


Mining Mobile Network Fraudsters with Augmented Graph Neural Networks

 ,
,
Abstract
1. Introduction
- We formulate the telecom fraud detection problem as node classification task and propose an augmented GNN framework to solve it.
- For the graph imbalance problem, we design a reinforcement learning-based graph sampling algorithm and train a semi-supervised model using class-balanced focal loss function.
- We treat GNNs as weak classifiers and integrate multiple GNNs to enhance their performance using the AdaBoost algorithm, while overcoming the oversmoothing problem of GNNs.
- Extensive experiments on two real-world telecom fraud detection datasets show that the method proposed in this paper is effective.
2. Related Work
2.1. Telecom Fraud Detection
2.2. Learning on Graph
3. Problem Definition
4. Proposed Method
4.1. Reinforcement Learning-Based Neighbor Sampler
4.1.1. Node Feature Transformation
4.1.2. Neighbor Sampling
4.2. GNN-Based Weak Classifier
4.3. Ensemble GNN with SAMME.R
4.4. Proposed Algorithm
| Algorithm 1: Augmented Graph Neural Networks. | |||
 | |||
5. Experiments
- Comparisons of the proposed method with state-of-the-art methods in graph-based anomaly detection
- The effectiveness of the proposed method on solving graph imbalance problem
- The effectiveness of the proposed method on overcoming the GNN over-smoothing problem
5.1. Experimental Setup
5.1.1. Dataset
5.1.2. Baseline Method
- GCN: GNN that aggregates neighbor information by spectral graph convolution
- GAT: A GNN that uses an attention mechanism to aggregate neighbor node information
- GraphSAGE: An inductive GNN with a fixed number of sampled neighbors
- FdGars: A GCN-based Social Opinion Fraud Detection System
- GraphConsis: A Heterogeneous Graph Neural Network for Graph Inconsistency
- GEM: A Heterogeneous Graph Fraud Detection GNN Based on Attention Mechanism
- SemiGNN: A GNN for Hierarchical Attention Aggregation with Multi-view
- BTG: A GNN-based Telecom Fraud Detector for Sparse Graphs
5.1.3. Evaluation Metrics and Experiment Settings
5.2. Overall Evaluation
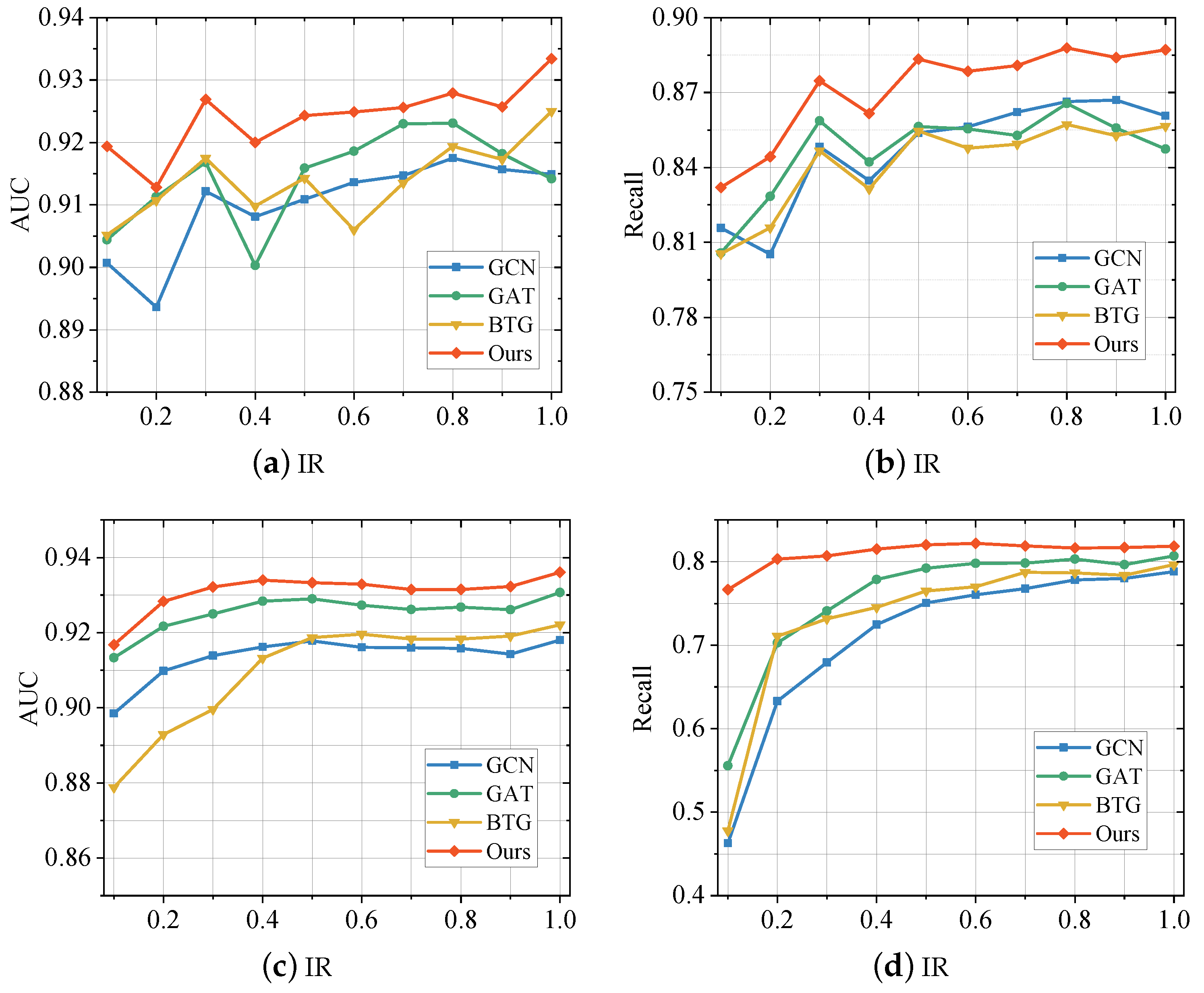
5.3. Alleviation of Graph Imbalance Problem
5.4. Avoidance of Over-Smoothing Effects
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Research Report on Telecommunication Network Fraud Management under the New Situation; Technical Report; China Academy of Information and Communications Technology: Beijing, China, 2020.
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Beutel, A.; Xu, W.; Guruswami, V.; Palow, C.; Faloutsos, C. Copycatch: Stopping group attacks by spotting lockstep behavior in social networks. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 119–130. [Google Scholar]
- Hooi, B.; Song, H.A.; Beutel, A.; Shah, N.; Shin, K.; Faloutsos, C. Fraudar: Bounding graph fraud in the face of camouflage. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 895–904. [Google Scholar]
- Liu, M.; Liao, J.; Wang, J.; Qi, Q. AGRM: Attention-Based Graph Representation Model for Telecom Fraud Detection. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019. [Google Scholar]
- Hu, X.; Chen, H.; Liu, S.; Jiang, H.; Chu, G.; Li, R. BTG: A Bridge to Graph machine learning in telecommunications fraud detection. Future Gener. Comput. Syst. 2022, 137, 274–287. [Google Scholar] [CrossRef]
