
VQProtect: Lightweight Visual Quality Protection for Error-Prone Selectively Encrypted Video Streaming

 ,
,  , , ,
, , ,  and
and 
Abstract
1. Introduction
- Q1:
- What will happen to the selectively encrypted video data after transmitting over wireless channels, which are prone to errors?
- Q2:
- Will it be possible to recover the multimedia content with an equivalent visual quality?
- Q3:
- Will the decryption of error-corrupted video still succeed at the receiver end, or will it fail?
- 1.
- This paper provides a novel and pioneer prototype (to the best of the authors’ knowledge) for protecting the video quality of selectively encrypted H.264/AVC compressed videos while transferring over erroneous wireless networks.
- 2.
- Selective Encryption (SE) using two-round secure process is applied to the selected syntax elements of an H.264/AVC CABAC encoder to achieve video privacy, and it maintains the video’s format compliancy and compression efficiency for effective channel bandwidth utilization.
- 3.
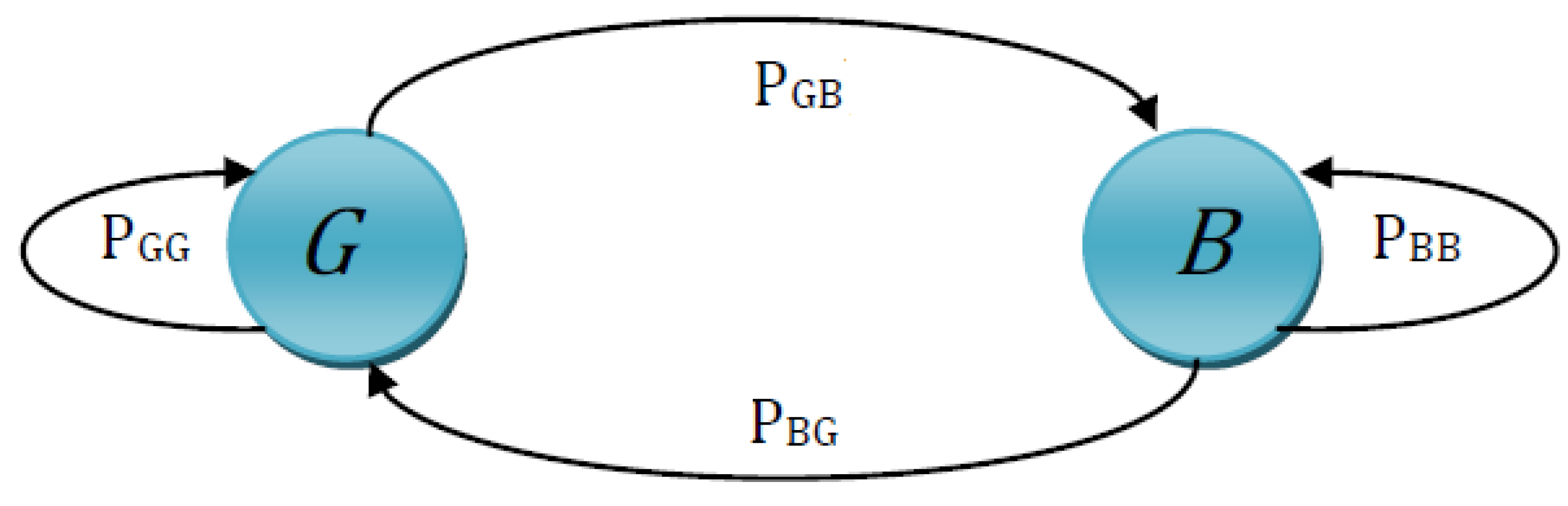
- The Gilbert–Elliot model is implemented for the simulation of an error-prone channel.
- 4.
- A Random Linear Block coding-based FEC mechanism is deployed on the encrypted H.264/AVC bitstreams for the recovery of bit-errors. The results are verified using various Video Quality Metrics and evaluation criteria.
2. Related Studies
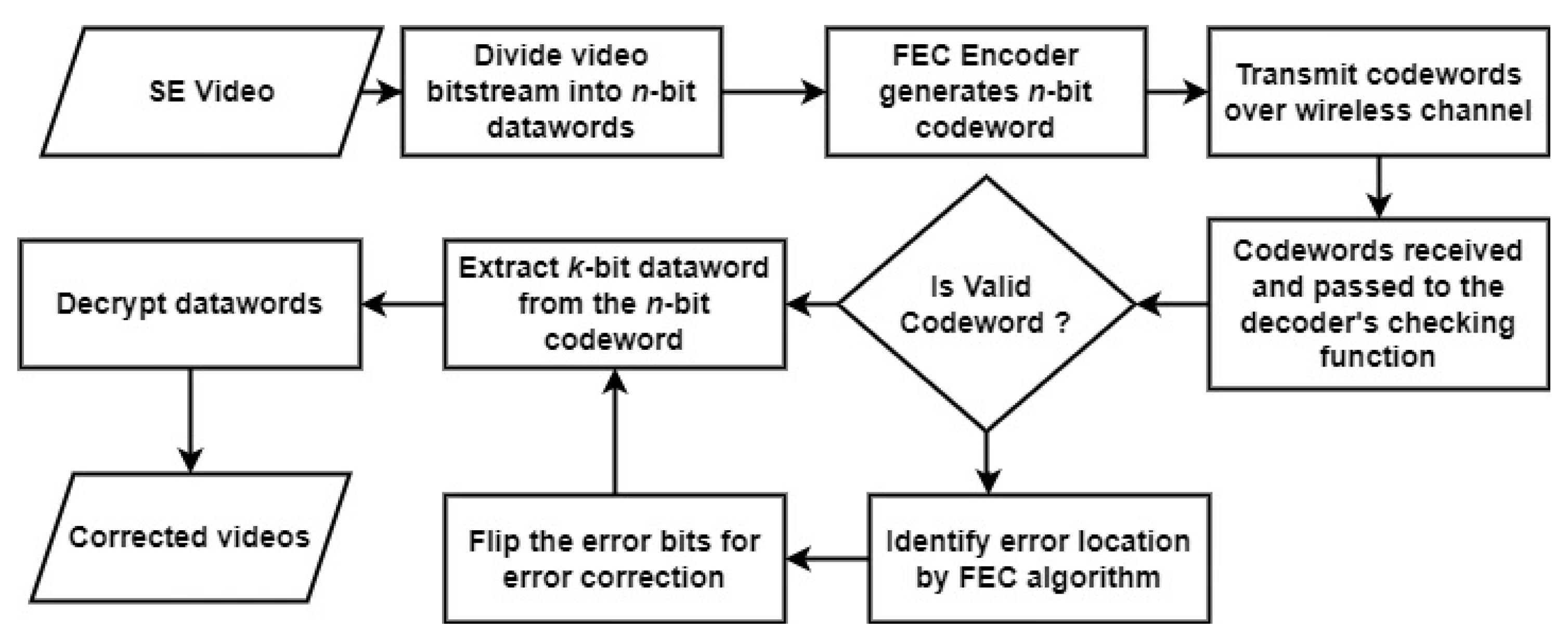
3. Proposed Solution
- In the first phase, video content is compressed and protected at the same time. The privacy protection is implemented using a two-round secure process. First, data diffusion is achieved by applying permutation on selected residuals data of compressed H.264/AVC bitstreams, and later, the XOR encryption algorithm is applied to the permuted data. The compressed selectively encrypted video bitstreams are produced as an output of this phase.
