As a general treatment, the curved exponential families, which encapsulate many important distributions for real-world problems, are considered as the statistical model for the hypothesis testing problems discussed in this paper. In this section, the MLE solution to parameter estimation for curved exponential families is derived. We then present two pictures of the GLRT, which are sketched based on the geometric structure of the curved exponential families developed by Efron [
8] in 1975 and Amari [
9] in 1982, to illustrate the information geometry of the GLRT. An example of the GLRT for a curved Gaussian distribution with a single unknown parameter is given, which is followed by a further discussion on the geometric formulation of the GLRT.
4.1. The MLE Solution to Statistical Estimation for Curved Exponential Families
Exponential families contain lots of the most commonly used distributions, including the normal, exponential, Gamma, Beta, Poisson, Bernoulli, and so on [
21]. The curved exponential families are the distributions whose natural parameters are nonlinear functions of “local” parameters. The canonical form of a curved exponential family [
9] is expressed as
where
is a vector of samples,
are the natural parameters,
are local parameters standing for the parameters of interest to be estimated, which is specified by (
9), while
denote sufficient statistics with respect to
, which take values from the sample space
X.
is the potential function of the curved exponential family and it is found from the normalization condition
, i.e.,
The term “curved” is due to the fact that the curved exponential family in (
9) is a submanifold of the canonical exponential family
by the embedding
.
Let
be the log-likelihood and
be the Jacobian matrix of the natural parameter
. According to (
9),
where
is the expectation of the sufficient statistics
, i.e.,
and is called the expectation parameter, which defines a distribution of mixture family [
4]. The natural parameter
and expectation parameter
are connected by the Legendre transformation [
9], as
where
is defined by
Therefore,
Thus, the maximum likelihood estimator
of the local parameter in (
9) can be obtained by the following likelihood equation:
Equation (
16) indicates that the solution to the MLE can be found by mapping the data
onto
orthogonally to the tangent of
. As
and
live in two different spaces
and
, the inner product between dual spaces is defined as
with a metric
. For the flat manifold, the identity matrix serves as the metric
. By analogy with the MLE for the universal distribution given by (
5), Hoeffding [
14] presented another interpretation for the MLE of the curved exponential family. In the interpretation,
represents a point in
which is located closest to the data point in the sense of the Kullback–Leibler divergence, i.e.,
where
denotes the Kullback–Leibler divergence from the multivariate joint distributions of
to
.
Based on the above analysis, there are two important spaces related to a curved exponential family. One is called the natural parameter space, denoted by
, which denotes the enveloping space including all the distributions of exponential families, and the other is called the expectation parameter space, denoted by
, denoting the dual space of
. The two spaces are “dual” with each other and flat under the
e-connection and
m-connection, respectively. The curved exponential family (
9) is regarded as submanifolds embedded in the two spaces, and the data can also be immersed in these spaces in the form of sufficient statistics
. Consequently, the estimators, such as the MLE given by (
16), associated with the curved exponential families can be geometrically performed in the two spaces.
4.2. Geometric Demonstration of the Generalized Likelihood Ratio Test
As mentioned earlier, the GLRT is one of the most widely used approaches in composite hypothesis testing problems with unknown parameters in the PDFs. The data
have the PDF
under hypothesis
and
under hypothesis
, where
and
are unknown parameters under each hypothesis. The GLRT enables a decision by means of replacement of the unknown parameters by their maximum likelihood estimates (MLEs) to implement a likelihood ratio test. The GLRT decides
if
where
is the MLE of
(by maximizing
).
From the perspective of information geometry, the probability distribution is an element of the parameterized family of PDFs , where is the parameter set. For the curved exponential family , it can be regarded as a submanifold embedding in the natural parameter space , which includes all the distributions of exponential families. The curved exponential family S can be represented by a curve (or surface) embedded in the enveloping space by the nonlinear mapping . The expectation parameter space of S is a dual flat space to the natural parameter space , while the “realizations” of sufficient statistics of the distribution can be immersed in this space. Consequently, the MLE is performed in the space by mapping the samples onto the submanifold specified by under the m-projection.
