1. Introduction
The dynamics of complex systems (complexity here refers to the notion used in physics and statistics, e.g., [
1,
2], not to other notions used, e.g., in design and manufacturing engineering [
3]) is of great interest in all natural sciences. The most influential contribution of statistical physics to this field is the
quantification beyond mere observation of the underlying mechanisms.
In particular, the effect of an external control parameter or an environmental factor on the internal dynamics reveals almost all technological exploitable insight for such a complex system. Examples range from the phenomenon of stochastic resonance and its applications [
4,
5,
6] to ecological systems described by the well-known Lotka–Volterra-type models [
7,
8].
Thus, we are left with the question of how to consistently, transferably quantify the change in the dynamical complexity upon an external perturbation in a conceptually sound manner. To this end, we herein propose an information-theoretic measure and show its applicability with three distinct examples: (a) a toy problem based on the logistic equation as a complex, but for our purposes controllable, model; (b) the evolutionary response of the HIV1 protease to drug treatment; and (c) the dynamics of foreign exchange rates.
2. Methods
The overall behavior of an observable can be well characterized by the (discretized) state variable. The different states can enumerated by , then the probability to observe the i-th value of the observable is . The overall distribution of all can then be written in vector-form .
Wootters, Crutchfield, and Young [
9,
10] argued that a system which is (a) completely random (
close to uniform) or (b) absolutely fixed (all but one
vanish) should not be regarded as “complex”. Thus, complexity occurs between those edge cases.
For discrete probabilities stored in , both edge cases are reflected in Shannon’s entropy : for (a) we have a (close to) maximal entropy for data discretized into N bins or states, while for (b) we find a vanishing one. Both cases reflect non-complex behavior: either (a) non-correlated randomness or (b) absolute predictability. Thus, complex behavior is to be expected only at intermediate entropy values.
Often,
H is normalized by its maximum
, so that
, where
N is the number of distinct states. (Note that the usage of Shannon’s entropy is related to the concept of “information content” in, e.g., [
3], Equations (5.5) and (5.5a)). In a subsequent study [
11], researchers developed the notation of Suh’s “information content” into an information-theory-based problem-solving methodology. The empirical counts
are used to obtain maximum-likelihood estimators of the respective
, where
is the number of all observations. Note that for “small”
L, we would need to include corrections to the Shannon entropy formula to account for small coverage [
12,
13,
14] for which efficient computational methods exist [
15]. In this study, we deal with a synthetic dataset and two real-life ones that are sufficiently large so that we can avoid this complication here.
Earlier ideas on how to improve upon Shannon’s entropy to assess complexity (and thus work in the “intermediate” regime between vanishing and maximal entropy) by Wootters [
9] were extended by several authors [
16,
17,
18,
19,
20] into measures of the general form
, where
is a distance between the realized dynamics giving rise to
in relation to a reference distribution
. The distribution
captures the dynamics of a system without the complex mechanism we are interested in. In all previous work [
9,
16,
18,
19,
20],
was set to the uniform distribution
. Then, the measure
M vanishes for completely random dynamics (
uniform, and thus
), as well as for constant values (
).
Below we will show that non-uniform distributions resulting from (reduced) complex dynamics are more informative to assess the response of a system to a perturbation or any change in its environment. Furthermore, the choice of D must not be ad hoc as in some of the previous work.
Note that an alternative approach to quantify the (stochastic) complexity of a system is based on using its Kolmogorov complexity [
21]. While conceptually sound, this approach suffers from the fact that the Kolmogorov complexity is not analytically computable in general [
22].
2.1. Complexity Change upon Perturbation
The well-known Kullback–Leibler divergence [
23] compares two distributions in an information theoretic sense:
and was used in, e.g., [
9] as the distance with respect to the uniform distribution
.
The inherent asymmetry renders the
itself a non-metric. However, it can be symmetrized and becomes the Jensen–Shannon divergence
Now,
was shown to fulfill all requirements of a metric [
24].
Then, with regard to the previously used uniform distribution, we would obtain
. In fact, this definition of stochastic complexity was already applied in quantitative finance [
25,
26] and general settings [
27] within the Martín–Plastino–Rosso (MPR) framework for stochastic complexity.
