1. Introduction
A risk measure is a functional
that maps from convex cone
of risks to
on a probability space
. A good risk measure should satisfy some desirable properties (see, e.g., [
1,
2,
3]). The several standard properties for general risk measures are presented as follows:
- (A)
Law invariance: For , if , then ;
- (A1)
Monotonicity: For , if , then ;
- (A2)
Translation invariance: For and any , we have ;
- (A3)
Positive homogeneity: For and any , we have ;
- (A4)
Subadditivity: For , we have ;
- (A5)
Comonotonic additivity: If V and W are comonotonic, then .
To estimate and identify risk measure, the law invariance (A) is an essential requirement. When a risk measure
further satisfies (A1)–(A4), then
is said to be coherent. It is well known that value-at-risk (VaR) and expected shortfall (ES) are the two extremely important risk measures used in banking and insurance. The VaR and ES at confidence level
for a random variable (r.v.)
V with cumulative distribution function (cdf)
are defined as
and
respectively. If
is continuous, then ES equals the tail conditional expectation (TCE), which is written as
where
.
Some risk measures have other desirable properties; for example, (B1) Standardization: For , we have ; (B2) Location invariance: For and , we have . If a functional satisfies law invariance (A), (B1) and (B2), we say that is a measure of variability. If further satisfies properties (A3) and (A4), then we say is a coherent measure of variability.
To capture the variability of the risk
V beyond the quantile
, Furman and Landsman [
4] proposed the tail standard deviation (TSD) risk measure
where
,
denotes the loading parameter and
the tail standard deviation measure defined as
Here,
is the tail variance of
V. As its extension, Furman et al. [
5] introduced the Gini shortfall (GS), which is defined by
where
is tail-Gini functional. Recently, Hu and Chen [
6] further proposed a shortfall of cumulative residual entropy (CRE), defined by
where
is the tail-based CRE of
V. Here,
for
, and
for
.
Inspired by those works, our main motivation is to find coherent shortfalls of entropy, which is the generalization of TSD, GS and CRES. These shortfalls of entropy can be used to capture the variability of a financial position. For specific financial applications, we can refer to [
5,
7,
8]. To this aim, we give covariance and Choquet integral representations for some entropies, and provide upper bounds of those entropies. These representations not only make it easier for us to judge their cohesiveness, but also facilitate the extension of these results to two-dimensional and multi-dimensional cases in the future. Furthermore, we define TCRTE and TRTD, and propose CRTES and RTDS. As illustrated examples, CRTESs of elliptical, inverse Gaussian, gamma and beta distributions are simulated.
The remainder of this paper is structured as follows.
Section 2 provides the covariance and Choquet integral representations for some entropies.
Section 3 introduces some tail-based entropies. In
Section 4, we propose two shortfalls of entropy, and give some equivalent results. The CRTESs of some parametric distributions are presented in
Section 5. Finally,
Section 6 concludes this paper and summarizes two possible research studies in the future.
Throughout the paper, let be an atomless probability space. For a random variable V with cumulative distribution function (cdf) , we use to denote any uniform random variable such that holds almost everywhere. Let be the set of all random variables on with a finite kth-moment. Denote by the set of all non-negative random variables. denotes the first derivative of g. Notation , and is the indicator function of set A.
2. Covariance and Choquet Integral Representations for Some Entropies
In this section, we derive covariance and Choquet integral representations for some entropies, which include initial, weighted and dynamic entropies. In addition, the upper bounds of these entropies are established.
Given
g defined in
with
, weighted function
and a r.v.
X with cdf
, the initial and weighted entropies (forms) are defined as, respectively,
and
Further, given two r.v.s
and
, the dynamic entropies (forms) are defined as
and
To derive the covariance of entropy, we first introduce below lemma.
Lemma 1 ([
5]).
Let g be an almost everywhere (a.e.) differentiable function in with (a.e.) and . Suppose that and . Then, we have Proof. Since
g is almost everywhere differentiable in
, we let
. Then,
Note that
. Therefore,
Further, we use correlation coefficient , , and the last inequality is immediately obtained. □
2.1. Initial Entropy
To find the covariance represent of initial entropy, we give the following theorem.
Theorem 1. Let g be a continuous and almost everywhere differentiable function in with (a.e.) and . Further, there exists a unique minimum (or maximum) point such that g is decreasing on and increasing on (or there exists such that g is increasing on and decreasing on ). Suppose that and . Then, we have Proof. Since
is almost everywhere differentiable in
, and
, there exists a unique minimum (or maximum) point
. Hence, we can use
g to induce Lebesgue–Stieltjes measures on the Borel-measurable spaces
and
, respectively. Denote
; we have
where we have used Fubini’s theorem in the third equality. Further, using Lemma 1, we obtain
□
Remark 1. Note that the function g is of bounded variation since g has the following representation , where is increasing and is decreasing. Similar results can be found in Lemma 3 of [9]. However, the result of this article is different from Lemma 3 of [9]. The integral interval and integrand are different, with one integrand being a function of F (i.e., ) and the other being a function of (i.e., ). So, our result cannot be obtained from theirs. Corollary 1. Let g be a concave function in with (a.e.) and . Suppose that and . Then, we have 2.2. Weighted Entropy
Weighted entropy is an extension of initial entropy, which is an initial entropy associated with a weight function. We have the corresponding theorem as follows.
Theorem 2. Let g be a continuous and almost everywhere differentiable function in with (a.e.) and . Further, there exists a unique minimum (or maximum) point and . Suppose that and . Then, we have Proof. Similar to the proof of Theorem 1, we have
where we have used Fubini’s theorem in the third equality.
Note that
and
.
Therefore, we obtain
ending the proof. □
Corollary 2. Let in Theorem 2; we have Corollary 3. Let g be a concave function in with (a.e.) and . Suppose that and . Then, we have 2.3. Dynamic (Weighted) Entropy
Dynamic entropy is also a generalization of an initial entropy that focuses on feasible choices of the ranges (upper tail or lower tail).
