



FLPP: A Federated-Learning-Based Scheme for Privacy Protection in Mobile Edge Computing


Abstract
:1. Introduction
- (1)
- Targeting heterogeneous data, we present a federated-learning-based scheme for privacy protection in MEC. The scheme can improve the accuracy of training by adjusting the weights of its model parameters according to the amount of different users’ data. In addition, a differential privacy technique is implemented by adding noise to the model parameters so as to protect the privacy of user data.
- (2)
- To achieve flexible adjustment of differential privacy, we build a layered adaptive differential privacy model. During each epoch of training, different levels of noise can be added to cope with the requirements under various conditions.
- (3)
- Due to the higher privacy level, the model training is influenced by noise resulting in lower accuracy. In order to trade off the accuracy and security of the model, we customize a differential evolution algorithm to derive the optimal policy to achieve the best overall performance.
2. Related Work
3. System Model and Problem Formulation
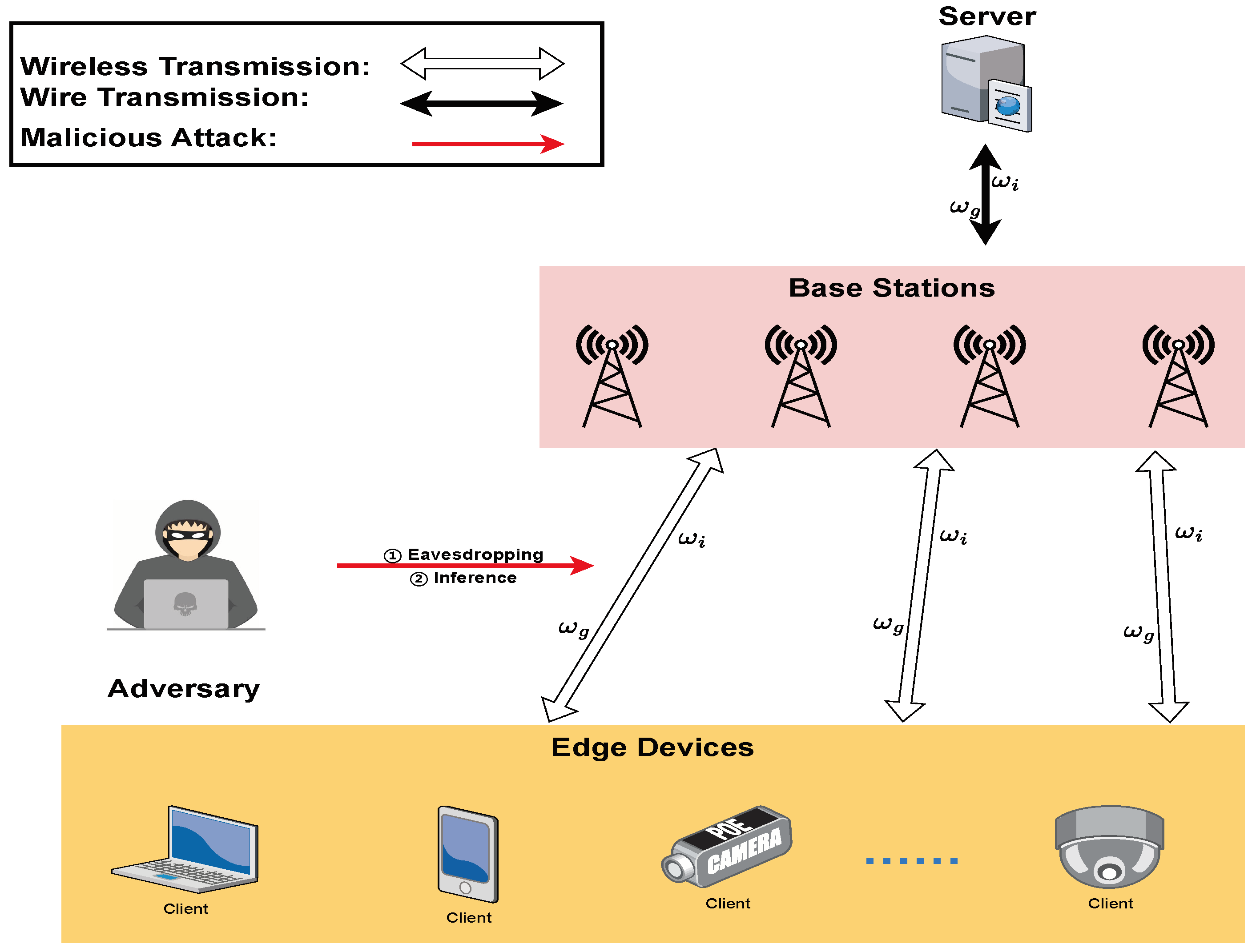
3.1. Threat Model
- (1)
- Eavesdropping: Also called sniffing or snooping attack, eavesdropping refers to picking up a transmitted packet sent over the network. The edge nodes directly offloaded will be vulnerable to malicious attacks against the data itself, causing privacy leakage.