- In the second phase, channel modeling is performed through the Markov-Chain based Gilbert–Elliot model, which introduces bit errors inside the selectively encrypted videos (output of Phase 1) and enables simulations of the burst error effects of communications links.
- In the last phase, an FEC mechanism is applied (on both the encoder and decoder side) to detect and correct bit errors from the H.264/AVC selectively encrypted bitstreams (output of Phase 2) for their error-free transmission.
3.1. Compression and Privacy Protection
3.2. Channel Modeling
| GE Channel Modeling Algorithm for Error Encoding |
| Step1: Obtain the encrypted data or the encrypted and FEC encoded data to be sent over a communication channel. |
| Step 2: Determine the state of the transmission channel, i.e., is it in a good or bad state? |
| Step 3: Determine the stationary state probabilities for the good state and for the bad state. |
| Step 4: Determine the sojourn time and of both states. |
| Step 5: Determine the steady-state probabilities and . |
| Step 6: Calculate the mean Bit Error Rate. |
| Step 7: Induce the errors according to the calculated mean BER (varied within 0.07 to 0.1%) in the B state only. |
| Step 8: Forward the data with errors added toward the decryption and decoder modules. |
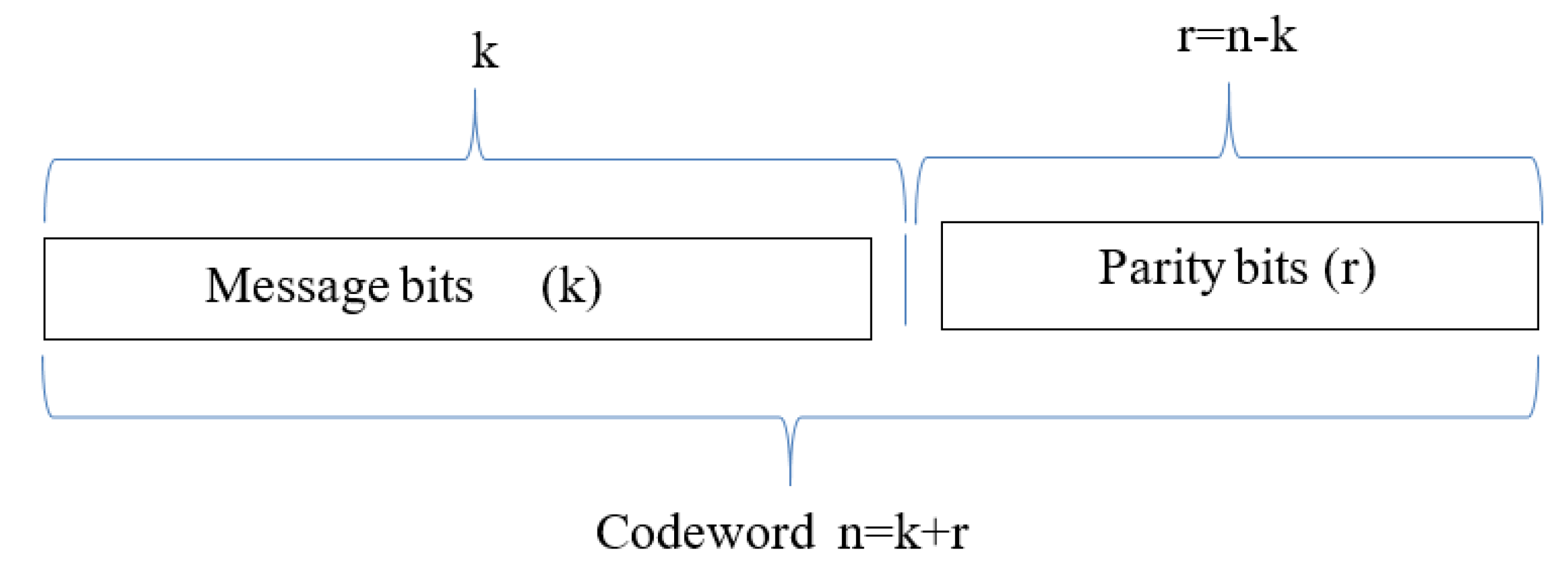
3.3. Forward Error Correction
| Algorithm 1 Pseudocode of Implemented FEC Method: Source/Sender |
|
| Algorithm 2 Pseudocode of Implemented FEC Method: Destination/Receiver Side |
|
4. Experimental Results and Performance Evaluation
4.1. Video Quality Analysis
4.1.1. PSNR
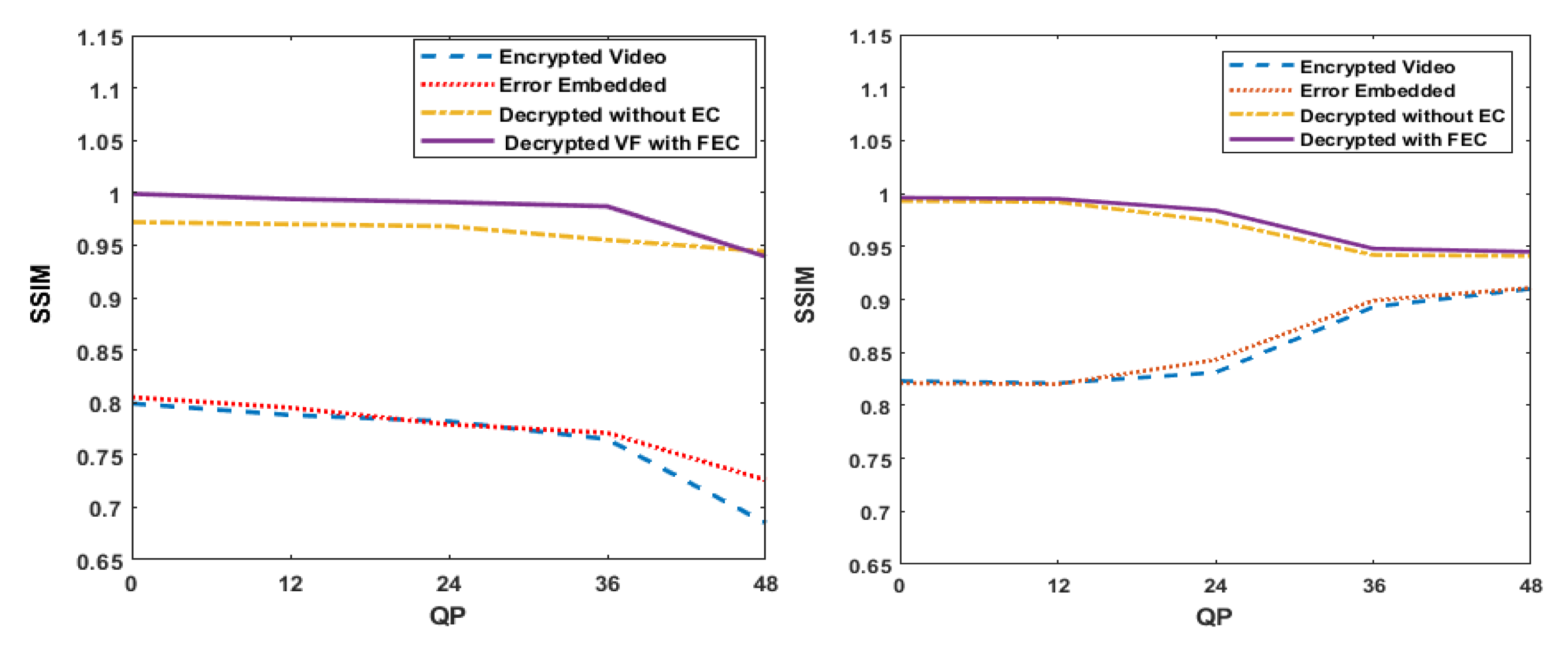
4.1.2. SSIM
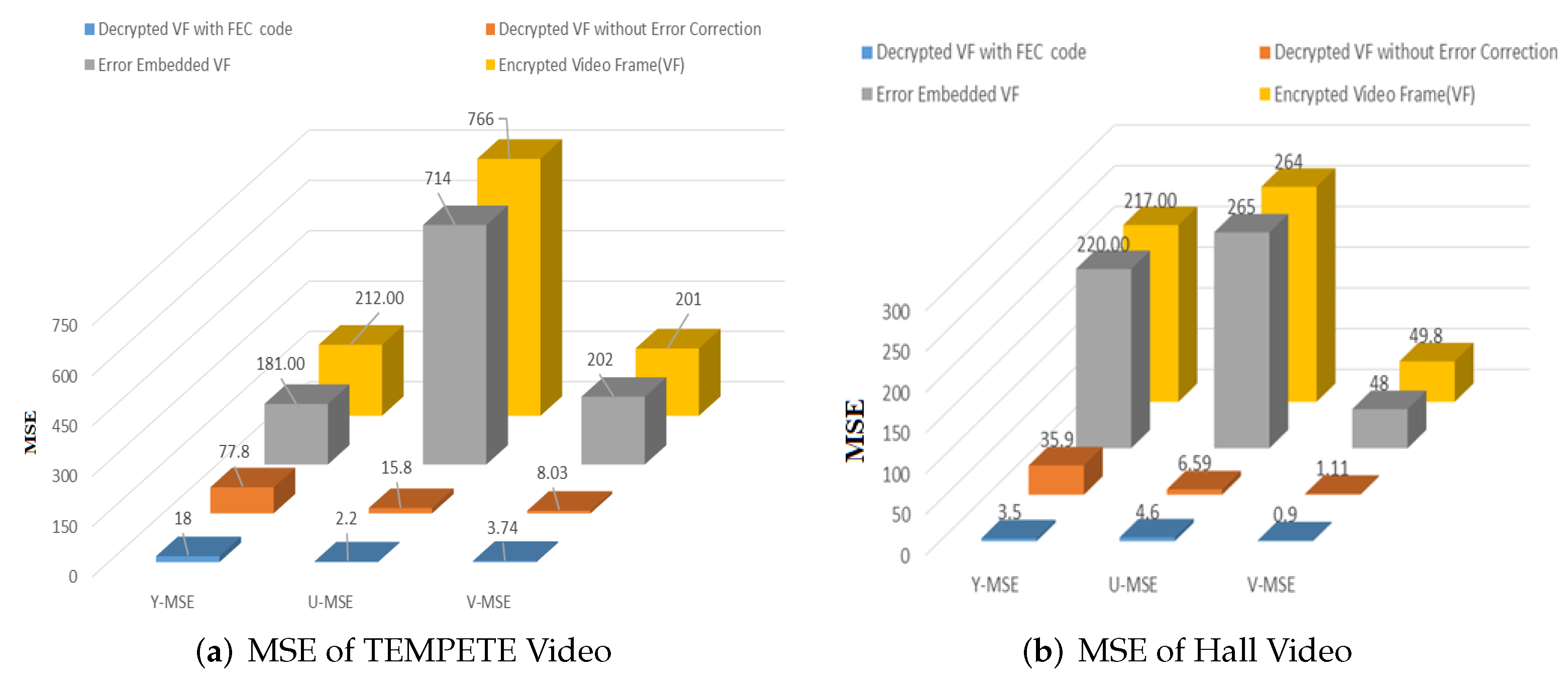
4.1.3. MSE
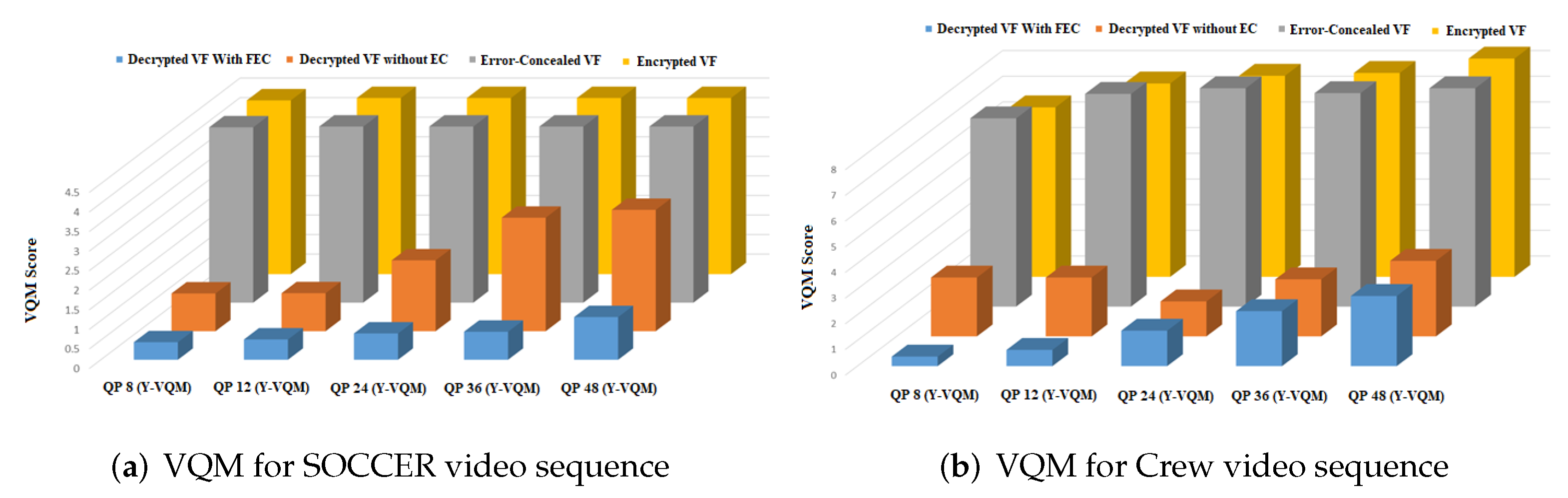
4.1.4. VQM
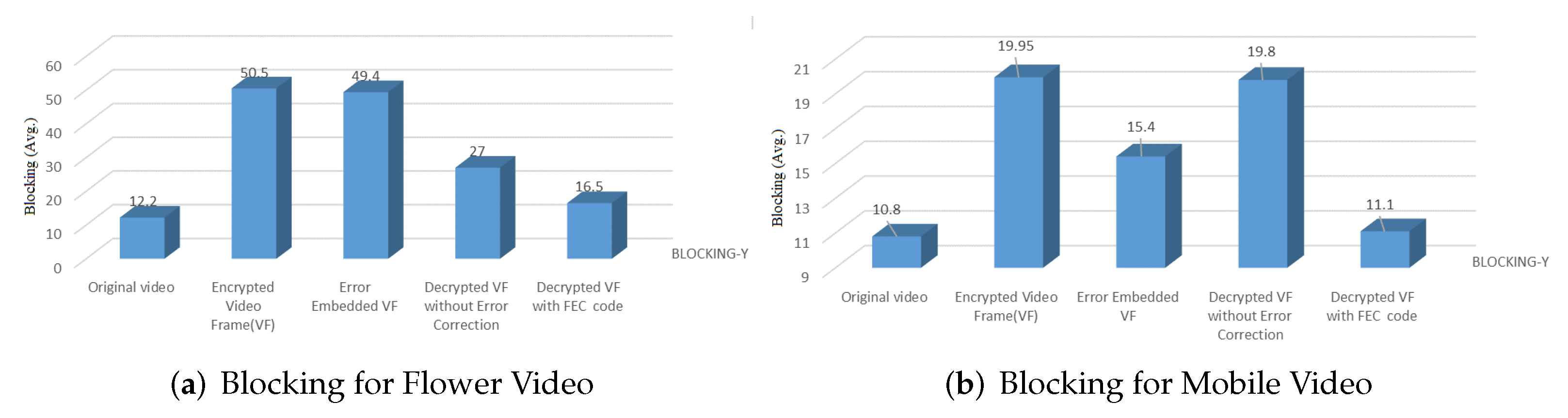
4.1.5. Histogram Analysis
4.2. No-Reference Video Quality Assessment
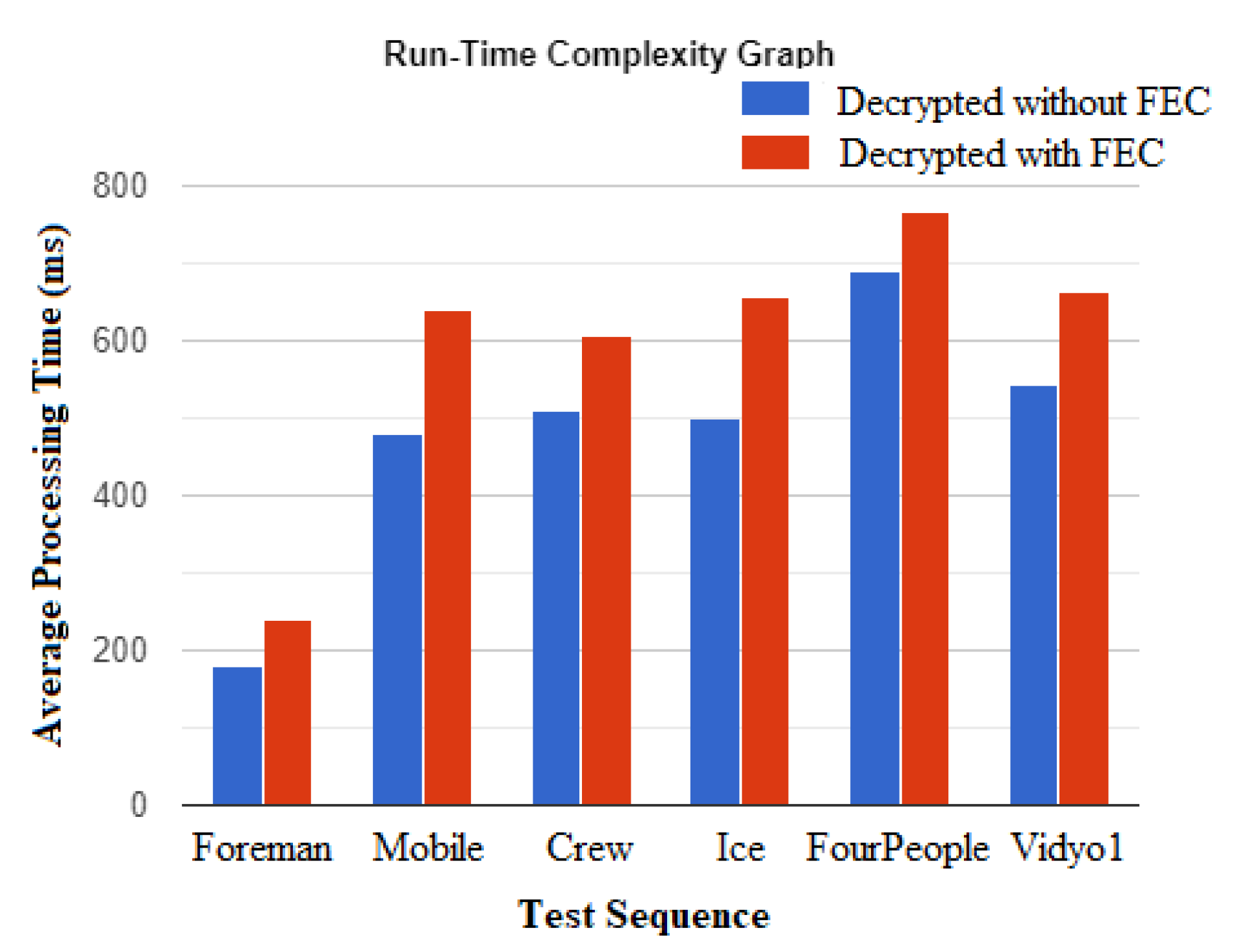
4.3. Computational Cost Analysis
4.4. Comparative Analysis
5. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alvarez, F.; Breitgand, D.; Griffin, D.; Andriani, P.; Rizou, S.; Zioulis, N.; Moscatelli, F.; Serrano, J.; Keltsch, M.; Trakadas, P.; et al. An edge-to-cloud virtualized multimedia service platform for 5G networks. IEEE Trans. Broadcast. 2019, 65, 369–380. [Google Scholar] [CrossRef]
- Marpe, D.; Wiegand, T.; Sullivan, G.J. The H.264/MPEG4 advanced video coding standard and its applications. IEEE Commun. Mag. 2006, 44, 134–143. [Google Scholar] [CrossRef]
- Piran, M.J.; Pham, Q.; Islam, S.R.; Cho, S.; Bae, B.; Suh, D.Y.; Han, Z. Multimedia communication over cognitive radio networks from QoS/QoE perspective: A comprehensive survey. J. Netw. Comput. Appl. 2020, 172, 102759. [Google Scholar] [CrossRef]
- Amjad, M.; Rehmani, M.H.; Mao, S. Wireless multimedia cognitive radio networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2018, 20, 1056–1103. [Google Scholar] [CrossRef]
