1. Introduction and Previous Work
Multiple Importance Sampling (MIS) [
1,
2] has been proven efficient in Monte Carlo integration. It is able to preserve the advantages of the combined techniques and requires only the calculation of the pdfs of all methods when a sample is generated with one particular method. The weighting scheme applied in MIS depends on the pdfs of the individual techniques and also on the number of samples generated with each of them.
MIS has been applied in a number of rendering algorithms, and its variance is extensively studied [
1]. Several estimators have been proposed that are better than balance heuristics with equal sample budgets [
3,
4,
5,
6]. Lu et al. [
7] proposed an adaptive algorithm for environment map illumination, which used the Taylor series approximation of the variance around an equal sample budget case. In [
8,
9], different equal sample number strategies were analyzed. Sbert et al. [
10] considered the cost associated with the sampling strategies and obtained an adaptive solution by optimizing the variance using the Newton–Raphson method [
11]. In [
12], the Kullback–Leibler divergence was optimized instead of the variance. Several authors have shown that the variance of an importance sampling estimator is equal to a chi-square divergence [
13,
14,
15,
16], which, in turn, can be approximated by the Kullback–Leibler divergence up to the second order [
17]. The optimal sample budget has also been targeted with neural networks [
15,
18]. Recently, a theoretical formula has been elaborated for the weighting functions [
19]. In [
16], the balance heuristic estimator was generalized by decoupling the weights from the sampling rates, and implicit solutions for the optimal case were given.
These techniques offer lower variance and, therefore, theoretically outperform MIS with equal number of samples. However, equations determining the optimal weighting and sample budget require the knowledge of the integrand and numerical solution methods. In computer graphics, for example, this integrand is not analytically available, so previous discrete samples should be used for the approximation, which introduces errors in the computation. Thus, it is not guaranteed that a theoretically superior estimator also performs better in practice.
This paper proposes an adaptive approach to automatically determine the sampling budgets of the combined methods based on the statistics of previous samples. To improve the robustness, instead of directly optimizing the variance, we make the combined pdf mimic the integrand by minimizing the divergence between them. From the possible alternatives, the Tsallis -divergence is used since this leads to a general and stable approach. We show that finding the optimum in all cases, including also Hellinger, chi-square, Kullbach–Leibler divergences, and the variance, boils down to a non-linear equation stating that the -moments of the different combined techniques must be equal. This equation has unique root that can be found by Newton–Raphson iteration.
The organization of the paper is the following. In
Section 2, the multi-sample version of the MIS estimator is reviewed where the number of samples allocated to each combined technique is fixed deterministically.
Section 3 summarizes the one-sample MIS estimator where the particular sampling method is also selected randomly. In
Section 4, the adaptation of the MIS weighting functions is discussed and we argue that the adaptation should be controlled not by the estimated variance but by an appropriately chosen divergence.
Section 5 reformulates the MIS problem as the optimization of divergences and introduces the
-moments. In
Section 6, the details of the numerical optimization are discussed. Finally, the results are demonstrated with numerical examples and the direct lighting solution of computer graphics.
2. Multi-Sample Balance Heuristic Mis
Suppose we wish to estimate the value of integral and have m proposal pdfs to generate the jth sample of method i in the domain of the integral. With method i, independent samples are drawn, so the total number of samples is . When the sample numbers are fixed deterministically, the approach is called multi-sample.
The multi-sample MIS estimator [
1] has the following expression:
where the weights satisfy the normalization condition:
Integral estimator
F is unbiased, as its expected value
is equal to the integral:
where
. The variance of the integral estimator is
The variance of the estimator depends on the combination weights
. The first step of their definition is to propose an algebraic form. The
balance heuristic states that the weight of method
i at domain point
x should be proportional to the density of samples generated by method
i in this point:
where
is the
fraction of the samples allocated to method
i, and
is the
mixture pdf:
Substituting this weighting function into the MIS estimator formulas, we obtain the multi-sample balance heuristics estimator:
The variance of the balance heuristics estimator is
where
.