- (2)
- Membership Inference Attacks: As the name denotes, an inference attack is a way to infer training data details. Attackers obtain the gradient information of the aggregation process by eavesdropping or other methods. Then, this information can be used to infer more valuable intelligence.
3.2. Data Protection Model
- step 1 Local Training: Each node trains the model locally according to its own data after the MEC server distributes the initial model to each edge node.Gradient descent of client i can be expressed aswhere is the distributed model parameter and denotes the loss function of client i.The updated model parameter of client i can be calculated bywhere is the learning rate.
- step 2 Model Uploading: The participating nodes upload the model parameters obtained from local training to the MEC server.
- step 3 Model Aggregating: The MEC server securely aggregates the uploaded model parameters to get the updated global model parameter.Each aggregated weight is related to the size of the node dataset and the updated global model parameter can be expressed aswhere I stands for the set of participating clients.
- step 4 Model Broadcasting: The server broadcasts the updated global model parameter to each edge node and starts a new round of training.
3.3. Model Parameter Protection Model
3.4. Problem Statement
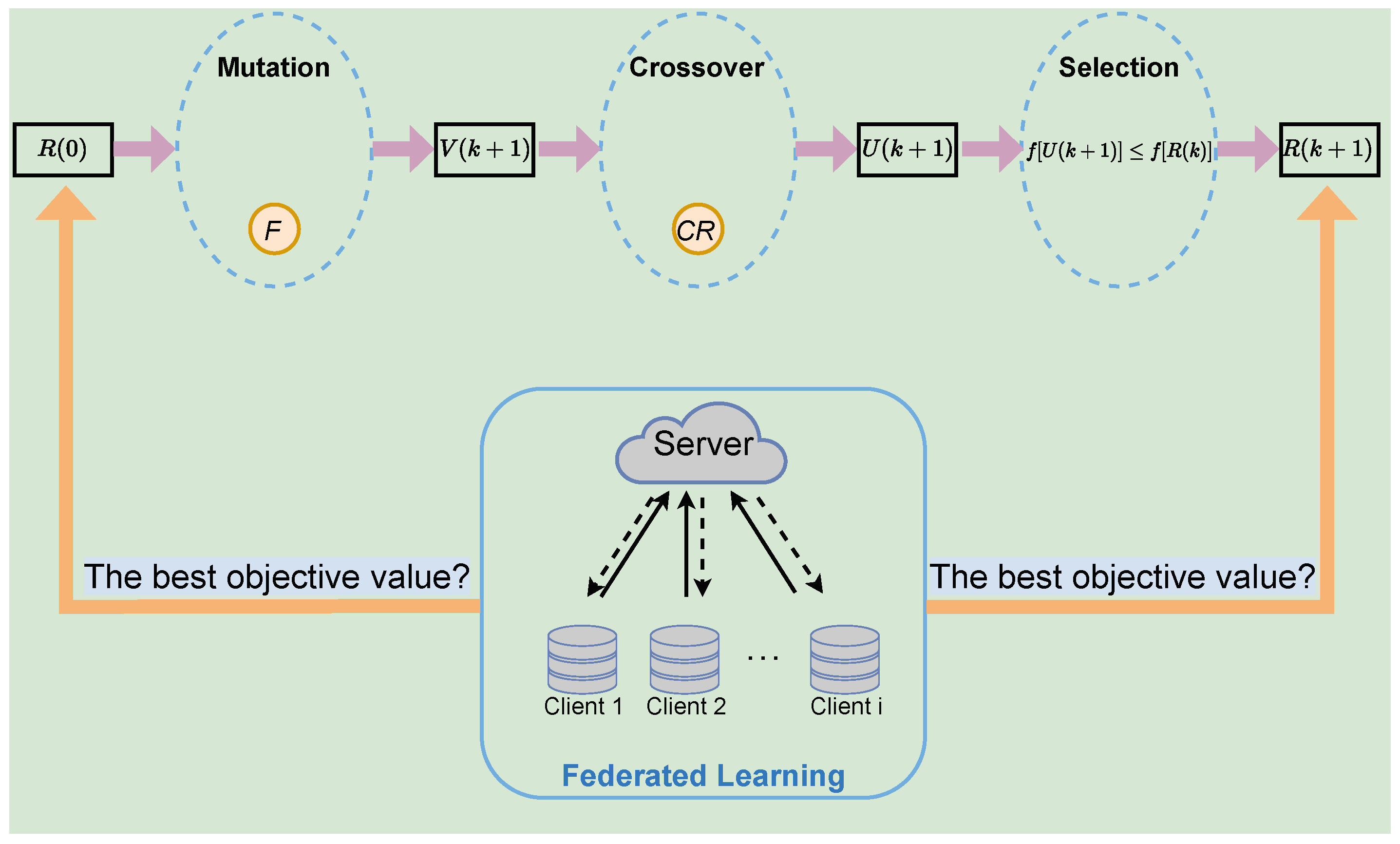
4. FLPP Scheme
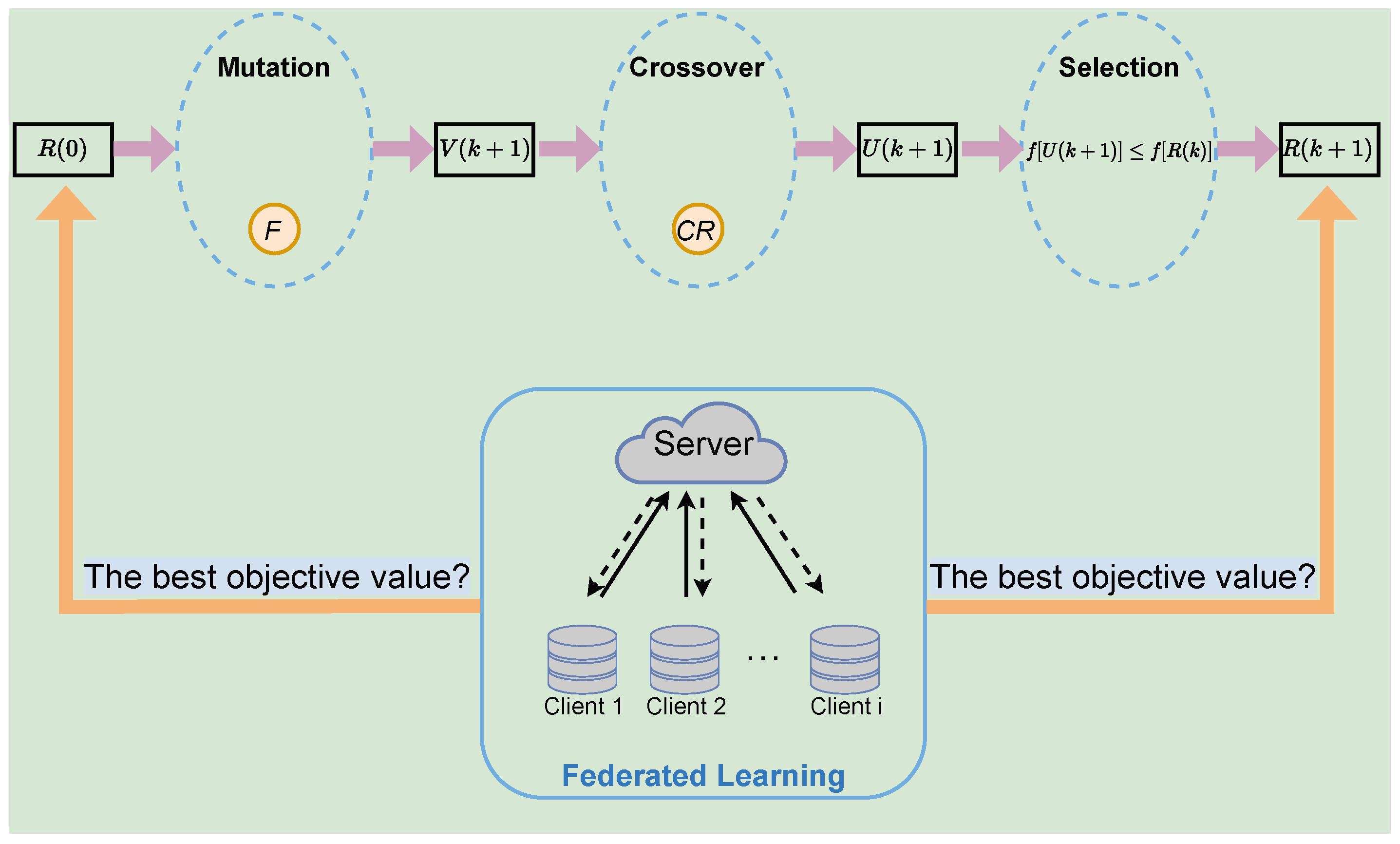
4.1. Algorithmic Framework of Federated Learning
| Algorithm 1 Federated Learning |
 |
4.2. Privacy-Protection Optimization Algorithm
| Algorithm 2 Differential Evolution |
 |
5. Simulation and Discussion
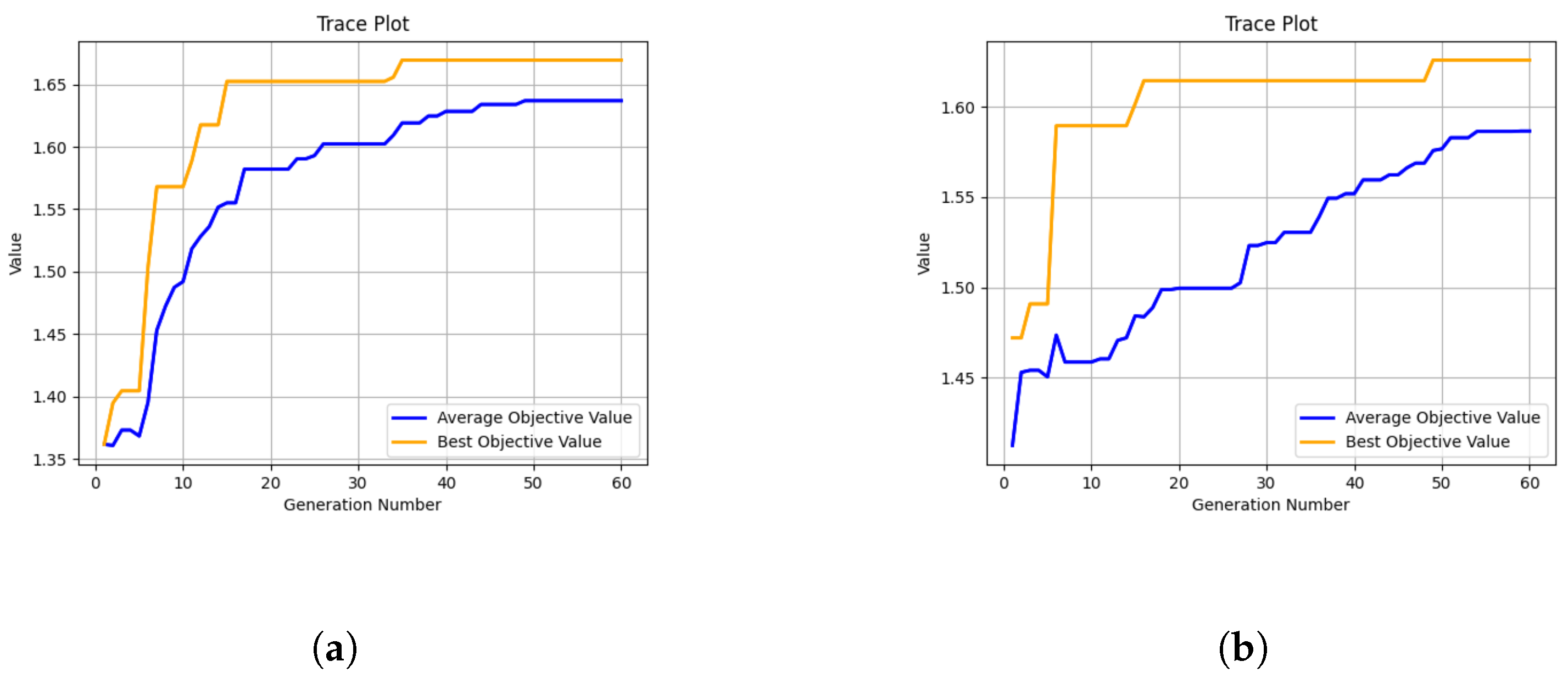
5.1. Performance of Training
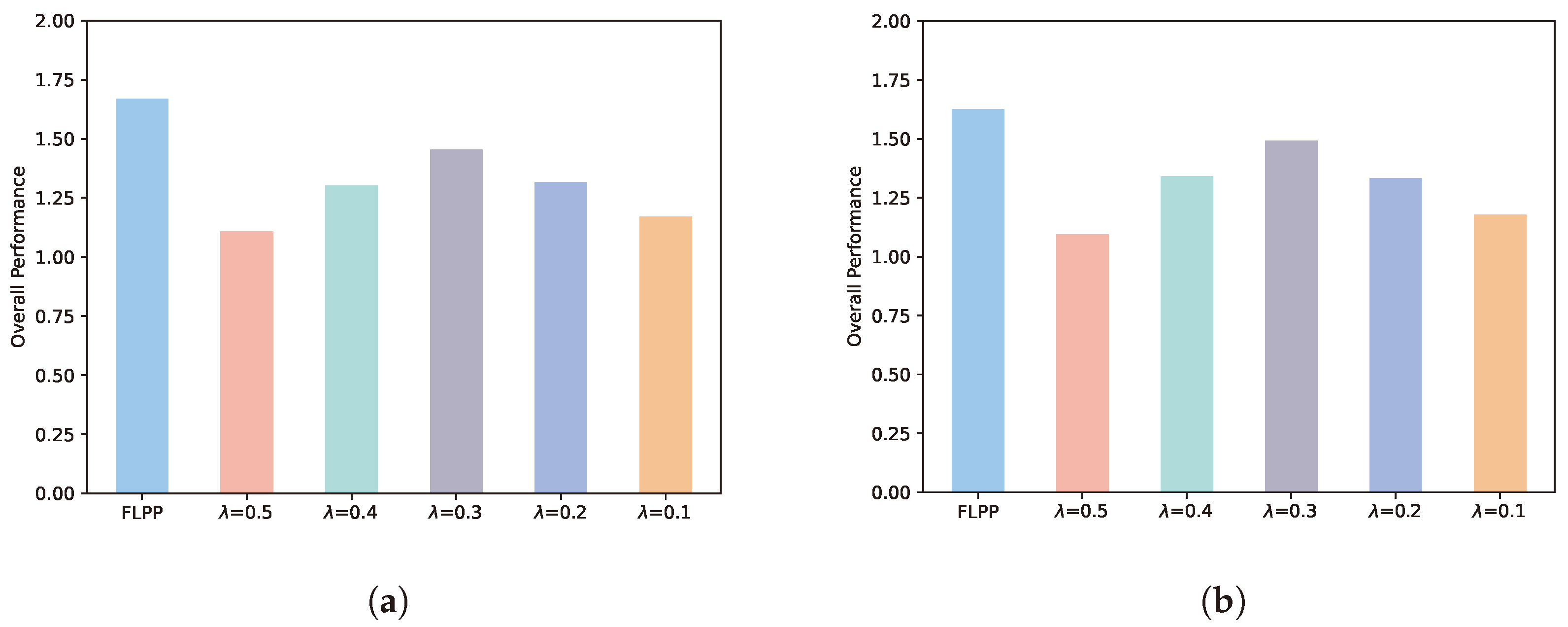
5.2. Overall Performance
5.3. Accuracy Performance
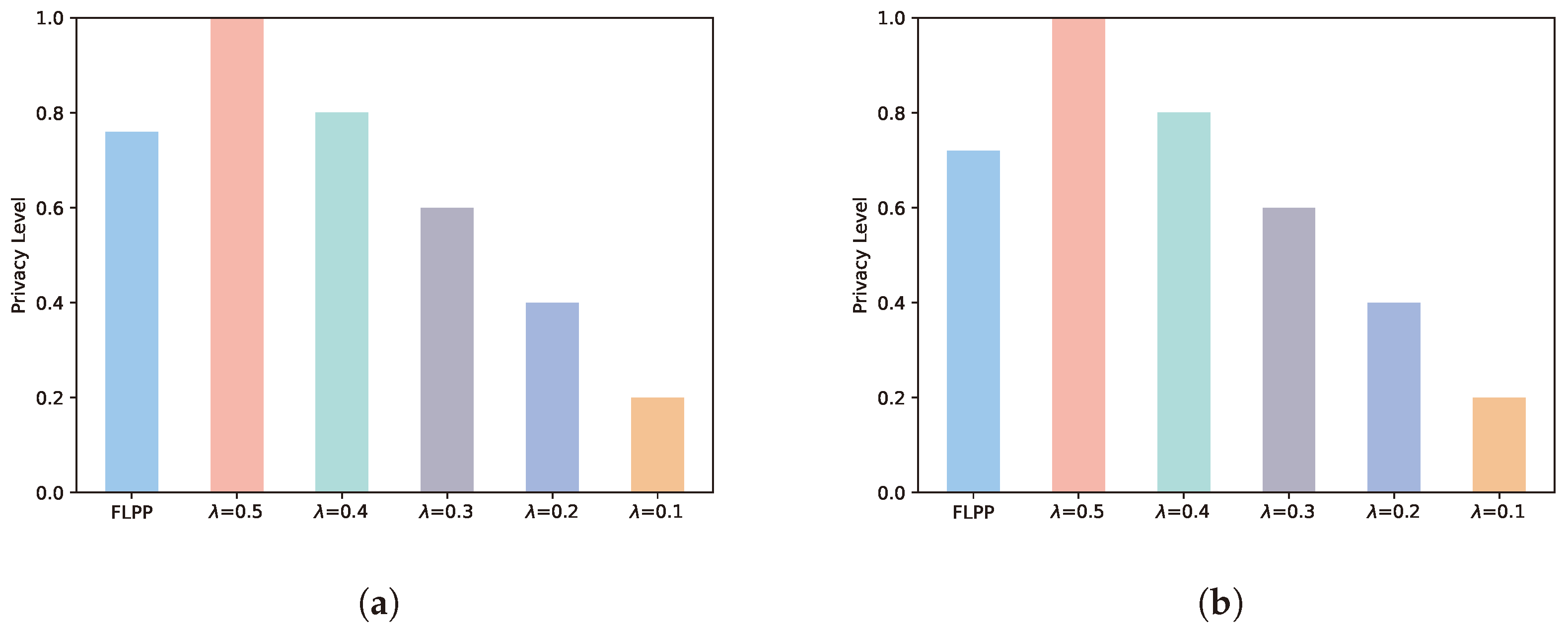
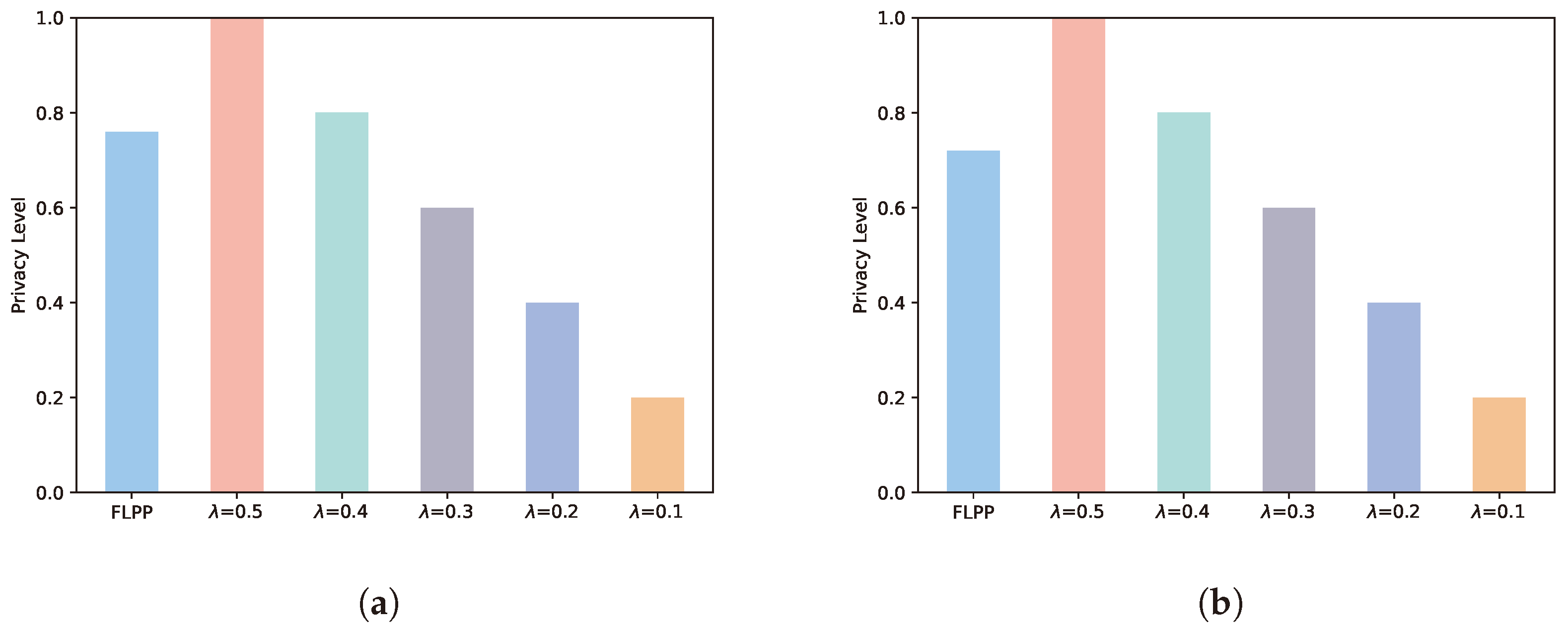
5.4. Security Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Notation | Meaning |
| M | Set of mobile devices |
| Learning rate | |
| D | Set of data volume of mobile devices |
| Test dataset | |
| I | Set of participating clients |
| Privacy budget | |
| J | Total training rounds |
| Sensitivity of dataset | |
| Global model parameter | |
| Privacy level | |
| Model parameter of client i | |
| A | Training accuracy |
References
- Sun, X.; Ansari, N. EdgeIoT: Mobile Edge Computing for the Internet of Things. IEEE Commun. Mag. 2016, 54, 22–29. [Google Scholar] [CrossRef]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An Overview on Edge Computing