Our extension revolves around the question of the
change in complexity upon a perturbation rather than its absolute value itself. To compare two distinct scenarios—one before and one after an external perturbation—we compute the difference in those complexity values, where
is the distribution of an observable
X before and
after a perturbation:
In the subsequent parts, we will use and as well as and interchangeablely as X is our “reference” and Y our perturbed system. Note that we have replaced the uniform distribution put forward in previous work by the one of the unperturbed system. Therefore, we measure the complexity change upon perturbation by .
2.2. Datasets
In order to assess the performance of
, we chose two distinct scenarios. First, we use a synthetic, controllable toy model which consists of coupled logistic maps in the chaotic regime with
where
100,000 with the coupling
varying between 0 and
. This system allows for the continuous modulation of the dynamics of
by an external, independent dynamics, namely
. Note that
X shows the same statistical properties as the unperturbed
y-system. We can thus use
X in agreement with the nomenclature of the previous section.
Computation of (see below) was performed for the comparison of the distribution with both the uniform U and the actually realized distribution of . Note that in this case, the random variable serves two purposes at the same time: it is driving the perturbation to Y by the strength , while the distributions equal each other and thus can be regarded as the histogram of the unperturbed () dynamics of .
The second dataset consisted of protein sequences from the HIV protease (HIVP). This enzyme consists of 99 amino acids and is essential for the formation of functional HIV virions. It became one of the two major targets for drugs to treat AIDS. This dataset can be subdivided into sequences from patients treated and untreated by HIVP inhibitors. Then, we regard a treatment as a “perturbation” and we can gain insight into the reaction of the viral evolution to this evolutionary environmental change. Note that each of the 99 positions will be analyzed independently and regarded as a separated pair.
The high number of annotated sequences [
28] renders the HIVP an ideal area of application for
; furthermore, no multiple sequence alignment is necessary in this case—effectively avoiding poor signal-to-noise ratios (SNR), frequently encountered in biomolecular sequence studies [
29]. To increase the SNR further, all sequences with more than one position with multiple and non-canonic amino acids were removed due to unknown combinatorics. The resulting 53,793 sequences were then subdivided into a
treated (11,521 sequences) and
untreated dataset (42,272 sequences). We computed
between the distributions of
treated and
untreated sequences per position with the latter being the reference distribution. Note that for such a large dataset, we do not need to take into account finite-size corrections [
30] as put forward by, e.g., Grassberger [
13,
14].
As a third example, we investigate the complex dynamics of foreign exchange markets (under external perturbation). A prime example is the change of those rates for the British Pound with respect to other currencies; here the external perturbation is the referendum (on 23 June 2016) to leave the European Union and thus (prospectively) reduce the strength of economic coupling of the British economy with other European countries. As the Pound was never part of the Euro system, the change in dynamics is ceteris paribus only affected by the decision alone. To this end, we obtained the tick data for the whole year 2016 from histdata.com for the currency pairs GBP-EUR, GBP-USD, GBP-CHF, and GBP-JYP. We averaged bit and ask prices to obtain one time series.
3. Results
We applied our measure to the datasets described above in the dataset section.
3.1. Synthetic Data Set for Coupled Logistic Maps
Using the synthetic dataset of the toy model in Equation (
2), we illustrate the insight one might gain from
. Here, we discretized the continuous values simulated for the coupled map into 20 bins.
