
Quantum Machine Learning: A Review and Case Studies


Abstract
1. Introduction
2. Background
2.1. Dirac (Bra-Ket) Notation
- Ket:
- Bra:Note that the complex conjugate of any complex number can be generated by inverting the sign of its imaginary component—for example, the complex conjugate of is .
- Bra-Ket: Inner product
- Ket-Bra: Outer product
2.2. Qubit
- X-Basis:
- Y-Basis:
2.3. Quantum Circuit
2.4. Quantum Gates
2.4.1. Single Qubit Gates
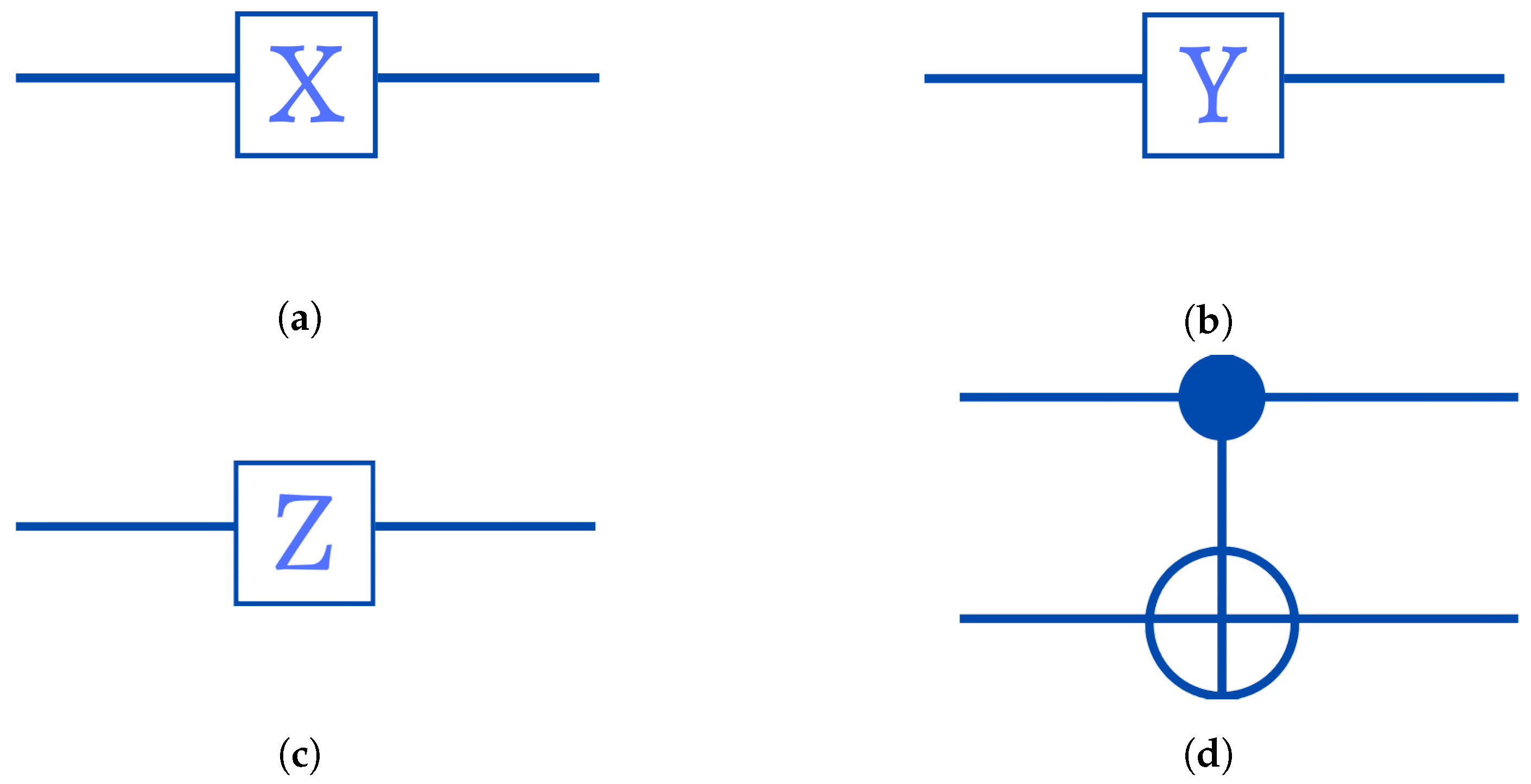
- Pauli-X Gate: Is the quantum equivalent of the NOT gate used in traditional computers, generally termed as the bit flip operator or x :When we apply X to , we obtainAs we can see, this gate flips the amplitudes of the and states. In a quantum circuit, the symbol in Figure 2a represents the Pauli-X gate.
- Pauli-Y Gate: Is commonly abbreviated as , which transforms the state vector throughout the whole y-axis:Consequently, when it is applied to the state, we obtainIn Figure 2b, the circuit design for the Y operator is displayed.
- Pauli-Z Gate: The Z operator, also known as the phase flip operator, used to perform a 180 rotation of the state vector around the z-axis.By applying the Pauli-Z gate to the computational basis state, we obtain the result shown below:For the particular case , we present it in matrix form:We have in the case where ,The Pauli-Z gate’s circuit diagram is shown in Figure 2c.
- Phase shift gates: Consists of a set of single-qubit gates which convert the basis states and .The matrix below represents the phase shift gate:where denotes the phase shift over a period of 2π. Typical instances include the Pauli-Z gate where , T gate where , and S gate where .
- Hadamard Gate: This quantum operator is essential for quantum computing because it allows the qubit to transform from one computational basis state to a superposition.When Hadamard gate is applied to the state , we obtainand to state , we obtainAs can be seen, the Hadamard gate projects a computational basis state into the superposition of two states.
2.4.2. Multi Qubit States and Gates
2.5. Representation of Qubit States
- arbitrary ;
- arbitrary ;
- ;
- ;
- ;
- .
- For a single qubit as shown in Figure 4a:
- -
- The south pole represents the state ;
- -
- The north pole represents the state ;
- -
- The size of the blobs is related to the likelihood that the relevant state will be measured;
- -
- The color indicates the relative phase compared to the state .
- For n qubits:In Figure 4b, we plot all states as equally distributed points on sphere with on the north pole, on the south pole, and all other state are aligned on parallels, such as the number of “1”s on each latitude is constant and increasing from north to south.
2.6. Entanglement
- 1.
- .
- 2.
- .
- 3.
- .
- 4.
- .
2.7. Quantum Computer
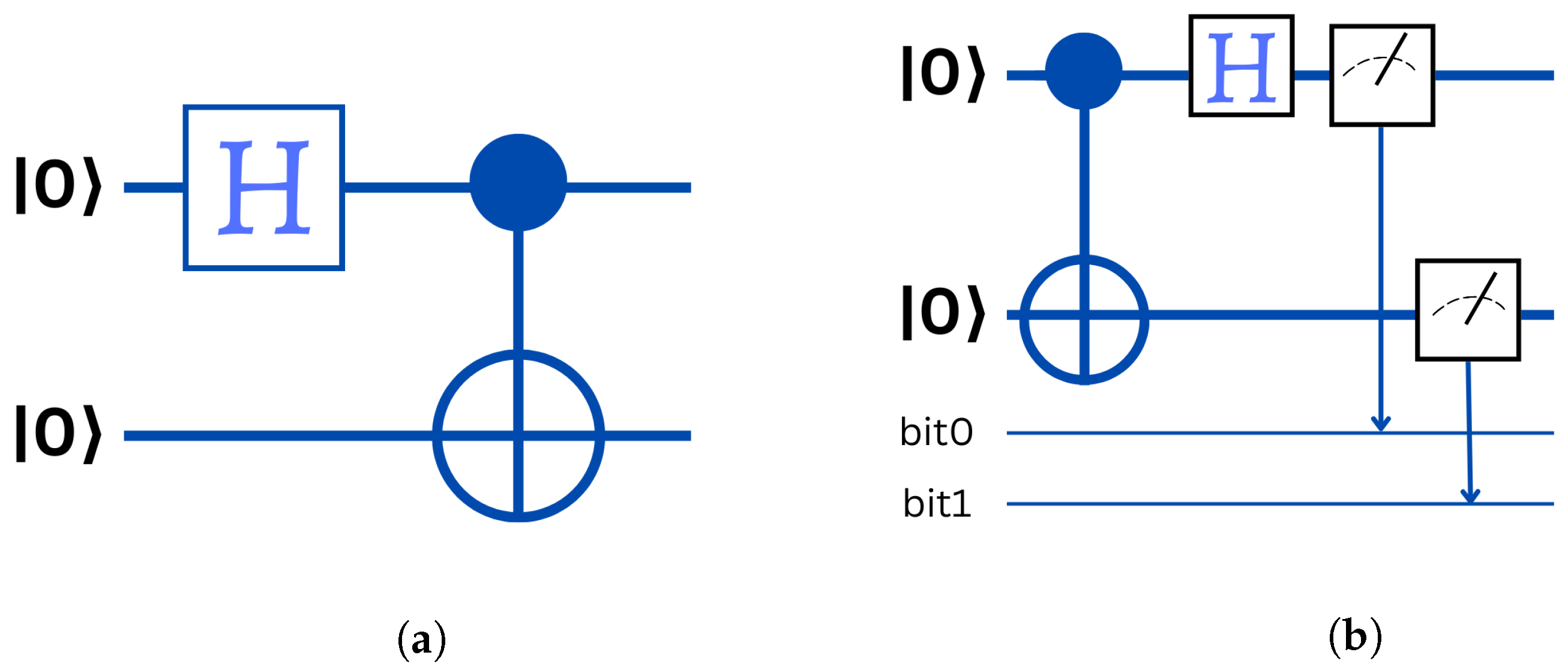
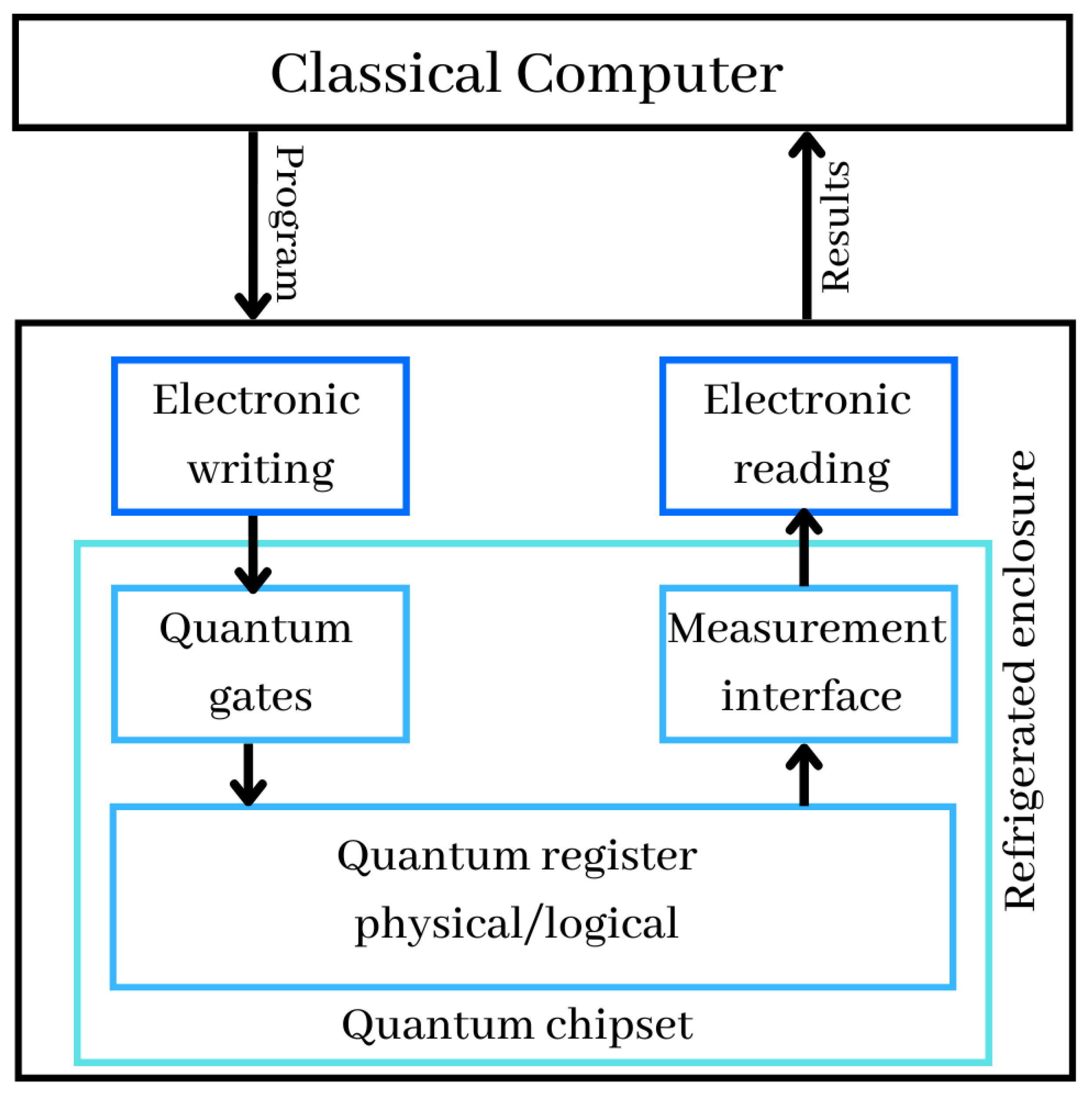
- Quantum registers are just a collections of qubits. In November 2022, the benchmarked record was 433 qubits, announced by IBM. Quantum registers store the information manipulated in the computer and exploit the principle of superposition allowing a large number of values to coexist in these registers and to operate on them simultaneously;
- Quantum gates are physical systems acting on the qubits of the quantum registers, to initialize them and to perform computational operations on them. These gates are applied in an iterative way according to the algorithms to be executed;
