
MHSA-EC: An Indoor Localization Algorithm Fusing the Multi-Head Self-Attention Mechanism and Effective CSI


Abstract
:1. Introduction
1.1. CSI-Based Localization
1.2. Limitations
1.3. Attention Mechanism
1.4. Contributions
- 1.
- The algorithm solves the problem of long-distance fingerprint point mismatch in the CSI-based fingerprint positioning algorithm. For the problem of mismatches that are prone to occur at farther distances, we introduce effective CSI as an input to the decision module. Since there is a nonlinear mapping relationship between effective CSI and distance, this signal is introduced to help the decision module to more effectively constrain the position output. The introduction of effective CSI can greatly increase the average positioning accuracy of the system.
- 2.
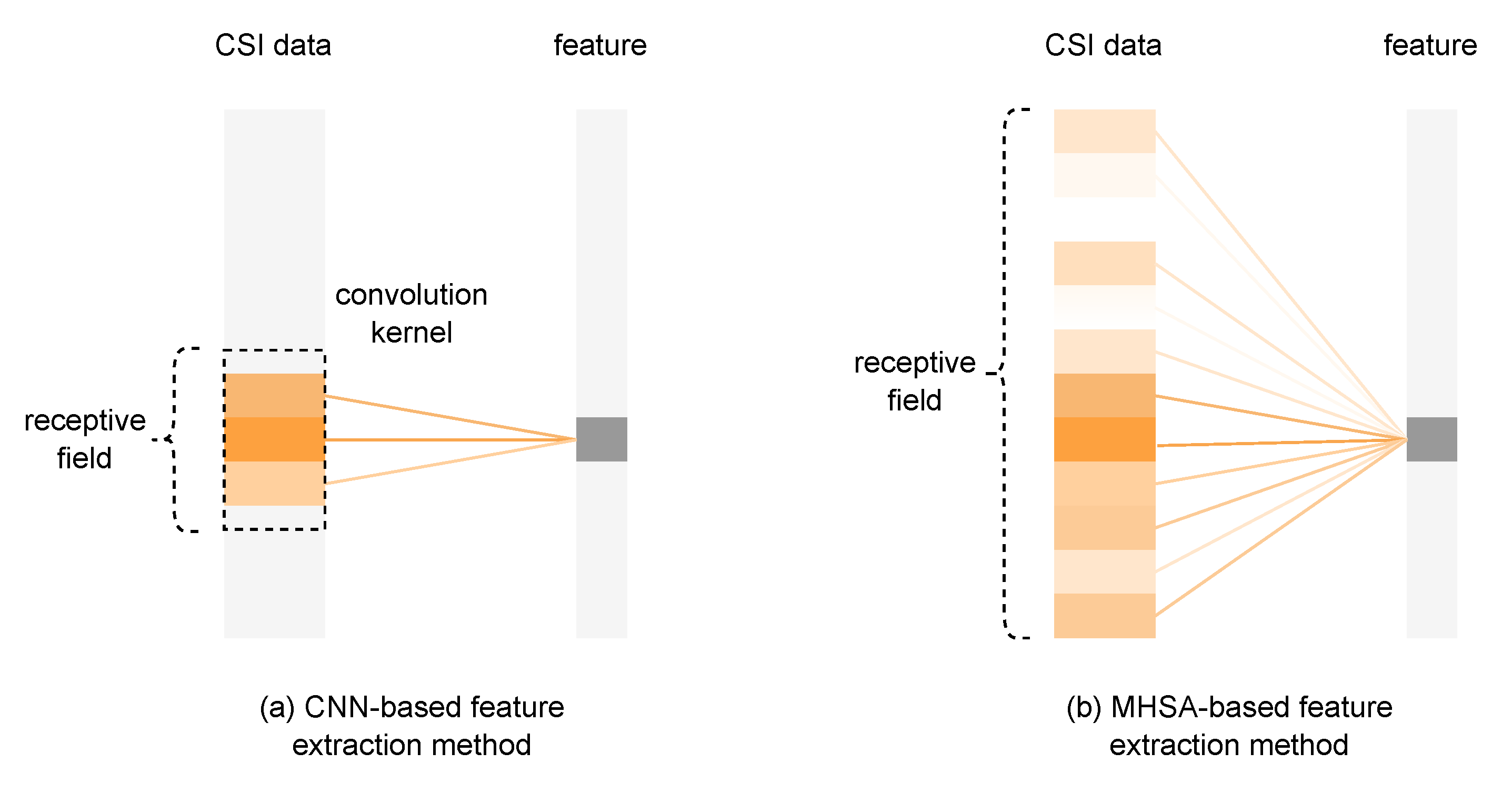
- The attention mechanism solves the problem of insufficient CSI feature extraction ability of the CNN network. The multi-path information contained in the subcarriers and arrays in the CSI signal increases the discrimination of