


Cross-Corpus Speech Emotion Recognition Based on Multi-Task Learning and Subdomain Adaptation

Abstract
1. Introduction
- The proposed method uses multi-task learning to help the network extract speech features, which is more robust than the features obtained only using emotional recognition tasks.
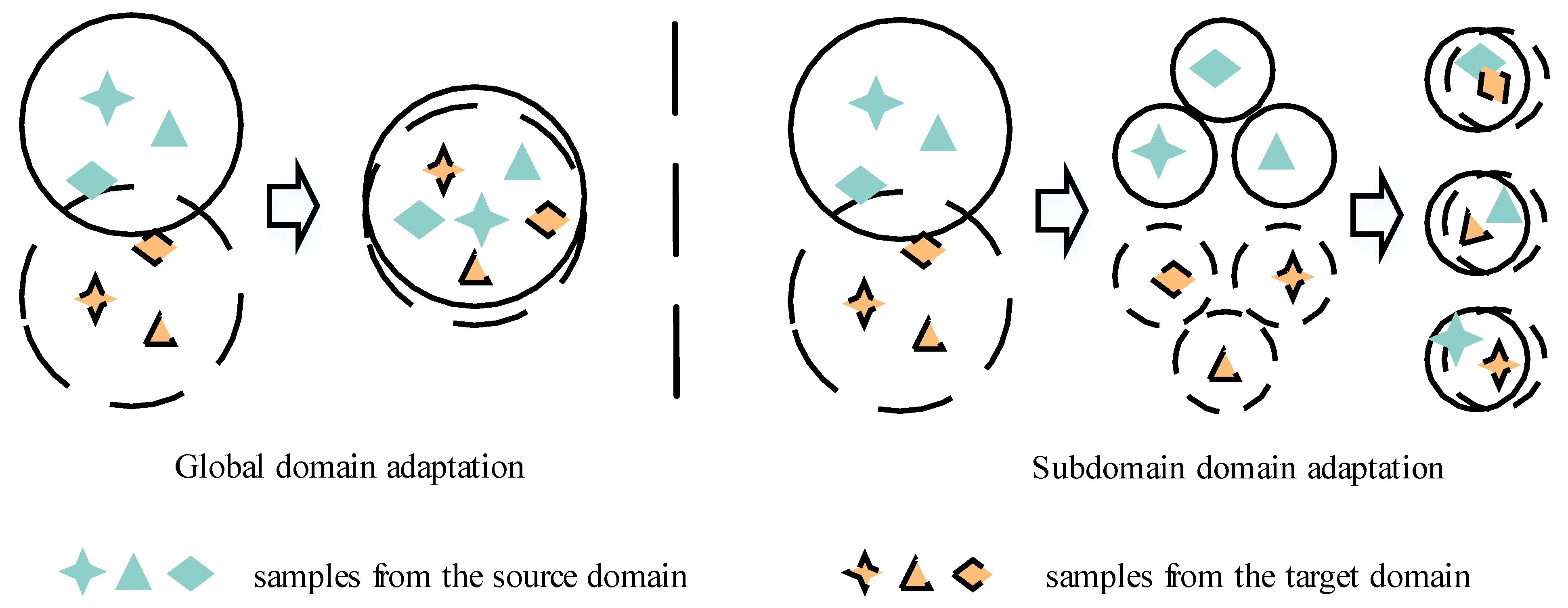
- A subdomain transfer learning method is proposed, which can reduce the negative transfer in the whole local adaptation process more than the global adaptation method.
- In the ablation experiment and the evaluation compared with other algorithms, the proposed method has achieved performance leadership in most cross-corpus schemes.
2. Related Work
- To obtain the emotional information with strong representation ability in speech feature. Human speech contains a variety of paralinguistic information in addition to semantic information, such as mood, gender, emotion, but the ideal speech emotional feature should be independent of the speaker, semantics, language and other objective factors, and reflect emotional information as effectively as possible, which puts forward higher requirements for the generalization of emotional features of the cross-corpus SER system.
- To effectively measure the distribution discrepancy of features. In cross-corpus SER research, researchers mostly use the emotion feature measurement criteria based on the global feature area [12,13,17], and only measure the distance between two emotion vector matrices representing the source domain and target domain, ignoring the differences of different emotion features in the field, which may lead to the confused transfer of similar emotion information, such as happy and surprise, anger and disgust, which is not conducive to the subsequent emotion classification.
