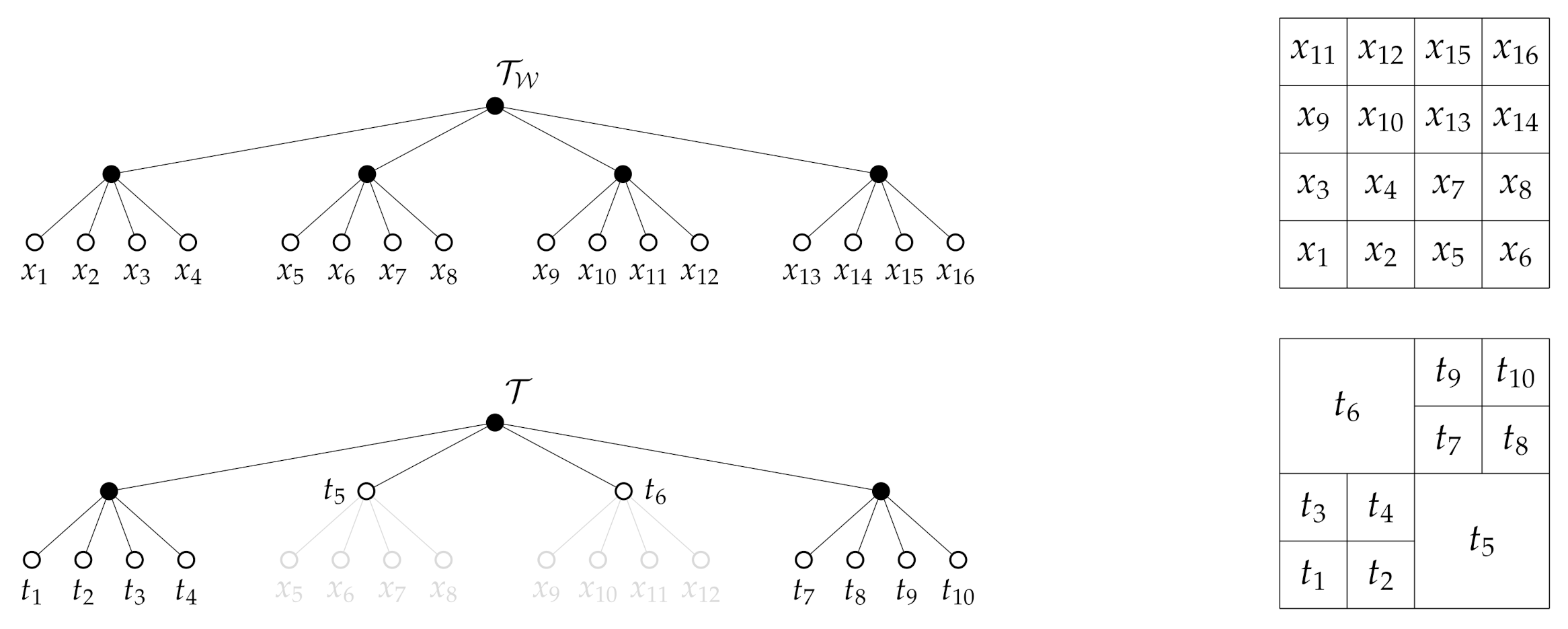
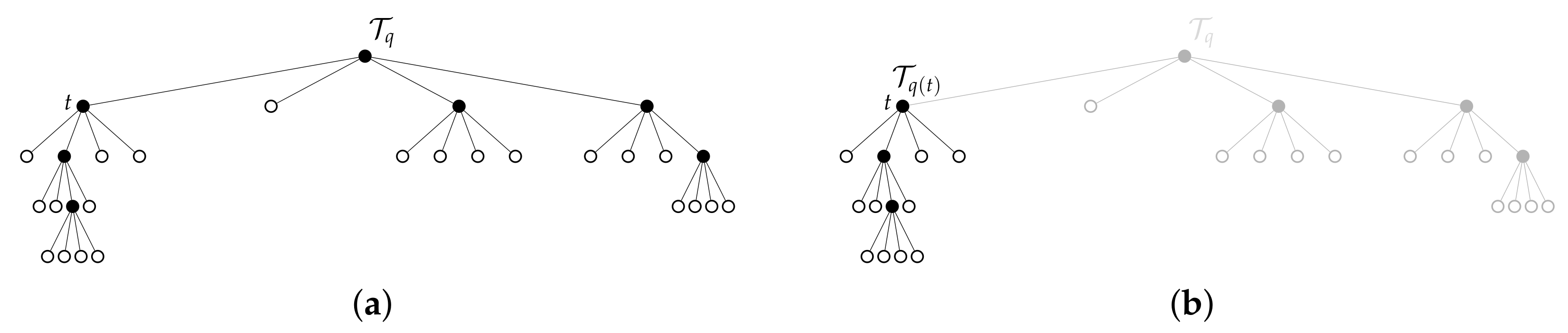
1. Introduction
Driven by the human ability to discern pertinent details from immense amounts of perceptual information, the process of identifying task-relevant structures from data has long been considered a cornerstone to the development of intelligent systems [
1,
2,
3,
4]. To this end, researchers in the autonomous systems community have spend a great deal of effort studying abstractions, which is a problem generally viewed as an information-removal procedure to discard details that are not relevant for a given task [
1,
2,
3,
4,
5]. The central motivation for the employment of abstractions is to simplify the problem domain by removing details that can be safely ignored, thereby creating a new representation of the problem for which reasoning and decision making requires fewer computational resources [
1,
2,
3]. Despite their importance, autonomous systems thus far seldom design abstractions on their own, instead relying on system designers and prior domain knowledge to provide hand-crafted rules for the emergence of abstractions as a function of task in various domains [
3,
5]. In spite of these shortcomings, abstractions have seen wide-spread use in a number of autonomous systems applications.