The survival function of a random variable
can be represented as
Therefore, for any
,
Theorem 3. Let g be a continuous and almost everywhere differentiable function in with (a.e.) and . Further, there is a unique minimum (or maximum) point and . Suppose that and . Then, we havewhere for , and for . Proof. Using Equation (
9) and the same argument of Theorem 2, we can easily obtain Theorem 3. □
Corollary 4. Let in Theorem 3; we havewhere for , and for . Corollary 5. Let g be a concave function in with (a.e.) and . Suppose that and . Then, we havewhere for , and for . The distribution function of a random variable
can be written as
Therefore, for any
,
Theorem 4. Let g be a continuous and almost everywhere differentiable function in with (a.e.) and . Further, there is a unique minimum (or maximum) point and . Suppose that and . Then, we havewhere for , and for . Proof. Using Equation (
13), Theorem 2 and translation
, we can obtain Theorem 4. □
Corollary 6. Let in Theorem 4; we havewhere for , and for . Corollary 7. Let g be a concave function in with (a.e.) and . Suppose that and . Then, we havewhere for , and for . 2.4. Examples
Example 1. Let , in Corollary 1, Equation (6) denoted by ; we have In particular, when
, the above measure denotes the cumulative Tsallis past entropy introduced by Calì et al. ([
10]). Note that when
, it reduces to cumulative entropy (
), defined as (see [
11])
Further,
where
.
In particular, when
,
, we obtain
Further,
which is Gini mean semi-difference, denoted by
; for details, see [
6,
12].
Example 2. Let , in Corollary 1, Equation (6) denoted by ; we have In particular, when
, the above measure is the cumulative residual Tsallis entropy of order
introduced by Rajesh and Sunoj [
13]. Note that when
, it reduces to cumulative entropy (
), defined as (see [
14])
Further,
where
.
Example 3. Let , in Corollary 1, Equation (6) denoted by , so that . Then, we have In particular, when
, the above measure is called the fractional cumulative residual entropy of
X by Xiong et al. [
15].
Example 4. Let in Corollary 1, Equation (6) denoted by ; we have In particular, when
, the above measure is the right-tail deviation introduced by Wang [
16].
Example 5. Let , in Corollary 1, Equation (6) denoted by ; we have In particular, when
, the above measure is the extended Gini coefficient (see [
7]). As a special case, when
, the extended Gini coefficient becomes the simple Gini (see [
5]).
Example 6. Let , in Theorem 1, Equation (5) denoted by , so that . Then, we have In particular, when
, the above measure is called the fractional generalized cumulative residual entropy of
X by Di Crescenzo et al. [
17].
In particular, if
is a positive integer, say
, in this case,
. Then,
identifies with the generalized cumulative residual entropy (
) that has been introduced by Psarrakos and Navarro [
18], i.e.,
Example 7. Let , in Theorem 1, Equation (5) denoted by , so that . Then, we have In particular, when
, the above measure is called the fractional generalized cumulative entropy of
X by Di Crescenzo et al. ([
17]).
In particular, if
is a positive integer, say
, in this case,
. Then,
identifies with the generalized cumulative entropy (
) that has been introduced by Kayal [
19] (see also [
20]), i.e.,
Example 8. Let , in Corollary 3, Equation (8) denoted by ; we have In particular, when
, the above measure is the weighted cumulative Tsallis entropy of order
introduced by Chakraborty and Pradhan [
21]. Note that when
, it reduces to weighted cumulative entropy (
), defined as (see [
22,
23])
Further,
where
.
In particular, when
,
, we obtain
Example 9. Let , in Corollary 3, Equation (8) denoted by ; we have In particular, when
, the above measure is the weighted cumulative residual Tsallis entropy of order
introduced by Chakraborty and Pradhan [
21]. Note that when
, it reduces to weighted cumulative residual entropy (
), defined as (see [
23,
24])
Further,
where
.
Example 10. Let , in Theorem 2, Equation (7) denoted by , so that . Then, we have In particular, when
, the above measure is the weighted generalized cumulative residual entropy introduced by Tahmasebi ([
25]) (also see [
26]). As a special case, when
,
reduces to a shift-dependent GCRE of order
n (
) defined by Kayal [
27], i.e.,
In particular, when
,
, the
reduces to weighted cumulative residual entropy with weight function
(
) defined by Suhov and Yasaei Sekeh [
28], i.e.,
They also define weighted cumulative entropy with weight function
(
; in this case,
):
Example 11. Let in Corollary 5, Equation (12) denoted by ; we havewhere for , and for . In particular, when
, the above measure is dynamic cumulative entropy defined by Asadi and Zohrevand [
29].
Example 12. Let in Corollary 5, Equation (12) denoted by , so that . Then, we havewhere for , and for . Example 13. Let , in Corollary 5, Equation (12) denoted by ; we havewhere for , and for . In particular, when
, the above measure is the dynamic cumulative residual Tsallis entropy of order
introduced by Rajesh and Sunoj [
13].
In particular, when
and
, we obtain (dynamic Gini mean semi-difference)
where
for
, and
for
.
Example 14. Let , in Corollary 5; we havewhere for , and for . Example 15. Let , in Corollary 5; we havewhere for , and for . Example 16. Let in Corollary 4, Equation (11) denoted by , so that . Then, we havewhere for , and for . In particular, when
, the above measure denotes the dynamic generalized cumulative residual entropy introduced by Psarrakos and Navarro [
18].
Example 17. Let in Theorem 3, Equation (10) denoted by , so that . Then, we havewhere for , and for . In particular, when
, the above measure is the dynamic WGCRE introduced by Tahmasebi [
25].
Particularly, when
and
, the
reduces to the dynamic weighted cumulative residual entropy (
) defined as
where
for
, and
for
. As a special case, when
, the above measure is introduced by Miralia and Baratpour [
30]. They also defined
,
, i.e.,
where
for
, and
for
.
Example 18. Let in Corollary 7, Equation (16) denoted by ; we havewhere for , and for . In particular, when
and
, the above measure is a generalization of the dynamic cumulative Tsallis entropy introduced by Calì et al. [
10]. Note that when
, it reduces to (a generalization of) cumulative past entropy, defined as (see, e.g., [
31])
where
for
, and
for
.
Example 19. Let , in Corollary 6, Equation (15) denoted by , so that . Then, we havewhere for , and for . In particular, when
, the above measure is the dynamic generalized cumulative entropy introduced by Kayal [
19].
