1. Introduction
The wiretap channel introduced by Wyner in [
1] and later generalized by Csiszár and Körner in [
2] is the most fundamental channel model that has been used to study broadcast security problems in the context of information theory. One version of this channel model is depicted in
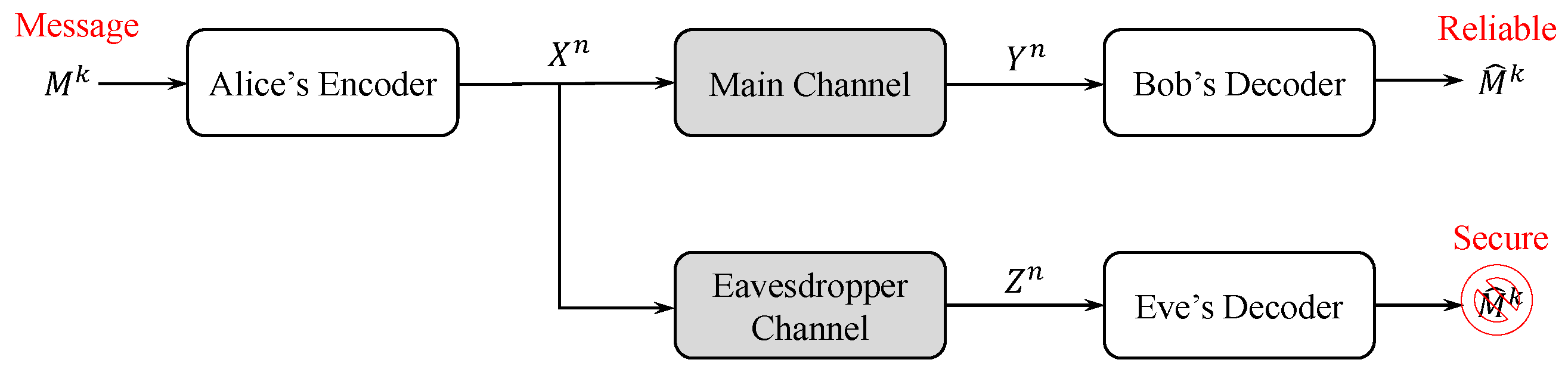
Figure 1, where the confidential communication occurring over a discrete memoryless main channel is observed by an eavesdropper who has access to a noisy version of the channel input. Later, in [
3], Ozarow and Wyner introduced the wiretap channel type II, wherein the eavesdropper is able to select the positions of revealed bits, and they provided a secure coding technique based on coset codes. These channel models have been studied by many authors from the perspectives of security, reliability, and coding construction [
4,
5,
6].
In recent years, coset coding has emerged as an important coding technique in the context of the finite-blocklength regime [
7,
8,
9]. In this regime, the design of the code plays a critical role in achieving high communication rates while balancing the tradeoff between complexity and performance. The effectiveness of coset coding in the finite-blocklength regime has been demonstrated in a wide range of applications, including wiretap channels, broadcast channels, and multiple-access channels [
10,
11,
12,
13,
14].
The
nested linear code construction was first presented in [
15] to generate a diluted version of the original coset code. Later, in [
16,
17], the authors proposed a secure error-correcting code based on the nested code construction for the wiretap channel type II, and in [
18] the authors considered nested codes based on low-density parity-check (LDPC) codes for the original wiretap channel when both the eavesdropper and main channels are binary erasure channels (BECs).
Generalized Hamming weights (GHW) and the dimension/length profile (DLP), which were first introduced in [
19,
20], respectively, were two of the first parameters of linear block codes that could be used to characterize the performance of the original linear coset codes, especially over a wiretap channel of type II. Numerous papers have investigated these parameters on various linear codes [
21,
22,
23,
24,
25,
26]. Later, the authors of [
16,
27] extended these two parameters to nested coding constructions and defined two new formats for them: the relative generalized Hamming weight (RGHW) and relative dimension/length profile (RDLP), which can be used to characterize the security and error-correction performance of nested linear codes. Further studies have shown that with the rank properties of generator and parity-check matrices, the performance of linear codes can also be precisely characterized [
28,
29,
30]. In [
29], we utilized rank properties to create and develop a tool for analyzing finite-blocklength wiretap codes based on coset coding over erasure channels, known as an equivocation matrix.
Designing the most secure nested linear codes, referred to as nested linear secrecy codes, to achieve optimal performance in the-finite blocklength regime is still a challenging task, and there is currently no single solution for creating the best codes in this scenario. Identifying these optimal codes would facilitate a comparison of the tradeoffs between complexity and performance for different codes, providing a benchmark for the optimality of other wiretap code designs.
1.1. Our Contributions
This paper explores the characteristics of nested linear codes in a wiretap channel model where both the main and eavesdropper channels are BECs. A novel approach is proposed to find the optimal nested linear secrecy codes by using a dual relationship between nested linear codes and their dual codes. Essentially, we demonstrate that instead of searching for the best code directly, it can be found by starting with the worst nested linear secrecy code from the dual space, which is easy to identify. The results demonstrate an efficient and fast technique for finding optimal nested linear secrecy codes.
The main contributions of this work can be summarized as follows:
New representation of RGHW: We introduce a new representation of the relative generalized Hamming weight (RGHW) by analyzing the rank properties of parity-check matrices. This innovative approach enables us to accurately predict the security performance of nested linear codes based on rank properties.
Equivalence condition evaluation: A comprehensive evaluation of the equivalence codes for nested linear codes is conducted, along with an exploration of its associated properties.
Exploration of equivocation curves: We explore and evaluate the equivocation curves of nested linear codes. Notably, we discover that these curves can exhibit both convex and concave characteristics simultaneously, a novel observation in the field. This discovery presents an exciting opportunity to concentrate on codes that effectively balance both secrecy and reliability constraints.
Efficient algorithm for best code identification: The main contribution of this paper lies in the development of an algorithm that efficiently identifies the best nested linear secrecy codes. This algorithm surpasses conventional methods in terms of speed and effectiveness.
These contributions not only enrich our understanding of nested linear codes but also enhance their design and deployment for diverse applications.
1.2. Organization of the Paper
The rest of the paper is organized as follows.
Section 2 consists of preliminary details about the channel model and nested linear coding structure.
Section 3 introduces a new expression of the generalized Hamming weight that can be used to quantify the performance of nested linear codes. We also present some properties of nested linear codes in this section.
Section 4 describes the behavior of equivocation curves of the nested linear codes. The novel algorithm for finding the best nested linear secrecy codes is explained in
Section 5.