Perhaps the most notable field of research where abstractions have seen particular success is within the planning community [
1]. Examples of work that employ the power of abstract representations in planning for autonomous systems include [
6,
7,
8,
9,
10,
11,
12,
13,
14]. The idea of utilizing abstractions in planning is to form reduced graphs on which classical search algorithms, such as A
and Dijkstra, are implemented. By reducing the number of vertices in the graph, the computational burden of executing these search algorithms is reduced. However, while the cited works all leverage graph abstractions to ease the computational cost of planning, the methods by which they generate these abstractions differ. For example, in [
7,
8,
9,
10,
11] the environment abstractions are created via the wavelet transform. In contrast, the works of [
12,
13,
14] generate abstractions of the environment in the form of multi-resolution quadtree and octree data structures. Notably, the work of [
12,
13] develops a framework that incorporates sensor uncertainty in robotic systems by merging ideas from multi-resolution planning and probabilistic tree structures introduced in [
15]. Today, the use of probabilistic trees in robotics is ubiquitous, and has led to the development of open-source software packages for their implementation [
16].
Motivated by the possibly dynamic nature of the environment as well as sensing limitations inherent to autonomous systems, the abstractions employed in all the aforementioned works maintain high resolution nearest the autonomous agent (e.g., robotic ground vehicle), while aggregating other portions of the environment at various resolution levels. In this way, the region nearest to the vehicle is considered the most relevant, and thus preserved through the process of abstraction. To strike a balance between path-optimality (system performance) and the computational cost of planning, agents recursively re-plan as they traverse the world.
The design of abstractions has also been considered by information theorists in the context of optimal signal encoding for communication over capacity-limited channels [
17]. In order to formulate mathematical optimization problems that yield optimal encoders it is required to identify the relevant structure of the original signal necessary to guarantee that a satisfactory system performance can be achieved. To this end, the framework of rate-distortion theory approaches the optimal encoder problem by measuring the degree of compression via the mutual information between the compressed representation and the original signal, whereas the performance of the system is quantified by a user-provided distortion function [
17]. In this way, the distortion function implicitly specifies which aspects of the original signal are relevant, and should be retained, in order to guarantee low distortion. A notable drawback to the rate-distortion framework is, however, the need to specify the distortion function, which may be difficult and non-intuitive for a given task [
18].
In contrast, the information bottleneck (IB) method developed in [
18] approaches the optimal encoder problem to preserve relevant information more directly. That is, the IB method considers an optimal encoder problem where the degree of achieved compression is captured by the mutual information between the compressed and original signals, and the model quality is measured by the mutual information between the compressed representation and an auxiliary variable which is assumed to contain task-relevant information. The IB approach is entirely data-driven, requiring only the joint distribution of the original signal and relevant information (i.e., the data) in order to be applied.
Owing to its general statistical formulation, the IB method, or some variation of it, has been considered in a number of studies [
19,
20,
21,
22,
23,
24,
25,
26]. Among these works, reference [
19] develops an approach to obtain deterministic encoders to an IB-like problem motivated by reducing the number of clusters in the compressed space as opposed to designing encoders for communication. Consequently, the deterministic IB [
19] measures the degree of achieved compression not by the mutual information between the original and compressed representations, as in communication systems, but by the entropy of the reduced space. The work of [
20] considers the IB problem with side-information, allowing for both relevant and irrelevant structures to be provided to aid the identification of task-relevant information during the creation of signal encoders. The authors of [
21,
23] consider a multivariate extension of the IB principle, employing the use of Bayesian networks to specify the compression-relevance relations between the random variables to be maintained through the abstraction process. It should be noted that, while it does not directly employ the IB principle in its formulation, the empirical coordination problem [
27,
28] considers an information-theoretic compression problem over a graph, where interconnections between vertices represent communication links that agents may use to correlate their sequence of outcomes. Much like the multi-IB method [
21,
23], the network (communication) topology specifies the statistical dependencies that are possible in the empirical coordination problem. Observe, however, that the objective of the empirical coordination problem is to characterize the set of achievable joint distributions that are possible with various network topologies and communication (code) rates between vertices, whereas the multi-IB problem is a generalization of the encoder-design problem considered by the IB method to multivariate settings where the Bayesian networks are used to specify the relationships between source, reproduction and prediction (relevance) variables.
Other variants of the IB principle include the work in [
22], where the authors consider the development of a bottom-up, agglomerative, hard clustering approach that employs the IB objective in determining which clusters to myopically merge at each step of the proposed algorithm. In related work inspired by the AIB problem, the authors of [
29] exploit the structure of the AIB merging rule to design algorithms that form compressed representations of images by performing a sequence of greedy merges based on minimizing the stage-wise loss of relevant information at each iteration. Crucially, however, the algorithms developed in [
29] do not consider the IB problem as they aim to design a sequence of myopic merges so as to minimize the loss of only relevant information, as compared with the much more challenging IB problem of simultaneously balancing information retention
and information-theoretic compression. Moreover, in contrast to the work presented in this paper, the algorithms developed in [
29] are not accompanied by theoretical performance guarantees that certify the optimality of the abstractions, nor are the methods readily extendable to cases where information from multiple sources must be considered in the design of compressed representations. Finally, the research conducted by the authors of [
24] considers the IB problem in the setting of jointly-Gaussian data. More specifically, the authors of [
24] established that when the original signal and the auxiliary (relevant) variable are jointly Gaussian, the solution to the IB problem is a noisy linear projection. For completeness, we note that when the data are not jointly Gaussian, or are described by a general probability density function, a solution to the IB problem is difficult to obtain. However, a number of studies have proposed methods leveraging variational inference in order to obtain approximate solutions to the IB problem in these cases [
30,
31,
32,
33].