Example 20. Let in Theorem 4, Equation (14) denoted by , so that . Then, we havewhere for , and for . In particular, when
and
,
is reduced as (see [
30])
where
for
, and
for
.
2.5. Discussion
Note that the above entropy risk measures satisfy (B1) standardization by their covariance representations. For any , using , we obtain that initial entropy and simple dynamic entropy risk measures satisfy (B2) location invariance, but weighted entropy risk measures do not satisfy (B2). Therefore, initial entropy and simple dynamic entropy risk measures are measures of variability.
For any , using , we obtain that initial entropy and simple dynamic entropy risk measures satisfy (B3) positive homogeneity.
When
is finite variation and
, the signed Choquet integral is defined by
When
g is right-continuous, then Equation (
20) can be expressed as
Furthermore, when g is absolutely continuous, with
, then Equation (
21) can be expressed as
From (
21), we can see that the signed Choquet integral satisfies the co-monotonically additive property ([
32]). Thus, initial entropy and simple dynamic entropy risk measures are co-monotonically additive measures of variability.
The functional
defined by Equation (
20) is sub-additive if and only if g is convex (e.g., [
33,
34]). Hence, initial entropy risk measures, which are shown in Examples 1–5 and (
17)–(
19), satisfy (A4) sub-additivity. Therefore, Examples 1–5 and (
17)–(
19) are co-monotonically additive and coherent measures of variability.
These initial entropy risk measures can be applied to the predictability of the failure time of a system (see [
11,
14]). The weighted entropy risk measures are shift-dependent measures of uncertainty, and can be applied to some practical situations of reliability and neurobiology (see [
35,
36]). The dynamic entropy risk measures can be used to capture effects of the age
t of an individual or an item under study on the information about the residual lifetime (see [
29]).