- Ji, S.; Li, J.; Yuan, Q.; Lu, J. Multi-range gated graph neural network for telecommunication fraud detection. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar]
- Yang, Y.; Xu, Y.; Sun, Y.; Dong, Y.; Wu, F.; Zhuang, Y. Mining fraudsters and fraudulent strategies in large-scale mobile social networks. IEEE Trans. Knowl. Data Eng. 2019, 33, 169–179. [Google Scholar] [CrossRef]
- Zhao, T.; Zhang, X.; Wang, S. Graphsmote: Imbalanced node classification on graphs with graph neural networks. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021; pp. 833–841. [Google Scholar]
- Zhao, L.; Akoglu, L. PairNorm: Tackling Oversmoothing in GNNs. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Rosset, S.; Murad, U.; Neumann, E.; Idan, Y.; Pinkas, G. Discovery of fraud rules for telecommunications—Challenges and solutions. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 409–413. [Google Scholar]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving prediction of the minority class in boosting. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 107–119. [Google Scholar]
- Estévez, P.A.; Held, C.M.; Perez, C.A. Subscription fraud prevention in telecommunications using fuzzy rules and neural networks. Expert Syst. Appl. 2006, 31, 337–344. [Google Scholar] [CrossRef]
- Kim, H.C.; Pang, S.; Je, H.M.; Kim, D.; Bang, S.Y. Constructing support vector machine ensemble. Pattern Recognit. 2003, 36, 2757–2767. [Google Scholar] [CrossRef]
- Hilas, C.S.; Sahalos, J.N. An application of decision trees for rule extraction towards telecommunications fraud detection. In Proceedings of the International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, Vietri sul Mare, Italy, 12–14 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1112–1121. [Google Scholar]
- Taniguchi, M.; Haft, M.; Hollmén, J.; Tresp, V. Fraud detection in communication networks using neural and probabilistic methods. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), Seattle, WA, USA, 15 May 1998; Volume 2, pp. 1241–1244. [Google Scholar]
- Zheng, Y.J.; Zhou, X.H.; Sheng, W.G.; Xue, Y.; Chen, S.Y. Generative adversarial network based telecom fraud detection at the receiving bank. Neural Netw. 2018, 102, 78–86. [Google Scholar] [CrossRef] [PubMed]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.L.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, A.; Qin, Z.; Liu, R.; Yang, Y.; Li, D. Spam review detection with graph convolutional networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2703–2711. [Google Scholar]
- Wang, J.; Wen, R.; Wu, C.; Huang, Y.; Xiong, J. Fdgars: Fraudster detection via graph convolutional networks in online app review system. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 310–316. [Google Scholar]
- Liu, Z.; Chen, C.; Yang, X.; Zhou, J.; Li, X.; Song, L. Heterogeneous graph neural networks for malicious account detection. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 2077–2085. [Google Scholar]