CSI features. The CSI feature extraction method based on the CNN network is limited by the receptive field, and it is difficult to aggregate non-adjacent CSI features, resulting in the insufficient ability of the model to extract multi-path information. This paper improves the feature extraction capability of CSI signals by introducing the attention mechanism from a larger network receptive field and a better ability to aggregate non-adjacent features. The model’s ability to extract CSI features determines whether the model can correctly distinguish the CSI features of different fingerprint points. Therefore, the MHSA-EC model with better CSI feature extraction capability can theoretically improve the localization accuracy of the algorithm.
- 3.
- In addition, this paper also conducts extensive experiments to verify the localization performance of the network in two typical scenes. It also carries out ablation experiments to verify the effectiveness of the network module.
2. Preliminary
2.1. CSI
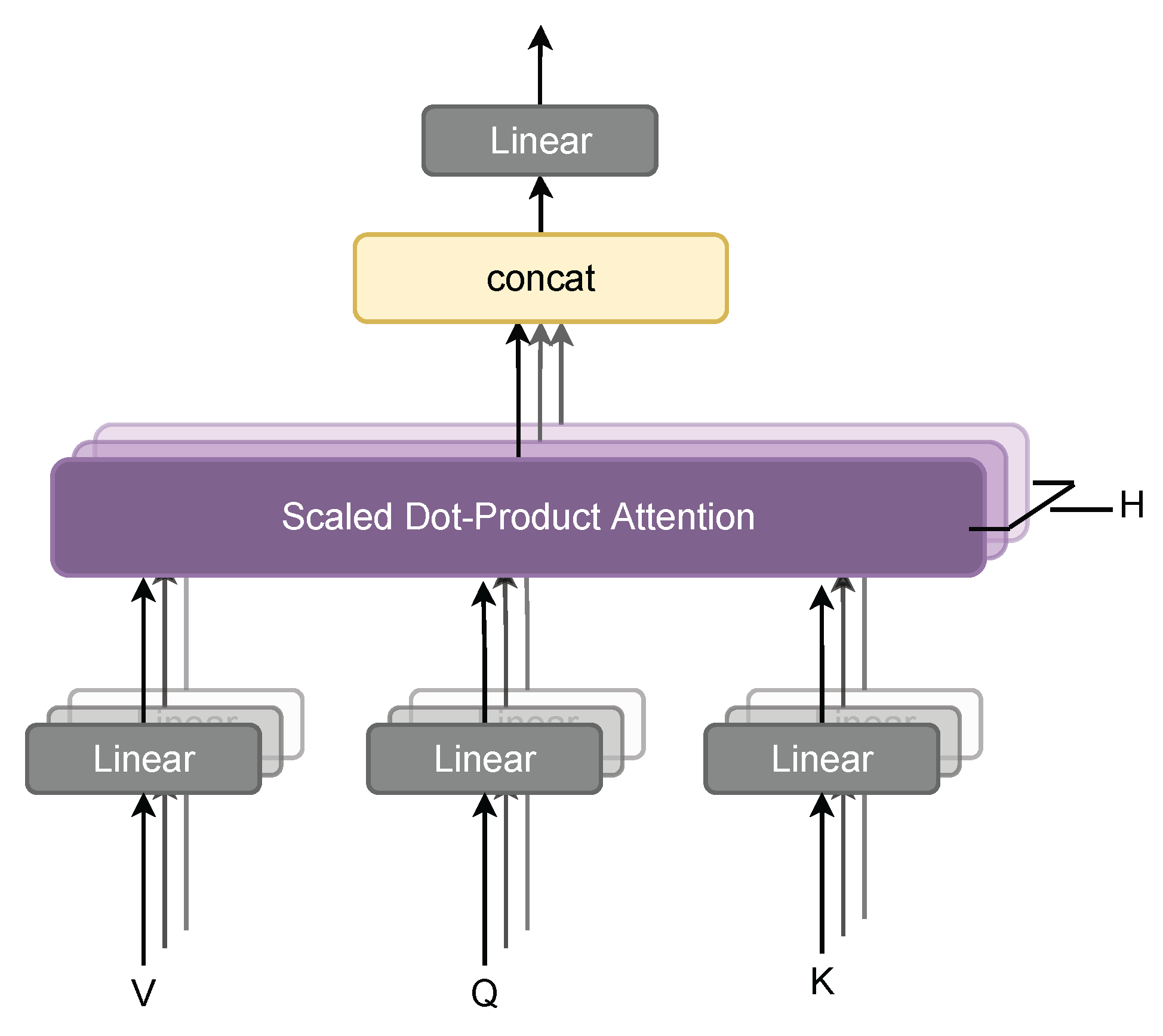
2.2. Self-Attention
