Abstract
This article offers an optimal control tracking method using an event-triggered technique and the internal reinforcement Q-learning (IrQL) algorithm to address the tracking control issue of unknown nonlinear systems with multiple agents (MASs). Relying on the internal reinforcement reward (IRR) formula, a Q-learning function is calculated, and then the iteration IRQL method is developed. In contrast to mechanisms triggered by time, an event-triggered algorithm reduces the rate of transmission and computational load, since the controller may only be upgraded when the predetermined triggering circumstances are met. In addition, in order to implement the suggested system, a neutral reinforce-critic-actor (RCA) network structure is created that may assess the indices of performance and online learning of the event-triggering mechanism. This strategy is intended to be data-driven without having in-depth knowledge of system dynamics. We must develop the event-triggered weight tuning rule, which only modifies the parameters of the actor neutral network (ANN) in response to triggering cases. In addition, a Lyapunov-based convergence study of the reinforce-critic-actor neutral network (NN) is presented. Lastly, an example demonstrates the accessibility and efficiency of the suggested approach.
1. Introduction
Recently, distributed coordination control of MASs has received a great deal of attention as a result of its extensive applications in power systems [1,2], multi-vehicle [3] and multi-area power systems [4], and other fields. MASs have a variety problems, such as consensus control [5,6,7], synchronization control [8,9], anti-synchronization control [10], and tracking control [11]. Reinforcement learning (RL) [12] and adaptive dynamic programming (ADP) methods [13,14] have been employed by researchers as a means of solving the optimal control problems. Due to its excellent ability for global approximation, neural networks are excellent for dealing with nonlinearities and uncertainties [15]. ADP has great online learning and adaptive ability when it uses neural networks. Furthermore, researchers used RL/ADP algorithms to settle optimal coordination control matters, proposed a lot of directions, tracked control [16,17,18,19], graphical games [19], consensus control [20], containment control [21] and formation control [22]. The controller is designed in the above ways were relying on traditional time-triggered methods. Event-triggered in [23,24], it was suggested that the traditional implementation be changed to an event-triggered one. Because of the increasing number of agents, MASs are required to resolve many computing costs related to the exchange of information. Traditionally, the controller or actuator is constantly updated over a fixed period while the system is in operation. In order to minimize computation and preserve resources, aperiodic sampling is employed in the method of triggering events to improve the controller’s computation efficiency. There have been a number of developments in methods that are based on events for addressing discrete time systems [24]. The traditional implementation was suggested to be replaced by one that is triggered by events.
With an increase in the number of agents, MASs must solve a large number of computing costs related to information exchange. Traditionally, the controller or actuator is constantly updated frequently using a predetermined period of sampling during system operation. To lessen the computational and save resources, aperiodic sampling is used in the event-triggering scheme to improve the associated controller’s computational efficiency. Researchers have developed some event-based methods to address discrete time systems [25] as well as systems based on continuous time [26,27]. Several algorithms based on triggered events have been designed to solve discrete-time systems [25], as well as systems that operate in continuous time [26,27]. According to these results, the system dynamics are assumed to be accurate ahead of time. However, it is not always possible to understand dynamics properly in practice. According to [24], a controller that was triggered by events was proposed which was designed with inaccurate or unknown dynamics for the system.
The application of Q-learning to process control [28], chemical process control, industrial process automatic control, and other areas was an early application of reinforcement learning (RL). The Q-learning algorithm provides a modeless data-driven method for solving control problems. A key point to keep in mind is all potential actions in the present state. Q-learning is currently used primarily for routing optimization and reception processing in network communication within the context of network management. The Q-learning algorithm supports a modeless data-driven method for solving control problems. It is important to note that all potential actions in the present state [29] are evaluated in the Q-learning method, relying on the Q-function. At present, Q-learning is used primarily for routing optimization and reception processing in network communication in the domain of network management [30]. As a result of AlphaGo’s emergence, dynamic research has been conducted in the field of game theory, and tracking control research has been conducted on issues associated with nonlinear MAS tracking control based on Q-learning, such as in [31]. At present, there is some research for tracking control issues for nonlinear MASs based on Q-learning, such as in [32].
The MAS’s issue of optimal control was solved using the RL/ADP method, as mentioned above. The majority of the above results share two common features. First, the direct use of the immediate or immediate reward (IR) signal to define each agent’s performance index function results in limited learning opportunities. As a second step, a state’s value function is used to determine the Hamilton–Jacobi–Bellman (HJB) equation. The corresponding controller is designed using RL/ADP, which results in efficient learning of the MAS equation. It is beneficial to provide each agent with more information signals in a wide range of realistic applications in order to enhance their learning capabilities. In addition to merely considering performance in terms of status, performance can also be viewed from a broader perspective. The purpose of our research is to avoid the limitations described above.
