1. Introduction
Soldering chip components to PCB is an important part of printed circuit board assembly (PCBA) production [
1]. Various defects occur during the soldering process of chip components [
2,
3]. The most common defects include missing components, excessive solder, insufficient solder, solder skips, misalignment, tombstoning, component damage, etc.
From all these representative defects shown in
Figure 1, we can see that most of the defects (e.g., excessive solder, solder skips) are directly related to the solder joints and some (e.g., missing components, component damage) are not directly related to the solder joints, but they all bring some changes to the solder joints. Hence, we can detect most of the defects in the soldering process of chip components by detecting the solder joint defects. For ease of understanding, abnormal solder joint images are collectively referred to as NG images, and the normal ones are called OK images in the following parts of the paper.
Automated optical inspection (AOI) is an advanced visual detection method for PCBAs. It uses optical cameras to scan PCBAs and detects two types of failures: catastrophic failures (missing components) and quality failures (misshapen fillet or skewed components). However, due to the diversity of defect shapes, forms, and features, AOI alone cannot meet the high-precision requirements for defect detection [
4]. In addition, the inspection scenarios for chip components are also complicated [
5]. For example, the bending of the PCB may displace components from their original positions; blurred images or smeared surfaces of chip components can also produce false or missing positives. To solve these issues, artificial reinspection has to be involved in the production line, despite it decreasing the inspection efficiency and increasing the labor costs.
Deep learning is one of the prominent developments in artificial intelligence (AI) [
6,
7,
8,
9,
10]. It has been successfully applied in various fields, such as classification, object detection, signal diagnosis, and instance segmentation [
11,
12,
13,
14,
15,
16]. Many deep-learning methods have been used to improve the detection accuracy of AOI for chip solder defects. Some of the methods are based on supervised learning. Cai et al. [
17] used a convolutional neural network cascade to inspect solder joint defects. Hao et al. [
18] used an improved Mask-RCNN to segment and classify chip soldering defects in parallel branches. Fan et al. [
