
Binary Bamboo Forest Growth Optimization Algorithm for Feature Selection Problem






Abstract
:1. Introduction
- The first binary bamboo forest growth optimization algorithm (BBFGO) is proposed.
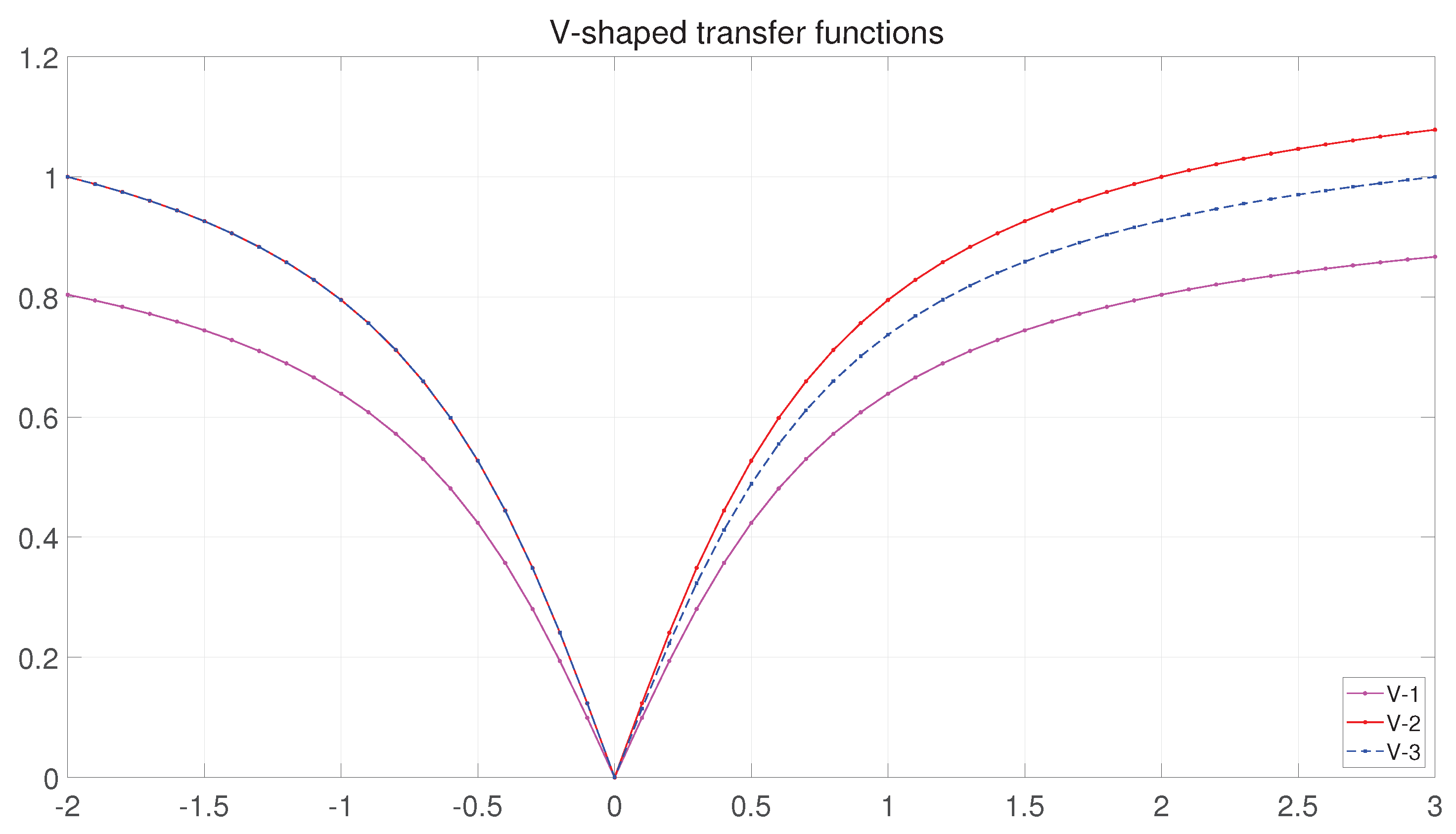
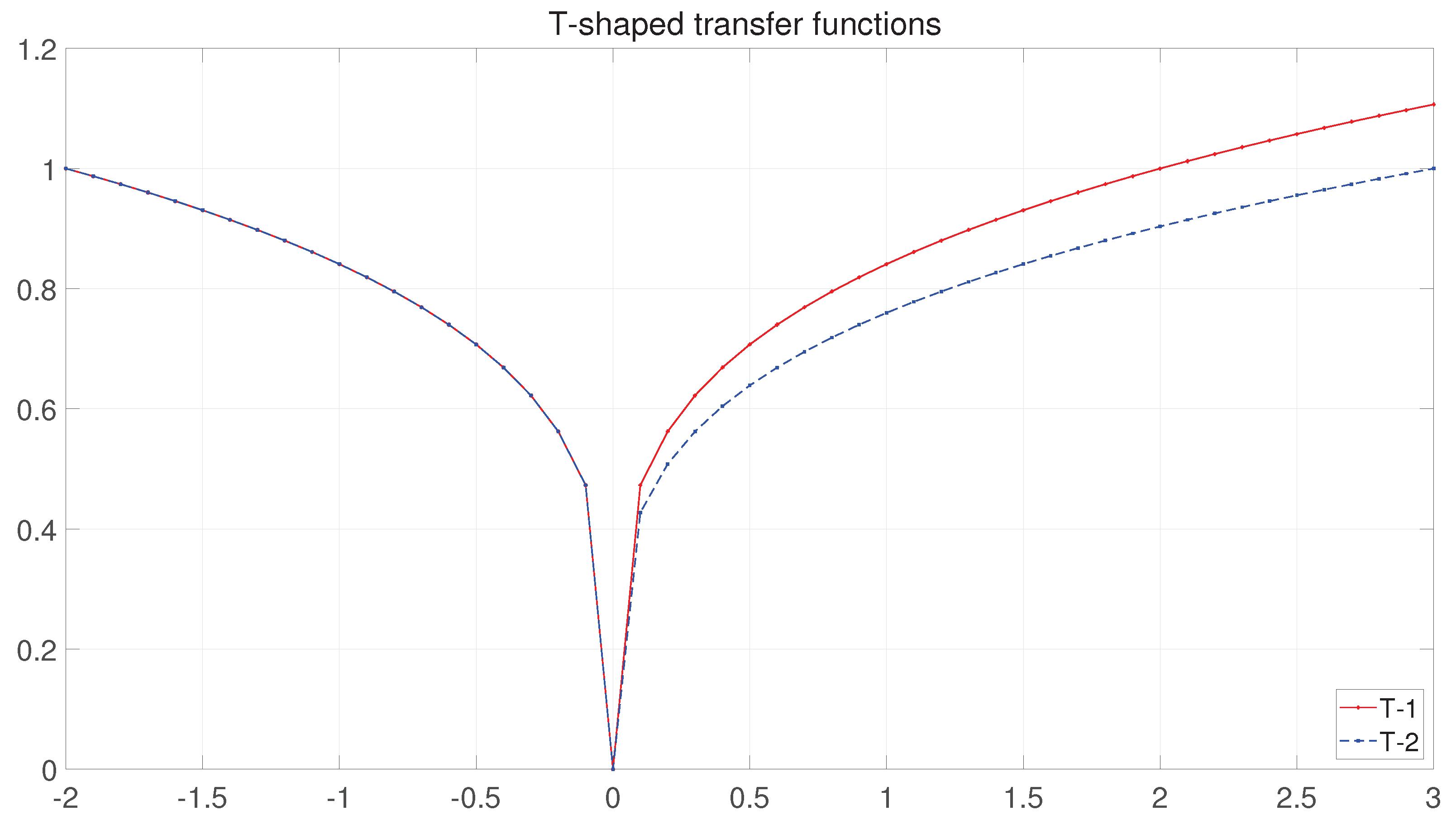
- Based on a mathematical analysis approach, the first analysis is carried out for the search space of binary BFGO. Based on the results of this analysis, the V−transfer function is stretched in two ways, two new curvature V−transfer functions for binary BFGO are proposed and the new curvature V−transfer function is successfully verified to have better performance in the test function.