- Roy, A.; Sengupta, S.; Wong, K.K.; Raychoudhury, V.; Govindan, K.; Singh, S. 5G wireless with cognitive radio and massive IoT. IETE Tech. Rev. 2017, 34, 1–3. [Google Scholar] [CrossRef][Green Version]
- Kawamoto, J.; Kurakake, T. XOR-based FEC to improve burst-loss tolerance for 8K ultra-high definition TV over IP transmission. In Proceedings of the Globecom 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Jung, T.; Jeong, Y.; Lee, H.; Seo, K. Error-resilient surveillance video transmission based on a practical joint source-channel distortion computing model. J. Supercomput. 2017, 73, 1017–1043. [Google Scholar] [CrossRef]
- Hu, H.; Jiang, D.; Li, B. An error resilient video coding and transmission solution over error-prone channels. J. Vis. Commun. Image Represent. 2009, 20, 35–44. [Google Scholar] [CrossRef]
- Song, J.; Yang, Z.; Wang, J. Channel Coding for DTTB System; Chapter Digital Terrestrial Television Broadcasting: Technology and System; Wiley: Hoboken, NJ, USA, 2015; pp. 69–112. [Google Scholar] [CrossRef]
- Urrea, C.; Morales, C.; Kern, J. Implementation of error detection and correction in the Modbus-RTU serial protocol. Int. J. Crit. Infrastruct. Prot. 2016, 15, 27–37. [Google Scholar] [CrossRef]
- Asghar, M.N.; Kanwal, N.; Lee, B.; Fleury, M.; Herbst, M.; Qiao, Y. Visual surveillance within the EU general data protection regulation: A technology perspective. IEEE Access 2019, 7, 111709–111726. [Google Scholar] [CrossRef]
- Shifa, A.; Asghar, M.N.; Fleury, M.; Kanwal, N.; Ansari, M.S.; Lee, B.; Herbst, M.; Qiao, Y. MuLViS: Multi-level encryption based security system for surveillance videos. IEEE Access 2020, 8, 177131–177155. [Google Scholar] [CrossRef]
- Shah, R.A.; Asghar, M.N.; Abdullah, S.; Fleury, M.; Gohar, N. Effectiveness of crypto-transcoding for H.264/AVC and HEVC video bit-streams. Multimed. Tools Appl. 2019, 78, 21455–21484. [Google Scholar] [CrossRef]
- Alfaqheri, T.T.; Sadka, A.H. Low delay error resilience algorithm for H. 265| HEVC video transmission. J. Real-Time Image Process. 2020, 17, 2047–2063. [Google Scholar] [CrossRef]
- Chen, H.; Zhao, C.; Sun, M.T.; Drake, A. Adaptive intra-refresh for low-delay error-resilient video coding. J. Vis. Commun. Image Represent. 2015, 31, 294–304. [Google Scholar] [CrossRef]
- El-Shafai, W.; El-Rabaie, S.; El-Halawany, M.; Abd El-Samie, F.E. Enhancement of wireless 3d video communication using color-plus-depth error restoration algorithms and Bayesian Kalman filtering. Wirel. Pers. Commun. 2017, 97, 245–268. [Google Scholar] [CrossRef]
- ElShafai, W.; ElRabaie, S.; ElHalawany, M.; Abd ElSamie, F.E. Encoder-independent decoder-dependent depth-assisted error concealment algorithm for wireless 3D video communication. Multimed. Tools Appl. 2018, 77, 13145–13172. [Google Scholar] [CrossRef]
- Hassan, M.S.; Abusara, A.; El Din, M.S.; Ismail, M.H. On efficient channel modeling for video transmission over cognitive radio networks. Wirel. Pers. Commun. 2016, 91, 919–932. [Google Scholar] [CrossRef]
