3.1. Overview
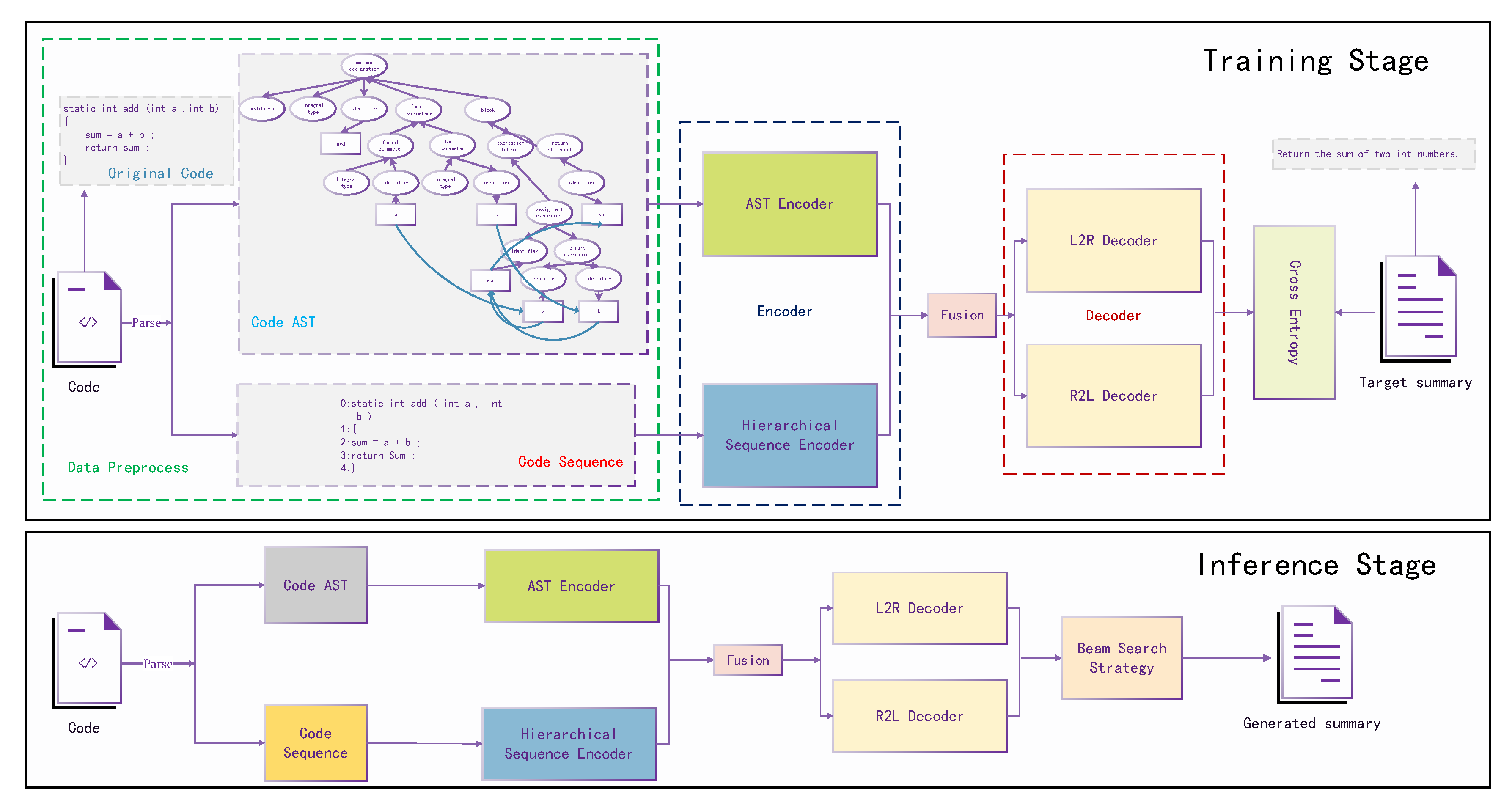
The overview of our proposed method(SSCS) is shown in
Figure 1.
To detail our proposed method, we separate the whole process into two stages, training stage and inference stage. We can clearly see that SSCS contains three main components encoder, fusion module and decoder, which will be detailed in the following section.