3. One-Sample Balance Heuristic MIS
In the one-sample version of MIS, the numbers of samples used by particular techniques are not determined before starting the sampling process, but for each sample, the sampling method itself is selected randomly with the probability of fraction parameter . As this approach introduces additional randomization, its variance is larger than that of the multi-sample version, but can also be used in cases when the number of total samples is less than the number of combined methods.
The one-sample balance heuristic estimator is given by
with variance
4. Adaptive MIS
Having the algebraic form of the weight function, the task is to find the optimal fractions with the constraint that the sum of sample numbers must be equal to the total sample budget, i.e., . One possibility is to use some heuristics before starting the sampling process. A simple example is the equal sample count MIS that sets all fractions to be equal.
Adaptive techniques, on the other hand, try to minimize the error by controlling the fractions on-the-fly as new samples introduce additional information. During this, the following issues need to be considered:
The integrals in the variance cannot be computed analytically, but must be estimated from the available finite number of samples drawn from the sampling distribution. This uncertainty may significantly affect the goodness of the final results.
The optimization process should be fast and should not introduce too high overhead.
Unfortunately, the direct optimization for the variance does not meet these requirements. The integral of the variance can be estimated from the available samples
drawn from mixture distribution
as:
where
is the expectation of random variable
of pdf
p. In this estimation, the ratios of the integrand and the pdf are squared causing high fluctuation and making the optimization process unstable.
Thus, instead of the variance, we need other optimization targets with more robust estimators in order to find the fractions during adaptation.
5. MIS as Divergence between Distributions
MIS consists in looking for a distribution that mimics as much as possible. If we have non-negative integrand with integral , then the integrand scaled down by the integral is also a distribution. The MIS problem can be stated as finding mixture pdf that minimizes the divergence between two distributions.
5.1. -Divergences
A
-divergence
[
20,
21] is a measure of the dissimilarity between two probability distributions
and
. It is defined by a convex function
satisfying
:
-divergences are always positive (by Jensen inequality) and are zero iff
(for strict convexity) [
21].
For instance, for
, we obtain the Kullback–Leibler divergence:
Note that
-divergence is not symmetric, thus we have in principle two options to measure the dissimilarity of probability densities
q and
r, using either
or
. Any of these two options can be used in practice, although they are not independent. If we define
then
[
22]. For
, we have
.
The objective of importance sampling is to make probability density
similar to scaled integrand
, i.e., to minimize
-divergence
. A
-divergence is a convex function in both arguments and
is a linear function of
, thus the functional is convex in
. This will ensure the existence of a minimum. With choosing
, we can get the variance back as a special case of this more general approach:
The optimal MIS problem is reduced to find the minimum of
with the constraints
and
. Using Lagrange multipliers, the solution is
which means that the derivatives of the divergence with respect to fractions
must be the same for each sampling method
i.
The derivative can be expressed as
This integral is the expectation when samples are generated with pdf
, thus we can write
Equation (
16) only holds when
, i.e., in the interior of the simplex domain, not on the border.
Swapping the two distributions in the
-divergence, we have another measure for the dissimilarity between
and
g,
. Using Lagrange multipliers again, this leads to the following equation for unknown fractions
Using expected values, this option is expressed as
The problem with the optimization of the variance was that in the resulting equation the ratios of the sampled integrand and the pdf are squared (see Equation (
10)), making the equation sensitive to non-optimal pdfs. With the proper definition of
, we can solve this issue. For example, if
, then
, and the condition of optimality is
Remembering that
, the last equation can also be written as
which contains the ratios without squaring. This gives back the solution in [
23], which is also conjectured in [
16]. To further exploit this idea, we take the parametric family of Tsallis divergences. With its parameter the compromise between the robustness of the optimization equation and the similarity to the variance can be controlled.
5.2. Tsallis Divergences
Tsallis divergence [
24] is associated with the Tsallis entropy [
25]. Let us consider the one-parameter Tsallis divergence between distributions
and
:
Tsallis divergence
is a
-divergence defined by
Parameter
should satisfy
and
, which guarantees that
exists and is convex.
It can be shown that
is the Kullbach–Leibler divergence. When
, Tsallis divergence turns to be the chi-square divergence:
For
, Tsallis divergence
becomes the squared Hellinger distance
:
Note that
is a true metric.