Employing a unified viewpoint between abstractions in autonomy and those driven by information-theoretic principles, the authors of [
34,
35,
36,
37] developed frameworks for the emergence of abstractions in autonomous systems via methods inspired by information-theoretic signal compression. For example, the work of [
34] employs the use of the IB principle to generate multi-resolution quadtree abstractions for planning, developing a framework that couples environment resolution, information and path value. Moreover, the research conducted in [
35] utilizes environment abstractions to reduce the computational cost of evaluating mutual-information objective functions in active sensing applications. Of the reviewed works, those most closely related to the developments in this paper is that of [
36,
37], where the authors develop algorithms to select multi-resolution trees that are optimal with respect to the IB objective in both the soft-constrained (Lagrangian) [
36] and hard-constrained [
37] settings of the IB problem.
Inspired by the recent developments in information-theoretic driven approaches for generating abstractions for autonomous agents for the purposes of planning, the contribution of this paper is the development of a generalized information-theoretic framework that allows for multi-resolution tree abstractions to be obtained when multiple sources of relevance and irrelevance are specified. The incorporation of irrelevant information allows for connections between our framework and notions of information-theoretic privacy. Moreover, our generalized approach allows for abstractions to be refined by removing aspects of the relevant variables that are correlated with the irrelevant information structure, thus allowing for more compressed representations to emerge. This is especially critical in resource-constrained systems, which must make the best use of scarce on-board memory and bandwidth-limited communication channels.
The remainder of the paper is organized as follows. We begin in
Section 3 with a brief overview of information-theoretic signal compression and detail the connection between hierarchical trees and signal encoders.
Section 4 contains our formal problem statement. We propose and discuss solution approaches in
Section 5. In
Section 6, we present a discussion and comparison between the information-bottleneck method and the information-bottleneck problem with side-information (IBSI) in the setting of hierarchical tree abstractions. Examples and results are discussed in
Section 7 before concluding remarks in
Section 8. Proofs for the theoretical results presented in this paper are provided in the appendices.
4. Problem Formulation
In
Section 3, we discussed the relation between trees and signal encoders and showed how the observation that a tree
can be represented as a deterministic encoder
allows us to quantify the information contained in the tree. With these observations, we can now formally state the problem we consider in this paper.
Problem 1. Given the environment , vectors and , a scalar and the joint distribution , consider the problem of maximizing It should be noted that Problem 1 cannot be solved by applying existing algorithms (e.g., the Blahut-Arimoto algorithm [
17,
18] or the iterative IB method [
18,
39]) from signal encoding theory as the set of feasible solutions is discrete, in addition to the presence of the constraint that
must correspond to a tree
. The added constraint poses significant technical challenges, as it is not obvious how this constraint can be represented mathematically so as to render Problem 1 solvable via numerical methods. Moreover, as a result of the discrete nature of
, it follows that Problem 1 cannot be solved via standard (sub-)gradient approaches from optimization theory, as it belongs to a class of combinatorial optimization problems. Despite these challenges, in the next section we propose a novel and tractable numerical algorithm to find a solution to Problem 1 with theoretical guarantees.
Before proceeding, we provide a few comments regarding the relation of Problem 1 to other areas of research. Namely, Problem 1 is similar to problems considered in the information-theoretic security community [
42,
43,
44] where
are viewed as private variables whose information content we wish not to disclose to an un-trusted party. In this setting, the value of
represents the amount of private information disclosed by the tree
and the vector of weights
encodes the relative cost of private information disclosure, allowing for the privacy variables to be distinguished in their importance of revelation. Alternatively, one may interpret the privacy aspects of Problem 1 via conditional entropy. Using (
3) and (
7), we can write
and note that
is constant, given the data
. Consequently, performing the maximization in Problem 1 encourages solutions
for which
is as large as possible, amounting to trees that attempt to make
and
independent since
. Then, Fano’s inequality ([
17], pp. 37–41) implies that the lower bound of the error probability of any estimator designed to infer
from
increases as a function of
. It follows that when
large, the probability of error when estimating the value of
from
increases [
17,
42]. Consequently, information regarding
remains protected.
It should be noted that the incorporation of additional irrelevant variables when designing abstractions has been considered in other works. Previous approaches that introduce irrelevance variables when forming abstractions, such as the IBSI method [
20], employ the viewpoint that the information provided via
is general task-irrelevant information, with no motivation from an information-theoretic security standpoint. In the IBSI approach, the incorporation of irrelevant information helps improve the quality of abstractions with respect to the task-relevant variable, as aspects of the task-relevant variable that are correlated with the irrelevant information can be discarded when forming the compressed representations. In summary, we note that, while our formulation given by Problem 1 can be interpreted from an information-theoretic security standpoint, the main motivation for our approach is not one of security. Rather, it is the development of a general information-theoretic framework that allows for both relevant and irrelevant information to be specified and balanced versus compression in the design of multi-resolution tree abstractions for autonomous systems. However, as the discussion above shows, the proposed framework could also be useful in obscuring private information contained in quadtree abstractions.
5. Solution Approach
In this section, we discuss an approach to find a solution to Problem 1 and introduce a tractable numerical algorithm that searches for an optimal tree as a function of the weight parameters
,
, and
. In what follows, it will be convenient to write the objective of Problem 1 in terms of the function
, defined by
Then our problem is one of selecting a tree
such that
The evaluation of the objective (
10) for a given tree
may be computationally expensive, as it requires the computation of each joint distribution
,
, and
,
, as well as the evaluation of the mutual information terms (
8) and (
9), each of which requires summation over the sample spaces of
,
and
for each
and
. Such a computation is especially burdensome if the sample spaces have a large number of elements. Instead, we seek an easier, less computationally costly incremental approach toward evaluating the objective (
10) for any
.