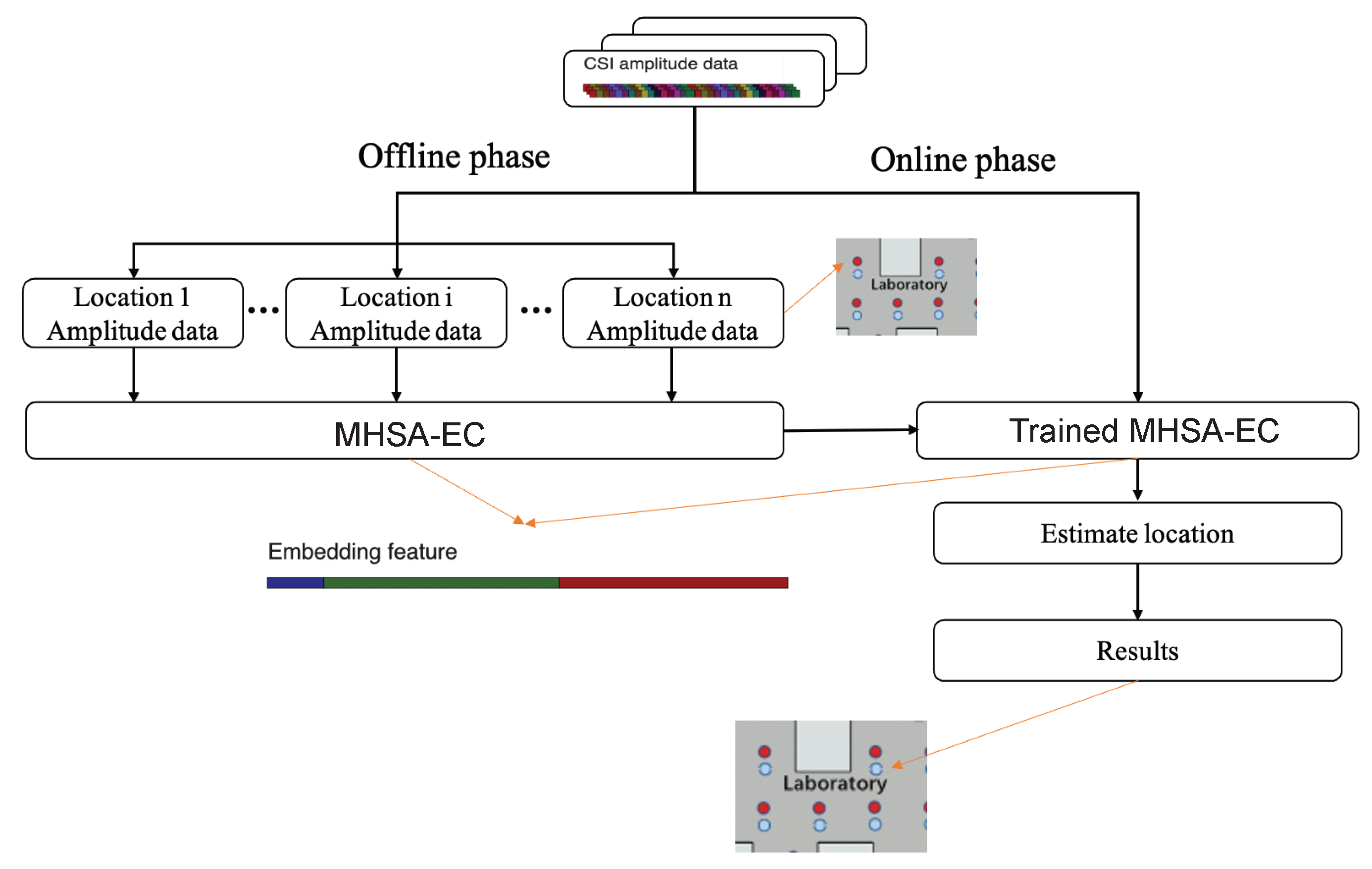
3. Materials and Methods
3.1. CSI Tensor
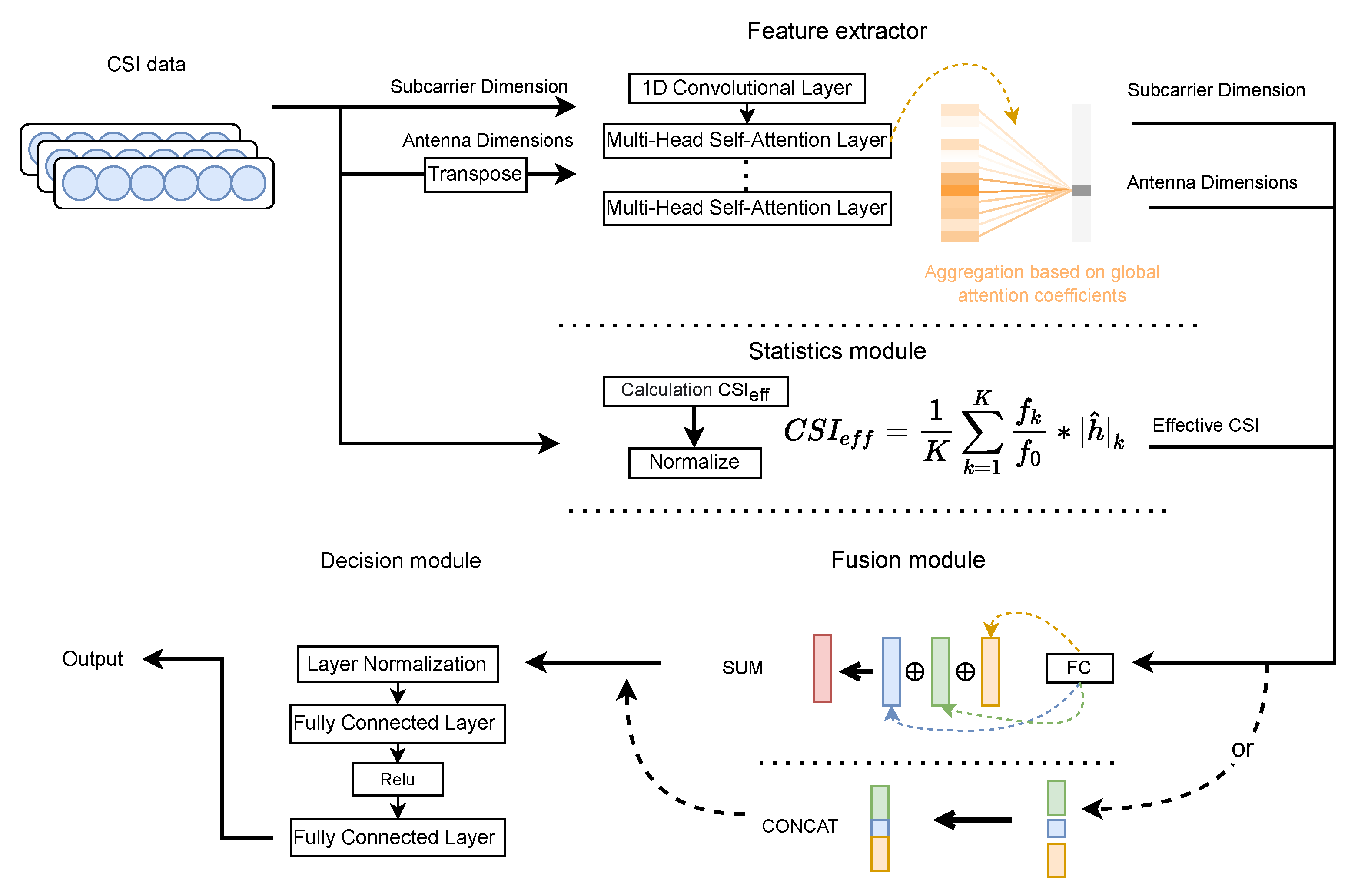
3.2. System Architecture
3.2.1. Feature Extraction Module
3.2.2. Effective CSI Statistics Module
3.2.3. Fusion and Position Determination
3.3. Optimization
4. Experimental Verification
4.1. Experimental Parameters and Scenes
4.1.1. Experimental Parameters
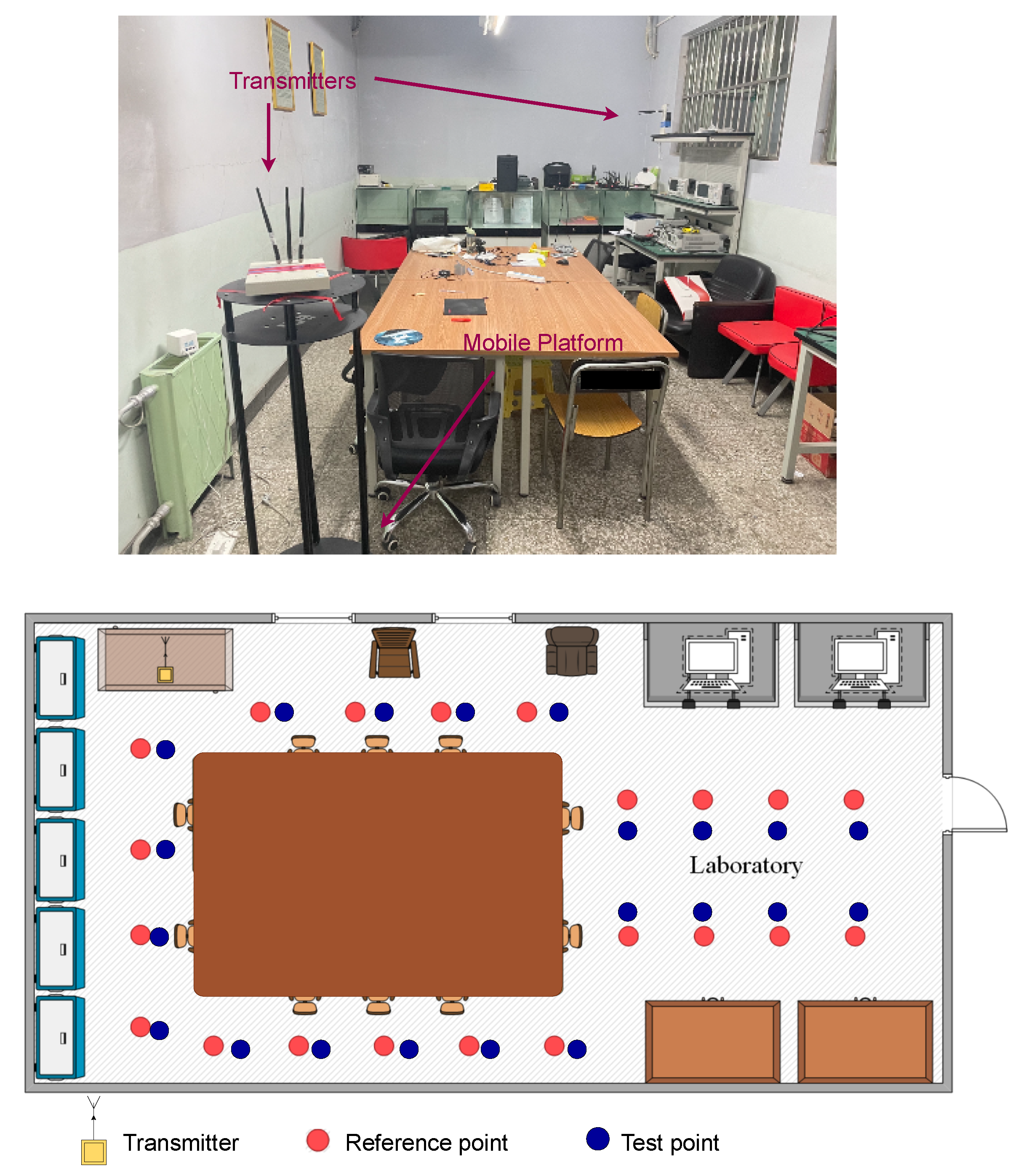
4.1.2. Laboratory
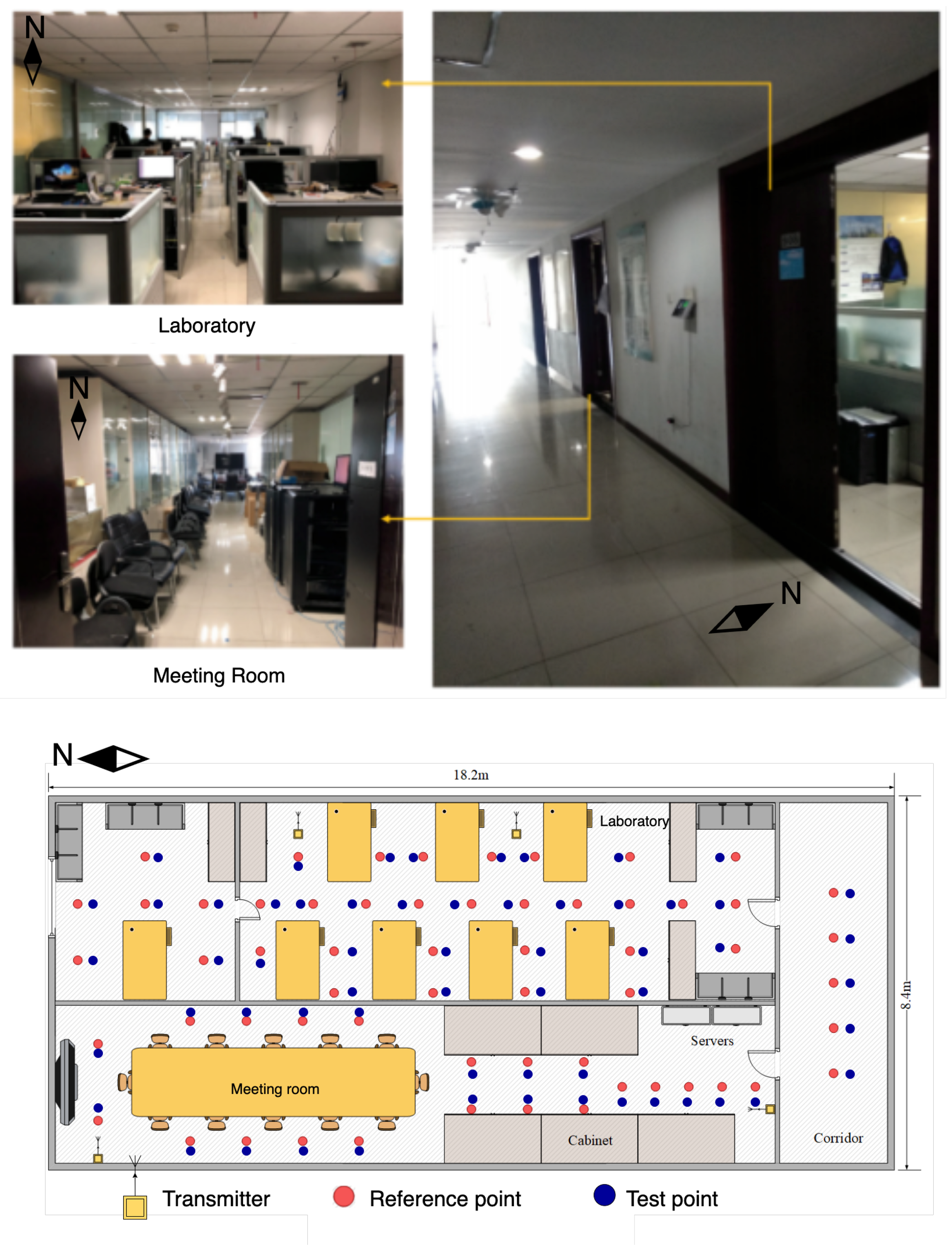
4.1.3. Comprehensive Office
4.2. Model Performance Evaluation
4.2.1. Multi-Head Self-Attention Layers Experiment
4.2.2. Fusion Method Experiment
4.2.3. Positioning Performance Evaluation
5. Summary
Author Contributions
Funding
Conflicts of Interest
References
- Guo, X.; Li, L.; Ansari, N.; Liao, B. Accurate WiFi localization by fusing a group of fingerprints via a global fusion profile. IEEE Trans. Veh. Technol. 2018, 67, 7314–7325. [Google Scholar] [CrossRef]
