





Quick Estimate of Information Decomposition for Text Style Transfer


Abstract
1. Introduction
2. Related Work
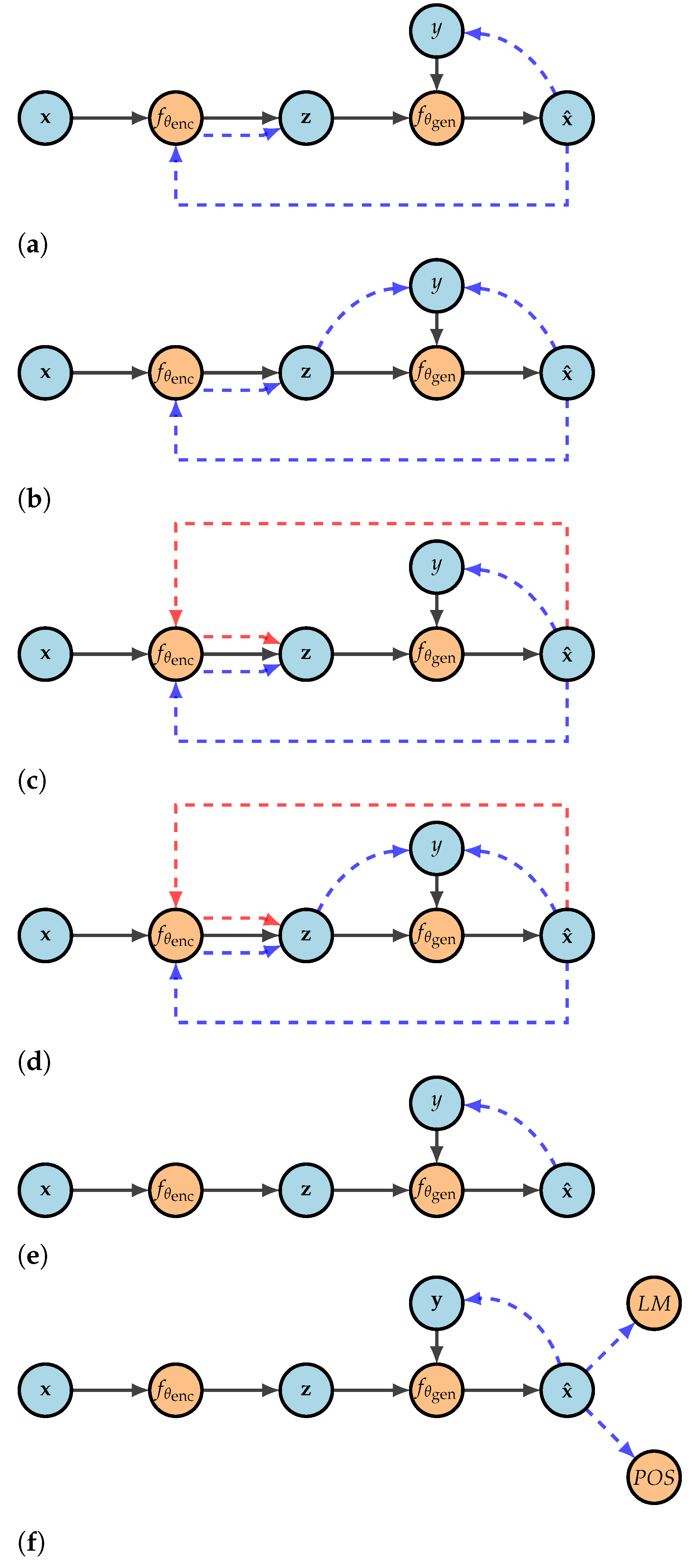
3. Style Transfer
4. Qualifying Latent Representations with Coinformation
5. Experiments
5.1. Calculating Mutual Information
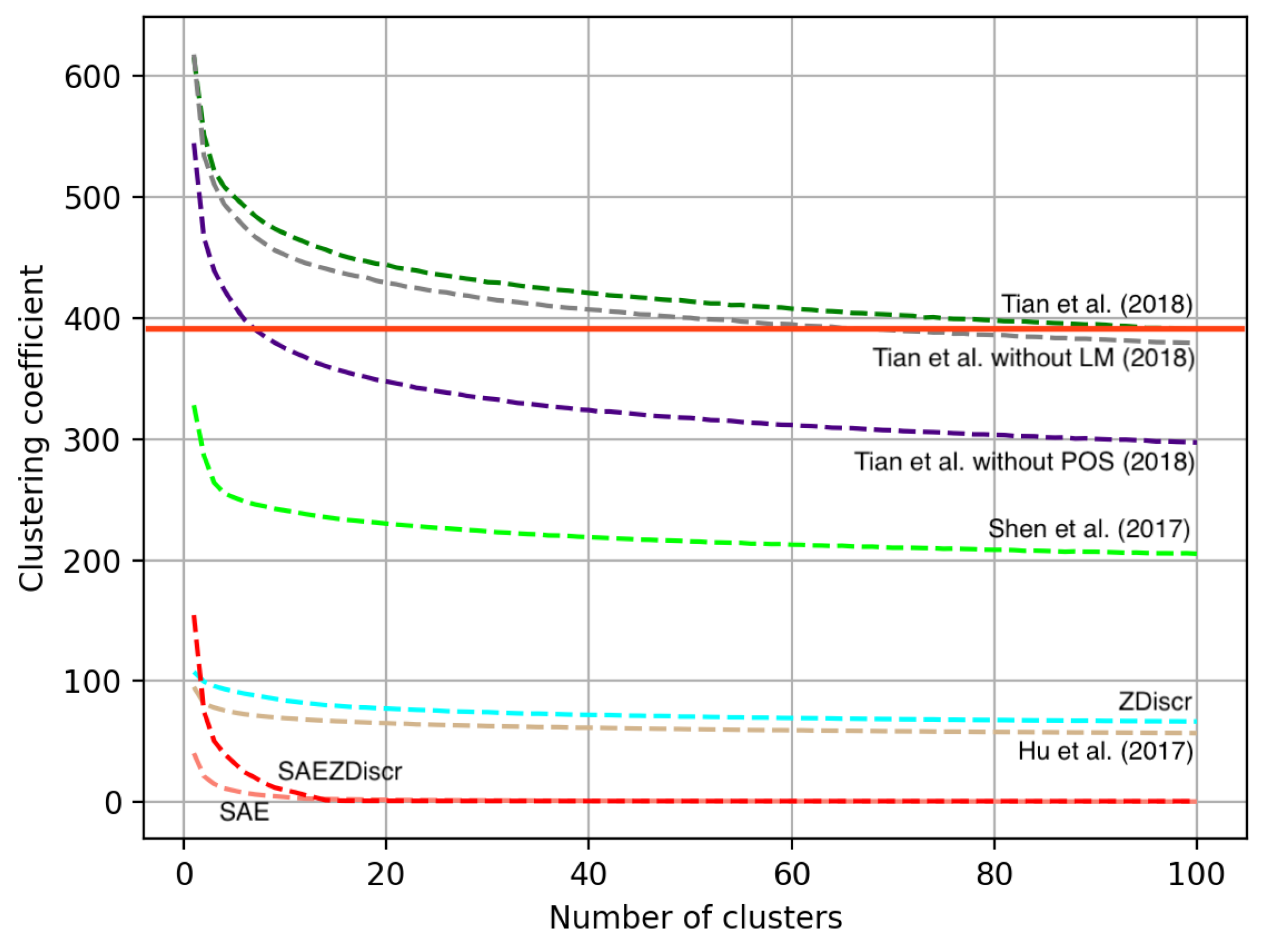
5.2. Exploring Latent Spaces
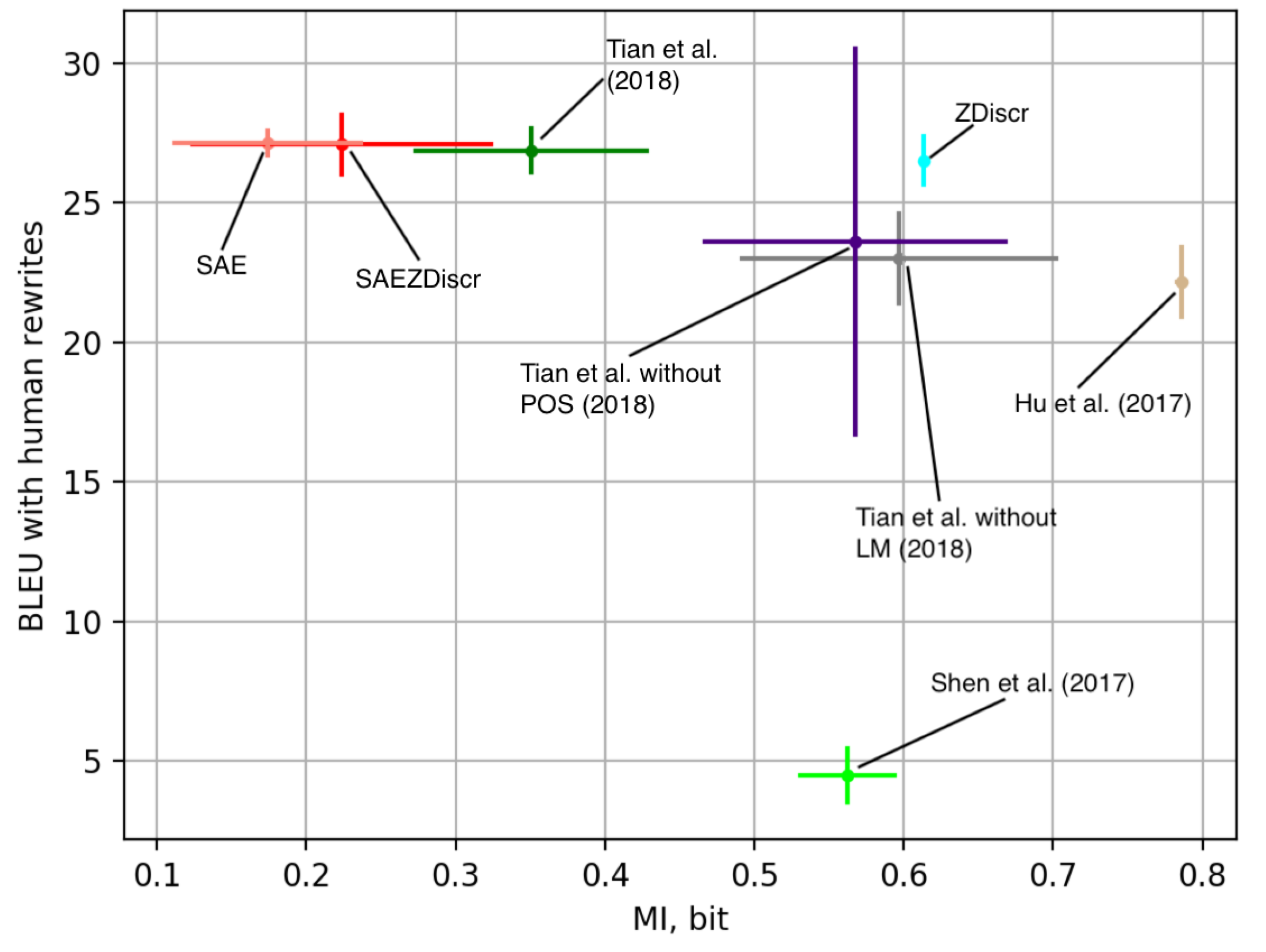
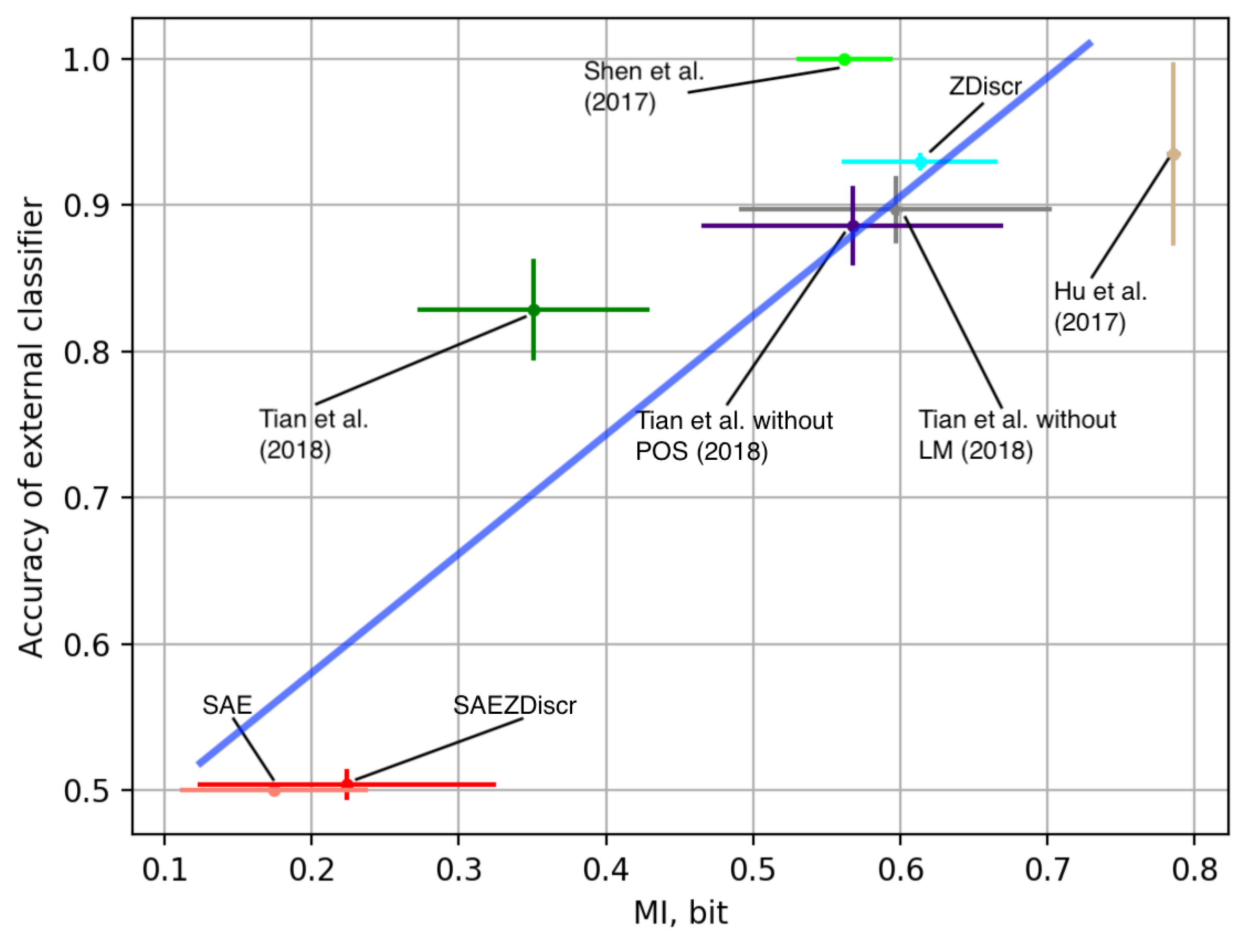
5.3. Correspondence with Empirical Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hu, Z.; Yang, Z.; Liang, X.; Salakhutdinov, R.; Xing, E.P. Toward Controlled Generation of Text. In Proceedings of the International Conference on Machine Learning, Ho Chi Minh City, Vietnam, 13–16 January 2017; pp. 1587–1596. [Google Scholar]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 632–642. [Google Scholar]
- Shen, T.; Lei, T.; Barzilay, R.; Jaakkola, T. Style transfer from non-parallel text by cross-alignment. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6830–6841. [Google Scholar]
- Fu, Z.; Tan, X.; Peng, N.; Zhao, D.; Yan, R. Style transfer in text: Exploration and evaluation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Tian, Y.; Hu, Z.; Yu, Z. Structured Content Preservation for Unsupervised Text Style Transfer. arXiv 2018, arXiv:1810.06526. [Google Scholar]