To this end, we write the objective (
10) for any
as
where
is a collection of trees in the space
. While the relation (
12) is valid for any tree
and any collection
, it was noted in [
36,
37] that when the tree
and the sequence
is selected in a specific way, the objective (
12) reduces to a special form. Specifically, if we select
as the tree consisting of a single node where all finest resolution cells are aggregated, and the sequence
is constructed by expanding a leaf node of
to create
for
, then (
12) can be expressed in terms of the local changes made in moving from the tree
to
. Formally, when the tree
is selected to be the root tree (the root tree
is the tree
such that
), and the sequence
is constructed so that
for some
for all
, the objective (
12) takes the form
where
and
,
,
are given by
The relations (
15)–(
21) are computed via direct calculation in terms of the difference in mutual information between two encoders corresponding to the trees
that satisfy
for some
. Observe that the condition
for some
implies that the trees
and
differ only by a single nodal expansion. An example is shown in
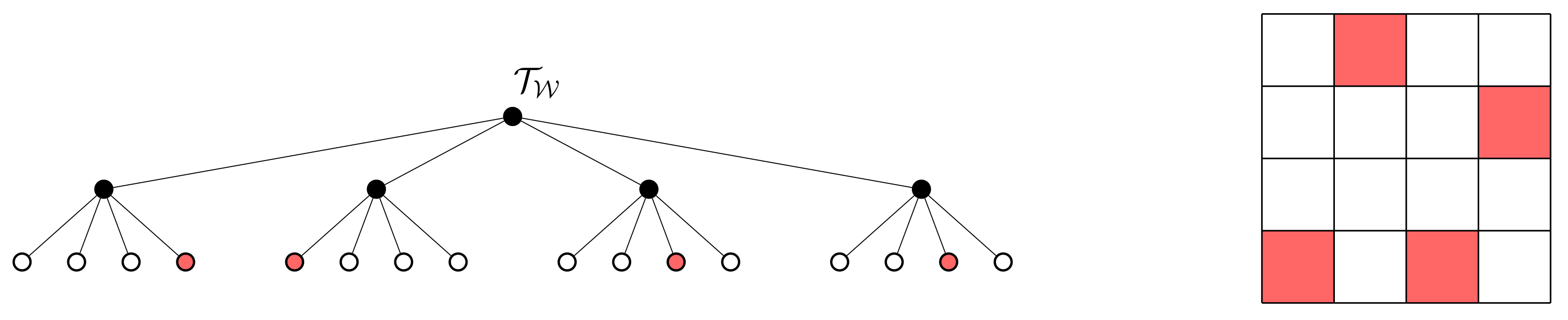
Figure 2. To show that the term
in (
12) when the tree
is taken to be the root tree, we note from (
3) that
,
and
. Then, since the root tree has only a single leaf node, it follows that the distribution
is deterministic. As a result,
and thus
.
It is important to note that the incremental relations (
15)–(
21) depend only on the node
expanded in moving from the tree
to
, and not on any other nodes in the tree. As a result, the evaluation of the incremental changes in information are dependent only on the changes induced by expanding the node
, thereby alleviating the need to sum over all the outcomes of the random variable
as otherwise required in order to evaluate the mutual information. Furthermore, the observation that the objective and information terms can be decomposed into an incremental form according to (
13)–(
21) allows for tractable algorithms to be designed in order to obtain a solution to Problem 1. Lastly, it is important to note that there is no loss of generality in using the expression (
13). To see why this is the case, we present the following definition.
Definition 2 ([
41]).
A tree is asubtree
of the tree , denoted by , if and . Note that the root tree is a subtree of every tree in the space
. As a result, one can always express the cost (
10) as (
13), since each tree
can be obtained by starting at the root tree
and creating a sequence
such that
for some
and all
. Next, we leverage the structure of our problem to design a tractable algorithm in order to find the solution to Problem 1.
5.1. The Generalized Tree Search Algorithm (G-Tree Search)
In this section, we show how the structural properties of Problem 1 discussed in the previous section can be exploited in order to yield a tractable algorithm to find a multi-resolution tree that is a solution to (
11). Specifically, among all trees
, we seek those trees that ensure no improvement of (
10) is possible, as these trees provide the best trade-off between relevant information retention, irrelevant information removal, and compression. The following definition establishes the notion of optimality we employ throughout this paper.
Definition 3. A tree isoptimal with respect to Jif for all trees .
To differentiate between candidate solutions, we specify additional properties considered favorable for an optimal multi-resolution tree. One such property is that the tree be minimal, which is defined as follows.
Definition 4. A tree isminimal with respect to Jif for all trees such that .
A tree that is both optimal and minimal will be called an optimal minimal tree. Importantly, an optimal minimal tree is guaranteed to not contain any redundant nodal expansions. In other words, removing any portion of an optimal minimal tree is guaranteed to result in a pruned tree that is strictly worse with respect to the objective function. In contrast, if an optimal tree is not minimal, then some portion(s) of the tree can be pruned with no loss in the objective value, indicating that the non-minimal tree contains redundant nodal expansions. Thus, of all optimal trees, the minimal solution is preferred as it contains the fewest number of leaf nodes among solution candidates and also requires the least amount of resources to store in memory. Our goal is then to design an algorithm that returns, as a function of , and , an optimal minimal tree.
In theory, one may take a number of approaches to find a solution (not necessarily optimal) to Problem 1. One approach is the brute-force method of generating each tree in the space
and picking one that satisfies (
11); a process which is akin to grid-search methods in optimization theory. However, such an exhaustive approach does not scale well to large environments. Alternatively, one may notice that the node-wise structure of the cost (
14) renders the implementation of a greedy approach straightforward. Specifically, given any tree
one may expand the leaf node
that results in the greatest change in the cost
. By expanding a node
, we remove
and add its children
to the leaf set to generate the tree
, leaving other nodes unchanged. One may continue this process until a tree is reached for which no further improvement is possible, as quantified by the one-step incremental objective value
. This myopic steepest-ascent-like approach is not guaranteed to find an optimal solution, however, as the process may fail to identify expansions that are suboptimal with respect to the one-step objective
, but lead to higher-valued expansions in future iterations. Consequently, we seek to incorporate the value of expansions-to-come when deciding whether or not to expand a leaf node of the current tree.