- At the conclusion of the sequential execution of quantum gates, the measurement interface permits the retrieval of the calculations’ results. Typically, this cycle of setup, computation, and measurement is repeated several times to assess the outcome. We then obtain an average value between 0 and 1 for each qubit of the quantum computer registers. The values received by the physical reading devices are therefore translated into digital values and sent to the traditional computer, which controls the whole system and permits the interpretation of the data. In common cases, such as at D-Wave or IBM, which are the giants of quantum computers building, the calculation is repeated at least 1024 times in the quantum computer;
- Quantum chipset includes quantum registers, quantum gates and measurement devices when it comes to superconducting qubits. Current chipsets are not very large. They are the size of a full-frame photo sensor or double size for the largest of them. The size of the latest powerful quantum chip called the 433-qubit Osprey, around the size of a quarter;
- Refrigerated enclosure generally holds the inside of the computer at temperatures near absolute zero. It contains part of the control electronics and the quantum chipset to avoid generating disturbances that prevent the qubits from working, especially at the level of their entanglement and coherence, and to reduce the noise of their operation;
- Electronic writing and reading in the refrigerated enclosure, control the physical devices needed to initialize, update, and read the state of qubits.
2.8. Quantum Algorithms
- Polynomial time (P): Are issues solvable in a polynomial amount of time. In other terms, a traditional computer is capable of resolving the issue in a reasonable time;
- Non-deterministic Polynomial time (NP): Is a collection of decision issues that a nondeterministic Turing machine might solve in polynomial time. P is an NP subset;
- NP-Complete: X is considered to be NP-Complete only if the requirements here are met: X is in NP, and in polynomial time, all NP problems are reducible to X. We assert that X is NP-hard if only is true and not necessarily ;
- Polynomial Space (PSPACE): This category is concerned with memory resources instead of time. PSPACE is a category of decision issues that can be solved by an algorithm whose total space utilization is always polynomially restricted by the instance size;
- Bounded-error Probabilistic Polynomial time (BPP): Is a collection of decision issues which may be handled in polynomial time using a probabilistic Turing computer with such a maximum error probability equal to 1/3;
- Bounded-error Quantum Polynomial time (BQP): A decision issue is BQP, if it has a polynomial time solution and has a high accuracy probability. BQP is the basic complexity category of problems which quantum computers may effectively solve. It corresponds to the classical BPP class on the quantum level;
- Exact Quantum Polynomial time (EQP or QP): Is a type of decision issue that a quantum computer can handle in polynomial time with probability 1. This is the quantum counterpart of the P complexity class.
3. Quantum Machine Learning
3.1. Quantum Encoding
3.1.1. Basis Encoding
3.1.2. Amplitude Encoding
3.1.3. Qsample Encoding
3.2. Essential Quantum Routines for QML
3.2.1. HHL Algorithm
3.2.2. Grover’s Algorithm
- 1.
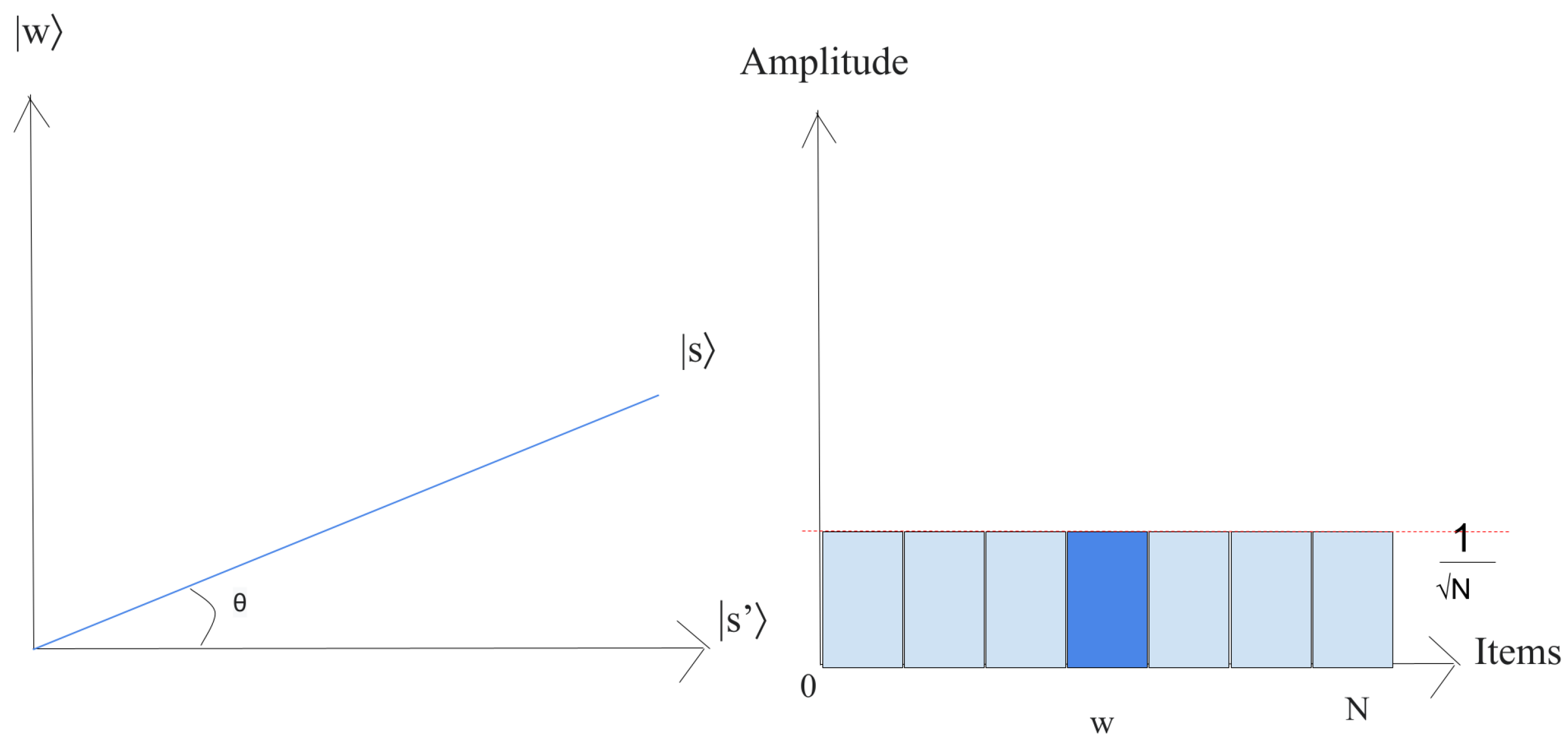
- Let us just put the system in the state ,This superposition , which is easily produced from , is the beginning for the amplitude amplification technique, as shown in Figure 9.The left chart corresponds to the two-dimensional plane spanned by orthogonal vectors and which allows for describing the beginning state as , where . The right picture is a bar chart of the amplitudes of the state .