- Zhang, G.; Yang, Z.; Wu, J.; Yang, J.; Xue, S.; Peng, H.; Su, J.; Zhou, C.; Sheng, Q.Z.; Akoglu, L.; et al. Dual-discriminative Graph Neural Network for Imbalanced Graph-level Anomaly Detection. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Deng, L.; Wu, C.; Lian, D.; Wu, Y.; Chen, E. Markov-Driven Graph Convolutional Networksfor Social Spammer Detection. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Chai, Z.; You, S.; Yang, Y.; Pu, S.; Xu, J.; Cai, H.; Jiang, W. Can Abnormality be Detected by Graph Neural Networks? In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI), Vienna, Austria, 23–29 July 2022. [Google Scholar]
- Wang, D.; Lin, J.; Cui, P.; Jia, Q.; Wang, Z.; Fang, Y.; Yu, Q.; Zhou, J.; Yang, S.; Qi, Y. A semi-supervised graph attentive network for financial fraud detection. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 598–607. [Google Scholar]
- Zhang, Y.; Fan, Y.; Ye, Y.; Zhao, L.; Shi, C. Key player identification in underground forums over attributed heterogeneous information network embedding framework. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 549–558. [Google Scholar]
- Liu, Z.; Chen, C.; Li, L.; Zhou, J.; Li, X.; Song, L.; Qi, Y. Geniepath: Graph neural networks with adaptive receptive paths. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4424–4431. [Google Scholar]
- Hu, B.; Zhang, Z.; Shi, C.; Zhou, J.; Li, X.; Qi, Y. Cash-out user detection based on attributed heterogeneous information network with a hierarchical attention mechanism. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 946–953. [Google Scholar]
- Liu, Z.; Dou, Y.; Yu, P.S.; Deng, Y.; Peng, H. Alleviating the inconsistency problem of applying graph neural network to fraud detection. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 1569–1572. [Google Scholar]
- Dou, Y.; Liu, Z.; Sun, L.; Deng, Y.; Peng, H.; Yu, P.S. Enhancing graph neural network-based fraud detectors against camouflaged fraudsters. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Galway, Ireland, 19–23 October 2020; pp. 315–324. [Google Scholar]
- Liu, Y.; Ao, X.; Qin, Z.; Chi, J.; Feng, J.; Yang, H.; He, Q. Pick and choose: A GNN-based imbalanced learning approach for fraud detection. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3168–3177. [Google Scholar]
- Zhao, L.; Sawlani, S.; Srinivasan, A.; Akoglu, L. Graph Anomaly Detection with Unsupervised GNNs. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 30 November–3 December 2022. [Google Scholar]
- Liu, F.; Ma, X.; Wu, J.; Yang, J.; Xue, S.; Beheshti, A.; Zhou, C.; Peng, H.; Sheng, Q.Z.; Aggarwal, C.C. DAGAD: Data Augmentation for Graph Anomaly Detection. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 30 November–3 December 2022. [Google Scholar]
- Li, Q.; He, Y.; Xu, C.; Wu, F.; Gao, J.; Li, Z. Dual-Augment Graph Neural Network for Fraud Detection. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 4188–4192. [Google Scholar]
- Chen, B.; Zhang, J.; Zhang, X.; Dong, Y.; Song, J.; Zhang, P.; Xu, K.; Kharlamov, E.; Tang, J. GCCAD: Graph Contrastive Coding for Anomaly Detection. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Jin, M.; Liu, Y.; Zheng, Y.; Chi, L.; Li, Y.F.; Pan, S. Anemone: Graph anomaly detection with multi-scale contrastive learning. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Queensland, Australia, 1–5 November 2021; pp. 3122–3126. [Google Scholar]