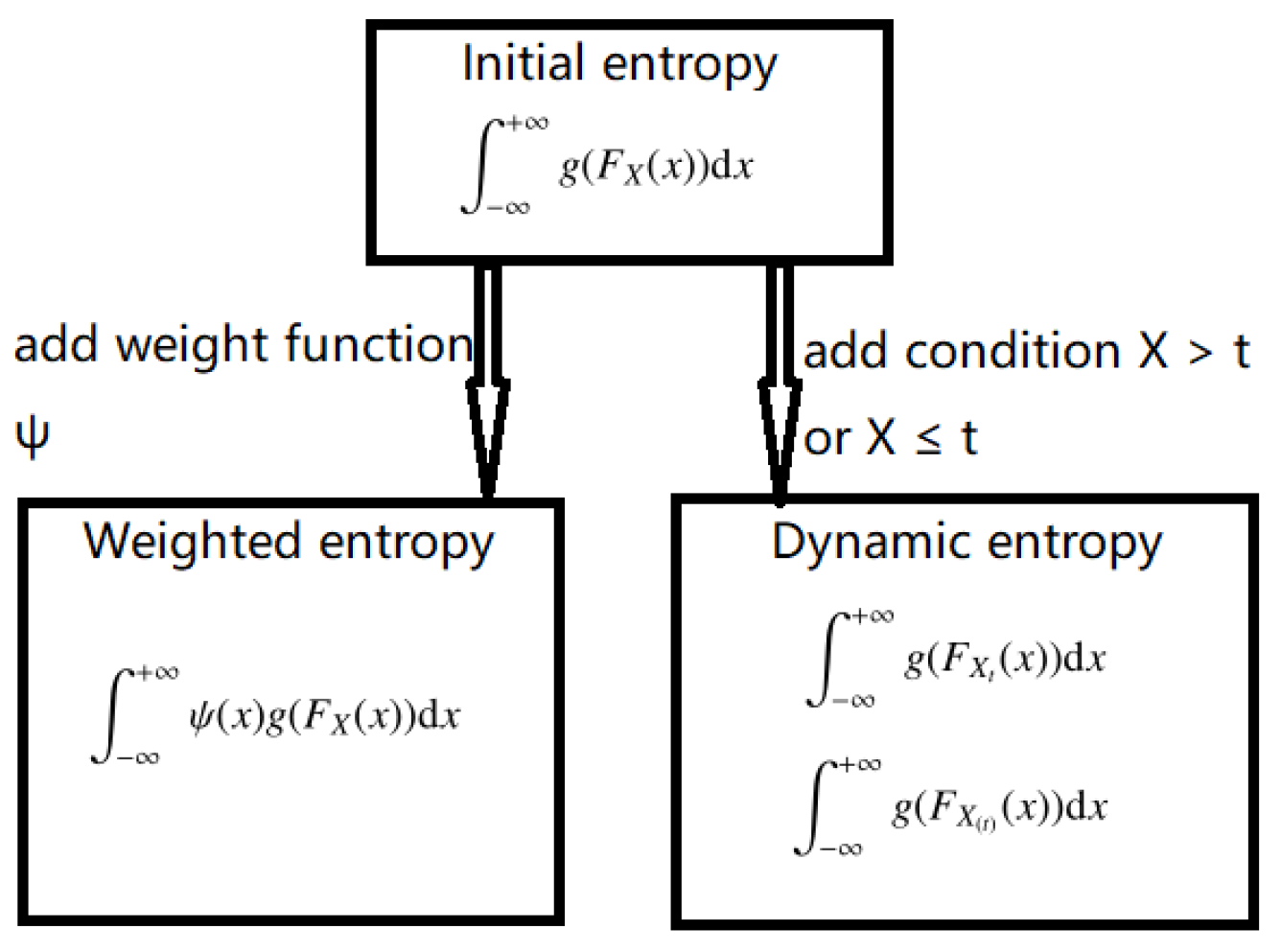
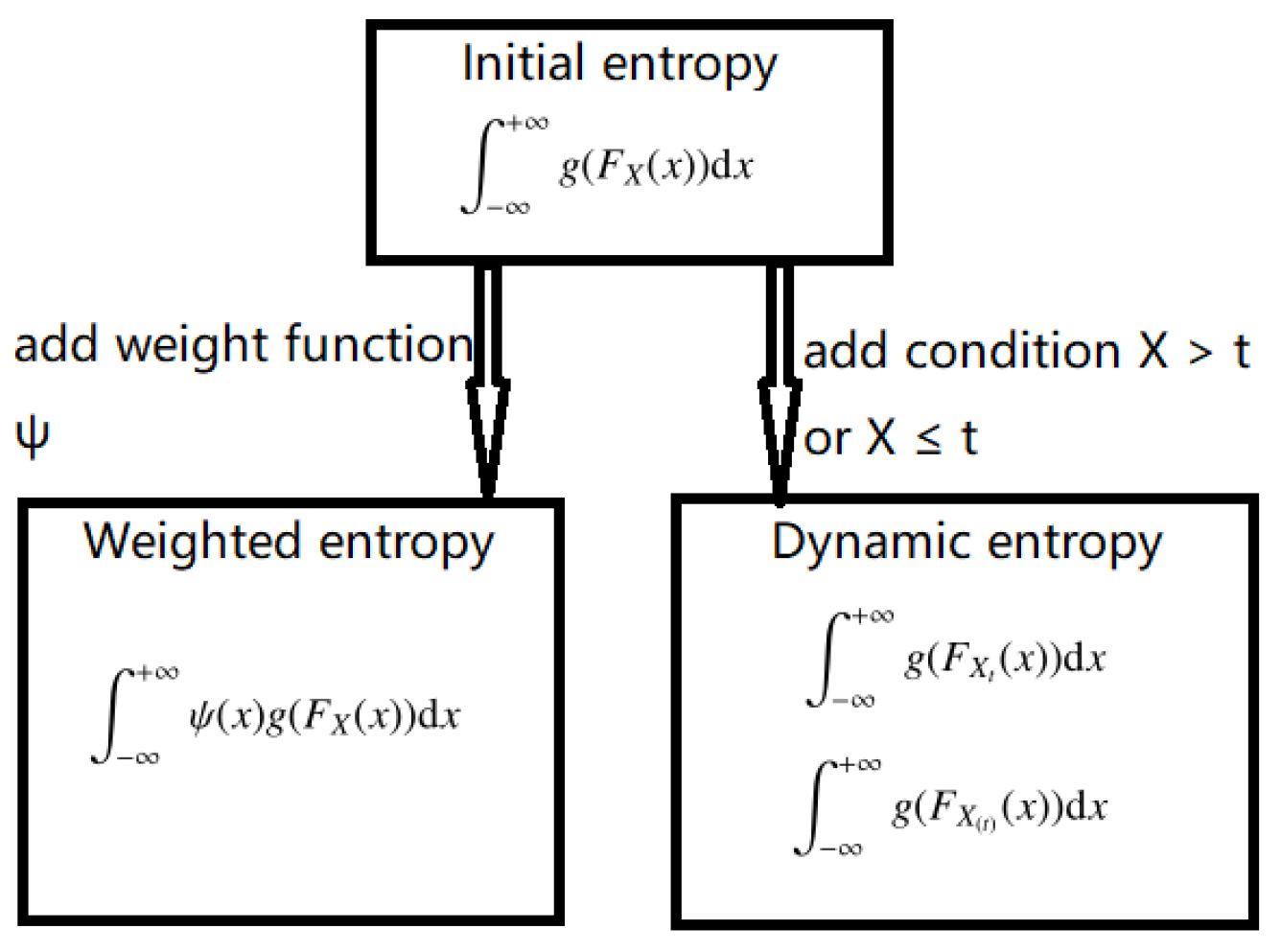
The initial, weighted and dynamic entropy risk measures are closely related, as shown in
Figure 1:
From a risk measure point of view, the initial entropy risk measures can capture the variability of a financial position as a whole. The dynamic entropy risk measures can depict the variability of a financial position focused on feasible choices of the ranges (upper tail or lower tail).
In finance and risk management, Markowitz’s mean-variance portfolio theory plays a vital role in modern portfolio theory. It is known that the initial entropy and simple dynamic entropy risk measures