchytskyy, B.; Melko, R. Quantum Boltzmann Machine. Phys. Rev. X 2018, 8, 021050. [Google Scholar] [CrossRef]
- Kieferová, M.; Wiebe, N. Tomography and generative training with quantum Boltzmann machines. Phys. Rev. A 2017, 96, 062327. [Google Scholar] [CrossRef]
- Niu, M.Y.; Zlokapa, A.; Broughton, M.; Boixo, S.; Mohseni, M.; Smelyanskyi, V.; Neven, H. Entangling Quantum Generative Adversarial Networks. Phys. Rev. Lett. 2022, 128, 220505. [Google Scholar] [CrossRef] [PubMed]
- Lloyd, S.; Weedbrook, C. Quantum Generative Adversarial Learning. Phys. Rev. Lett. 2018, 121, 040502. [Google Scholar] [CrossRef] [PubMed]
- Hu, L.; Wu, S.H.; Cai, W.; Ma, Y.; Mu, X.; Xu, Y.; Wang, H.; Song, Y.; Deng, D.; Zou, C.; et al. Quantum generative adversarial learning in a superconducting quantum circuit. Sci. Adv. 2019, 5, eaav2761. [Google Scholar] [CrossRef]
- Dallaire-Demers, P.L.; Killoran, N. Quantum generative adversarial networks. Phys. Rev. A 2018, 98, 012324. [Google Scholar] [CrossRef]
- Li, T.; Zhang, S.; Xia, J. Quantum Generative Adversarial Network: A Survey. Mater. Contin. 2020, 64, 401. [Google Scholar] [CrossRef]
- Kandala, A.; Mezzacapo, A.; Temme, K.; Takita, M.; Brink, M.; Chow, J.M.; Gambetta, J.M. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature 2017, 549, 242. [Google Scholar] [CrossRef]
- Qi, J.; Tejedor, J. Classical-to-quantum transfer learning for spoken command recognition based on quantum neural networks. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Singapore, 2022; pp. 8627–8631. [Google Scholar]
- Mari, A.; Bromley, T.R.; Izaac, J.; Schuld, M.; Killoran, N. ransfer learning in hybrid classical-quantum neural networks. Quantum 2020, 4, 340. [Google Scholar] [CrossRef]
- Gokhale, A.; Pande, M.B.; Pramod, D. Implementation of a quantum transfer learning approach to image splicing detection. Int. J. Quantum Inf. 2020, 18, 2050024. [Google Scholar] [CrossRef]
- Zen, R.; My, L.; Tan, R.; Hébert, F.; Gattobigio, M.; Miniatura, C.; Poletti, D.; Bressan, S. Transfer learning for scalability of neural-network quantum states. Phys. Rev. E 2020, 101, 053301. [Google Scholar] [CrossRef]
- Wang, L.; Sun, Y.; Zhang, X. Quantum deep transfer learning. New J. Phys. 2021, 23, 103010. [Google Scholar] [CrossRef]
- Liu, J.; Zhong, C.; Otten, M.; Chandra, A.; Cortes, C.L.; Ti, C.; Gray, S.K.; Han, X. Quantum Kerr learning. Mach. Learn. Sci. Technol. 2023, 4, 025003. [Google Scholar] [CrossRef]
- Haug, T.; Self, C.N.; Kim, M.S. Quantum machine learning of large datasets using randomized measurements. Mach. Learn. Sci. Technol. 2023, 4, 015005. [Google Scholar] [CrossRef]
- Sheng, Y.-B.; Zhou, L. Distributed secure quantum machine learning. Sci. Bull. 2017, 62, 1025. [Google Scholar] [CrossRef]
- Li, W.; Deng, D.L. Recent advances for quantum classifiers. Sci. China Phys. Mech. Astron. 2022, 65, 220301. [Google Scholar] [CrossRef]
- Li, W.; Lu, S.; Deng, D.L. Quantum federated learning through blind quantum computing. Sci. China Phys. Mech. Astron. 2021, 64, 100312. [Google Scholar] [CrossRef]
- Hu, F.; Wang, B.-N.; Wang, N.; Wang, C. Quantum machine learning with d-wave quantum computer. Quantum Eng. 2019, 1, e12. [Google Scholar] [CrossRef]
- Schuld, M.; Bocharov, A.; Svore, K.M.; Wiebe, N. Circuit-centric quantum classifiers. Phys. Rev. A 2020, 101, 032308. [Google Scholar] [CrossRef]
- Schuld, M.; Killoran, N. Quantum Machine Learning in Feature Hilbert Spaces. Phys. Rev. Lett. 2019, 122, 040504. [Google Scholar] [CrossRef]
- Havlíček, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef] [PubMed]
- Park, G.; Huh, J.; Park, D.K. Variational quantum one-class classifier. Mach. Learn. Sci. Technol. 2023, 4, 015006. [Google Scholar] [CrossRef]
- Schuld, M.; Petruccione, F. Supervised Learning with Quantum Computers; Springer: Berlin, Germany, 2018. [Google Scholar]
- Peruzzo, A.; McClean, J.; Shadbolt, P.; Yung, M.H.; Zhou, X.Q.; Love, P.J.; Aspuru-Guzik, A.; O’Brien, J.L. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 2014, 5, 4213. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.L.; Wu, Y.S.; Wan, L.C.; Pan, S.J.; Qin, S.J.; Gao, F.; Wen, Q.Y. Variational quantum algorithm for the Poisson equation. Phys. Rev. A 2021, 104, 022418. [Google Scholar] [CrossRef]
- McClean, J.R.; Romero, J.; Babbush, R.; Aspuru-Guzik, A. The theory of variational hybrid quantum-classical algorithms. New J. Phys. 2016, 18, 023023. [Google Scholar] [CrossRef]
- Blank, C.; Da Silva, A.J.; De Albuquerque, L.P.; Petruccione, F.; Park, D.K. Compact quantum kernel-based binary classifier. Quantum Sci. Technol. 2022, 7, 045007. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, X.D. Entanglement-based quantum deep learning. New J. Phys. 2020, 22, 033041. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, S.; Zhang, H.; Mandic, D.P. Convergence of the RMSProp deep learning method with penalty for nonconvex optimization. Neural Netw. 2021, 139, 17. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).