Abstract
Due to the widespread presence of disturbances in practical engineering and widespread applications of high-order systems, this paper first pays attention to a class of high-order strict-feedback nonlinear systems subject to bounded disturbance and investigates the prescribed performance tracking control and anti-disturbance control problems. A novel composite control protocol using the technique of a disturbance observer—prescribed performance control—is designed using the back-stepping method. The disturbance observer is introduced for estimating and compensating for unknown disturbances in each step, and the prescribed performance specifications guarantee both transient and steady-state performance of the tracking error to improve the control performance and result in better disturbance rejection. Moreover, the technique of adding a power integrator is modified to tackle controller design problems for the high-order systems. The Lyapunov function method is utilized for rigorous stability analysis. It is revealed that while the control performance completely remains in the prescribed bound, all states in the closed-loop system are input-to-state stable, and the tracking error and the disturbances estimating error asymptotically converge to zero simultaneously. Then, the feasibility and effectiveness of the proposed control protocol are verified by a simulation result.
1. Introduction
Any practical system in life has different degrees of nonlinear properties. Since the Dutch meteorologist Lorenz opened the door to mankind’s understanding of the nonlinear world in the 1960s, the control problem of nonlinear systems has been in full swing [1,2,3,4]. There are many main research methods, such as differential geometry methods, passivity theory, Lyapunov stability theory, and so on. Due to the complexity and diversity of nonlinear systems, different methods are applicable to different problems.
In many practical control problems, one often needs to quantitatively characterize the impact of errors and disturbances in measurement elements or execution mechanisms in the system, so the stability of the forced system is the most fundamental issue in control theory. There are two approaches to describing the stability of forced systems with different ideas: one uses the operator theory technique. The input–output stability based on the small gain theorem can obtain great results in applying to a infinite network [5]. The other is the application of the state space approach. Sontag in [6] introduced the concept of input-to-state stability for the first time to systematically describe the stability of a forced system by the state space approach. This approach replaces the finite gain with a nonlinear gain function, resulting in fewer limitations, and the advantage of having multiple equivalent representations (e.g., Lyapunov-like description of the function) makes it more compatible with existing control theory. Nowadays, it has been widely used in neural networks [7], control [8], inverse optimal control [9], stochastic systems [10], time-delay systems [11], switching systems [12], discrete systems [13], etc.
Moreover, due to practical engineering needs, tracking control is often one of the main control objectives for nonlinear forced dynamic systems—for example, see [14,15,16] and references therein—which aims to make the system output asymptotically track our expected dynamic signal by applying inputs to the system.
Although there have been many related studies about tracking control, in order to better apply it to engineering systems, studies in the past decades started to be keen on solving the tracking control problem with external disturbances in the system. With the increasing requirements for control accuracy, many control methods have been proposed for systems with various disturbances and parameter uncertainties: for example, nonlinear control [8], sliding mode control [17], output regulation theory [18], and adaptive methods [19]. Although the above methods effectively attenuate or reject disturbances, the output regulation theory requires the derivative of the controller [20], whereas most other methods sacrifice nominal system performance when achieving robustness [21]. To avoid above effects, Nakao et al. proposed disturbance observer-based control (DOBC) in the late 1980s, which can estimate unknown disturbances that are difficult to be measured directly by sensors, and compensates for the equivalent disturbances in the feed-forward channel. Owing to its excellent interference rejection capability, DOBC has been widely used in various practical systems, such as servo systems [22] and robot systems [23]. Reference [24] proposed a method combining DOBC and sliding mode control to estimate the disturbance and attenuate it using a designed sliding surface. However, the tracking errors in the existing studies [25] do not reach asymptotic convergence. Subsequently, the back-stepping method was proposed [26]. This method decomposes a complex nonlinear system into subsystems and uses the introduction of virtual control law and the design of Lyapunov functions for each subsystem to complete the controller design for the entire main system. With the development of the back-stepping method, the construction of controllers have a systematic approach, which was then introduced in the literature [27] along with DOBC for the disturbed nonlinear problems.