To this end, we introduce a generalized tree search algorithm we call G-tree search. The G-tree search algorithm works from top-down, starting at the root tree
and utilizing the function
, defined as
in order to decide which nodes to expand. Specifically, given any tree
, G-tree search will inspect the G-values, computed according to (
22), for each node
and expand a node
for which
. Once a node
is selected for expansion, a new tree
is defined by removing the node
t and adding its children,
, to the set of leafs, leaving the other nodes in the tree
unchanged. In this way, the tree
is related to
via
. The process then repeats until we find a tree
for which there does not exist
such that
. Note that by designing the algorithm in this way, the constraint
is naturally enforced. The G-tree search method is detailed in Algorithm 1. Note that the pseudo-code for a greedy tree search is identical to that of G-tree search in Algorithm 1 with each
replaced by
. We will discuss the shortcomings of the greedy approach in more detail in
Section 6.1.
| Algorithm 1 The G-tree Search Algorithm. |
![Entropy 24 00809 i001]() |
A few comments are in order regarding the G-tree search method. First, the routine
populates the G-values, as follows. The routine utilizes the joint distribution
in order to compute the values of
,
and
for all
,
and
. Given the weights
one may compute
and apply the rule (
22) to obtain the G-values via a recursion that begins at the leafs of
. The pseudo-code for the
ComputeGvalues procedure is shown in Algorithm 2. Lastly, the function
updates the information contained in the tree at the current time-step of the solution. It does so by utilizing the values of
,
and
for each
and
, which were computed in the process of evaluating the nodal G-values described above. The information contained in the tree
is then given by
,
and
where
and
. Recall that starting the algorithm at the root tree
implies, for all
i and
j, we have
,
and
.
| Algorithm 2 The ComputeGvalues routine. |
![Entropy 24 00809 i002]() |
5.2. Theoretical Analysis of the G-Tree Search Algorithm
In this section, we discuss the theoretical properties of the G-tree search algorithm introduced in
Section 5.1. Our main result is that the G-tree search algorithm returns an optimal minimal tree. In our analysis, we will oftentimes refer to the part of a tree
that is descendant (or rooted) at some node
. To make this notion precise, we have the following definition.
Definition 5 ([
36]).
Let be a node in the tree .The subtree of
rooted at node
t is denoted by and has node setwhere , , and An example of a subtree is shown in
Figure 3. Each time the G-tree search visits and expands a node
, the algorithm can be viewed as determining the part of the subtree rooted at
t for which a net increase in the objective can be achieved. For example, consider the case when the algorithm is provided with a tree
. In order to determine whether or not expanding some
will lead to a tree of greater objective value than
, the algorithm must determine if expanding the node
t leads to future expansions that result with a tree
for which
. Of course, if
for some
, then it is clear that expanding the node
t leads to a tree that improves the value of the objective. However, when
, the decision of whether or not to expand
is not so clear, as the algorithm must then consider if, by continuing the expansion process along the children of
t, can result in a tree that improves of the overall objective value. In essence, we are interested in investigating how the G-function in (
22) relates to the incremental objective value of a subtree rooted at any
and to show that, if there exists a subtree rooted at
t that results in a overall improvement of the objective, then
. To answer this question, we have the following results.
Lemma 6. Let , and . Then, for all .
Corollary 7. Let , , and . If there exists a tree such that then .
Proof. The result is immediate from Lemma 6. □
As a result of Lemma 6 and Corollary 7, we are guaranteed that, if there is a subtree rooted at
t for which an increase in the overall objective is possible, then
. Furthermore, we are guaranteed that the value of the G-function (
22) is bounded below by the incremental value of the objective contributed by any subtree rooted at
t. The converse to Lemma 6 and Corollary 7 is also of important; namely if we know
for some
, then it is of interest in establishing whether or not this implies that there is a subtree rooted at
t for which a net increase in the objective is possible. This leads us to the following results.
Lemma 8. Let , , and . If , then there exists a tree such that .
Corollary 9. Let , , and . If , then there exists a tree such that .
Proof. The proof follows from Lemma 8. □
Importantly, Lemma 8 establishes the connection between the G-function and the incremental objective value, as well as the existence of a subtree rooted at for which a net positive objective increment is possible, in the case when . Moreover, Lemma 8 and Corollary 9 together guarantee that if the G-value of a node is strictly positive, then there exists a subtree rooted at the node such that expanding t (and possibly continuing the expansions process along the children of t) will result in a tree that has strictly greater objective value. Also, observe that by combining the results of Corollaries 7 and 9 we obtain the following lemma.
Lemma 10. Let , , and . Then if and only if there exists a tree such that .
Proof. The result is a consequence of Corollaries 7 and 9. □
Lemma 10 is important, as it provides necessary and sufficient conditions linking the existence of a subtree rooted at any node to the value of the nodal G-function value. We are now in a position to prove the optimality of the solution returned by G-tree search, as stated by the following theorem.
Theorem 11. Assume , and . Then, the G-tree search algorithm returns an optimal minimal tree with respect to J.
As a consequence of Theorem 11, we can guarantee that for any set of parameters , the G-tree search algorithm will return a tree that is the optimal and minimal solution to Problem 1.
5.3. Complexity Analysis
While Theorem 11 establishes that the G-tree search algorithm introduced in
Section 5.1 returns an optimal minimal tree that satisfies (
11), it is also important to characterize the number of operations required to execute the algorithm, in the worst case. To this end, we note that a tree
corresponding to some grid in the
d-dimensional space with side-length
has
total nodes, where
for any integer
. As a result, the number of nodes in the tree is on the order of the number of leaf nodes of
. Thus, executing the G-tree search algorithm in Algorithm 1 once the G-function is known, requires order
operations, as the search may visit, in the worst case, every node in the tree. Now, note that for a given number of relevant variables
and irrelevant variables
, the computation of the G-function requires on the order of
operations per node in the tree, corresponding to the calculation of
and
and G-function values. Thus, visiting each node in the tree requires on the order of
operations. Consequently, updating the G-values and running the G-tree search requires on the order of
operations in the worst case for a given setting of the problem.