- Dey, S.; Misra, I.S. A Novel Content Aware Channel Allocation Scheme for Video Applications over CRN. Wirel. Pers. Commun. 2018, 100, 1499–1515. [Google Scholar] [CrossRef]
- Zi, W. High definition wireless multimedia transmission model based on bit-stream control and differential fault tolerance. J. Ambient. Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Yang, Y.; Zhu, Q. Error control and concealment for video communications: A review. Proc. IEEE 1998, 86, 974–997. [Google Scholar] [CrossRef]
- Carreira, J.F.; Assunção, P.A.; de Faria, S.M.; Ekmekcioglu, E.; Kondoz, A. Error concealment-aware encoding for robust video transmission. IEEE Trans. Broadcast. 2018, 65, 282–293. [Google Scholar] [CrossRef]
- Yao, R.; Liu, Y.; Liu, J.; Zhao, P.; Ci, S. Utility-based H.264/SVC video streaming over multi-channel cognitive radio networks. IEEE Trans. Multimed. 2015, 17, 434–449. [Google Scholar] [CrossRef]
- Asghar, M.N.; Ghanbari, M.; Fleury, M.; Reed, M.J. Analysis of channel error upon selectively encrypted H.264 video. In Proceedings of the 2012 4th Computer Science and Electronic Engineering Conference (CEEC), Colchester, UK, 12–13 September 2012; pp. 139–144. [Google Scholar]
- Boyadjis, B.; Bergeron, C.; Pesquet-Popescu, B.; Dufaux, F. Extended selective encryption of H.264/AVC (CABAC)-and HEVC-encoded video streams. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 892–906. [Google Scholar] [CrossRef]
- Bildea, A.; Alphand, O.; Rousseau, F.; Duda, A. Link quality estimation with the Gilbert-Elliot model for wireless sensor networks. In Proceedings of the 2015 IEEE 26th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Hong Kong, China, 30 August–1 September 2015; pp. 2049–2054. [Google Scholar]
- Elliott, E.O. Estimates of error rates for codes on burst-noise channels. Bell Syst. Tech. J. 1963, 42, 1977–1997. [Google Scholar] [CrossRef]
- EzZazi, I.; Arioua, M.; El Oualkadi, A.; el Assari, Y. Joint FEC/CRC coding scheme for energy constrained IoT devices. In Proceedings of the International Conference on Future Networks and Distributed Systems, Cambridge, UK, 19–20 July 2017; pp. 1–8. [Google Scholar]
- Nafaa, A.; Taleb, T.; Murphy, L. Forward error correction strategies for media streaming over wireless networks. IEEE Commun. Mag. 2008, 46, 72–79. [Google Scholar] [CrossRef]
- Singh, V.; Sharma, N. A review on various error detection and correction methods used in communication. Am. Int. J. Res. Sci. Technol. Eng. Math. 2015, 15, 252–257. [Google Scholar]
- Hussain, M.; Hameed, A. Adaptive video-aware forward error correction code allocation for reliable video transmission. Signal Image Video Process. 2018, 12, 161–169. [Google Scholar] [CrossRef]
- Shih, C.; Kuo, C.; Chou, Y. Frame-based forward error correction using content-dependent coding for video streaming applications. Comput. Netw. 2016, 105, 89–98. [Google Scholar] [CrossRef]
- Nunome, T. The Effect of MMT ALFEC on QoE of Error-Concealed Video Streaming. ITE Trans. Media Technol. Appl. 2020, 8, 186–194. [Google Scholar] [CrossRef]