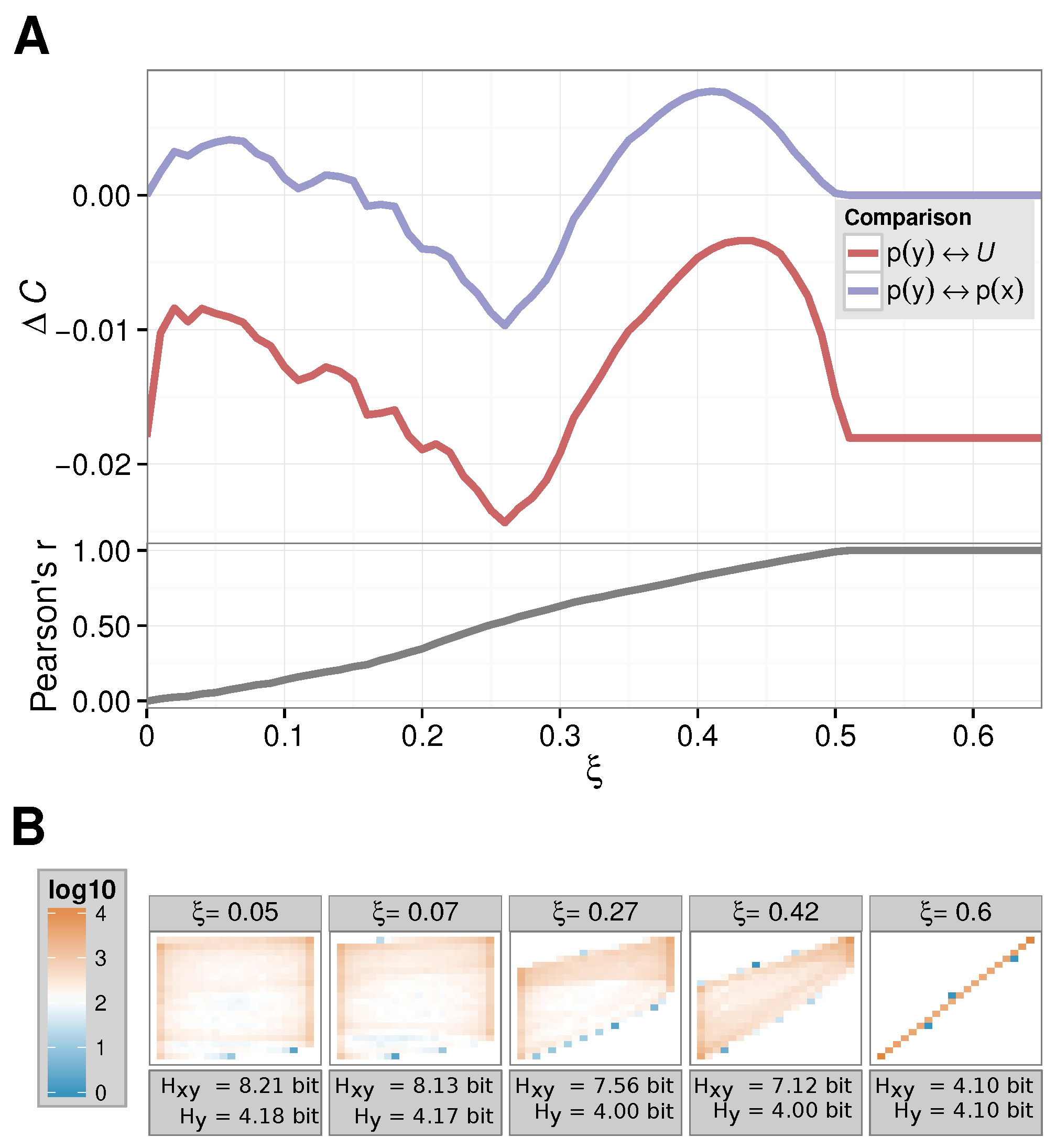
In
Figure 1, we show our results. First, we show how the complexity of the dynamics changes upon varying
with respect to the uniform distribution (we set
by hand, while recording the distribution
based on the simulated time series of Equation (
2), red line in
Figure 1A). We observe an undesirable effect: the
vanishes neither for
, nor for large(r)
. However, in those cases, the complexity change induced by the perturbation should be regarded as small: for
there is just no interaction, thus no change can occur. For large
, we can immediately conclude from Equation (
2) that the dynamics of
is actually equivalent to the one of
, so it is again the dynamics of one logistic equation. This is due to the fact that perfect synchronization between the two processes occurs only at intermediate coupling strengths, as Sun et al. [
31] already discussed. This argument is further strengthened by the Pearson correlation coefficient between
and
that we also show in
Figure 1A: for
the time series correlated perfectly; namely, they are the same. This can also be seen in the two-dimensional histogram of
value pairs for
recorded for
Figure 1B.
In
Figure 1A, we also show the
values computed as above (blue line). First we note that the sensible results for
and
eventually are produced.
actually vanishes at precisely
, at which
and
are synchronized.
Furthermore, we observe that Shannon’s entropy of the observable alone does not allow for any insight into the complexity (change) of the dynamics of as it remains within an error margin for varying . Furthermore, note that Shannon’s entropy for the two-dimensional histogram continuously decreases for larger couplings as the distributions become more and more spiked.