are measures of variability. We can replace variance with the initial entropy and simple dynamic entropy risk measures, respectively. The initial entropy risk measure is used to capture ordinary (general) risk, and it is favored by investors, such as the firm’s ordinary business and the shareholders’ interests. The dynamic entropy risk measure is used to depict the tails of risks (extreme events), which is to reduce (or avoid) the impact of extreme events and is favored by regulators and decision makers (see [
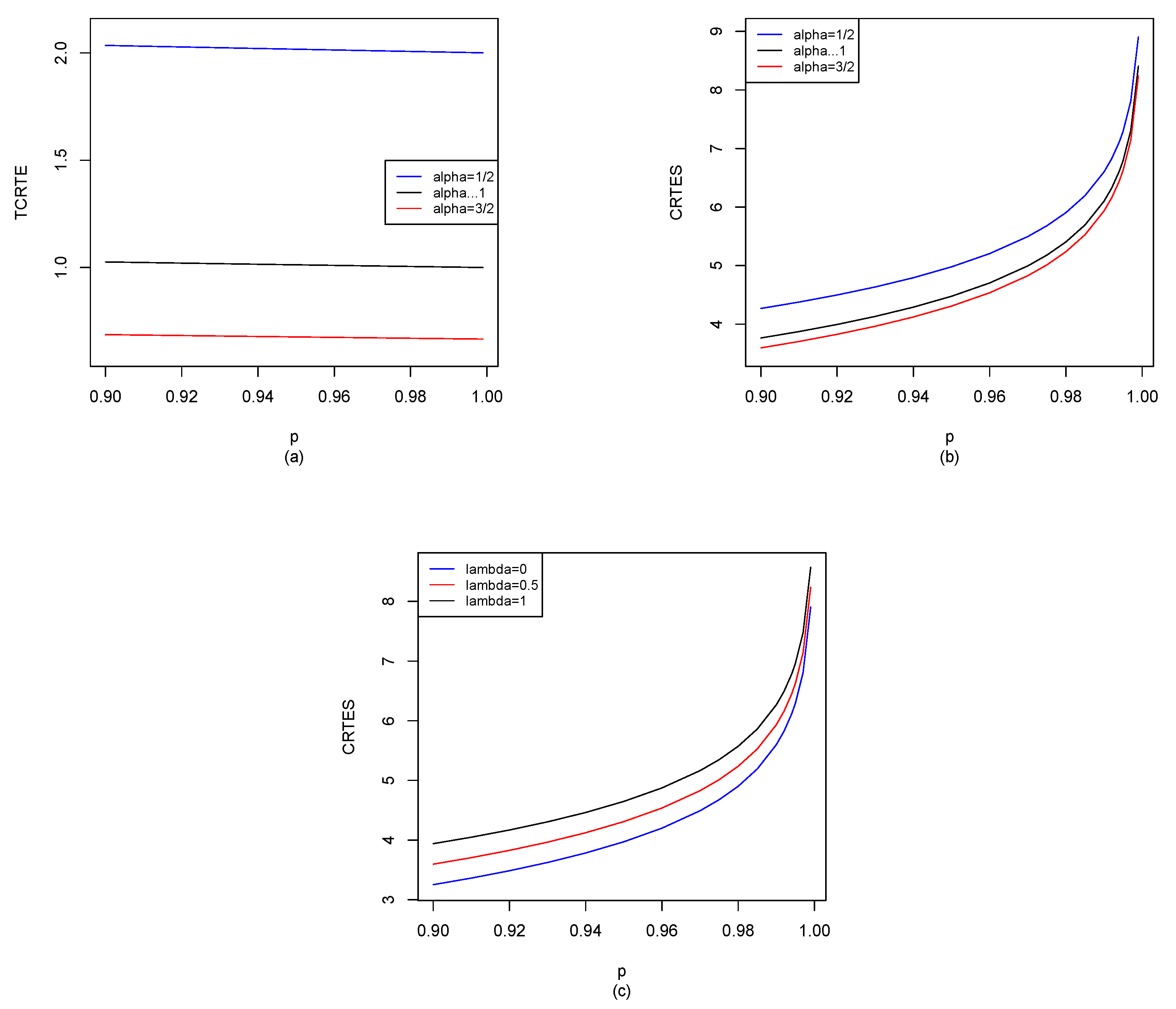
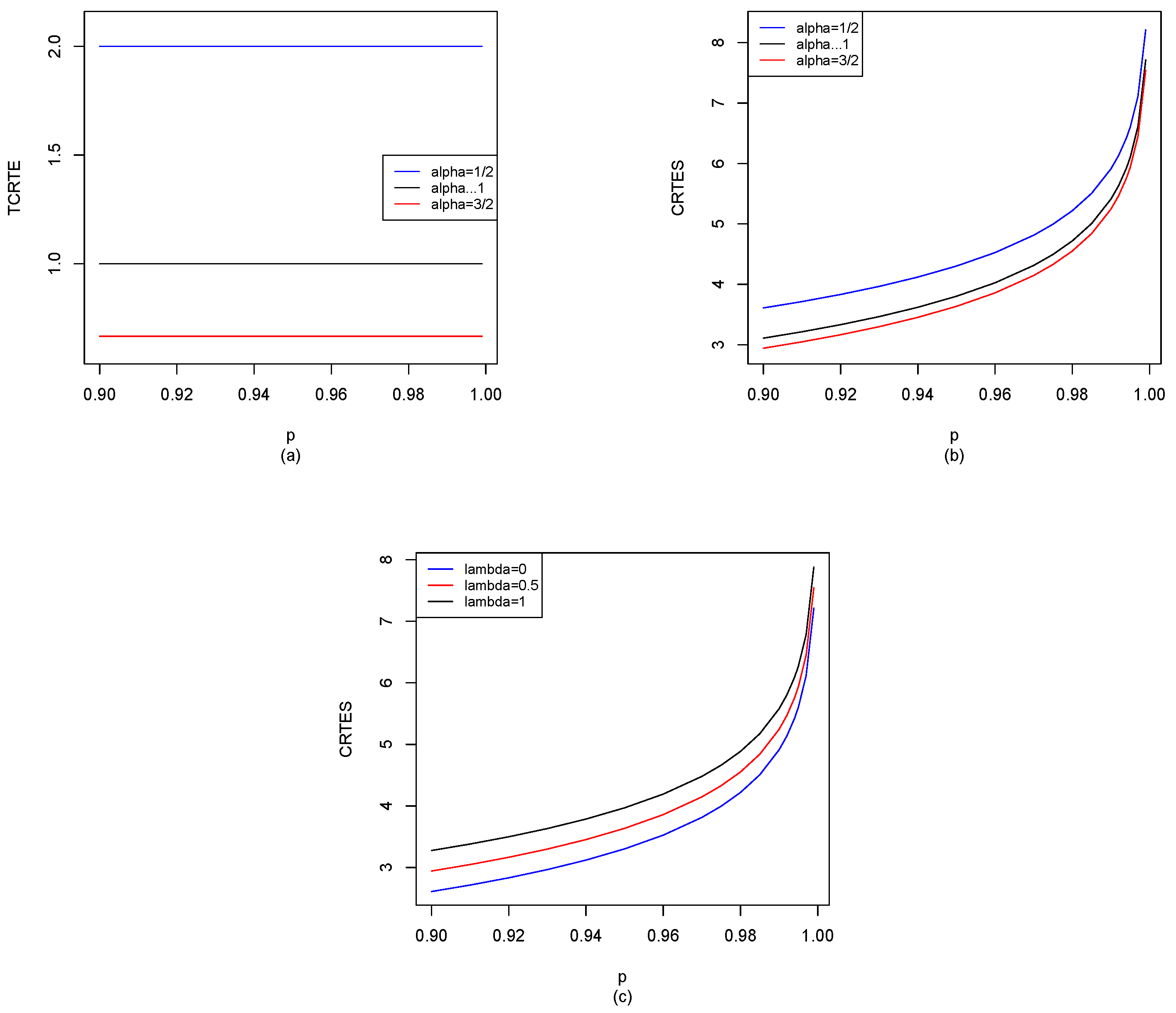
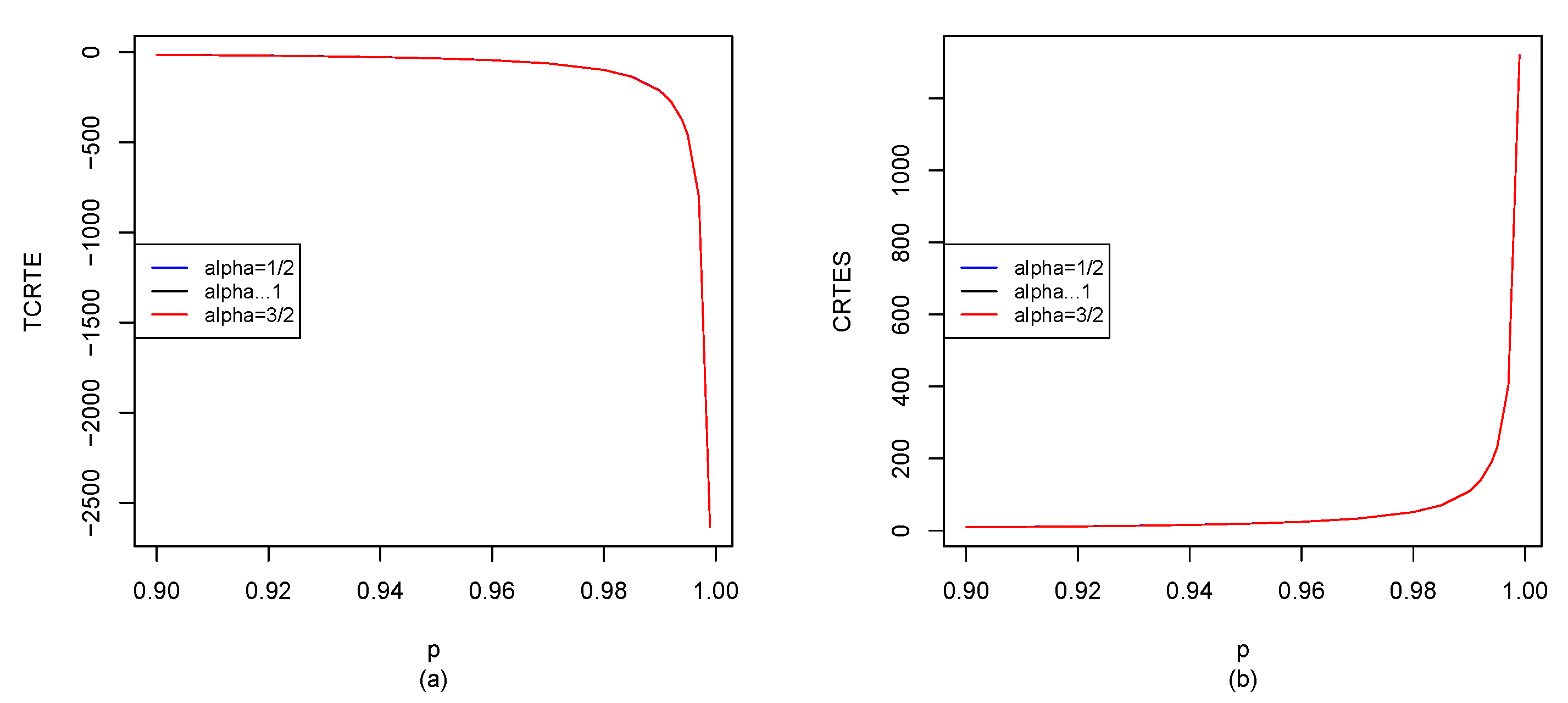
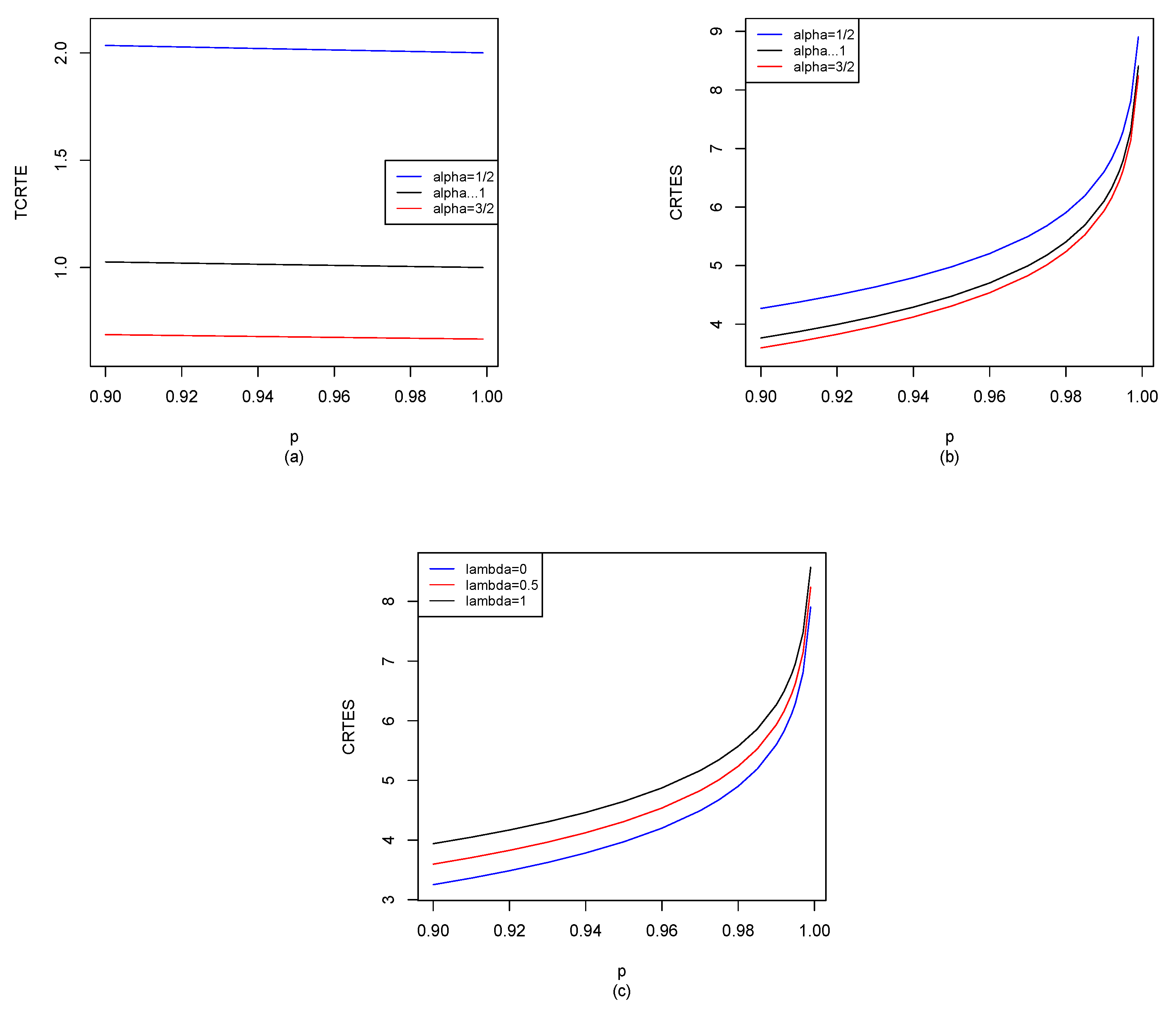