Section 6 presents a numerical example. In
Section 7, we evaluate the complexity of our proposed algorithm. Finally, in
Section 8, we present our conclusion.
2. Preliminaries
2.1. Notation
In this paper, capital letters represent random variables and matrices, lowercase letters represent realizations of these random variables, and calligraphic letters indicate the discrete alphabets associated with the random variables. The distributions and are probability mass functions. The length of vectors is denoted by superscripts, and sets used as subscripts on matrices specify sub-matrices that include only the columns indexed in the set, i.e., is the sub-matrix of made up of only the columns with indices in the set U. All vectors are row vectors, and all codes are binary. The notation represents a series of integers ranging from 1 to , where . The set represents all possible revealed-bit patterns over n transmitted bits by containing all subsets of , whereas the set indicates the set difference operation and is often read as J delete r.
2.2. Channel Models
Consider the wiretap channel model in
Figure 1. The channels between Alice and Bob and Alice and Eve can be any discrete memoryless channels, but for the purposes of this work, we assume that both channels are BECs, with erasure probabilities of
and
for the main and eavesdropper channels, respectively. In this model, Alice wants to transmit a secret message
, which is assumed to be chosen uniformly at random from the alphabet
, to Bob through the main channel and wishes to keep it secret as much as possible from a passive eavesdropper (Eve). To achieve this, Alice converts
into an
n-bit binary codeword
. The encoding is an invertible one-to-many mapping. This means that no more than one message can be mapped into the same codeword, but each message can be encoded to one of several possible codewords. Bob and Eve observe a noisy version of the transmitted codeword
through each of their channels, which are denoted by
and
, respectively. Thus,
.
There are two main constraints when utilizing coding over this type of wiretap channel.
Here,
and
are the desired secrecy and reliability levels, respectively, which can be defined by the system designer. Concisely, the encoding function that maps secret message
to codeword
should be such that Bob can decode
from
reliably, and at the same time, Eve receives as little information as possible about
from
. The level of secrecy achieved by a code can be quantified by either the average equivocation
or the average leakage
Both of these information-theoretic functions are used to evaluate the performance of a wiretap code in terms of its secrecy. As a result, in this scenario, it is preferable to minimize the average leakage
or maximize the average equivocation
, while also enhancing Bob’s error-correction capabilities, which can be achieved by reducing
.
2.3. Nested Linear Codes
The fundamental concept behind the nested linear coding approach is to partition the main code into sub-codes and employ
overhead bits to aid in secrecy or reliability as desired. The information rate between Alice and Bob is
. Let the number of overhead bits assigned to reliability and secrecy be
and
l, respectively, and let
Let
be an
linear block code and
be an
linear block code. Then, the nested linear code (
,
) is defined, where
is a
fine code with rate
and
is a
coarse code with rate
, where
, satisfying
which means that each codeword of
is also a codeword of
. Let the
matrix
be the generator matrix, and the
matrix
be the parity-check matrix for
. The generator matrix
is defined as follows:
where
is comprised of
k linearly independent rows from
that are not in
and make
a full-rank matrix. The parity-check matrix
also consists of two sub-matrices such that
where
is
and forms a basis for the dual space of the rowspace of
. The dimension of the sub-matrix
is
. It is important to note that according to the algebraic properties of nested linear codes,
and
.
The encoding process begins by selecting an auxiliary message
uniformly at random from
and then computing
where
m is a
k-bit secret message. Now, the fine code
is randomly partitioned into
disjoint subsets (cosets). The term
selects the coset, and the term
selects the specific codeword from the corresponding coset at random.
Bob uses the following decoding approach to retrieve
from
. First, Bob recovers as many erased bits as possible using the parity-check matrix
and obtains an estimated version
of
[
31]. Assuming
, then Bob’s decoder computes the syndrome
S of
as
It is possible to choose matrices such that
is the
identity; therefore,
[
32].
To achieve reliability and/or security, both codes and need to meet specific requirements. In this case, the fine code is primarily responsible for ensuring reliability, while the coarse code is utilized for security purposes. The following section will explore different properties of nested linear codes and examine several parameters that measure the performance of such codes.
3. Performance Parameters
This section explores practical metrics to measure the performance of nested linear codes and examines their properties. Consider the
and
dual codes of
and
and call them
and
, respectively.
uses
as the generator matrix and
as the parity-check matrix. Hence, the nested linear code
,
is the dual code of
,
. In the dual space,
serves as the fine code, and
is the coarse code. The information rate of the nested linear code in both spaces will not change and remains
. However, the secrecy and reliability overhead bits will change in the different spaces. In the dual space,
and
l represent the number of security and reliability bits, respectively [
30].
3.1. RGHW and RDLP
As previously stated, RGHW and RDLP are extended versions of the GHW and DLP, which can be utilized to characterize the security performance of nested linear codes over the wiretap channel of type II. Let J be a subset of . A new representation for the RGHW of the nested linear codes can be given as follows.
Proposition 1. The th relative generalized Hamming weight of the nested code can be written aswhere is a revealed-bit pattern over the erasure channel and and are the number of codewords in and , respectively, that have zeros for all bit locations in the indexed set . Proof. Since
represents the maximum number of bits that can be revealed while still maintaining at least
bits of equivocation, the total number of bits minus the maximum revealed bits must equal the minimum number of bits that must be leaked to reveal at least
bits of information, and the expression (
12) is valid. Thus, Equations (
11) and (
12) represent two equivalent expressions for the
th relative generalized Hamming weight of the nested linear code. □
3.2. Rank Properties and the Equivocation Matrix
Let
, where
is the observation of the
ith bit of the codeword
x over the eavesdropper’s BEC and
denotes an erased bit. Also, let
. According to the results of [
30,
33], we showed that the exact equivocation for the observation
over a binary erasure channel (BEC), given the coding scheme presented in
Section 2.3, is
Thus, in terms of code design for security and reliability, a revealed-bit pattern
is secure if and only if
. Furthermore, for reliability, the message information is obtained if and only if
. The following definition is from [
30].
Definition 1. The equivocation matrix A for the linear block code is a matrix where each entry () counts the number of revealed-bit patterns of size μ that maintain e bits of equivocation.
There are different patterns that can be used to reveal bits of n transmitted codeword bits over the erasure channel, and the bottom left entry of A is .
3.3. Equivalence of Nested Linear Codes
Lemma 1. Let and be two nested linear codes with generator matrices and , respectively. These two nested linear codes are equivalent if there exist two invertible scrambling matrices and and permutation matrix P, such thatwhere and are and full-rank matrices, respectively, and is a zero matrix. Note that, in general, codes are equivalent if the sets of codewords are the same up to the permutation of bit order in the codewords.