Most existing tracking control problems have focused on solving stability problems without considering constraints on the transient performance of the system before reaching steady state, which is often limited by factors such as hardware and interaction with humans. More than a decade ago, Bechlioulis and Rovithakis first proposed prescribed performance control (PPC) in [28,29] for nonlinear simple input simple output (SISO) system and multi-input multi-output (MIMO) systems, where the transient and steady-state performance of the system can be constrained simultaneously using the performance function, and asymptotic tracking control is achieved. PPC is gradually being used to solve various control problems [30,31]. In [32], Chen and Yang introduced a novel performance function into PPC and developed a controller based on the back-stepping method to achieve tracking control with prescribed performance.
It should be noted that, on the one hand although the PPC approach allows the tracking error to be always kept within the prescribed constraint, it is still difficult to design a specific composite controller to simultaneously guarantee the prescribed performance and achieve tracking control if external disturbances are present in the system. Bai et al. only considered the prescribed performance tracking control problem for high-order nonlinear systems without and external disturbances [31]. On the other hand, most studies of control methods that introduce disturbance observers, to our knowledge, did not consider prescribed performance specifications [22,23,24,25]. In addition, it is also noted that there has been few previous studies dealing with the problem of high-order nonlinear systems. Chen et al. investigated an adaptive output feedback control law for first-order, unknown, pure-feedback nonlinear systems with external disturbances [32]. As far as we know, there has been no work so far considering simultaneous prescribed performance tracking control and anti-disturbance control problems for high-order nonlinear systems, which gave the motivation to carry out this work.
Inspired by this, a composite controller was designed for a class of high-order strict feedback systems with external disturbances to address the prescribed performance-tracking problem. Concretely, a disturbance observer is used to estimate and compensate for external disturbances; a prescribed performance function and a transformation function are used to convert the original prescribed performance tracking control into an unconstrained system with the same stability; and finally, the DOB technique and a back-stepping method incorporating adding a power-integrator technique for dealing with high-order systems problems are used in the controller. This control scheme ensures the prescribed transient and steady-state behaviors of the tracking errors while enabling a high-order nonlinear system with stronger disturbance rejection. This article has the following contributions relative to existing results:
- (1)
- The proposed composite controller solves the output tracking problem of a class of high-order nonlinear systems, where the system states are stabilized and the tracking error converges to zero.
- (2)
- Differently from the methods designed to attenuate disturbances to a specified area [33,34], the error systems of nonvanishing disturbance estimating converge to zero. That is, this control scheme can eliminate the affect of disturbances on output.
- (3)
- Without the external disturbances, the nominal control performance of the proposed protocol remained.
- (4)
- Unlike the previous results in [30,35], the performance indices of the system regarding transient steady-state behavior are not only allowed to evolve within a prescribed bound, but also guarantee zero steady-state output tracking error.
The rest of this article is organized as follows. In Section 2, the problem formulation and preliminaries are given. In Section 3, the composite control protocol is constructed by utilizing back-stepping technique, and the stability and the prescribed performance are analyzed. In Section 4, an example is given to show the effectiveness. A short conclusion is given in Section 5.
2. Problem Formulation and Preliminaries
2.1. Problem Formulation
Following notation is used throughout the paper. For a given vector is the Euclidean norm of vector x.
Consider a class of high-order strict-feedback nonlinear systems modeled by
where denotes the system state, and , and , respectively, represent control input, unknown disturbances, and system output. are some positive odd integers, and are known nonlinear continuous functions. Moreover, we define as the given reference signal and as the tracking error between and .
In order to solve the anti-disturbance and prescribed performance tracking control problem of system (1), we aimed to develop a novel composite controller that meets the following control objectives for system (1):
- The tracking error converges to zero and achieves the prescribed performance in both transient state and steady state.
- All states in the closed-loop system are stable.
Assumption 1.
Define as positive odd integers:
- (i)
- p is considered as
- (ii)
- satisfies: .
Assumption 2.
The disturbances satisfy the following conditions:
- (i)
- and the derivatives of are bounded, and are nonvanishing.
- (ii)
- as
Assumption 3.
The expected signal and its i-order derivative are bounded, and they are known.
Remark 1.