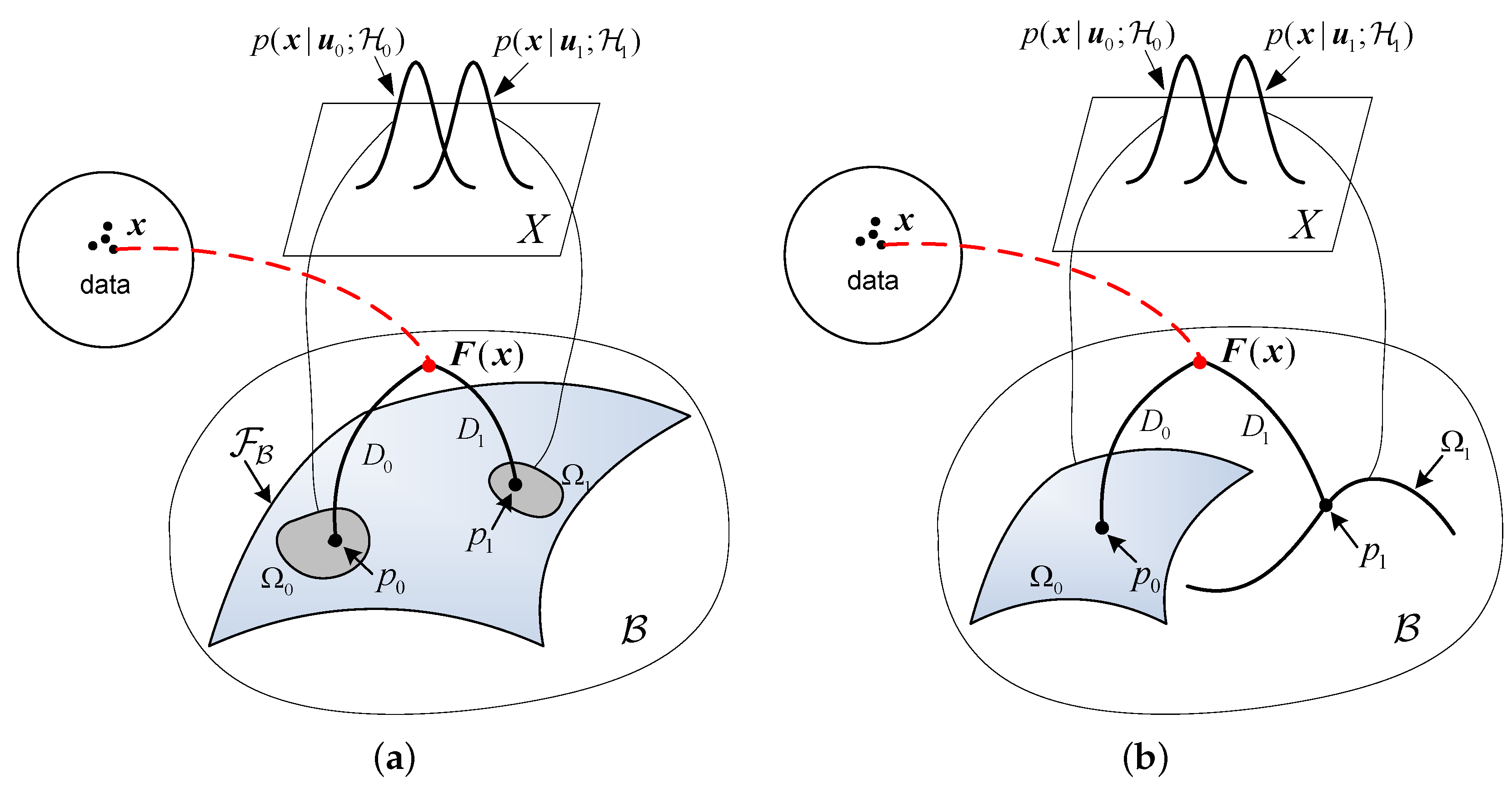
As the parameters
and
, as well as their dimensionalities, may or may not be the same under the null and alternative hypotheses, two pictures of the GLRT are presented for the two cases: one is with the same unknown parameters under each hypotheses and the other is with different parameters or different dimensionalities. The picture for the first case is illustrated in
Figure 2a. In this case, distributions under two hypotheses share the same form and the same unknown parameter
. However, the parameter takes different value sets under different hypotheses. The family of
can be smoothly embedded as a surface
specified by
in the space
. The hypotheses
with unknown
define two “uncertainty volumes”
and
on the submanifold
. These volumes are the collections of probability distributions specified by the value sets of the unknown parameter
. The measurements
are immersed in
in the form of sufficient statistics
. Consequently, the MLE can be found by “mapping” the samples
onto the uncertainty volumes
and
on
. The points
and
in
Figure 2 are the corresponding projections, i.e., the MLEs of the unknown parameter under two hypotheses. As indicated in (
17), the MLEs can also be obtained by finding the points on
and
which are located closest to the data point in the sense of KLD, i.e.,
and the corresponding minimum KLDs can be represented by
respectively.
It should be emphasized that the above “mapping” is a general concept. When the parameters to be estimated are not restricted by a given “value set”, the MLE is simply obtained by maximizing the likelihood and the projections will fall onto the submanifold
. However, if the parameters to be estimated are restricted in a given “value set”, the MLE should be operated by maximizing the likelihood with respect to the given parameter space. In the case where the projections fall outside the “uncertainty volumes”, the MLE solutions are given by those points which are closest to the data point described by (
19).
Let
be a
divergence sphere centered at
with radius
; that is, the submanifold of the enveloping space
consisting of points
for which the KLD
is equal to
. Denote this divergence sphere by
Then, the closest point in (
19) may be more easily found via the divergence sphere with center