Research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Qiu, T.; Chi, J.; Zhou, X.; Ning, Z.; Atiquzzaman, M.; Wu, D.O. Edge Computing in Industrial Internet of Things: Architecture, Advances and Challenges. IEEE Commun. Surv. Tutor. 2020, 22, 2462–2488. [Google Scholar] [CrossRef]
- Leung, C.K.; Deng, D.; Hoi, C.S.H.; Lee, W. Constrained Big Data Mining in an Edge Computing Environment. In Proceedings of the Big Data Applications and Services 2017, Tashkent, Uzbekistan, 15–18 August 2017; Lee, W., Leung, C.K., Eds.; Springer: Singapore, 2019; pp. 61–68. [Google Scholar]
- Du, M.; Wang, K.; Chen, Y.; Wang, X.; Sun, Y. Big Data Privacy Preserving in Multi-Access Edge Computing for Heterogeneous Internet of Things. IEEE Commun. Mag. 2018, 56, 62–67. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–9. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; Singh, A., Zhu, J., Eds.; PMLR: London, UK, 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Li, Z.; Sharma, V.; Mohanty, S.P. Preserving Data Privacy via Federated Learning: Challenges and Solutions. IEEE Consum. Electron. Mag. 2020, 9, 8–16. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Fang, H.; Qian, Q. Privacy preserving machine learning with homomorphic encryption and federated learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Xu, Y.; Mao, Y.; Li, S.; Li, J.; Chen, X. Privacy-Preserving Federal Learning Chain for Internet of Things. IEEE Internet Things J. 2023, 10, 18364–18374. