Abstract
Densely connected convolutional networks (DenseNet) behave well in image processing. However, for regression tasks, convolutional DenseNet may lose essential information from independent input features. To tackle this issue, we propose a novel DenseNet regression model where convolution and pooling layers are replaced by fully connected layers and the original concatenation shortcuts are maintained to reuse the feature. To investigate the effects of depth and input dimensions of the proposed model, careful validations are performed by extensive numerical simulation. The results give an optimal depth (19) and recommend a limited input dimension (under 200). Furthermore, compared with the baseline models, including support vector regression, decision tree regression, and residual regression, our proposed model with the optimal depth performs best. Ultimately, DenseNet regression is applied to predict relative humidity, and the outcome shows a high correlation with observations, which indicates that our model could advance environmental data science.
1. Introduction
With the increasing trend in environmental dataset size and complexity, data science has become popular in environmental applications [1]. In environmental data analysis, regression is a useful technique in prediction. Many studies focus on forecasting environmental parameters to address environmental issues, incorporating air pollution, climate change, and global warming. For example, ref. [2] predicts nitrogen dioxide concentrations with a land-use regression method to obtain the spatial distribution of traffic-related air pollution in Rome. Ref. [3] forecasts the river water temperature by regression to further analyze the possibility of future projections considering climate change. Furthermore, ref. [4] proposes a regression approach for greenhouse gases estimation.
Regression analysis statistically models the relationship between the dependent variable and the independent variable. Linear model is the most common form of regression analysis. It is used to model linear relationships and includes General Linear Regression [5], Stepwise Linear Regression [6], and linear regression with penalties, such as Ridge Regression [7], LASSO Regression [8], and Elastic Net Regression [9]. However, nonlinear relationships are more common and complicated in the real world. Therefore, nonlinear regression analysis gains a lot of attention [10,11,12]. There exist many tools to model nonlinear relationships, such as Polynomial Regression [13], Support Vector Regression (SVR) [14], and Decision Tree Regression (DTR) [15], where SVR and DTR are popular nonlinear regression techniques. Nevertheless, SVR often takes a long time to be trained on large datasets, and DTR is extremely non-robust and NP-complete to learn an optimal decision tree [16]. From the late 1980s, people began to use artificial neural networks (ANNs) for nonlinear regression since a neural network with a single hidden layer can approximate any continuous function with compact support for arbitrary accuracy when the width goes to infinity [17,18,19]. According to the universal approximation theorem, the regression accuracy of ANNs heavily depends on the width of the single hidden layer. However, the impact of depth on the accuracy of neural networks are not considered in this classical theorem [20].
Different from ANNs with a single hidden layer, deep neural networks (DNNs) trend in increasing the number of depth (layers) of neural networks, aiming at significantly improving the accuracy of models. In the last decade, there emerge many works on regression tasks using the deep learning-based method. Specifically, ref. [21] proposed a nonlinear regression approach based on DNNs to mimic the function between noisy and clean speech signals to improve speech. Ref. [22] design a DNN model to accurately predict the crop yield, and the result shows that the regression behavior of the DNN-based model in this scenario is better than shallow neural networks (SNNs). Ref. [23] conducted a comprehensive analysis of vanilla deep regression considering a large number of deep models with no significant difference in the network architecture and data pre-processing. Ref. [16] developed a nonlinear regression model with the technique of ResNet. By comparing to other nonlinear regression techniques, this work indicates the nonlinear regression model based on DNNs is stable and applicable in practice. Although DNNs show the progresses in regression with the deep hidden layers, it is limited that the feature of each layers is only used once and the feature reuse is not considered to improve the nonlinear approximation capacity [24].
Densely connected convolutional networks (DenseNet) introduce the concatenation shortcut into their frameworks [25]. The concatenation shortcuts play a significant role in realizing the feature reuse and the key information of initial input could be reserved and transmitted to the output, which makes DenseNet achieve good performance in applications [26,27,28]. DenseNet performs well in image processing because convolution is suitable for feature extraction of images with multiple channels. Usually, the input of images is high-dimensional and includes redundant information [29]. For instance, the input of a 96 × 96 pixels image with three channels would have 27,648 dimensions. If the number of neurons of the first hidden layer in the fully connected layer is the same as the input dimensions, the number of weights would be close to , which is too enormous and significantly aggravates the computation efficiency. The convolution kernel is designed for reducing the repetitive parts among the variables and extract featured information. Hence, for image processing, convolution plays a significant role in reducing redundant information and improving the efficiency of the algorithm. However, ref. [16] found that convolutional neural networks may lose essential information from input features due to local convolution kernels and thus are not suitable for nonlinear regression. To tackle this issue, they introduce the so-called residual regression model by replacing convolution and pooling layers into fully connected (FC) layers in ResNet. By maintaining the shortcut within residual blocks, residual regression enhances data flow in the neural network and has been applied in many fields, such as computational fluid dynamics [30,31], computer-aided geometric design [32], and safety control in visual serving applications [33,34]. Besides the localness of convolution, the independence of input features also requires the replacement of convolution layers in a neural network regression model. To sum up, the motivations of replacing convolution layers into FC layers in this work are explained as follows:
- Convolution is a local operator. As introduced by [16] and presented in Figure 1, convolution is a local operator. The localness of convolution may result in the convolutional neural network losing essential information and even key input features from input variables. Therefore, the convolutional network is not good enough for nonlinear regression.