- The long-mutation strategy is introduced to the original BBFGO to avoid solution stagnation, and a new mutation approach is proposed.
- BBFGO and BBFGO with the new mutation method are compared in test functions with advanced algorithms, and it is confirmed that the long-mutation strategy of the new mutation method improves the performance of BBFGO. Compared with the advanced algorithm, the new mutation strategy leads BBFGO to complete the reversal.
- BBFGO is applied to feature selection and compared with cutting-edge algorithms, which performs well in low and high dimensional classification accuracy. In particular, it is more competitive on high-dimensional data sets.
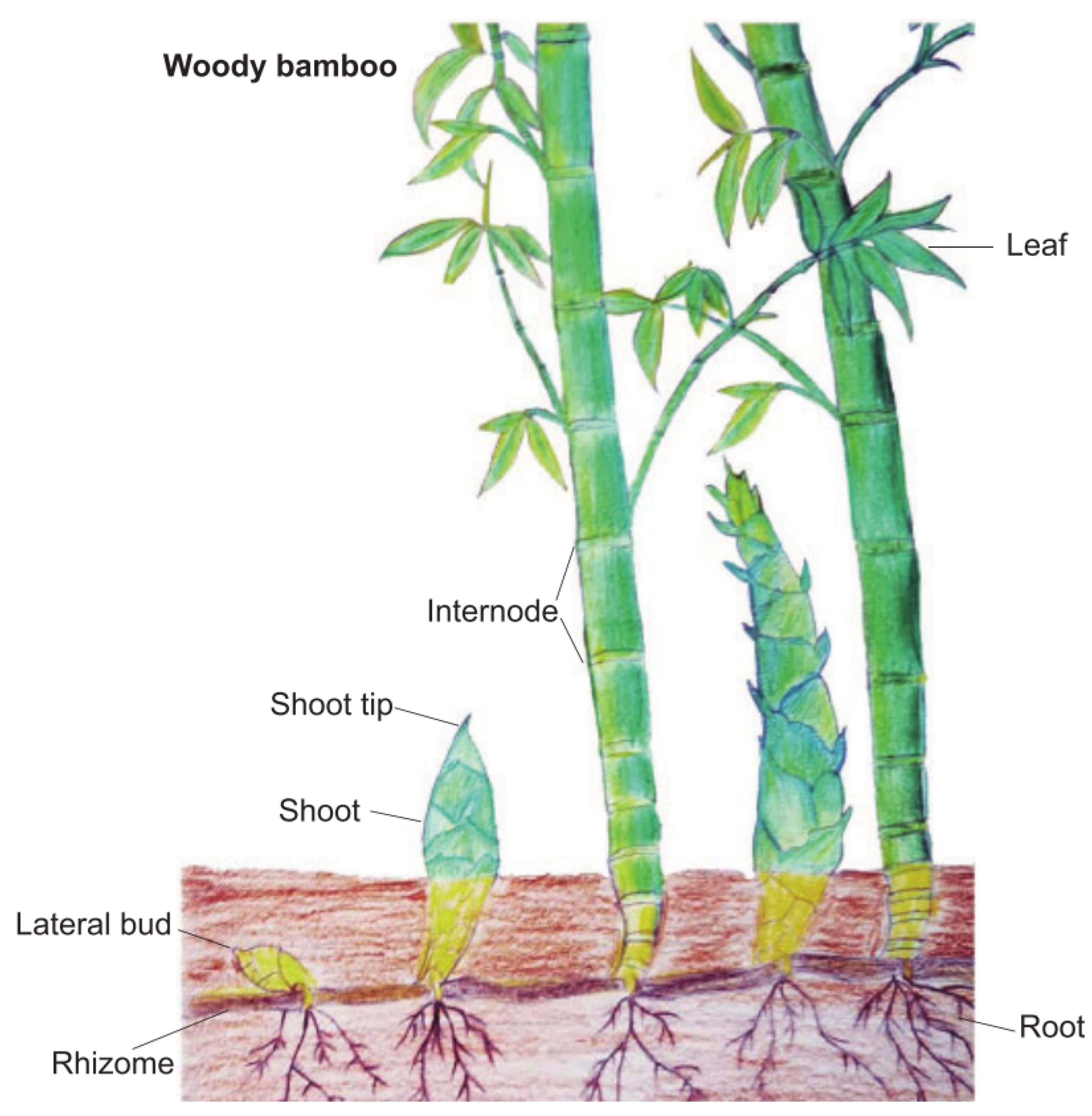
2. Bamboo Forest Growth Optimization
| Algorithm 1 Pseudocode of BFGO |
|
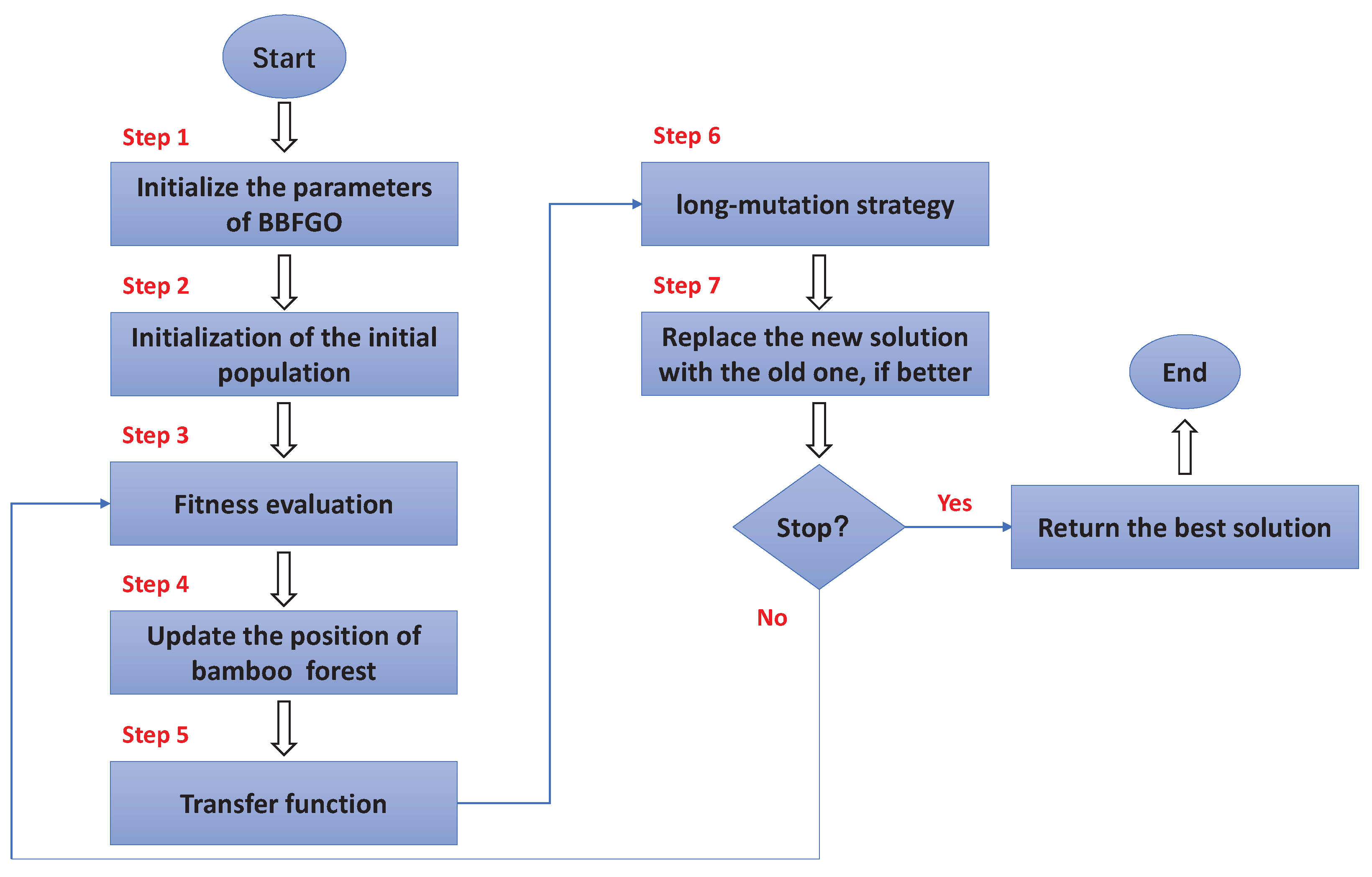
3. Binary Bamboo Forest Growth Optimization Algorithms