Taking into consideration the aforementioned findings, this work investigates an ideal solution to the optimum control issue for MASs with unknown nonlinearity to enhance the process of learning as well as the effectiveness of control systems. Utilizing the graph theory, a coordination control problem is first identified. According to the gathered information of the IR, increased reinforcement reward (IRR) signals are provided for a longer-term reward period. Based on the IRR function, a Q-function is then developed to assess the efficacy of each agent’s control system. In addition, a tracking control technique is developed using iterative IrQL to derive the HJB equation for each agent. Then, based on the IrQL technique, triggering mechanisms are employed to establish a tracking control system. Finally, an optimum event-triggered controller based on a network topology of reinforce-actor-critic is created. The event triggering mechanism in a closed-loop approach guarantees that the network weights converge and the system remains stable. In light of the findings of this study, an additional contribution has been made to the literature:
(1) With respect to nonlinear MAS tracking control, the authors of [32] proposed an IrQL framework, which differs from [18,33,34], and the design of a new long-term IRR signal is completed. This product was designed on the basis of the data of neighbors to provide more information to the agent. The IRR function is used to define a Q-function, and an iterative IrQL method is proposed for obtaining control schemes that are optimally distributed.
(2) It is designed to trigger a new condition and cite in an asynchronous and distributed manner [24]. As a result, each agent triggers at its own time. Consequently, there is no need to update the controller on a regular basis. For the purpose of achieving online learning, a reinforce-actor-critic neural network based on triggered events is established to determine the optimal control scheme for triggered events. When compared with other papers [18,33,35,36], this paper adjusts the weights non-periodically, and the ANN is only adjusted when a trigger is encountered.
(3) In this paper, the objective is to develop the most effective tracking control method using a new triggering mechanism developed using the IrQL method. As far as event-triggered optimal control mechanisms are concerned, the Lyapunov approach is used to determine the rigorous stability assurance of closed-loop multi-agent networks. The designed RCA-NN framework [32] offers an effective means of executing the proposed method online without requiring any knowledge of the dynamics of the system. We made a comparison between the traditional activation method and the IrQL method. According to the simulation results, the designed algorithm is capable of detecting control problems with good tracking performance.
This article is organized as follows. The graph theory and problems of Section 2 provide an overview of some foundations. In Section 3, IrQL-based HJB equations are obtained. As described in Section 4, the most appropriate controller design should be triggered by an event to build the proposed algorithm. Section 5 develops the RCA-NN. The use of Lyapunov technology leads to convergence of weights in the neural networks. Through analogy examples and comparisons, its effectiveness and correctness of the method are demonstrated in Section 6. The last part includes our final thoughts.
2. Preliminary Findings
2.1. Theoretical Basis of Graphs
It would be possible to model the exchange of information using a directed graph between agents , in which represents N nonempty notes and represents an edge set, indicating agent i could derive the data from agent j. We define , which is a matrix that is adjacency relevant and does not contain negative elements , where is satisfied if . Otherwise, . is defined as the set of nodes that are neighbors with node i, and is satisfied for each . We denote the input matrix , where . The Laplacian matrix is then defined as
A leader’s relationship with its followers is the subject of this article. In order to describe follower-leader interactions, we propose an enhanced directed graph model, (i.e., , in which and ). A leader’s communication with his or her followers is determined by . If , then there is an assumption that the leader and followers are in communication. Otherwise, . is defined as the matrix of related connections.
2.2. Problem Formulation
If a nonlinear MAS has one leader as well as N followers, then the dynamics for the ith follower would be as follows:
In this case, represents the system state, represents the control input, and represent unknown matrices for the plants and inputs.
The leader is written as follows:
It is assumed that represents the leader state.
Assumption 1.
If there is a spanning tree with a leader, then has a network of communication interactions, and does not contain repeated edges.
Definition 1.
As a result of our design, we are able to develop a control scheme that only requires agent information. Therefore, the followers can keep track of the leader. In the event that the funder’s conditions are met, we will be able to implement a perfect control scheme [32]:
The MAS’s local consensus error is expressed as follows:
Then, an overview of the error vector is presented as follows:
, , , as well as vector having n dimensions.
The tracking error is written as , which has the vector form
In this equation, .
Consequently, the localized neighbor error is represented in the following manner, in agreement with Equations (1) and (4):
Given Equations (5) and (6), it is evident that and are related as follows: as . Consequently, when the localized neighboring error is close to zero, the control problem is resolved.
3. Design of the IrQL Method
To resolve the issue of tracking control in systems with multiple agents, the authors of [32] developed the IrQL method. What is important is that in order to provide agents with a greater level of local information from other agents or environments, it is necessary to introduce IRR information, thereby improving control and learning efficiency. In addition, agents have been defined according to the Q-function, and the relevant HJB equation is acquired using the IrQL method.
As an example, consider the following IR function for the ith agent:
In this case, we can represent the agent’s neighbors’ input with . The weight matrices , and are positive.