- 2.
- Execute times the following “Grover iteration”:
- (a)
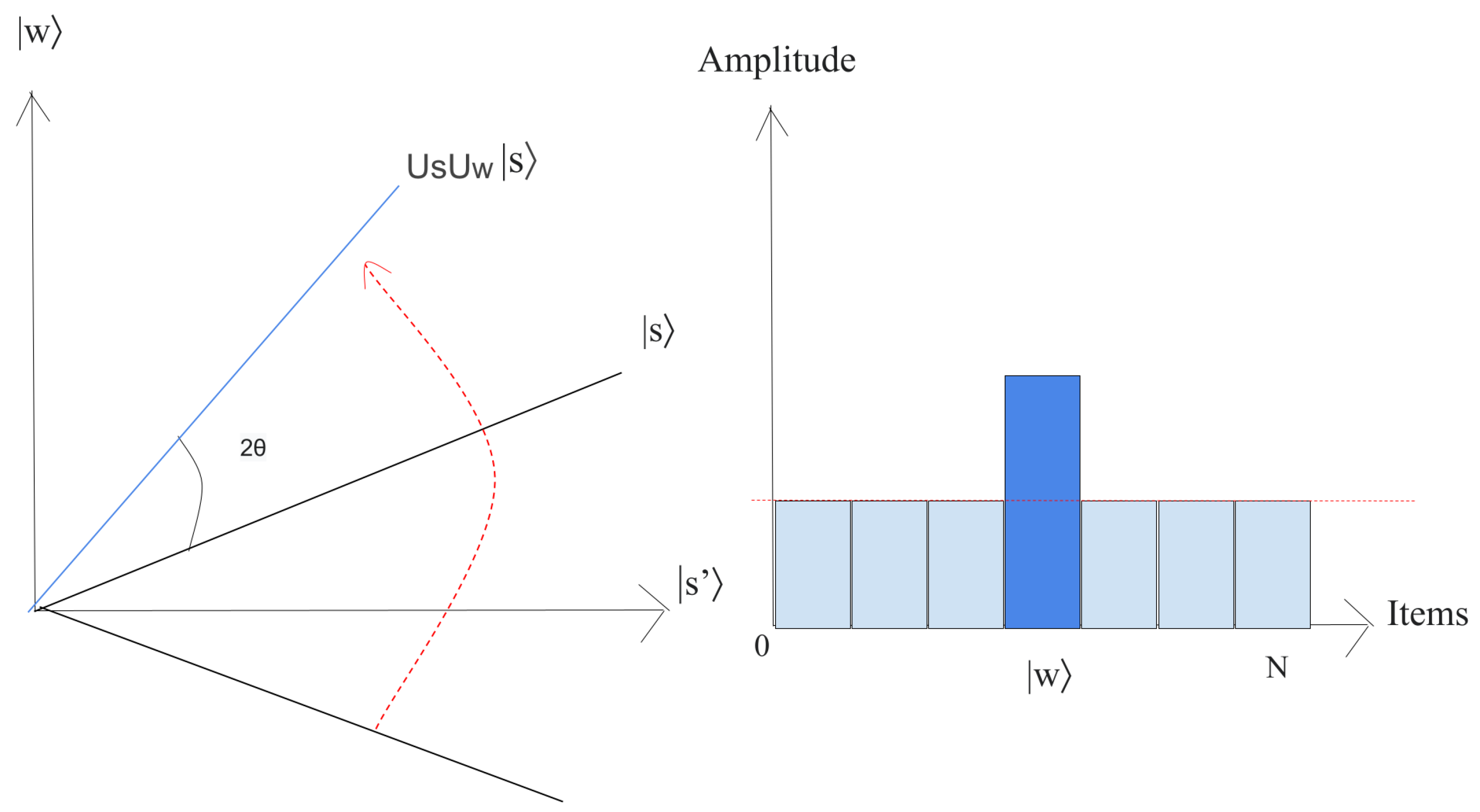
- Apply the operator to .Geometrically, this relates to a reflection of the state about . This transformation indicates that the amplitude in front of the state turns negative, which in turn implies that the average amplitude (shown by a dashed line in Figure 10) has been reduced.
- (b)
- We now implement the operator to the state .This transformation completes the transformation by matching the state to , which relates a rotation around an angle as shown in Figure 11.
The state will rotate by after r implementation of step 2, where [38]. - 3.
- The final measurement will give the state with probability .
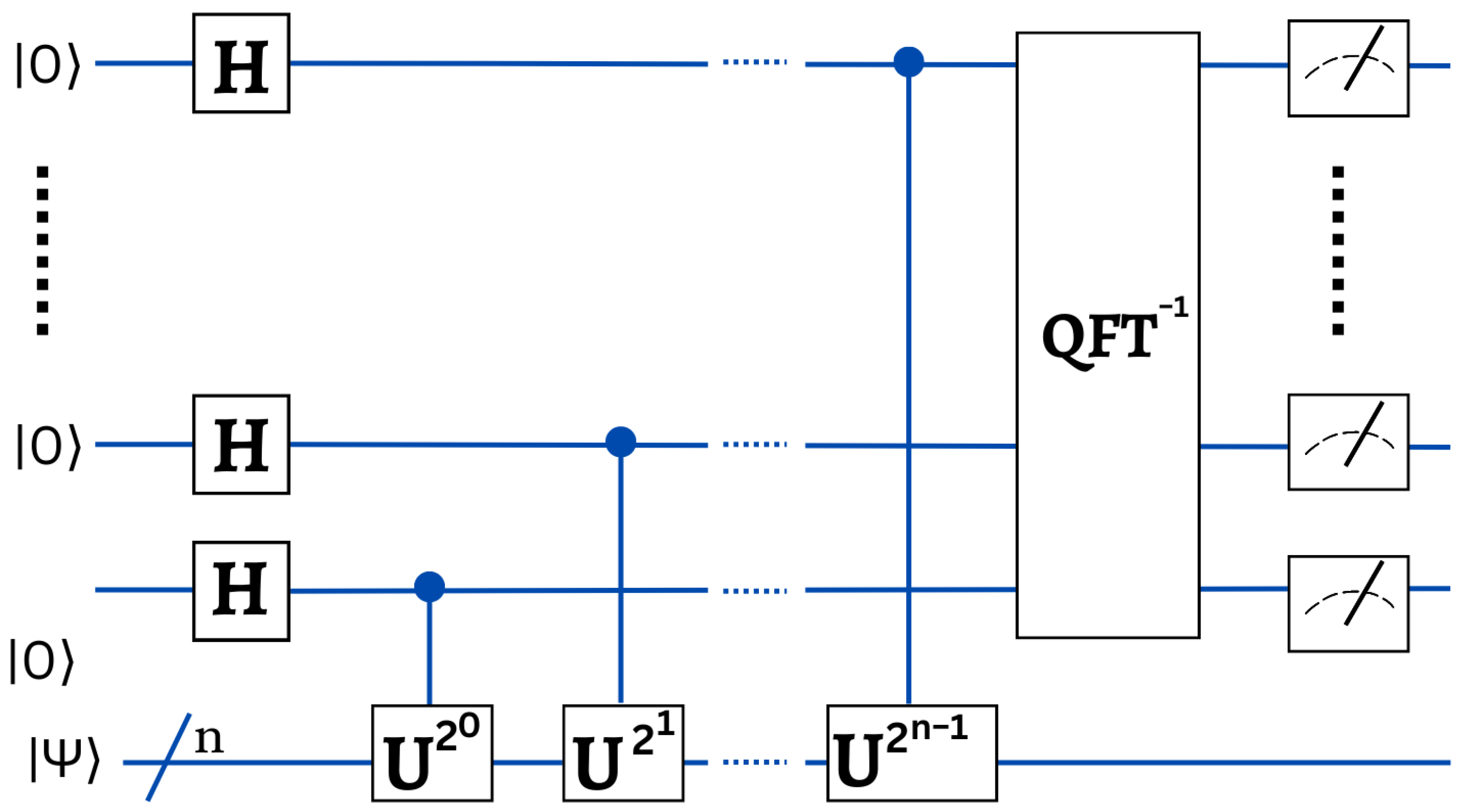
3.2.3. Quantum Phase Estimation
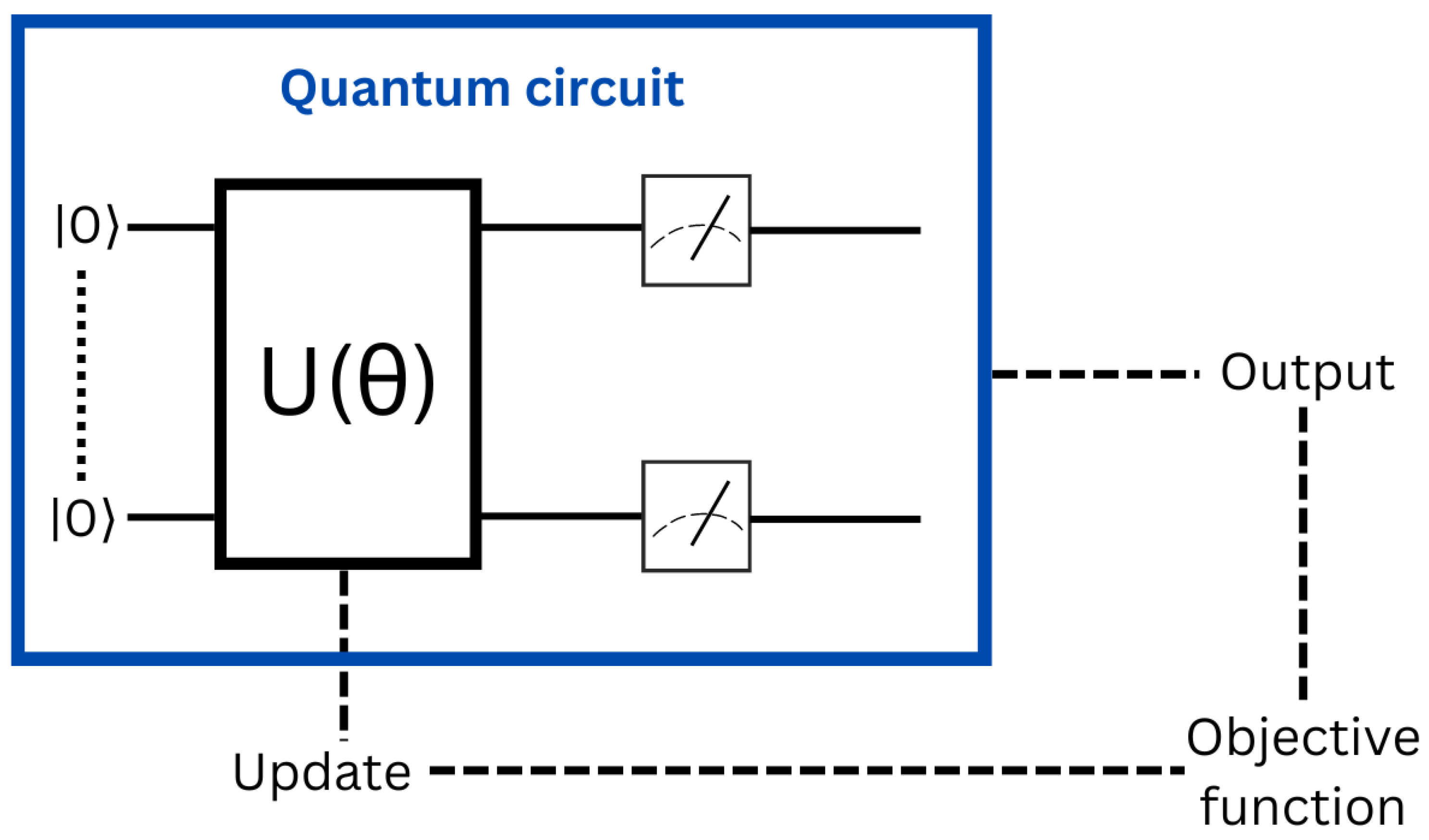
3.2.4. Variational Quantum Circuit
3.3. QML Algorithms
3.3.1. Quantum Support Vector Machines
- 1.