19] proposed an improved Faster R-CNN for PCBA solder joint defects, and components detection with a mean average precision close to 0.99. The supervised methods rely heavily on a large number of NG samples to obtain high generalization capability, but the amount and type of NG data obtained in practical production are often insufficient. Therefore, supervised methods are usually very limited in practical applications. There are many unsupervised-based studies for defect detection, which show a promising increased performance compared with conventional methods. S. Park et al. [
20] proposed a residual-based auto-encoder for the defect detection of micro-LEDs (chip components) and achieved an accuracy of 95.82% on 5143 micro-LED images. Wang et al. [
21] achieved an accuracy of 92.7% on 7233 solder joint images by using a generative adversarial network (GAN) [
22]. F. Ulger et al. [
23] proposed a new beta-variational auto-encoder (beta-VAE) architecture for the detection of solder joint defects.
Even though defect detection based on deep neural networks has been extensively explored and many related detection methods have been proposed, the detection of defects in chip solder joints is very rare. The main reasons for this situation are related to the following aspects:
1. Different components are different in internal design. It is difficult to design solder joint defect detection methods suitable for various scenarios.
2. Solder joints are the places where electronic components and PCBs are welded by hand or machine. Due to solder, time, temperature, and other factors, solder defects may take on different forms. The defective solder joint data are very few, and it is difficult to cover all types of defective solder joint data collected in the industry. Therefore, it is difficult for neural networks to extract key features that can distinguish defects from normal solder joints by using existing data.
3. As industrial detection has high requirements for accuracy and speed, many algorithms cannot meet the actual industrial requirements. Most solder joint defection still relies on machine learning and manual review, which increases human and economic costs.
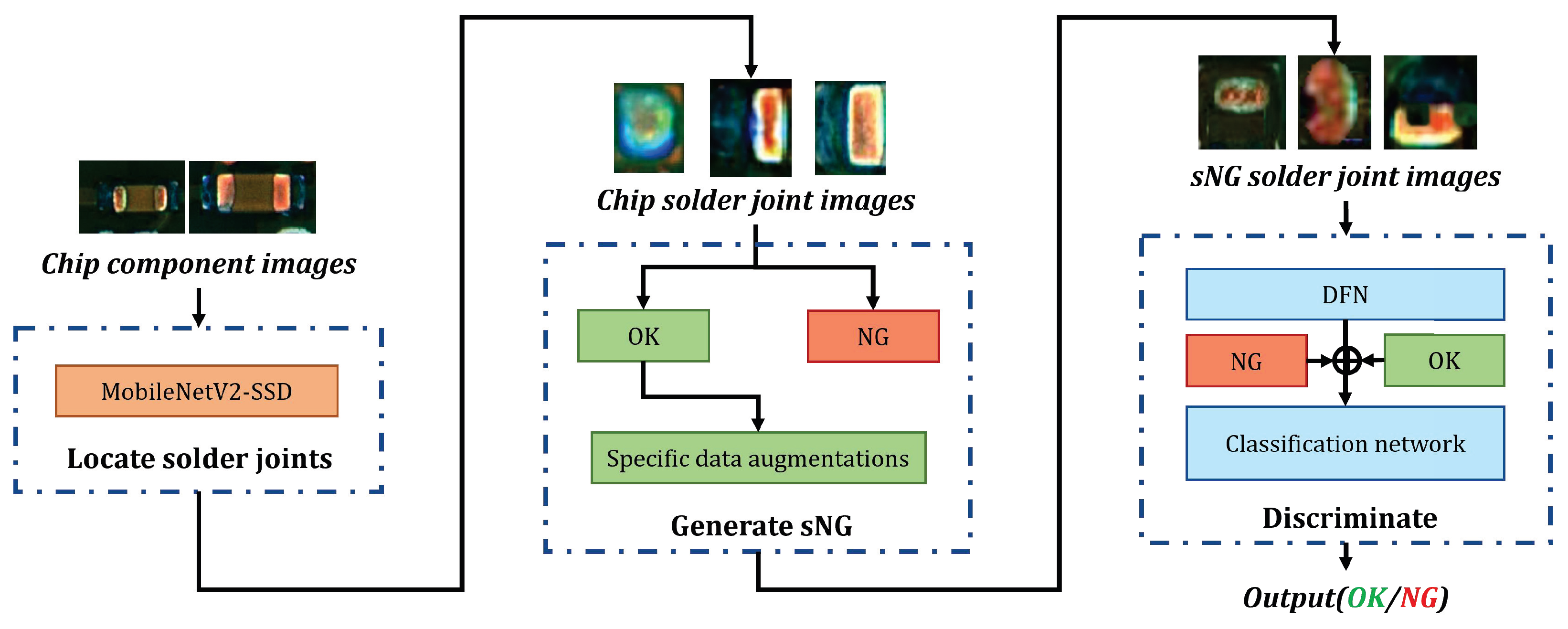
In this paper, we propose a method based on CSSL to achieve a high accuracy and high efficiency of detection for the solder joint defects of chip components. Our main contributions in this paper lie in three aspects:
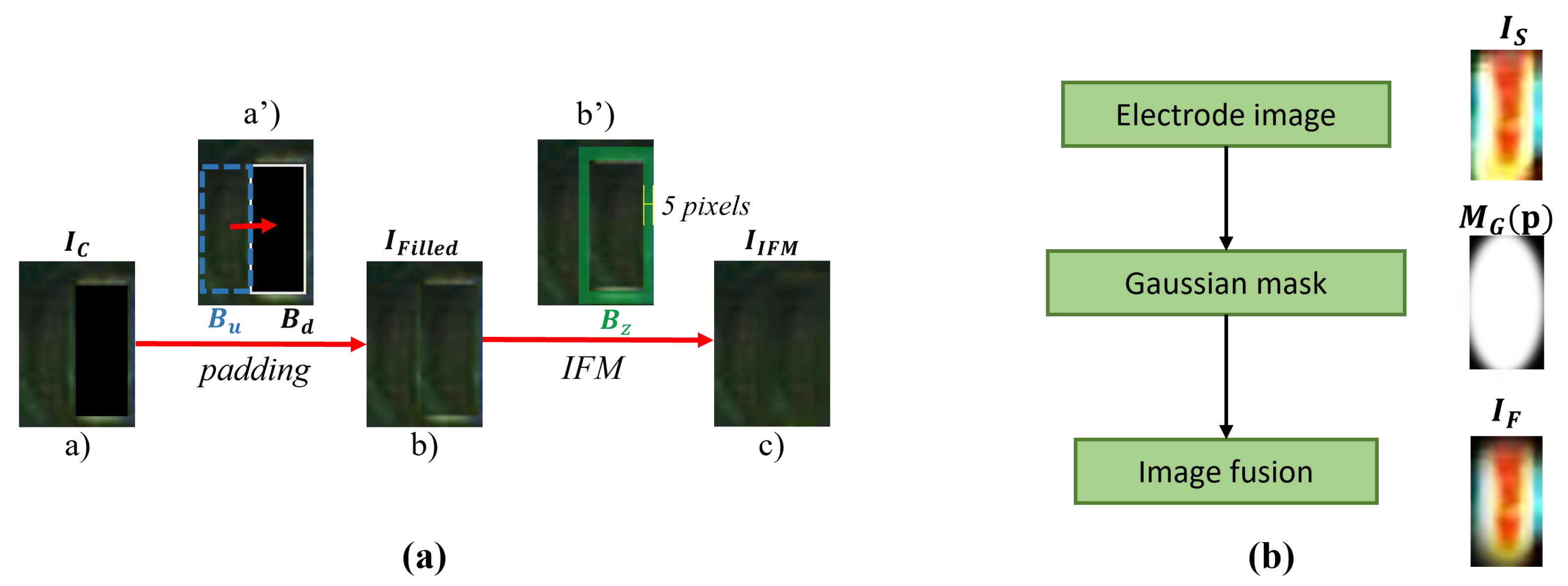
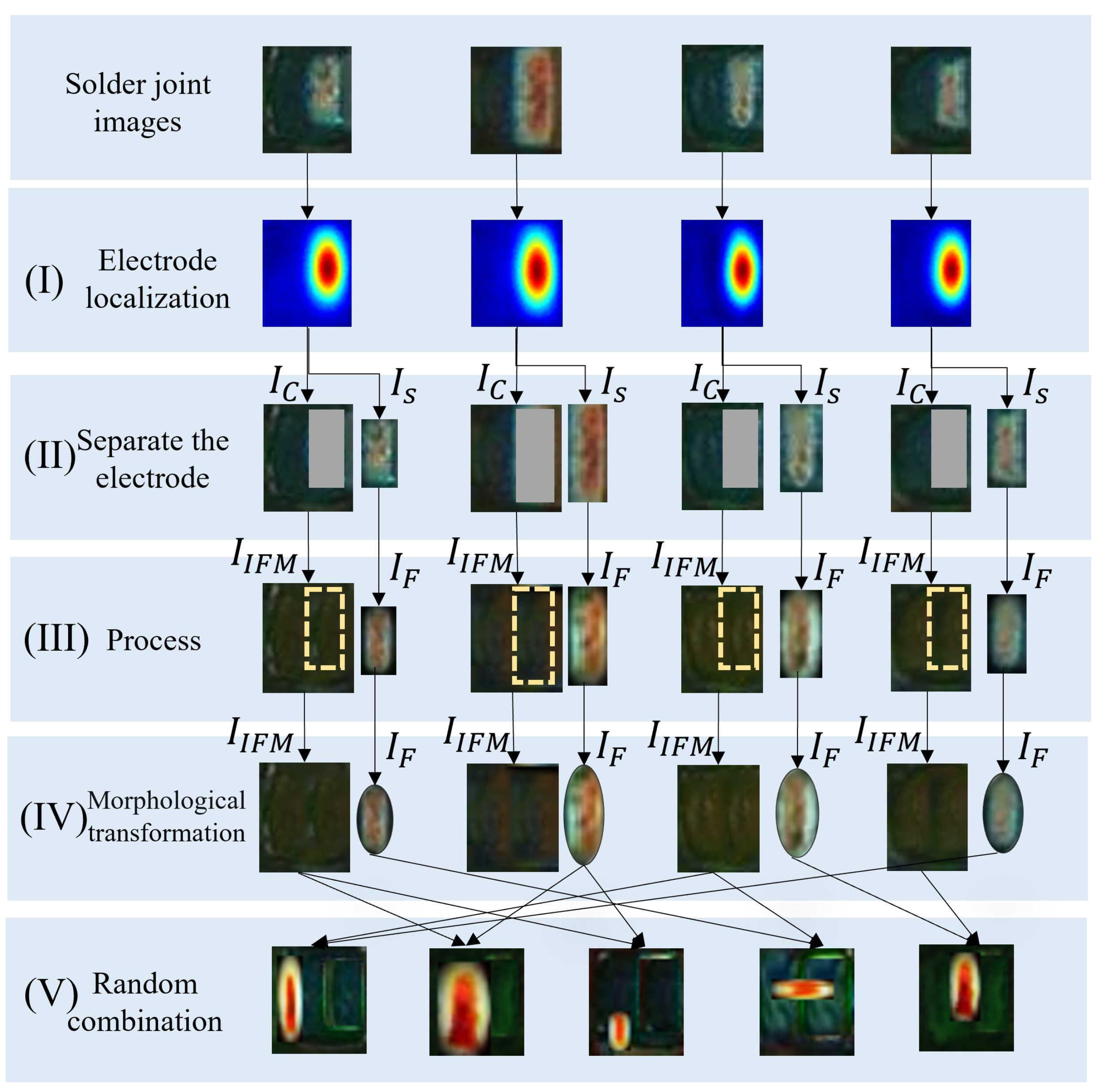
1. There are a few types of research on the detection of chip solder spot defects. This paper proposes a framework that can effectively detect chip solder joint defects. High-quality simulation defect data (sNG) are obtained by using data enhancement and contrastive self-supervised learning techniques. Moreover, the accuracy of detecting chip solder spot defects is improved.