- Wu, J.; Yuen, C.; Cheung, N.M.; Chen, J.; Chen, C.W. Streaming Mobile cloud gaming video over TCP with adaptive source–FEC coding. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 32–48. [Google Scholar] [CrossRef]
- Chao, H.; Fan, T. XOR-based progressive visual secret sharing using generalized random grids. Displays 2017, 49, 6–15. [Google Scholar] [CrossRef]
- Wu, J.; Cheng, B.; Wang, M.; Chen, J. Priority-aware FEC coding for high-definition mobile video delivery using TCP. IEEE Trans. Mob. Comput. 2016, 16, 1090–1106. [Google Scholar] [CrossRef]
- Weng, Y.T.; Shih, C.H.; Chou, Y.K. Sliding-window forward error correction using Reed-Solomon code and unequal error protection for real-time streaming video. Int. J. Commun. Syst. 2018, 31, e3405. [Google Scholar] [CrossRef]
- Tang, L.; Ramamoorthy, A. Coded caching schemes with reduced subpacketization from linear block codes. IEEE Trans. Inf. Theory 2018, 64, 3099–3120. [Google Scholar] [CrossRef]
- Zhou, M.; Jin, C. QoS-aware forward error correction cooperating with opportunistic routing in wireless multi-hop networks. Wirel. Pers. Commun. 2017, 92, 1407–1422. [Google Scholar] [CrossRef]
- Pham, T.; Tsai, M.; Wu, T.; Guizani, N. An algorithm for the selection of effective error correction coding in wireless networks based on a lookup table structure. Int. J. Commun. Syst. 2017, 30, e3346. [Google Scholar] [CrossRef]
- Kumar, N.; Jaishree. Error Detection and Correction Using Parity and Pixel Values of Image. In Progress in Advanced Computing and Intelligent Engineering; Springer: Berlin/Heidelberg, Germany, 2018; pp. 155–165. [Google Scholar]
- Kazemi, M.; Ghanbari, M.; Shirmohammadi, S. The performance of quality metrics in assessing error-concealed video quality. IEEE Trans. Image Process. 2020, 29, 5937–5952. [Google Scholar] [CrossRef] [PubMed]
- Usman, M.A.; Seong, C.; Lee, M.H.; Shin, S.Y. A novel error detection & concealment technique for videos streamed over error prone channels. Multimed. Tools Appl. 2019, 78, 22959–22975. [Google Scholar]
- Ali, F.A.; Simoens, P.; Van de Meerssche, W.; Dhoedt, B. Bandwidth efficient adaptive forward error correction mechanism with feedback channel. J. Commun. Netw. 2014, 16, 322–334. [Google Scholar] [CrossRef]
- Zhu, C.; Huo, Y.; Zhang, B.; Zhang, R.; ElHajjar, M.; Hanzo, L. Adaptive-truncated-HARQ-aided layered video streaming relying on interlayer FEC coding. IEEE Trans. Veh. Technol. 2015, 65, 1506–1521. [Google Scholar] [CrossRef]
- Shih, C.; Xu, Y.; Wang, Y.T. Secure and reliable IPTV multimedia transmission using forward error correction. Int. J. Digit. Multimed. Broadcast. 2012, 2012, 720791. [Google Scholar] [CrossRef]
- Wu, J.; Yuen, C.; Cheung, N.; Chen, J.; Chen, C.W. Enabling adaptive high-frame-rate video streaming in mobile cloud gaming applications. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1988–2001. [Google Scholar] [CrossRef]