Assumption 1 is utilized to ensure the reasonableness of the adding a power-integrator technology. Assumption 2 is widely used in the field of disturbance estimation for the reason that the derivatives of the disturbances will affect the convergence of error dynamics equation, and this assumption is essential in analyzing the stability of disturbance estimation error. It is worth pointing out that Assumption 3 is a standard assumption for output tracking control of nonlinear systems, and similar assumptions can be found in the literature [14,15,16].
Definition 1.
A continuous function is said to belong to class if it is strictly increasing and Additionally, it is said to belong to class if and as .
Lemma 1
([36]). Consider the following system:
Let be a continuously differentiable function such that
where and are class functions, is a continuous positive definite function, and is a class function. Then, system (2) is input-to-state stable (ISS).
Lemma 2
([36]). Consider system (2). If it is globally input-to-state stable, then the state of system (2) will asymptotically converge to zero; that is,
To complete this section, we give other existing inequalities as lemmas, which the main method of the modified adding a power-integrator technology is based on, and it will be utilized to deal with the error system.
Lemma 3
([37]). For any real valued function x, y and any positive odd integer the inequality is as follows:
Lemma 4
([37]). For any designed constant the following inequality hold:
In this paper, because of the uncertainty of , the relation between q and1 requires further discussion. Thus, to simplify the proof later, the situation that includes both above cases ( and ) is summed up in the following inequality:
Lemma 5
([38]). For any positive real numbers m and n and any real number , there are always any real variables x and y and a function such that the following inequality with two forms holds:
where
2.2. Prescribed Performance
In order to guarantee the transient and steady-state performance of tracking error simultaneously, a positive decreasing smooth function was chosen as the prescribed performance function (PPF) with In this research, was chosen as
where and are positive parameters which will be designed according to practical requirements.
Utilizing the similar idea from research [29], the prescribed performance can be guaranteed by achieving
where and are constants. Additionally, it must be pointed out that and should be chosen such that
Remark 2.
The principle of PPC is to transform the tracking error constrained by the performance function into an unconstrained error that is better handled. Reference [29] stated that the prescribed performance is guaranteed when the tracking error converges to an arbitrarily small set of residuals and the convergence rate and maximum overshoot are less than prescribed values. Therefore, to solve the control problem with prescribed performance (3), a smooth and strictly increasing function of the transformed error is defined which satisfies
- (i)
- (ii)
For the properties of , condition (3) equals
As is strictly monotonically increasing and the inverse function can be written as
From the above analysis, it can be observed that if is bounded, then the prescribed performance (3) can be guaranteed. To facilitate the control design to stabilize in (4), the transformed function can be chosen as
moreover, from (5), the transformed error can be deduced as
Therefore, based on (1), (4), and (5), the derivation of transformed error is derived as
where and .
Remark 3.
It is noted that specifies the upper bound of the maximum overshoot, and represents the lower one; the decreasing rate of embodies a lower bound on the needed speed of convergence of , which is drawn to . Furthermore, on behalf of the maximum allowable size of the tracking error at the steady state, the positive parameter can be selected to be arbitrarily small to promote the tracking accuracy.
2.3. Disturbance Observer
In system (1), the disturbance is unknown. For estimating , the following nonlinear DOB is designed as
where , represents the internal states of the DOB, and .
From (7), we know
Let , based on (1), (7) and (8). Then, the disturbance estimation error system can be described as
Remark 4.
In the actual control system, it is necessary to design a controller with robustness for avoiding the influences of model uncertainty, parameter perturbation, external disturbances, and other factors. The DOB-based controller can effectively eliminate the influence caused by the above factors. In addition, the composite controller with DOB can be divided into two parts, inner ring and outer ring, which is convenient for design and implementation. Concretely speaking, the inner ring can improve the robustness of the system, and the outer one can be flexibly designed to achieve control objection. Additionally, through the compensation of equivalent disturbance by DOB, the system can present the nominal performance, thereby facilitating the design of the outer-ring of controller.
3. Main Results
This section can be divided into two parts. First, a composite controller is recursively designed by means of the back-stepping method and the nonlinear disturbance observer constructed above. Secondly, the main results of this paper are derived from two theorems with strict proofs.
