
Ponder: Enabling Balloon-Borne Based Solar Unmanned Aerial Vehicle’s Take Off Diagnosis under Little Data


Abstract
:1. Introduction
2. Background
3. Insight of Ponder
4. Methodology of Ponder
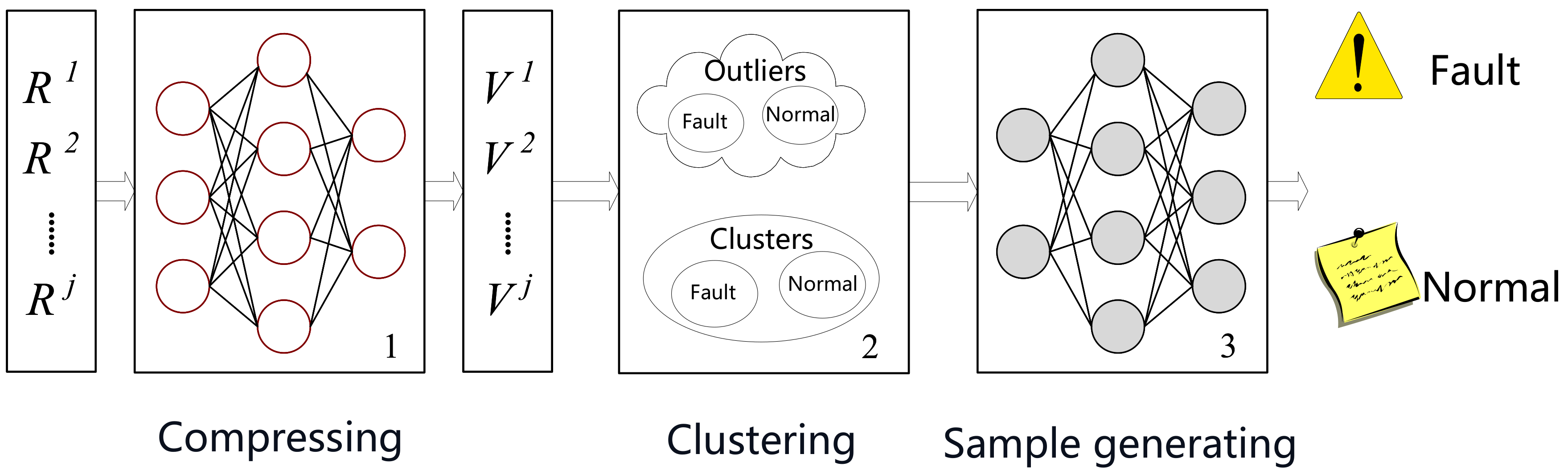
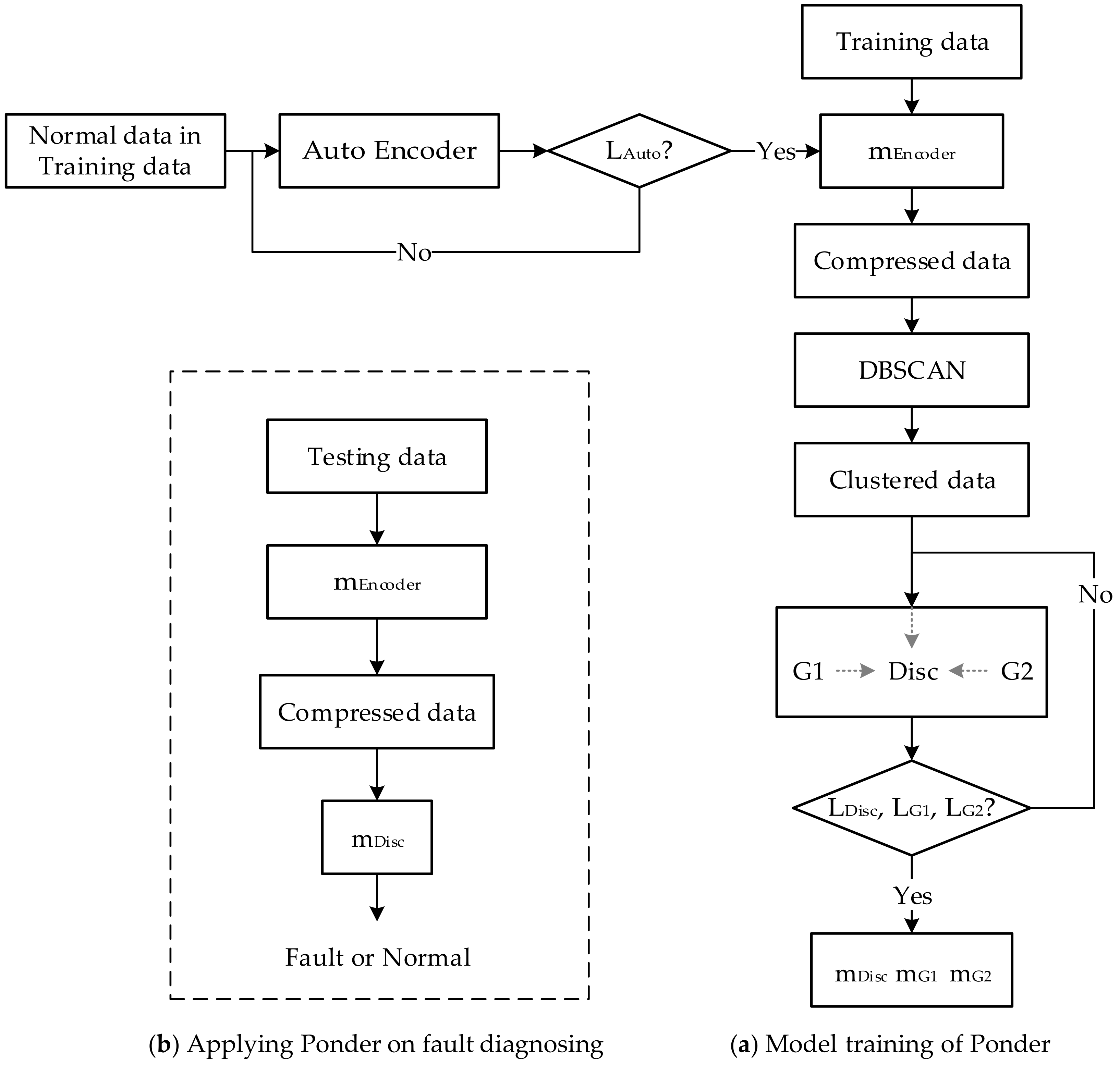
4.1. Overview of Ponder
4.2. Technical Details
4.2.1. Auto-Encoder
4.2.2. Dbscan
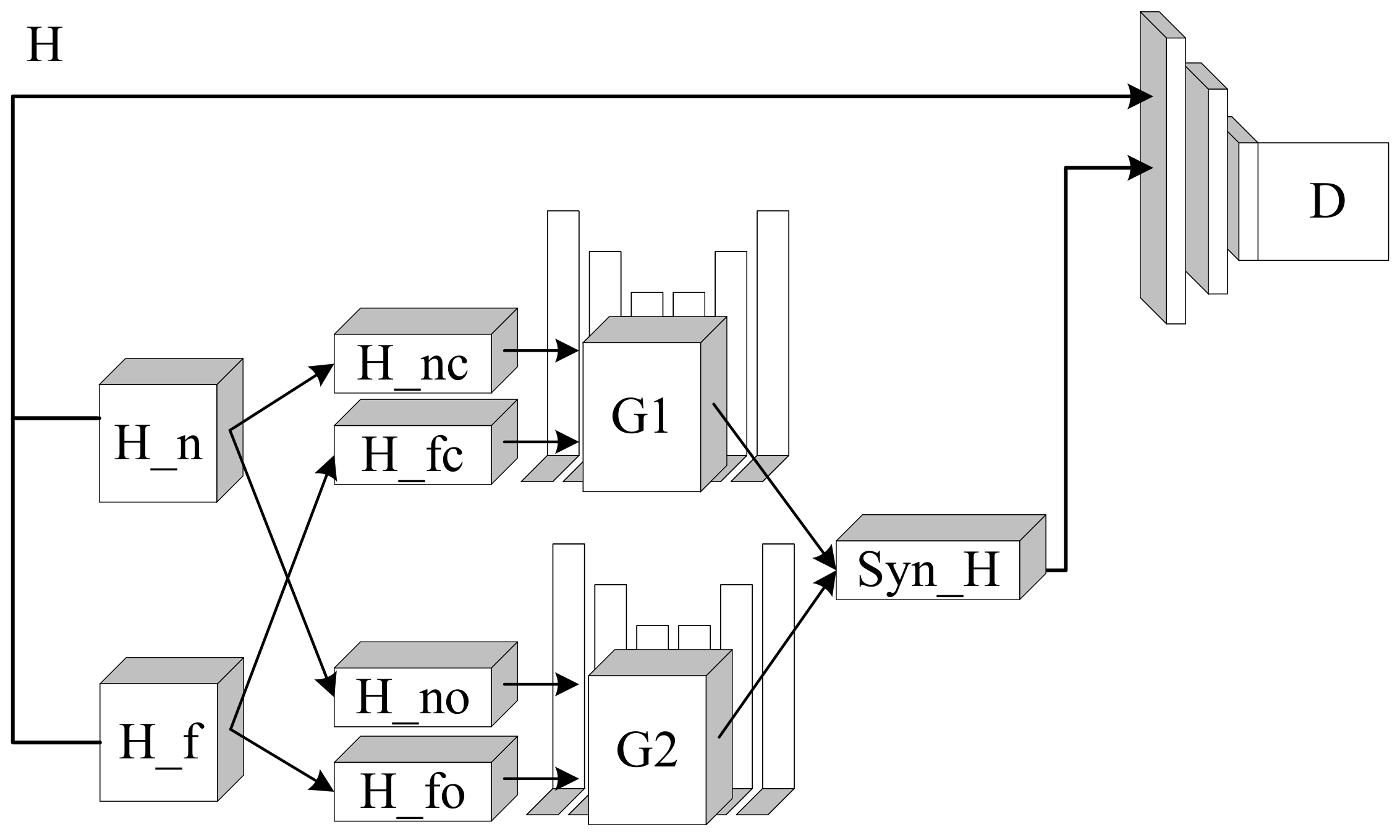
4.2.3. Modified Generative Adversarial Network
4.2.4. Hyper-Parameters
5. Evaluation
5.1. Experimental Setup
5.2. Experimental Design and Results
- : How is the performance of Ponder compared to that of DMO under the circumstance of little data?
- : How is the performance of Ponder compared to existing diagnosing models?
- : How does Ponder behave over time?
- : How much overhead does the Ponder introduce to the diagnosing model?
6. Discussion
7. Related Works
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, Y.; Yang, Y.; Ma, X.; Li, S. Computational optimal launching control for balloon-borne solar-powered unmanned aerial vehicles in near-space. Sci. Prog. 2020, 103, 0036850419877755. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Guo, J.; Meng, W.; Liu, G.; Xue, W. Longitudinal Control for Balloon-Borne Launched Solar Powered UAVs in Near-Space. J. Syst. Sci. Complex. 2022, 35, 802–819. [Google Scholar] [CrossRef]
- Keizer, M.C.O.; Teunter, R.H. Clustering condition-based maintenance for a multi-unit system with aperiodic inspections. In Safety and Reliability of Complex Engineered Systems: Proceedings of the 25th European Safety and Reliability Conference, ESREL 2015, Zürich, Switzerland, 7–10 September 2015; CRC Press: Boca Raton, FL, USA, 2015; pp. 983–991. [Google Scholar]
- Froger, A.; Gendreau, M.; Mendoza, J.E.; Pinson, E.; Rousseau, L.-M. Maintenance scheduling in the electricity industry: A literature review. Eur. J. Oper. Res. 2016, 251, 695–706. [Google Scholar] [CrossRef]