- Romanov, A.; Rumshisky, A.; Rogers, A.; Donahue, D. Adversarial Decomposition of Text Representation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MI, USA, 2019; pp. 815–825. [Google Scholar]
- John, V.; Mou, L.; Bahuleyan, H.; Vechtomova, O. Disentangled Representation Learning for Non-Parallel Text Style Transfer. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 424–434. [Google Scholar]
- Halevi, G.; Wadhawan, K. Text Style Transfer Using Partly-Shared Decoder. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1563–1567. [Google Scholar]
- Tikhonov, A.; Shibaev, V.; Nagaev, A.; Nugmanova, A.; Yamshchikov, I.P. Style Transfer for Texts: Retrain, Report Errors, Compare with Rewrites. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3927–3936. [Google Scholar]
- Hu, Z.; Lee, R.K.W.; Aggarwal, C.C.; Zhang, A. Text style transfer: A review and experimental evaluation. ACM Sigkdd Explor. Newsl. 2022, 24, 14–45. [Google Scholar] [CrossRef]
- Rao, S.; Tetreault, J. Dear Sir or Madam, May I Introduce the GYAFC Dataset: Corpus, Benchmarks and Metrics for Formality Style Transfer. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 129–140. [Google Scholar]
- Lyu, Y.; Liang, P.P.; Pham, H.; Hovy, E.; Poczós, B.; Salakhutdinov, R.; Morency, L.P. StylePTB: A Compositional Benchmark for Fine-grained Controllable Text Style Transfer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2116–2138. [Google Scholar]