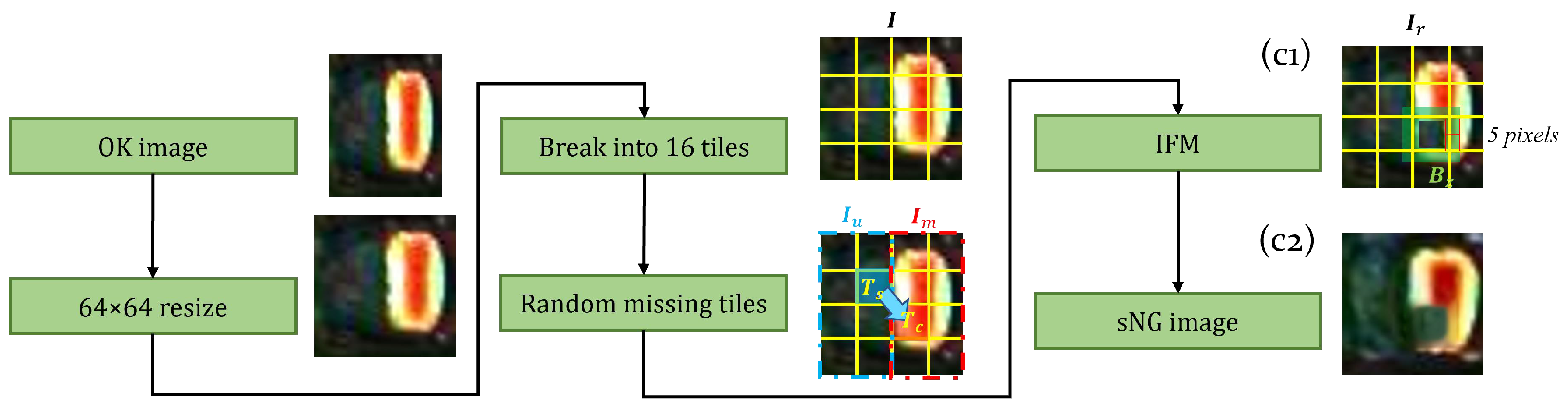
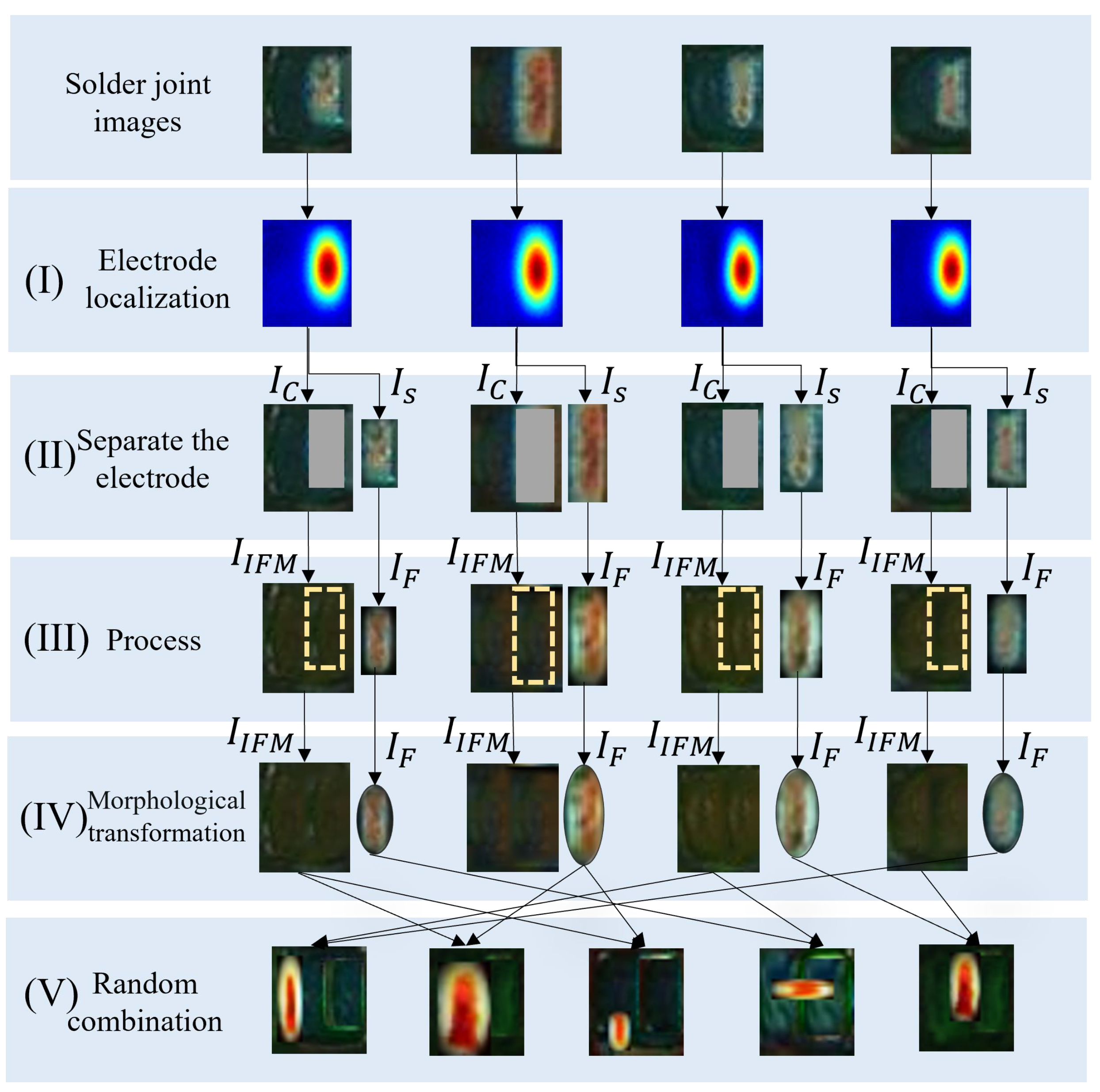
2. This paper proposes three customized enhancement methods for chip defect solder joint data. A large amount of sNG data can be obtained by using OK solder joint data to make up for the lack of NG solder joint data in many scenarios. At the same time, the specific data augmentation method combined with some prior experience can better help the classifier learn the key characteristics of solder joints, to better detect defective solder joints.
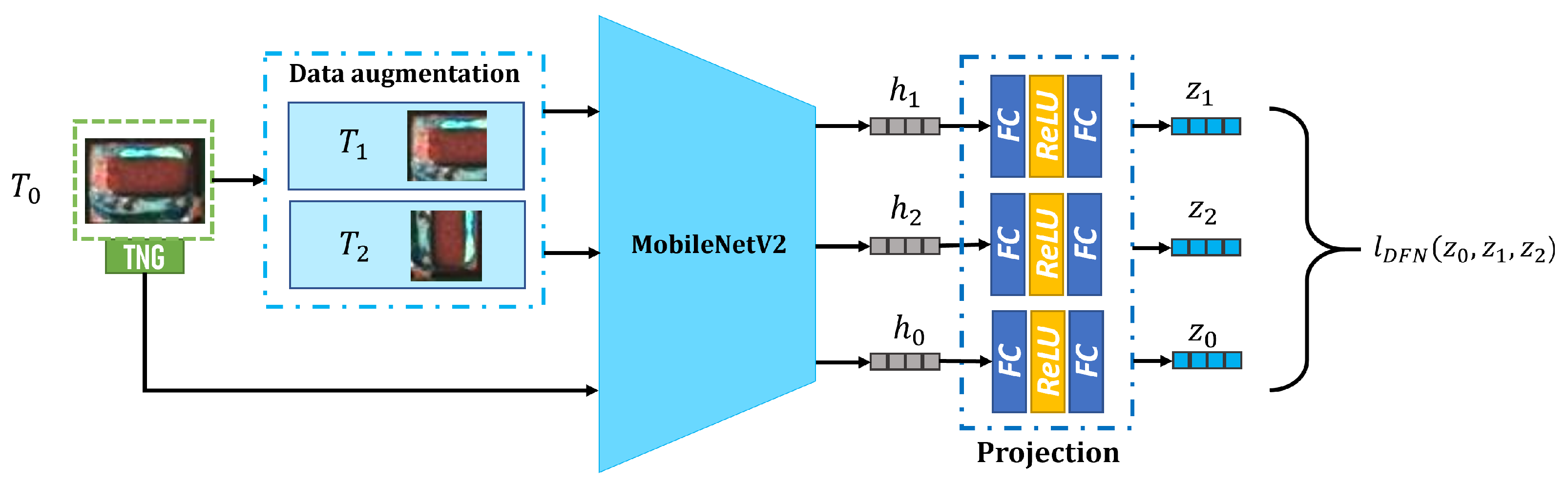
3. We designed a contrastive self-supervised learning NG solder joint data filtering network (DFN) that extracted high-quality sNG data from a large volume of sNG data, ensuring that the sNG data were more closely aligned with the NG data and maximizing the value of the sNG data.