- Li, W. Advance of intelligent fault diagnosis for complex system and its present situation. Comput. Simulation 2004, 21, 4–7. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Han, L.; Deyun, X. Survey on data driven fault diagnosis methods. Control. Decis. 2011, 26, 1–9. [Google Scholar]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Mao, W.; Feng, W.; Liang, X. A novel deep output kernel learning method for bearing fault structural diagnosis. Mech. Syst. Signal Process. 2019, 117, 293–318. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Gan, M.; Wang, C.; Zhu, C. Construction of hierarchical diagnosis network based on deep learning and its application in the fault pattern recognition of rolling element bearings. Mech. Syst. Signal Process. 2016, 72, 92–104. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Guo, L.; Lin, J.; Xing, S. A neural network constructed by deep learning technique and its application to intelligent fault diagnosis of machines. Neurocomputing 2018, 272, 619–628. [Google Scholar] [CrossRef]
- Li, K.; Wang, Q. Study on signal recognition and diagnosis for spacecraft based on deep learning method. In Proceedings of the Prognostics and System Health Management Conference (PHM), Beijing, China, 21–23 October 2015; pp. 1–5. [Google Scholar]
- Li, X.; Zhang, W.; Ding, Q. A robust intelligent fault diagnosis method for rolling element bearings based on deep distance metric learning. Neurocomputing 2018, 310, 77–95. [Google Scholar] [CrossRef]
- Miao, Z.H.; Zhou, G.X.; Liu, H.N. Tests and feature extraction algorithm of vibration signals based on sparse coding. J. Vib. Shock. 2014, 33, 76–81. [Google Scholar]
- Shao, H.; Jiang, H.; Lin, Y.; Li, X. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Process. 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhao, H.; Wang, F. A novel deep autoencoder feature learning method for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2017, 95, 187–204. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Hinton, G.; Osindero, E.S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhang, X.; Niu, M. Rolling bearing fault diagnosis using an optimization deep belief network. Meas. Sci. Technol. 2015, 26, 115002. [Google Scholar] [CrossRef]