- Talari, A.; Kumar, S.; Rahnavard, N.; Paluri, S.; Matyjas, J.D. Optimized cross-layer forward error correction coding for H.264 AVC video transmission over wireless channels. EURASIP J. Wirel. Commun. Netw. 2013, 2013, 1–13. [Google Scholar] [CrossRef]
- Berkani, A.; Belkasmi, M. A reduced complexity decoder using compact genetic algorithm for linear block codes. In Proceedings of the 2016 International Conference on Advanced Communication Systems and Information Security (ACOSIS), Marrakesh, Morocco, 17–19 October 2016; pp. 1–6. [Google Scholar]
- Hou, Y.; Xu, J.; Xiang, W.; Ma, M.; Lei, J. Near-optimal cross-layer forward error correction using raptor and RCPC codes for prioritized video transmission over wireless channels. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2028–2040. [Google Scholar] [CrossRef]
- Asghar, M.N.; Ghanbari, M. An efficient security system for CABAC bin-strings of H.264/SVC. IEEE Trans. Circuits Syst. Video Technol. 2012, 23, 425–437. [Google Scholar] [CrossRef]
- Da Silva, C.A.G.; Pedroso, C.M. Mac-layer packet loss models for wi-fi networks: A survey. IEEE Access 2019, 7, 180512–180531. [Google Scholar] [CrossRef]
- Short, M.; Sheikh, I.; Aley, S.; Rizvi, I. Bandwidth-efficient burst error tolerance in TDMA-based CAN networks. In Proceedings of the ETFA2011, Toulouse, France, 5–9 September 2011; pp. 1–8. [Google Scholar]
- McDougall, J.; Miller, S. Sensitivity of wireless network simulations to a two-state Markov model channel approximation. In Proceedings of the GLOBECOM’03. IEEE Global Telecommunications Conference (IEEE Cat. No. 03CH37489), San Fransico, CA, USA, 1–5 December 2003; Volume 2, pp. 697–701. [Google Scholar]
- Vujicic, B. Modeling and Characterization of Traffic in a Public Safety Wireless Networks. Ph.D. Thesis, School of Engineering Science-Simon Fraser University, Burnaby, BC, Canada, 2018. [Google Scholar]
- Chen, L.; Hung, H. A two-state markov-based wireless error model for bluetooth networks. Wirel. Pers. Commun. 2011, 58, 657–668. [Google Scholar] [CrossRef]
- Haßlinger, G.; Hohlfeld, O. Analysis of random and burst error codes in 2-state Markov channels. In Proceedings of the 2011 34th International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 18–20 August 2011; pp. 178–184. [Google Scholar]
- Haßlinger, G.; Hohlfeld, O. The Gilbert-Elliott model for packet loss in real time services on the Internet. In Proceedings of the 14th GI/ITG Conference-Measurement, Modelling and Evalutation of Computer and Communication Systems, VDE, Dortmund, Germany, 31 March–2 April 2008; pp. 1–15. [Google Scholar]
- Sousa, P.B.; Ferreira, L.L. Technical Report—Bit Error Models; 2007. Available online: https://depts.washington.edu/funlab/wp-content/uploads/2017/05/Technical-report-on-validation-of-error-models-for-802.11n.pdf (accessed on 7 April 2021).
- Xiph.org. Xiph.org: Derf’s Test Media Collection. 2021. Available online: https://media.xiph.org/video/derf/ (accessed on 8 March 2021).