7. Numerical Example and Discussion
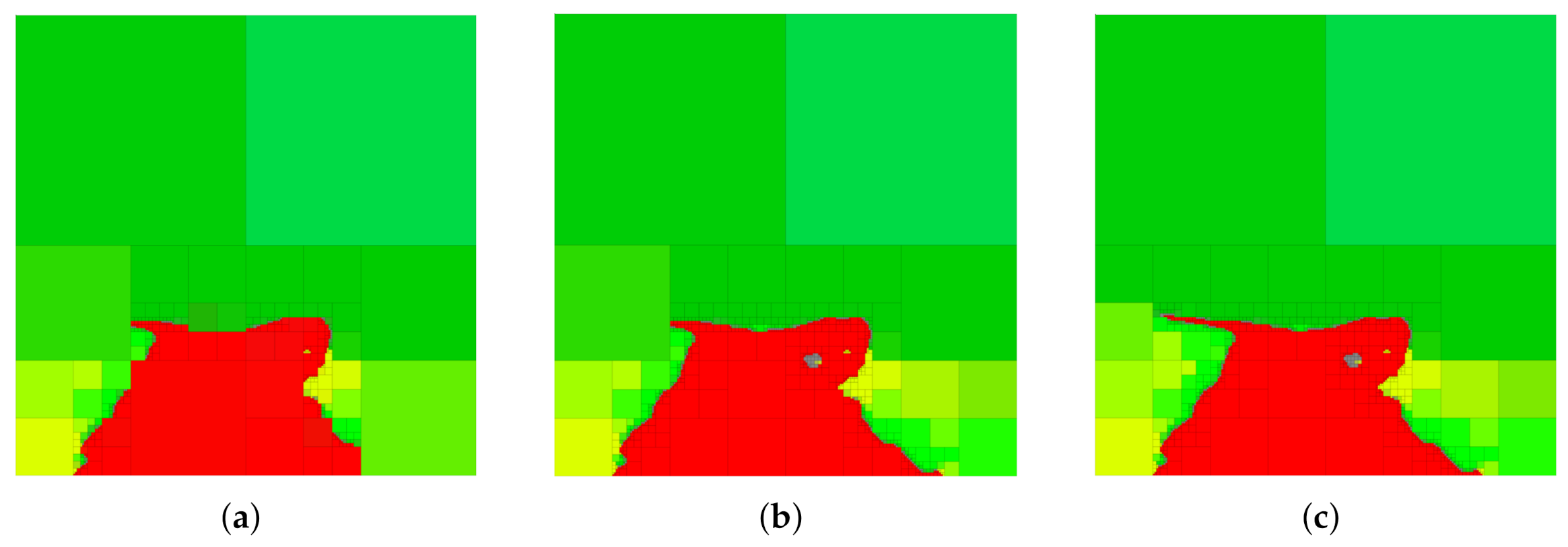
In this section, we demonstrate the utility of our approach on a real-world example. We consider the image shown in
Figure 5a, which is of size
. The image in
Figure 5a is then segmented, so that each pixel in the original image is classified into one of six distinct categories; the segmented image together with the original image is shown in
Figure 5b. Segmented images such as the one shown in
Figure 5b arise frequently in autonomous driving scenarios, where it is of interest to remove irrelevant details from the representation so as to focus available resources on only those aspects of the image that are considered important (e.g., the location of the obstacles or the shape of the road). In the segmented image shown in
Figure 5c, we see that the task of maintaining relevant information regarding the road corresponds to retaining the red color while the remaining colors, such light green and yellow, are not relevant to the task of identifying the road and should be removed from the representation.
The input data are provided to the G-tree search algorithm as follows. We consider each finest-resolution pixel as an outcome of the uncompressed random variable
X. Since the agent may not, in general, have the resources (time, computational, etc.) in order to determine the color (or category) information of each pixel with certainty, we model each color in
Figure 5c as a random variable. To this end, for each color in
Figure 5c we introduce a random variable, where colors that are assumed to be relevant are denoted as
and those considered irrelevant as
. For example, if we would like to generate abstractions where red and blue are relevant (and therefore should be retained) and yellow as irrelevant (and should be removed), we may define
to correspond to the category (or color) red and
to blue, whereas
may represent yellow.
Strictly speaking, knowledge of the distributions
,
and
is sufficient to apply our method, as from relations (
15)–(
21) we see that these distributions allow the determination of
,
and
for all
i,
j and
t. The conditional distributions
and
are obtained from the image segmentation step, where
is the probability that the cell
x has the color corresponding to
, with an analogous interpretation for
and
.In this example,
is assumed to be uniform, although any valid distribution is permissible in our framework (the G-tree search approach can handle any valid distribution
without modification. The use of a non-uniform
will lead to region-specific abstraction, where the G-tree search algorithm refines in regions only where
. For more information, the interested reader is referred to [
36]). The joint distributions
and
are then assigned according to
and
, respectively. In the more general setting where the input is the joint probability mass function
, the distributions
,
and
can be obtained via marginalization, and the conditional distributions
and
required to compute (
15)–(
17) are acquired by applying standard rules for conditional probability.
In order to provide a basis for the discussion that follows, we show in
Figure 6 a selection of abstractions obtained by trading relevant information and compression (i.e., the IB problem setting) in the case where red is the relevant variable. A number of observations can be deduced from the abstractions in
Figure 6. Firstly, it should be noted that G-tree search finds a tree that retains all the available red information and contains only about
of the nodes of the finest-resolution space. Next, notice that by changing the parameter
, we change the relative importance of compression and information retention. Consequently, at larger values of
, we obtain abstractions that contain less red information but contain fewer leaf nodes (achieve a greater degree of compression) as compared to the abstractions that arise as
is decreased.