As shown in
Figure 1, code and ground-truth summary are both utilized in the training stage, while only code will be utilized in the inference stage. First the code will be processed into AST and lines of code sequence for the AST encoder and hierarchical sequence encoder, respectively, followed by a fusion module. Later the fusion output will be used by the decoder. The main difference between the training stage and inference stage is the process of the decoder. In the training stage, the ground-truth summary will be fed into the decoder and computes the loss with the decoder output for backward propagation, while the input is the generated token from the last step in the inference stage.
3.2. Data Preprocessing
The dataset we use for our work contains large <code, summary> pairs. We simply tokenize the summary into a list of tokens. Furthermore, to reduce out-of-vocabulary issues caused by a large scale of unique tokens, we tokenize any CamelCase or snake_case defined by developers. The process of acquiring sequence information for code is same as the summary but we maintain the document property of code. Thus, the code sequence information consists of multiple tokenized lines of code sub-sequence.
Knowing that SSCS is a structure and sequence aligned model, we also need to parse code into an AST to obtain structural information. In this paper, we evaluate our method on two public Java and Python datasets. We generate Abstract Syntax Trees (ASTs) with open-source tool tree-sitter (
https://tree-sitter.github.io/ (accessed on 15 July 2022)) for Java code and
(
https://github.com/python/cpython/blob/master/Lib/ast.py (accessed on 26 July 2022)) module for Python code. Moreover, we also add extra data flow information to strengthen the structural information. As shown in
Figure 1, the variable
is computed from addition of
a and
b, and we can see in the Code AST that the leaf node
has data relationships with variable
a and variable
b, respectively. Finally, we obtain the node sequence by pre-order traversal and its adjacency as the AST encoder inputs.
3.4. AST Encoder
Wu et al. [
9] proposed the SiT model which used transformer architecture to directly capture the structural information instead of using Graph Neural Networks that inspired our work. Inspired by SiT, we designed a transformer-based AST encoder capturing the structural information in multi-view. From the last section, we know that two inputs will be imported into the AST encoder, so we first define each input. Given an AST with
L nodes
, where
denotes each node vector and
denotes the dimension of node vector in vector space
R.
A denotes the adjacency matrix in the shape of
LX
L, the computation process of the AST encoder can be split into three blocks: multi-view attention computation, adapted weight fusion and feed-forward network.