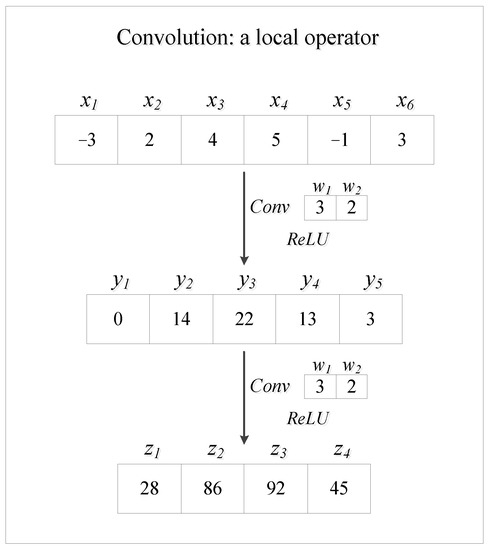 Figure 1. Convolution as a local operator. The input data are and are convoluted with a convolution kernel . The stride of convolution is 1. Then, . When the vector is convoluted again, we get . Here, when computing , the neural network is losing information from since . This illustrates that the localness of convolution may result in the neural network missing some input variables or essential information from input features. Thus, the convolutional neural network is not suitable for regression tasks.
Figure 1. Convolution as a local operator. The input data are and are convoluted with a convolution kernel . The stride of convolution is 1. Then, . When the vector is convoluted again, we get . Here, when computing , the neural network is losing information from since . This illustrates that the localness of convolution may result in the neural network missing some input variables or essential information from input features. Thus, the convolutional neural network is not suitable for regression tasks. - Predictors of regression tasks are independent. However, convolution kernels are used to extract features from redundant information or correlated variables. Therefore, the convolutional neural network would lose key information from regression predictors. Specifically, the convolutional neural network often uses 2D convolution layers. The input one-dimensional feature vector needs to be reshaped into a matrix when the network takes a regression task. The entries in the reshaped matrix are seen as the corresponding gray values of pixels of a figure and all the input entries are independent. However, the neighboring gray values in a figure are often highly correlated. This dilemma requires the substitution of convolution layers into FC layers.
Inspired by the residual regression model, we propose a novel DenseNet model for nonlinear regression. Specifically, the new neural network retains the major architecture of DenseNet excluding convolution and pooling layers. Fully connected layers are the substitution of convolution and pooling layers in the dense block. Therefore, the conceptual architecture of our DenseNet regression model consists of a number of building blocks, and each building block is linked to the others by concatenation shortcuts. Through concatenation, the DenseNet regression model could realize feature reuse, and critical information could be reserved.
This paper is organized as follows. In Section 2, the architecture of DenseNet regression is clarified and in Section 3, we introduce the simulated dataset. In Section 4, we derive the results and have a discussion. Firstly, the performance of DenseNet with different depths is evaluated, and then we compare the results of optimal DenseNet regression model with other regression techniques. At the end of this section, we estimate the effect of input dimension on the performance of DenseNet regression. In Section 5, we use DenseNet regression to predict relative humidity. Finally, we conclude and propose the future work in Section 6.
2. The Architecture of DenseNet Regression
DenseNet introduces the concatenation shortcuts to enhance the feature reuse in each dense block, which is beneficial to reduce the possibility of losing critical information and increase the accuracy of DNNs.
Generally, based on the characteristics of DenseNet, the architecture of our proposed model employs concatenation and removes the convolutional part, so that DenseNet could better serve the nonlinear regression tasks. Figure 2 and Figure 3 demonstrate the details of architecture of this DenseNet regression model. Unlike convolutional DenseNet, the DenseNet regression model replaces convolution and pooling layers with fully connected layers in the dense block. Meanwhile, we maintain Batch Normalization layers from the original DenseNet to our novel networks. Batch Normalization is a typical regularization method with the advantage of accelerating the training process, reducing the impact of parameters scale, and allowing the utilization of higher learning rates [35].
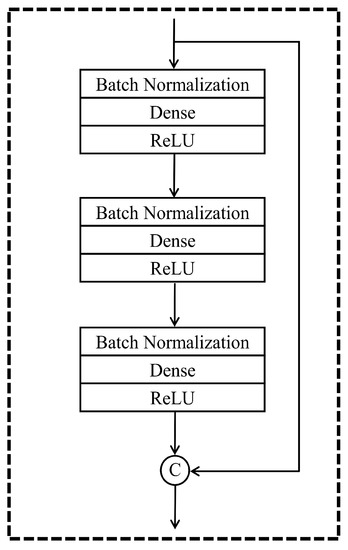
Figure 2.