- HuynhThu, Q.; Ghanbari, M. The accuracy of PSNR in predicting video quality for different video scenes and frame rates. Telecommun. Syst. 2012, 49, 35–48. [Google Scholar] [CrossRef]
- Z Wang, A.; C Bovik, H.; Sheikh, R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Li, T.; Zhengguo, L.; Han, T.; Rahardja, S.; Chuohuo, Y. A perceptually relevant MSE-based image quality. IEEE Trans. Image Process 2013, 22, 4447–4459. [Google Scholar]
- Pinson, M.H.; Wolf, S. A new standardized method for objectively measuring video quality. IEEE Trans. Broadcast. 2004, 50, 312–322. [Google Scholar] [CrossRef]
- Leontaris, A.; Reibman, A.R. Comparison of blocking and blurring metrics for video compression. In Proceedings of the (ICASSP’05). IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005; Volume 2, pp. 585–588. [Google Scholar]
- Thomos, N.; Boulgouris, N.V.; Strintzis, M.G. Optimized transmission of JPEG2000 streams over wireless channels. IEEE Trans. Image Process. 2005, 15, 54–67. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Hu, Y.; Au, O.C.; Li, H.; Chen, C.W. Video error concealment using spatio-temporal boundary matching and partial differential equation. IEEE Trans. Multimed. 2007, 10, 2–15. [Google Scholar] [CrossRef]
- Sun, H.; Liu, P.; Wang, J.; Goto, S. An efficient frame loss error concealment scheme based on tentative projection for H.264/AVC. In Proceedings of the Pacific-Rim Conference on Multimedia; Springer: Berlin/Heidelberg, Germany, 2010; pp. 394–404. [Google Scholar]
- Golaghazadeh, F.; Coulombe, S.; Coudoux, F.X.; Corlay, P. The impact of H.264 non-desynchronizing bits on visual quality and its application to robust video decoding. In Proceedings of the 2018 12th International Conference on Signal Processing and Communication Systems (ICSPCS), Cairns, Australia, 17–19 December 2018; pp. 1–7. [Google Scholar]
- Velea, R.; Gurzău, F.; Mărgărit, L.; Bica, I.; Patriciu, V.V. Performance of parallel ChaCha20 stream cipher. In Proceedings of the 2016 IEEE 11th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 12–14 May 2016; pp. 391–396. [Google Scholar]
- Mansri, I.; Doghmane, N.; Kouadria, N.; Harize, S.; Bekhouch, A. Comparative Evaluation of VVC, HEVC, H.264, AV1, and VP9 Encoders for Low-Delay Video Applications. In Proceedings of the 2020 Fourth International Conference on Multimedia Computing, Networking and Applications (MCNA), Valencia, Spain, 19–22 October 2020; pp. 38–43. [Google Scholar]
- Kazemi, M.; Ghanbari, M.; Shirmohammadi, S. A review of temporal video error concealment techniques and their suitability for HEVC and VVC. Multimed. Tools Appl. 2021, 80, 1–46. [Google Scholar] [CrossRef]
- Shah, R.A.; Asghar, M.N.; Abdullah, S.; Kanwal, N.; Fleury, M. SLEPX: An efficient lightweight cipher for visual protection of scalable HEVC extension. IEEE Access 2020, 8, 187784–187807. [Google Scholar] [CrossRef]
- Mukherjee, D.; Bankoski, J.; Grange, A.; Han, J.; Koleszar, J.; Wilkins, P.; Xu, Y.; Bultje, R. The latest open-source video codec VP9-an overview and preliminary results. In Proceedings of the 2013 Picture Coding Symposium (PCS), San Jose, CA, USA, 8–11 December 2013; pp. 390–393. [Google Scholar]
- Duong, D.T. New H. 266/VVC Based Multiple Description Coding for Robust Video Transmission over Error-Prone Networks. In Proceedings of the 2020 International Conference on Advanced Technologies for Communications (ATC), Nha Trang, Vietnam, 8–10 October 2020; pp. 155–159. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed Schemes | Video Format or Video Codec | Permutation applied | Video Quality Assessment | Analytical complexity | FEC Computational Average Time (ms) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Encryption | Simulation Model | FEC | PSNR | SSIM | MSE | VQM | Blocking | Blurring | |||||
| [31] | H.264/AVC | X | X | No fixed loss rate | Reed–Solomon | X | Yes | X | X | X | X | RC Block Size Dependent | Not mentioned |
| [36] | HD Video | X | X | Monte Carlo | Systematic RS Block Erasure Code | Yes | Yes | X | X | X | X | O(M ()) | 87.2, 73.5, 62.3, 51, 40.3, 32.5, 24.5 (in different feedback frequencies) |
| [39] | Not given | X | X | WLAN | Reed–Solomon | No but SINR provided | Not mentioned | Not mentioned | |||||
| [44] | Not given | X | X | GE Model | Reed–Solomon | No, but delay and redundancy provided | O() | 70, 125, and 150 (for FEC-16, FEC-64, and FEC-128) | |||||
| [45] | H.264/SVC | X | X | Monte Carlo | Recursive Systematic Cumulative Code | Yes | X | X | X | X | X | Low-complexity Table-look-up Operations Dependent | Not mentioned |
| [46] | IPTV data | X | AES | WLAN loss rate = 0.1 | Systematic RS Block erasure code | No, but exposure rate and recovery probability provided | Not mentioned | Not mentioned | |||||
| [47] | HFR video encoded with H.264 | X | X | Monte Carlo | Systematic RS Block Erasure Code | Yes | X | X | X | X | X | [0–2.5], [0–4.5] (for different frame rates) | |
| [48] | H.264/AVC | X | X | Monte Carlo on AWGN channel | Luby Transform and Rate-Compatible Punctured Convolutional (RCPC) Codes | Yes | X | X | X | X | X | O() | Not mentioned |
| [49] | HFR video encoded with H.264 | X | X | Adaptive White Gaussian Noise (AWGN) Channel | Linear Block Codes | No, but Bit Error Rates and latency given | Not mentioned | ||||||
| [50] | H.264/AVC | X | X | AWGN and Rayleigh Channels | Rate Compatible Punctured Convolution (RCPC) Codes | Yes | X | X | X | X | X | Not mentioned | |