According to the IR function, as a function of IRR, the following is expressed:
where the IRR function is defined as and r is its discount factor.
The following performance indices must be minimized for every agent to find a solution to the issue of controlling tracking optimally:
In this case, its performance index discount factor is .
Remark 1.
The function of the designed IRR function incorporates accumulated prospective long-term reward data from the IR function. The performance factor is measured depending on IRR as opposed to IR, which is contrary to the majority of methods. The advantage is that we can enhance the control actions, and the learning process can be accelerated by using a great deal of data.
Remark 2.
Intrinsic motivation (IM) provides a possible method for enhancing the faculty of abstract actions or solving the difficulties associated with exploring the environment in its reinforcement learning direction. IRR acts as a driving agent that learns skills through intrinsic motivation [32].
Definition 2.
In order to resolve the MAS’s tracking control issue, we propose a distributed tracking control scheme. As the time step k approaches infinity, minimizes the performance metrics simultaneously.
We can obtain a state value function as follows based on the control method of the agent as well as the neighbors and :
Equation (11) can also be expressed as the following formula:
Based on the theory, the ideal state value function meets the following conditions:
In this case, in Bellman form, the function of IRR is expressed as
On the basis of the condition of stationarity, (i.e., ), the description of the optimal distributed control method is given below:
In this equation, .
Remark 3.
As is well known, the state value algorithm is highly concerned with the space of states. In accordance with the state action function, the Q-learning method is designed with RL. The Q-function can be used by each agent to estimate the properties of all possible decisions in the current situation, and we can determine what is the best behavior of the agent at each step by using the Q-function.
The Q-function is written as follows:
In accordance with the optimal scheme, the optimal Q-function is given by
Based on Equations (16) and (17), we can express the optimal solution as follows:
In comparison with the control method of Equation (15), its optimum Q-function provides the optimal solution for the control scheme here. As a result, we intend to calculate the solution to Equation (17).
4. Designs of the Event-Driven Controller
According to a previous work [18], a time-triggered controller was developed. Nevertheless, a new event-triggering mechanism is designed to minimize computing costs for this case.
is defined as the sequence of trigger times. At the triggering instant, the sampled disagreement error is expressed as .
As a result of the threshold value and error, the triggering time varies. The control scheme can only be updated when and cannot be updated under any other circumstances:
To design a triggering condition, we propose a function that measures the gap arising from the existing error and the previously sampled error:
We have set the triggering error equal to zero at .
The dynamic expression of localized mistakes based on an event-triggered controlling approach can be written as
Thus, the equation for event-triggered events is obtained:
It is possible to express the optimal tracking control using an event-triggered approach in the following way:
Assumption 2.
There is a constant that explains the inequality below:
Assumption 3.
There is a triggering condition which is as follows:
where represents the triggering threshold and [24]. Once the multi-agent system dynamics have stabilized, followers are able to track their leaders.
5. Neural Network Implementation for the Event-Triggered Approach Using the IrQL Method
This section discusses the tree-NN structure, also known as RCA-NNs. Three virtual networks are included in the tree-NN structure.
5.1. Reinforce Neutral Network (RNN) Learning Model
The reinforced NN is employed to approximate the IRR signal as follows:
where represents the input vector, which has , while . represents the matrix of weights for input-to-hidden layering. Meanwhile, represents the matrix of weights for hidden-to-output layering, and represents an activation function [24].
Due to the reinforced NN, the associated error function is as follows:
The loss function is written as
For convenience’s sake, only the matrices are updated, and the matrices remain unchanged during the training process.
The RNN’s update law is expressed as
In this equation, represents the rate at which the RNN learns.
The gradient descent rule (GDR) is used to obtain an updated law for the reinforced NN’s weight, which yields the following results:
In this equation, .
5.2. Critic Neutral Network (CNN) Learning Model
In the following section, when designing the critic NN, an attempt is made to achieve a close approximation of the Q-function:
In this equation, represents the relative vector of inputs that has , , and as well as , while and represent the input layer weight matrices and output layer weight matrices.
It is possible to express the function of the error for the CNN to be
Its function of loss is written to be
In accordance with the operation of RNNs, only is updated, and remains unchanged.
With the help of the gradient descent rule (GDR), it can be used to express the weight update law:
where represents the critic NN’s learning rate. Furthermore, we can obtain its weight update schemes for the critic NN:
In this equation, .
5.3. Actor Neutral Network (ANN) Learning Model
Based on the actor NN, an approximate optimal scheme is defined as follows:
where the input data of the ANN is represented by , represents the weight matrices of the input layer, and represents the weight matrices of the output layer.
Based on the prediction error of the actor NN, the following result is obtained:
It is possible to express the function of loss of the ANN to be
As with RNNs and CNNs, must remain unchanged throughout the learning process. The actor NN update laws are defined as follows:
where represents the ANN learning rate. We can design a weight-tuning scheme for an ANN as follows:
where , , .