Proof. We know that the space spanned by the rows of is the same as the space spanned by the rows of (and similarly for the space spanned by the rows of and ). The multiplication by P changes only the order of bits in codewords and the mapping of specific messages to specific codewords but achieves equivalence. □
Lemma 2. If generator matrices and correspond to respective equivalent nested codes and , then the RGHW, RDLP, and equivocation matrices for the two codes are identical.
Proof. According to Lemma 1, two nested linear codes
and
are equivalent if
can be converted into
using simple linear operations over rows and/or column pivots. These basic operations produce the same set of codewords from the new generator matrices up to a consistent bit permutation in the codeword sets. Thus, (
11) and (
12) are the same for both codes for all
, and the equivalence for the RDLP is similarly trivial. For the equivalence of equivocation matrices, every
for code
maps to a unique revealed-bit pattern for
of the same size such that (
14) is equivalent. □
Previous research, including [
16,
17], has analyzed the bounds on the RGHW and RDLP of nested linear codes
to aid in constructing nested linear secrecy codes. Furthermore, studies such as [
29,
30] enable comparisons between the performance of nested linear codes on specific sizes. Even with these results, the challenge of finding optimal nested linear secrecy codes remains unsolved and requires a brute-force search.
4. Concavity and Convexity of Equivocation Curves
The equivocation quantifies Bob and Eves’ uncertainty about the secret message
after observing
and
, respectively. We may want to maximize the equivocation for security constraints or minimize it for reliability limitations, depending on the system requirements. In the noiseless main channel model where reliability constraints are not considered and all overhead bits are allocated for security purposes, the equivocation of the nested linear code
is always a concave function of
[
32]. However, when both reliability and security are important, such as in the case of a noisy main channel, our simulation results indicate a different behavior compared to the noiseless main channel case.
Lemma 3. Consider the nested linear code of rate and , respectively. Assume that this pair of linear codes is used to transmit a k-bit message m over the binary erasure wiretap channel. The equivocation curve that can be achieved by nested coding construction can be concave, convex, or both as a function of ϵ.
The proof follows directly from Theorem 2.7.4 [
34] and is included here for completeness.
Proof. is a concave function of
, and
If
is fixed, then
is a linear function of
; hence,
is also a concave function of
, and the second term of (
17) is a linear function of
. The difference is then a concave function of
. Moreover, the conditional entropy
of
for a fixed
will be concave, and the difference of two concave functions can either be concave, convex, or both. □
Simulation results show that there are indeed three distinct equivocation curve behaviors for nested linear codes , as follows:
Convex equivocation curve: These codes are appropriate for situations when is small; thus, Alice may purposefully use a nested linear code of this nature to improve Bob’s ability to correct errors.
Concave equivocation curve: If is small, these codes give Alice the ability to keep data as secure as possible from the eavesdropper.