| VQProtect | H.264/AVC | One Round | XOR algorithm | Gilbert–Elliot Model | Random Linear Block Codes | Yes | Yes | Yes | Yes | Yes | Yes | 35, 132, 109, 133, 99, 128 (for encrypted CIF, 4CIF and HD videos) | |
| Average PSNR | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Encoding Mode | QP | ||||||||||||
| Crew | Soccer | Vidyo1 | FourPeople | ||||||||||
| Y | U | V | Y | U | V | Y | U | V | Y | U | V | ||
| 8 | 15.9 | 26.1 | 22.3 | 23.2 | 17.5 | 26.2 | 5.5 | 22 | 27.6 | 5.4 | 21.7 | 25.6 | |
| 12 | 16.1 | 24 | 20.2 | 23.5 | 17.8 | 26 | 5.8 | 22.0 | 26.1 | 5.9 | 21.1 | 24.8 | |
| Encrypted Video | 24 | 16.5 | 23.9 | 20.5 | 24.7 | 17.9 | 25.8 | 6.3 | 22.1 | 26.9 | 6.1 | 21.6 | 25.3 |
| 36 | 16.2 | 23.2 | 20.1 | 23.2 | 17.6 | 25.6 | 5.9 | 22.5 | 26.7 | 5.8 | 21.0 | 24.9 | |
| 48 | 14.9 | 21.9 | 19.8 | 23.1 | 17.1 | 25.5 | 5.6 | 22.4 | 26.3 | 6.0 | 21.4 | 25.5 | |
| 8 | 15.2 | 27.1 | 23 | 22.7 | 17.6 | 25.9 | 5.5 | 22.8 | 26.9 | 5.8 | 21.9 | 26.3 | |
| 12 | 16.8 | 25.4 | 20.8 | 23.1 | 17.4 | 25.5 | 5.6 | 22.0 | 26.7 | 5.8 | 21.2 | 25.6 | |
| Encrypted Videos with Errors | 24 | 17.8 | 24.2 | 21 | 25.2 | 17.3 | 25.3 | 5.9 | 22.2 | 26.6 | 6.0 | 20.8 | 25.4 |
| 36 | 16.2 | 23.8 | 20.5 | 24.9 | 17 | 25.1 | 5.7 | 23 | 26.9 | 5.9 | 20.9 | 25.4 | |
| 48 | 14.6 | 23.3 | 20 | 23 | 16.8 | 25.3 | 5.7 | 22.3 | 26.8 | 5.6 | 21.1 | 25.9 | |
| 8 | 29.8 | 36 | 39.4 | 35.7 | 53.3 | 53.4 | 21.9 | 37.9 | 38.9 | 17.2 | 34.7 | 35.9 | |
| 12 | 32.8 | 36 | 39.4 | 36.5 | 50.7 | 53 | 21.6 | 37.6 | 38.8 | 17.2 | 34.5 | 33.2 | |
| Decrypted Video without FEC | 24 | 35.7 | 33.4 | 38.9 | 36.7 | 49.8 | 52.8 | 22.3 | 34.5 | 32.9 | 17.9 | 33.5 | 35.8 |
| 36 | 30.5 | 32.2 | 37.1 | 35.1 | 47.1 | 52.5 | 18.6 | 33.5 | 33.9 | 16.5 | 33.6 | 33.4 | |
| 48 | 27.2 | 31.6 | 36.4 | 29 | 46.3 | 49.6 | 17.3 | 34.9 | 33.4 | 15.6 | 30.2 | 32.1 | |
| 8 | 36.8 | 49.3 | 50.4 | 38.9 | 60.5 | 54.3 | 20.1 | 40.1 | 40.5 | 18.1 | 37.2 | 38.4 | |
| 12 | 34.4 | 48.4 | 45.2 | 41.8 | 60.4 | 53.2 | 22.8 | 39.4 | 39.9 | 18.4 | 34.7 | 37.7 | |
| Decrypted Video with FEC | 24 | 43.5 | 46 | 42.1 | 41.9 | 52.3 | 52.4 | 23.4 | 34.8 | 33.7 | 19.1 | 36.5 | 36.7 |
| 36 | 44.3 | 37.1 | 39.5 | 42 | 48.4 | 52.1 | 18.2 | 34.6 | 33.9 | 17.6 | 35.3 | 36.6 | |
| 48 | 29.8 | 34.6 | 38.1 | 35.6 | 46.7 | 48.5 | 17.0 | 35.2 | 33.7 | 16.2 | 31.5 | 32.3 | |
| Phase | Metrics | Videos | |||||
|---|---|---|---|---|---|---|---|
| (Avg.) | Flower | Hall | Tempete | Mobile | Four People | Vidyo1 | |
| SSIM | 0.84 | 0.78 | 0.84 | 0.82 | 0.05 | 0.03 | |
| Encrypted Video | MSE | 212 | 217 | 212 | 114 | 15,457 | 16,813 |
| VQM | 9.64 | 10.7 | 9.64 | 7.82 | 23.1 | 22.24 | |
| SSIM | 0.85 | 0.83 | 0.85 | 0.85 | 0.056 | 0.05 | |
| Encrypted Video with Errors | MSE | 181 | 220 | 181 | 123 | 15,168 | 16,440 |
| VQM | 8.07 | 9.8 | 8.07 | 7.87 | 22.7 | 22.0 | |
| SSIM | 0.96 | 0.97 | 0.96 | 0.93 | 0.84 | 0.87 | |
| Decrypted Video without FEC | MSE | 77.8 | 35.9 | 77.8 | 21.5 | 592.1 | 357.7 |
| VQM | 2.38 | 1.37 | 2.38 | 4.04 | 6.94 | 5.21 | |
| SSIM | 0.99 | 0.98 | 0.99 | 0.98 | 0.97 | 0.96 | |
| Decrypted Video with FEC | MSE | 18 | 3.5 | 18 | 1.4 | 491.4 | 311.3 |
| VQM | 0.79 | 0.89 | 0.79 | 2.3 | 5.98 | 4.80 | |
| Videos | Blurring (Average) | |||
|---|---|---|---|---|
| Flower | Tempete | Mobile | Hall | |
| Original | [Y:4.64,U:0.17,V:0.15] | [Y:5.95,U:1.69,V:0.90] | [Y:8.48,U:2.21,V:2.07] | [Y:4.25,U:0.71,V:0.39] |
| Encrypted | [Y:10.3,U:1.51,V:1.26] | [Y:6.22,U:1.89,V:0.88] | [Y:9.89,U:2.61,V:2.31] | [Y:6.1,U:0.86,V:0.52] |
| Encrypted with errors | [Y:10.4,U:1.59,V:1.34] | [Y:6.52,U:2.07,V:0.86] | [Y:9.94,U:2.76,V:2.39] | [Y:5.05,U:0.89,V:0.53] |
| Decrypted without FEC | [Y:6.8,U:1.03,V:1.33] | [Y:6.19,U:2.09,V:0.88] | [Y:8.82,U:2.53,V:2.33] | [Y:4.96,U:0.79,V:0.43] |
| Decrypted with FEC | [Y:5.96,U:0.19,V:0.17] | [Y:6.07,U:1.73,V:0.89] | [Y:8.52,U:2.28,V:2.19] | [Y:4.53,U:0.74,V:0.41] |
| Error-Coding Technique | QP | Average PSNR (dB) | |||
|---|---|---|---|---|---|
| Foreman (CIF) | Crew (4CIF) | Ice (4CIF) | Average PSNR Difference (dB) from Intact | ||
| Intact | 22 | 41.35 | 41.78 | 43.70 | - |
| 32 | 34.67 | 35.69 | 39.00 | ||
| JM-FC | 22 | 37.60 | 39.21 | 39.18 | 3.61 |
| 32 | 33.70 | 34.96 | 36.50 | 1.40 | |
| STBMA | 22 | 39.49 | 40.64 | 41.74 | 1.65 |
| 32 | 34.19 | 35.44 | 38.15 | 0.52 | |
| NDBV | 22 | 39.99 | 39.03 | 40.58 | 2.41 |
| 32 | 33.93 | 35.23 | 37.51 | 0.89 | |
| VQProtect | 22 | 40.02 | 41.19 | 42. 29 | 1.14 |
| 32 | 34.78 | 35.52 | 38.68 | 0.28 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gillani, S.M.; Asghar, M.N.; Shifa, A.; Abdullah, S.; Kanwal, N.; Fleury, M. VQProtect: Lightweight Visual Quality Protection for Error-Prone Selectively Encrypted Video Streaming. Entropy 2022, 24, 755. https://doi.org/10.3390/e24060755
Gillani SM, Asghar MN, Shifa A, Abdullah S, Kanwal N, Fleury M. VQProtect: Lightweight Visual Quality Protection for Error-Prone Selectively Encrypted Video Streaming. Entropy. 2022; 24(6):755. https://doi.org/10.3390/e24060755
Chicago/Turabian StyleGillani, Syeda Maria, Mamoona Naveed Asghar, Amna Shifa, Saima Abdullah, Nadia Kanwal, and Martin Fleury. 2022. "VQProtect: Lightweight Visual Quality Protection for Error-Prone Selectively Encrypted Video Streaming" Entropy 24, no. 6: 755. https://doi.org/10.3390/e24060755
APA StyleGillani, S. M., Asghar, M. N., Shifa, A., Abdullah, S., Kanwal, N., & Fleury, M. (2022). VQProtect: Lightweight Visual Quality Protection for Error-Prone Selectively Encrypted Video Streaming. Entropy, 24(6), 755. https://doi.org/10.3390/e24060755