
Precision Machine Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Problem Setting
1.2. Decomposition of Loss
1.3. Importance of Scaling Exponents
1.4. Organization
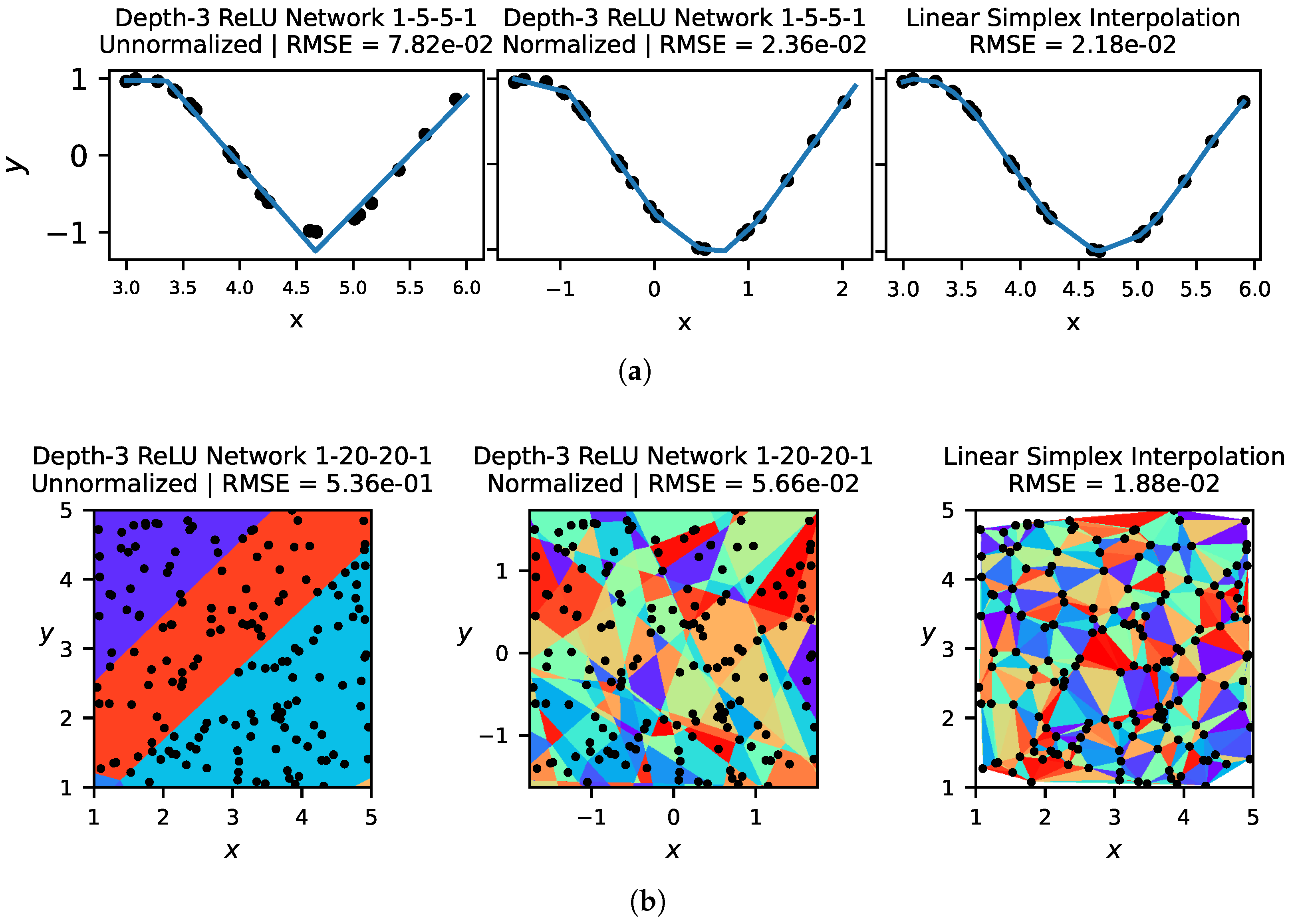
2. Piecewise Linear Methods
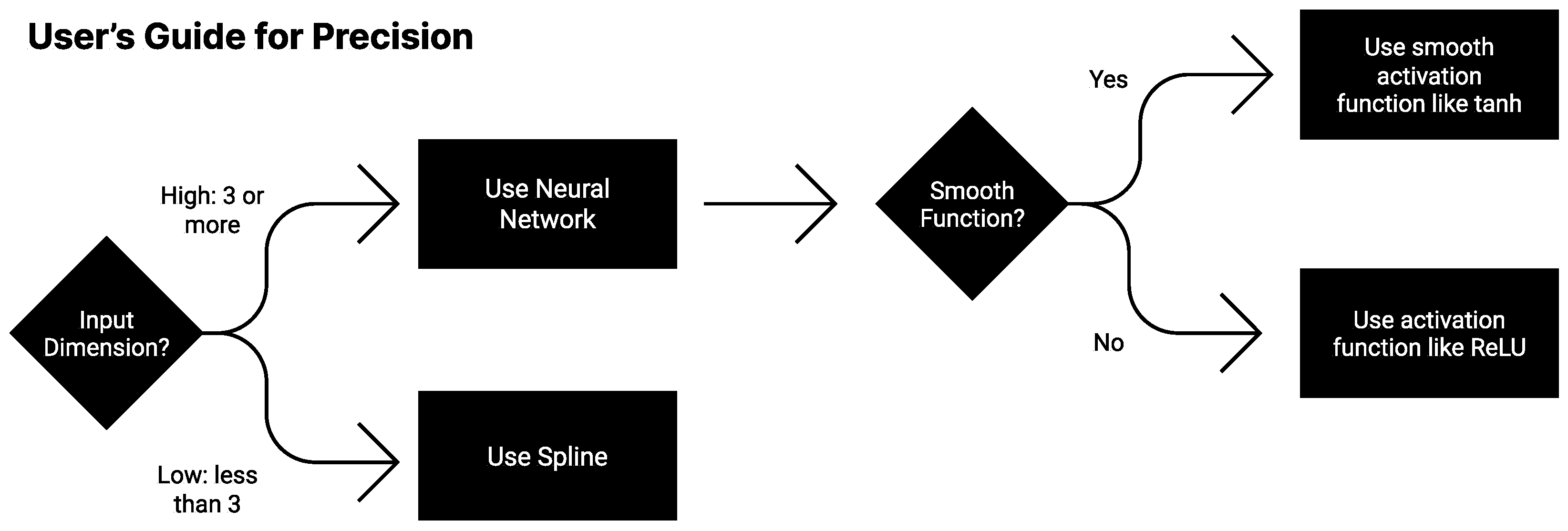
3. Nonlinear Methods