3.1. Composite Controller
For simplifying the expression of functions, a function can be rewritten as or f in the following analysis. The design procedures of back-stepping composite controller are given as follows:
STEP 1. Consider the first subsystem as
Choose a Lyapunov function as
According to (9) and (12), the time derivative of yields
through the help of Lemmas 3 and 4, and (11), one gets
and by applying the first inequality of Lemma 5 with , we obtain
where .
Using the same , let of the first inequality of Lemma 5. This yields
where .
Meanwhile, with the help of the second inequality of Lemma 5, let and . We get
where .
Now, we select
where
By substituting (15)–(18) and the control law (19) into (14), the latter is rewritten as
STEP 2. Based on , (10) and (19), we have
Choose the following Lyapunov function
Combine (9), (20) and (21). The derivative of is depicted by
where is a non-negative constant under the second condition of Assumption 1.
Currently, is designed as
where , , and are designed next.
Meanwhile, by applying Lemma 5, it follows that
where .
A similar argument for (15)–(17) in Step 1 leads to
where , and .
By substituting (25) and (26) and the control law (24) into (23), it is rewritten as
STEP 3. Similarly to Step 2, consider and (24). We have
Choose the following Lyapunov function:
By combining (9), (27), and (28), the derivative of is concluded as
where is a non-negative constant under the second condition of Assumption 1.
Currently, is designed as
where , and are designed later.
Meanwhile, by applying Lemma 5, it follows that
where
Similarly, the processing of (26) in Step 2 leads to
where , and .
By substituting (31) and (32) and the control law (30) into (29), it is rewritten as
STEP i. At Step with we assume there exists a continuously differential function such that
It is obvious that when , (34) is (33). In what follows, we will give strict proof that (33) also holds at the ith step:
For this purpose,
and the Lyapunov function can be chosen as follows:
Enlightened by (9), (11), and (34), we get the following inequality spontaneously:
where is a non-negative constant under the second condition of Assumption 1.
Currently, is designed as
and , , and are designed later.
Now applying Lemma 5 again, it follows that
where
Furthermore,
where , and .
By substituting (38) and (39) and the control law (37) into (36), it is rewritten as
STEP n. In particular, the actual controller that we truly need can be found at the last step. can be expressed as
and the Lyapunov function also can be chosen as
Through the same process above, we select
and the derivative of can be found straightforwardly:
Remark 5.
In the whole process above, in order to counteract the crossing terms consisting of the coupling among disturbances, system states, and compensation errors, two sets of auxiliary terms, and , are constructed and introduced into both the virtual laws and actual control input of the back-stepping control design.
3.2. Stability Analysis
So far, the design of a back-stepping control protocol has been achieved. The two conclusions areas follows.
Theorem 1.
Proof of Theorem 1.
Choose the Lyapunov function as
according to former work (42), one has
In order to facilitate the following theoretical analysis, we select a constant , and let . Then, (43) is rewritten as
where .
Consider (44). It is plain that when one has
Therefore, according to Lemma 1, regarding e and as state and input, respectively, the closed-loop system is input-to-state stable. Furthermore, it follows that are uniformly ultimately bounded [36]. □
3.3. Prescribed Performance and Convergence Analysis
Next, we discuss the asymptotical output tracking of system (1) with disturbances and the prescribed performance control.
Theorem 2.
Under Assumptions 1 and 2, consider the nonlinear system (1) with disturbance observer (7) and composite controller (41). Then, the following three control objectives are achieved:
- (i)
- the disturbance estimation error asymptotically converge to zero;
- (ii)
- the tracking error satisfies
- (iii)
- the prescribed performance (3) is guaranteed.
Proof of Theorem 2.
Then, we have therefore,
According to Theorem 1, regarding as the control input to system (1), with the help of the second condition of Assumption 1 and Lemma 2, the states satisfy
- which implies that
In addition, since is bounded, is bounded. According to the properties of transforming function in Remark 2, which means that Thus, the tracking error with prescribed error performance (3) is achieved. □
Remark 6.
The control protocol proposed in this paper can achieve a global results for any initial conditions, and also can satisfy any performance constraints about the speed of convergence, the steady-state error, and the overshoot, which are various in practical engineering applications.
Remark 7.