Furthermore, we can obtain
It is described in detail in Algorithm 1 how the controller is designed using RCA-NNs and event triggering. When the trigger conditions are met, the actor NN is updated.
For analysis of stability based on the Lyapunov method, we present an analysis of stability and convergence in the following section.
Assumption 4.
The following conditions are assumed to be true: . There are bounded activation functions, i.e., . What’s more, the functions of activation is the function of Lipschitz that satisfies , where , are positive constants. Approximation errors of NNs’ output can be defined to be: .
Theorem 1.
Assume that Assumptions 1 and 2 are true. CNN and ANN weights are renewed by (36) and (42). Upon satisfying the triggering term(26), the local inconsistency error is , critic evaluated error and actor evaluated error error are consistent and ultimately bounded. Furthermore the control method converges to the optimal value .
Evidence: Set as the weighting assessment error between the optimal weights for RNNs . Its assessment , is the error resulting from weighting evaluation involving the ideal CNN weights ; its assessed , as well as is the weighting evaluated error involving the ideal ANN weightings and its estimation .
| Algorithm 1 RCA neural networks based on the IrQL method with event triggering. |
| Set initial value: |
| 1: Set initial values for between ; |
| 2: Set a low level of degree of precision for the calculation . |
| 3: Initialize the score of within |
| The iterative process: Make . Error calculation at the localized level ; |
| 4: Keep on; |
| 5: Based on actor NN, estimate by |
| 6: Update the reinforce NN; |
| 7: Via the inputting into the reinforce NN, and we can obtain the |
| estimated the function of IRR via |
| 8: Obtain by ; |
| 9: Renew the matrices by ; |
| 10: Renew the critic NN: |
| 11: Via the inputting into critic NN, |
| and we can obtain its estimated Q-function via ; |
| 12: Obtain by ; |
| 13: Renew the matrices by ; |
| 14: Renew the actor NN: |
| 15: Input to the actor NN, and we can obtain the estimated Q-function |
| via |
| 16: Calculation via |
| 17: In the event that the triggering conditions are met, renew the matrices |
| of the actor NN using |
| 18: Otherwise, do not update the weight matrices |
| 19: Until ; otherwise, set , then go to |
| procedure |
| 20: Keep on as the optimal weights. |
(1) We can obtain the following function at the time of triggering as follows:
In this equation,
is written to be
In this equation, we have
Furthermore, we have
can be written as
Within this equation, we have
Furthermore, we have
where
The following result is obtained by computation:
In the case of the difference of the first order of , we can obtain
where,
Therefore, we have
where
In the case of , the simplified formula is given below:
By adding Equations (47), (51), and (56), we can obtain as follows:
Therefore, we can obtain
where , and we can obtain . Next, we can obtain
Moreover, we can obtain
If the conditions are met, then we can obtain
We can derive . The proof has been completed.
(2) In the absence of the triggering conditions, consider the following:
where
In the event that it is satisfied that , and , one has . Thus, we can derive , and the proof is completed.
6. Statistical Data Illustration
To demonstrate the viability of the proposed method, a simulation is presented in the following section.
Nonlinear MAS Consisting of One Leader and Six Followers
There were six followers and one leader in this tangled set of MASs which were considered. Figure 1 depicts the connection graph of the studied MASs. There was a leader of 0, and there were followers of 1, 2, 3, 4, 5, and 6. It is possible to obtain the corresponding adjacency matrix . There is a weighted relationship involving the leaders and followers where . It is possible for agent 1 to accept the information of the leader immediately. The system model parameters for MASs with one leader as well as six followers are as follows: , and .
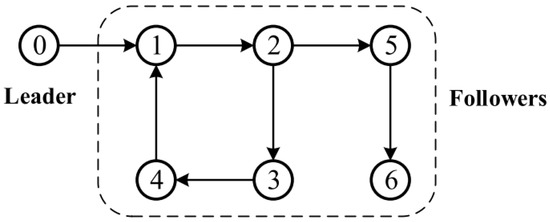
Figure 1.
The topology structure for leader-follower MASs.
The weight matrices are as follows: , and . The learning rates are , and , with a discount factor of .
For the agents, the activation function of the RNNs and ANNs is as follows:
The initial values of the leader and followers are , and .