- Li, S.; Gou, G.; Liu, C.; Hou, C.; Li, Z.; Xiong, G. TTAGN: Temporal Transaction Aggregation Graph Network for Ethereum Phishing Scams Detection. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 661–669. [Google Scholar]
- Liu, K.; Dou, Y.; Zhao, Y.; Ding, X.; Hu, X.; Zhang, R.; Ding, K.; Chen, C.; Peng, H.; Shu, K.; et al. BOND: Benchmarking Unsupervised Outlier Node Detection on Static Attributed Graphs. In Proceedings of the Thirty-Sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, Virtual, 28 November–9 December 2022. [Google Scholar]
- Li, R.; Wang, S.; Zhu, F.; Huang, J. Adaptive graph convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Chen, Y.; Wu, L.; Zaki, M.J. Deep iterative and adaptive learning for graph neural networks. arXiv 2019, arXiv:1912.07832. [Google Scholar]
- Liu, W.; Liu, Z.; Rehg, J.M.; Song, L. Neural similarity learning. Adv. Neural Inf. Process. Syst. 2019, 32, 5025–5036. [Google Scholar]
- Verma, V.; Qu, M.; Lamb, A.; Bengio, Y.; Kannala, J.; Tang, J. GraphMix: Regularized training of graph neural networks for semi-supervised learning. arXiv arxiv e-prints, art. 2019, arXiv:1909.11715. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class adaboost. Stat. Interface 2009, 2, 349–360. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Nodes (Fraud Ratio) | Edges | Classes | Features | IR |
|---|---|---|---|---|---|
| Sichuan | 6106 (32.1%) | 838,528 | Benign: 4144 | 55 | 0.4735 |
| Fraud: 1962 | |||||
| BUPT | 116,383 (7.3%) | 350,751 | Normal: 99,861 | 39 | 0.0809 |
| Fraudster: 8448 | |||||
| Courier: 8074 |
| Dataset | Metric | GCN | GAT | Graph-Sage | FdGars | Graph-Consis | GEM | SemiGNN | BTG | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| Sichuan | Macro AUC | 0.9163 | 0.9146 | 0.9159 | 0.7887 | 0.7615 | 0.8019 | 0.6958 | 0.9183 | 0.9312 |
| Macro recall | 0.8547 | 0.8510 | 0.8564 | 0.7082 | 0.6865 | 0.7230 | 0.5820 | 0.8426 | 0.8824 | |
| accuracy | 0.8812 | 0.8797 | 0.8829 | 0.7325 | 0.7238 | 0.7950 | 0.6113 | 0.8881 | 0.9155 | |
| Macro F1 | 0.8645 | 0.8519 | 0.8631 | 0.6499 | 0.6853 | 0.7401 | 0.5643 | 0.8629 | 0.8933 | |
| BUPT | Macro AUC | 0.8932 | 0.8686 | 0.8928 | 0.6462 | 0.6294 | 0.6346 | 0.5732 | 0.8952 | 0.9016 |
| Macro recall | 0.5706 | 0.5573 | 0.6715 | 0.4357 | 0.3319 | 0.3344 | 0.4007 | 0.6731 | 0.7281 | |
| accuracy | 0.9008 | 0.8875 | 0.9113 | 0.8651 | 0.8446 | 0.8583 | 0.8237 | 0.9076 | 0.9250 | |
| Macro F1 | 0.6265 | 0.5835 | 0.6918 | 0.4027 | 0.3127 | 0.3100 | 0.3514 | 0.6692 | 0.7395 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Chen, H.; Chen, H.; Li, X.; Zhang, J.; Liu, S. Mining Mobile Network Fraudsters with Augmented Graph Neural Networks. Entropy 2023, 25, 150. https://doi.org/10.3390/e25010150
Hu X, Chen H, Chen H, Li X, Zhang J, Liu S. Mining Mobile Network Fraudsters with Augmented Graph Neural Networks. Entropy. 2023; 25(1):150. https://doi.org/10.3390/e25010150
Chicago/Turabian StyleHu, Xinxin, Haotian Chen, Hongchang Chen, Xing Li, Junjie Zhang, and Shuxin Liu. 2023. "Mining Mobile Network Fraudsters with Augmented Graph Neural Networks" Entropy 25, no. 1: 150. https://doi.org/10.3390/e25010150
APA StyleHu, X., Chen, H., Chen, H., Li, X., Zhang, J., & Liu, S. (2023). Mining Mobile Network Fraudsters with Augmented Graph Neural Networks. Entropy, 25(1), 150. https://doi.org/10.3390/e25010150