- Abbas, M.; Elhamshary, M.; Rizk, H.; Torki, M.; Youssef, M. WiDeep: WiFi-based accurate and robust indoor localization system using deep learning. In Proceedings of the 2019 IEEE International Conference on Pervasive Computing and Communications, Kyoto, Japan, 11–15 March 2019; pp. 1–10. [Google Scholar]
- Iqbal, Z.; Luo, D.; Henry, P.; Kazemifar, S.; Rozario, T.; Yan, Y.; Westover, K.; Lu, W.; Nguyen, D.; Long, T.; et al. Accurate real time localization tracking in a clinical environment using Bluetooth Low Energy and deep learning. PLoS ONE 2018, 13, e0205392. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Topak, F.; Pekeriçli, M.K.; Tanyer, A.M. Technological viability assessment of Bluetooth low energy technology for indoor localization. J. Comput. Civ. Eng. 2018, 32, 04018034. [Google Scholar] [CrossRef]
- Jin, G.y.; Lu, X.y.; Park, M.S. An indoor localization mechanism using active RFID tag. In Proceedings of the IEEE International Conference on Sensor Networks, Ubiquitous, and Trustworthy Computing (SUTC’06), Taichung, Taiwan, 5–7 June 2006; Volume 1, p. 4. [Google Scholar]