The building block of DenseNet for nonlinear regression. There are three hidden layers in each building block. At the end of the building block, there is a concatenation shortcut transmitting the information from top to bottom to guarantee feature reuse. ‘C’ in the diagram stands for concatenation.
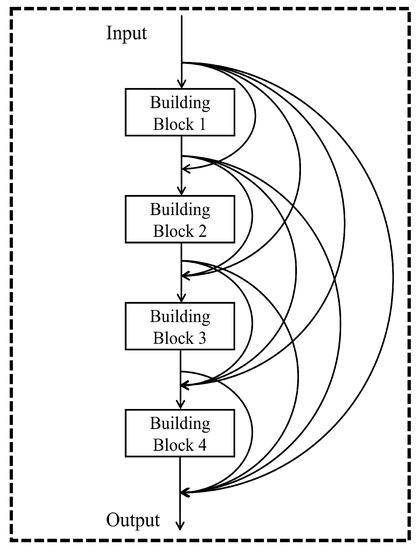
Figure 3.
The architecture of a DenseNet regression model with 13 layers. The model has four building blocks. Each building block is linked to the others by a concatenation shortcut. The output layer is positioned in the end. Through concatenation, the features of initial inputs and outputs of each building block would be transmitted to the following output layer.
The fundamental component of the DenseNet regression algorithm is the building block in Figure 2. There are three fully connected layers in this block, and each layer contains three operations, including batch normalization, dense, and ReLU activation function. Activation function is indispensable for the design of neural networks. Rectified linear unit (ReLU) activation function shown in Equation (1) is widely used in neural networks, as it does not activate all the neurons at the same time, immensely reducing the computation [36]. This is particularly beneficial to DenseNet regression where there are plenty of parameters to optimize. The ReLU function is shown as follows:
Another vital element in the building block is the concatenation shortcut, which is designed to append the input feature to the end of the output sequence in a building block. Furthermore, to satisfy the nonlinear regression tasks, a linear activation function is applied for the output (or top) layer. The number of layers in a building block is a hyperparameter and is determined by the accuracy and efficiency of neural networks. If there are few layers in the building block, the neural network would be too shallow and simple. Therefore, it is difficult to approximate nonlinear relationships. Nevertheless, if there are more layers in the building block, neural network parameters would be too large to optimize, which decreases the computation efficiency significantly. Meanwhile, under the same depth, neural networks with more layers in the building block have less concatenation shortcuts, decreasing the efficiency of feature reuse. Hence, the number of layers in the building block should be neither too small nor too large. Enlightened by the idea that there are three layers in each identity block and dense block in the optimal residual regression model [16], we make the input also go through three fully connected layers before concatenating in the building block.
Figure 3 shows an example of the architecture of a DenseNet regression model with four building blocks. The model begins with an input layer and is followed by four building blocks. Every building block is connected by concatenation shortcuts. The output layer is positioned in the end. Thus, the total layers of this model are 13. The feature reuse is reflected in the concatenation shortcuts or curve arrows in Figure 3. The features of initial inputs and outputs of each building block would be transmitted to the following output layer through concatenation shortcuts. For example, the input of building block 2 not only contains the output of building block 1, but also includes the initial input features. By analogy, the input of the top layer contains initial input features and the outputs of building block 1, 2, 3, and 4. Accordingly, the architecture of this model could keep feature reuse and enhance the performance of the neural network on nonlinear regression. It should be noted that the specific number of building blocks needs to be optimized under the given circumstances.
3. Simulated Data Generation
To better understand the performance of this novel regression algorithm before it is applied to specific fields, a simulated nonlinear dataset is introduced to test the algorithm. We set a maximum value of 1200 in the simulated dataset. Moreover, in order to enhance the degree of nonlinearity, we add two smaller values (400 and 800) in the dataset, and finally, we have a nonlinear piecewise function as shown in Equation (2). In this scenario, 10,000,000 samples are generated from Equation (2) where is uniformly distributed in the interval , i.e., .
Three hundred cases from the generated dataset are shown in Figure 4. In this work, 6,750,000 samples are employed for training the DenseNet nonlinear regression model, while 750,000 samples served as validation data. The remaining 2,500,000 samples are utilized for testing.
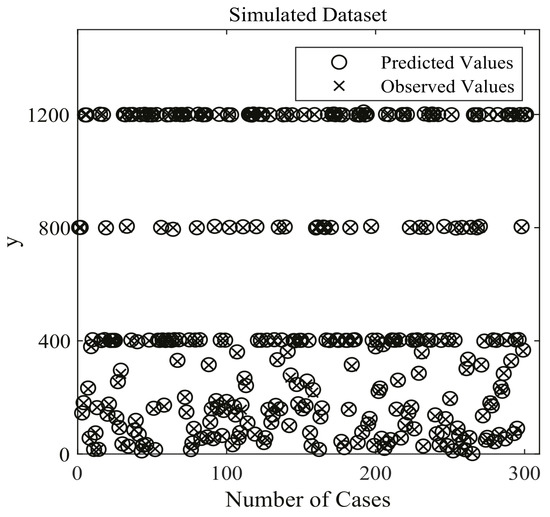
Figure 4.