The remainder of this paper is organized as follows: in
Section 2, the preliminaries of contrastive self-supervised learning are drawn; in
Section 3, three data augmentation methods, the DFN, and the CSSL framework are elaborated; in
Section 4, comparative experiments are conducted and results are given; in
Section 5, some related issues are discussed; finally, in
Section 6, the conclusion is drawn.
2. Preliminaries
In recent years, contrastive self-supervised learning (CSSL) has been one of the research hotspots in deep learning [
24,
25,
26]. The main advantage is its great ability to learn semantically rich representations from numerous unlabeled data. The process of CSSL can be divided into three steps:
(1) Constructing positive or negative samples;
(2) Training the model to learn the feature similarity of these samples in the pretext task;
(3) Fine-tuning the pre-trained model in the downstream task.
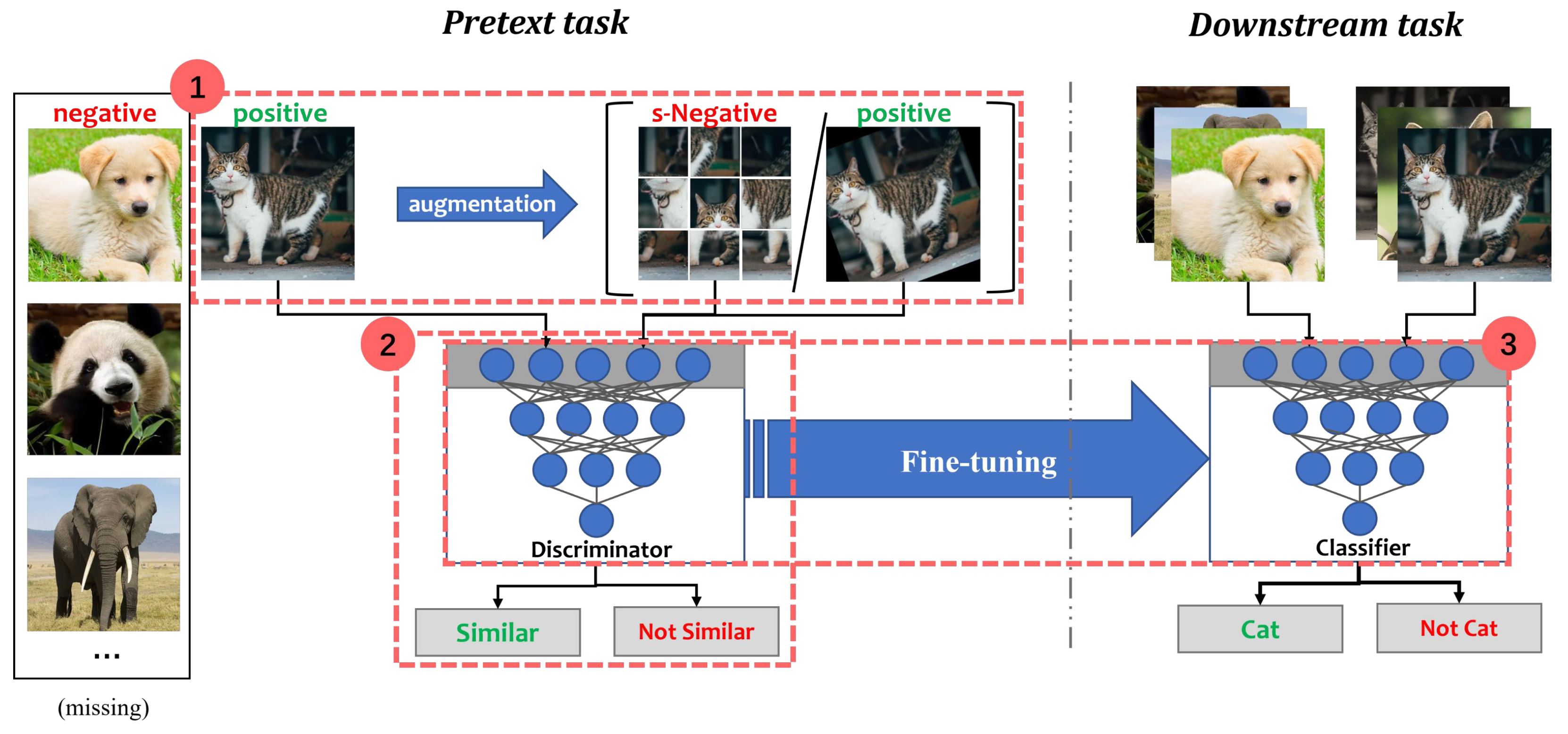
A dichotomous classification illustration of the CSSL process is shown in
Figure 2. In the Animals dataset, “cat” is the positive class while “not-cat” is the negative class. Assuming that negative samples are missing or very few, synthetic negative samples (s-Negative) and positive samples can be generated by some data augmentation methods. For example, s-Negative samples are created by shuffling tiles from “cat”. Positive samples are obtained by randomly rotating “cat”. The discriminator is a feature extraction network, consisting of convolutional and non-linear layers. It is used to distinguish whether the transformed data are similar to “cat”. The aim of the discriminator is to pull together semantically similar (positive) samples and push apart non-similar (negative) samples in a shared latent space. After the pretext task, the discriminator is placed on a new task for fine-tuning [
27].
2.1. The Pretext Task
The pretext task is a kind of self-supervised learning task that learns the data representation using pseudo-labels. Most of these pseudo-labels represent some form of transformation of the data. In the pretext task, the original image acts as an anchor, and its transformed version acts as a positive sample or a negative sample. In CSSL, the pretext task design is vital to the performance of the network on the downstream task. Many studies have made substantial contributions to the design of pretext tasks [
28,
29,
30,
31,
32]. He et al. [
33] proposed a momentum contrastive method (MoCo) using two distinct encoders (a primary encoder and a momentum encoder) with identical architectures. Chen et al. [
34] introduced a simple framework for the contrastive learning of visual representations (SimCLR), which consists of one encoder and a multi-layer perceptron (MLP) with one hidden layer. SimCLR creates pairs of transformed images to learn the similarity among them, thus maximizing the agreement between different augmentations of the same image. Many recent studies have also reported that data augmentation is important for contrastive learning [
35,
36]. In CSSL, the pretext task can improve the ability of networks to learn key features when using only “cat” data.