4. Optimization
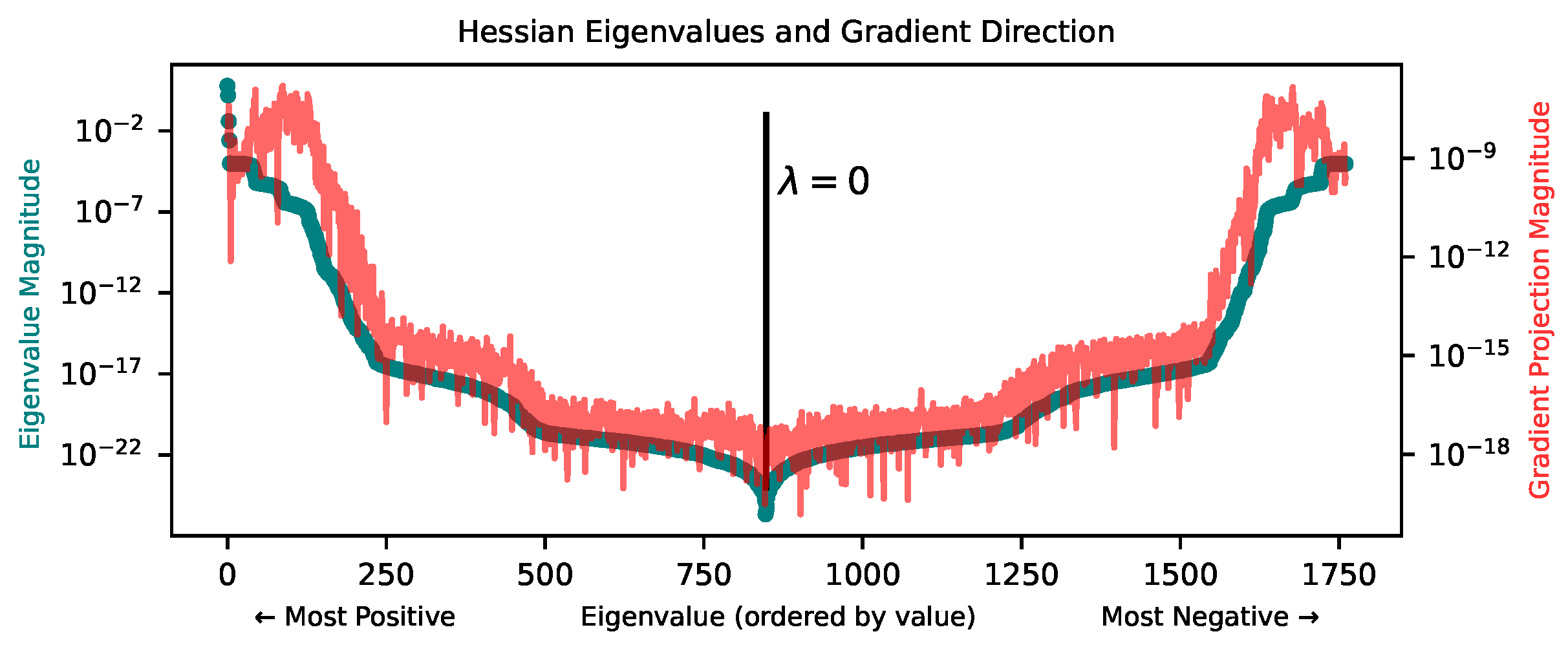
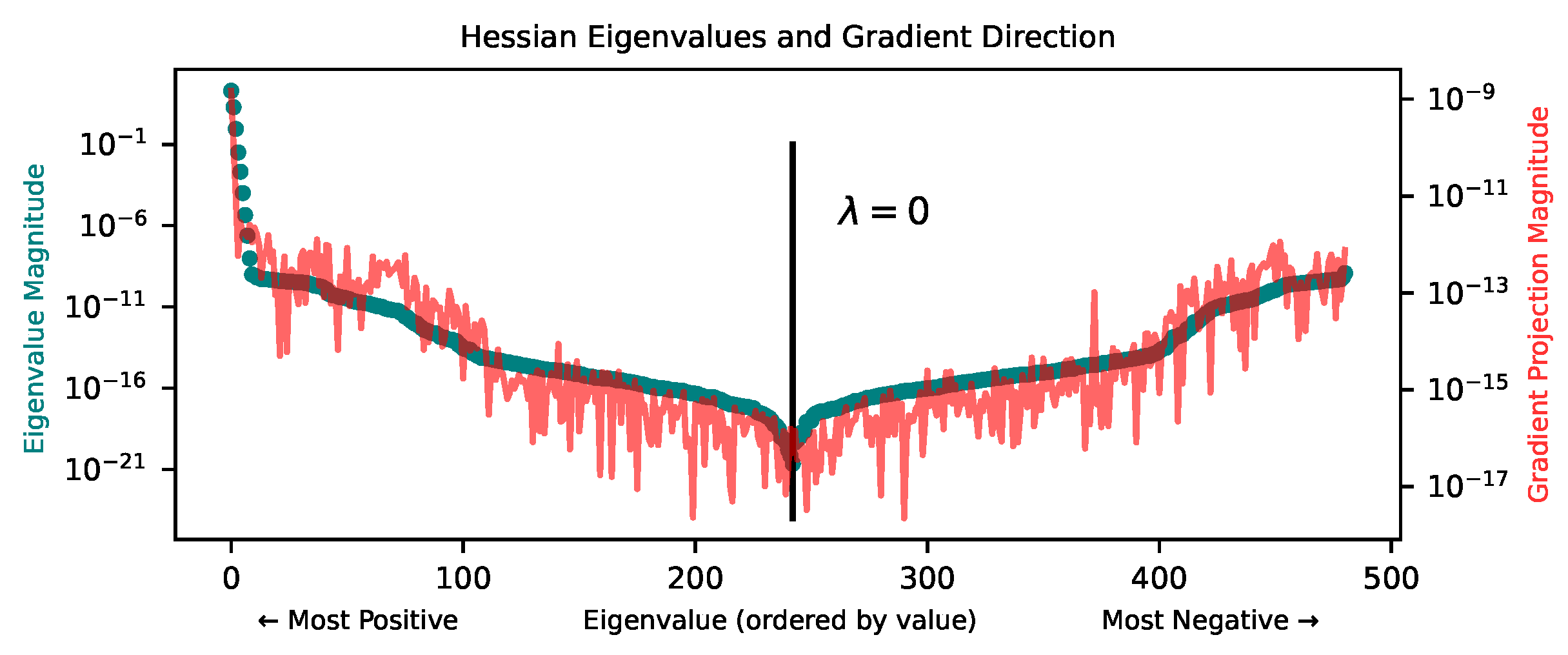
4.1. Properties of Loss Landscape
4.2. Optimization Tricks for Reducing Optimization Error
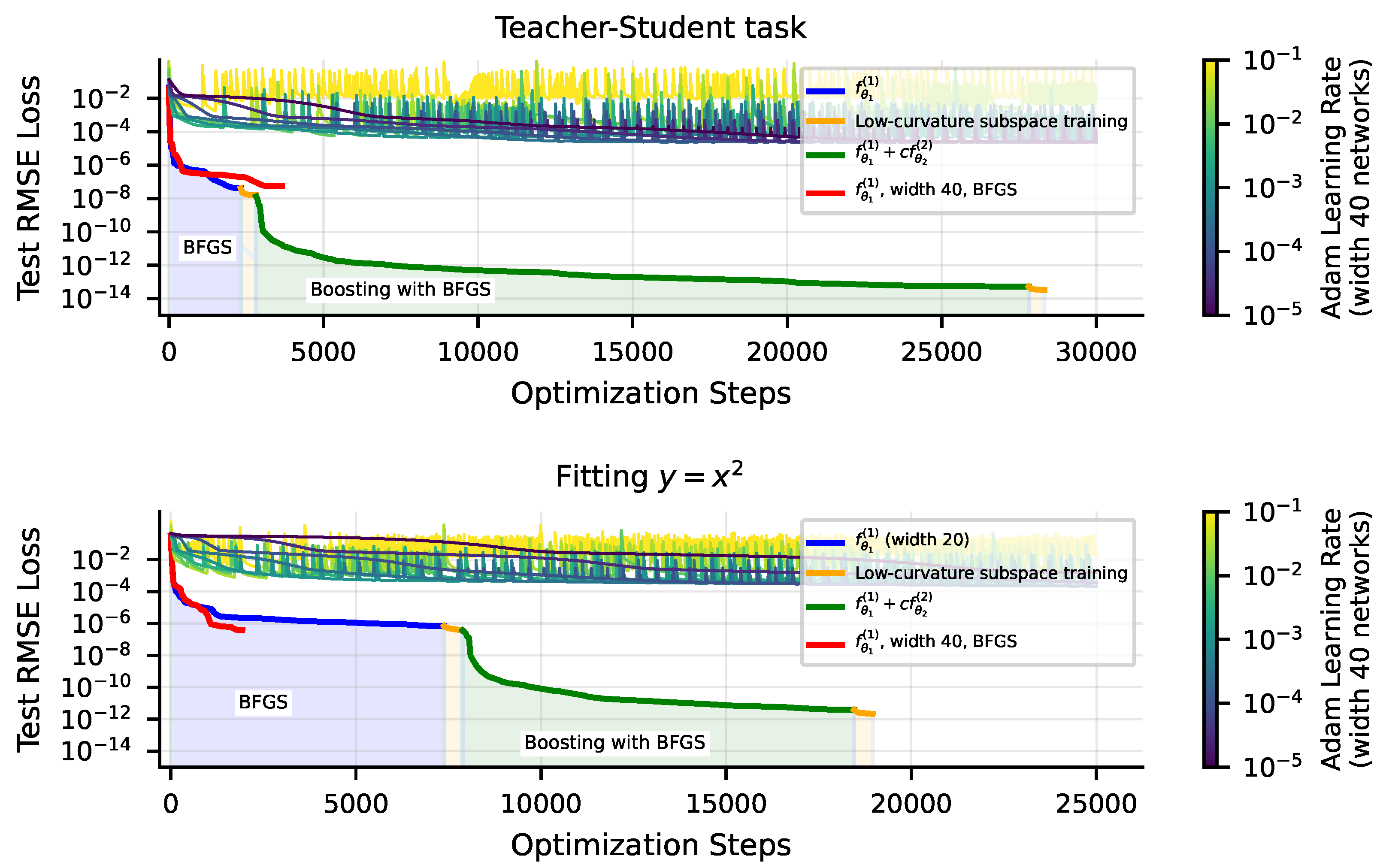
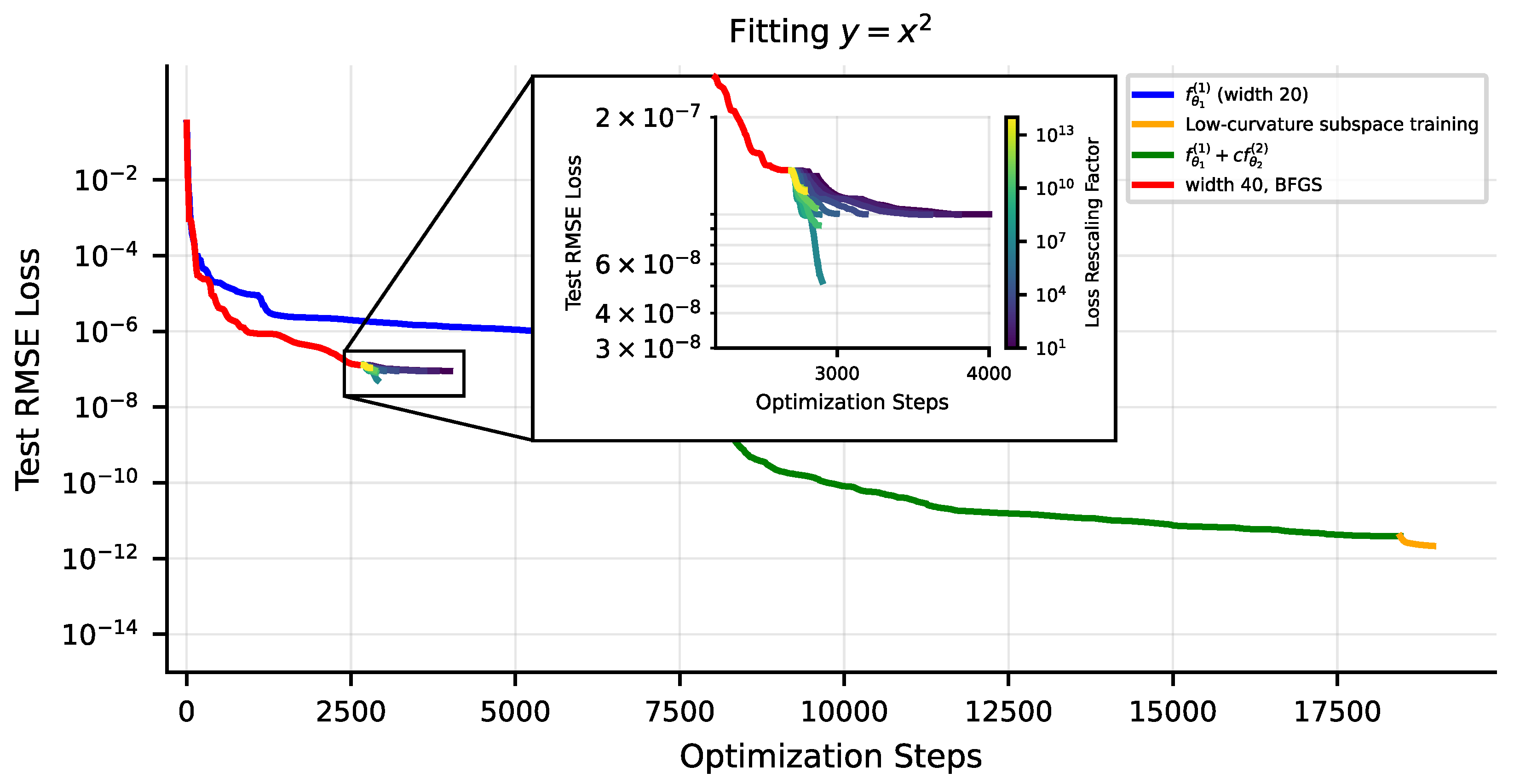
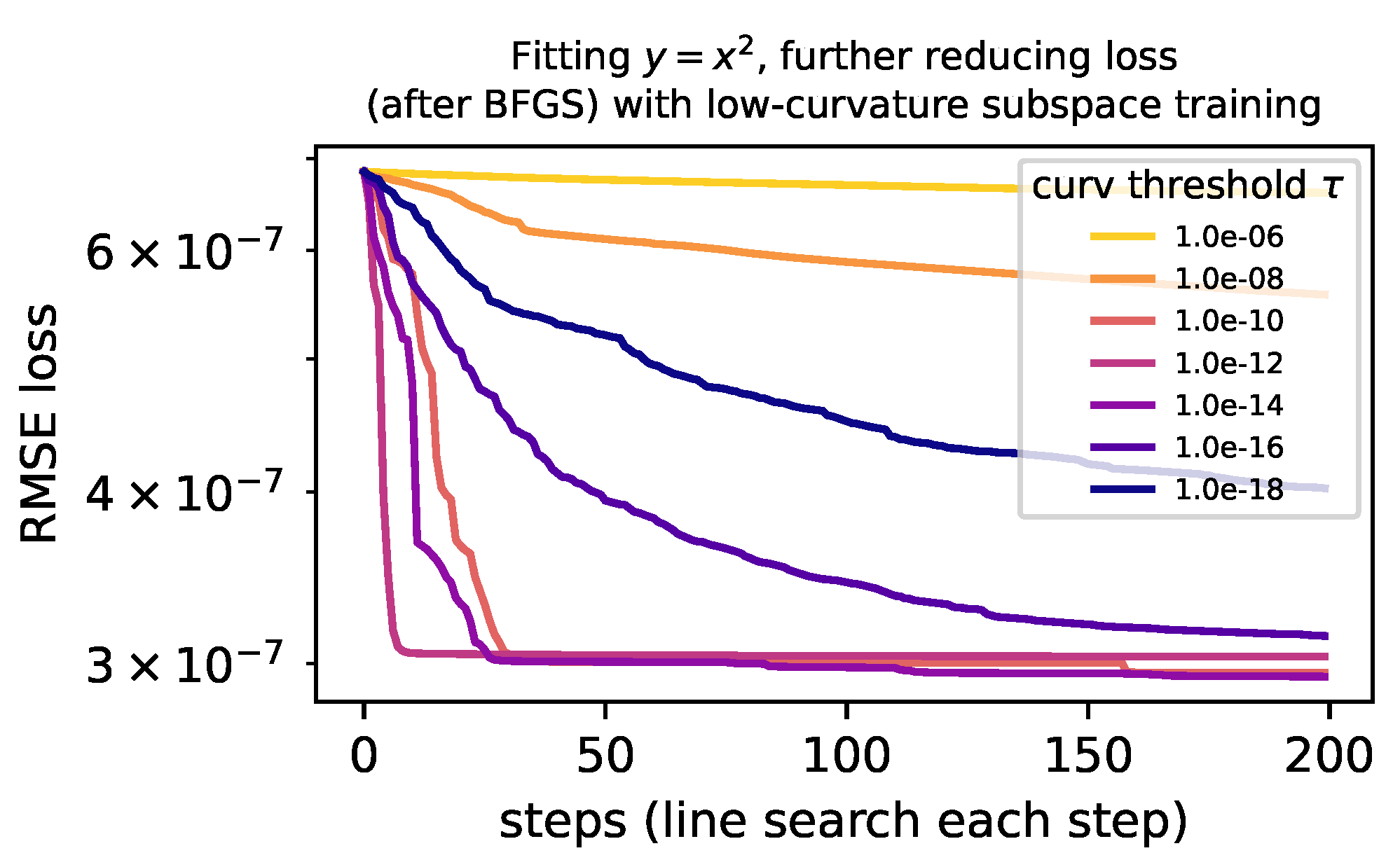