Three hundred cases of simulated Dataset for DenseNet nonlinear regression model. ◯ stands for the predicted values of optimal DenseNet regression model, and × stands for the true (observed) values of the simulated dataset.
4. Results and Discussion
4.1. DenseNet Regression Model Specification
Before training, the original data generated by Equation (2) were standardized via the Min-Max scaler:
where is one of the sample data, stands for standardized data of , and i varies from one to the vector length.
Turning to the DenseNet regression model coding, Keras is employed as the application programming interface with TensorFlow as the backend. The program is run on Palmetto cluster of Clemson University. The computing environment is equipped with 10 CPUs and 10 GB RAM. The type of CPUs is Intel(R) Xeon(R) CPU E5-2640 V4 with 2.40 GH, and each core has two threads. Additionally, the Tesla P100-PCIE GPU is used for data training acceleration. It is produced by NVIDIA and has an 11.9 GB memory.
For the model optimization, mean squared error (MSE) is served as the loss function as shown in Equation (4). To minimize the loss function, the Adam method is applied in this work. The Adam method computes individual adaptive learning rates for different parameters and integrates the merits of AdaGrad and RMSProp method, which work well in sparse gradients and online and non-stationary settings, respectively [37,38,39]. The default learning rate of the Adam method is 0.001 in Keras, but in practice, we notice that the validation loss oscillates in training. Therefore, the learning rate is set to 0.0001 in this section, so that the neural network has a better convergence performance.
Overfitting is a common issue when training machine learning models. It is probable that the loss gradually decreases during the training period while it rises in validation and testing. To prevent this and obtain a better model, early stopping strategy is used so that the neural network is very close to the epoch where the minimum validation loss arises. This strategy is effective and straightforward so that it is a popular regularization method in deep learning [40]. After adding this strategy to the neural networks, the algorithm would stop when no progress has been made over the best-recorded validation loss for some pre-specified number (or patience) of epochs.
Primary parameter settings for the numerical validation scenario in this paper are as follows. The input dimension is 7. The epoch number in training is 800, and the patience of early stopping is 100 epochs. The batch size for gradient descent is 5000. As mentioned above, the learning rate of the Adam method is 0.0001. The magnitude of training loss, validation loss, and testing loss are .
4.2. DenseNet Regression with the Optimal Depth
To evaluate the effect of depth and find its optimal value, multiple DenseNet regression models with different depths ranging from 4 to 37 were trained on the simulated dataset in this part. The corresponding training parameters and performance of different regression models are shown in Table 1. It was observed that with the rise of depth, the number of parameters and expected running time increased synchronously. When the depth was four, the DenseNet regression model had a high testing loss of , which shows that the neural network regression model with four layers was too simple to address complex and nonlinear regression tasks. As the depth of the DenseNet regression model goes up, the testing loss goes down gradually. Remarkably, the testing loss reached the lowest point, , when the depth was 19. Moreover, as the depth exceeded 19 and continued to increase, the testing loss went up again. For the model with a depth of 37, the training result showed OOM (stands for Out of Memory) due to the tremendous number of parameters and computation. The outcome indicates that the depth of DenseNet regression model should be neither too small nor too large. In conclusion, the DenseNet regression model with depth 19 had the minimum testing loss and the best performance on simulated data. Therefore, the depth of the optimal DenseNet regression model on the simulated dataset was 19. It is worth noticing that the testing loss had a slight difference as the depth ranged from 13 to 19. It is also noted that the data structures in real world applications may be different from the simulated dataset. Therefore, we recommend setting the value of depth in the range if DenseNet regression is applied under real scenarios.

Table 1.
Performance of DenseNet regression models with different depths.
4.3. Comparisons with the Baseline
In this part, to evaluate the optimal DenseNet regression model, we also considered other regression techniques as the baseline on the dataset generated by Equation (2). The dataset was the same as Section 3. The 10,000,000 samples were generated by Equation (2) with 6,750,000 samples for training, 750,000 samples for validation and 2,500,000 samples for testing. Four linear models, including linear regression, ridge regression, lasso regression, and elastic regression, were applied to the simulated dataset. Nonlinear regression techniques incorporate conventional machine learning methods and artificial neural networks (ANNs), such as decision tree, support vector regression (SVR) machine, and deep residual regression. Neural networks contain the deep residual regression model and ANN Not Concatenated model. The residual regression model is a variant of ResNet. It replaces convolution and pooling layers with fully connected layers and has a good performance on nonlinear regression [16]. The ANN Not Concatenated model has the same structure as the optimal DenseNet regression model but has no concatenation shortcuts. This means that the depth of ANN not Concatenated model was 19. The epoch number and the patience of early stopping for neural networks were 800 and 100, respectively. The computing environment of residual regression model and ANN Not concatenated model is the same as DenseNet regression, modeling by Keras with TensorFlow as the backend. The four linear models, SVR model, and decision tree regression were built in Python with the scikit-learn package. The training results of different regression techniques are displayed in Table 2, including the comparison items, training time, validation loss, and testing loss. Table 3 lists the optimal hyperparameters of all regression models mentioned above. Grid search method is employed to optimize the value of hyperparameters of each regression model, excluding linear regression and the last three neural networks. Usually, it takes a long time to train a support vector regression model on a large dataset. Therefore, the SVR model was pre-trained before grid search. The pre-training gives smaller ranges of hyperparameters and thus improves the computing efficiency. Particularly, since the linear regression has no hyperparameters, the corresponding parameters were set as NA (NA stands for Not Applicable in Table 2 and Table 3).