In addition, our
shows a “direction” in the sense that an increase in complexity (or a reduction) can be detected. For
, one can, e.g., clearly observe a stronger connection between
X and
Y in the
of
Figure 1A; thus, a reduction in the complexity –
dominates the first factor in Equation (
1). At
and
, we found the exact opposite: here, the entropy of
reaches a comparable low value and thus influences the
accordingly.
Note that for other information theoretic measures such as the mutual information , we obtain less sensible results. For this measure, we have bit=const for all . We then would obtain a monotonously increasing MI running in analogy to Pearson’s correlation coefficient.
3.2. Complexity within HIVP
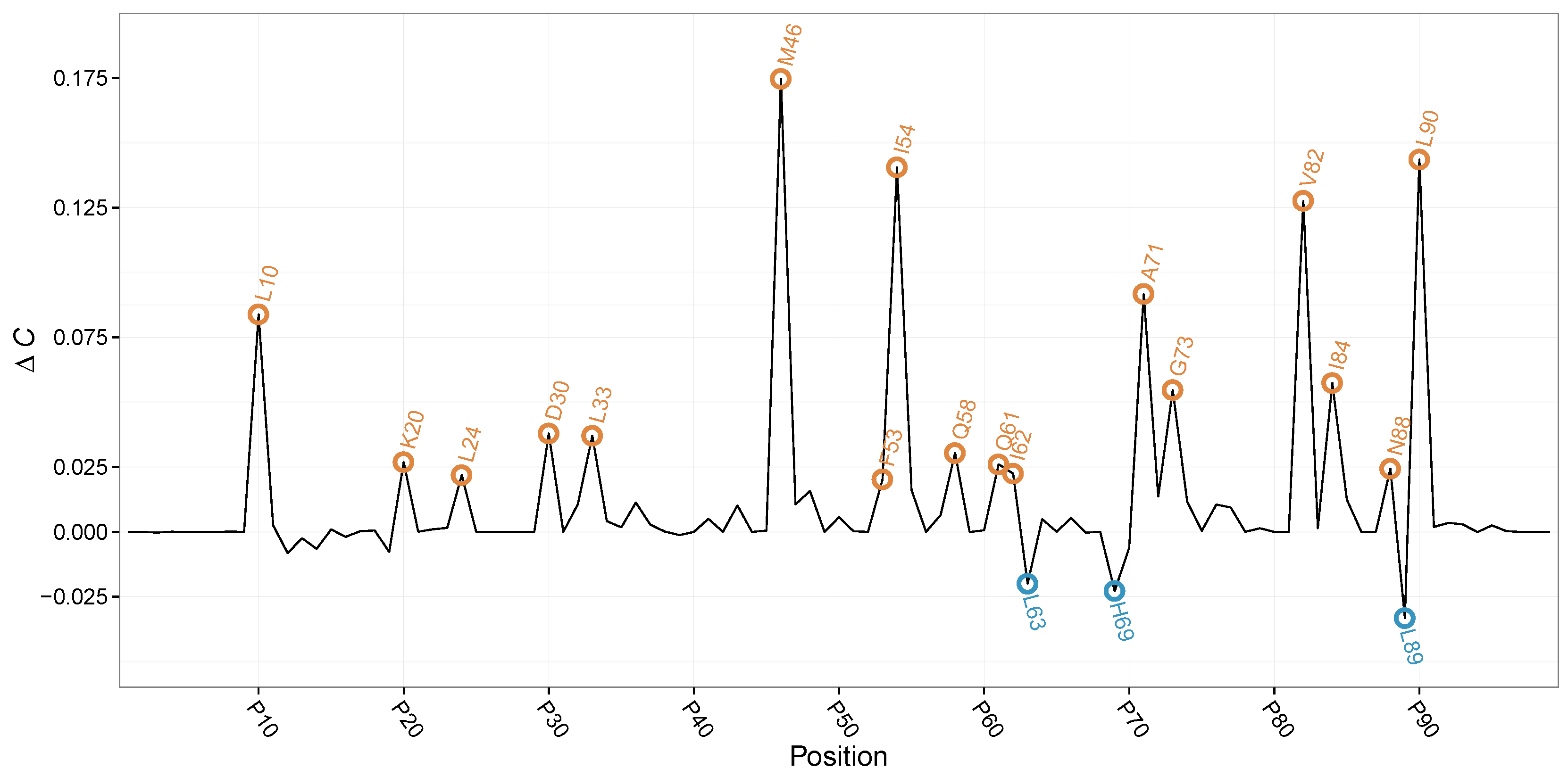
We proceeded to apply to each position in the HIVP sequences described above. For each position, we can therefore quantitatively assess the evolutionary impact of drug treatment. Here, we built histograms as counts for each of the 20 naturally occurring amino acid types. X then are the (amino acid) outcomes for the untreated patient dataset, while Y are the ones for the treated patients for which the viral evolution is under-perturbed selective pressure.