5.3. Optimal MIS Solution with Tsallis Divergence
Optimal MIS needs to find fractions
that minimize
with the constraint
. Substituting function
of Tsallis divergence into Equation (
16), we obtain that for all
i, the quantities, called
γ-moments,
have to be equal. Equation (
25) guarantees a global minimum, as the function
is convex for all
. Considering the case when
and
are swapped in the divergence, i.e., substituting function
of Tsallis into Equation (
17), the requirement of the equality of the
-moments is established again, but now
should be replaced by
. Examining Equation (
20) we can realize that optimizing for
is the same as minimizing the cross entropy or the Kullbach–Leibler divergence. Thus, the criterion of the equality of the
-moments covers all cases.
5.4. Other -Divergences: Total Variation Divergence, and Divergences
The total variation can also be interpreted as a
-divergence defined by
:
This is the only
-divergence that is a true metric [
26]. The condition of optimality is
for all
i, although we can hardly use Equation (
26) to approximate a solution.
-divergences also include the Pearson–Vajda
and
divergences:
defined by the functions
and
, respectively [
17]. For
, we have
, and for
, identities
and
hold.
6. Finding the Optimal Solution
For the sake of simplicity, we assume that two sampling methods of pdfs
and
, associated with fractions
and
are combined. The mixture density is
From the optimality condition of Equation (
25), we obtain
This is a non-linear equation for unknown fraction
, which is solved with Newton–Raphson iteration. The derivative of
is
as
.
The value of
and its derivative can be estimated in the following way. Let us re-write
as an expectation:
Taking
N samples
according to pdf
, we have the estimator
and in the same way,
The integrals are estimated with an iterative algorithm updating