- Tamilselvan, P.; Wang, P. Failure diagnosis using deep belief learning based health state classification. Reliab. Eng. Syst. Saf. 2013, 115, 124–135. [Google Scholar] [CrossRef]
- Guo, X.; Chen, L.; Shen, C. Hierarchical adaptive deep convolution neural network and its application to bearing fault diagnosis. Measurement 2016, 93, 490–502. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Jeong, H.; Park, S.; Woo, S.; Lee, S. Rotating machinery diagnostics using deep learning on orbit plot images. Procedia Manuf. 2016, 5, 1107–1118. [Google Scholar] [CrossRef] [Green Version]
- Jia, F.; Lei, Y.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72–73, 303–315. [Google Scholar] [CrossRef]
- Wang, K.; Zhao, Y.; Xiong, Q.; Fan, M.; Sun, G.; Ma, L.; Liu, T. Research on healthy anomaly detection model based on deep learning from multiple time-series physiological signals. Sci. Program. 2016, 2016, 5642856. [Google Scholar] [CrossRef] [Green Version]
- Guo, S.; Yang, T.; Gao, W.; Zhang, C. A Novel Fault Diagnosis Method for Rotating Machinery Based on a Convolutional Neural Network. Sensors 2018, 18, 1429. [Google Scholar] [CrossRef] [Green Version]
- Jia, F.; Lei, Y.; Lu, N.; Xing, S. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal Process. 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Jan, S.T.; Hao, Q.; Hu, T.; Pu, J.; Oswal, S.; Wang, G.; Viswanath, B. Throwing darts in the dark? Detecting bots with limited data using neural data augmentation. In Proceedings of the 2020 IEEE symposium on security and privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 1190–1206. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, F.; Cohen, W.W.; Salakhutdinov, R.R. Good semi-supervised learning that requires a bad gan. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://www.xueshufan.com/publication/2963170156 (accessed on 1 December 2021).