According to Figure 2, all followers of the leader were able to accurately follow the leader, and the whole MAS was able to achieve synchronization. Figure 3 illustrates the six agents’ cumulative amount of trigger instants. On average, the amount of trigger instants for the six agents was approximately 220. However, using the traditional RL method, the number was approximately 1000. As a result, the computational burden was reduced by in comparison with the conventional time-triggered method. According to Figure 4, the trigger mechanism of each agent is illustrated, which indicates that the actor network weight will be updated only when the trigger mechanism is satisfied. As can be seen in Figure 5, there is a correlation involving the error of triggering as well as the minimum triggering requirements . Over time, it appears that the triggering error converged. Figure 6 and Figure 7 illustrate the evaluation of the local neighborhood errors using the proposed control method, and it is shown that they could be converged to 0 at k = 60. The local neighborhood errors of [32] are shown in Figure 8 and Figure 9. In comparison with Figure 8 and Figure 9, our proposed control method produced a better convergence effect. Figure 10 and Figure 11 show the estimation of the ANN weight parameters. With the proposed control method, the actor network weights can stabilize faster than with IrQL.
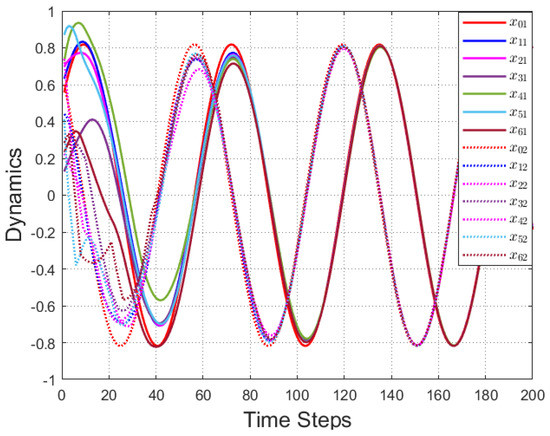
Figure 2.
The tracks for the leader and followers.
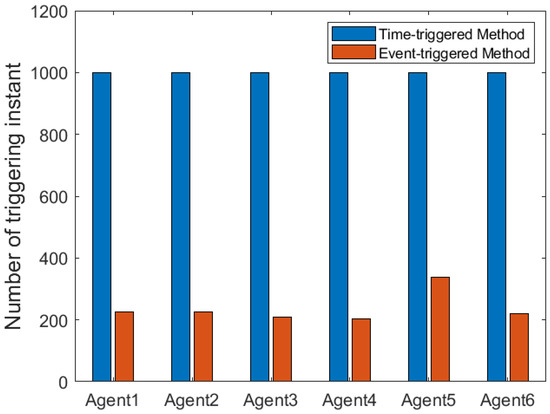
Figure 3.
The comparison of the trigger time number involving the suggested method as well as the conventional approach.
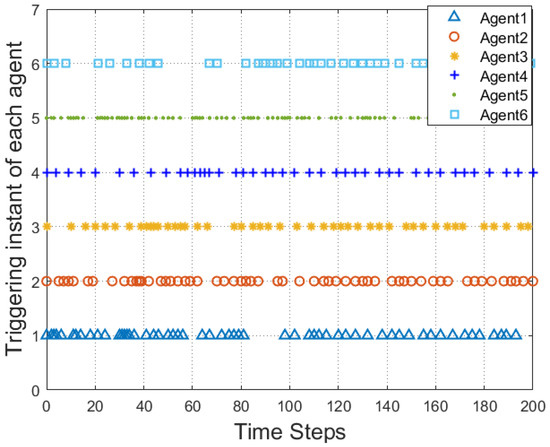
Figure 4.
The triggering instant for each agent.
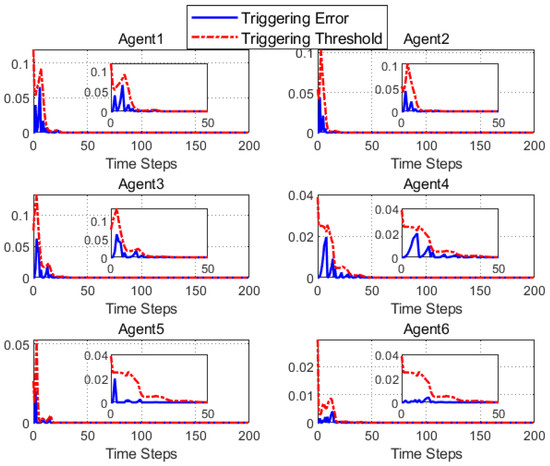
Figure 5.
The triggering error trajectory in addition to triggering thresholds .
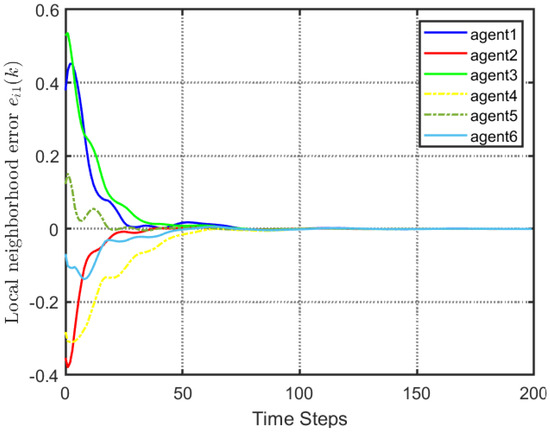
Figure 6.