2.2. The Downstream Task
Downstream tasks are the actual tasks that need to be solved in CSSL. The pretext task is to use an imaginary task to strengthen the ability of the network to extract some features of data. To better evaluate this ability, pre-trained models from pretext tasks are generally used for fine-tuning to verify the downstream task. The fine-tuning process is as follows:
(1) The auxiliary task model trained by a large amount of unlabeled data is used as the pre-training.
(2) The weights of the feature extraction part of the pre-trained model are transferred to the downstream task model.
(3) The model is retrained on labeled data to obtain a model that could adapt to the new task.
The ability of self-supervised learning will also be reflected in the performance of the downstream task model.
4. Datasets and Experiments
In this section, comparative experiments were conducted to demonstrate the performance of the CSSL method based on the specifically augmented data and the proposed DFN model. The experiments were performed on a graphics station equipped with an Nvidia GTX 1080Ti GPU and 16 GB of RAM. The trained network was finally deployed on a computer with an Intel Core i5-7300HQ CPU with 8 GB of RAM memory in the production line for real-time detection.
4.1. Dataset Preparation
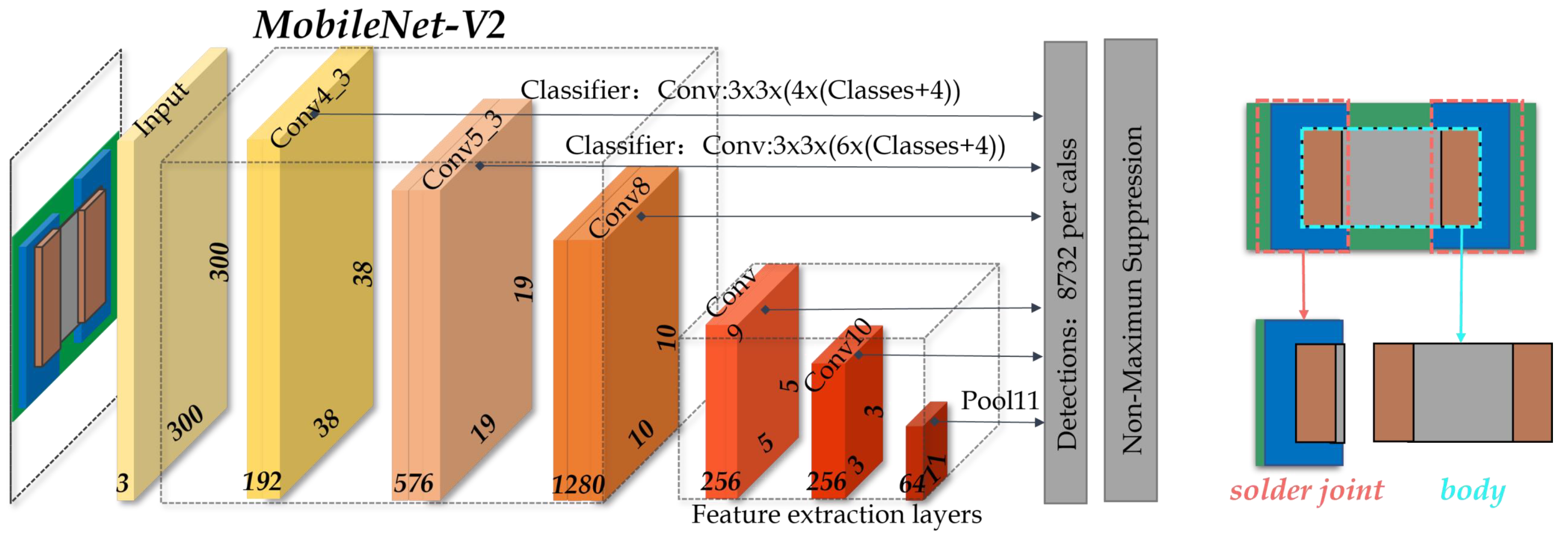
There were two sets of chip component data in this study from two electronic manufacturing companies, provided by Shenzhen MagicRay Technology Co., LTD. Based on these two sets of data, we used the MobileNetV2-SSD method to extract OK and NG data to establish two datasets, Chip-A and Chip-B. The details of the two datasets are shown in
Table 1.
(1) Chip-A consisted of 26,521 real solder joint images (23,224 OK images and 3297 NG images) and 21,372 sNG images. All real images were collected by professionals. The NG set consisted of 1031 images of excessive solder, 429 images of insufficient solder, 403 images of missing components, 634 images of component damage, and 800 images of misalignment. The sNG images were generated from OK images by the three specific augmentations. In the pretext tasks, 10,000 OK images and 10,000 sNG images were combined into the training set, and the test set contained 5000 OK images, 1037 NG images, and 5000 sNG images. In the downstream tasks, the training set contained 5244 OK images and 852 NG images, and the test set consisted of 3000 OK images and 1408 NG images. In the supervised learning, the training set consisted of 20,224 OK images and 1889 NG images, and the test set was the same as in the downstream tasks.
(2) Chip-B consisted of 20,512 real solder joint images (18,600 OK images and 1912 NG images) and 17,200 sNG images. In the pretext tasks, the training set consisted of 8000 OK images and 8000 sNG images, and the test set contained 4000 OK images, 592 NG images, and 4000 sNG images. In the downstream tasks, the training set consisted of 4000 OK images, 823 NG images, and 2600 sNG images. The test set contained 2600 OK images, 832 NG images, and 2600 sNG images. In the supervised learning, the training set consisted of 13,020 OK images and 1089 NG images, and the test set contained the same OK and NG images as in the downstream tasks.
4.2. Evaluation Metrics
To evaluate the performance of the proposed method, three metrics including precision (
P), recall (
R), and
F1-score (
F1) were used in this study. The confusion matrix is shown in
Table 2.
P,
R, and
are defined as follows:
4.3. Real Experiments
In this subsection, three experiments were conducted. Firstly, we performed a comparative experiment of supervised learning (SL) methods and SSL methods. Then, we performed an experiment to show the performance improvement of the CSSL method compared to the SSL method. Finally, we compared the CSSL method with the state-of-the-art defect detection methods.
4.3.1. Comparative Experiments of SL Methods and SSL Methods
To better demonstrate that SSL methods have better detection accuracy than SL methods when training data are insufficient, we introduced two classic classifiers, VGG16 [
43] and MobileNetV2. Based on these two classifiers, we built two supervised models named VGG16-SL and MobileNetV2-SL and two self-supervised models named VGG16-SSL and MobileNetV2-SSL. When training the SL models, the initial learning rate was set to 0.001, the Adam algorithm [
44] was used as the optimizer, and the loss function was categorical cross-entropy. Both SL models were trained for 2000 epochs. NG data were augmented by several common data augmentation methods, including rotation, flipping, and noise injection. When training the SSL models, the initial learning rate for the Adam optimizer was set to 0.001, and both SSL models were trained for 5000 epochs in the pretext tasks. After the pre-training was finished, the pre-trained models were transferred to the downstream tasks for fine-tuning, and the learning rate was 0.0002. For the sake of fairness, the common data augmentations applied to the NG data were also used for the sNG data.