3.1. Binary Bamboo Forest Growth Optimization (BBFGO)
3.1.1. Mathematical Analysis
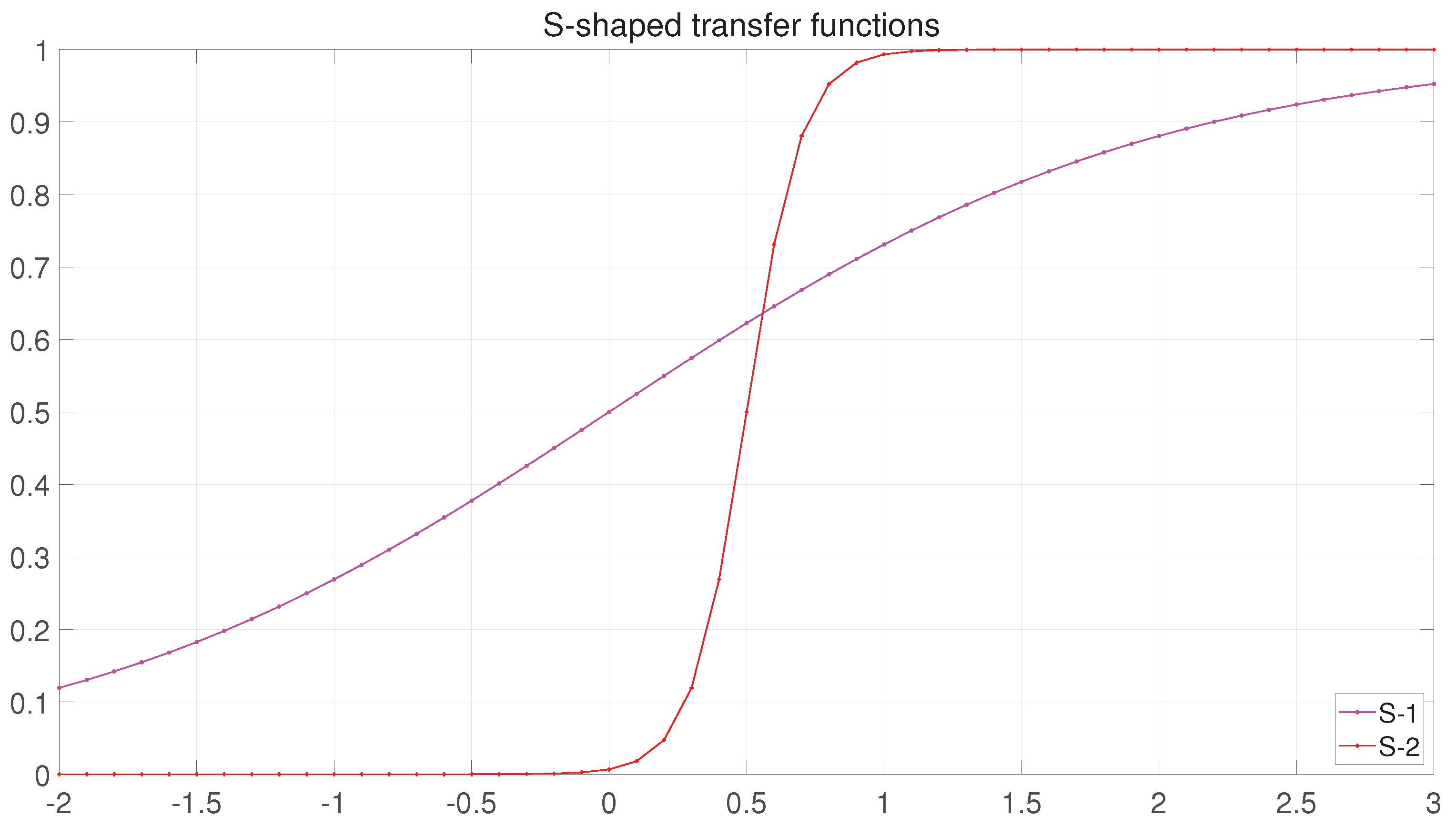
3.1.2. BBFGO with Transfer Functions
| Algorithm 2 Pseudocode of BBFGO |
|
3.2. Advanced Binary Bamboo Forest Growth Optimization (ABBFGO)
| Algorithm 3 Pseudocode of ABBFGO |
|
4. Experimental Results and Analysis
4.1. Experimental Analysis of the Transfer Functions and ABBFGO
4.2. Experimental Results for Cutting-Edge Algorithms
5. Apply to Feature Selection
5.1. Datasets Description
5.2. Simulation Results
5.2.1. KNN and K-Fold Validation
5.2.2. Evaluation Criteria
5.2.3. Result Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, J.; Alelyani, S.; Liu, H. Feature Selection for Classification: A Review. Data Classification: Algorithms and Applications. 2014, p. 37. Available online: https://www.cvs.edu.in/upload/feature_selection_for_classification.pdf (accessed on 8 September 2022).