Local neighborhood errors with the proposed control method.
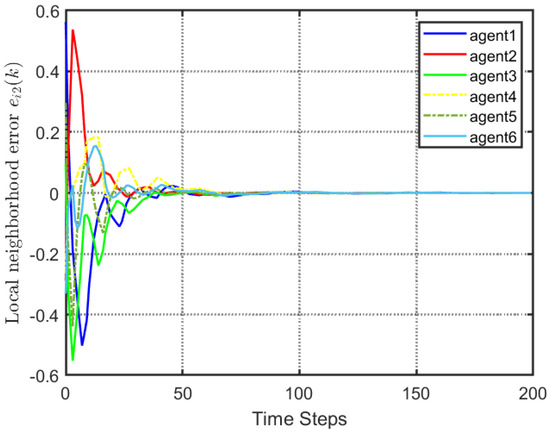
Figure 7.
Local neighborhood errors with proposed control method.
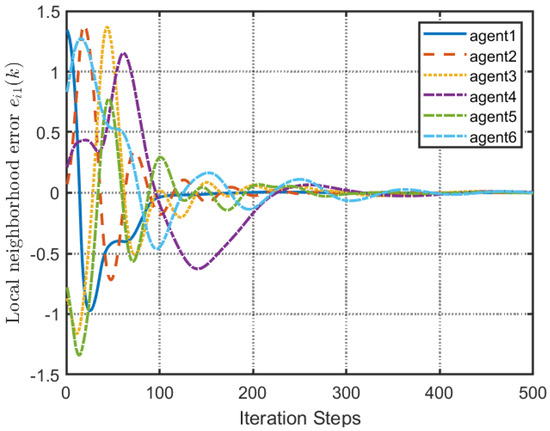
Figure 8.
Local neighborhood errors of [32].
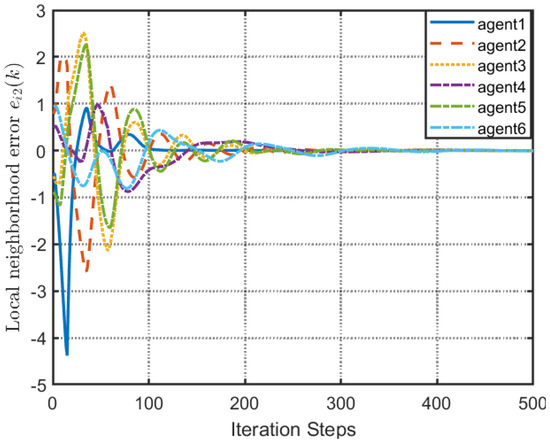
Figure 9.
Local neighborhood errors of [32].
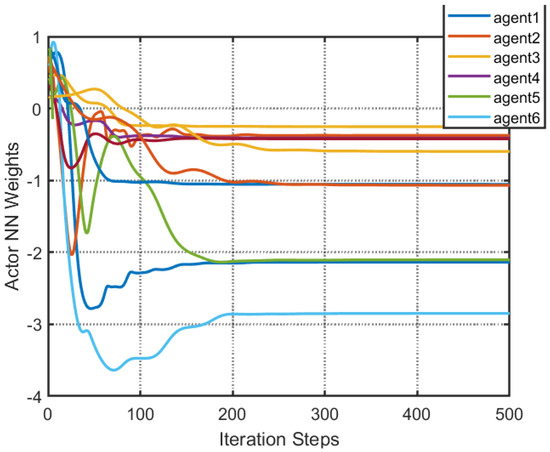
Figure 10.
The estimation of weight parameters of the ANN of [32].
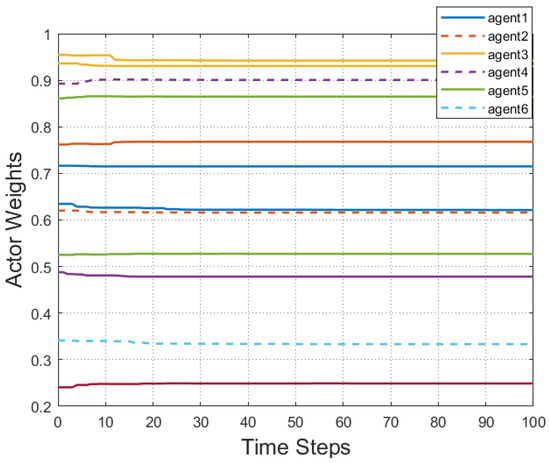
Figure 11.
Estimation of the weight parameters of an ANN using the proposed control method.