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, B.; Yu, S.; Deng, H. PEFL: A Privacy-Enhanced Federated Learning Scheme for Big Data Analytics. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Kalapaaking, A.P.; Stephanie, V.; Khalil, I.; Atiquzzaman, M.; Yi, X.; Almashor, M. SMPC-Based Federated Learning for 6G-Enabled Internet of Medical Things. IEEE Netw. 2022, 36, 182–189. [Google Scholar] [CrossRef]
- Abou El Houda, Z.; Hafid, A.S.; Khoukhi, L. Mitfed: A privacy preserving collaborative network attack mitigation framework based on federated learning using sdn and blockchain. IEEE Trans. Netw. Sci. Eng. 2023, 10, 1985–2001. [Google Scholar] [CrossRef]
- Sotthiwat, E.; Zhen, L.; Li, Z.; Zhang, C. Partially Encrypted Multi-Party Computation for Federated Learning. In Proceedings of the 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Melbourne, Australia, 10–13 May 2021; pp. 828–835. [Google Scholar] [CrossRef]
- Fereidooni, H.; Marchal, S.; Miettinen, M.; Mirhoseini, A.; Möllering, H.; Nguyen, T.D.; Rieger, P.; Sadeghi, A.R.; Schneider, T.; Yalame, H.; et al. SAFELearn: Secure Aggregation for private FEderated Learning. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 27 May 2021; pp. 56–62. [Google Scholar] [CrossRef]