- Abualigah, L.; Diabat, A. Chaotic binary group search optimizer for feature selection. Expert Syst. Appl. 2022, 192, 116368. [Google Scholar]
- Yang, L.; Xu, Z. Feature extraction by PCA and diagnosis of breast tumors using SVM with DE-based parameter tuning. Int. J. Mach. Learn. Cybern. 2019, 10, 591–601. [Google Scholar] [CrossRef]
- Zeng, A.; Li, T.; Liu, D.; Zhang, J.; Chen, H. A fuzzy rough set approach for incremental feature selection on hybrid information systems. Fuzzy Sets Syst. 2015, 258, 39–60. [Google Scholar]
- Li, G.; Zhao, J.; Murray, V.; Song, C.; Zhang, L. Gap analysis on open data interconnectivity for disaster risk research. Geo-Spat. Inf. Sci. 2019, 22, 45–58. [Google Scholar]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A combination of objective functions and hybrid krill herd algorithm for text document clustering analysis. Eng. Appl. Artif. Intell. 2018, 73, 111–125. [Google Scholar]
- Arafat, H.; Elawady, R.M.; Barakat, S.; Elrashidy, N.M. Different feature selection for sentiment classification. Int. J. Inf. Sci. Intell. Syst. 2014, 1, 137–150. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2017, 50, 1–45. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Liu, Y.; Tang, F.; Zeng, Z. Feature selection based on dependency margin. IEEE Trans. Cybern. 2014, 45, 1209–1221. [Google Scholar] [CrossRef]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Sharma, M.; Kaur, P. A comprehensive analysis of nature-inspired meta-heuristic techniques for feature selection problem. Arch. Comput. Methods Eng. 2021, 28, 1103–1127. [Google Scholar]
- SS, V.C.; HS, A. Nature inspired meta heuristic algorithms for optimization problems. Computing 2022, 104, 251–269. [Google Scholar] [CrossRef]
- Beheshti, Z.; Shamsuddin, S.M.H. A review of population-based meta-heuristic algorithms. Int. J. Adv. Soft Comput. Appl 2013, 5, 1–35. [Google Scholar]
- Osman, I.H.; Kelly, J.P. Meta-heuristics: An overview. In Meta-Heuristics; Springer: Berlin/Heidelberg, Germany, 1996; pp. 1–21. [Google Scholar]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Sayed, S.; Nassef, M.; Badr, A.; Farag, I. A nested genetic algorithm for feature selection in high-dimensional cancer microarray datasets. Expert Syst. Appl. 2019, 121, 233–243. [Google Scholar] [CrossRef]
- Mellit, A.; Kalogirou, S.A.; Drif, M. Application of neural networks and genetic algorithms for sizing of photovoltaic systems. Renew. Energy 2010, 35, 2881–2893. [Google Scholar] [CrossRef]
- Ilonen, J.; Kamarainen, J.K.; Lampinen, J. Differential evolution training algorithm for feed-forward neural networks. Neural Process. Lett. 2003, 17, 93–105. [Google Scholar] [CrossRef]
- Hancer, E.; Xue, B.; Zhang, M. Differential evolution for filter feature selection based on information theory and feature ranking. Knowl.-Based Syst. 2018, 140, 103–119. [Google Scholar]
- Zhang, Y.; Gong, D.W.; Gao, X.Z.; Tian, T.; Sun, X.Y. Binary differential evolution with self-learning for multi-objective feature selection. Inf. Sci. 2020, 507, 67–85. [Google Scholar] [CrossRef]
- Pan, J.S.; Meng, Z.; Xu, H.; Li, X. QUasi-Affine TRansformation Evolution (QUATRE) algorithm: A new simple and accurate structure for global optimization. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Morioka, Japan, 2–4 August 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 657–667. [Google Scholar]
- Meng, Z.; Pan, J.S.; Xu, H. QUasi-Affine TRansformation Evolutionary (QUATRE) algorithm: A cooperative swarm based algorithm for global optimization. Knowl.-Based Syst. 2016, 109, 104–121. [Google Scholar]
- Liu, N.; Pan, J.S.; Nguyen, T.T. A bi-population QUasi-Affine TRansformation Evolution algorithm for global optimization and its application to dynamic deployment in wireless sensor networks. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 175. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Chu, S.C.; Tsai, P.W.; Pan, J.S. Cat swarm optimization. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Guilin, China, 7–11 August 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 854–858. [Google Scholar]
- Pan, J.S.; Tsai, P.W.; Liao, Y.B. Fish migration optimization based on the fishy biology. In Proceedings of the 2010 IEEE Fourth International Conference on Genetic and Evolutionary Computing, Shenzhen, China, 13–15 December 2010; pp. 783–786. [Google Scholar]
- Xing, J.; Zhao, H.; Chen, H.; Deng, R.; Xiao, L. Boosting Whale Optimizer with Quasi-Oppositional Learning and Gaussian Barebone for Feature Selection and COVID-19 Image Segmentation. J. Bionic Eng. 2022, 1–22. [Google Scholar] [CrossRef]
- Jiang, F.; Wang, L.; Bai, L. An improved whale algorithm and its application in truss optimization. J. Bionic Eng. 2021, 18, 721–732. [Google Scholar] [CrossRef]
- Fang, L.; Liang, X. A Novel Method Based on Nonlinear Binary Grasshopper Whale Optimization Algorithm for Feature Selection. J. Bionic Eng. 2022, 20, 237–252. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput.-Aided Des. 2011, 43, 303–315. [Google Scholar]
- Liu, Z.Z.; Chu, D.H.; Song, C.; Xue, X.; Lu, B.Y. Social learning optimization (SLO) algorithm paradigm and its application in QoS-aware cloud service composition. Inf. Sci. 2016, 326, 315–333. [Google Scholar]
- Ramezani, F.; Lotfi, S. Social-based algorithm (SBA). Appl. Soft Comput. 2013, 13, 2837–2856. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar]
- Webster, B.; Bernhard, P.J. A Local Search Optimization Algorithm Based on Natural Principles of Gravitation. Technical Report. 2003. Available online: http://hdl.handle.net/11141/117 (accessed on 8 September 2022).