Table 2.
Comparisons of DenseNet regression with the baseline models.
Table 3.
Optimal hyperparameters of regression techniques.
The comparison results could be intuitively observed from the list of testing loss in Table 2. Generally, the first four linear models had more significant testing loss than nonlinear models, reaching the magnitude of , which turns out that these four linear techniques are not applicable for nonlinear regression tasks. Among the remaining nonlinear regression techniques, the testing loss of the support vector regression (SVR) machine also had a magnitude of . Although support vector regression has been pre-trained before grid search, it still had a significant testing loss, which shows that support vector regression is not suitable for large datasets. The artificial neural networks (ANNs) without dense concatenation shortcuts in Table 2 have the same depth as the optimal DenseNet regression model but has a higher testing loss compared to the optimal DenseNet regression. It was also observed that DenseNet regression presents the best behavior among all the regression models in Table 2, with the lowest testing loss (). This shows that concatenation shortcuts could enable feature reuse and keep critical information, and thus have a critical effect on the performance of DenseNet regression. Furthermore, one could note that the residual regression model had the second-smallest testing loss () behind the DenseNet regression model. This is because the addition shortcuts in residual regression enable data flow and thus makes the model have a better performance. However, although residual regression can bypass addition shortcuts, the identity blocks and dense blocks are not densely connected. This illustrates that the outperformance of DenseNet regression to residual regression is due to the concatenation shortcuts and dense connection. Therefore, one could conclude that the topology of neural network and the method of connection (addition or concatenation) are essential to regression success. In conclusion, DenseNet regression is suitable for tackling nonlinear regression problems with high accuracy.
4.4. The Effect of Input Dimension
It is known that the number of parameters in a deep neural network is related to input dimensions. The number of parameters becomes more remarkable as the neural network gets more input variables, and thus it takes more time for the algorithm to optimize and obtain a good validation. It is also noted that the computation progress even has OOM (Out of Memory) errors when the magnitude of parameters reaches under the given computation environment and simulated dataset, as shown in the depth optimization part of Section 4.2. Therefore, to enhance the computational efficiency, the input dimension should be limited. Table 4 lists the input dimensions of the optimal DenseNet regression model and the corresponding number of parameters. The optimal depth of the used neural network here was 19. In Table 4, the magnitude of parameter number reached when the input dimension was 5. However, there was a sharp increase reaching 1,663,801 in the number of parameters as the input dimension extends to 20. Dramatically, when the input dimension is 50, the magnitude of parameter numbers becomes . Nevertheless, when the input dimension varies from 50 to 100, the magnitude of parameter numbers does not change and is still kept at .
Table 4.
The effect of input shape.
In conclusion, as the input dimension increases, the number of parameters goes up. Especially when the input dimension exceeds 80, the number of parameters increases sharply. If the input dimension reaches 200, the magnitude of parameter number would be . In contrast, according to Table 1, the outcome shows the out of memory (OOM) error if the magnitude of parameters reaches . For the sake of computational efficiency, we conservatively suggest that if the computing capacity is as limited as our work, the input dimension for the optimal DenseNet regression model with depth 19 should be under 200 to avoid out of memory errors.
5. Application of DenseNet Regression on Climate Modeling
In recent years, machine learning has been successfully applied in atmospheric and environmental science, see [41,42,43,44,45,46,47,48,49] for more details. In this section, DenseNet regression is also employed on climate modeling. Similar to the application part of [16], DenseNet regression is used to approximate the nonlinear relationship between relative humidity (RH) and other meteorological variables. Relative humidity is defined as the ratio of the water vapor pressure to the saturated water vapor pressure at a given temperature. It has a critical effect on cloud microphysics and dynamics, and hence plays a vital role in environment and climate [50]. However, the relative humidity is not accurate under vapor supersaturation circumstances since the formation of cloud condensation nuclei needs water vapor to be supersaturated in the air, and there is no widely accepted and reliable method to measure the supersaturated vapor pressure accurately at present [51]. To address this issue, this section uses the DenseNet regression model with optimal depth to quantify the nonlinear relationship between relative humidity and other environmental factors.