after each iteration. Starting with
, in iteration
k we draw
N samples according to
, compute
and
, and use the Newton–Raphson formula to obtain updated fraction
:
7. Numerical Examples
We present here three 1D examples. We used the Mathematica package for the computations.
7.1. Example 1
Suppose we want to evaluate the integral (see
Figure 1)
by MIS combining sampling methods of pdfs
and
, where
stands for the normal distribution of mean
m and standard deviation
. For this example, equal sample number MIS has variance
, and the minimum variance is
.
In
Figure 2, we show the variances
and
for the optimal solution of Tsallis divergences from
to
in steps of 0.1. Dots depict the values of
for the optimal
fractions for each parameter
using 5 Newton–Raphson iterations with 100 total samples in each iteration.
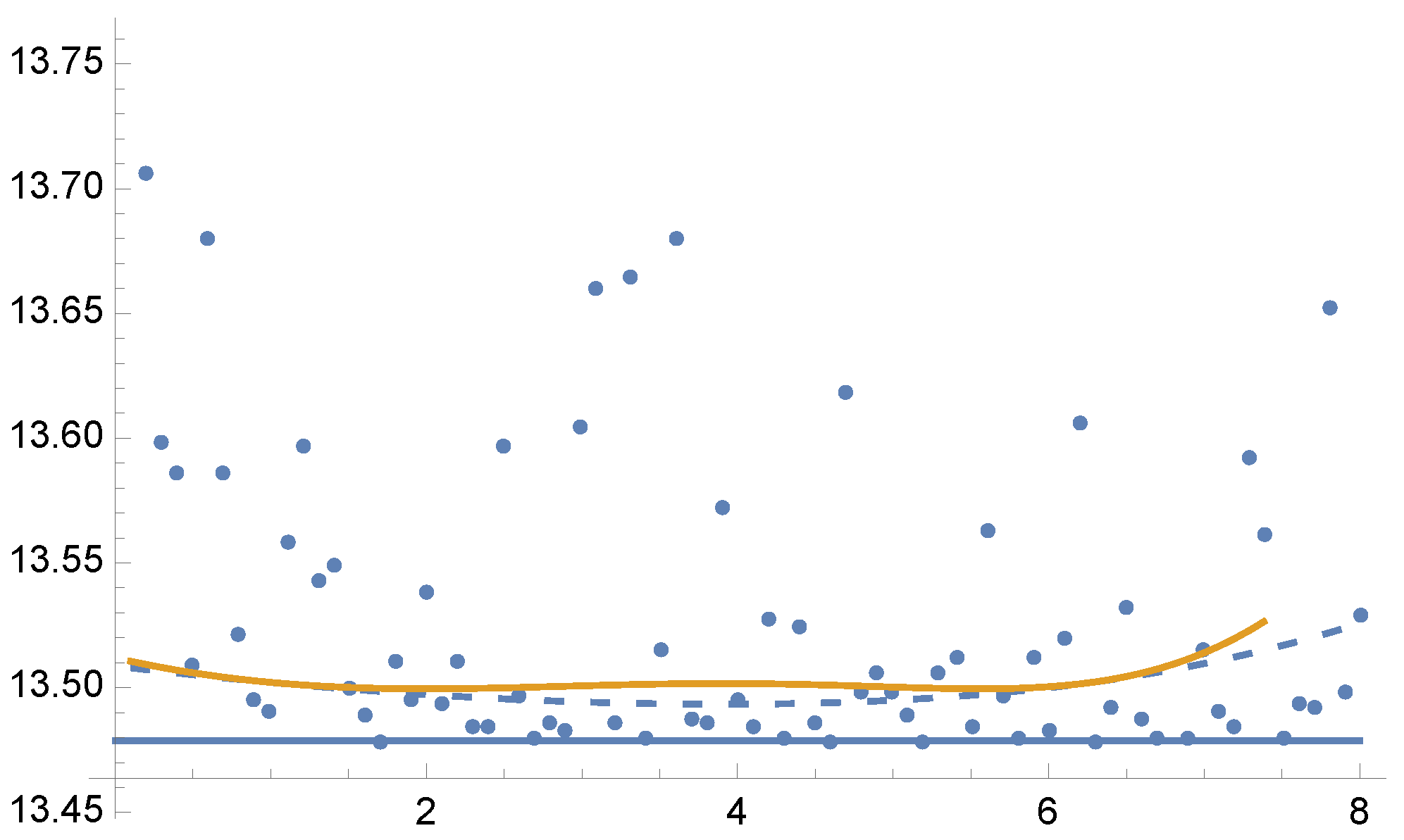
Figure 2.
Example 1: Values of
(dashed line) and
(continuous line) for the solution of Equation (
25) for each value of parameter
from 0.1 to 8, in the horizontal axis. Variance
(continuous line) is minimal when
, as
corresponds to
divergence (Equation (
13)). Dots show the variance
for the optimal
values for each parameter
using 5 Newton–Raphson iterations with 100 total samples in each iteration. Horizontal line corresponds to the minimum variance
. A zoom-out is shown in
Figure 3.
Figure 2.
Example 1: Values of
(dashed line) and
(continuous line) for the solution of Equation (
25) for each value of parameter
from 0.1 to 8, in the horizontal axis. Variance
(continuous line) is minimal when
, as
corresponds to
divergence (Equation (
13)). Dots show the variance
for the optimal
values for each parameter
using 5 Newton–Raphson iterations with 100 total samples in each iteration. Horizontal line corresponds to the minimum variance
. A zoom-out is shown in
Figure 3.