4.2.1. Low-Curvature Subspace Optimization
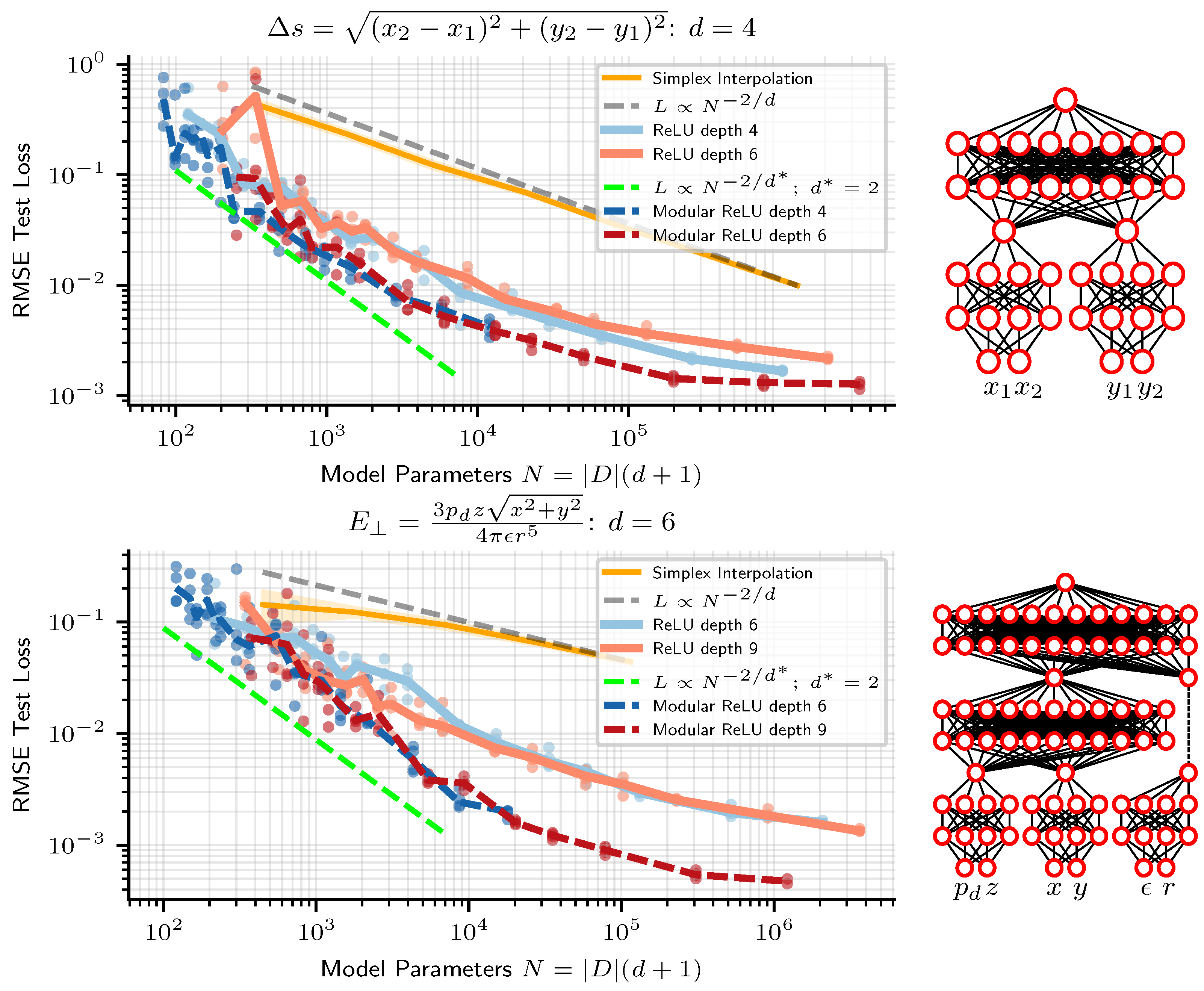
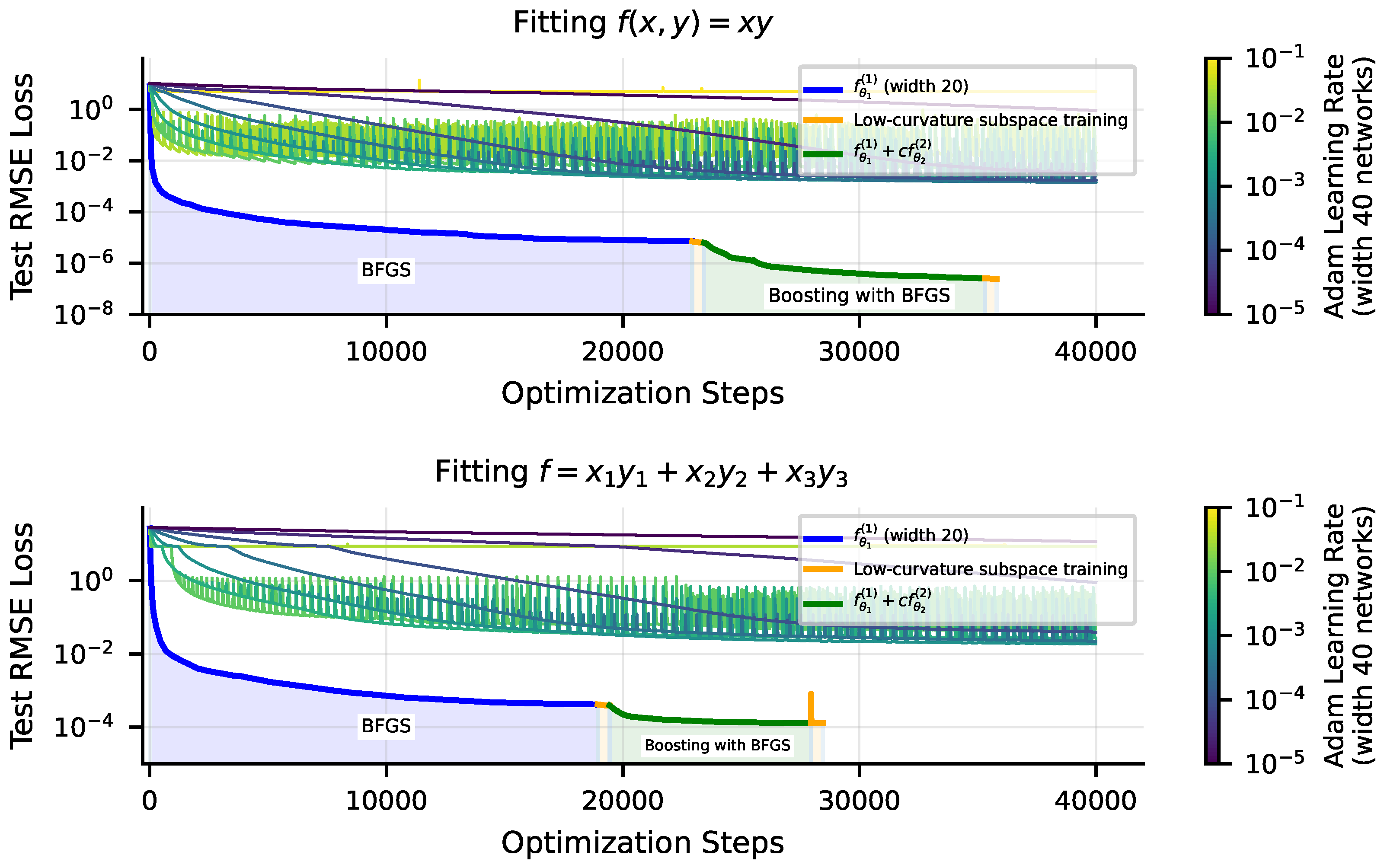
4.2.2. Boosting: Staged Training of Neural Networks
4.3. Limitations and Outlook
5. Conclusions
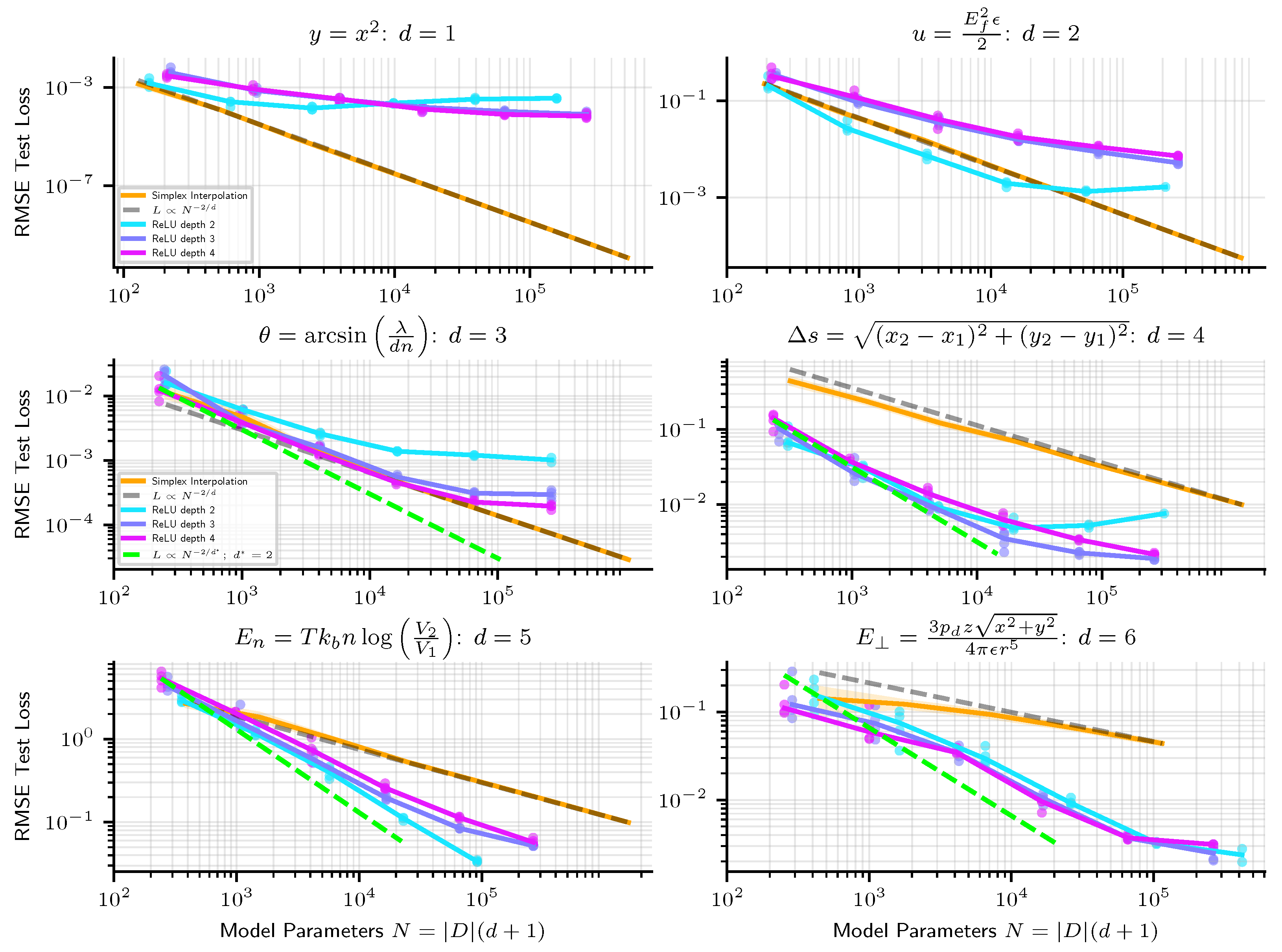