- Briakou, E.; Lu, D.; Zhang, K.; Tetreault, J. Olá, bonjour, salve! XFORMAL: A benchmark for multilingual formality style transfer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 3199–3216. [Google Scholar]
- Yamshchikov, I.P.; Shibaev, V.; Nagaev, A.; Jost, J.; Tikhonov, A. Decomposing Textual Information For Style Transfer. In Proceedings of the 3rd Workshop on Neural Generation and Translation, Hong Kong, China, 4 November 2019; pp. 128–137. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. GBLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Xu, W. From Shakespeare to Twitter: What are Language Styles all about? In Proceedings of the Workshop on Stylistic Variation, Copenhagen, Denmark, 8 September 2017; pp. 1–9. [Google Scholar]
- Hughes, J.M.; Foti, N.J.; Krakauer, D.C.; Rockmore, D.N. Quantitative patterns of stylistic influence in the evolution of literature. Proc. Natl. Acad. Sci. USA 2012, 109, 7682–7686. [Google Scholar] [CrossRef] [PubMed]
- Potash, P.; Romanov, A.; Rumshisky, A. GhostWriter: Using an LSTM for Automatic Rap Lyric Generation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Lisbon, Portugal, 17–21 September 2015; pp. 1919–1924. [Google Scholar]
- Yamshchikov, I.P.; Tikhonov, A. Learning Literary Style End-to-end with Artificial Neural Networks. Adv. Sci. Technol. Eng. Syst. J. 2019, 4, 115–125. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Controlling politeness in neural machine translation via side constraints. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 35–40. [Google Scholar]