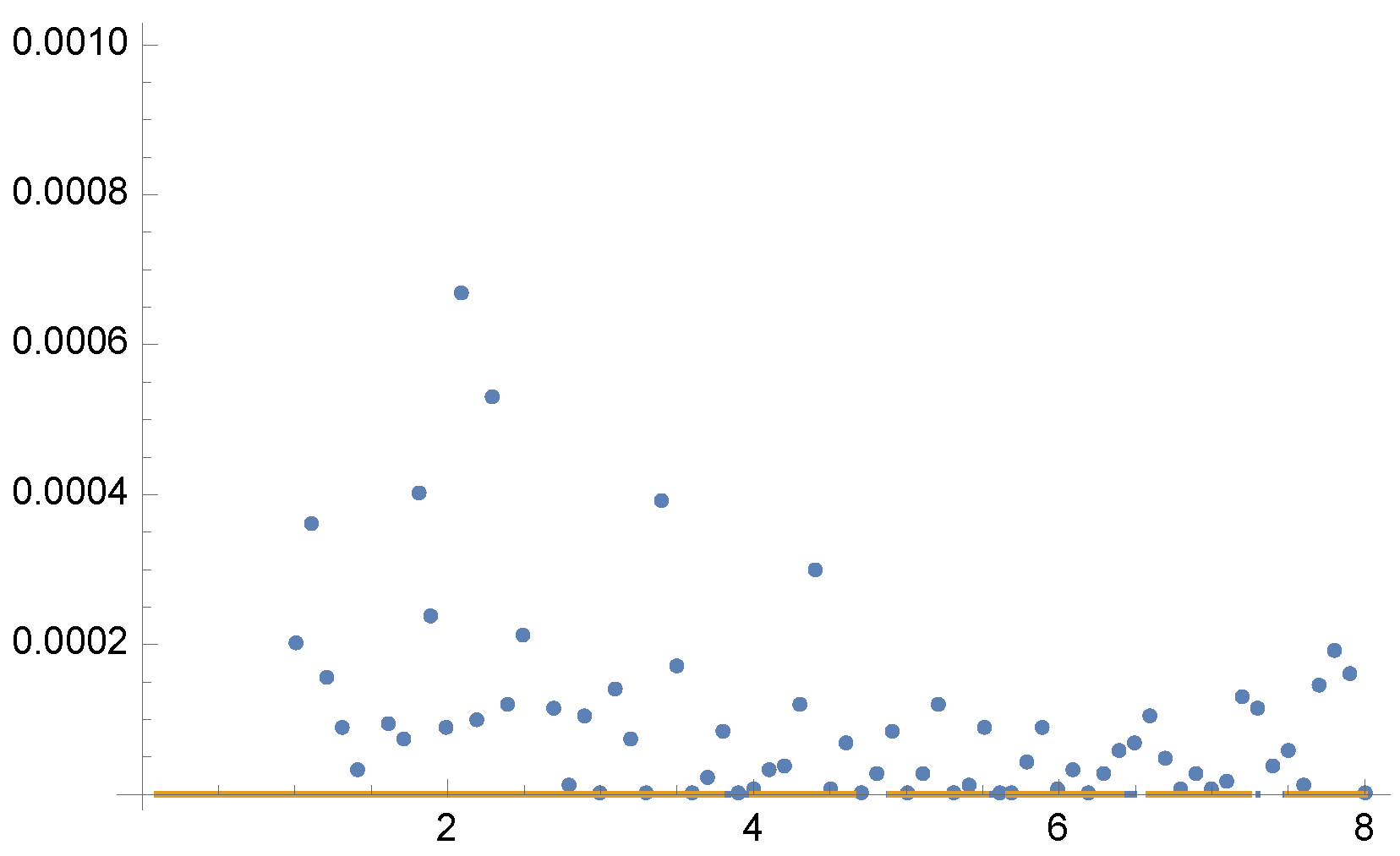
Figure 3.
Example 1. Zoom-out of
Figure 2. Observe that
except for
where
. For the equal sample budget case,
, while the minimum is
.
Figure 3.
Example 1. Zoom-out of
Figure 2. Observe that
except for
where
. For the equal sample budget case,
, while the minimum is
.