- Galletta, A.; Taheri, J.; Celesti, A.; Fazio, M.; Villari, M. Investigating the Applicability of Nested Secret Share for Drone Fleet Photo Storage. IEEE Trans. Mob. Comput. 2023, 1–13. [Google Scholar] [CrossRef]
- Galletta, A.; Taheri, J.; Villari, M. On the Applicability of Secret Share Algorithms for Saving Data on IoT, Edge and Cloud Devices. In Proceedings of the 2019 International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Atlanta, GA, USA, 14–17 July 2019; pp. 14–21. [Google Scholar] [CrossRef]
- Galletta, A.; Taheri, J.; Fazio, M.; Celesti, A.; Villari, M. Overcoming security limitations of Secret Share techniques: The Nested Secret Share. In Proceedings of the 2021 IEEE 20th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Shenyang, China, 20–22 October 2021; pp. 289–296. [Google Scholar] [CrossRef]
- Wang, Y.; Tian, Y.; Yin, X.; Hei, X. A trusted recommendation scheme for privacy protection based on federated learning. CCF Trans. Netw. 2020, 3, 218–228. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Vincent Poor, H. Federated Learning with Differential Privacy: Algorithms and Performance Analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Zhao, B.; Fan, K.; Yang, K.; Wang, Z.; Li, H.; Yang, Y. Anonymous and Privacy-Preserving Federated Learning With Industrial Big Data. IEEE Trans. Ind. Inform. 