The comparison results are shown in
Table 3. From the F1-scores in the table, we can see that VGG16-SSL outperforms VGG16-SL, and MobileNetV2-SSL outperforms MobileNetV2-SL. These two results are consistent, and they can demonstrate that SSL methods can achieve better defect detection accuracy than SL methods. It is worth noting that the amount of the NG data used to train the SSL models is much smaller than the amount of NG data to train the SL models. This demonstrates that SSL models are more suitable for the scenario of insufficient NG data than SL models. By comparing the values of all metrics in
Table 3, we can also see that MobileNetV2-SSL outperforms VGG16-SSL. To validate the performance in real applications, the fully trained VGG16-SSL and MobileNetV2-SSL were deployed in the production line. The parameter number and inference speed for both models are shown in
Table 4. It can be seen that MobileNetV2-SSL has fewer parameters and a faster inference speed than VGG16-SSL. Summarizing the above results, we can conclude that MobileNetV2 has better detection accuracy, better efficiency, and fewer parameters than VGG16; therefore, in the following comparative experiments, we use MobileNetV2 as the classifier of the CSSL Framework.
4.3.2. Validation of the CSSL Framework
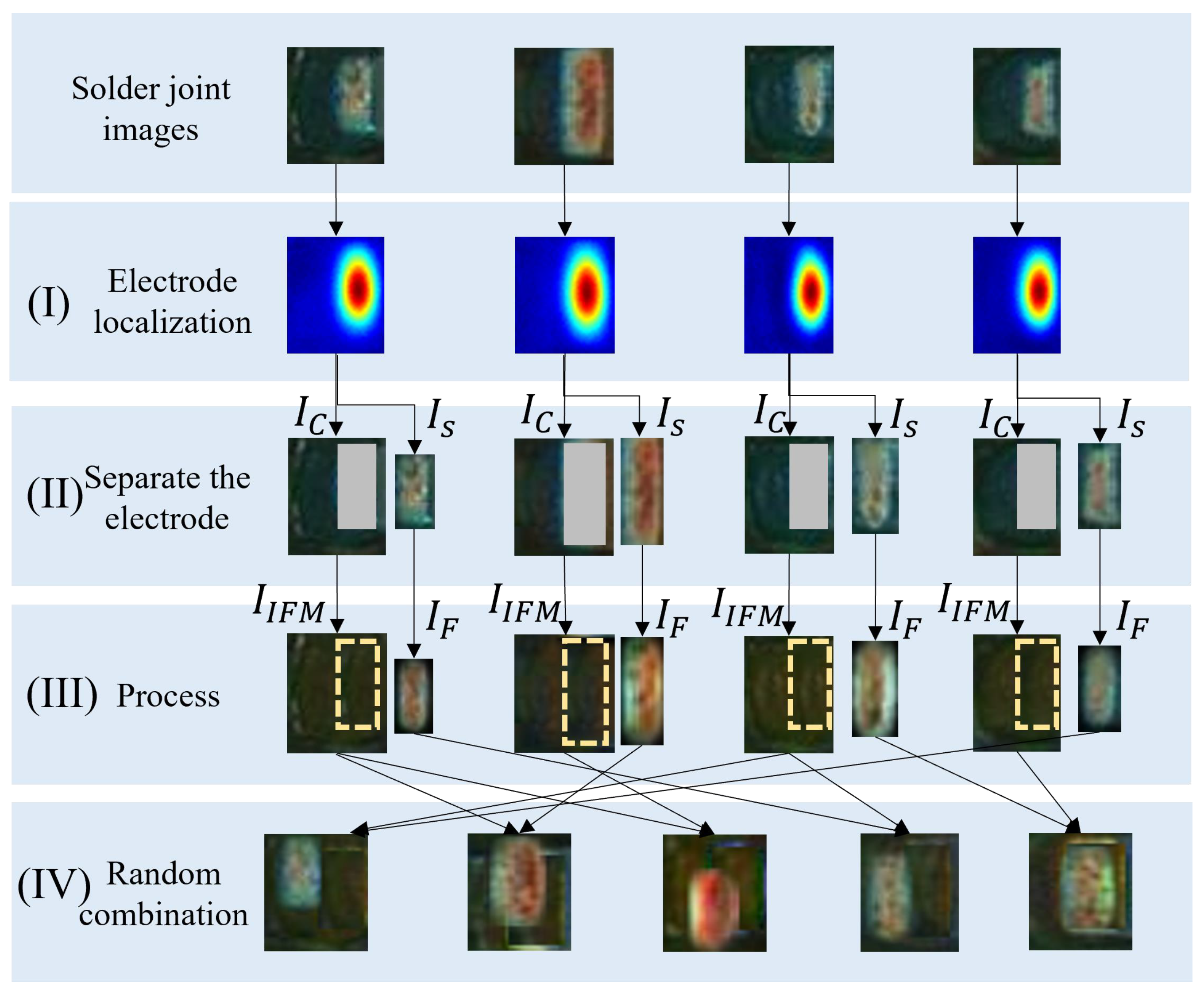
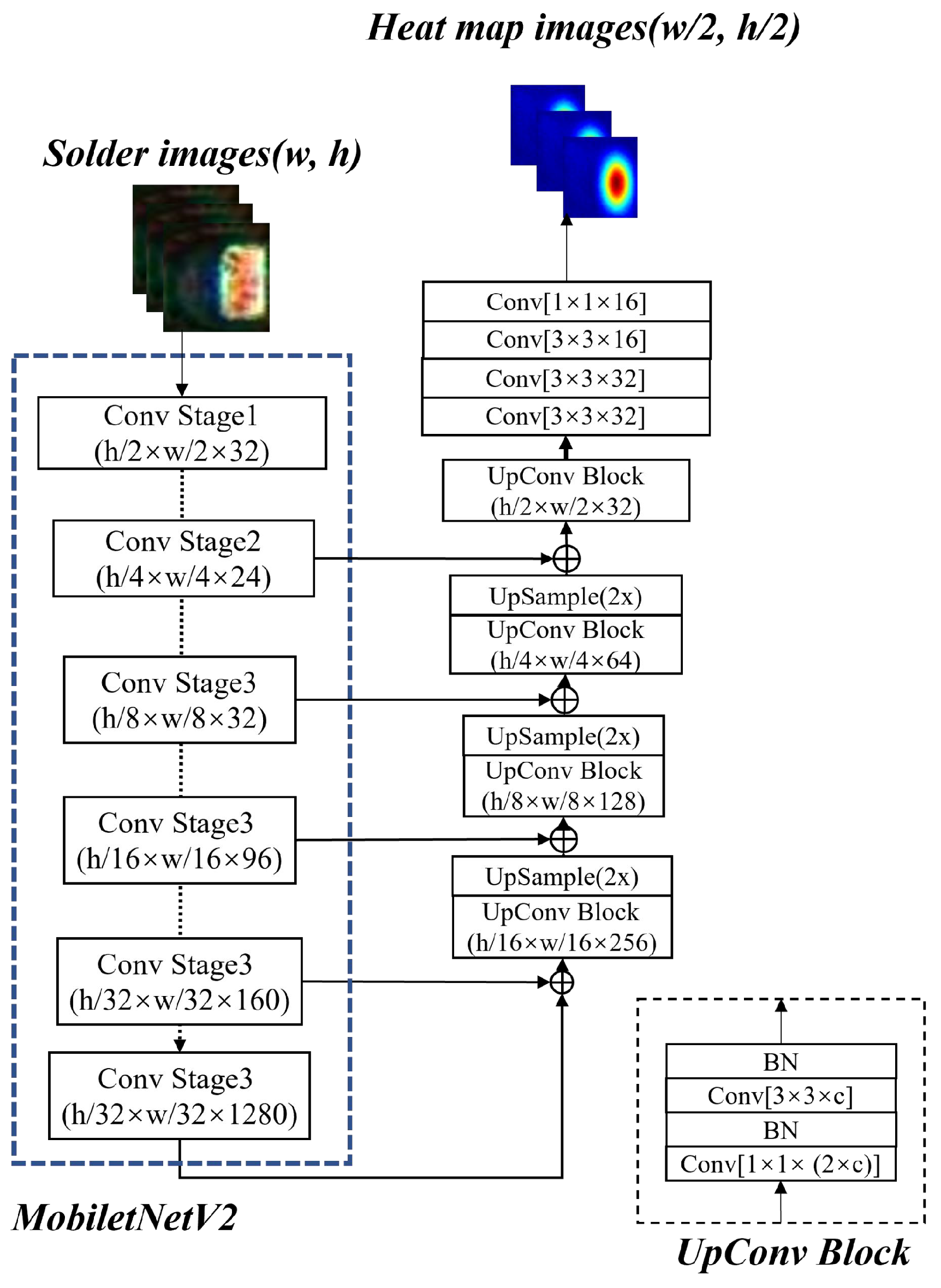
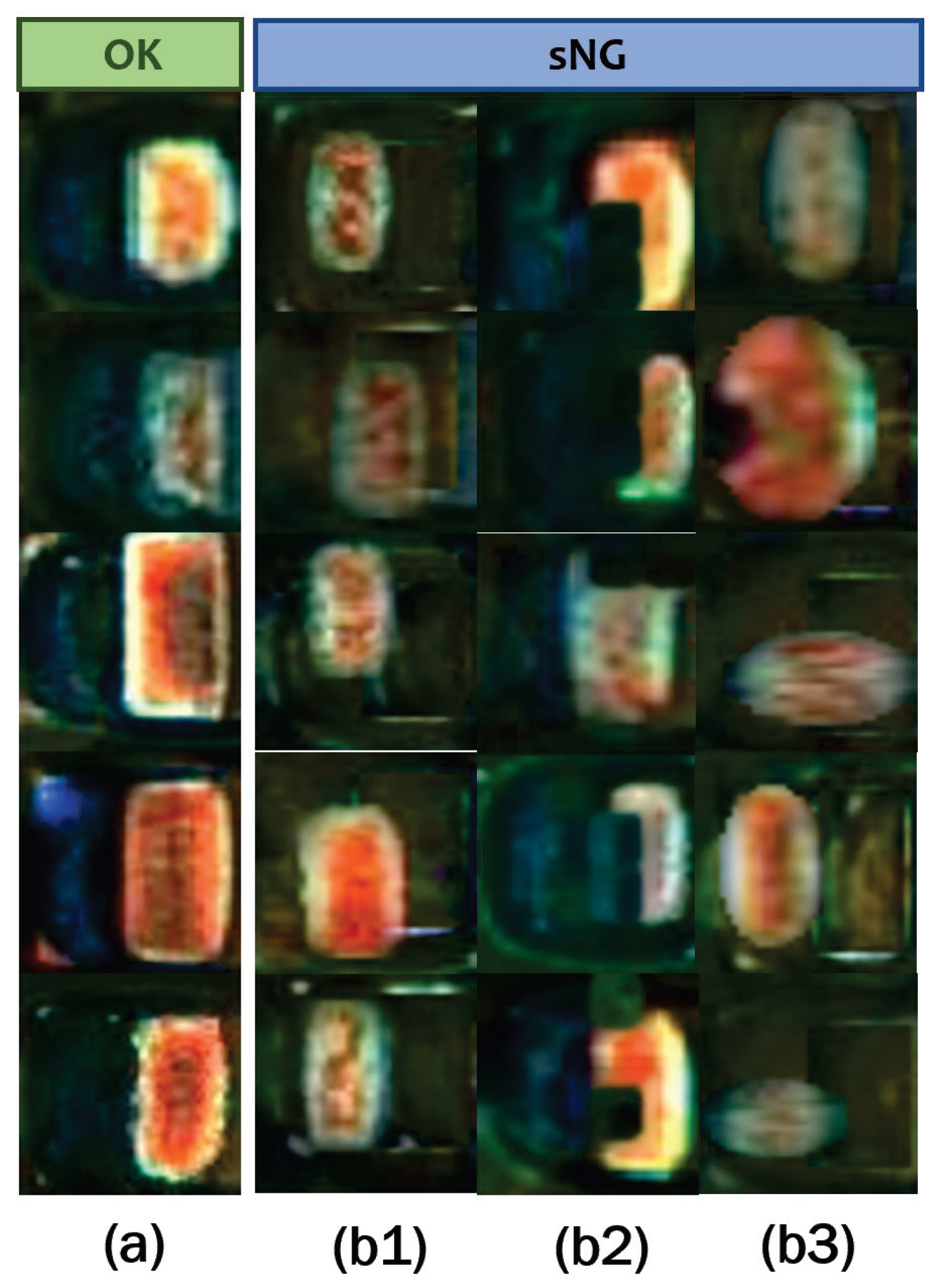
To further improve the detection accuracy of MobileNetV2-SSL, a contrastive self-supervised learning network is added to MobileNetV2-SSL to construct a CSSL framework. Unlike the traditional CSSL networks in computer vision, which are directly used in the classification process, our CSSL network is used to distill high-quality sNGs before the pretext