- Hu, P.; Pan, J.S.; Chu, S.C. Improved binary grey wolf optimizer and its application for feature selection. Knowl.-Based Syst. 2020, 195, 105746. [Google Scholar]
- Pan, J.S.; Tian, A.Q.; Chu, S.C.; Li, J.B. Improved binary pigeon-inspired optimization and its application for feature selection. Appl. Intell. 2021, 51, 8661–8679. [Google Scholar]
- Liu, Y.; Wang, G.; Chen, H.; Dong, H.; Zhu, X.; Wang, S. An improved particle swarm optimization for feature selection. J. Bionic Eng. 2011, 8, 191–200. [Google Scholar] [CrossRef]
- Feng, Q.; Chu, S.C.; Pan, J.S.; Wu, J.; Pan, T.S. Energy-Efficient Clustering Mechanism of Routing Protocol for Heterogeneous Wireless Sensor Network Based on Bamboo Forest Growth Optimizer. Entropy 2022, 24, 980. [Google Scholar]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar]
- He, Y.; Zhang, F.; Mirjalili, S.; Zhang, T. Novel binary differential evolution algorithm based on Taper-shaped transfer functions for binary optimization problems. Swarm Evol. Comput. 2022, 69, 101022. [Google Scholar]
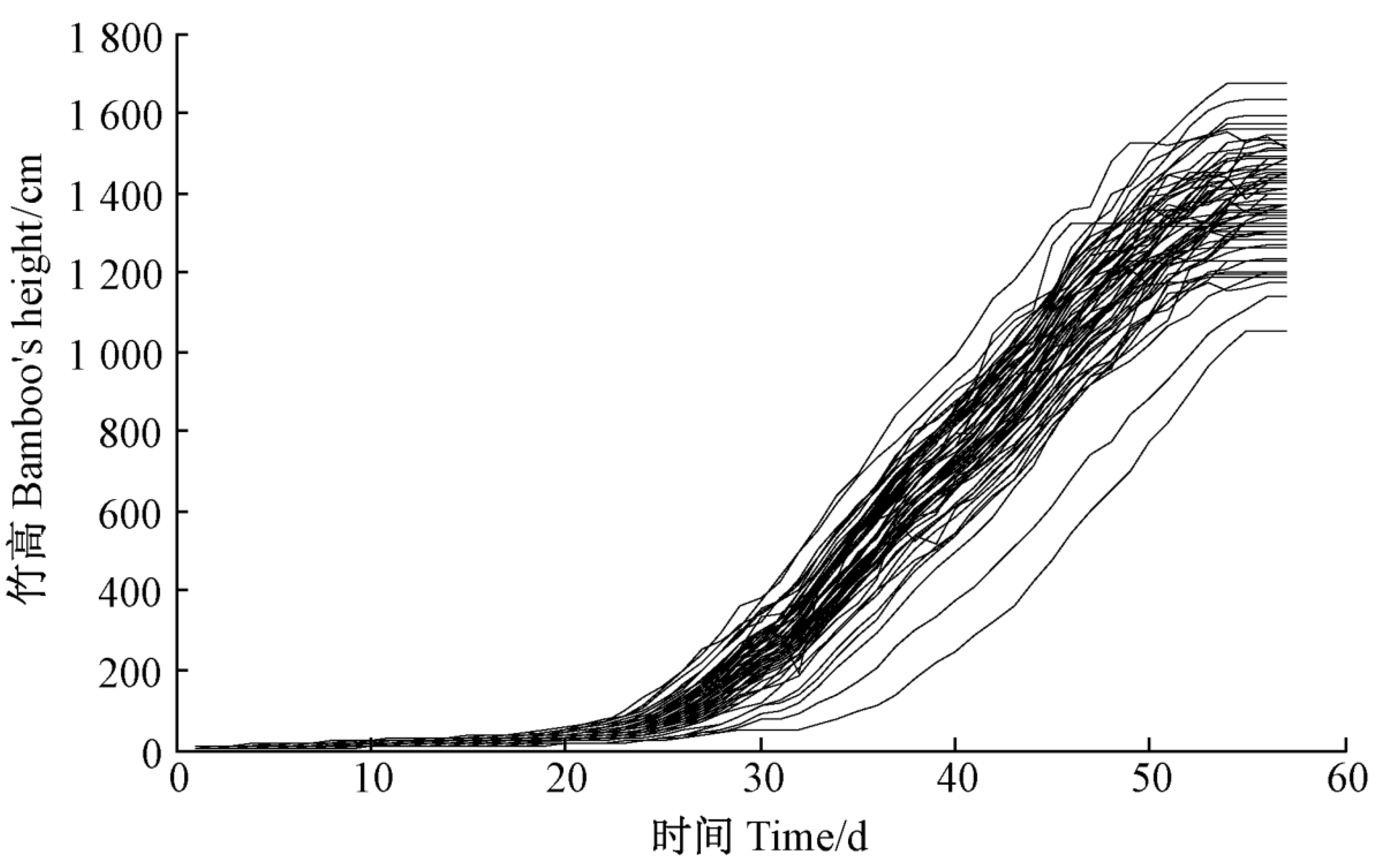
- Jin, G.; Ma, P.F.; Wu, X.; Gu, L.; Long, M.; Zhang, C.; Li, D.Z. New Genes Interacted with Recent Whole-Genome Duplicates in the Fast Stem Growth of Bamboos. Mol. Biol. Evol. 2021, 38, 5752–5768. [Google Scholar] [CrossRef]
- Shi, Y.; Liu, E.; Zhou, G.; Shen, Z.; Yu, S. Bamboo shoot growth model based on the stochastic process and its application. Sci. Silvae Sin. 2013, 49, 89–93. [Google Scholar]
- Beheshti, Z. A time-varying mirrored S-shaped transfer function for binary particle swarm optimization. Inf. Sci. 2020, 512, 1503–1542. [Google Scholar] [CrossRef]
- Liu, F.F.; Chu, S.C.; Wang, X.; Pan, J.S. A Novel Binary QUasi-Affine TRansformation Evolution (QUATRE) Algorithm and Its Application for Feature Selection. In Proceedings of the Advances in Intelligent Systems and Computing, Hangzhou, China, 29–31 May 2021; Springer Nature: Singapore, 2022; pp. 305–315. [Google Scholar]
- Asuncion, A.; Newman, D. UCI Machine Learning Repository. 2007. Available online: https://www.semanticscholar.org/paper/%5B7%5D-A.-Asuncion-and-D.-J.-Newman.-UCI-Machine-Aggarwal-Han/ea2be4c9913e781e7930cc2d4a0b2021a6a91a44 (accessed on 8 September 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num | Name | Parameter Space | Dim | Opt |
|---|---|---|---|---|
| Sphere | [−100, 100] | 30 | 0 | |
| Schwefel’s function 2.21 | [−10, 10] | 30 | 0 | |
| Schwefel’s function 1.2 | [−100, 100] | 30 | 0 | |
| Schwefel’s function 2.221 | [−100, 100] | 30 | 0 | |
| Rosenbrock | [−30, 30] | 30 | 0 | |
| Step | [−100, 100] | 30 | 0 | |
| Dejong’s noisy | [−1.28, 1.28] | 30 | 0 | |
| Schwefel | [−500, 500] | 30 | −12,569 | |
| Rastringin | [−5.12, 5.12] | 30 | 0 | |
| Ackley | [−32, 32] | 30 | 0 | |
| Griewank | [−600, 600] | 30 | 0 | |
| Generalized penalized 1 | [−50, 50] | 30 | 0 | |
| Generalized penalized 2 | [−50, 50] | 30 | 0 | |
| Fifth of Dejong | [−65, 65] | 2 | 1 | |
| Kowalik | [−5, 5] | 4 | 0.0003 | |
| Six-hump camel back | [−5, 5] | 2 | −1.0316 | |
| Branins | [−5, 5] | 2 | 0.398 | |
| Goldstein–Price | [−2, 2] | 2 | 3 | |
| Hartman 1 | [1, 3] | 3 | −3.86 | |
| Hartman 2 | [0, 1] | 6 | −3.32 | |
| Shekel 1 | [0, 10] | 4 | −10.1532 | |
| Shekel 2 | [0, 10] | 4 | −10.4028 | |
| Shekel 3 | [0, 10] | 4 | −10.5363 |
| Algorithm | Transfer Function |
|---|---|
| BBFGO | Transfer Function from Equation (11) |
| BBFGO-S | Transfer Function from Equation (12) |
| BBFGO-V1 | Transfer Function from Equation (14) |
| BBFGO-V2 | Transfer Function from Equation (15) |
| BBFGO-V3 | Transfer Function from Equation (16) |
| BBFGO-T1 | Transfer Function from Equation (18) |
| BBFGO-T2 | Transfer Function from Equation (19) |
| BGWO | Transfer Function from [37] |