Convex/concave equivocation curve: The more desirable and interesting codes are those that provide both reliability for Bob and confusion for Eve, in scenarios where Bob and Eve experience erasure with different rates. These codes can effectively balance both constraints as required, resulting in a convex/concave equivocation curve.
Simulations of (
1) were completed using (
14) and considering all possible erasure patterns
. Curves were plotted as a function of the erasure probability
, noting that
. This examination of the behavior of equivocation curves enhanced our comprehension of nested linear codes, unveiling the dual relationship between error correction capabilities and security attributes. Furthermore, our simulations demonstrated that the number of overhead bits allocated to security or reliability can have a significant impact on the shape and number of the equivocation curves. In particular, increasing the number of overhead bits allocated to security (
l) can lead to an increase in the number of concave curves. This observation is consistent with the fact that adding more security overhead bits to the code will result in a higher level of confusion for the eavesdropper. Similarly, increasing the number of overhead bits allocated to reliability (
) can lead to an increase in the number of convex curves and affect their shape, as more reliability overhead bits will provide Bob with better error correction capabilities. Overall, our results highlight the importance of carefully balancing the allocation of overhead bits between security and reliability to achieve the desired level of secrecy and reliability for the system. Additionally, we showed that there exist codes that can balance both restrictions effectively (codes with convex/concave equivocation curves).
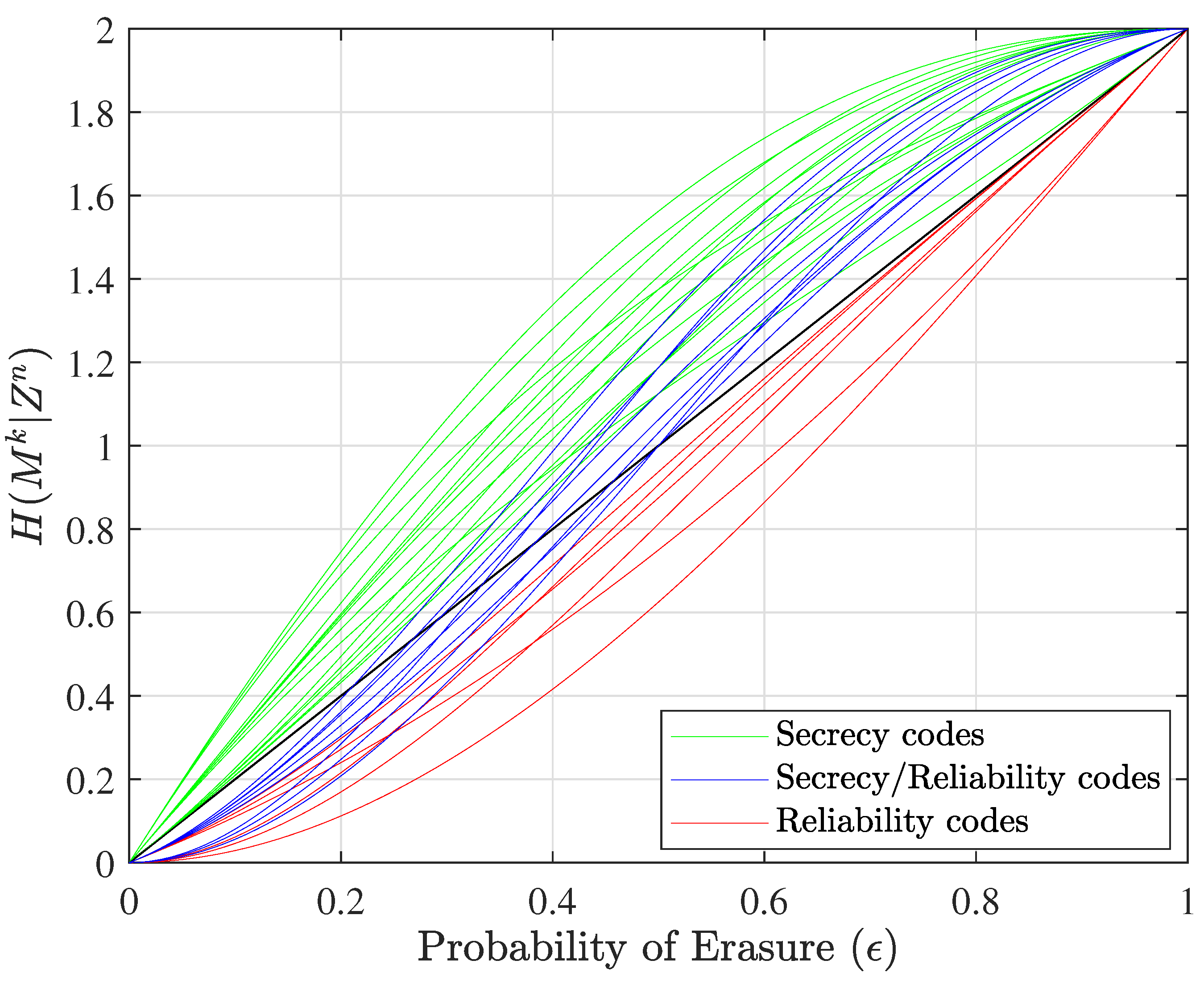
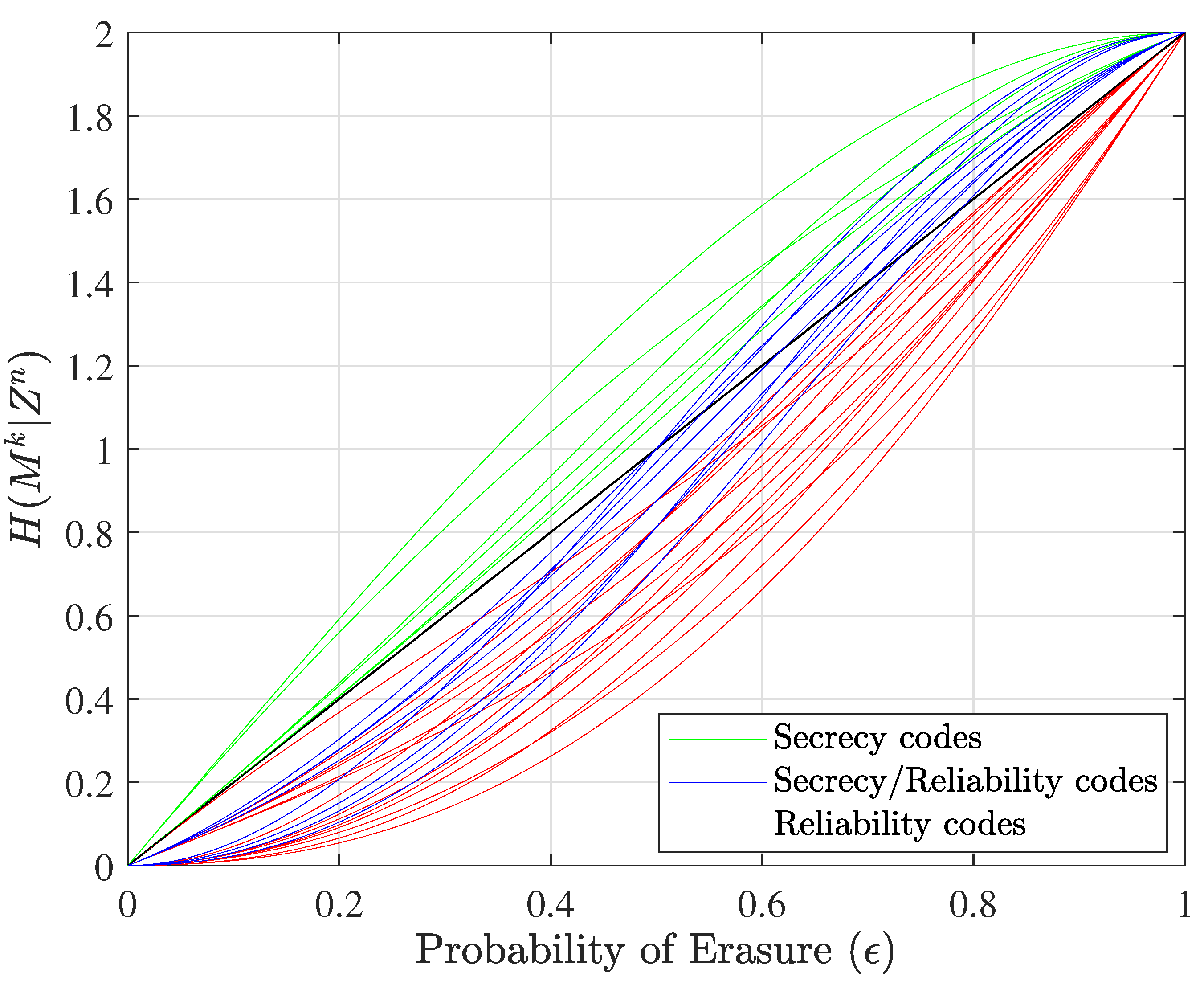
These types of codes are represented, respectively, with red, green, and blue equivocation curves in
Figure 2 for the
,
,
, and
case, and in
Figure 3 for the corresponding dual case, where
l and
change their responsibilities, which means that the number of overhead bits allocated to security will be
, and the number of overhead bits allocated to reliability will be
. This change in the allocation of overhead bits results in a different set of equivocation curves. The probability of erasure,
, refers to both
and
to show performance for all users on the same plot.
5. Finding the Best Nested Linear Secrecy Codes
In this section, we propose a coding construction algorithm to generate the best nested linear secrecy code according to the equivocation by taking advantage of the dual relationship between nested linear codes. In essence, we show that the difficult search for the best code can be computed instead by the easy search for the worst nested linear secrecy code in the dual space. The concept of the
worst and
best refers to nested linear codes with the lowest and highest security level, respectively, among all possible nested linear codes for a particular size. The general algorithm is provided here, and an example is given in
Section 6.
Algorithm 1. This algorithm demonstrates how to construct the best nested linear secrecy codes through the construction of the worst nested linear secrecy codes using the subsequent steps:
The first phase:
- -
Generate the worst secrecy code with generator matrix . The general schematic of the worst can be found in (30) in Section 6. - -
Generate by searching k random vectors from with the following considerations:
- ∗
For most patterns of revealed bits , the rank of should be as large as possible compared to the rank of .