- Guo, K.; Qiu, Z.; Miao, C.; Zaini, A.H.; Chen, C.L.; Meng, W.; Xie, L. Ultra-wideband-based localization for quadcopter navigation. Unmanned Syst. 2016, 4, 23–34. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, G. Ultra-wide-band based indoor positioning technologies. J. Data Acquis. Process. 2013, 28, 706–713. [Google Scholar]
- Zanca, G.; Zorzi, F.; Zanella, A.; Zorzi, M. Experimental comparison of RSSI-based localization algorithms for indoor wireless sensor networks. In Proceedings of the Workshop on Real-World Wireless Sensor Networks, Glasgow, UK, 1 April 2008; pp. 1–5. [Google Scholar]
- Chapre, Y.; Ignjatovic, A.; Seneviratne, A.; Jha, S. CSI-MIMO: An efficient Wi-Fi fingerprinting using channel state information with MIMO. Pervasive Mob. Comput. 2015, 23, 89–103. [Google Scholar] [CrossRef] [Green Version]
- Zhou, R.; Lu, X.; Zhao, P.; Chen, J. Device-free presence detection and localization with SVM and CSI fingerprinting. IEEE Sens. J. 2017, 17, 7990–7999. [Google Scholar] [CrossRef]
- Ramadan, M.; Sark, V.; Gutierrez, J.; Grass, E. NLOS identification for indoor localization using random forest algorithm. In Proceedings of the WSA 2018, 22nd International ITG Workshop on Smart Antennas, VDE, Bochum, Germany, 14–16 March 2018; pp. 1–5. [Google Scholar]
- Wang, Y.; Xiu, C.; Zhang, X.; Yang, D. WiFi indoor localization with CSI fingerprinting-based random forest. Sensors 2018, 18, 2869. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Gao, L.; Mao, S.; Pandey, S. CSI-based fingerprinting for indoor localization: A deep learning approach. IEEE Trans. Veh. Technol. 2016, 66, 763–776. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Zhang, Y.; Li, W.; Tao, X.; Zhang, P. ConFi: Convolutional neural networks based indoor Wi-Fi localization using channel state information. IEEE Access 2017, 5, 18066–18074. [Google Scholar] [CrossRef]
- Hsieh, C.H.; Chen, J.Y.; Nien, B.H. Deep learning-based indoor localization using received signal strength and channel state information. IEEE Access 2019, 7, 33256–33267. [Google Scholar] [CrossRef]
- Liu, W.; Chen, H.; Deng, Z.; Zheng, X.; Fu, X.; Cheng, Q. LC-DNN: Local connection based deep neural network for indoor localization with CSI. IEEE Access 2020, 8, 108720–108730. [Google Scholar] [CrossRef]