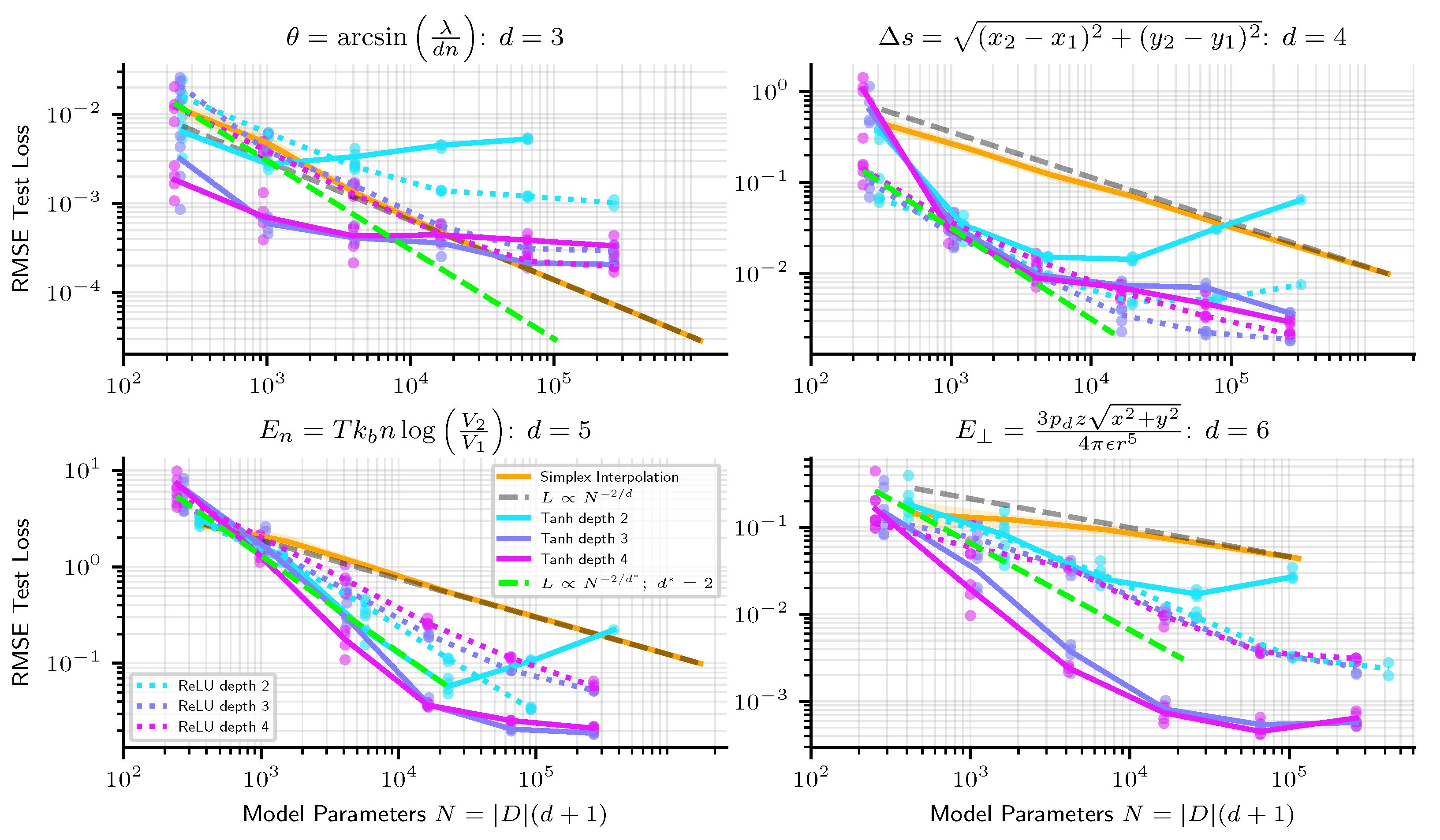
- Linear Simplex Interpolation provides a piecewise linear fit to data, with RMSE loss scaling reliably as . Linear simplex interpolation always fits the training points exactly, and so error comes from the generalization gap and the architecture error.