By
, we were able to identify previously reported compensatory mutation by setting a threshold at
. Here, two different groups of
can be observed as
can be either positive or negative in value (see
Figure 2). Hence,
allows us not only to annotate position in HIVP where the amino acid distributions between
treated and
untreated differ, but also allows us to annotate the direction in change of evolutionary complexity.
For positive
, we find positions 10, 20, 24, 30, 33, 46, 53, 54, 58, 62, 71, 73, 82, 84, 88, and 89. Earlier studies revealed a reduced susceptibility to protease inhibitors at these positions [
32,
33] (see
Table 1). Only position 61 has yet to be reported as compensatory mutation upon protease inhibitor administration. For the aforementioned position, we observe a positive
, resulting in increased evolutionary complexity upon protease inhibitor treatment. Here, HIVP increases the amino acid diversity to compensate the drug-induced evolutionary pressure. Interestingly, we observe increased frequencies of smaller, polar amino acids at position 61 upon drug treatment, indicating a potentially not documented compensatory effect.
For the second group of
, positions with a negative
, we obtain positions 63, 69, and 89, with all three reported earlier to be affected by drug treatment [
33]. The negative
at these sites points to a reduction in position-wise evolutionary complexity upon treatment with protease inhibitors, indicating ideal targets for further combination therapy.
3.3. Foreign Exchange Rates under Perturbation
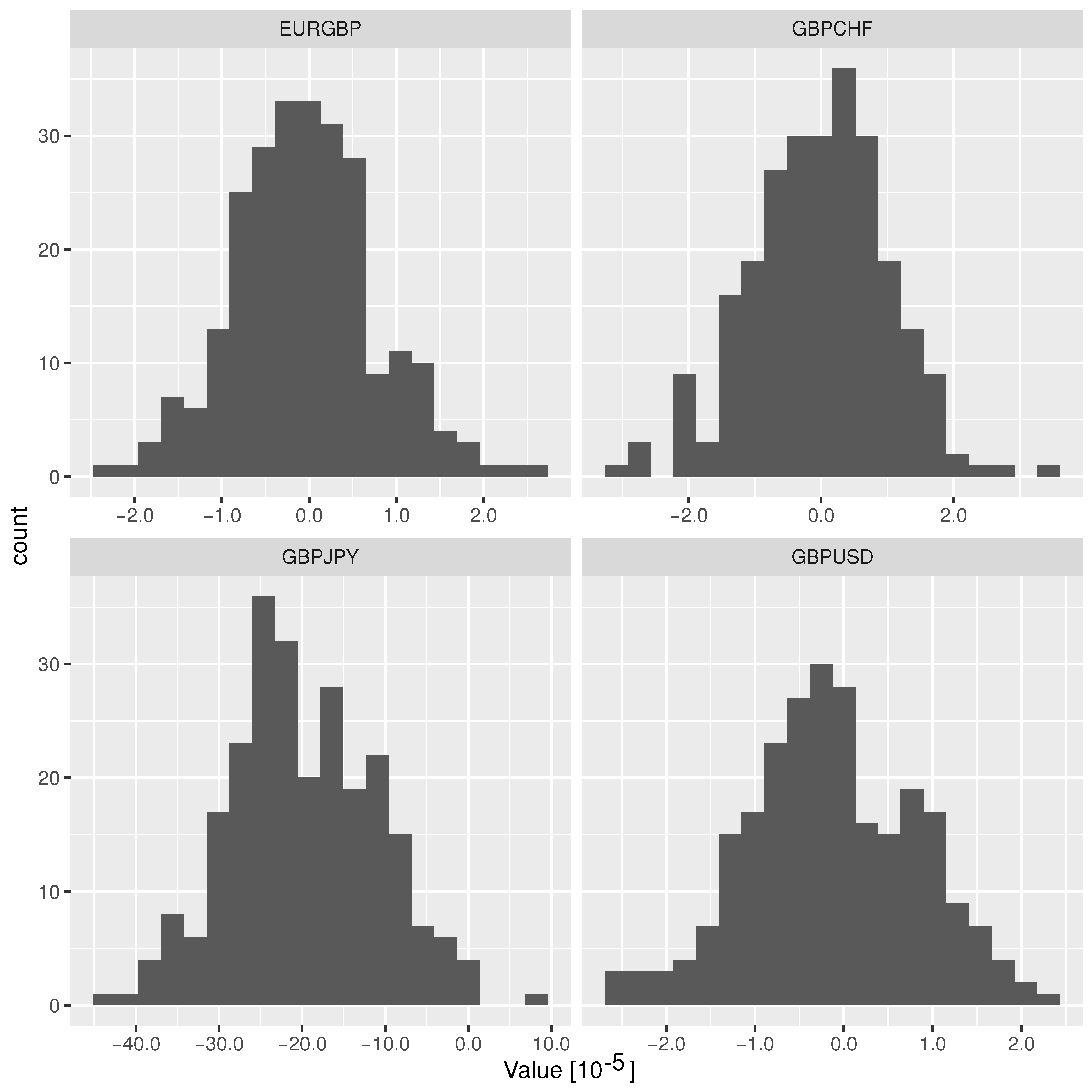
As described above, we used the foreign exchange rate of the pound sterling to other major currencies and obtained the differences of our complexity measure before and after the Brexit referendum. As mentioned above, we used the average of bid and ask prices. We downloaded the tick data for the year 2016 from histdata.com and thus have market data roughly from half a year before and half a year after the referendum (the Brexit referendum was held on 23 June 2016). We binned the rates, following standard procedure, into basis points (bps).
In
Table 2, we summarize the findings. To assess the statistical relevance of the
values in
Table 2, we additionally applied a resampling technique. We sampled 250 replicas of the original data into random temporal order, extracting the same number of data points as in the original dataset for the sets of exchange rates before and after the referendum. Then, we computed the
values for these as an in-sample estimator of the
values regardless of intervention or external perturbation. The resulting histograms are shown in