- Xu, W.; Ritter, A.; Dolan, W.B.; Grishman, R.; Cherry, C. Paraphrasing for style. In Proceedings of the COLING, Mumbai, India, 8–15 December 2012; pp. 2899–2914. [Google Scholar]
- Jhamtani, H.; Gangal, V.; Hovy, E.; Nyberg, E. Shakespearizing Modern Language Using Copy-Enriched Sequence-to-Sequence Models. In Proceedings of the Workshop on Stylistic Variation, Copenhagen, Denmark, 8 September 2017; pp. 10–19. [Google Scholar]
- Prabhumoye, S.; Tsvetkov, Y.; Black, A.W.; Salakhutdinov, R. Style Transfer Through Back-Translation. arXiv 2018, arXiv:1804.09000. [Google Scholar]
- Ficler, J.; Goldberg, Y. Controlling linguistic style aspects in neural language generation. In Proceedings of the Workshop on Stylistic Variation, Copenhagen, Denmark, 8 September 2017; pp. 94–104. [Google Scholar]
- Lin, K.; Liu, M.Y.; Sun, M.T.; Kautz, J. Learning to Generate Multiple Style Transfer Outputs for an Input Sentence. In Proceedings of the Fourth Workshop on Neural Generation and Translation, Online, 10 July 2020; pp. 10–23. [Google Scholar]
- Cheng, P.; Min, M.R.; Shen, D.; Malon, C.; Zhang, Y.; Li, Y.; Carin, L. Improving Disentangled Text Representation Learning with Information-Theoretic Guidance. arXiv 2020, arXiv:2006.00693. [Google Scholar]