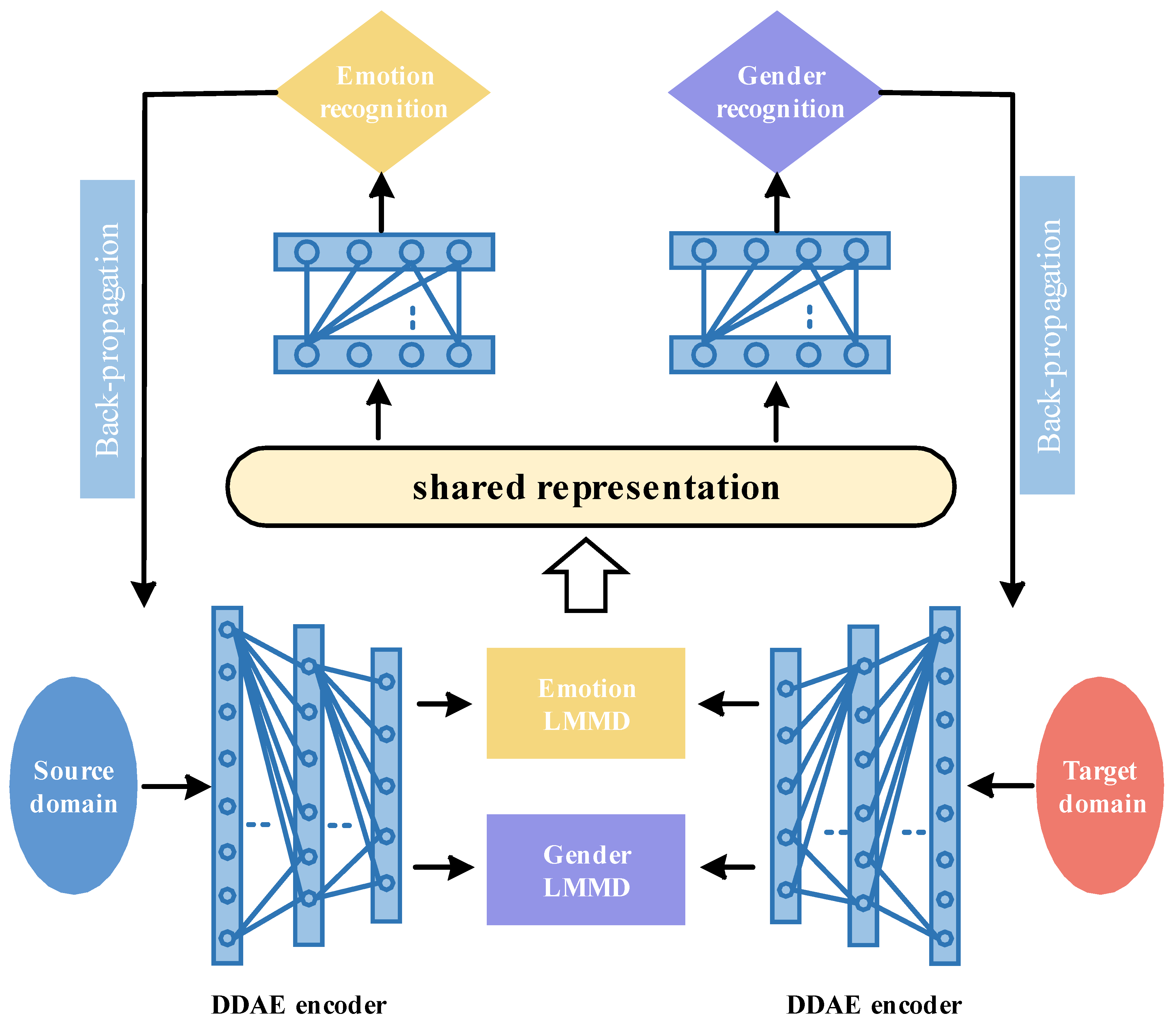
3. Model Framework
3.1. Multi-Task Learning
3.2. Subdomain Adaptation
3.3. Model Training and Identification
4. Experimental Setup
4.1. Corpus
4.2. Extract Speech Features
4.3. Experimental Scheme
5. Analysis of Experimental Results
5.1. Analysis of Ablation Experiment
5.2. Comparative Experimental Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Alisamir, S.; Ringeval, F. On the Evolution of Speech Representations for Affective Computing: A brief history and critical overview. IEEE Signal Process. Mag. 2021, 38, 12–21. [Google Scholar] [CrossRef]
- Malik, M.; Malik, M.K.; Mehmood, K.; Makhdoom, I. Automatic speech recognition: A survey. Multimed. Tools Appl. 2021, 80, 9411–9457. [Google Scholar] [CrossRef]
- Sitaula, C.; He, J.; Priyadarshi, A.; Tracy, M.; Kavehei, O.; Hinder, M.; Hinder, M.; Withana, A.; McEwan, A.; Marzbanrad, F. Neonatal Bowel Sound Detection Using Convolutional Neural Network and Laplace Hidden Semi-Markov Model. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1853–1864. [Google Scholar] [CrossRef]
- Burne, L.; Sitaula, C.; Priyadarshi, A.; Tracy, M.; Kavehei, O.; Hinder, M.; Withana, A.; McEwan, A.; Marzbanrad, F. Ensemble Approach on Deep and Handcrafted Features for Neonatal Bowel Sound Detection. IEEE J. Biomed. Health Inform. 2022. [CrossRef] [PubMed]
- Lee, S. Domain Generalization with Triplet Network for Cross-Corpus Speech Emotion Recognition. In Proceedings of the IEEE Spoken Language Technology Workshop, Shenzhen, China, 19–22 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 389–396. [Google Scholar]
- Antoniadis, P.; Filntisis, P.P.; Maragos, P. Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Ryumina, E.; Dresvyanskiy, D.; Karpov, A. In search of a robust facial expressions recognition model: A large-scale visual cross-corpus study. Neurocomputing 2022, 514, 435–450. [Google Scholar] [CrossRef]
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying Emotions and Engagement in Online Learning Based on a Single Facial Expression Recognition Neural Network. IEEE Trans. Affect. Comput. 2022, 13, 2132–2143. [Google Scholar] [CrossRef]
- Du, G.; Su, J.; Zhang, L.; Su, K.; Wang, X.; Teng, S.; Liu, P.X. A Multi-Dimensional Graph Convolution Network for EEG Emotion Recognition. IEEE Trans. Instrum. Meas. 2022, 71, 3204314. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Zhao, L.; Li, B.; Hu, W.; Yu, J.; Zhang, Y. 3DCANN: A spatio-temporal convolution attention neural network for EEG emotion recognition. IEEE J. Biomed. Health Inform. 2021, 26, 5321–5331. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Zhang, Z.; Eyben, F.; Schuller, B. Autoencoder-based unsupervised domain adaptation for speech emotion recognition. IEEE Signal Process. Lett. 2014, 21, 1068–1072. [Google Scholar] [CrossRef]