Our data is from ERA5 hourly reanalysis datasets on the 1000 hPa pressure level of ECMWF (European Centre for Medium-Range Weather Forecasts) [52]. The input features of DenseNet regression are temperature (T) and specific humidity (q). The response variable is relative humidity. The dataset is selected from 00:00:00 a.m. to 23:00:00 p.m. on 1 September 2007 with a spatial resolution of , and the spatial range of the dataset is global. There are 24,917,709 samples in total. The optimal DenseNet regression model with depth 19 is trained on 16,819,454 samples and validated on 1,868,828 samples. The remaining 6,229,427 samples are testing data. The batch size is 20,000, and the setting of other parameters are the same as the optimal DenseNet regression setting in Section 4. Furthermore, the consequence shows that the correlation coefficient () for the fitted values and observed values of testing data is , which is shown in Figure 5. This indicates that the fitted values and observed ones are highly correlated. The average relative error in testing for relative humidity is , verifying that the DenseNet regression model behaves excellently in practice.
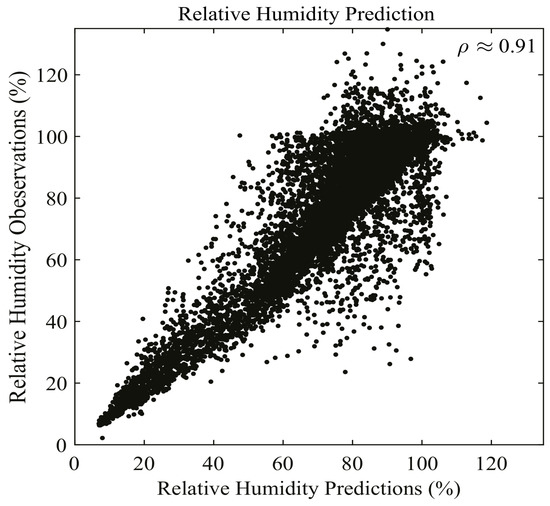
Figure 5.
Performance of RH prediction on 1 September 2007 using DenseNet regression. The figure shows the first 20,000 cases of relative humidity prediction. The correlation coefficient is approximately 0.91. This shows that DenseNet regression has high performance under real-world scenarios.
To further evaluate the performance of DenseNet regression, a similar dataset on another day was tested on the above DenseNet RH regression model. The dataset was selected at 00:00:00 a.m. of the next day (2 September 2007) and was still on the 1000 hPa pressure level. The spatial range of the data was global and the resolution was . There are 1,038,240 samples in total. The result is shown in Figure 6. Global distributions of temperature, specific humidity, and observed values of relative humidity are presented in Figure 6a,b,c, respectively. The predicted values of relative humidity are displayed in Figure 6d. Compared to the result on 1 September, the correlation coefficient () between observed values and predicted ones of RH on 2 Septmeber 2007 was , and the average relative error was , which indicates that the performance of DenseNet regression model is stable in practice.

Figure 6.
Performance of RH prediction on Sep. 2 using DenseNet regression. The figure shows the relative humidity prediction at 00:00:00 a.m. of the next day (2 September 2007) with the same DenseNet regression model in Figure 5. The dataset was still on the 1000 hPa pressure level. The spatial range of the data was global and the resolution was still . The correlation coefficient was 0.90, indicating that the performance of DenseNet regression is stable under real-world scenarios.
6. Conclusions and Future Work
The convolutional DenseNet behaves well in image processing. However, when it is applied to regression tasks, the independence of input features makes the convolutional neural network lose critical information from input variables. To address this issue, we develop a novel densely connected neural network for nonlinear regression. Specifically, we replace convolutional layers and pooling layers with fully connected layers, and reserve the DenseNet dense concatenation connections to enhance feature reuse in the regression model. The new regression model is numerically evaluated on simulated data, and the results recommend an optimal depth (19) and input dimensions (under 200) for the regression model. In addition, we compare DenseNet regression with other baseline techniques, such as support vector regression, decision tree regression, and deep residual regression. It turns out that the DenseNet regression model with optimal depth has the lowest testing loss. Finally, the optimal DenseNet regression is applied to predict relative humidity, and we obtain a high correlation coefficient and a low average relative error, which indicates that the DenseNet regression model is applicable in practice and could advance environmental data science.
In the future, we intend to apply the DenseNet regression model to the parameterization of the subgrid-scale process of large eddy simulation of turbulence at the atmospheric boundary layer. In addition, we will also employ the DenseNet regression to estimate global terrestrial carbon fluxes using net ecosystem exchange (NEE), gross primary production (GPP), and ecosystem respiration (RECO) from the FLUXNET2015 dataset.
Author Contributions
C.J. (Chao Jiang): methodology, manuscript preparation, manuscript submission, formal analysis, application design, visualization. C.J. (Canchen Jiang): methodology, manuscript preparation, manuscript submission, formal analysis, application design, visualization. D.C.: conceptualization, methodology, Algorithm implementation, Manuscript preparation, Manuscript submission, formal analysis, application design, data acquisition, visualization. F.H.: methodology, manuscript preparation, manuscript submission, application design, data acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by National Natural Science Foundation of China (Grant 41975018).