- Qian, K.; Zhang, Y.; Chang, S.; Hasegawa-Johnson, M.; Cox, D. Unsupervised speech decomposition via triple information bottleneck. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 13–18 July 2020; pp. 7836–7846. [Google Scholar]
- Tikhonov, A.; Yamshchikov, I.P. What is wrong with style transfer for texts? arXiv 2018, arXiv:1808.04365. [Google Scholar]
- Kabbara, J.; Cheung, J.C.K. Stylistic transfer in natural language generation systems using recurrent neural networks. In Proceedings of the Workshop on Uphill Battles in Language Processing: Scaling Early Achievements to Robust Methods, Austin, TX, USA, 5 November 2016; pp. 43–47. [Google Scholar]
- Li, J.; Jia, R.; He, H.; Liang, P. Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 865–1874. [Google Scholar]
- Xu, J.; Sun, X.; Zeng, Q.; Ren, X.; Zhang, X.; Wang, H.; Li, W. Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach. arXiv 2018, arXiv:1805.05181. [Google Scholar]
- Yamshchikov, I.P.; Shibaev, V.; Khlebnikov, N.; Tikhonov, A. Style-transfer and Paraphrase: Looking for a Sensible Semantic Similarity Metric. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 35, pp. 14213–14220. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Williams, P.; Beer, R. Nonnegative Decomposition of Multivariate Information. arXiv 2010, arXiv:1004.2515v1. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- McGill, W. Multivariate information transmission. Trans. Ire Prof. Group Inf. Theory 1954, 4, 93–111. [Google Scholar] [CrossRef]