- Liu, W.; Cheng, Q.; Deng, Z.; Jia, M. C-GCN: A Flexible CSI Phase Feature Extraction Network for Error Suppression in Indoor Positioning. Entropy 2021, 23, 1004. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; OUP Oxford: Oxford, UK, 2017; pp. 5998–6008. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tang, G.; Müller, M.; Rios, A.; Sennrich, R. Why self-attention? A targeted evaluation of neural machine translation architectures. arXiv 2018, arXiv:1808.08946. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Value |
|---|---|
| batch size | 16 |
| learning rate | 0.0005 |
| nhead | 5 |
| loss function | Adam |
| initializer | Glorot initializer |
| MHSA Layers | MAE (m) | STD (m) |
|---|---|---|
| 1 | 1.49 | 1.63 |
| 2 | 1.15 | 1.37 |
| 3 | 0.71 | 0.83 |
| 4 | 0.72 | 0.92 |
| Fusion Method | MAE (m) | Parameters (m) |
|---|---|---|
| sum | 0.71 | 17 |
| concat | 0.82 | 19 |
| Method | Lab.mae (m) | Lab.std (m) | Com.mae (m) | Com.std (m) |
|---|---|---|---|---|
| 1dCNN-CSI | 0.98 | 1.21 | 1.28 | 1.45 |
| Confi | 1.02 | 1.18 | 1.19 | 1.28 |
| MHSA | 0.83 | 0.96 | 0.91 | 1.08 |
| MHSA-EC | 0.64 | 0.85 | 0.71 | 0.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Jia, M.; Deng, Z.; Qin, C. MHSA-EC: An Indoor Localization Algorithm Fusing the Multi-Head Self-Attention Mechanism and Effective CSI. Entropy 2022, 24, 599. https://doi.org/10.3390/e24050599
Liu W, Jia M, Deng Z, Qin C. MHSA-EC: An Indoor Localization Algorithm Fusing the Multi-Head Self-Attention Mechanism and Effective CSI. Entropy. 2022; 24(5):599. https://doi.org/10.3390/e24050599
Chicago/Turabian StyleLiu, Wen, Mingjie Jia, Zhongliang Deng, and Changyan Qin. 2022. "MHSA-EC: An Indoor Localization Algorithm Fusing the Multi-Head Self-Attention Mechanism and Effective CSI" Entropy 24, no. 5: 599. https://doi.org/10.3390/e24050599
APA StyleLiu, W., Jia, M., Deng, Z., & Qin, C. (2022). MHSA-EC: An Indoor Localization Algorithm Fusing the Multi-Head Self-Attention Mechanism and Effective CSI. Entropy, 24(5), 599. https://doi.org/10.3390/e24050599