Data Availability Statement
Available online via https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-pressure-levels?tab=form (accessed on 21 May 2022).
Acknowledgments
Clemson University is acknowledged for their generous allotment of computing time on the Palmetto cluster. The authors thank all the anonymous reviewers for their constructive comments. Senfeng Liu is appreciated for helping plot Figure 6. The authors also thank all the editors for their careful proofreading. The code of optimal DenseNet regression model could be found at https://github.com/DowellChan/DenseNetRegression, accessed on 21 May 2022.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Gibert, K.; Horsburgh, J.S.; Athanasiadis, I.N.; Holmes, G. Environmental data science. Environ. Model. Softw. 2018, 106, 4–12. [Google Scholar] [CrossRef]
- Rosenlund, M.; Forastiere, F.; Stafoggia, M.; Porta, D.; Perucci, M.; Ranzi, A.; Nussio, F.; Perucci, C.A. Comparison of regression models with land-use and emissions data to predict the spatial distribution of traffic-related air pollution in Rome. J. Expo. Sci. Environ. Epidemiol. 2008, 18, 192–199. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rehana, S. River water temperature modelling under climate change using support vector regression. In Hydrology in a Changing World; Springer: Cham, Switzerland, 2019; pp. 171–183. [Google Scholar]
- Krishna, K.V.; Shanmugam, P.; Nagamani, P.V. A Multiparametric Nonlinear Regression Approach for the Estimation of Global Surface Ocean pCO 2 Using Satellite Oceanographic Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 6220–6235. [Google Scholar] [CrossRef]
- Pandey, M.; Zakwan, M.; Sharma, P.; Ahmad, Z. Multiple linear regression and genetic algorithm approaches to predict temporal scour depth near circular pier in non-cohesive sediment. ISH J. Hydraul. Eng. 2020, 26, 96–103. [Google Scholar] [CrossRef]
- Zhou, N.; Pierre, J.W.; Trudnowski, D. A stepwise regression method for estimating dominant electromechanical modes. IEEE Trans. Power Syst. 2011, 27, 1051–1059. [Google Scholar] [CrossRef]
- Ahn, J.J.; Byun, H.W.; Oh, K.J.; Kim, T.Y. Using ridge regression with genetic algorithm to enhance real estate appraisal forecasting. Expert Syst. Appl. 2012, 39, 8369–8379. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Yagiz, S.; Gokceoglu, C. Application of fuzzy inference system and nonlinear regression models for predicting rock brittleness. Expert Syst. Appl. 2010, 37, 2265–2272. [Google Scholar] [CrossRef]
- Majda, A.J.; Harlim, J. Physics constrained nonlinear regression models for time series. Nonlinearity 2012, 26, 201. [Google Scholar] [CrossRef]
- Rhinehart, R.R. Nonlinear Regression Modeling for Engineering Applications: Modeling, Model Validation, and Enabling Design of Experiments; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar] [CrossRef]
- Ostertagová, E. Modelling using polynomial regression. Procedia Eng. 2012, 48, 500–506. [Google Scholar] [CrossRef] [Green Version]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Chen, D.; Hu, F.; Nian, G.; Yang, T. Deep residual learning for nonlinear regression. Entropy 2020, 22, 193. [Google Scholar] [CrossRef] [Green Version]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Funahashi, K.I. On the approximate realization of continuous mappings by neural networks. Neural Netw. 1989, 2, 183–192. [Google Scholar] [CrossRef]
- Kůrková, V. Kolmogorov’s theorem and multilayer neural networks. Neural Netw. 1992, 5, 501–506. [Google Scholar] [CrossRef]
- Chui, C.K.; Li, X.; Mhaskar, H.N. Limitations of the approximation capabilities of neural networks with one hidden layer. Adv. Comput. Math. 1996, 5, 233–243. [Google Scholar] [CrossRef]
- Xu, Y.; Du, J.; Dai, L.R.; Lee, C.H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 7–19. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop yield prediction using deep neural networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef] [Green Version]
- Lathuilière, S.; Mesejo, P.; Alameda-Pineda, X.; Horaud, R. A comprehensive analysis of deep regression. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2065–2081. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, X.; Gui, G.; Li, Y.; Liu, R.P.; An, Y. ResInNet: A novel deep neural network with feature reuse for Internet of Things. IEEE Internet Things J. 2018, 6, 679–691. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Liang, X.; Dong, X.; Xie, Y.; Cao, G. A sparse-view CT reconstruction method based on combination of DenseNet and deconvolution. IEEE Trans. Med Imaging 2018, 37, 1407–1417. [Google Scholar] [CrossRef]