- Huang, Z.; Xue, W.; Mao, Q.; Zhan, Y. Unsupervised domain adaptation for speech emotion recognition using PCANet. Multimed. Tools Appl. 2017, 76, 6785–6799. [Google Scholar] [CrossRef]
- Zong, Y.; Zheng, W.; Zhang, T.; Huang, X. Cross-corpus speech emotion recognition based on domain-adaptive least-squares regression. IEEE Signal Process. Lett. 2016, 23, 585–589. [Google Scholar] [CrossRef]
- Liu, N.; Zong, Y.; Zhang, B.; Liu, L.; Chen, J.; Zhao, G.; Zhu, J. Unsupervised cross-corpus speech emotion recognition using domain-adaptive subspace learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5144–5148. [Google Scholar]
- Song, P. Transfer linear subspace learning for cross-corpus speech emotion recognition. IEEE Trans. Affect. Comput. 2019, 10, 265–275. [Google Scholar] [CrossRef]
- Luo, H.; Han, J. Nonnegative matrix factorization based transfer subspace learning for cross-corpus speech emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2047–2060. [Google Scholar] [CrossRef]
- Liu, J.; Zheng, W.; Zong, Y.; Lu, C.; Tang, C. Cross-corpus speech emotion recognition based on deep domain-adaptive convolutional neural network. IEICE Trans. Inf. Syst. 2020, 103, 459–463. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep subdomain adaptation network for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1713–1722. [Google Scholar] [CrossRef] [PubMed]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A-corpus of German emotional speech. In Proceedings of the Eurospeech, 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; Volume 5, pp. 1517–1520. [Google Scholar]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 audio-visual emotion-corpus. In Proceedings of the 22nd International Conference on Data Engineering Workshops, Atlanta, GA, USA, 3–7 April 2006; IEEE: Piscataway, NJ, USA, 2006; p. 8. [Google Scholar]
- Tao, J.; Liu, F.; Zhang, M.; Jia, H. Design of speech corpus for mandarin text to speech. In Proceedings of the Blizzard Challenge 2008 Workshop, Brisbane Australia, 20 September 2008. [Google Scholar]
- Zhang, W.; Song, P. Transfer sparse discriminant subspace learning for cross-corpus speech emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 307–318. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Latif, S.; Rana, R.; Younis, S.; Qadir, J.; Epps, J. Transfer learning for improving speech emotion classification accuracy. arXiv 2018, arXiv:1801.06353. [Google Scholar]