- ∗
should remain a full-rank matrix.
The second phase:
- -
The best generator matrix for security code is equal to the basis of the dual space of the rowspace of .
- -
Choose k rows from a basis of the dual space of as , with a consideration of the following:
- ∗
For most patterns of , the rank of should be equal to the rank of .
- ∗
remains a full-rank matrix.
Proof. According to our result in [
30], it can be deduced that minimizing the equivocation in the dual space of the nested linear codes leads to the maximization of equivocation in the original space of the nested linear code.
In particular, we have:
or, equivalently,
Therefore, by constructing the nested linear code that minimizes the equivocation in the dual space, we can generate the best nested linear secrecy code within the code space. □
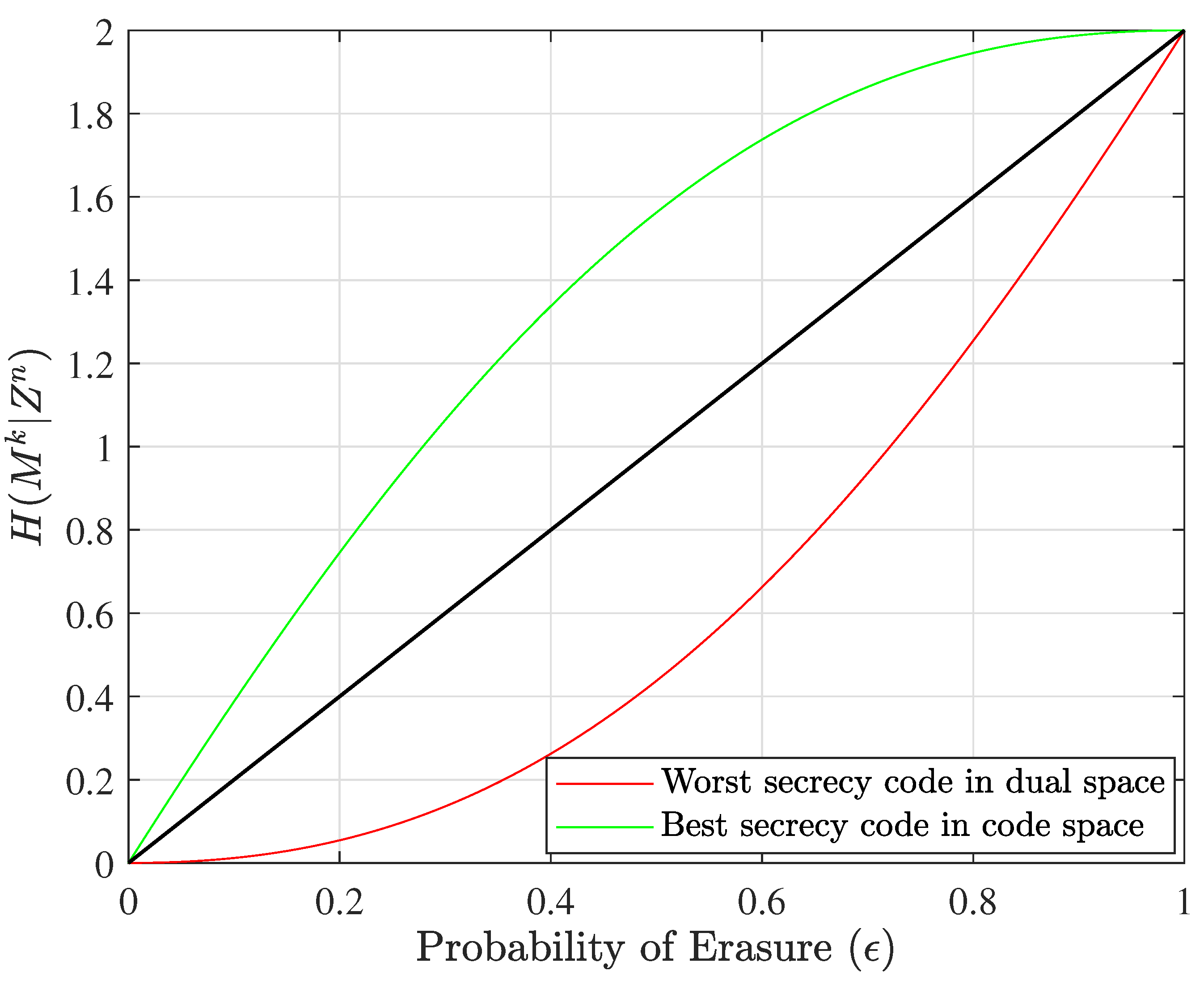
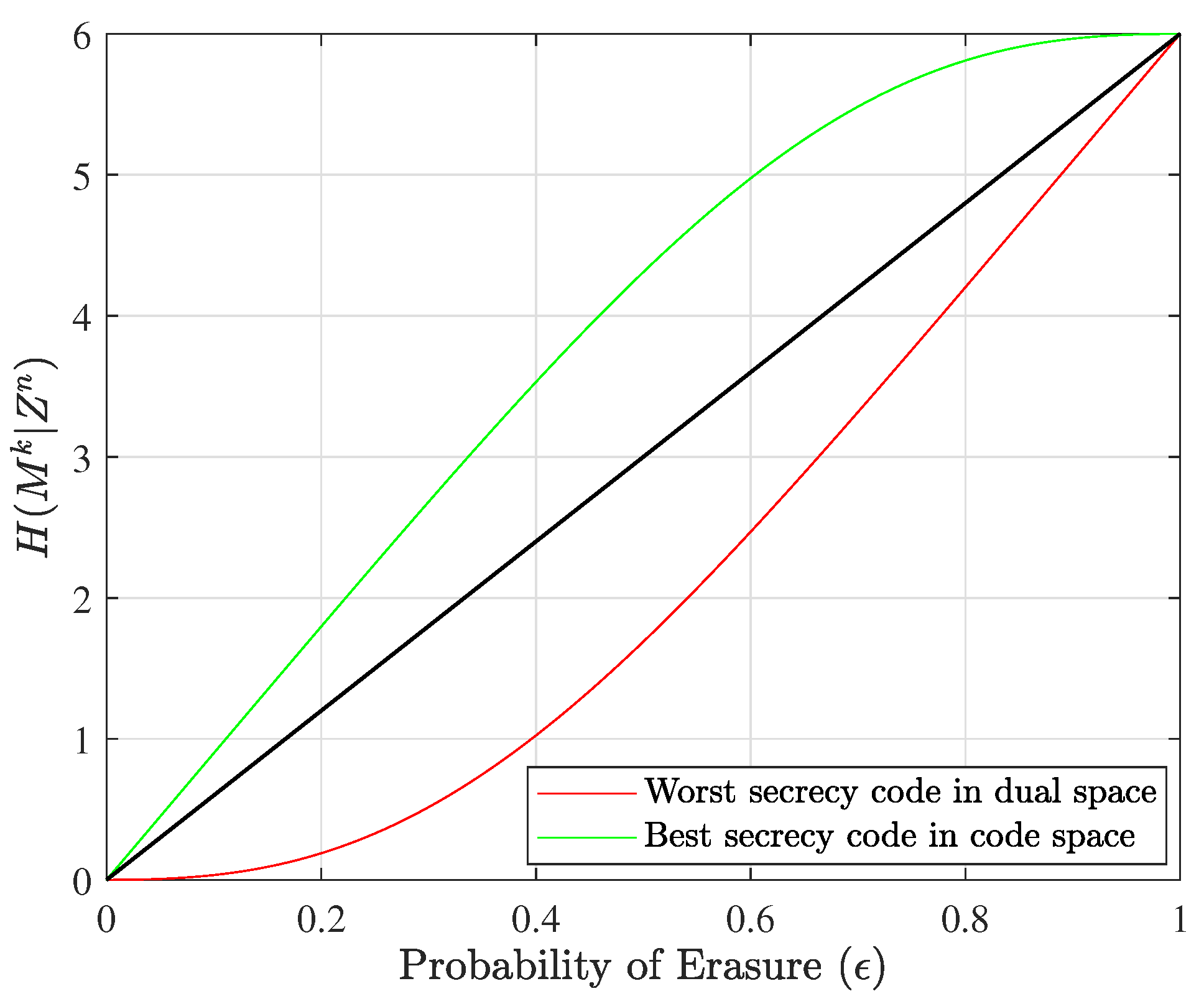
This algorithm can be better understood with reference to an example; hence, the results of this algorithm for a specific size are shown in
Figure 4, and the details of this example are given in the next section.
6. Numerical Example
Consider the nested code
with the rate
and
, respectively. In other words,
,
,
, and
. In this example, the information rate is equal to
. Let
and
The RGHW and equivocation matrix for this nested code are equal to
and for the dual nested code are equal to
Figure 2 illustrates the equivocation curves of all unique nested linear codes in this specific size. It should be noted that the number of green equivocation curves is greater than the number of red equivocation curves because in this example we assume that two of the three overhead bits are assigned to security
and just one bit is assigned to reliability
. If we evaluate nested linear codes in the dual space when
and
, we can see that the number of equivocation curves for nested codes that provide an error-correction capability is greater than the number for nested codes that offer a security capability (green equivocation curves).
Figure 3 shows the equivocation curves for dual nested linear codes.
We now aim to determine how we can identify the optimal nested linear secrecy code
at this specific size using the algorithm outlined in Algorithm 1. To start, we need to build the generator matrix
for code
with the worst rank properties. We know that
must be a full-rank matrix with the most zero columns, which results in a zero rank in most collections of columns. Hence,
is
In general,
where
V and
are the identity and zero matrices, respectively. Then, we need to generate
by searching
k random vectors from
, with the consideration of the specific criteria as mentioned in Algorithm 1. Let
In the second phase, we can generate
from the dual space of
, which is equal to
Now, we need to select
k rows from the basis of the dual space of
as follows:
Additionally, we must be sure that
is a full-rank matrix and
as much as possible for most patterns of
, so
The generator matrix
outperforms other generator matrices in terms of security performance. The equivocation matrix of this example is equal to (