Furthermore, observe from
Figure 6 that regions in the image that contain both no red information and are homogeneous in red color remain aggregated even at high values of
. This occurs for two reasons. Firstly, observe from (
15) that if a node
has children
for which
for all
y, then
as
. Consequently, regions that either contain no red or that are homogeneous in red color contain no relevant information. Intuitively, if a region in the finest resolution is homogeneous in the color red, then no information is lost by aggregating homogeneously-colored finest resolution cells (i.e., given the aggregated cell we can perfectly predict the color of the descendant nodes). Thus, nodes
for which all descendant nodes are homogeneous in red color provide no additional relevant information, and thus one can see from (
22) that
for these nodes. Notice that the reason regions with no or homogeneous relevant information remain aggregated is due to Theorem 11. To see why, consider the scenario when compression is ignored
. In this case, regions that contain no relevant information may be expanded at no cost, but would not contribute to an increase in the objective value as seen by relation (
13). However, such expansions would lead to a non-minimal tree to be returned by the G-tree search algorithm, which is precluded by Theorem 11. As a result, G-tree search will return the tree with the least number of leaf-nodes that attains the optimal objective function value. This implies that the tree returned by G-tree search maintains regions with no relevant information aggregated.
Next, we generate multi-resolution tree abstractions by employing G-tree search to not only retain relevant information, but also remove information that is considered irrelevant. To this end, we continue our example of considering red as the relevant variable of interest, now letting light green and yellow be irrelevant variables and represented by
and
, respectively. Example abstractions obtained in this case are shown in
Figure 7. Notice that the case shown in
Figure 7c corresponds to the standard IB problem with red as relevant and no penalty on compression.
A number of observations can be made from the sample abstractions shown in
Figure 7. First, notice that, in comparison with the abstractions shown in
Figure 6 which only consider the retention of the color red, the abstractions in
Figure 7 aggregate cells along the boundary of red and the irrelevant information (light green and yellow) so as to obscure this information from the abstraction, while being as predictive regarding red (the relevant information) as possible. Moreover, observe that at greater values of the vector
, regions of yellow and light green are shown in lower resolution as compared with the resolution of these areas at lower values of
. Notice also that, as the irrelevant information is ignored (
), we recover an abstraction (
Figure 7c) that is equivalent to the tree in
Figure 6c returned by the standard IB approach, which does not consider the removal of the irrelevant information content. To better illustrate the differences between the standard IB case shown in
Figure 6 and the generalized tree search scenario in
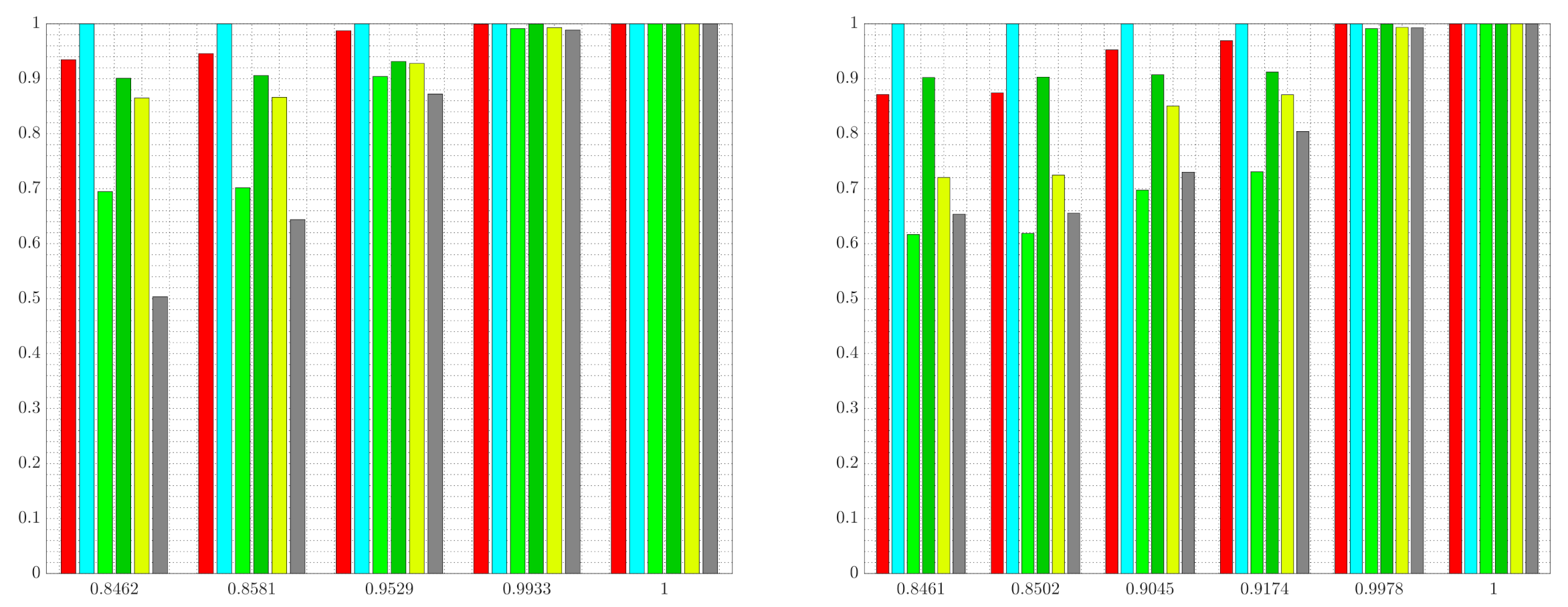
Figure 7, we show the normalized information retained by each color for various settings of the weight parameters in
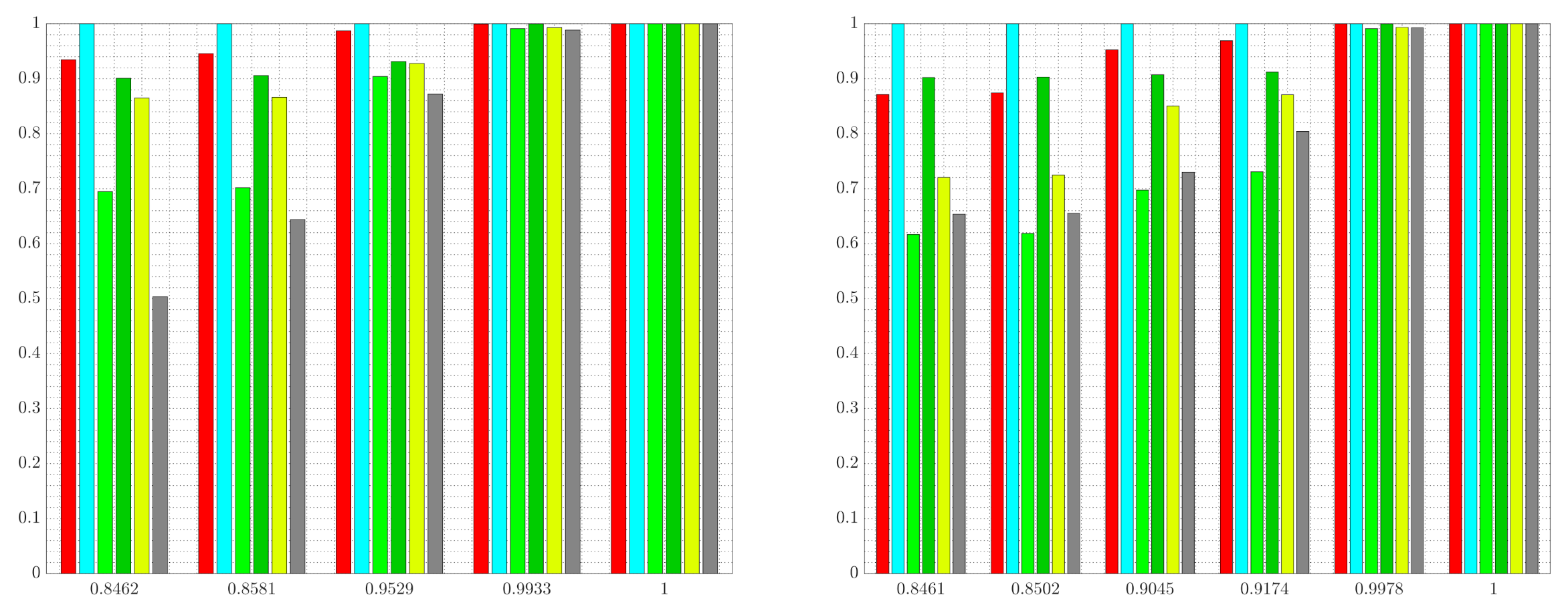
Figure 8. The results shown in
Figure 8 are obtained by setting
,
and by varying the vector
.
Figure 8 shows the normalized information retained in the solutions returned by G-tree search for two cases: (i) the standard IB problem with red as relevant, and (ii) the generalized tree search with red as relevant and light green as well as yellow as irrelevant. In the standard IB problem, decreasing the value of