- ReLU Neural Networks also provide a piecewise linear fit to data. Their performance (RMSE loss) often scales as , where is the maximum arity of the task (typically ). Accordingly, they can scale better than linear simplex interpolation when . Unfortunately, they are often afflicted by optimization error making them scale worse than linear simplex interpolation on 1D and 2D problems, and even in higher dimensions in the large-network limit.
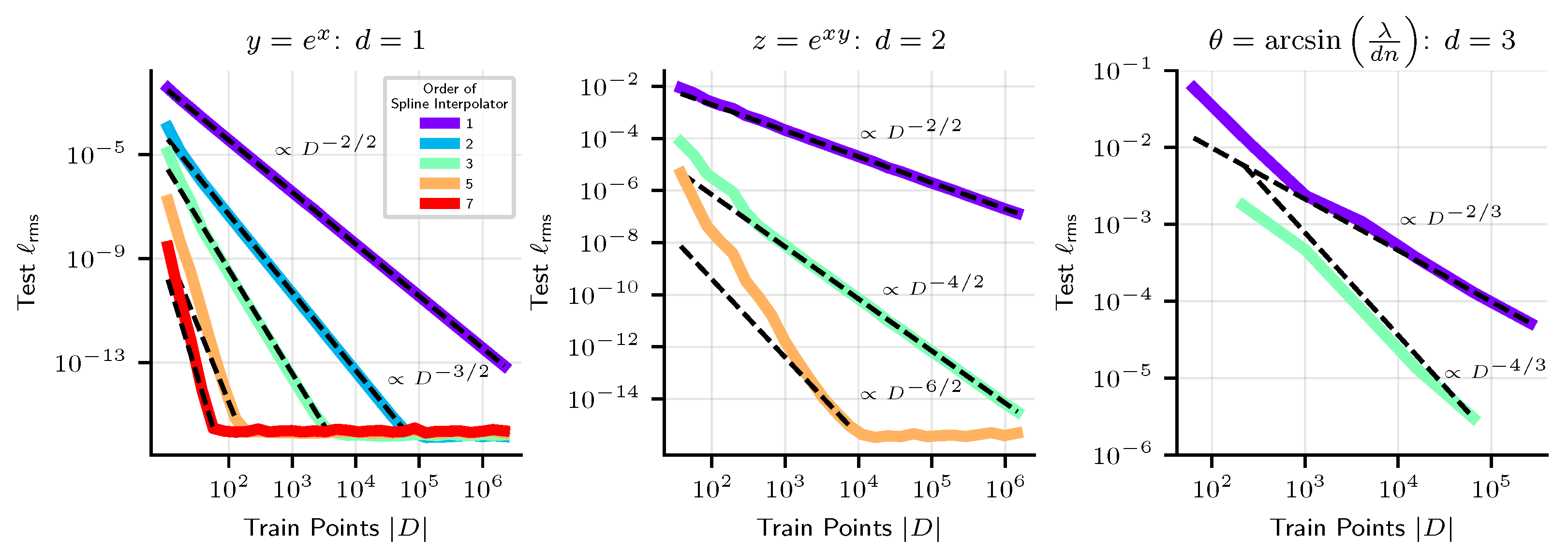
- Nonlinear Splines approximate a target function piecewise by polynomials. They scale as where n is the order of the polynomial.