tasks. Specifically, first, we generated 100,000 sNGs by the three special augmentations above. Then, we calculated the average similarity value between each sNG image and all NG images through the trained DFN. The output similarity values of all sNG images were in the range . After that, we sorted sNG images according to the similarity value. To better validate the effectiveness of the DFN, we set 4 distillation rates to distill sNG images, meaning the top percent of the sNG images ordered by the similarity value were extracted. For simplicity and better understanding, we referred to MobileNetV2-SSL incorporating DFN with a distillation rate r as r-MobileNetV2-CSSL. For example, 0.25-MobileNetV2-CSSL is a materialized model under the CSSL framework with the distillation rate being 0.25 and the classifier being MobileNetV2. In all models, 5000 epochs were trained for the pretext tasks and 1000 epochs for the downstream tasks. Other experimental parameters were set to be the same as those used in the first experiment above.
The comparison results of the four models are shown in
Table 5. From the F1-scores on both datasets, we can see that the performance of
r-MobileNetV2-CSSL improves as
r decreases, and 0.25-MobileNetV2-CSSL achieves the best F1-scores. These results validate that DFN can effectively distill the best sNG images to help the network improve detection accuracy. To validate the performance of the CSSL framework in the production line, an additional 2078 images of chip solder joints with defects were collected from the production line for testing 0.25-MobileNetV2-CSSL. The detection results are shown in
Table 6, and it is clear that the detection accuracy is very high and can meet the accuracy needs in practical applications.