- kernel function and parameters initialization: Each parameter utilized by a kernel function must have its value initialized. Choose a relevant kernel function for the problem at hand and then generate the corresponding kernel matrix;
- 2.
- Parameters and classical information represented by quantum states: In this stage, the objective function is segmented, and its components are recorded in qubits. Binary strings may be used to represent the conventional data:with for . Then, the binary strings may be simply converted into k qubit quantum states:which form a Hilbert space of dimensions covered by basis ;
- 3.
- The quantum minimization subroutine examines objective function space: The Grover technique determines the optimal value of that resolves for and c by searching the space of all possible objective functions. By first generating a superposition of all potential inputs to a quantum oracle O expressing the objective function, this procedure achieves a global minimum for the SVM optimization problem. This subroutine’s measurement yields the answer with a high degree of probability.
3.3.2. Quantum Least Square SVM
- Quantum random access memory (QRAM) data translation: Preparing the collected data as input into the quantum device for computation is among the difficult tasks in QML. QRAM aids in transforming a collection of classical data into its quantum counterpart. QRAM requires steps to retrieve data from storage in order to reconstruct a state, with d representing the feature vector’s dimension;
- Computation of the kernel matrix: The kernel matrix is mostly determined by the examination of the dot product. Therefore, if we obtain speedup benefits of the dot product performance in the quantum approach, this will result in an overall speedup increase in the computation of the kernel matrix. With the use of quantum characteristics, the authors of [5] provide a quicker method for calculating dot products. A quantum paradigm is also used for the computation of the normalized kernel matrix inversion . As previously said, QRAM requires only steps to request for recreating a state, hence a simple dot product using QRAM requires steps, where represents a desired level of accuracy;
- Least square formulation: The quantum implementation of the exponentially faster eigenvector performance makes the speedup increase conceivable during the training phase in matrix inversion method and non-sparse density matrices [5].
3.3.3. Quantum Linear Regression
3.3.4. Quantum K-Means Clustering
- 1.
- Initialization: Set the k cluster by using heuristic comparable to that of the traditional k-means algorithm. For instance, k data points may be randomly selected as the first clusters;
- 2.
- Until Convergence:
- (a)
- In every piece of data, defined with its magnitude saved conventionally as well as the unit norm saved like a quantum state, the distance is computed by using quantum Euclidean distance computation procedure with every one of the k cluster centroids:with
- (b)
- Apply the search technique developed by Grover to allocate every in the data set to a single k clusters. As seen below, the oracle implemented in Grover’s search method must be capable of taking the distance and then allocate the proper cluster according to the formula below:
- (c)
- The mean of each cluster is determined after assigning each piece of data to its cluster :where represents the total number of data that might be assigned to cluster j.
3.3.5. Quantum Principal Component Analysis
4. ML vs. QML Benchmarks
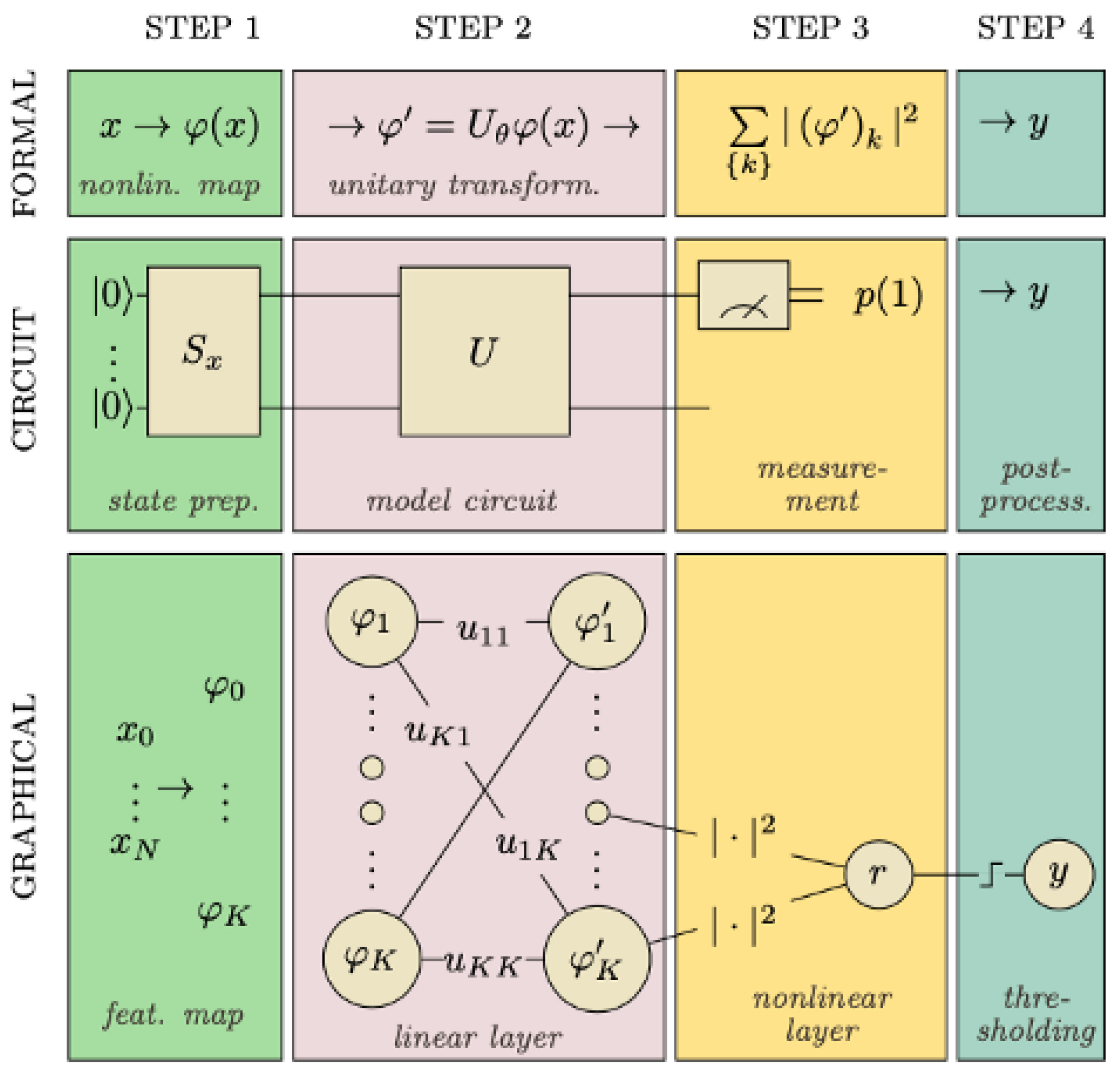
4.1. Variational Quantum Classifier
- State preparation: To be able to encode classical data into quantum states, we use particular operations to help us work with data in a quantum circuit. As mentioned earlier, quantum encoding is one these methods that consists of representing classical data in the form of a quantum state in Hilbert space employing a quantum feature map. Recall that a feature map is a mathematical mapping that allows us to integrate our data into higher dimensional spaces, such as quantum states in our case. It is similar to a variational circuit in which the parameters are determined by the input data. It is essential to emphasize that a variational circuit depends on parameters that can be optimized using classical methods;
- The model circuit: The next step is the model circuit, or the classifier in precise terms. is generated using a parameterized unitary operator applied to the feature vector noted as which became a vector of a quantum state in an n-qubit system (in the Hilbert space ). The model uses a circuit that is composed of gates which change the state of the input and are built on unitary processes, and they depend on external factors that can be adjusted. translates into another vector with a prepared state in the model circuit. is comprised of a series of unitary gates;
- Measurement: We take measurements in order to obtain information from a quantum system. Although a quantum system has an infinite number of potential states, we can only recover a limited amount of information from a quantum measurement. Notice that the number of qubits is equal to the amount of results;
- Post-process: Finally, the results were post-processed including a learnable bias parameter and a step function to translate the result to the outcome 0 or 1.