26), and
Figure 4 depicts the equivocation curves of the worst nested linear secrecy codes in the dual space and the best nested linear secrecy codes in the code space.
In the following section, we will analyze the computational complexity of our proposed algorithm for finding the optimal nested linear secrecy code and compare it with the computational complexity of traditional approaches (the brute-force method).
7. Computational Complexity Analysis
The number of distinct generator matrices
that can be chosen such that the resulting matrix is full-rank can be calculated as
where
n is the number of codeword bits and
is the number of overhead bits allocated to the reliability. This equation gives the total number of different nested linear codes (
) for a given size, which for the example explored in
Section 6 is 624,960. However, not all of these nested linear codes are unique. Based on Lemma 1, some nested linear codes may be equivalent and have the same performance, while others are unique and cannot be transformed into each other through equivalent operations on generator matrices. Therefore, the total number of unique nested linear codes can be lower than the total number of different nested linear codes. For the example in the previous section, the number of unique generator matrices
is 256, which is much smaller than the total number of different nested linear codes. However, finding equivalent codes itself is a complex problem, and it is not guaranteed that we can always identify all equivalent codes.
The traditional approach to finding the best nested linear secrecy codes involves a brute-force search over all possible generator matrices , which are . This means that for a given size of nested linear code, all possible generator matrices must be formed and their performance calculated. Then, all codes must be compared based on their equivocation to find the best nested linear secrecy code. Using this approach, generator matrices must be formed. Lemma 1 can be used to identify equivalent generators, but all of them must be examined at some level. In contrast, our proposed approach fixes the matrix in the dual space and only requires a search for different patterns of the matrix , which is , with the consideration of the two restrictions explained in Algorithm 1. We can throw out a number of candidates due to the fixed form of , e.g., matrices with any number of zero columns and/or matrices that do not result in a full-rank . This significantly reduces the search space and computational complexity compared to the traditional approach. Fewer than matrices must be compared.
In summary, our proposed approach of searching for the worst code instead of the best code was shown to be easier and more efficient, requiring fewer resources. This is because the generator matrix of the worst linear code has as many zero columns as possible, making it easier to construct. This improvement in efficiency compared to the full brute-force search method could have important implications for the design of reliable and secure communication systems in practical settings.