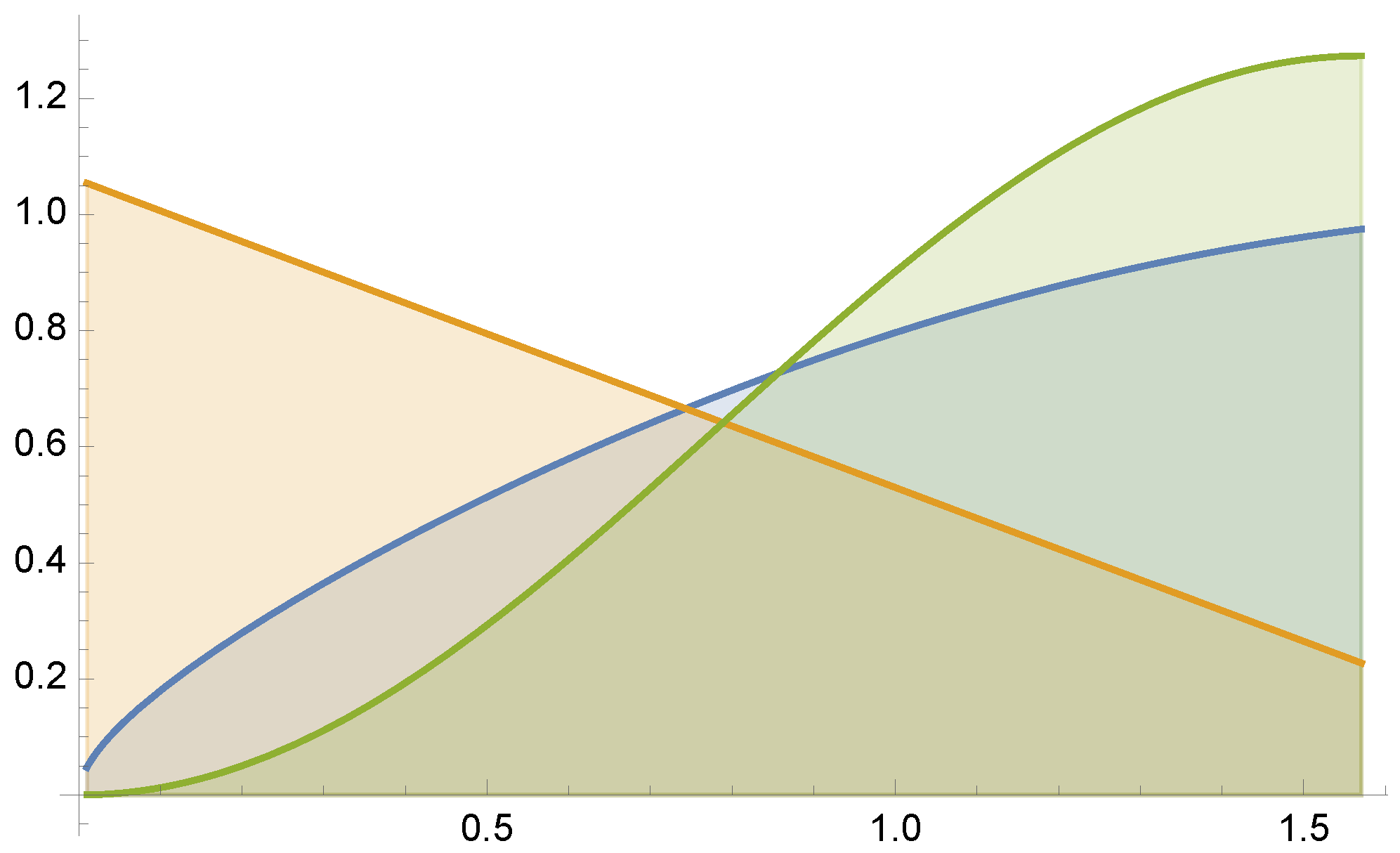
7.2. Example 2
Let us consider integral (see
Figure 4)
by MIS using functions
and
. For this example, equal sample number MIS has a variance of
, and the minimum variance is
.
Figure 5 and
Figure 6 present the optimal solutions and the results after 5 Newton–Raphson iterations with 100 total samples in each iteration.