4.3.3. Performance Comparison of the CSSL Framework with Other Classic Methods
To more intuitively validate the performance of our CSSL framework, several state-of-the-art defect inspection methods such as DIM [
45], AMDIM [
46], CPC-v2 [
47], GANomaly [
22], and GSDD [
48] were introduced for comparison. The best-performing model in the above second experiment, 0.25-MobileNetV2-CSSL, was used as the comparison model for these competing methods. The experimental parameter settings of 0.25-MobileNetV2-CSSL were the same as in the second experiment above.
The comparison results are shown in
Table 7. It can be seen that GANomaly has the highest
p value on the TOK data and the CPC-v2 has the highest
p value on the NG data. However, GANomaly has a relatively low
p value on the NG data, which means the detection performance of GANomaly on NG images is not good. Part of the reason is that there is not enough NG information to support the training process of GANomaly. Most of the
p values and R values of CPC-v2 and DIM are comparably good except for the R value on the NG data. CPC-v2 learns features by extracting features from each block by dividing the OK image into blocks. Therefore, CPC-v2 is more sensitive to OK data, while it is unfamiliar to NG data that it has never met. DIM constructs contrastive learning tasks by local features in OK images. Its discrimination ability for OK data is also much better than that for NG data. For chip solder joint defect detection, we should pay more attention to the recall rate of NG data. From the perspective of industrial production, if NG data are missed, it will cause more potential risks. Therefore, DIM and CPC do not meet the ideal requirements for solder joint defect detection. The proposed method is compared with a similar research method GSDD, and it is found that GSDD can not cover more complex defect scenes by solving the problem of defect classification through the color gradient. F1-score is a comprehensive metric that can better evaluate the ability of a method in detection accuracy. From the F1 values in
Table 7, we can see that 0.25-MobileNetV2-CSSL outperforms all the competing methods. In particular, 0.25-MobileNetV2-CSSL makes a significant improvement to the F1-score on the NG data compared to all competing methods.
4.4. Ablation Study
4.4.1. Effectiveness of the Three Specifically Designed Data Augmentation Methods
To demonstrate the contribution of each augmentation method, we performed an ablation study. Most of the experiment settings are the same as in the second experiment above, except that the three augmentation methods are optional during the training of the DFN. The results of the ablation study are summarized in
Table 8. In this table,
a,
b, and
c represent electrode shift, random dropping, and electrode morphology transformation, respectively. It can be seen that any combination of two augmentation methods is better than a single augmentation method in terms of the F1-score. By comparing all three combinations of two augmentation methods, we can see that the combination of the three augmentations has the best performance.
4.4.2. Effectiveness of WNT-Xent Loss
To demonstrate the effectiveness of the WNT-Xent, we compared four contrastive loss functions (NT-Xent, NT-Logistic, InfoNCE, and Margin Triplet).
Table 9 shows the results of the contrastive loss function ablation study. It can be seen that WNT-Xent performs best for distilling sNG images compared to other contrastive loss functions.
5. Discussion
Supervised learning is limited by the requirement for a large amount of labeled data in many application scenarios. Solder joint defect detection is one such scenario where labeled NG data are so insufficient; hence, it is a typical class imbalance problem. Usually, we can obtain a large amount of normal data but very little abnormal data. If we use such a dataset to train a supervised network, there is a high probability that the trained network will perform poorly in identifying abnormal data. The potential approach to solve this issue is to augment abnormal data to make as much of them as normal data. However, the common augmentation methods are not suitable for this case, because augmenting data from NG samples through these common methods can only generate similar defect images to the existing ones in the training set. Therefore, we propose several augmentation methods based on the OK data. The benefit of this idea is that we can transform, reshape, or modify a large number of normal images to simulate abnormal images. Due to a large amount of OK data and a random combination of various transformations that simulate real defects, we can obtain a great number of sNG images, many of which are similar to NG data. In the first comparative experiment, we have shown that these sNG images are very helpful for improving defect detection accuracy (
Table 8). In the univariate experiments, shifting is better than random missing. Electrode morphological transformation is better than electrode shifting. This indicates electrode morphology is the key feature that can be extracted from MobileNetV2 to distinguish OK and NG solder joint data. In the multivariate experiments, the combination of the three data transformations performs best. This result verifies from the side that the generated sNG data by our proposed augmentation methods can simulate the NG data well. It is worth noting that we propose only three augmentation methods, but there should be many other augmentation methods that can be used to further improve detection accuracy or solve some other less common detection problems.
The data filtering network DFN proposed in the paper is a very important support to the whole framework, because in the augmentation process we can only generate a great amount of NG data without prioritization, and we do not know which NG image is more helpful to the training process. The DFN is based on contrastive self-supervised learning, and it can be trained by using a little NG data. After training, the core feature vector of each NG image or sNG image can be extracted through the DFN, so that high-quality sNG images can be extracted according to the average distance between the feature vector of each sNG image and the feature vectors of all NG images. In the experiments, we can see that the detection accuracy increases as the distillation rate decreases, which is good proof that the DFN successfully extracts the sNG data that best match the NG data. The benefit of DFN in the paper is that we can select good samples and discard bad samples in a targeted manner, thereby effectively improving the quality of the enhanced data. By doing so, we do not need to worry about the negative impact of wrongly generated sNG data on the classification network any longer.
On the basis of the special augmentation methods and the DFN, we develop a CSSL framework. The reason we call it a framework is that it is like a frame with many replaceable or adjustable modules. For example, we can customize the augmentation methods, select an appropriate classifier, set a suitable distillation rate for the DFN, and even further optimize the DFN to better sift the sNG data. In the comparative experiment with several state-of-the-art self-supervised methods and unsupervised methods, we find that it is not a complicated thing to set up a model under the framework that can achieve better performance than these classical methods. This demonstrates that the proposed framework still has a lot of room for improvement. Moreover, when this model is deployed in the production line, it is found that it can achieve an accuracy of 99.14% with an average detection speed of about 6 ms per chip image. It is a satisfactory achievement for the practical application.
Although our method has not been thoroughly tested on various datasets with large amounts of defect data, we are confident that the proposed framework will be suitable for various application scenarios since the framework is very flexible. However, we may need to design other special augmentation methods, develop better classification networks, or further optimize the DFN to make the framework adapt to some uncommon situations.
6. Conclusions
In this paper, we propose three specifically designed augmentation methods to generate sNG data and build a DFN to select the best sNG data. Based on these special augmentation methods and the DFN, we construct a CSSL framework and validate its effectiveness through a series of comparative experiments. Experiments show that the CSSL framework can achieve better detection accuracy than the supervised methods and the state-of-the-art unsupervised and self-supervised methods in the case of insufficient NG data. An optimized model based on the CSSL framework has been deployed in the production line and can achieve an accuracy of 99.14%. The average detection speed is about 6 ms per chip image, which can meet the real-time detection needs in applications.
Nevertheless, there is still much room for improvement regarding the research in this paper. There are two aspects, as follows:
(1) The detection of some uncommon solder joint defects still needs further research.
(2) The framework proposed in this paper can further simplify the process of training classifiers and save training time.
In the future, we will focus on solving the above problems and extend the proposed framework to as many components as possible.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}