| BPSO-S | Transfer Function from [45] |
| BQUATRE | Transfer Function from [46] |
| Algorithm | Parameter | Values |
|---|---|---|
| BFGO(BBFGO) | Number of individuals | 30 |
| Maximum number of iterations | 500 | |
| Number of bamboo shoots | 6 | |
| Number of bamboo whips | 5 | |
| GWO(BGWO) | Number of wolves | 30 |
| Maximum number of iterations | 500 | |
| The a parameter | 2 * it/MAX_IT | |
| PSO(BPSO-S) | Number of particles | 30 |
| Maximum number of iterations | 500 | |
| Inertia weight | 0.9 | |
| Inertia weight | 0.2 | |
| 2 | ||
| 2 | ||
| , | [−6, 6] | |
| QUATRE(BQUATRE) | Number of individuals | 30 |
| Maximum number of iterations | 500 | |
| Matrix control factor | 0.7 |
| Function | BBFGO-S | BBFGO-V1 | BBFGO-V2 | BBFGO-V3 | BBFGO-T1 | BBFGO-T2 | BBFGO | ABBFGO | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AVG | STD | AVG | STD | AVG | STD | AVG | STD | AVG | STD | AVG | STD | AVG | STD | AVG | STD | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.4667 | 0.9732 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.9667 | 0.8503 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 207.1333 | 56.8905 | 0.1 | 0.5477 | |
| 0 | 0 | 0 | 0 | 0.1 | 0.3051 | 0.0333 | 0.1826 | 1 | 0 | 0.9333 | 0.2537 | 1 | 0 | 1 | 0 | |
| 29 | 0 | 29 | 0 | 19.3333 | 13.9044 | 28.0333 | 5.2947 | 1.9333 | 7.3575 | 14.9333 | 31.1392 | 124.4 | 82.0431 | 0 | 0 | |
| 7.5 | 0 | 7.5 | 0 | 7.5 | 0 | 7.5 | 0 | 7.5 | 0 | 7.5 | 0 | 17.6333 | 1.5698 | 7.5 | 0 | |
| 3.68 × | 3.75 × | 3.39 × | 3.10 × | 3.23 × | 2.89 × | 3.42 × | 3.13 × | 3.45 × | 3.63 × | 3.56 × | 4.13 × | 55.9377 | 9.5740 | 4.15 × | 3.60 × | |
| −25.2441 | 1.08 × | −21.0648 | 0.84099 | −25.2441 | 1.08 × | −24.6551 | 0.54802 | −25.2441 | 1.08 × | −25.1319 | 2.91 × | −24.6271 | 0.4908 | −25.2441 | 1.08 × | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.8667 | 0.8193 | 0 | 0 | |
| 8.88 × | 0 | 8.88 × | 0 | 8.88 × | 0 | 8.88 × | 0 | 8.88 × | 0 | 8.88 × | 0 | 1.5665 | 0.1383 | 0.0239 | 0.1309 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.1533 | 0.0262 | 0.0017 | 0.0066 | |
| 1.6690 | 1.13 × | 1.6690 | 1.13 × | 1.6690 | 1.13 × | 1.6690 | 1.13 × | 1.6690 | 1.13 × | 1.6690 | 1.13 × | 2.4223 | 0.1366 | 1.6690 | 1.13 × | |
| 1.35 × | 5.57 × | 0.4867 | 0.1548 | 1.35 × | 5.57 × | 0.0567 | 0.0568 | 1.35 × | 5.57 × | 0.0400 | 4.98 × | 0.0667 | 0.0547 | 1.35 × | 5.57 × | |
| 12.6705 | 3.61 × | 12.6705 | 3.61 × | 12.6705 | 3.61 × | 12.6705 | 3.61 × | 12.6705 | 3.61 × | 12.6705 | 3.61 × | 12.6705 | 3.61 × | 12.6705 | 3.61 × | |
| 0.1484 | 0 | 0.1484 | 0 | 0.1484 | 0 | 0.1484 | 0 | 0.1484 | 0 | 0.1484 | 0 | 0.1484 | 0 | 0.1484 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 27.7029 | 1.81 × | 27.7029 | 1.81 × | 27.7029 | 1.81 × | 27.7029 | 1.81 × | 27.7029 | 1.81 × | 27.7029 | 1.81 × | 27.7029 | 1.81 × | 27.7029 | 1.81 × | |
| 600 | 0 | 600 | 0 | 600 | 0 | 600 | 0 | 600 | 0 | 600 | 0 | 600 | 0 | 600 | 0 | |
| −0.3348 | 1.69 × | −0.3348 | 1.69 × | −0.3348 | 1.69 × | −0.3348 | 1.69 × | −0.3348 | 1.69 × | −0.3348 | 1.69 × | −0.3348 | 1.69 × | −0.3348 | 1.69 × | |
| −0.1657 | 2.82 × | −0.1657 | 2.82 × | −0.1657 | 2.82 × | −0.1657 | 2.82 × | −0.1657 | 2.82 × | −0.1657 | 2.82 × | −0.1657 | 2.82 × | −0.1657 | 2.82 × | |
| −5.0552 | 4.52 × | −5.0552 | 4.52 × | −5.0552 | 4.52 × | −5.0552 | 4.52 × | −5.0552 | 4.52 × | −5.0552 | 4.52 × | −5.0552 | 4.52 × | −5.0552 | 4.52 × | |
| −5.0877 | 0 | −5.0877 | 0 | −5.0877 | 0 | −5.0877 | 0 | −5.0877 | 0 | −5.0877 | 0 | −5.0877 | 0 | −5.0877 | 0 | |
| −5.1285 | 2.71 × | −5.1285 | 2.71 × | −5.1285 | 2.71 × | −5.1285 | 2.71 × | −5.1285 | 2.71 × | −4.9891 | 7.63 × | −5.1285 | 2.71 × | −5.1285 | 2.71 × | |
| Function | BQUATRE | BGWO-a | BPSO-TVMS | |||
|---|---|---|---|---|---|---|
| AVG | STD | AVG | STD | AVG | STD | |