4.1.1. Implementation
- Dataset: Our classification data sets made up of three sorts of irises (Setosa, Versicolour, and Virginica), and containing four features that are Sepal Length, Sepal Width, Petal Length and Petal Width. In our implementation, we used the two first classes:
- Implemented models:
- -
- VQC: The Variational Quantum Classifiers commonly define a “layer”, whose fundamental circuit design is replicated to create the variational circuit. Our circuit layer is composed of a random rotation upon each qubit, and also a CNOT gate that entangles each qubit with its neighbor. The classical data were encoded to amplitude vectors via amplitude encoding;
- -
- SVC: A support vector classifier (SVC) implemented by the sklearn Python library;
- -
- Decision Tree: Is a non-parametric learning algorithm which anticipates the target variable through learning decision rules;
- -
- Naive Bayes: Naive Bayes classifiers utilize Bayes theory with the assumption of conditional independence in between each pair of features;
- Experimental Environment: We use the Jupyter Notebook and PennyLane [80] (A cross-platform Python framework for discrete programming of quantum computing) for developing all the codes and executing them on IBM Quantum simulators [81]. We implemented three classical Scikitlearn [82] algorithms to accomplish the same classification task on a conventional computer in order to compare their performance with that of the VQC. We also used the end value of the cost function and the test accuracy as metrics for evaluating the implemented algorithms.
4.1.2. Results
4.2. SVM vs. QSVM
4.2.1. Implementation
- Breast cancer dataset: The Wisconsin Diagnostic Breast Cancer dataset (WDBC) of UCI machine learning repository is a classification dataset that includes breast cancer case metrics. There are two categories: benign and malignant. This dataset contains information on 31 characteristics that define a tumor, among which are: average radius, mean perimeter, mean texture, etc., and a total of 569 records and 31 features;
- Principal Component Analysis: The existing quantum computers are yet to attain full potential as their functions are constrained by the limited number of accessible qubits, noise, and decoherence. Thereby, a dataset with exceptionally big dimensionality is difficult to be implemented. In addition, this is where Principal Component Analysis (PCA) comes to help. As mentioned above, PCA is the technique that reduces the huge dimension into smaller-scaled dimensions keeping the correlation given in the dataset. The principal components are orthogonal since they are the eigenvectors of the covariance matrix. Generally, we can assume that the data summarized can be processed by a quantum computer. Using PCA offers us the flexibility to leave out some of the components without losing much information and therefore minimizing the complexity of the problem as illustrated in Figure 15, where we reduced our dataset in order to handle it with a quantum computer;
- Quantum Feature Map: As we discussed earlier, the Kernel techniques are the set of algorithms for pattern analysis or recognition of the data points. Kernel techniques map data to higher dimensional spaces in order to ease data structure and separability. The data may be translated not only to higher-level space but to an endless dimension. Kernel “trick” is the technique of replacing the inner products of two vectors in our algorithm with the kernel function. In other hand, we have Quantum Kernel techniques which is a method for identifying a hyperplane that is performing a nonlinear transformation to the data, This is termed as a “feature map”. We may either apply available Qiskit (an open-source quantum computing framework created by IBM.) feature maps including ZZ feature map, Z feature map, or a Pauli feature map that has Pauli (X, Y, Z) gates, or create a custom feature map based on the dataset compatibility. The quantum feature map can be built by using Hadamard gates with entangling unitary gates between them. In our case, we used the ZZ feature map.The needed number of qubits is proportional to the data dimensionality. By altering the angle of unitary gates to a certain value, data are encoded. QSVM uses a Quantum processor to estimate the kernel in the feature space. During the training step, the kernel is estimated or computed, and support vectors are obtained. However, in applying the Quantum Kernel method directly, we should encode our training data and test data into proper quantum states. Using Amplitude Encoding, we may encode the training samples in a superposition inside one register, while test examples can be encoded in a second register.
4.2.2. Results
4.3. CNN vs. QCNN
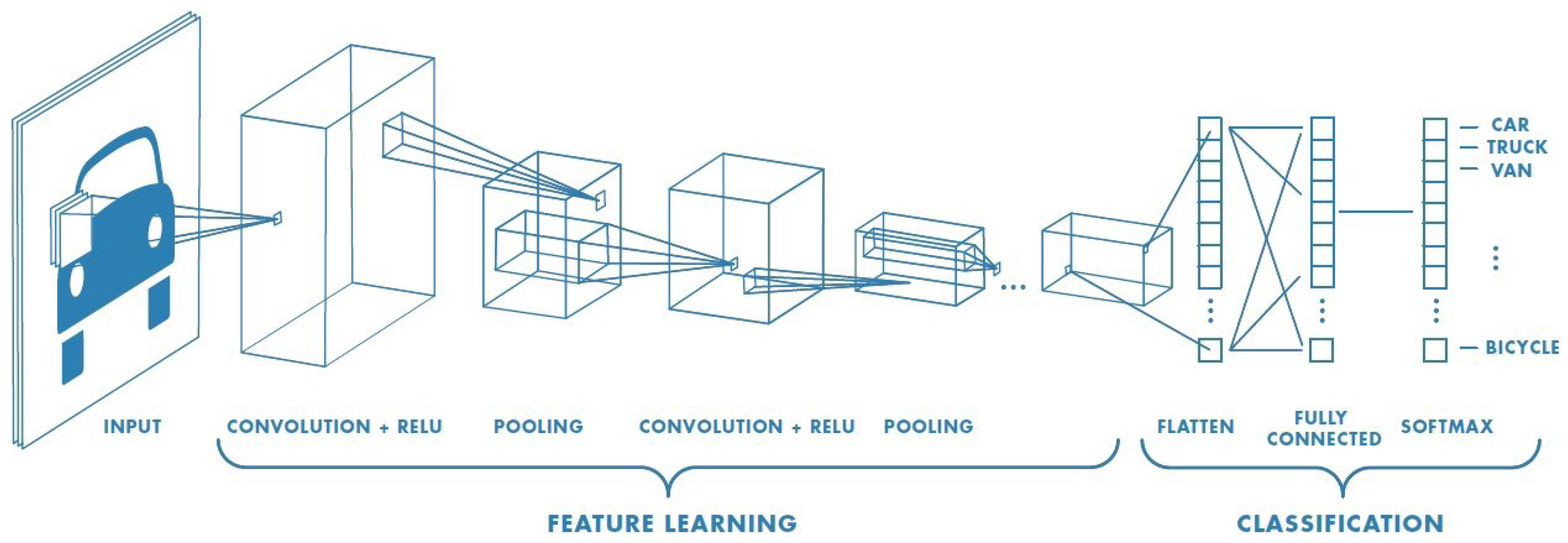
- Convolutional Neural NetworksConvolutional neural networks (CNNs) are a specialized sort of neural networks, built primarily for time series or image processing. They become presently the most frequently used models for image recognition applications. Their abilities have indeed been applied in several sectors such as gravitational wave detection or autonomous vision. Despite these advances, CNNs struggle from a computational limitation which renders deep CNNs extremely pricey in reality. As Figure 18 illustrates, a convolutional neural network generally consists of three components even though the architectural implementation varies considerably:
- 1.
- Input: The most popular input is an image, although significant work has also been carried out on so-called 3D convolutional neural networks which can handle either volumetric data (three spatial dimensions) or videos (two spatial dimensions + one temporal dimension). For the majority of the implementations, the input needs to be adjusted to correspond to the specifics of the CNN used. These include cropping, lowering the size of the image, identifying a particular region of interest, and also normalizing pixel values to specified regions. Images, and even more widely layers of a network, may be represented as tensors. The tensor is a generalization of a matrix into extra dimensionality. For example, an image of a height H and a width W may indeed be visualized as just a matrix in , wherein every pixel represents a greyscale ranging between 0 and 255. Furthermore, all three channels in color RGB (Red Green Blue) should be taken into account, simply layering 3 times the matrix for every color. A whole image is thus viewed as a three-dimensional vector in wherein D represents the number of channels;
- 2.
- Feature Learning: The feature learning is built of three principal procedures, executed and repeated in any sequence: Convolution Layers, usually followed with an Activation Function and Pooling Layers at the end of this feature learning process. We indicate by l the present layer.
- -
- Convolution Layer: Each lth layer is combined by a collection filter named kernels. The result of this procedure would be the th layer. The convolution using a simple kernel may be considered to be like a feature detector, which will screen through all sections of the input. If a feature described by a kernel, for example, a vertical border, is present through some area of the input, it will be highly valuable at the corresponding point of the outcome. The outcome is known as the feature map of the whole convolution;
- -
- Function: Just like in normal neural networks, we add certain nonlinearities also named activation functions. These functions are necessary for a neural network in order to be capable of learning any function. As in implementation of a CNN, every convolution is frequently followed by a Relu (Rectified Linear Unit function). This is a basic function that sets all negative numbers of the output to zero, then leaves the positive values as they are;
- -
- Pooling Layer: The downsampling method that reduces the dimensions of the layer, particularly optimizing the calculation. Furthermore, it provides the CNN the capability to learn a form invariant to lower translations. Almost all of the cases, either we use a Maximum Pooling or perhaps an Average Pooling. Maximum Pooling consists of swapping a subsection of components just by another with the biggest value. Average Pooling achieves this by averaging all numbers. Note that the number of a pixel relates to how often a certain feature is represented in the preceding convolution layer;
- 3.