- Niculescu-Mizil, A.; Caruana, R. Predicting good probabilities with supervised learning. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 625–632. [Google Scholar]
- Yang, L.; Guo, W.; Hao, Q.; Ciptadi, A.; Ahmadzadeh, A.; Xing, X.; Wang, G. {CADE}: Detecting and explaining concept drift samples for security applications. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual, 11–13 August 2021; pp. 2327–2344. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Dataset | G1 Generator | G2 Generator | Both Generators |
|---|---|---|---|
| Testing | 0.931 | 0.927 | 0.950 |
| D-Feb. | 0.917 | 0.911 | 0.932 |
| Dataset | D-Feb | D-Oct | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Metric | Precision | Recall | F1-Score | FPR | Prec. | Rec. | F1. | FPR | Time (ms) |
| RF | 0.82 | 0.84 | 0.83 | 0.08 | 0.78 | 0.79 | 0.79 | 0.08 | 0.17 |
| ODDS | 0.90 | 0.92 | 0.91 | 0.06 | 0.88 | 0.87 | 0.87 | 0.06 | 0.11 |
| Ponder | 0.92 | 0.94 | 0.93 | 0.04 | 0.90 | 0.91 | 0.91 | 0.04 | 0.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Jiao, Y.; Shang, Y.; Li, S.; Hu, Y. Ponder: Enabling Balloon-Borne Based Solar Unmanned Aerial Vehicle’s Take Off Diagnosis under Little Data. Entropy 2022, 24, 997. https://doi.org/10.3390/e24070997
Hu Y, Jiao Y, Shang Y, Li S, Hu Y. Ponder: Enabling Balloon-Borne Based Solar Unmanned Aerial Vehicle’s Take Off Diagnosis under Little Data. Entropy. 2022; 24(7):997. https://doi.org/10.3390/e24070997
Chicago/Turabian StyleHu, Yanfei, Yingkui Jiao, Yujie Shang, Shuailou Li, and Yanpeng Hu. 2022. "Ponder: Enabling Balloon-Borne Based Solar Unmanned Aerial Vehicle’s Take Off Diagnosis under Little Data" Entropy 24, no. 7: 997. https://doi.org/10.3390/e24070997
APA StyleHu, Y., Jiao, Y., Shang, Y., Li, S., & Hu, Y. (2022). Ponder: Enabling Balloon-Borne Based Solar Unmanned Aerial Vehicle’s Take Off Diagnosis under Little Data. Entropy, 24(7), 997. https://doi.org/10.3390/e24070997