Figure 3. This allows us to judge the original values with respect to an ensemble that contains no signature of the referendum in the spirit of similar approaches to resampling [
34,
35,
36]. To this end, for each currency pair we computed the
Z-value under resampling, where
with
and
being the mean and the standard deviation over the 250 samples for each currency pair.
Under a two-sided test—the question being whether the
values for the raw data are outliers to the resampled ones—all currency pairs show a significant signal. This can already be seen from the standard deviation of the resampled data in
Figure 3, which turns out to be of the order
to
.
Our results suggest a complex scenario that economically makes sense. In particular, the foreseeable to-be-expected de-coupling of the United Kingdom’s economy from the one of the EU strengthens the independence towards the Euro (positive entropy difference in Equation (
1)) which can be seen in the positive
of
Table 2. The US Dollar and the Euro (as the two major currencies) are tightly coupled, so that the positive
for the Pound–Dollar exchange rate might be an indirect effect due to overall Euro influence. Furthermore, the negative
values for GBP-CHF and GBP-JPY are the flip side of the same coin: while the complexity of the GBP-EUR and GBP-USD dynamics was somewhat related and became less tightly coupled after the referendum, it is a logical necessity that the GBP-
xyz (where
xyz stand for any other economic entity) dynamics get closer (negative
) to each other.
4. Discussion
In this study, we have derived an information theoretic measure
to quantitatively assess the impact of an external perturbation on the complexity of a dynamical system. Starting from previous work, such as the MPR framework [
19,
27], we derived this measure based on a set of requirements.
For a controllable toy system, we showed that fulfills the requirements and delivers reasonable results.
In a real application, we assessed the viral evolution of the HIV1 protease under the influence of drug treatment targeting this particular enzyme. Our measures identified—purely based on the biomolecular sequences—those positions that were identified in expansive experiments as the ones to which the particular drugs bind. Interestingly, we can also extract signals on the type of drug used in any treatment.
Furthermore, our measure was able to show the impact on economic time series (foreign exchange rates) upon stress (Brexit referendum).
We note in passing that the qualitative results of our analysis were the same for both and , non-surprisingly due to the monotonicity of the square root.





{kind=link}
{kind=link}
{kind=link}