- Classification/Fully Connected Layer: Following a specific set of convolution layers, the inputs had been properly handled such that we may deploy a fully connected network. The weights link every input to every output, wherein inputs are all components of the preceding layer. The final layer must include a single node for each possible label. The node value may be read as the probability that the input image belongs to the specified class.
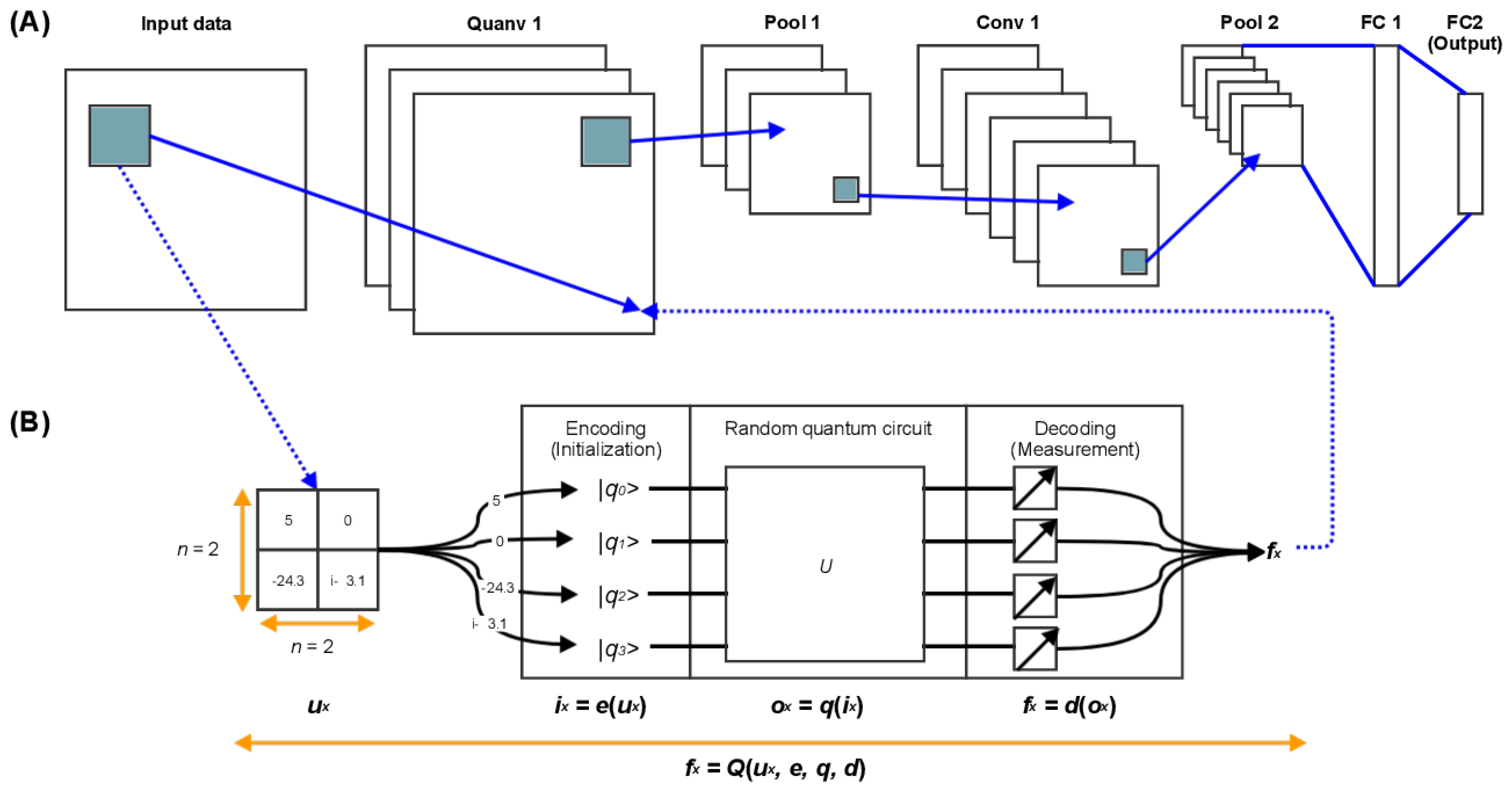
- Quanvolutional Neural NetworksThe Quanvolutional Neural Networks (QNNs) are essentially a variant of classical convolutional neural networks with an extra transformation layer known as the quanvolutional layer, or quantum convolution that is composed of quanvolutional filters [29]. When applied, the latter filters to a data input tensor; then, this will individually generate a feature map by changing spatially local subsections of this input. However, unlike the basic handling data element by element in matrix multiplication performed by a traditional convolutional filter, a quanvolutional filter transforms input data using a quantum circuit that may be structured or arbitrary. In our implementation, we employ random quantum circuits as proposed in [29] for quanvolutional filters rather than circuits with a specific form, for simplicity and to create a baseline.This technique for converting classical data using quanvolutional filters can be formalized as follows and illustrated in Figure 19:
- 1.
- Let us simply begin with a basic quanvolutional filter. The latter filter employs the arbitrary quantum circuit q that accepts as inputs subsections of images of dataset a u. Each input is denoted by the letter , with each being a two-dimensional matrix of length n-by-n, where n is greater than 1;
- 2.
- Despite the fact that there are a variety of methods for “encoding” as an initial state of q, we chose one encoding method e for every quanvolutional filter, and we define the resulting state of this encoding with ;
- 3.
- Thereafter, the application of the quantum circuit q to the beginning state , and the outcome of the quantum computing was indeed the quantum state , as defined by the relation that also equals ;
- 4.
- In order to decode the quantum state , we use d which is our decoding method that converts the quantum output into classical output using a set of measurements, which guarantees that the output of the quanvolutional filter is equivalent to the output of a simple classical convolution. The decoded state is described by with in which represents a scale value;
- 5.


4.3.1. Implementation
- Dataset: We used a subset of the MNIST (Modified or Mixed National Institute of Standards and Technology) dataset, which includes 70,000 handwritten 28 by 28 pixels in grayscale;
- Implemented models:
- -
- The CNN model: We used a simple model: Fully-connected layer containing ten output nodes and then a final activation function softmax in a pure classical convolutional neural network;
- -
- The QNN model: A CNN with one quanvolutional layer seems to be the simplest basic quanvolutional neural network. The single quantum layer will be the first, and then the rest of the model is identical to the traditional CNN model;
- Experimental Environment: The Pennylane library [80] was used to create the implementation, which was then run on the IBM quantum computer simulator QASM;
- Quanvolutional layer generation process described as follows:
- -
- A quantum circuit is created by including some small section of the input image, in our case a square of . A rotation encoding layer denoted by (with angles scaled by a factor );
- -
- The system performs a quantum computation associated with a unit U. A variational quantum circuit or, quite generally, a randomized circuit could generate this unit;
- -
- The quantum system is measured using a computational basis measurement, which gives a set of four classical expectation values. The outcomes of the measurements can eventually be post-processed in a classical way;
- -
- Each value is translated into a distinct channels of one output pixel, as in a classical convolution layer;
- -
- In repeating the technique on different parts, the whole input image can be scanned, thus obtaining an output object structured as a multi-channel;
- -
- Other quantum or classical layers can be added after the quanvolutional layer.