In the proposed control protocol, the selection of the parameters and should be proper to guarantee the initial conditions of prescribed performance . For instance, a large will lead the tracking error to be close to its boundary, which causes a large control input . However, this situation may be too strict to fit the limitations of the hardware. Reselecting the parameters and may be a practicable solution.
4. Simulation
In order to show the practical effectiveness of the design protocol proposed in this paper, we applied it to the following second-order nonlinear system as an application and illustration:
where . Our objective was to track the expected signal .
In this case, consider , and the disturbances are given as
In addition, let the initial condition Additionally, we selected the parameters and ; and , and of the prescribed performance function and the composite controller, respectively.
Figure 1 shows the simulation results. Firstly, as Figure 1a shows, the prescribed performance of tracking error can be confirmed, and disturbances have been rejected superbly by the controller, which shows the effectiveness of the proposed control protocol. Secondly, Figure 1b presents the curves of the output , the given signal , and the state of , which indicates that is bounded and can fit completely in less than 5 s. Thirdly, The curve of input can be seen in Figure 1c, which is also bounded. It is noted that when there are large fluctuations in disturbances from to , also changes considerably at and . Lastly, Figure 1d ensures the effectiveness of disturbance observer by showing that and can be well estimated. Therefore, it is obvious that the proposed composite controller achieves all the control objectives, which proves that it has good tracking control and anti-disturbance performance.
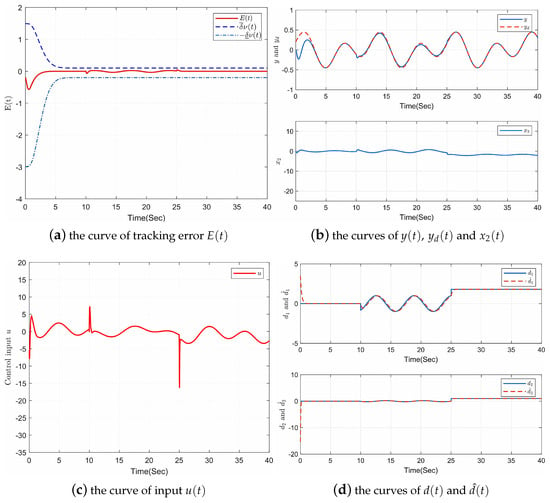
Figure 1.
Response curves of system (45).
Remark 8.
It is worth noting that the first-order case of above example can be applied to the single-link robot dynamic equation as a engineering application. The single-link robot dynamic equation proposed by Ho et al. [39] can be described as
where , and q are the mass, the length, and the angle of the link; and denote the moment of inertia and the gravity coefficient, respectively; u is the controlling torque. Let q and be and ; and are unknown external disturbances. (10) can be written as
Let , (47) is the first-order case of (45) as
5. Conclusions
In this article, the prescribed performance tracking control and anti-disturbance control problems have been solved for a class of high-order, strict-feedback systems with external disturbances. With the help of the PPC method, the DOB technique, the back-stepping method, and the technique of adding a power integrator, a novel composite controller was developed to guarantee that all states in the closed-loop system are stable and the tracking error maintains the prescribed performance throughout the evolution. In addition, the output tracking error converges to zero when the disturbances satisfy a weak assumption of boundedness. At last, a numerical simulation was presented to show the effectiveness of the theoretical result.