- Bell, A.J. The co-information lattice. In Proceedings of the Fifth International Workshop on Independent Component Analysis and Blind Signal Separation: ICA, Granada, Spain, 22–24 September 2003; Volume 2003. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Ross, B.C. Mutual information between discrete and continuous data sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, S.; Lample, G.; Smith, E.M.; Denoyer, L.; Ranzato, M.A.; Boureau, Y.L. Multiple-Attribute Text Style Transfer. arXiv 2018, arXiv:1811.00552. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shibaev, V.; Olbrich, E.; Jost, J.; Yamshchikov, I.P. Quick Estimate of Information Decomposition for Text Style Transfer. Entropy 2023, 25, 322. https://doi.org/10.3390/e25020322
Shibaev V, Olbrich E, Jost J, Yamshchikov IP. Quick Estimate of Information Decomposition for Text Style Transfer. Entropy. 2023; 25(2):322. https://doi.org/10.3390/e25020322
Chicago/Turabian StyleShibaev, Viacheslav, Eckehard Olbrich, Jürgen Jost, and Ivan P. Yamshchikov. 2023. "Quick Estimate of Information Decomposition for Text Style Transfer" Entropy 25, no. 2: 322. https://doi.org/10.3390/e25020322
APA StyleShibaev, V., Olbrich, E., Jost, J., & Yamshchikov, I. P. (2023). Quick Estimate of Information Decomposition for Text Style Transfer. Entropy, 25(2), 322. https://doi.org/10.3390/e25020322