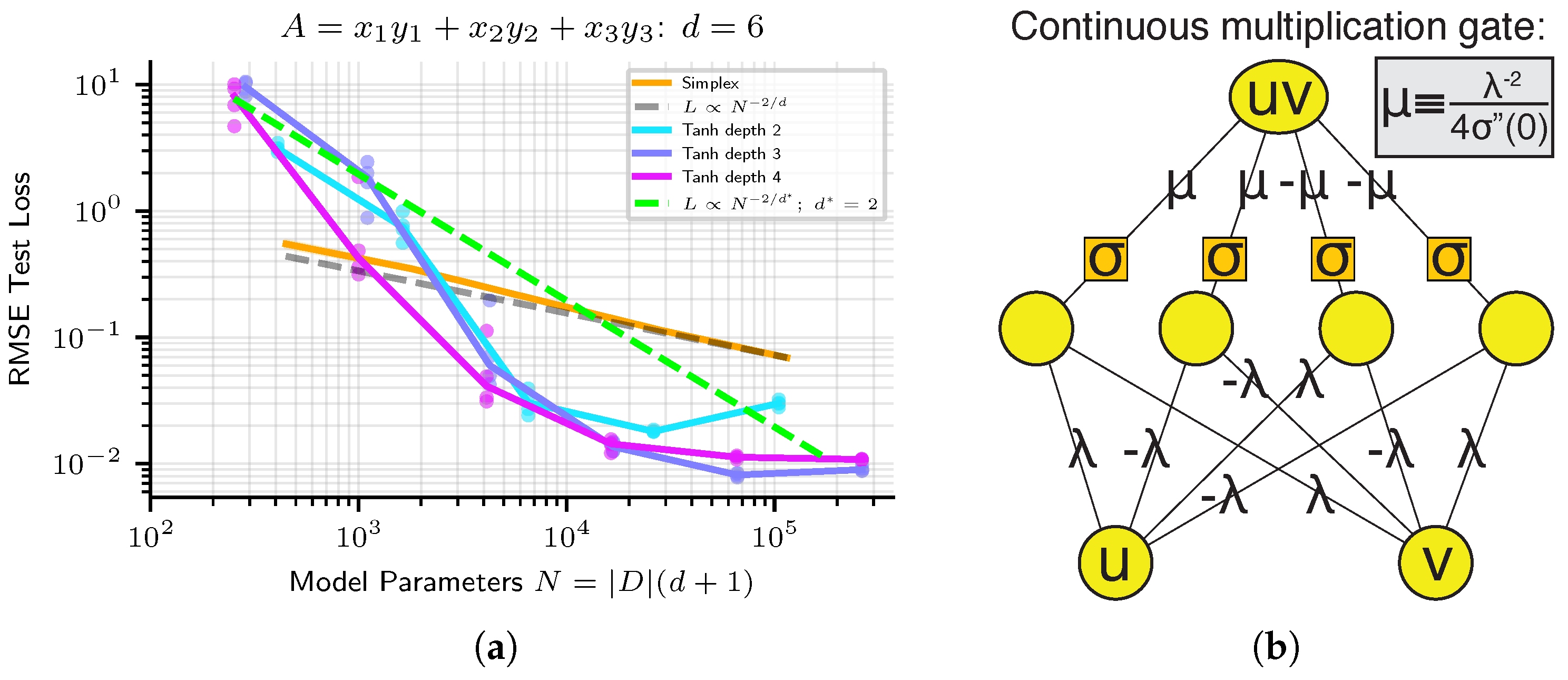
- Neural Networks with smooth activations provide a nonlinear fit to data. Quite small networks with twice-differentiable nonlinearities can perform multiplication arbitrarily well [35], and so for many of the tasks we study (given by symbolic formulas), their architecture error is zero. We find that their inaccuracy does not appear to scale cleanly as power-laws. Optimization error is unfortunately a key driver of the error of these methods, but with special training tricks, we found that we could reduce RMSE loss on 1D problems down within 2–4 orders of magnitude of the 64-bit machine precision limit .
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Boosting Advantage Comes Not Just from Rescaling Loss

Appendix B. A Closer Look at Low-Curvature Subspace Optimization

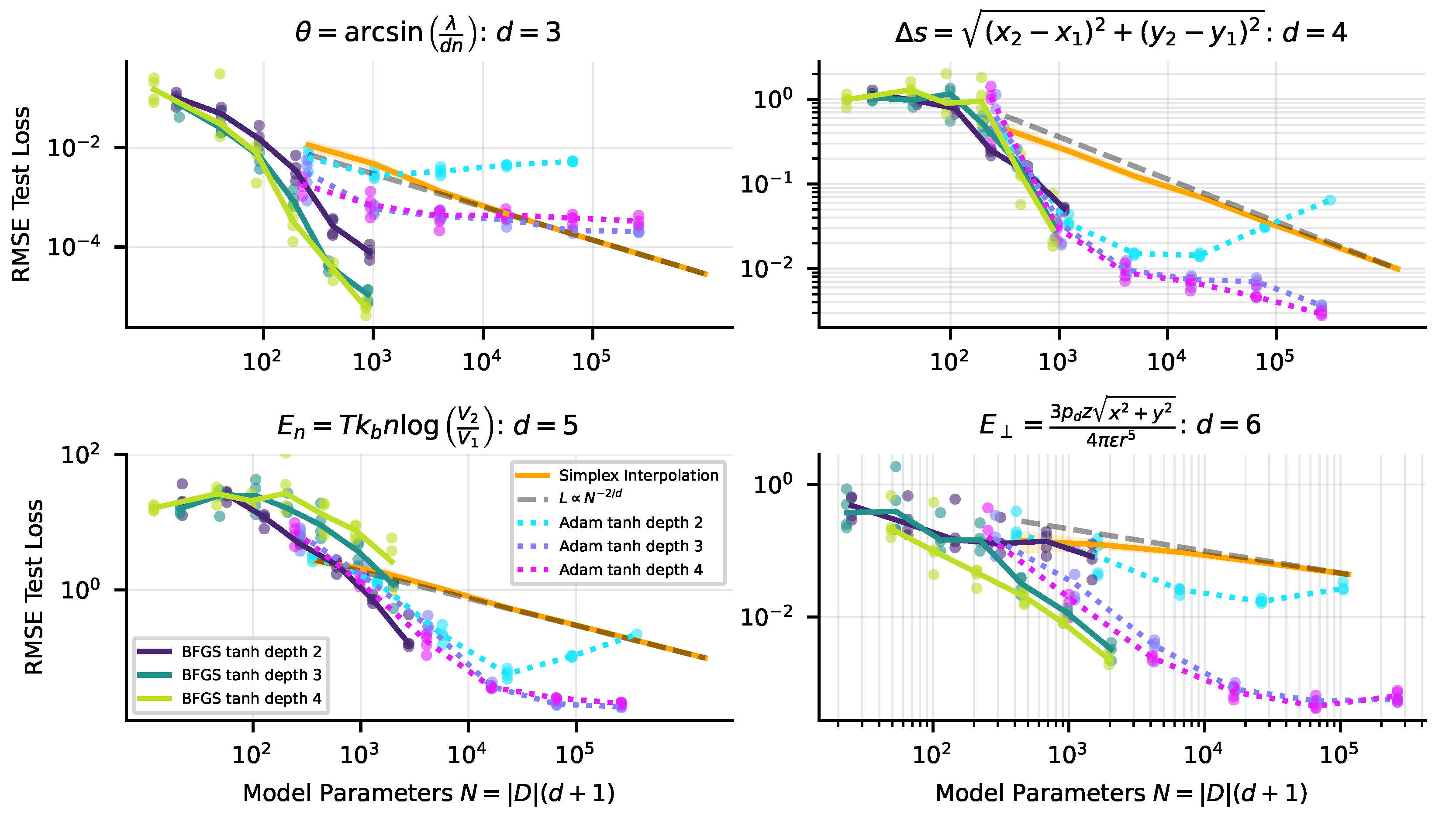
Appendix C. Neural Scaling of Tanh Networks with BFGS versus Adam Optimizer

Appendix D. Loss Landscape at Lower Loss

References
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep Learning with Limited Numerical Precision. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 1737–1746. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed precision training. arXiv 2017, arXiv:1710.03740. [Google Scholar]
- Kalamkar, D.; Mudigere, D.; Mellempudi, N.; Das, D.; Banerjee, K.; Avancha, S.; Vooturi, D.T.; Jammalamadaka, N.; Huang, J.; Yuen, H.; et al. A study of BFLOAT16 for deep learning training. arXiv 2019, arXiv:1905.12322. [Google Scholar]
- Wang, Y.; Lai, C.Y.; Gómez-Serrano, J.; Buckmaster, T. Asymptotic self-similar blow up profile for 3-D Euler via physics-informed neural networks. arXiv 2022. [Google Scholar] [CrossRef]
- Jejjala, V.; Pena, D.K.M.; Mishra, C. Neural network approximations for Calabi-Yau metrics. J. High Energy Phys. 2022, 2022, 105. [Google Scholar] [CrossRef]
- Martyn, J.; Luo, D.; Najafi, K. Applying the Variational Principle to Quantum Field Theory with Neural-Networks; Bulletin of the American Physical Society; American Physical Society: Washington, DC, USA, 2023. [Google Scholar]
- Wu, D.; Wang, L.; Zhang, P. Solving statistical mechanics using variational autoregressive networks. Phys. Rev. Lett. 2019, 122, 080602. [Google Scholar] [CrossRef] [PubMed]
- Udrescu, S.M.; Tegmark, M. AI Feynman: A physics-inspired method for symbolic regression. Sci. Adv. 2020, 6, eaay2631. [Google Scholar] [CrossRef] [PubMed]
- Udrescu, S.M.; Tan, A.; Feng, J.; Neto, O.; Wu, T.; Tegmark, M. AI Feynman 2.0: Pareto-optimal symbolic regression exploiting graph modularity. Adv. Neural Inf. Process. Syst. 2020, 33, 4860–4871. [Google Scholar]
- Leighton, R.B.; Sands, M. The Feynman Lectures on Physics; Addison-Wesley: Boston, MA, USA, 1965. [Google Scholar]
- IEEE Std 754-2019 (Revision of IEEE 754-2008); IEEE Standard for Floating-Point Arithmetic; IEEE: Piscataway, NJ, USA, 2019; pp. 1–84. [CrossRef]
- Gühring, I.; Raslan, M.; Kutyniok, G. Expressivity of deep neural networks. arXiv 2020, arXiv:2007.04759. [Google Scholar]
- Hestness, J.; Narang, S.; Ardalani, N.; Diamos, G.; Jun, H.; Kianinejad, H.; Patwary, M.; Ali, M.; Yang, Y.; Zhou, Y. Deep learning scaling is predictable, empirically. arXiv 2017, arXiv:1712.00409. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Henighan, T.; Kaplan, J.; Katz, M.; Chen, M.; Hesse, C.; Jackson, J.; Jun, H.; Brown, T.B.; Dhariwal, P.; Gray, S.; et al. Scaling laws for autoregressive generative modeling. arXiv 2020, arXiv:2010.14701. [Google Scholar]
- Hernandez, D.; Kaplan, J.; Henighan, T.; McCandlish, S. Scaling laws for transfer. arXiv 2021, arXiv:2102.01293. [Google Scholar]
- Ghorbani, B.; Firat, O.; Freitag, M.; Bapna, A.; Krikun, M.; Garcia, X.; Chelba, C.; Cherry, C. Scaling laws for neural machine translation. arXiv 2021, arXiv:2109.07740. [Google Scholar]