Author Contributions
Conceptualization, X.T. and H.J.; methodology, X.T.; software, X.T.; validation, X.T. and H.J.; writing—original draft preparation, X.T.; writing—review and editing, X.T.; supervision, H.J.; project administration, H.J.; funding acquisition, H.J. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported jointly by National Natural Science Foundation of China (62163035), by the Key Project of Natural Science Foundation of Xinjiang (2021D01D10), by Xinjiang Key Laboratory of Applied Mathematics (XJDX1401), and by the Special Project for Local Science and Technology Development Guided by the Central Government (ZYYD2022A05).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
References
- Kim, B.; Calise, A. Nonlinear flight control using neural networks. J. Guid. Control Dynam. 1997, 20, 26–33. [Google Scholar] [CrossRef]
- Nijmeijer, H.; Van der Schaft, A. Nonlinear Dynamical Control Systems, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Liu, C.; Liu, X.; Wang, H.; Lu, S.; Zhou, Y. Adaptive control and application for nonlinear systems with input nonlinearities and unknown virtual control coefficients. IEEE Trans. Cybern. 2022, 52, 8804–8817. [Google Scholar] [CrossRef] [PubMed]
- Oishi, Y.; Sakamoto, N. Optimal Sampled-Data Control of a Nonlinear System. arXiv 2021, arXiv:2112.145072021. [Google Scholar]
- Kawan, C.; Mironchenko, A.; Swikir, A.; Noroozi, N.; Zamani, M. A Lyapunov-based small-gain theorem for infinite networks. IEEE Trans. Autom. Control 2021, 66, 5830–5844. [Google Scholar] [CrossRef]
- Sontag, E. Stabilization implies coprime factorization. IEEE Trans. Autom. Control 1989, 34, 435–443. [Google Scholar] [CrossRef]
- Yu, P.; Qi, D.; Sun, Y.; Wan, F. Stability analysis of impulsive stochastic delayed Cohen-Grossberg neural networks driven by Levy noise. Appl. Math. Comput. 2022, 434, 127444. [Google Scholar] [CrossRef]
- He, D.; Huang, H. Input-to-state stability of efficient robust H∞ MPC scheme for nonlinear systems. Inf. Sci. 2015, 292, 111–124. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, Z.; Zhang, Y.; Philip Chen, C. Adaptive neural inverse optimal tracking control for uncertain multi-agent systems. Inf. Sci. 2022, 584, 31–49. [Google Scholar] [CrossRef]
- Pu, Z.; Rao, R. LMI-based criterion on stochastic ISS property of delayed high-order neural networks with explicit gain function and simply event-triggered mechanism. Neurocomputing 2020, 377, 57–63. [Google Scholar] [CrossRef]
- Nekhoroshikh, A.; Eflmov, D.; Fridman, E.; Perruquetti, W.; Furtat, L.; Polyakov, A. Practical fixed-time ISS of neutral time-delay systems with application to stabilization by using delays. Automatica 2022, 143, 110455. [Google Scholar] [CrossRef]
- Mancilla-Aguilar, J.; Haimovich, H. (Integral-)ISS of switched and time-varying impulsive systems based on global state weak linearization. IEEE Trans. Autom. Control 2021, 67, 6918–6925. [Google Scholar] [CrossRef]
- Gao, L.; Liu, Z.; Wang, S.; Qu, M.; Zhang, M. Input-to-state stability for discrete hybrid time-delay systems with admissible edge-dependent average dwell time. J. Franklin Inst. 2021. [Google Scholar] [CrossRef]
- Gong, Y.; Guo, Y.; Ma, G.; Ran, G.; Li, D. Predefined-time tracking control for high-order nonlinear systems with control saturation. Int. J. Robust Nonlinear Control 2022, 32, 6218–6235. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Cheng, D. Output tracking of Boolean control networks. IEEE Trans. Autom. Control 2019, 65, 2730–2735. [Google Scholar] [CrossRef]
- Wu, C.; Pan, W.; Sun, G.; Liu, J.; Wu, L. Learning tracking control for cyber-physical systems. IEEE Internet Things J. 2021, 8, 9151–9163. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, S.; Jiang, H.; Hu, C. Distributed consensus for multi-agent systems via adaptive sliding mode control. Int. J. Robust Nonlinear Control 2021, 31, 7125–7151. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, Y.; Ma, D. Output regulation for switched systems with multiple disturbances. IEEE Trans. Circuits Syst. Regul. Pap. 2020, 67, 5326–5335. [Google Scholar] [CrossRef]