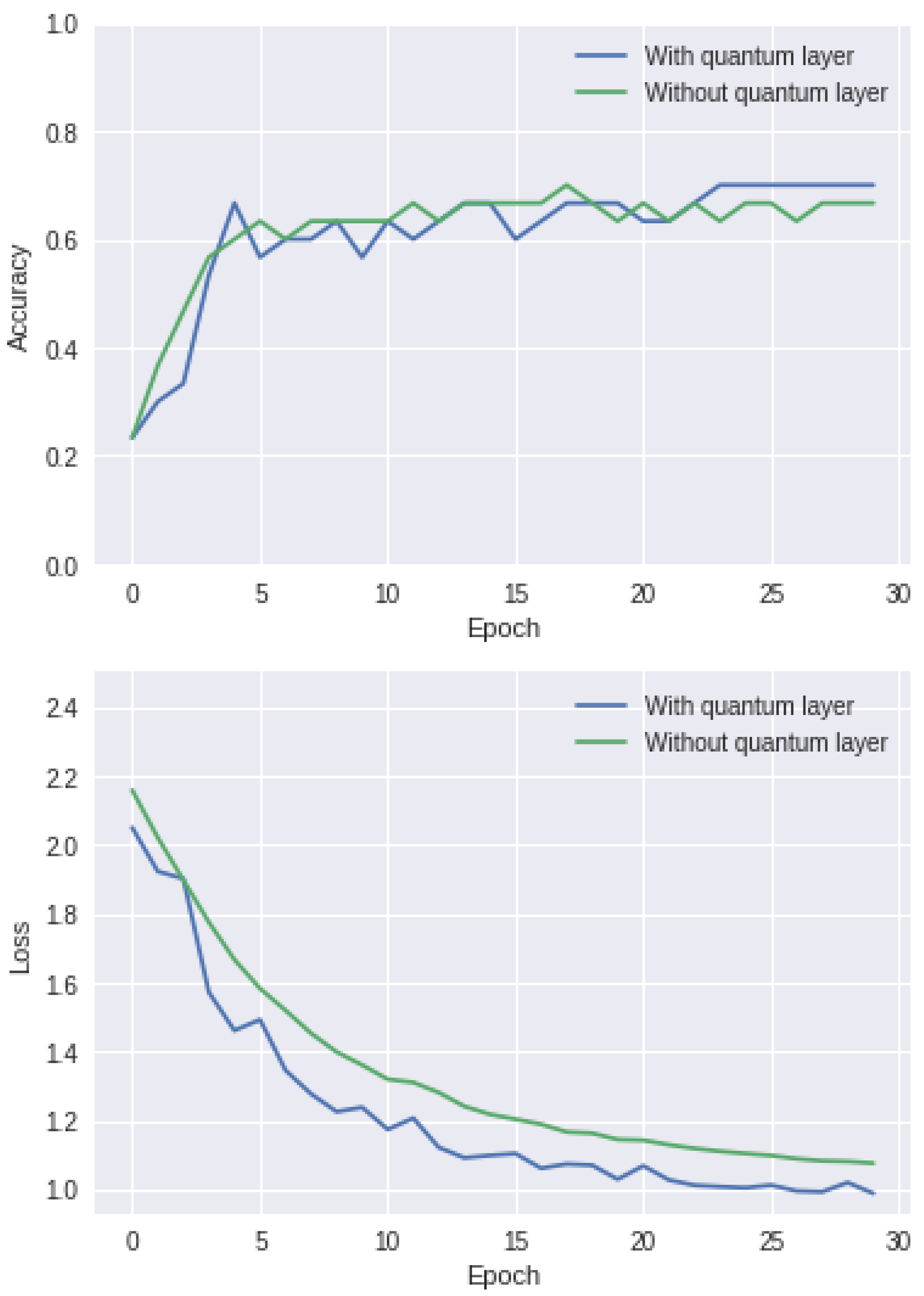
4.3.2. Results
5. General Discussion
6. Conclusions and Perspectives
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Grover, L.K. Quantum Mechanics Helps in Searching for a Needle in a Haystack. Phys. Rev. Lett. 1997, 79, 325–328. [Google Scholar] [CrossRef]
- Shor, P.W. Algorithms for Quantum Computation: Discrete Logarithms and Factoring. In Proceedings of the 35th Annual Symposium on Foundation of Computer Science, Washington, DC, USA, 20–22 November 1994; pp. 124–134. [Google Scholar]
- Menneer, T.; Narayanan, A. Quantum-inspired neural networks. In Proceedings of the Neural Information Processing Systems 95, Denver, CO, USA, 27–30 November 1995. [Google Scholar]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum Support Vector Machine for Big Data Classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef] [PubMed]
- Harrow, A.W.; Hassidim, A.; Lloyd, S. Quantum Algorithm for Linear Systems of Equations. Phys. Rev. Lett. 2009, 103, 150502. [Google Scholar] [CrossRef] [PubMed]
- Wiebe, N.; Kapoor, A.; Svore, K. Quantum algorithms for nearest-neighbor methods for supervised and unsupervised learning. arXiv 2014, arXiv:1401.2142. [Google Scholar] [CrossRef]
- Dang, Y.; Jiang, N.; Hu, H.; Ji, Z.; Zhang, W. Image classification based on quantum K-Nearest-Neighbor algorithm. Quantum Inf. Process. 2018, 17, 1–18. [Google Scholar] [CrossRef]
- Schuld, M.; Sinayskiy, I.; Petruccione, F. Prediction by linear regression on a quantum computer. Phys. Rev. A 2016, 94, 022342. [Google Scholar] [CrossRef]
- Lu, S.; Braunstein, S.L. Quantum decision tree classifier. Quantum Inf. Process. 2014, 13, 757–770. [Google Scholar] [CrossRef]
- Lloyd, S.; Mohseni, M.; Rebentrost, P. Quantum algorithms for supervised and unsupervised machine learning. arXiv 2013, arXiv:1307.0411. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Kerenidis, I.; Landman, J.; Luongo, A.; Prakash, A. q-means: A quantum algorithm for unsupervised machine learning. arXiv 2018, arXiv:1812.03584. [Google Scholar]
- Aïmeur, E.; Brassard, G.; Gambs, S. Quantum speed-up for unsupervised learning. Mach. Learn. 2013, 90, 261–287. [Google Scholar] [CrossRef]
- Lloyd, S.; Mohseni, M.; Rebentrost, P. Quantum principal component analysis. Nat. Phys. 2014, 10, 631–633. [Google Scholar] [CrossRef]
- Dong, D.; Chen, C.; Li, H.; Tarn, T.-J. Quantum Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2008, 38, 1207–1220. [Google Scholar] [CrossRef]
- Ronagh, P. Quantum algorithms for solving dynamic programming problems. arXiv 2019, arXiv:1906.02229. [Google Scholar]
- McKiernan, K.A.; Davis, E.; Alam, M.S.; Rigetti, C. Automated quantum programming via reinforcement learning for combinatorial optimization. arXiv 2019, arXiv:1908.08054. [Google Scholar]
- Lloyd, S.; Weedbrook, C. Quantum Generative Adversarial Learning. Phys. Rev. Lett. 2018, 121, 040502. [Google Scholar] [CrossRef]
- Dallaire-Demers, P.-L.; Killoran, N. Quantum generative adversarial networks. Phys. Rev. A 2018, 98, 012324. [Google Scholar] [CrossRef]
- Situ, H.; He, Z.; Wang, Y.; Li, L.; Zheng, S. Quantum generative adversarial network for generating discrete distribution. Inf. Sci. 2020, 538, 193–208. [Google Scholar] [CrossRef]
- Huang, H.-L.; Du, Y.; Gong, M.; Zhao, Y.; Wu, Y.; Wang, C.; Li, S.; Liang, F.; Lin, J.; Xu, Y.; et al. Experimental Quantum Generative Adversarial Networks for Image Generation. Phys. Rev. Appl. 2021, 16, 024051. [Google Scholar] [CrossRef]
- Chakrabarti, S.; Yiming, H.; Li, T.; Feizi, S.; Wu, X. Quantum Wasserstein generative adversarial networks. arXiv 2019, arXiv:1911.00111. [Google Scholar]
- Kieferová, M.; Wiebe, N. Tomography and generative training with quantum Boltzmann machines. Phys. Rev. A 2017, 96, 062327. [Google Scholar] [CrossRef]
- Amin, M.H.; Andriyash, E.; Rolfe, J.; Kulchytskyy, B.; Melko, R. Quantum Boltzmann Machine. Phys. Rev. X 2018, 8, 021050. [Google Scholar] [CrossRef]
- Romero, J.; Olson, J.P.; Aspuru-Guzik, A. Quantum autoencoders for efficient compression of quantum data. Quantum Sci. Technol. 2017, 2, 045001. [Google Scholar] [CrossRef]
- Khoshaman, A.; Vinci, W.; Denis, B.; Andriyash, E.; Sadeghi, H.; Amin, M.H. Quantum variational autoencoder. Quantum Sci. Technol. 2018, 4, 014001. [Google Scholar] [CrossRef]
- Cong, I.; Choi, S.; Lukin, M.D. Quantum convolutional neural networks. Nat. Phys. 2019, 15, 1273–1278. [Google Scholar] [CrossRef]
- Kerenidis, I.; Landman, J.; Prakash, A. Quantum algorithms for deep convolutional neural networks. arXiv 2019, arXiv:1911.01117. [Google Scholar]
- Henderson, M.; Shakya, S.; Pradhan, S.; Cook, T. Quanvolutional neural networks: Powering image recognition with quantum circuits. Quantum Mach. Intell. 2020, 2, 2. [Google Scholar] [CrossRef]
- Jiang, Z.; Rieffel, E.G.; Wang, Z. Near-optimal quantum circuit for Grover’s unstructured search using a transverse field. Phys. Rev. A 2017, 95, 062317. [Google Scholar] [CrossRef]
- Farhi, E.; Goldstone, J.; Gutmann, S. A quantum approximate optimization algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar]
- Kerenidis, I.; Prakash, A. Quantum gradient descent for linear systems and least squares. Phys. Rev. A 2020, 101, 022316. [Google Scholar] [CrossRef]
- Schumacher, B. Quantum coding. Phys. Rev. A 1995, 51, 2738. [Google Scholar] [CrossRef] [PubMed]
- Barenco, A.; Bennett, C.H.; Cleve, R.; DiVincenzo, D.P.; Margolus, N.; Shor, P.; Sleator, T.; Smolin, J.A.; Weinfurter, H. Elementary gates for quantum computation. Phys. Rev. A 1995, 52, 3457–3467. [Google Scholar] [CrossRef] [PubMed]
- Toffoli, T. Reversible computing. In International Colloquium on Automata, Languages, and Programming; Springer: Berlin/Heidelberg, Germany, 1980; pp. 632–644. [Google Scholar]
- Fredkin, E.; Toffoli, T. Conservative logic. Int. J. Theor. Phys. 1982, 21, 219–253. [Google Scholar] [CrossRef]
- Kockum, A.K. Quantum Optics with Artificial Atoms; Chalmers University of Technology: Gothenburg, Sweden, 2014. [Google Scholar]
- Nielsen, M.A.; Chuang, I.; Grover, L.K. Quantum Computation and Quantum Information. Am. J. Phys. 2002, 70, 558–559. [Google Scholar] [CrossRef]
- Deutsch, D.; Jozsa, R. Rapid solution of problems by quantum computation. Proc. R. Soc. Lond. Ser. Math. Phys. Sci. 1992, 439, 553–558. [Google Scholar] [CrossRef]
- Coppersmith, D. An approximate Fourier transform useful in quantum factoring. arXiv 2002, arXiv:quant-ph/0201067. [Google Scholar]
- Xu, N.; Zhu, J.; Lu, D.; Zhou, X.; Peng, X.; Du, J. Quantum Factorization of 143 on a Dipolar-Coupling Nuclear Magnetic Resonance System. Phys. Rev. Lett. 2012, 108, 130501. [Google Scholar] [CrossRef]
- Dridi, R.; Alghassi, H. Prime factorization using quantum annealing and computational algebraic geometry. Sci. Rep. 2017, 7, 1–10. [Google Scholar]
- Crane, L. Quantum computer sets new record for finding prime number factors. New Scientist, 13 December 2019. [Google Scholar]
- David, H. “RSA in a “Pre-Post-Quantum” Computing World”. Available online: https://www.f5.com/labs/articles/threat-intelligence/rsa-in-a-pre-post-quantum-computing-world (accessed on 20 April 2022).