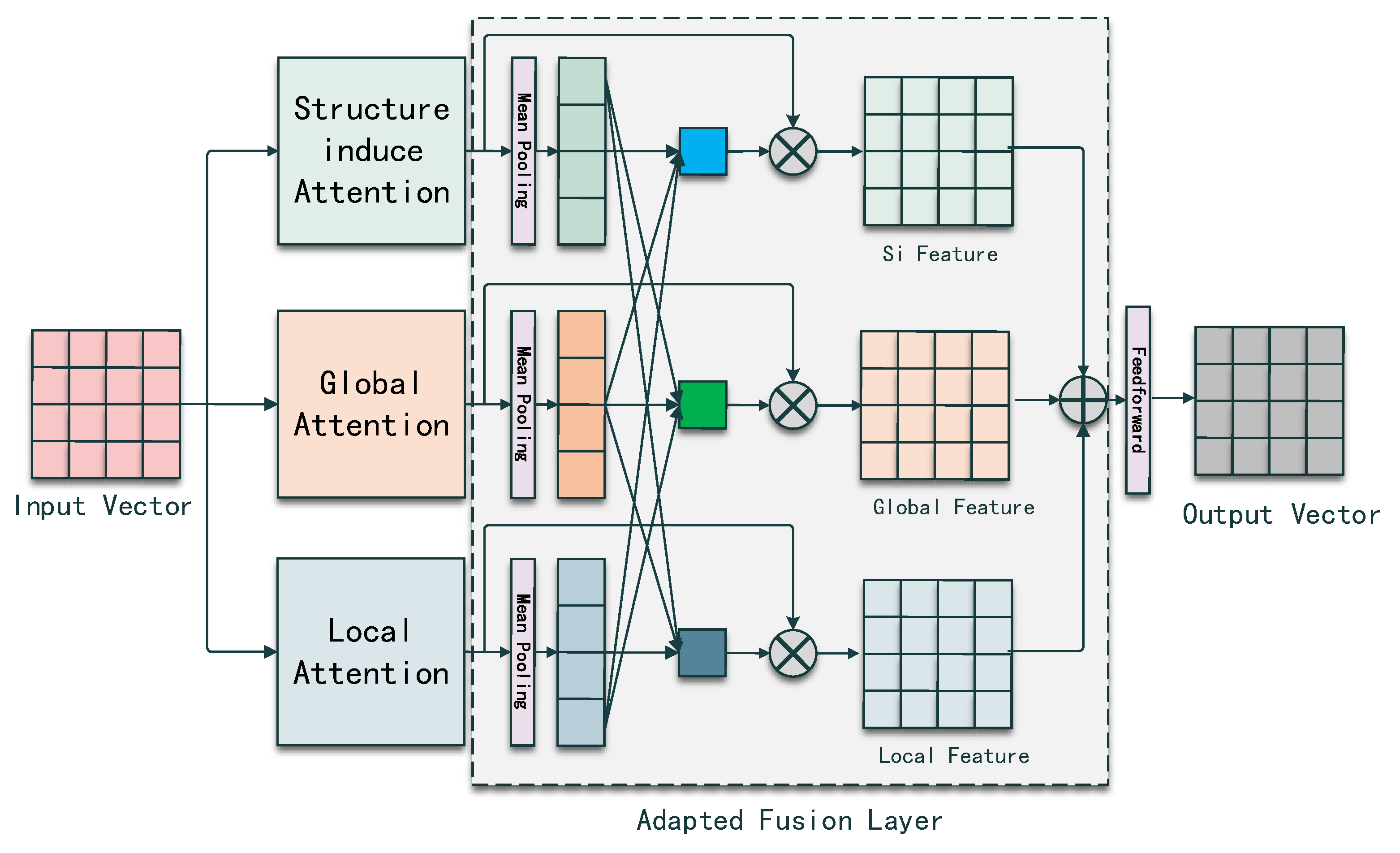
Figure 2 shows the overview of an AST encoder.
Global Self-Attention The computation of the global self-attention is based on the vanilla self-attention in transformers [
7]. We treat the AST of the source code as an undirected complete graph, which means a node
can learn the relation from the whole tree without any blocking. Therefore, we are able to capture the global AST representation. The global self-attention mechanism is denoted as follows:
where
denotes the input sequence of nodes,
l denotes the node sequence length and
is the dimension of
K.
,
and
,
,
,
are three learnable matrices using as projection to transform the vector space into a different vector space.
and
represent matrix multiply operation (matrix N dot matrix W).
Structure-induced Self-Attention We follow the previous work by Wu et al. [
9] to represent the structure information using transformer architecture equipped with a special attention mechanism. The structure-induced self-attention network (Si-SAN) is able to capture the structural information instead of using Graph Neural Networks (GNNs). The computation of the Si-San is to multiply the adjacency matrix by key-query pairs:
where
A denotes the adjacency matrix of the code.
denotes there is an edge between
and
. The attention score between
and
will be dropped out when
in
A.
Local Self-Attention To further capture the structural information, we also adopt a local attention network to capture the local information. By adding a window mask, we can initialize a window which can slide through the whole tree to learn the local relation.
where
denotes the window matrix for constraining the computation of node pairs in window distance.
Adaptive Weight Fusion Layer In SiT [
9], the process of the encoder module is a global self-attention network followed by a structure-induced self-attention network, where the global information will be diluted by the Si-SAN. Thus, we adopt a superior fusion strategy for the different views of information by using an adaptive weight fusion layer, which is shown in
Figure 2.
Given the outputs
G,
S,
L from the
,
and
, we first use a Mean Pooling Module to condense
G,
S,
into
,
,
.
For vector
,
obtains the relation weights by summing up the vectors after matrix multiplication with the rest of the two dense vectors and
and
repeat the same process. To simplify the computation, we join
,
and
and compute the dot value between the joint matrix and its transpose matrix. We sum up the relation weights and normalize as the adaptive weight for
.
and
repeat the same process to obtain the adaptive weight for themselves. The computation process is shown below.
where
,
are the adaptive for
G,
S and
L.
refers to the
activation function for normalizing the weight. “:” denotes the joint operation.