- Liu, S.; Feng, J.; Wang, Q.; Song, W. Adaptive consensus control for a class of nonlinear multi-agent systems with unknown time delays and external disturbances. Trans. Inst. Meas. Control 2022, 44, 2063–2075. [Google Scholar] [CrossRef]
- Huang, J.; Chen, Z. A general framework for tackling the output regulation problem. IEEE Trans. Autom. Control 2004, 49, 2203–2218. [Google Scholar] [CrossRef]
- Back, J.; Shim, H. Adding robustness to nominal output-feedback controllers for uncertain nonlinear systems: A nonlinear version of disturbance observer. Automatica 2008, 44, 2528–2537. [Google Scholar] [CrossRef]
- Wang, W.; Guo, P.; Hu, C.; Zhu, L. High-performance control of fast tool servos with robust disturbance observer and modified H∞ control. Mechatronics 2022, 84, 102781. [Google Scholar]
- Santina, C.; Turby, R.; Rus, D. Data-driven disturbance observers for estimating external forces on soft robots. IEEE Robot. Autom. Lett. 2020, 5, 5717–5724. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, D.; Shen, G.; Sun, Z.; Xia, Y. Disturbance observer based adaptive fuzzy sliding mode control: A dynamic sliding surface approach. Automatica 2021, 129, 109606. [Google Scholar] [CrossRef]
- Zhang, W.; Wei, W. Disturbance-observer-based finite-time adaptive fuzzy control for non-triangular switched nonlinear systems with input saturation. Inf. Sci. 2021, 561, 152–167. [Google Scholar] [CrossRef]
- Krstic, M.; Kokotovic, P.; Kanellakopoulos, I. Nonlinear and Adaptive Control Design; John Wiley & Sons, Inc.: New York, NY, USA, 1995. [Google Scholar]
- Wang, J.; Rong, J.; Lu, L. Reduced-order extended state observer based event-triggered sliding mode control for DC-DC buck converter system with parameter perturbation. Asian J. Control 2020, 23, 1591–1601. [Google Scholar] [CrossRef]
- Bechlioulis, C.; Rovithakis, G. Prescribed performance adaptive control of SISO feedback linearizable systems with disturbances. In Proceedings of the 2008 16th Mediterranean Conference on Control and Automation, Ajaccio, France, 25–27 June 2008. [Google Scholar]
- Bechlioulis, C.; Rovithakis, G. Robust adaptive control of feedback linearizable MIMO nonlinear systems with prescribed performance. IEEE Trans. Autom. Control 2008, 53, 2090–2099. [Google Scholar] [CrossRef]
- Fu, D.; Yin, H.; Huang, J. Controlling an uncertain mobile robot with prescribed performance. Nonlinear Dyn. 2021, 5, 2347–2362. [Google Scholar] [CrossRef]
- Bai, W.; Wang, H. Robust adaptive fault-tolerant tracking control for a class of high-order nonlinear system with finite-time prescribed performance. Int. J. Robust Nonlinear Control 2020, 30, 4708–4725. [Google Scholar] [CrossRef]
- Chen, L.; Yang, H. Adaptive neural prescribed performance output feedback control of pure feedback nonlinear systems using disturbance observer. Int. J. Adapt. Control 2020, 34, 520–542. [Google Scholar] [CrossRef]
- Huang, Y.; Lin, S.; Liu, X. H∞ synchronization and robust H∞ synchronization of coupled neural networks with non-identical nodes. Neural Process. Lett. 2021, 53, 3467–3496. [Google Scholar] [CrossRef]
- Gao, F.; Chen, W. Disturbance rejection in singular time-delay systems with external disturbances. Int. J. Control Autom. 2022, 20, 1841–1848. [Google Scholar] [CrossRef]
- Chen, F.; Dimarogonas, D. Leader-follower formation control with prescribed performance guarantees. IEEE Trans. Control Netw. 2020, 8, 450–461. [Google Scholar] [CrossRef]
- Vidyasagar, M. Nonlinear Systems Analysis; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2002. [Google Scholar]
- Yang, B.; Lin, W. Homogeneous observers, iterative design and global stabilization of high-order nonlinear systems by smooth output feedback. IEEE Trans. Autom. Control 2004, 49, 1069–1080. [Google Scholar] [CrossRef]
- Qian, C.; Lin, W. Non-lipschitz continuous stabilizers for nonlinear systems with uncontrollable unstable linearization. Syst. Control Lett. 2001, 42, 185–200. [Google Scholar] [CrossRef]
- Ho, H.; Wong, Y.; Rad, A. Adaptive fuzzy approach for a class of uncertain nonlinear systems in strict-feedback form. ISA Trans. 2008, 47, 286–299. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).