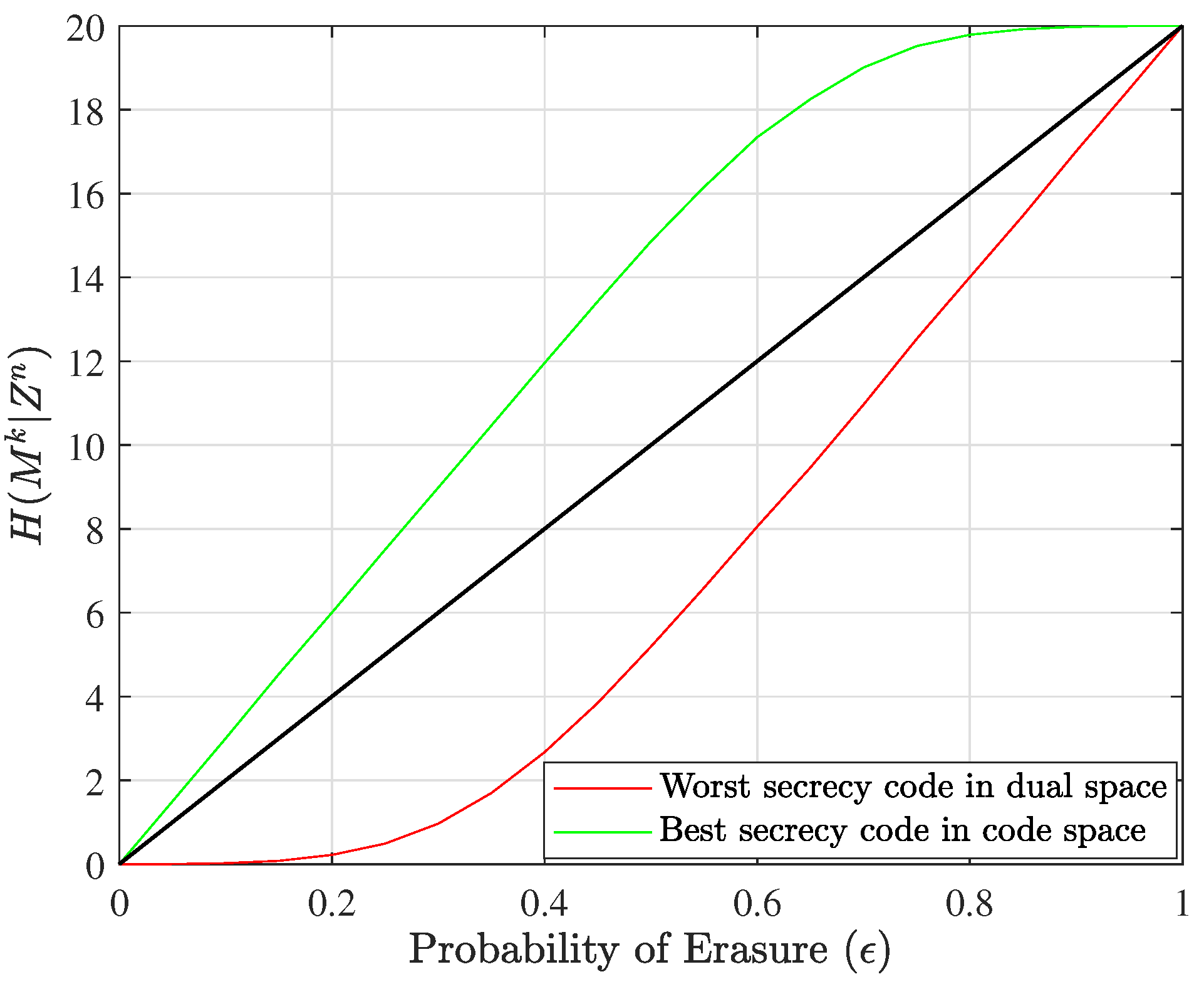
On a personal laptop, it is possible to find best codes up to blocklength 12 with little issue, and we show in
Figure 5 the results for the best and worst nested linear secrecy codes with
,
,
, and
. The best and worst equivocation matrices for this example are given in
Figure 6.
Note that although there is a marked increase in efficiency for identifying best codes by first finding worst codes in the dual space, Algorithm 1 still requires a brute-force search in choosing the elements of
. Thus, for larger code sizes, we still have limitations in finding best codes. In
Figure 7, we present performance curves for one set of candidate codes when
,
,
, and
. The candidate was found by choosing random columns to fill out
and checking for full rank, as depicted in Algorithm 1. We leave the identification of large optimal codes as an open problem.
8. Conclusions and Future Study
In this study, we analyzed the properties of nested linear codes in the presence of a noisy wiretap channel model and derived a new expression for the relative generalized Hamming weight of these codes. We showed that there are three distinct behaviors in terms of equivocation in this coding scheme. Moreover, we proposed a code design algorithm to find the worst nested linear secrecy code, which is constructed by identifying the code with the lowest security in the dual space. Our results demonstrated that this approach is more efficient and quicker in producing optimal nested linear secrecy codes compared to brute-force methods.
Overall, the findings of this paper contribute to the development of reliable and secure communication systems in practical settings. The ability to efficiently design secure nested linear codes can enhance the privacy and security of communication channels, which is of great importance in various applications, such as wireless communication, network security, and cryptography. Future work could explore the applicability of our proposed algorithm to larger blocklengths and investigate its performance in other channel models.