7. Conclusions
According to this study, an event-triggered optimum controlling problem for model-free MASs was examined using the IrQL method based on RL. A new IrQL method was introduced by adding additional IRR functions [32], As a result, more information could be obtained by the agent. As a consequence of defining the IRR formula, we defined the Q-function and derived the corresponding HJB equation. In an iterative approach to IrQL, this method was designed to calculate the optimal control strategy. Using the IrQL algorithm, an event-triggered controller utilizing the IrQL method was presented. It was designed to update the controller only at the time of triggering to reduce the burden on computing resources and the transmission network. An RCA-NN was used to implement the suggested approach, which eliminated the need for a model of the system. It is possible to determine the convergent weights of neural networks using the Lyapunov method. To assess the performance and control efficiency of the suggested algorithm, a simulation model was used. Further research will be conducted on the effect of the discount rates on system reliability.
Author Contributions
Software, Y.T., Y.L. and J.H.; Writing—review & editing, Z.W.; Supervision, X.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wen, G.; Yu, X.; Liu, Z.W.; Yu, W. Adaptive consensus-based robust strategy for economic dispatch of smart grids subject to communication uncertainties. IEEE Trans. Ind. Inform. 2018, 14, 2484–2496. [Google Scholar] [CrossRef]
- Li, P.; Hu, J.; Qiu, L.; Zhao, Y.; Ghosh, B.K. A distributed economic dispatch strategy for power-water networks. IEEE Trans. Control Netw. Syst. 2021, 9, 356–366. [Google Scholar] [CrossRef]
- Fax, J.A.; Murray, R.M. Information flow and cooperative control of vehicle formations. IEEE Trans. Autom. Control 2004, 49, 1465–1476. [Google Scholar] [CrossRef]
- Wen, S.; Yu, X.; Zeng, Z.; Wang, J. Event-triggering load frequency control for multiarea power systems with communication delays. IEEE Trans. Ind. Electron. 2016, 63, 1308–1317. [Google Scholar] [CrossRef]
- Wen, G.; Wang, P.; Huang, T.; Lü, J.; Zhang, F. Distributed consensus of layered multi-agent systems subject papers. IEEE Trans. Circuits Syst. 2020, 67, 3152–3162. [Google Scholar] [CrossRef]
- Wu, Z.G.; Xu, Y.; Pan, Y.J.; Su, H.; Tang, Y. Event-triggered control for consensus problem in multi-agent systems with quantized relative state measurements and external disturbance. IEEE Trans. Circuits Syst. 2018, 65, 2232–2242. [Google Scholar] [CrossRef]
- Liu, H.; Cheng, L.; Tan, M.; Hou, Z.G. Exponential finite-time consensus of fractional-order multiagent systems. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 1549–1558. [Google Scholar] [CrossRef]
- Shi, K.; Wang, J.; Zhong, S.; Zhang, X.; Liu, Y.; Cheng, J. New reliable nonuniform sampling control for uncertain chaotic neural networks under Markov switching topologies. Appl. Math. Comput. 2019, 347, 169–193. [Google Scholar] [CrossRef]
- He, W.; Chen, G.; Han, Q.L.; Du, W.; Cao, J.; Qian, F. Multi-agent systems on multilayer networks: Synchronization analysis and network design. IEEE Trans. Syst. 2017, 47, 1655–1667. [Google Scholar]
- Hu, J.; Wu, Y. Interventional bipartite consensus on coopetition networks with unknown dynamics. J. Frankl. Inst. 2017, 354, 4438–4456. [Google Scholar] [CrossRef]
- Hu, J.P.; Feng, G. Distributed tracking control of leader follower multi-agent systems under noisy measurement. Automatica 2010, 46, 1382–1387. [Google Scholar] [CrossRef]
- Wu, X.; Tang, Y.; Cao, J. Input-to-State Stability of Time-Varying Switched Systems with Time Delays. IEEE Trans. Autom. Control 2019, 64, 2537–2544. [Google Scholar] [CrossRef]
- Chen, D.; Liu, X.; Yu, W. Finite-time fuzzy adaptive consensus for heterogeneous nonlinear multi-agent systems. IEEE Trans. Netw. Sci. Eng. 2021, 7, 3057–3066. [Google Scholar] [CrossRef]
- Wang, J.L.; Wang, Q.; Wu, H.N.; Huang, T. Finite-time consensus and finite-time H∞ consensus of multi-agent systems under directed topology. IEEE Trans. Netw. Sci. Eng. 2020, 7, 1619–1632. [Google Scholar] [CrossRef]
- Ren, Y.; Zhao, Z.; Zhang, C.; Yang, Q.; Hong, K.S. Adaptive neural-network boundary control for a flexible manipulator with input constraints and model uncertainties. IEEE Trans. Cybern. 2021, 51, 4796–4807. [Google Scholar] [CrossRef]