- Saleh, K.; Hossny, M.; Nahavandi, S. Real-time intent prediction of pedestrians for autonomous ground vehicles via spatio-temporal densenet. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9704–9710. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhao, J.; Lin, H.; Tan, Y.; Cheng, J.X. High-speed chemical imaging by dense-net learning of femtosecond stimulated Raman scattering. J. Phys. Chem. Lett. 2020, 11, 8573–8578. [Google Scholar] [CrossRef] [PubMed]
- Danasingh, A.A.G.S.; Epiphany, J.L. Identifying redundant features using unsupervised learning for high-dimensional data. SN Appl. Sci. 2020, 2, 1367. [Google Scholar] [CrossRef]
- Rojek, K.; Wyrzykowski, R.; Gepner, P. AI-Accelerated CFD Simulation Based on OpenFOAM and CPU/GPU Computing. In Proceedings of the International Conference on Computational Science, Krakow, Poland, 16–18 June 2021; pp. 373–385. [Google Scholar]
- Shin, J.; Ge, Y.; Lampmann, A.; Pfitzner, M. A data-driven subgrid scale model in Large Eddy Simulation of turbulent premixed combustion. Combust. Flame 2021, 231, 111486. [Google Scholar] [CrossRef]
- Scholz, F.; Jüttler, B. Parameterization for polynomial curve approximation via residual deep neural networks. Comput. Aided Geom. Des. 2021, 85, 101977. [Google Scholar] [CrossRef]
- Shi, L.; Copot, C.; Vanlanduit, S. A Deep Regression Model for Safety Control in Visual Servoing Applications. In Proceedings of the 2020 Fourth IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 9–11 November 2020; pp. 360–366. [Google Scholar] [CrossRef]
- Shi, L.; Copot, C.; Vanlanduit, S. A Bayesian Deep Neural Network for Safe Visual Servoing in Human–Robot Interaction. Front. Robot. AI 2021, 8, 165. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar] [CrossRef]
- Hanin, B.; Sellke, M. Approximating continuous functions by relu nets of minimal width. arXiv 2017, arXiv:1710.11278. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of Adam and Beyond. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Chantry, M.; Christensen, H.; Dueben, P.; Palmer, T. Opportunities and challenges for machine learning in weather and climate modelling: Hard, medium and soft AI. Philos. Trans. R. Soc. A 2021, 379, 20200083. [Google Scholar] [CrossRef] [PubMed]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.Y.; Li, L.; Liu, Y.S.; Chan, P.W.; Zhang, W.H.; Zhang, L. Estimation of precipitation induced by tropical cyclones based on machine-learning-enhanced analogue identification of numerical prediction. Meteorol. Appl. 2021, 28, e1978. [Google Scholar] [CrossRef]
- Liu, Y.Y.; Li, L.; Liu, Y.S.; Chan, P.W.; Zhang, W.H. Dynamic spatial-temporal precipitation distribution models for short-duration rainstorms in Shenzhen, China based on machine learning. Atmos. Res. 2020, 237, 104861. [Google Scholar] [CrossRef]
- Liu, Y.y.; Li, L.; Zhang, W.h.; Chan, P.w.; Liu, Y.s. Rapid identification of rainstorm disaster risks based on an artificial intelligence technology using the 2DPCA method. Atmos. Res. 2019, 227, 157–164. [Google Scholar] [CrossRef]
- Mostajabi, A.; Finney, D.L.; Rubinstein, M.; Rachidi, F. Nowcasting lightning occurrence from commonly available meteorological parameters using machine learning techniques. Npj Clim. Atmos. Sci. 2019, 2, 1–15. [Google Scholar] [CrossRef]
- Arcomano, T.; Szunyogh, I.; Pathak, J.; Wikner, A.; Hunt, B.R.; Ott, E. A machine learning-based global atmospheric forecast model. Geophys. Res. Lett. 2020, 47, e2020GL087776. [Google Scholar] [CrossRef]
- Krishnamurthy, R.; Newsom, R.K.; Berg, L.K.; Xiao, H.; Ma, P.L.; Turner, D.D. On the estimation of boundary layer heights: A machine learning approach. Atmos. Meas. Tech. 2021, 14, 4403–4424. [Google Scholar] [CrossRef]
- Rodriguez, A.; Cuellar, C.R.; Rodriguez, L.F.; Garcia, A.; Gudimetla, V.R.; Kotteda, V.K.; Munoz, J.A.; Kumar, V. Stochastic Analysis of LES Atmospheric Turbulence Solutions with Generative Machine Learning Models. In Proceedings of the Fluids Engineering Division Summer Meeting, Online, 13–15 July 2020; Volume 83716, p. V001T01A001. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, R.; Li, G.; Tao, W.K. Effects of aerosols and relative humidity on cumulus clouds. J. Geophys. Res. Atmos. 2007, 112, 1–15. [Google Scholar] [CrossRef]
- Shen, C.; Zhao, C.; Ma, N.; Tao, J.; Zhao, G.; Yu, Y.; Kuang, Y. Method to estimate water vapor supersaturation in the ambient activation process using aerosol and droplet measurement data. J. Geophys. Res. Atmos. 2018, 123, 10–606. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 Hourly Data on Pressure Levels from 1979 to Present—Copernicus Climate Change Service (C3S) and Climate Data Store (CDS). 2018. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-pressure-levels?tab=overview (accessed on 21 May 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).