- Aggarwal, D.; Brennen, G.K.; Lee, T.; Santha, M.; Tomamichel, M. Quantum attacks on Bitcoin, and how to protect against them. arXiv 2017, arXiv:1710.10377. [Google Scholar] [CrossRef]
- Peruzzo, A.; McClean, J.; Shadbolt, P.; Yung, M.-H.; Zhou, X.-Q.; Love, P.J.; Aspuru-Guzik, A.; O’Brien, J.L. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 2014, 5, 4213. [Google Scholar] [CrossRef]
- Wikipedia. Quantum Machine Learning. Last Modified 6 June 2021. 2021. Available online: https://en.wikipedia.org/w/index.php?title=Quantum_machine_learning&oldid=1055622615 (accessed on 20 April 2022).
- Stoudenmire, E.; Schwab, D.J. Supervised learning with quantum-inspired tensor networks. arXiv 2016, arXiv:1605.05775. [Google Scholar]
- Aaronson, S. The learnability of quantum states. Proc. R. Soc. A Math. Phys. Eng. Sci. 2007, 463, 3089–3114. [Google Scholar] [CrossRef]
- Sasaki, M.; Carlini, A. Quantum learning and universal quantum matching machine. Phys. Rev. A 2002, 66, 022303. [Google Scholar] [CrossRef]
- Bisio, A.; Chiribella, G.; D’Ariano, G.M.; Facchini, S.; Perinotti, P. Optimal quantum learning of a unitary transformation. Phys. Rev. A 2010, 81, 032324. [Google Scholar] [CrossRef]
- da Silva, A.J.; Ludermir, T.B.; de Oliveira, W.R. Quantum perceptron over a field and neural network architecture selection in a quantum computer. Neural Netw. 2016, 76, 55–64. [Google Scholar] [CrossRef]
- Tiwari, P.; Melucci, M. Towards a Quantum-Inspired Binary Classifier. IEEE Access 2019, 7, 42354–42372. [Google Scholar] [CrossRef]
- Sergioli, G.; Giuntini, R.; Freytes, H. A new quantum approach to binary classification. PLoS ONE 2019, 14, e0216224. [Google Scholar] [CrossRef]
- Ding, C.; Bao, T.Y.; Huang, H.L. Quantum-inspired support vector machine. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7210–7222. [Google Scholar] [CrossRef]
- Sergioli, G.; Russo, G.; Santucci, E.; Stefano, A.; Torrisi, S.E.; Palmucci, S.; Vancheri, C.; Giuntini, R. Quantum-inspired minimum distance classification in a biomedical context. Int. J. Quantum Inf. 2018, 16, 18400117. [Google Scholar] [CrossRef]
- Chen, H.; Gao, Y.; Zhang, J. Quantum k-nearest neighbor algorithm. Dongnan Daxue Xuebao 2015, 45, 647–651. [Google Scholar]
- Yu, C.H.; Gao, F.; Wen, Q.Y. An improved quantum algorithm for ridge regression. IEEE Trans. Knowl. Data Eng. 2019, 33, 858–866. [Google Scholar] [CrossRef]
- Sagheer, A.; Zidan, M.; Abdelsamea, M.M. A Novel Autonomous Perceptron Model for Pattern Classification Applications. Entropy 2019, 21, 763. [Google Scholar] [CrossRef] [PubMed]
- Adhikary, S.; Dangwal, S.; Bhowmik, D. Supervised learning with a quantum classifier using multi-level systems. Quantum Inf. Process. 2020, 19, 89. [Google Scholar] [CrossRef]
- Havlíček, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef]
- Ruan, Y.; Xue, X.; Liu, H.; Tan, J.; Li, X. Quantum Algorithm for K-Nearest Neighbors Classification Based on the Metric of Hamming Distance. Int. J. Theor. Phys. 2017, 56, 3496–3507. [Google Scholar] [CrossRef]
- Zhang, D.B.; Zhu, S.L.; Wang, Z.D. Nonlinear regression based on a hybrid quantum computer. arXiv 2018, arXiv:1808.09607. [Google Scholar]
- Cortese, J.A.; Braje, T.M. Loading classical data into a quantum computer. arXiv 2018, arXiv:1803.01958. [Google Scholar]
- Schuld, M.; Killoran, N. Quantum Machine Learning in Feature Hilbert Spaces. Phys. Rev. Lett. 2019, 122, 040504. [Google Scholar] [CrossRef]
- Schuld, M.; Petruccione, F. Supervised Learning with Quantum Computers; Springer: Berlin/Heidelberg, Germany, 2018; Volume 17. [Google Scholar]
- Wikipedia. Amplitude Amplification. Last Modified 5 April 2021. 2021. Available online: https://en.wikipedia.org/w/index.php?title=Amplitude_amplification&oldid=1021327631 (accessed on 24 June 2022).
- Cerezo, M.; Arrasmith, A.; Babbush, R.; Benjamin, S.C.; Endo, S.; Fujii, K.; McClean, J.R.; Mitarai, K.; Yuan, X.; Cincio, L.; et al. Variational quantum algorithms. Nat. Rev. Phys. 2021, 3, 625–644. [Google Scholar] [CrossRef]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef]
- Coyle, B.; Mills, D.; Danos, V.; Kashefi, E. The Born supremacy: Quantum advantage and training of an Ising Born machine. NPJ Quantum Inf. 2020, 6, 60. [Google Scholar] [CrossRef]
- Biamonte, J. Universal variational quantum computation. Phys. Rev. A 2021, 103, L030401. [Google Scholar] [CrossRef]
- Abbas, A.; Sutter, D.; Zoufal, C.; Lucchi, A.; Figalli, A.; Woerner, S. The power of quantum neural networks. Nat. Comput. Sci. 2021, 1, 403–409. [Google Scholar] [CrossRef]
- Mitarai, K.; Negoro, M.; Kitagawa, M.; Fujii, K. Quantum circuit learning. Phys. Rev. A 2018, 98, 032309. [Google Scholar] [CrossRef]
- Bishwas, A.K.; Mani, A.; Palade, V. An all-pair quantum SVM approach for big data multiclass classification. Quantum Inf. Process. 2018, 17, 282. [Google Scholar] [CrossRef]
- Wiebe, N.; Braun, D.; Lloyd, S. Quantum Algorithm for Data Fitting. Phys. Rev. Lett. 2012, 109, 050505. [Google Scholar] [CrossRef]
- Kapoor, A.; Wiebe, N.; Svore, K. Quantum perceptron models. arXiv 2016, arXiv:1602.04799. [Google Scholar]
- Schuld, M.; Bocharov, A.; Svore, K.M.; Wiebe, N. Circuit-centric quantum classifiers. Phys. Rev. A 2020, 101, 032308. [Google Scholar] [CrossRef]
- Chen, S.Y.-C.; Yang, C.-H.H.; Qi, J.; Chen, P.-Y.; Ma, X.; Goan, H.-S. Variational Quantum Circuits for Deep Reinforcement Learning. IEEE Access 2020, 8, 141007–141024. [Google Scholar] [CrossRef]
- Anguita, D.; Ridella, S.; Rivieccio, F.; Zunino, R. Quantum optimization for training support vector machines. Neural Netw. 2003, 16, 763–770. [Google Scholar] [CrossRef]
- Bergholm, V.; Izaac, J.; Schuld, M.; Gogolin, C.; Alam, M.S.; Ahmed, S.; Arrazola, J.M.; Blank, C.; Delgado, A.; Jahangiri, S.; et al. Pennylane: Automatic differentiation of hybrid quantum-classical computations. arXiv 2018, arXiv:1811.04968. [Google Scholar]
- Aleksandrowicz, G.; Alexander, T.; Barkoutsos, P.; Bello, L.; Ben-Haim, Y.; Bucher, D.; Cabrera-Hernández, F.J.; Carballo-Franquis, J.; Chen, A.; Chen, C.F.; et al. Qiskit: An Open-Source Framework for Quantum Computing. 2019. Available online: https://zenodo.org/record/2562111 (accessed on 26 June 2022).
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Before Applying CNOT | After Applying CNOT | ||
|---|---|---|---|
| Controlled | Targeted | Controlled | Targeted |
| Input | H | CNOT |
|---|---|---|
| Quantum Routines | QML Applications |
|---|---|
| HHL algorithm | QSVM [4,74] |
| Q linear regression [8] | |
| Q least squares [75] | |
| QPCA [14] | |
| Grover’s algorithm | Q k-Means [10] |
| Q K-Median [13] | |
| QKNN [6] | |
| Q Perceptron Models [76] | |
| Q Neural Networks [3] | |
| Quantum phase estimation | Q k-Means [10] |
| Variational quantum circuit | Q decision tree [9] |
| Circuit-centric quantum | |
| classifiers [77] | |
| Deep reinforcement | |
| learning [78] |
| Metric | VQC | SVC | Decision Tree | Naive Bayes |
|---|---|---|---|---|
| Accuracy | 1 | 0.96 | 0.96 | 0.96 |
| Cost | 0.2351166 | 0.0873071 | 0.0906691 | 1.381551 |
| Algorithm | Loss Function | Test Accuracy |
|---|---|---|
| CNN | 1.0757 | 0.6667 |
| QNN | 0.9882 | 0.7000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeguendry, A.; Jarir, Z.; Quafafou, M. Quantum Machine Learning: A Review and Case Studies. Entropy 2023, 25, 287. https://doi.org/10.3390/e25020287
Zeguendry A, Jarir Z, Quafafou M. Quantum Machine Learning: A Review and Case Studies. Entropy. 2023; 25(2):287. https://doi.org/10.3390/e25020287
Chicago/Turabian StyleZeguendry, Amine, Zahi Jarir, and Mohamed Quafafou. 2023. "Quantum Machine Learning: A Review and Case Studies" Entropy 25, no. 2: 287. https://doi.org/10.3390/e25020287
APA StyleZeguendry, A., Jarir, Z., & Quafafou, M. (2023). Quantum Machine Learning: A Review and Case Studies. Entropy, 25(2), 287. https://doi.org/10.3390/e25020287