- Mu, C.; Zhao, Q.; Gao, Z.; Sun, C. Q-learning solution for optimal consensus control of discrete-time multiagent systems using reinforcement learning. J. Frankl. Inst. 2019, 356, 6946–6967. [Google Scholar] [CrossRef]
- Peng, Z.; Zhao, Y.; Hu, J.; Ghosh, B.K. Data-driven optimal tracking control of discrete-time multi-agent systems with two-stage policy iteration algorithm. Inf. Sci. 2019, 481, 189–202. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, H.; Luo, Y.; Xiao, G. Data-driven optimal consensus control for discrete-time multi-agent systems with unknown dynamics using reinforcement learning method. IEEE Trans. Ind. Electron. 2017, 64, 4091–4100. [Google Scholar] [CrossRef]
- Abouheaf, M.I.; Lewis, F.L.; Vamvoudakis, K.G.; Haesaert, S.; Babuska, R. Multi-agent discrete-time graphical games and reinforcement learning solutions. Automatica 2014, 50, 3038–3053. [Google Scholar] [CrossRef]
- Peng, Z.; Zhao, Y.; Hu, J.; Luo, R.; Ghosh, B.K.; Nguang, S.K. Input–output data-based output antisynchronization control of multiagent systems using reinforcement learning approach. IEEE Trans. Ind. Inform. 2021, 17, 7359–7367. [Google Scholar] [CrossRef]
- Peng, Z.; Hu, J.; Ghosh, B.K. Data-driven containment control of discrete-time multi-agent systems via value iteration. Sci. China Inf. Sci. 2020, 63, 189205. [Google Scholar] [CrossRef]
- Wen, G.; Chen, C.P.; Feng, J.; Zhou, N. Optimized multi-agent formation control based on an identifier-actor-critic reinforcement learning algorithm. IEEE Trans. Fuzzy Syst. 2018, 26, 2719–2731. [Google Scholar] [CrossRef]
- Bai, W.; Li, T.; Long, Y.; Chen, C.P. Event-triggered multigradient recursive reinforcement learning tracking control for multiagent systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 366–379. [Google Scholar] [CrossRef] [PubMed]
- Peng, Z.; Luo, R.; Hu, J.; Shi, K.; Ghosh, B.K. Distributed optimal tracking control of discrete-time multiagent systems via event-triggered reinforcement learning. IEEE Trans. Circuits Syst. 2022, 69, 3689–3700. [Google Scholar] [CrossRef]
- Hu, J.; Chen, G.; Li, H.X. Distributed event-triggered tracking control of leader-follower multi-agent systems with communication delays. Kybernetika 2011, 47, 630–643. [Google Scholar]
- Eqtami, A.; Dimarogonas, D.V.; Kyriakopoulos, K.J. Event-triggered control for discrete-time systems. In Proceedings of the American Control Conference, Baltimore, MD, USA, 30 June–2 July 2010; pp. 4719–4724. [Google Scholar]
- Chen, X.; Hao, F. Event-triggered average consensus control for discrete-time multi-agent systems. IET Control Theory Appl. 2012, 6, 2493–2498. [Google Scholar] [CrossRef]
- Jiang, Y.; Fan, J.; Chai, T.; Li, J.; Lewis, F.L. Data-driven flotation industrial process operational optimal control based on reinforcement learning. IEEE Trans. Ind. Inform. 2018, 14, 1974–1989. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Alsheikh, M.A.; Lin, S.; Niyato, D.; Tan, H.P. Machine learning in wireless sensor networks: Algorithms, strategies, and applications. IEEE Commun. Surv. Tutor. 2014, 16, 1996–2018. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Modares, H.; Kiumarsi, B.; Lewis, F.L. Game theory-based control system algorithms with real-time reinforcement learning: How to solve multiplayer games online. IEEE Control Syst. 2017, 37, 33–52. [Google Scholar]
- Peng, Z.; Luo, R.; Hu, J. Optimal tracking control of nonlinear multiagent systems using internal reinforce Q-learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 4043–4055. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Liu, D.; Wei, Q.; Zhao, D.; Jin, N. Optimal control of unknown nonaffine nonlinear discrete-time systems based on adaptive dynamic programming. Automatica 2012, 48, 1825–1832. [Google Scholar] [CrossRef]
- Peng, Z.; Hu, J.; Shi, K.; Luo, R.; Huang, R.; Ghosh, B.K.; Huang, J. A novel optimal bipartite consensus control scheme for unknown multi-agent systems via model-free reinforcement learning. Appl. Math. Comput. 2020, 369, 124821. [Google Scholar] [CrossRef]
- Zhang, H.; Yue, D.; Dou, C.; Zhao, W.; Xie, X. Data-driven distributed optimal consensus control for unknown multiagent systems with input-delay. IEEE Trans. Cybern. 2019, 49, 2095–2105. [Google Scholar] [CrossRef] [PubMed]
- Si, J.; Wang, Y.-T. Online learning control by association and reinforcement. IEEE Trans. Neural Netw. 2001, 12, 264–276. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).