37]). For example, we give
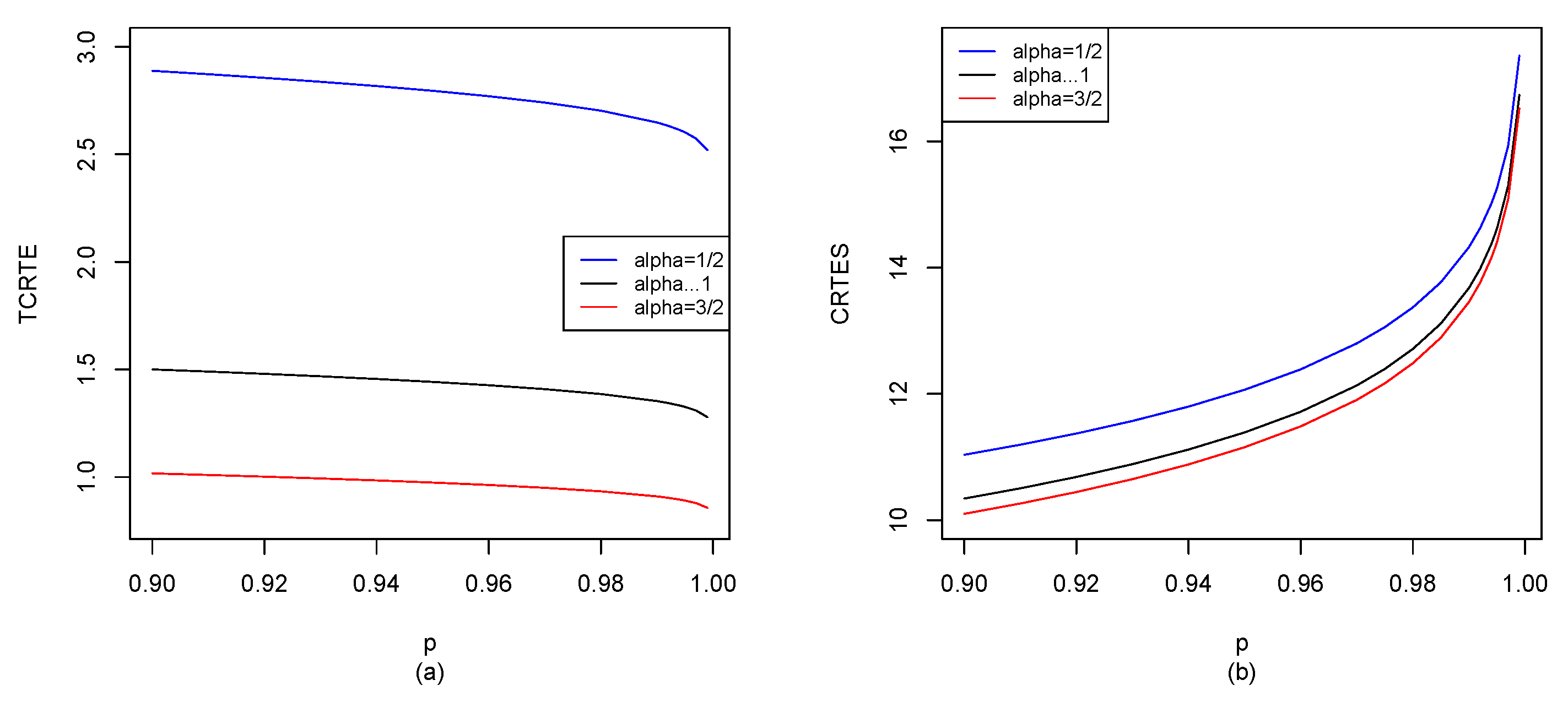
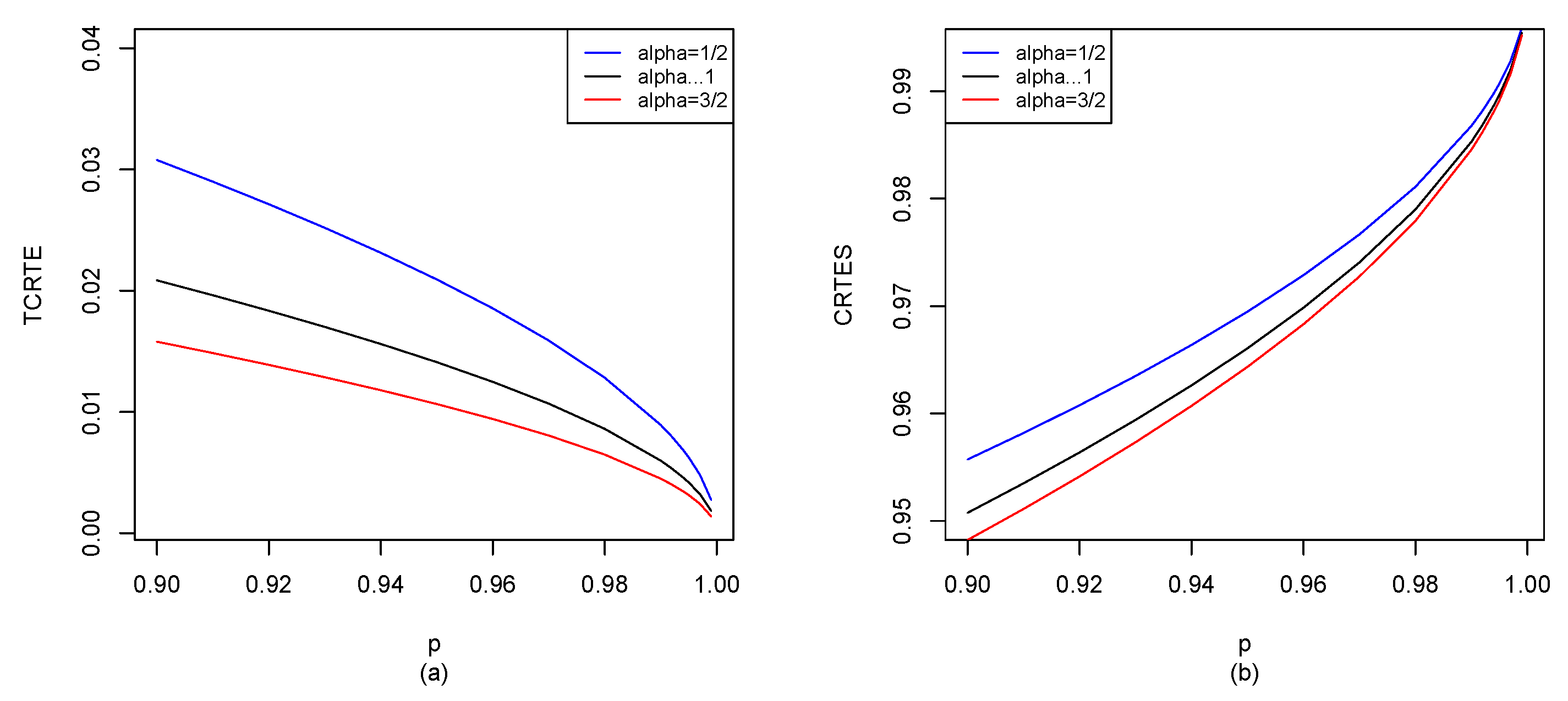
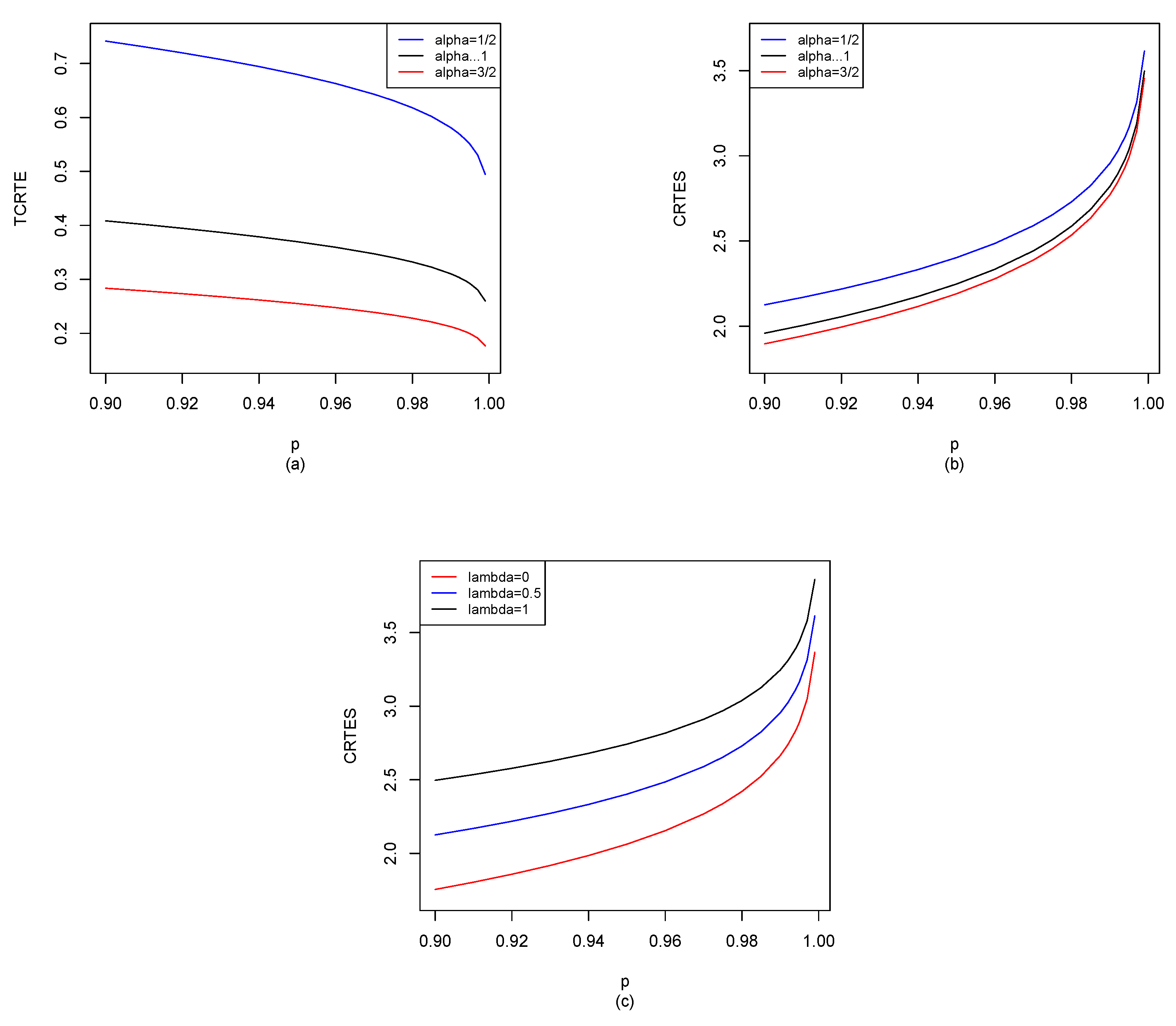
for different distributions in
Section 5, and also use the R software to compute
for
, shown in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8. When
,
reduces to
given by Hu and Chen [
6], we can observe the difference between our results and Hu and Chen’s results through
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8. Other potential applications of these entropy risk measures need to be further explored in the future.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}