- Gordon, M.A.; Duh, K.; Kaplan, J. Data and parameter scaling laws for neural machine translation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 5915–5922. [Google Scholar]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12104–12113. [Google Scholar]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; Casas, D.d.L.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training Compute-Optimal Large Language Models. arXiv 2022, arXiv:2203.15556. [Google Scholar]
- Clark, A.; de Las Casas, D.; Guy, A.; Mensch, A.; Paganini, M.; Hoffmann, J.; Damoc, B.; Hechtman, B.; Cai, T.; Borgeaud, S.; et al. Unified scaling laws for routed language models. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 4057–4086. [Google Scholar]
- Sharma, U.; Kaplan, J. A neural scaling law from the dimension of the data manifold. arXiv 2020, arXiv:2004.10802. [Google Scholar]
- Bahri, Y.; Dyer, E.; Kaplan, J.; Lee, J.; Sharma, U. Explaining neural scaling laws. arXiv 2021, arXiv:2102.06701. [Google Scholar]
- Arora, R.; Basu, A.; Mianjy, P.; Mukherjee, A. Understanding deep neural networks with rectified linear units. arXiv 2016, arXiv:1611.01491. [Google Scholar]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLU activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient backprop. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar]
- Poggio, T. Compositional Sparsity: A Framework for ML; Technical Report; Center for Brains, Minds and Machines (CBMM): Cambridge, MA, USA, 2022. [Google Scholar]
- Dahmen, W. Compositional Sparsity, Approximation Classes, and Parametric Transport Equations. arXiv 2022, arXiv:2207.06128. [Google Scholar]
- Poggio, T.; Mhaskar, H.; Rosasco, L.; Miranda, B.; Liao, Q. Why and when can deep-but not shallow-networks avoid the curse of dimensionality: A review. Int. J. Autom. Comput. 2017, 14, 503–519. [Google Scholar] [CrossRef]
- Kohler, M.; Langer, S. On the rate of convergence of fully connected deep neural network regression estimates. Ann. Stat. 2021, 49, 2231–2249. [Google Scholar] [CrossRef]
- Bauer, B.; Kohler, M. On deep learning as a remedy for the curse of dimensionality in nonparametric regression. Ann. Stat. 2019, 47, 2261–2285. [Google Scholar] [CrossRef]
- Lekien, F.; Marsden, J. Tricubic interpolation in three dimensions. Int. J. Numer. Methods Eng. 2005, 63, 455–471. [Google Scholar] [CrossRef]
- Lin, H.W.; Tegmark, M.; Rolnick, D. Why does deep and cheap learning work so well? J. Stat. Phys. 2017, 168, 1223–1247. [Google Scholar] [CrossRef]
- Sagun, L.; Bottou, L.; LeCun, Y. Eigenvalues of the hessian in deep learning: Singularity and beyond. arXiv 2016, arXiv:1611.07476. [Google Scholar]
- Sagun, L.; Evci, U.; Guney, V.U.; Dauphin, Y.; Bottou, L. Empirical analysis of the hessian of over-parametrized neural networks. arXiv 2017, arXiv:1706.04454. [Google Scholar]
- Gur-Ari, G.; Roberts, D.A.; Dyer, E. Gradient descent happens in a tiny subspace. arXiv 2018, arXiv:1812.04754. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: New York, NY, USA, 1999. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Schwenk, H.; Bengio, Y. Training methods for adaptive boosting of neural networks. Adv. Neural Inf. Process. Syst. 1997, 10, 647–650. [Google Scholar]
- Schwenk, H.; Bengio, Y. Boosting neural networks. Neural Comput. 2000, 12, 1869–1887. [Google Scholar] [CrossRef] [PubMed]
- Badirli, S.; Liu, X.; Xing, Z.; Bhowmik, A.; Doan, K.; Keerthi, S.S. Gradient boosting neural networks: Grownet. arXiv 2020, arXiv:2002.07971. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michaud, E.J.; Liu, Z.; Tegmark, M. Precision Machine Learning. Entropy 2023, 25, 175. https://doi.org/10.3390/e25010175
Michaud EJ, Liu Z, Tegmark M. Precision Machine Learning. Entropy. 2023; 25(1):175. https://doi.org/10.3390/e25010175
Chicago/Turabian StyleMichaud, Eric J., Ziming Liu, and Max Tegmark. 2023. "Precision Machine Learning" Entropy 25, no. 1: 175. https://doi.org/10.3390/e25010175
APA StyleMichaud, E. J., Liu, Z., & Tegmark, M. (2023). Precision Machine Learning. Entropy, 25(1), 175. https://doi.org/10.3390/e25010175