| 0 | 0 | 2.8333 | 1.2058 | 1.1667 | 0.5921 | |
| 0.0333 | 0.1826 | 3.1667 | 1.5555 | 1.4333 | 0.6789 | |
| 0.4667 | 1.1059 | 83.7667 | 67.5174 | 17.1333 | 13.9599 | |
| 1 | 0 | 1 | 0 | 1 | 0 | |
| 0 | 0 | 0 | 0 | 93.5667 | 90.9607 | |
| 7.5 | 0 | 13.7667 | 2.5587 | 10.4333 | 1.4606 | |
| 2.6001 | 3.6540 | 39.0334 | 21.0557 | 9.1307 | 4.5008 | |
| −25.2441 | 1.08 × | −25.2441 | 1.08 × | −24.0100 | 0.4808 | |
| 0 | 0 | 3.5 | 1.3326 | 1.4333 | 0.5040 | |
| 8.88 × | 0 | 1.1964 | 0.3619 | 0.8040 | 0.1349 | |
| 0.0144 | 0.0187 | 0.1390 | 0.0572 | 0.0293 | 0.0154 | |
| 1.6725 | 1.33 × | 2.1409 | 0.2106 | 1.8653 | 0.0981 | |
| 1.35 × | 5.57 × | 1.35 × | 5.57 × | 0.1500 | 0.0509 | |
| 12.6705 | 3.61 × | 12.6705 | 3.61 × | 12.6705 | 3.61 × | |
| 0.1484 | 0 | 0.1484 | 0 | 0.1484 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | |
| 27.7029 | 1.81 × | 27.7029 | 1.81 × | 27.7029 | 1.81 × | |
| 600 | 0 | 600 | 0 | 600 | 0 | |
| −0.3348 | 1.69 × | −0.3337 | 0.0063 | −0.3348 | 1.69 × | |
| −0.1657 | 2.82 × | −0.1397 | 0.0479 | −0.1657 | 2.82 × | |
| −5.0552 | 4.52 × | −5.0552 | 4.52 × | −5.0552 | 4.52 × | |
| −5.0877 | 0 | −5.0877 | 0 | −5.0877 | 0 | |
| −5.1285 | 2.71 × | −5.1285 | 2.71 × | −5.1285 | 2.71 × | |
| Dataset | No. of Features | No. of Instances | No. of Classes |
|---|---|---|---|
| Turkish Music Emotion | 50 | 400 | 4 |
| Musk (Version 1) | 166 | 476 | 2 |
| Cancer | 9 | 683 | 2 |
| Dermatology | 34 | 366 | 6 |
| Dnatest | 180 | 1186 | 3 |
| German | 24 | 1000 | 4 |
| Glass | 9 | 214 | 6 |
| Heartstatlog | 13 | 270 | 2 |
| Ionosphere | 34 | 351 | 2 |
| LSVT Voice Rehabilitation | 310 | 126 | 2 |
| Sonar | 60 | 208 | 2 |
| WDBC | 30 | 569 | 2 |
| Dataset | ABBFGO | ABBFGO-S | ABBFGO-V2 | ABBFGO-V3 | ABBFGO-T1 | ABBFGO-T2 | BPSO-TVMS | BQUATRE | BGWO-a | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Num | Acc | Num | Acc | Num | Acc | Num | Acc | Num | Acc | Num | Acc | Num | Acc | Num | Acc | Num | |
| Turkish Music Emotion | 0.7617 | 25.67 | 0.7748 | 11.80 | 0.7902 | 17.53 | 0.7879 | 16.73 | 0.7783 | 20.40 | 0.7881 | 15.87 | 0.7098 | 22.33 | 0.7005 | 38.27 | 0.7386 | 27.40 |
| Cancer | 0.9787 | 5.67 | 0.9775 | 4.80 | 0.9766 | 4.27 | 0.9766 | 4.33 | 0.9768 | 4.47 | 0.9770 | 4.60 | 0.9766 | 5.40 | 0.9720 | 6.07 | 0.9770 | 5.80 |
| Musk (Version 1) | 0.9149 | 85.93 | 0.9318 | 46.27 | 0.9424 | 47.20 | 0.9331 | 43.53 | 0.9286 | 58.00 | 0.9420 | 49.33 | 0.8786 | 81.73 | 0.8627 | 136.67 | 0.9073 | 86.87 |
| Dermatology | 0.9904 | 19.13 | 0.9847 | 15.60 | 0.9904 | 18.27 | 0.9909 | 18.00 | 0.9912 | 20.13 | 0.9910 | 19.53 | 0.9802 | 19.40 | 0.9789 | 25.87 | 0.9854 | 21.53 |
| Dnatest | 0.8548 | 91.07 | 0.9041 | 27.53 | 0.9092 | 16.80 | 0.9074 | 17.67 | 0.8924 | 39.33 | 0.9057 | 20.53 | 0.8191 | 85.40 | 0.8044 | 132.80 | 0.8564 | 90.47 |
| German | 0.5076 | 12.93 | 0.5038 | 6.80 | 0.5121 | 9.60 | 0.5070 | 7.33 | 0.5134 | 12.67 | 0.5107 | 10.13 | 0.4886 | 11.07 | 0.4752 | 16.53 | 0.4980 | 13.53 |
| Glass | 0.4559 | 3.60 | 0.4521 | 2.93 | 0.4610 | 3.73 | 0.4609 | 3.80 | 0.4616 | 4.07 | 0.4559 | 3.47 | 0.4478 | 3.80 | 0.3748 | 4.80 | 0.4413 | 4.73 |
| Heartstatlog | 0.8562 | 5.20 | 0.8569 | 3.87 | 0.8588 | 4.33 | 0.8580 | 5.13 | 0.8608 | 5.87 | 0.8562 | 4.80 | 0.8494 | 4.60 | 0.8292 | 7.80 | 0.8440 | 7.13 |
| Ionosphere | 0.9291 | 10.13 | 0.9387 | 5.20 | 0.9415 | 4.47 | 0.9377 | 4.33 | 0.9385 | 7.73 | 0.9409 | 4.27 | 0.9066 | 11.27 | 0.9023 | 15.80 | 0.9168 | 13.33 |
| LSVT Voice Rehabilitation | 0.9192 | 154.87 | 0.9421 | 50.67 | 0.9462 | 43.27 | 0.9482 | 29.40 | 0.9310 | 82.87 | 0.9405 | 45.87 | 0.8717 | 151.20 | 0.8234 | 231.47 | 0.9073 | 149.73 |
| Sonar | 0.9081 | 27.93 | 0.9125 | 14.67 | 0.9321 | 16.53 | 0.9257 | 15.27 | 0.9290 | 23.00 | 0.9238 | 17.40 | 0.8600 | 27.40 | 0.8431 | 42.07 | 0.9023 | 30.60 |