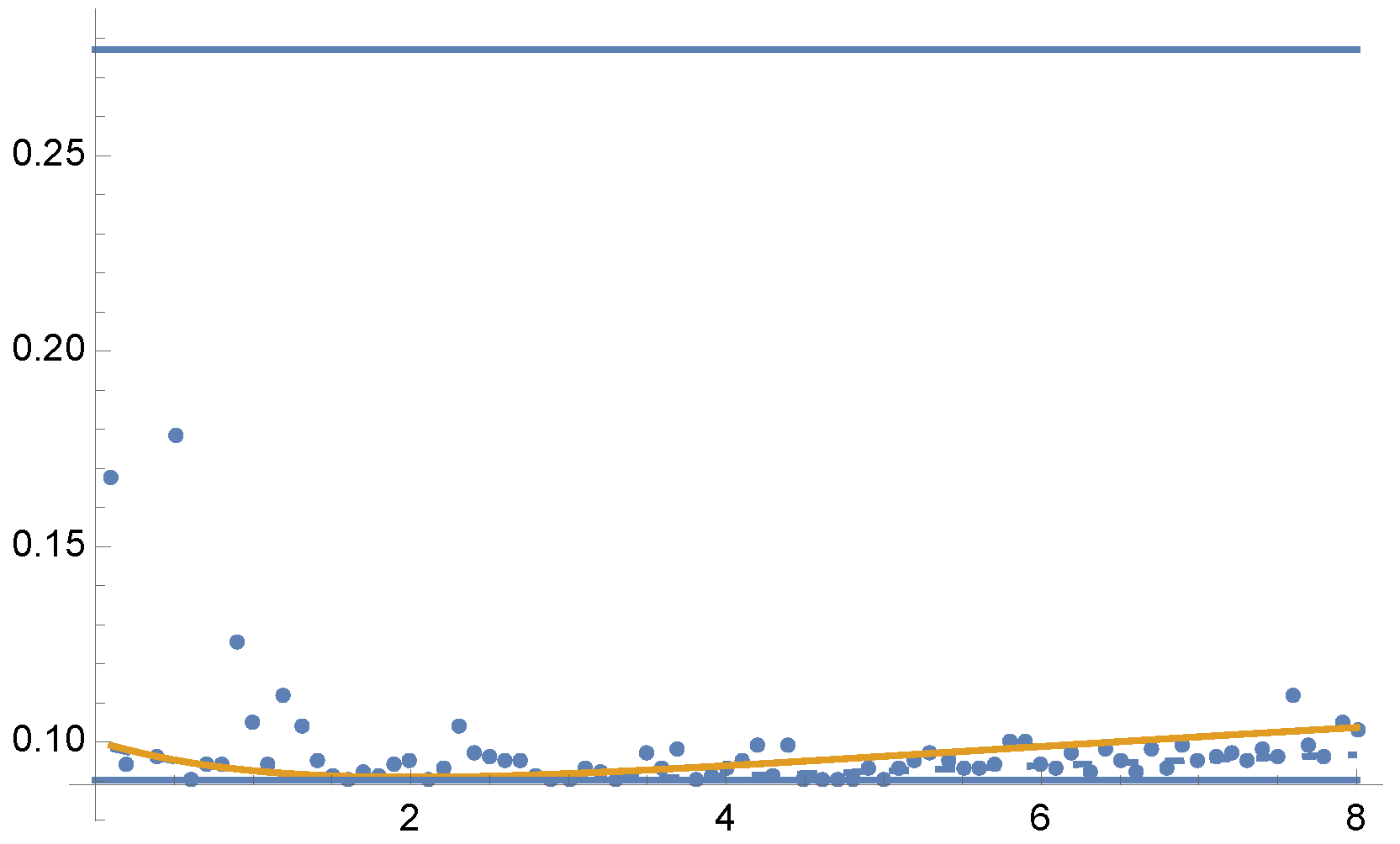
7.3. Example 3
Finally, consider the approximation of the following integral (see
Figure 7)
by MIS using functions
, and
. For this example, equal sample budget MIS has a variance of
, and the minimum variance is
. In
Figure 8 and
Figure 9 we show the variances
and
for the optimal solution for parameters from
to
. Dots are the results of
using 5 Newton–Raphson iterations with 100 total samples in each iteration.
8. Combination of Light Source Sampling and BRDF Sampling in Computer Graphics
Here we consider a classical problem of computer graphics, the combination of light source sampling and BRDF (Bidirectional Reflectance Distribution Function) sampling. To compute the reflected radiance
of a surface point
at direction
, the following integral should be evaluated in the hemispherical domain of incident directions
:
where
is the radiance of point
visible from point
in incident direction
,
is the BRDF expressing the portion of the light beam that is reflected from direction
to
at point
and
is the angle between the surface normal at point
and incident direction
. While solving such problems, we have two sampling methods,
approximately mimicking the
factor and
mimicking the incident radiance
.
