2.2. Pre-Classification
For multinomial data, when the number of categories
m is large, it is sometimes not realistic to treat all categories equally. For example, of all the cities in China, only a few of them account for half of the economy, which means that the rest of the cities have a small average share. The well-known Pareto principle [
33] that 20% of the population owns 80% of the wealth in society also illustrates this phenomenon. Therefore, it is reasonable to classify the categories with different orders of magnitude.
Consider problem (
1), i.e.,
We denote
under
, and
,
under
. Denote
,
. Note that
.
Similar to Wang et al. [
20], let
be a subset of
such that
,
be a subset of
such that
, where
is
satisfying some conditions as
. Let
and
, where the superscript
c stands for the complement operator. Assume that
and
for some
as
. Let
and
. Then,
m categories are divided into large and small orders of magnitude by
denoted by
A and
B. A change from
to
might occur either in
A or
B.
Let
be the component of
in
A for
and
be the component of
in
A. Let
and
be similarly defined. Then, the marginal distributions of
and
under the null assumption are
and
In the next subsection, we construct a statistic built on the marginal distributions (
5) and (
6).
Here are some additional notations. Denote , , as the number of experiments in total, before and after time k, and , , as the number of successful trials in total, before and after time k. Let , , and be the corresponding frequencies.
For the data in
A, let
,
,
be the number of successful trials in total, before and after time
k. Define
,
, and
as the sum of successful trials in
B of total, before, and after
k. Let
,
,
,
,
,
,
be the corresponding frequencies. Subscript
S denotes the sum of frequencies. Similarly, we define
,
,
,
,
,
,
,
,
,
,
,
,
. We illustrate some of the above notations in
Table 1 in a more structured fashion.
2.3. Test Statistic
We use MI between the data
and the location of the data to construct the statistic. For the data in
A, the entropy is
The entropies in
A before and after
k are
and
respectively.
Denote
the location of
is before
as the indicator function of the position of a sample relative to
k. Note that, given the observations,
by the independence. By
Section 2.1, the MI between
X and
in
A is
where
is the conditional entropy of
X given
. Similarly,
, where
,
and
are defined similarly as in (
7)–(
9).
The uncertainty of X given would reach the largest reduction if k is at the true break point ; hence, either or should be large. On the contrary, if the sequence is stable, the value of should be small for any .
Since
A and
B are unknown, in light of Wang et al. [
20], we use
to estimate
A. Here,
is some constant. As shown in [
20],
is a consistent estimator of
A if
satisfies certain assumptions. Let
. Construct the test statistic
for (
1). Summation and maximization are conducted respectively for the MI of
and
in
. The first term in
is the weighted log-likelihood ratio estimate, as pointed out after Lemma 1. The second term in
is based on the maximum norm of MI. It is widely acknowledged that the max-norm test is more suitable for sparse and strong signals, see [
34,
35].
is a threshold for
, which ensures that the second term in
converges to zero under
.
is a large number. Note that the statistic in [
20] is based on the Pearson Chi-square statistic. Since in reality, the frequencies of small categories might be zeros, the Pearson Chi-square statistic for
is hence modified. The statistic presented here does not need to take into account the fact that a frequency may be zero, since by the definition of entropy,
if
. In order to study the properties of
better, we first give a lemma about MI .
Lemma 1. Denote . Then, . It is also true by replacing A with B in all the subscripts, that is, .
Note that and in Lemma 1 are estimations of minus two log likelihood ratios for data in A and B when the change-point is at k. Therefore, the problem based on MI can be transformed into the problem based on likelihood ratios.
By Lemma 1, the second term in (
11) is
, and hence the existing limit theorems on likelihood ratios can be applied to it directly. The first term in (
11) is
, which has the form of a weighted log likelihood ratio estimation. In
Appendix A, we show that it is only an infinitesimal quantity away from some CUSUM statistic [
36] using Taylor expansion and then prove the asymptotic distribution of
from related conclusions.
The sum of
without weighting,
, is closely related to the Shiryayev–Roberts procedure [
37,
38]. It uses
as a statistic, where
is the likelihood ratio when the change point is at
k. It is widely applied to determine the best stopping criterion in sequential change-point monitoring (see, e.g., [
39]). However, replacing unknown parameters in
with their maximum likelihood estimation, which leads to
in this paper, would result in a complex asymptotic analysis [
40]. So, here we use the weighted version
instead of
.
Theorem 1. Let denote the cardinality of any set A and denote the maximal cardinality of the set A. Assume that , and
- (i)
as ,
- (ii)
and as ,
- (iii)
,
.
Then, under ,as , where , . Theorem 1 shows that
is asymptotically normally distributed under the null hypothesis. The condition (
i) in Theorem 1 ensures the consistency of
, which was also assumed in Theorem 1 of [
20]. The condition (
) in Theorem 1 requires the threshold
to be large enough in order to guarantee that
converges to zero with probability one under the null hypothesis. Condition (
) means that every
is much less than
N. Next, we focus on the properties of the statistic under the alternative hypothesis.
Theorem 2. Assume that the conditions (i)–() in Theorem 1 hold. Let , . Further assume that
- (i)
as , where .