| WDBC | 0.9851 | 14.80 | 0.9843 | 7.60 | 0.9853 | 9.13 | 0.9846 | 8.13 | 0.9849 | 10.33 | 0.9848 | 8.53 | 0.9831 | 13.87 | 0.9739 | 21.73 | 0.9838 | 14.47 |
| Dataset | ABBFGO | ABBFGO-S | ABBFGO-V2 | ABBFGO-V3 | ABBFGO-T1 | ABBFGO-T2 | BPSO-TVMS | BQUATRE | BGWO-a | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fitness | Rank | Fitness | Rank | Fitness | Rank | Fitness | Rank | Fitness | Rank | Fitness | Rank | Fitness | Rank | Fitness | Rank | Fitness | Rank | |
| Turkish Music Emotion | 0.2412 | 6 | 0.2254 | 5 | 0.2112 | 1 | 0.2134 | 3 | 0.2236 | 4 | 0.2130 | 2 | 0.2919 | 9 | 0.2546 | 7 | 0.2644 | 8 |
| Cancer | 0.0274 | 1 | 0.0276 | 2 | 0.0279 | 4 | 0.0280 | 5 | 0.0280 | 5 | 0.0278 | 3 | 0.0292 | 7 | 0.0284 | 6 | 0.0292 | 7 |
| Musk (Version 1) | 0.0895 | 6 | 0.0703 | 4 | 0.0599 | 1 | 0.0688 | 3 | 0.0742 | 5 | 0.0604 | 2 | 0.1251 | 9 | 0.1151 | 8 | 0.0970 | 7 |
| Dermatology | 0.0151 | 4 | 0.0197 | 5 | 0.0148 | 3 | 0.0143 | 1 | 0.0147 | 2 | 0.0147 | 2 | 0.0253 | 7 | 0.0151 | 4 | 0.0208 | 6 |
| Dnatest | 0.1488 | 7 | 0.0965 | 4 | 0.0909 | 1 | 0.0927 | 2 | 0.1087 | 5 | 0.0945 | 3 | 0.1838 | 9 | 0.1769 | 8 | 0.1472 | 6 |
| German | 0.4928 | 5 | 0.4941 | 6 | 0.4870 | 1 | 0.4912 | 3 | 0.4870 | 1 | 0.4887 | 2 | 0.5109 | 8 | 0.4926 | 4 | 0.5026 | 7 |
| Glass | 0.5427 | 5 | 0.5457 | 7 | 0.5378 | 2 | 0.5379 | 3 | 0.5375 | 1 | 0.5425 | 4 | 0.5509 | 8 | 0.5433 | 6 | 0.5584 | 9 |
| Heartstatlog | 0.1463 | 6 | 0.1447 | 4 | 0.1431 | 2 | 0.1446 | 3 | 0.1423 | 1 | 0.1460 | 5 | 0.1527 | 8 | 0.1484 | 7 | 0.1600 | 9 |
| Ionosphere | 0.0732 | 6 | 0.0622 | 3 | 0.0593 | 1 | 0.0629 | 4 | 0.0632 | 5 | 0.0598 | 2 | 0.0958 | 9 | 0.0790 | 7 | 0.0863 | 8 |
| LSVT Voice Rehabilitation | 0.0850 | 6 | 0.0589 | 3 | 0.0547 | 2 | 0.0522 | 1 | 0.0710 | 5 | 0.0604 | 4 | 0.1319 | 9 | 0.1291 | 8 | 0.0966 | 7 |
| Sonar | 0.0957 | 6 | 0.0891 | 5 | 0.0700 | 1 | 0.0762 | 3 | 0.0741 | 2 | 0.0783 | 4 | 0.1431 | 9 | 0.1158 | 8 | 0.1019 | 7 |
| WDBC | 0.0197 | 6 | 0.0181 | 4 | 0.0176 | 1 | 0.0179 | 3 | 0.0184 | 5 | 0.0179 | 2 | 0.0214 | 9 | 0.0206 | 7 | 0.0209 | 8 |
| Total | 64 | 52 | 20 | 34 | 41 | 35 | 101 | 80 | 89 | |||||||||
| Dataset | Sum of Squares | Degree of Freedom | Mean Squares | p-Value |
|---|---|---|---|---|
| Turkish Music Emotion | 2845.41 | 140 | 20.3244 | 0.6354 |
| Cancer | 2876.36 | 140 | 20.5455 | 0.9315 |
| Musk (Version 1) | 2798.73 | 140 | 19.9909 | 0.4450 |
| Dermatology | 2751.55 | 140 | 19.6539 | 0.3303 |
| Dnatest | 2741.45 | 140 | 19.5818 | 0.2625 |
| German | 2797.09 | 140 | 19.9792 | 0.4440 |
| Glass | 2743.91 | 140 | 19.5994 | 0.2792 |
| Heartstatlog | 2939.45 | 140 | 20.9961 | 0.9499 |
| Ionosphere | 2772.23 | 140 | 19.8016 | 0.3581 |
| LSVT Voice Rehabilitation | 2852.50 | 140 | 20.3750 | 0.6619 |
| Sonar | 2851.45 | 140 | 20.3675 | 0.6540 |
| WDBC | 2812.00 | 140 | 20.0857 | 0.5548 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, J.-S.; Yue, L.; Chu, S.-C.; Hu, P.; Yan, B.; Yang, H. Binary Bamboo Forest Growth Optimization Algorithm for Feature Selection Problem. Entropy 2023, 25, 314. https://doi.org/10.3390/e25020314
Pan J-S, Yue L, Chu S-C, Hu P, Yan B, Yang H. Binary Bamboo Forest Growth Optimization Algorithm for Feature Selection Problem. Entropy. 2023; 25(2):314. https://doi.org/10.3390/e25020314
Chicago/Turabian StylePan, Jeng-Shyang, Longkang Yue, Shu-Chuan Chu, Pei Hu, Bin Yan, and Hongmei Yang. 2023. "Binary Bamboo Forest Growth Optimization Algorithm for Feature Selection Problem" Entropy 25, no. 2: 314. https://doi.org/10.3390/e25020314
APA StylePan, J.-S., Yue, L., Chu, S.-C., Hu, P., Yan, B., & Yang, H. (2023). Binary Bamboo Forest Growth Optimization Algorithm for Feature Selection Problem. Entropy, 25(2), 314. https://doi.org/10.3390/e25020314