MIS would use a combined pdf in the following form
where the task is the optimal determination of weight
.
In order to test the proposed method, we render the classic scene of Veach [
1] with combined light source and BRDF sampling. The shiny rectangles have max-Phong BRDF [
27] with shininess parameters 50, 100, 500, and 1000, respectively. The four spherical light sources emit the same power.
For each pixel, we used 50 samples in total organized in 5 iterations. The process starts with 5 BRDF and 5 light source samples per pixel, and the per-pixel
weights are updated at the end of each iteration.
Figure 10 shows the rendered images together with the
-maps, and we compare the original sampling techniques, equal count MIS, variance minimization, and Tsallis divergence. The reference obtained by high number of samples is shown by
Figure 11.
Table 1 depicts the Root Mean Square Error (RMSE) values.
Figure 12 shows the convergence plots.
Finally, we note that
-divergences were used for global illumination as oracles for adaptive sampling in [
28].
9. Discussion
The goal of adaptive MIS is to find the weights of given pdfs that eventually lead to minimal integration error. The definition of the error may be application dependent, in this paper we chose the RMSE, which describes the variance of the estimator. We argued that instead of the direct optimization of the estimated variance, it is better to use other measures for the optimization target since the variance estimation may strongly fluctuate if the sample number is moderate, which prevents the adaptation process from converging to the real optimum. The alternative criterion is the Tsallis divergence, which includes important particular divergence types and by setting its parameter, more robust targets can be defined.
In order to demonstrate the proposed method, we took three numerical examples and a fundamental problem of computer graphics. We can observe in all examples that the adaptive MIS can significantly outperform the equal sample count MIS, thus examining adaptation strategies has theoretical and practical relevance. In the first numerical example, none of the combinations of the two sampling pdfs could well mimic the integrand, thus the computation errors are quite high and the influence of parameter is small. In the second numerical example, the integrand is proportional to an appropriate linear combination of the two sampling pdfs, thus zero variance estimator is possible. If parameter is not too small, the method could indeed compute the integral with high accuracy. This means that in easy integration problems, Tsallis divergence can be safely used. The third numerical example is a more difficult, realistic case when sufficiently high number of samples are used in each iteration step to estimate the optimization target. As expected, the optimal value of parameter is close to 2 since this is the point where Tsallis divergence becomes the variance .
In the image synthesis example, the integrand is not a weighted sum but a product where the sampling pdfs approximately mimic the factors. In this case, no zero variance MIS is possible. Unlike in the numerical examples, we took small number of samples for each pixel according to practical scenarios. The small sample number made the optimization target equation unreliable unless parameter
is reduced from 2 that corresponds to the variance. Looking at
Figure 10, we can observe that when
becomes smaller, the computed weight maps become slightly less accurate in average but also less noisy, which eventually reduces the computation error.
We have also seen in the examples that the differences between the variances corresponding to the optimal values for the different parameters
of the Tsallis divergence are small. This is in accordance with any
-divergence being a second order approximation of
divergence [
17], thus obtaining any minimum within a wide range of
parameters would be a good solution. Aside from
, which corresponds to
, the most interesting Tsallis divergence from a practical perspective is the Kullback-Leibler divergence, corresponding to
.
10. Conclusions and Future Work
We have shown in this paper that finding the optimal weights for MIS can be presented as finding the minimum -divergence between the normalized integrand and the importance pdf. Being convex, a -divergence allows convex optimization. We have singled out the Tsallis divergences with parameter as they have the further advantage that the equations for the optimal value consist of making the -moments equal. We have tested our results with numerical examples and solving an illumination problem.
In our future work we will investigate the optimal efficiencies, i.e., taking into account the cost of sampling. This has been done for the variance
(i.e.,
) in [
4,
6] where the implicit equation for the optimal solution was given. However, the efficiency equation does not allow convex optimization. Using the
-moments, or a different family of
-divergences, could help in obtaining a robust solution for the efficiency.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}