2021, 17, 6314–6323. [Google Scholar] [CrossRef]
- Adnan, M.; Kalra, S.; Cresswell, J.C.; Taylor, G.W.; Tizhoosh, H.R. Federated learning and differential privacy for medical image analysis. Sci. Rep. 2022, 12, 1953. [Google Scholar] [CrossRef]
- Ali, B.; Gregory, M.A.; Li, S. Multi-Access Edge Computing Architecture, Data Security and Privacy: A Review. IEEE Access 2021, 9, 18706–18721. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. IEEE Trans. Knowl. Data Eng. 2023, 35, 3347–3366. [Google Scholar] [CrossRef]
- Melis, L.; Song, C.; De Cristofaro, E.; Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2019; pp. 691–706. [Google Scholar]
- Hitaj, B.; Ateniese, G.; Perez-Cruz, F. Deep models under the GAN: Information leakage from collaborative deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 603–618. [Google Scholar]
- Price, K.; Storn, R.M.; Lampinen, J.A. Differential Evolution: A Practical Approach to Global Optimization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 24–28 October 2016; Association for Computing Machinery. pp. 308–318. [Google Scholar] [CrossRef]
- Gong, M.; Feng, J.; Xie, Y. Privacy-enhanced multi-party deep learning. Neural Netw. 2020, 121, 484–496. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of clients | 50 |
| Data volume of clients | [1, 60,000] |
| Number of participating clients | [4, 10] |
| Privacy level range | [0.1, 0.5] |
| Learning rate | 0.005 |
| Number of local epochs | 10 |
| Crossover rate | 0.7 |
| Step size parameter | 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Z.; Ji, X.; You, W.; Bai, Y.; Chen, Y.; Qin, X. FLPP: A Federated-Learning-Based Scheme for Privacy Protection in Mobile Edge Computing. Entropy 2023, 25, 1551. https://doi.org/10.3390/e25111551
Cheng Z, Ji X, You W, Bai Y, Chen Y, Qin X. FLPP: A Federated-Learning-Based Scheme for Privacy Protection in Mobile Edge Computing. Entropy. 2023; 25(11):1551. https://doi.org/10.3390/e25111551
Chicago/Turabian StyleCheng, Zhimo, Xinsheng Ji, Wei You, Yi Bai, Yunjie Chen, and Xiaogang Qin. 2023. "FLPP: A Federated-Learning-Based Scheme for Privacy Protection in Mobile Edge Computing" Entropy 25, no. 11: 1551. https://doi.org/10.3390/e25111551
APA StyleCheng, Z., Ji, X., You, W., Bai, Y., Chen, Y., & Qin, X. (2023). FLPP: A Federated-Learning-Based Scheme for Privacy Protection in Mobile Edge Computing. Entropy, 25(11), 1551. https://doi.org/10.3390/e25111551