- (ii)
as , , and there exist such that for as .
If the shift sizes satisfy either of the following two conditions,
- (iii)
for some ,
- (iv)
for some ,
then as ,where is the critical value of the standard normal distribution at level α. Theorem 2 establishes the consistency of the test under certain conditions when the probability in
A or
B changes. Condition (
i) in Theorem 2 means that
tends to infinity at a certain rate. It aims to ensure that
tends to infinity when the parameters in
A change. Condition (
) requires comparable sample sizes before and after the change point. The proofs of Theorem 1 and Theorem 2 are provided in
Appendix A.
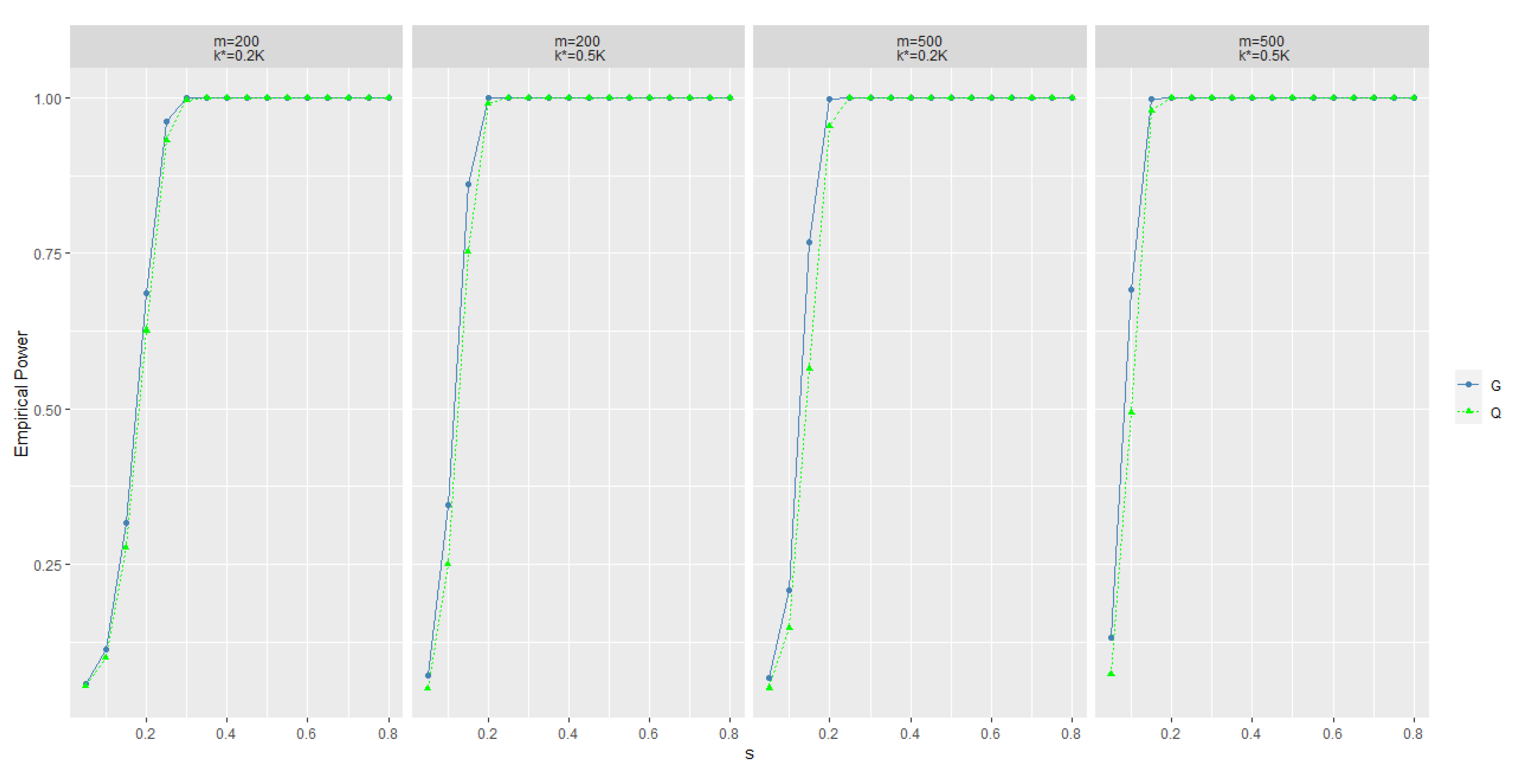
Once is rejected, we further use MI to estimate . If , then ; otherwise, . Numeric studies in the next section show that the power of the new statistic increases rapidly as the difference between the alternative hypothesis and the null hypothesis increases. At the same time, the precision of using pre-classification is also satisfactory.









{kind=link}
{kind=link}
{kind=link}
{kind=link}