Author Contributions
Conceptualization, M.S. and W.H.; methodology, M.S.; visualization, M.S.; validation, M.S. and W.H.; formal analysis, M.S.; investigation, M.S.; writing—original draft preparation, M.S.; writing—review and editing, W.H.; supervision, W.H.; funding acquisition, W.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation, grant number 1910812.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| BEC | Binary erasure channel |
| LDPC | Low-density parity-check |
| GHW | Generalized Hamming weights |
| DLP | Dimension/length profile |
| RGHW | Relative generalized Hamming weight |
| RDLP | Relative dimension/length profile |
References
- Wyner, A.D. The Wire-Tap channel. Bell Syst. Tech. J. 1975, 54, 1355–1387. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Broadcast channels with confidential messages. IEEE Trans. Inf. Theory 1978, 24, 339–348. [Google Scholar] [CrossRef]
- Ozarow, L.H.; Wyner, A.D. Wire-tap channel II. AT&T Bell Lab. Tech. J. 1984, 63, 2135–2157. [Google Scholar] [CrossRef]
- Wei, Y.P.; Ulukus, S. Polar Coding for the General Wiretap Channel With Extensions to Multiuser Scenarios. IEEE J. Sel. Areas Commun. 2016, 34, 278–291. [Google Scholar] [CrossRef]
- Harrison, W.K.; Shoushtari, M. On Caching with Finite Blocklength Coding for Secrecy over the Binary Erasure Wiretap Channel. In Proceedings of the Wireless Telecommunications Symposium (WTS), San Francisco, CA, USA, 21–23 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Shoushtari, M.; Arabian, F.; Harrison, W.K. On the Crucial Role of Information Theory in the Metaverse. In Proceedings of the 2023 Intermountain Engineering, Technology and Computing (IETC), Provo, UT, USA, 12–13 May 2023; pp. 77–82. [Google Scholar] [CrossRef]
- Sheng, Z.; Tuan, H.D.; Nasir, A.A.; Poor, H.V. PLS for Wireless Interference Networks in the Short Blocklength Regime with Strong Wiretap Channels. In Proceedings of the IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, W.; Schaefer, R.F.; Poor, H.V. Finite-blocklength bounds for wiretap channels. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 3087–3091. [Google Scholar] [CrossRef]
- Taleb, K.; Benammar, M. On the information leakage of finite block-length wiretap polar codes. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Virtual Event, 12–20 July 2021; pp. 61–65. [Google Scholar] [CrossRef]
- Harrison, W.K.; Bloch, M.R. Attributes of Generators for Best Finite Blocklength Coset Wiretap Codes over Erasure Channels. In Proceedings of the International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 827–831. [Google Scholar] [CrossRef]
- Padakandla, A.; Pradhan, S.S. Achievable Rate Region for Three User Discrete Broadcast Channel Based on Coset Codes. IEEE Trans. Inf. Theory 2018, 64, 2267–2297. [Google Scholar] [CrossRef]
- Shoushtari, M.; Harrison, W. Secrecy coding in the integrated network enhanced telemetry (iNET). In Proceedings of the International Telemetering Conference (ITC), International Foundation for Telemetering, Las Vegas, NV, USA, 25–28 October 2021. [Google Scholar]
- Harrison, W.K.; Almeida, J.; Bloch, M.R.; McLaughlin, S.W.; Barros, J. Coding for Secrecy: An Overview of Error-Control Coding Techniques for Physical-Layer Security. IEEE Signal Process. Mag. 2013, 30, 41–50. [Google Scholar] [CrossRef]
- Shoushtari, M.; Arabian, F.; Harrison, W.K. Post-Quantum Cryptography Based on Codes: A Game Changer for Secrecy in Aeronautical Mobile Telemetry. In Proceedings of the International Telemetering Conference (ITC), International Foundation for Telemetering, Phoenix, AZ, USA, 25–28 October 2022. [Google Scholar]
- Zamir, R.; Shamai, S.; Erez, U. Nested linear/lattice codes for structured multiterminal binning. IEEE Trans. Inf. Theory 2002, 48, 1250–1276. [Google Scholar] [CrossRef]
- Luo, Y.; Mitrpant, C.; Vinck, A.; Chen, K. Some new characters on the wire-tap channel of type II. IEEE Trans. Inf. Theory 2005, 51, 1222–1229. [Google Scholar] [CrossRef]
- Liu, R.; Liang, Y.; Poor, H.V.; Spasojevic, P. Secure Nested Codes for Type II Wiretap Channels. In Proceedings of the IEEE Information Theory Workshop (ITW), Solstrand, Norway, 1–6 July 2007; pp. 337–342. [Google Scholar] [CrossRef]
- Thangaraj, A.; Dihidar, S.; Calderbank, A.R.; McLaughlin, S.W.; Merolla, J. Applications of LDPC Codes to the Wiretap Channel. IEEE Trans. Inf. Theory 2007, 53, 2933–2945. [Google Scholar] [CrossRef]
- Wei, V.K. Generalized Hamming weights for linear codes. IEEE Trans. Inf. Theory 1991, 37, 1412–1418. [Google Scholar] [CrossRef]
- Forney, G. Dimension/length profiles and trellis complexity of linear block codes. IEEE Trans. Inf. Theory 1994, 40, 1741–1752. [Google Scholar] [CrossRef]
- Heijnen, P.; Pellikaan, R. Generalized Hamming weights of q-ary Reed-Muller codes. IEEE Trans. Inf. Theory 1998, 44, 181–196. [Google Scholar] [CrossRef]
- Cheng, J.; Chao, C.C. On generalized Hamming weights of binary primitive BCH codes with minimum distance one less than a power of two. IEEE Trans. Inf. Theory 1997, 43, 294–298. [Google Scholar] [CrossRef]
- Feng, G.; Tzeng, K.; Wei, V. On the generalized Hamming weights of several classes of cyclic cods. IEEE Trans. Inf. Theory 1992, 38, 1125–1130. [Google Scholar] [CrossRef]
- Rajaraman, V.; Thangaraj, A. EG-LDPC codes for the erasure wiretap channel. In Proceedings of the National Conference on Communications (NCC), Chennai, India, 29–31 January 2010; pp. 1–5. [Google Scholar] [CrossRef]
- Bras-Amoros, M.; Lee, K.; Vico-Oton, A. New Lower Bounds on the Generalized Hamming Weights of AG Codes. IEEE Trans. Inf. Theory 2014, 60, 5930–5937. [Google Scholar] [CrossRef]
- Yang, M.; Li, J.; Feng, K.; Lin, D. Generalized Hamming Weights of Irreducible Cyclic Codes. IEEE Trans. Inf. Theory 2015, 61, 4905–4913. [Google Scholar] [CrossRef]
- Kurihara, J.; Uyematsu, T.; Matsumoto, R. Secret Sharing Schemes Based on Linear Codes Can Be Precisely Characterized by the Relative Generalized Hamming Weight. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2012, E95.A, 2067–2075. [Google Scholar] [CrossRef]
- Al-Hassan, S.; Ahmed, M.; Tomlinson, M. Extension of the parity check matrix to construct the best equivocation codes for syndrome coding. In Proceedings of the Global Information Infrastructure and Networking Symposium (GIIS), Montreal, QC, Canada, 15–19 September 2014; pp. 1–3. [Google Scholar] [CrossRef]
- Harrison, W.K.; Bloch, M.R. On Dual Relationships of Secrecy Codes. In Proceedings of the Allerton Conf. Communication, Control, Computing, Monticello, IL, USA, 2–5 October 2018; pp. 366–372. [Google Scholar] [CrossRef]
- Shoushtari, M.; Harrison, W.K. New Dual Relationships for Error-Correcting Wiretap Codes. In Proceedings of the IEEE Information Theory Workshop (ITW), Kanazawa, Japan, 17–21 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Richardson, T.; Urbanke, R. Modern Coding Theory; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar] [CrossRef]
- Pfister, J.; Gomes, M.A.C.; Vilela, J.P.; Harrison, W.K. Quantifying equivocation for finite blocklength wiretap codes. In Proceedings of the IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Harrison, W.K. Exact Equivocation Expressions for Wiretap Coding Over Erasure Channel Models. IEEE Commun. Lett. 2020, 24, 2687–2691. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}