The final AST encoder output is the weighted sum of
and
L followed by a Feed-Forward network.
where
x denotes the output from the adaptive weight fusion layer,
are two learnable matrices. For activation function
,
.
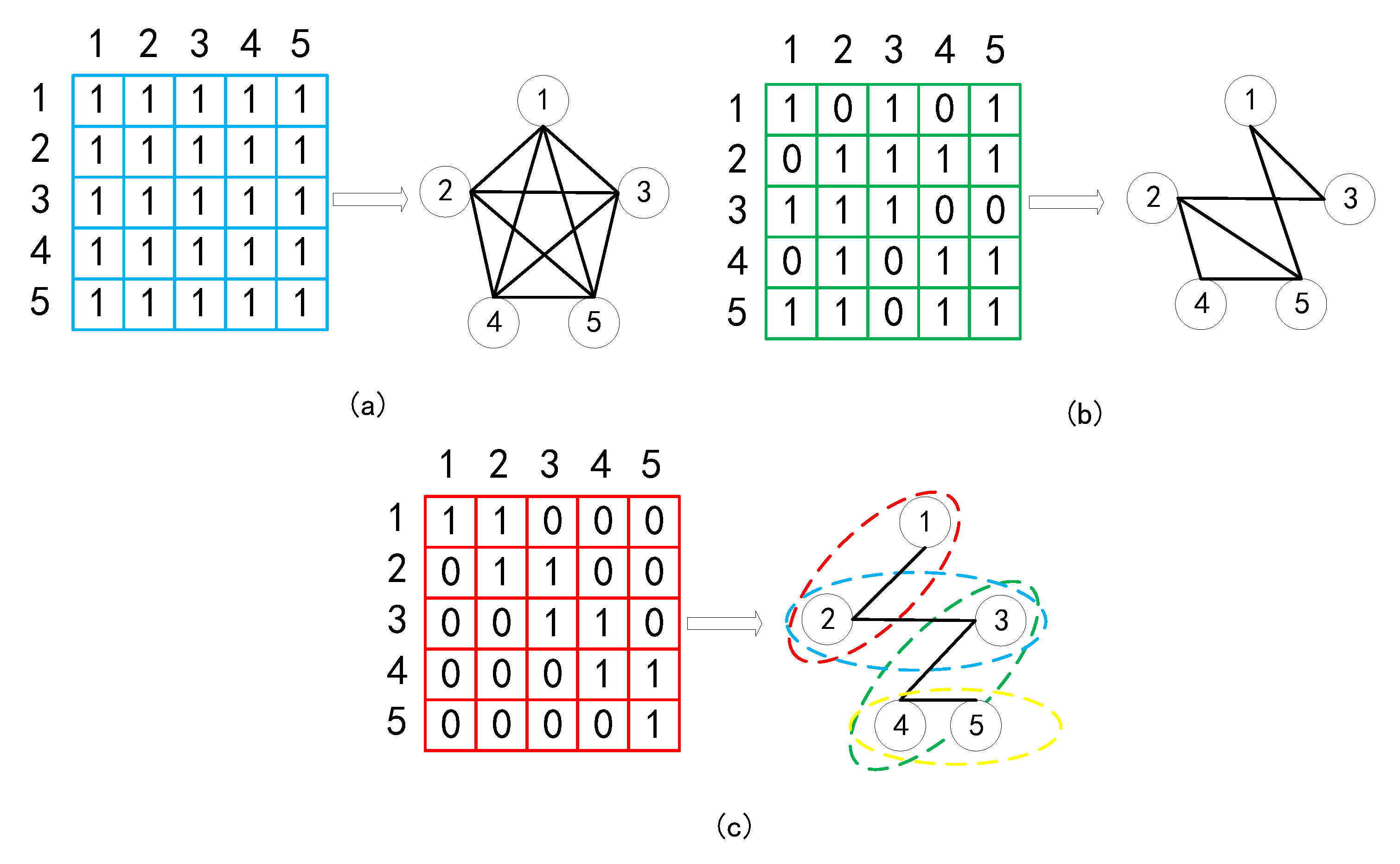
During attention computation stage, the
operation creates a square matrix, so we can utilize mask strategy to control the reception field. To better understand why the mask matrices are able to control the receptive field allowing the AST encoder to capture multi-view information, we visualize three kinds of mask matrix, two are human-defined (global mask and window mask) and one (structure-induced mask) is from the AST in
Figure 3. The global mask (
Figure 3a) is a matrix filled with “1”, allowing the node sequence to construct a fully connected graph to capture global information (can be omitted). Each node is able to study from the rest of them. For the structure-induced mask (
Figure 3b), each node studies according to the adjacency extracted from the AST and only studies from the node with an edge connection. The window mask is a special mask simulating the sliding window. As shown in
Figure 3c, we take a window with size 2 as example. As the window is sliding forward, we are able to capture local information at each window.