leads to abstractions that are more informative regarding the relevant information, at the cost of obtaining a tree
that achieves a lower degree of compression. Consequently, one moves from right to left in
Figure 8 (left) as the value of
is increased. In contrast, in the generalized setting of maintaining red information while removing light green and yellow, increasing the weights of the irrelevant information leads to abstractions that achieve more compression, since the importance of information removal increases with larger values of
. Thus, keeping all other weights constant, we move from right to left in
Figure 8 (right) as
is increased.
We also see from
Figure 8 that, compared with the IB tree solutions, the trees obtained from the G-tree search approach in case (ii) retain less information regarding light green and yellow. One may also observe from
Figure 8 that when the generalized-tree search algorithm is tasked with retaining red information while removing light green and yellow, less red information is retained. This occurs as the importance of information removal necessitates an abstract representation in order to obscure, or remove, the irrelevant details. However, it is only regions that contain both relevant
and irrelevant information that are of interest to the algorithm in this case, since regions that contain no relevant information are not refined even in the absence of irrelevant information content. In other words, one may view the relevant information as driving refinement, while irrelevant information promoting aggregation. It is therefore regions that contain both irrelevant and relevant information that becomes the focus of G-tree search. We can observe this trend in the abstractions shown in
Figure 7. Specifically, notice that regions not containing any relevant information (i.e., regions with no red) are left unchanged and aggregated in
Figure 7a–c. In contrast, when comparing the results of
Figure 6, where irrelevant information is not taken into account, to those of
Figure 7, we see that the areas containing both relevant and irrelevant information are aggregated as the relative importance of information removal is increased. This occurs for the aforementioned reasons, namely, we must sacrifice some relevant information in order to obscure, or remove, the irrelevant details. At the same time, those regions containing red and no irrelevant colors are maintained with relatively high resolution (e.g., the middle of the image where red boarders with darker green), since these regions contain relevant information with no irrelevant details.
We conclude this section by briefly showcasing the versatility of the G-tree search algorithm to remove redundancies from segmented images. Since the G-tree search algorithm allows any integer number
of relevant random variables to be defined, it is possible to allow each color in
Figure 5c to be a distinct relevant variable. In this case, G-tree search will find trees for which the distinct colors are as distinguishable as possible while balancing the degree of compression achieved by the abstraction. Interestingly, if one were to take
for all
and
, then G-tree search will find a multi-resolution tree that retains all the color information, while removing as much redundancy as possible, as seen in
Figure 9. Remarkably, the abstraction in
Figure 9 contains only
of the nodes of the finest-resolution representation in
Figure 5c while retaining
all the color (semantic) information.
The ability to compress the environment in this way while losing no information regarding the information content of the image represents a drastic savings in the required on-board memory needed to store the depiction of the environment.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}