{kind=link}
{kind=link}
| Emotion Recognition Task | Gender Identification Task | |||
|---|---|---|---|---|
| Corpus | Num of Samples | Emotional Tags | Male Samples | Female Samples |
| Berlin | 375 | Anger, Sad, Fear, Happy, Disgust | 159 | 216 |
| eNTERFACE | 1072 | 885 | 187 | |
| CASIA | 1000 | Anger, Sad, Fear, Happy, Surprise | 500 | 500 |
| eNTERFACE | 1072 | 847 | 225 | |
| Berlin | 408 | Anger, Sad, Fear, Happy, Neutral | 187 | 221 |
| CASIA | 1000 | 500 | 500 | |
| Scheme | Source Domain | Target Domain | Cross-Corpus Identification |
|---|---|---|---|
| E→B | eNTERFACE | Berlin | Anger, Sad, Fear, Happy, Disgust |
| B→E | Berlin | eNTERFACE | |
| E→C | eNTERFACE | CASIA | Anger, Sad, Fear, Happy, Surprise |
| C→E | CASIA | eNTERFACE | |
| B→C | Berlin | CASIA | Anger, Sad, Fear, Happy, Neutral |
| C→B | CASIA | Berlin |
| Model | E→B | B→E | E→C | C→E | B→C | C→B |
|---|---|---|---|---|---|---|
| MTLSA_L | 36.80 | 24.44 | 32.90 | 23.23 | 30.10 | 39.95 |
| MTLSA_M | 55.73 | 30.60 | 34.40 | 30.32 | 39.30 | 53.94 |
| MTLSA | 57.60 | 34.12 | 35.21 | 31.52 | 41.90 | 56.86 |
| Model | E→B | B→E | E→C | C→E | B→C | C→B | Average |
|---|---|---|---|---|---|---|---|
| PCA+SVM | 50.85 | 33.68 | 28.60 | 27.80 | 33.60 | 43.87 | 36.40 |
| TSDSL [22] | 50.67 | 35.47 | 32.50 | 33.28 | 37.40 | 56.60 | 40.98 |
| DBN+BP [24] | 26.67 | 32.28 | 24.20 | 31.04 | 35.80 | 46.81 | 32.80 |
| DoSL [14] | 49.58 | 30.64 | 35.20 | 33.90 | 35.77 | 57.51 | 40.43 |
| MTLSA | 57.60 | 34.12 | 35.21 | 31.52 | 41.90 | 56.86 | 42.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, H.; Zhuang, Z.; Wang, Y.; Huang, C.; Duan, W. Cross-Corpus Speech Emotion Recognition Based on Multi-Task Learning and Subdomain Adaptation. Entropy 2023, 25, 124. https://doi.org/10.3390/e25010124
Fu H, Zhuang Z, Wang Y, Huang C, Duan W. Cross-Corpus Speech Emotion Recognition Based on Multi-Task Learning and Subdomain Adaptation. Entropy. 2023; 25(1):124. https://doi.org/10.3390/e25010124
Chicago/Turabian StyleFu, Hongliang, Zhihao Zhuang, Yang Wang, Chen Huang, and Wenzhuo Duan. 2023. "Cross-Corpus Speech Emotion Recognition Based on Multi-Task Learning and Subdomain Adaptation" Entropy 25, no. 1: 124. https://doi.org/10.3390/e25010124
APA StyleFu, H., Zhuang, Z., Wang, Y., Huang, C., & Duan, W. (2023). Cross-Corpus Speech Emotion Recognition Based on Multi-Task Learning and Subdomain Adaptation. Entropy, 25(1), 124. https://doi.org/10.3390/e25010124