3.5. Hierarchical Sequence Encoder
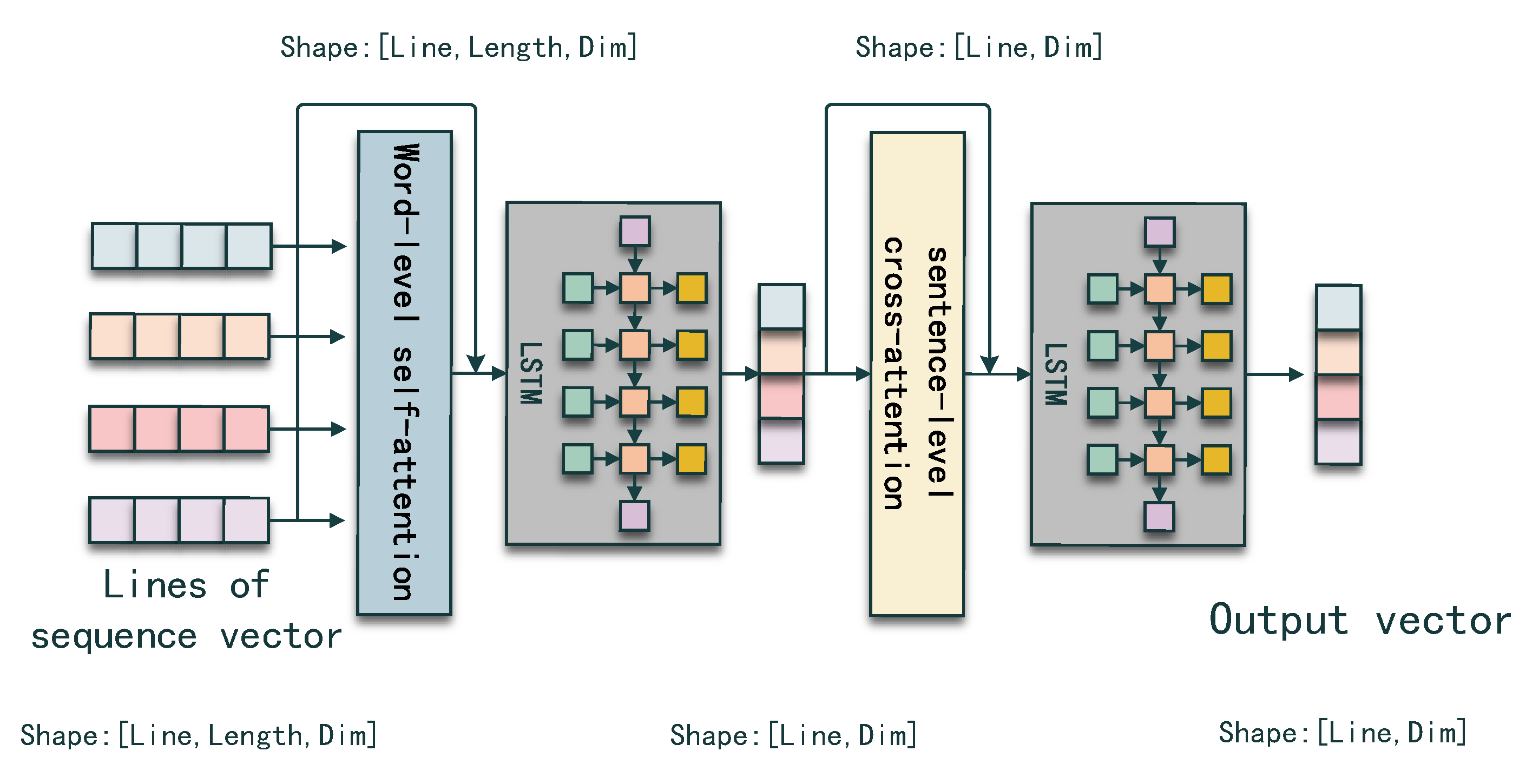
A code snippet is some kind of document which consists of several statement sequences. To maintain the document property instead of treating a code snippet as a single sequence, we adopt a hierarchical encoding strategy which captures the code sequence information from token-level to sentence-level.
Given lines of code sub-sequences
,
, where
m denotes the max sequence length between all the sub-sequences and
n denotes the line number, we are able to capture the hierarchical information using a hierarchical sequence encoder. The procedure is shown in
Figure 3.
First, we use the self-attention mechanism to capture the relation between the tokens in each sub-sequence. The first step output
can be formulated as follows:
where
,
is the token representation.
Second, to obtain the sentence-level representation, we send the first step output into a long short-term memory network (LSTM), which is able to condense the token-level representation into the sentence-level representation and capture the position information. The final layer of the hidden state in each sub-sequence computation stage is used as the sentence-level representation for each sub-sequence.
where
,
is the final layer hidden state in the
mth time step generated by
.
Then, in the same way as step one, we adopt the self-attention mechanism to capture the relation between sub-sequences.
Finally, the second LSTM network has the same effect as the first LSTM network. We use all the final layer hidden states generated in each time step as the code sequence representation.
In
Figure 4, we also represent the change of the vector shape in each step to better represent the hierarchical encoding process. At first, the shape of input lines sequence vector is 3D, which has three dimensions ([Line, Length, Dim]), and after the word-level self-attention and LSTM, the vector is compressed into 2D ([Line, Dim]). The final shape remains 2D after the sentence-level self-attention and LSTM modules. Thus, we transform 3D lines of sequence vector into a 2D vector for later combination.
3.6. Encoder Output Fusion
In above section, we utilized two encoders for capturing structural information and sequence information. We define the output from the AST encoder as and from the hierarchical sequence encoder.
The SSCS encoder output is obtained by jointing the outputs from the AST encoder and hierarchical code sequence encoder. The computation is as follows:
where
denotes the AST encoder and
denotes the hierarchical code sequence encoder.
N refers to the input node vector and
A is adjacency.
S refers to the lines of code sequence.
The encoder output will be utilized in the decoding stage for generating the summary.
3.7. Bidirectional Decoder
Liu et al. [
29] found that the quality of the prefixes of translation hypotheses is much higher than that of the suffixes in machine translation tasks. Furthermore, in order to produce more balanced translations, Liu et al. adopted a simple strategy for joint training the forward decoder and the backward decoder.
Inspired by the previous work of Liu et al., we adopt the same strategy to produce more balanced predictions. We simultaneously generate sequence in the Left-to-Right (L2R) direction and Right-to-Left (R2L) direction. Both directions guide each other by optimizing the shared parameters which are learnable. We define the input vector for the L2R decoder as and for the R2L decoder. The L2R decoder and R2L decoder can be regarded as two sub-tasks. By optimizing the shared parameters, one task can guide the other one. The details are presented below.
The L2R decoder and R2L decoder share the same Embedding Layer, which converts the one-hot vector of the token into a dense vector:
where
,
W is a learnable matrix, a converting discrete vector into a continuous vector.
denotes position encoding operation, used for capturing sequence order.
We define
in different directions as
. The two directions’ multi-head attention outputs can be computed as below:
After the attention computation, the outputs will be sent into a Feed-Forward network, which contains two linear transformations and a ReLU activation function.
By using the function, we can obtain the probability of the generated token.
In the training stage, the bidirectional guiding decoder generates two directions’ outputs. Our goal is to find the parameter
which can maximize the likelihood of success. For a training data pair
,
is the encoder output,
and
are the decoder inputs. The generation procedure is auto-regressive which means the generation for the next token is based on the previous all generated tokens. We compute the likelihood as follows:
The final likelihood function is the joint of the likelihood functions of two sub-tasks:
where
is the weight to balance the guidance of the two sub-tasks.
decides the training purpose to focus on which direction task more. j denotes the time step and J denotes the whole generating step length.
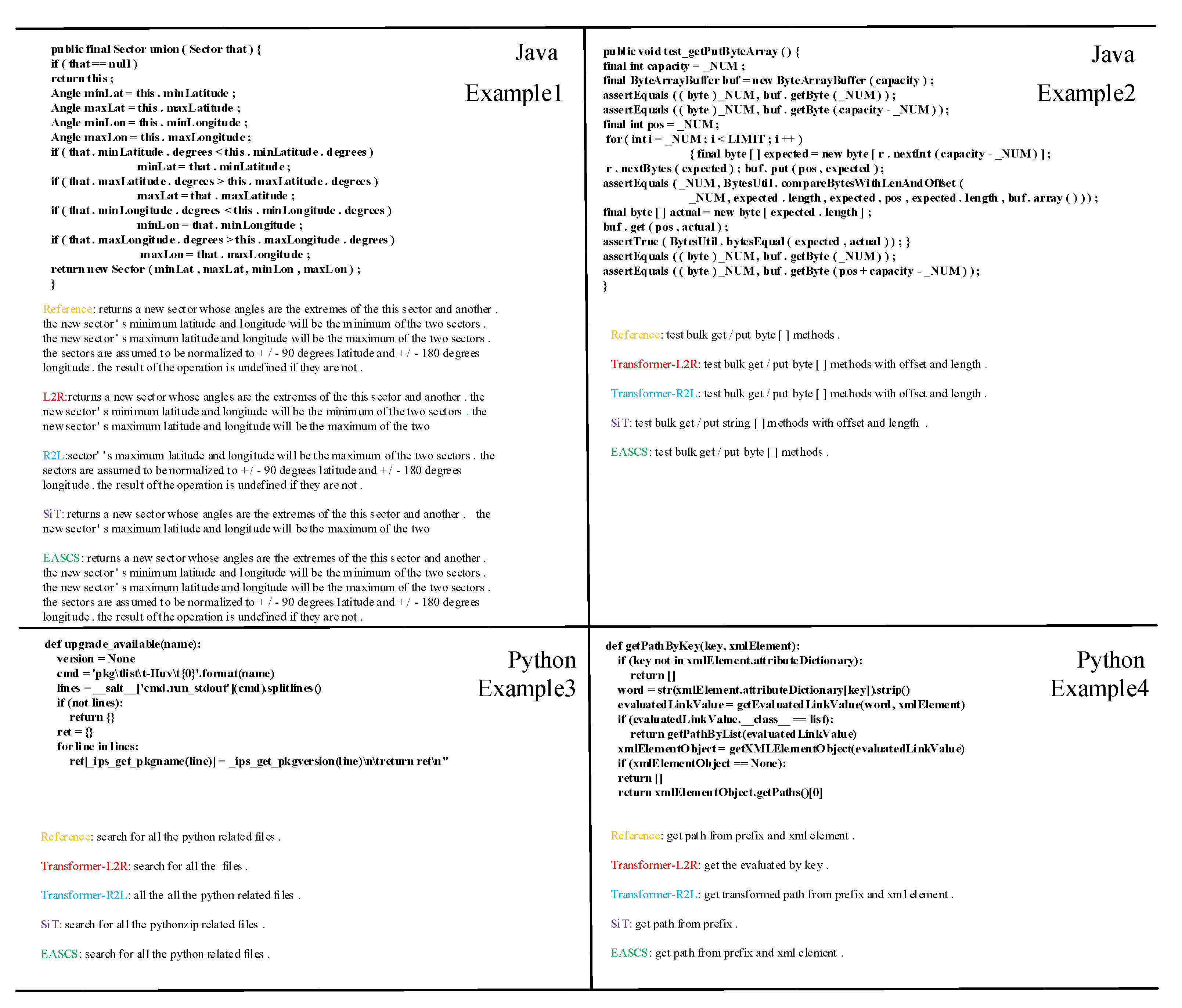
Different from the training stage, we adopt a beam search strategy for the summary generation. Beam search strategy expands the searching area reserving the best top k token (k denotes the beam size) instead of shrinking the best one as in a greedy search. For each inference step, we generate beam-size candidate sequences and reserve k-best at last. The final sequence is chosen between the two outputs from the L2R decoder and the R2L decoder. Furthermore, we can regard greedy search as a beam search strategy when beam size is 1.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}