and radius
tangent to
at
, as illustrated in
Figure 3. Consequently, according to (
2), the GLRT can be geometrically performed by comparing the difference between the minimum KLDs
and
with a threshold
, i.e.,
In practice, the Neyman–Pearson criterion is commonly employed to determine the threshold
in (
22) and the detector is of maximum probability of detection
under a given probability of false alarm
. As a commonly used performance index, the missingprobability
usually decays exponentially as the sample size increases. The rate of exponential decay can be represented by [
22], as
Based on Stein’s lemma, for a constant false-alarm constraint, the best error exponent is related to the Kullback–Leibler divergence
from
to
[
23], i.e.,
and
where ≐ denotes the first-order equivalence in the exponent. For example,
In the above sense, the KLD from to is equivalent to the signal-to-noise ratio (SNR) of the underlying detection problem. Therefore, information geometry offers an insightful geometrical explanation for the detection performance of a Neyman–Pearson detector.
In the second case, the dimensionality of the unknown parameters
and
is different, while the dimensionality of the enveloping spaces is common for both hypotheses due to the same measurements
. However, the hypotheses may correspond to two separated submanifolds,
and
, embedded in
caused by the different dimensionality between the unknown parameters. As illustrated in
Figure 2b, a surface and a curve are used to denote the submanifolds
and
, corresponding to the two hypotheses, respectively. Similar to the first case, the GLRT with different unknown parameters may also be geometrically interpreted.
4.3. A Demonstration of One-Dimensional Curved Gaussian Distribution
Consider the following detection problem:
The measurement originates from a curved Gaussian distribution
where
a is a positive constant and
u is an unknown parameter.
The probability density function of the measurement is
By reparameterization, the probability density function can be represented in the general form of a curved exponential family as
where
and the potential function
is
The above distributions with local parameter
u correspond to a one-dimensional curved exponential family embedded in the natural parameter space
. The natural coordinates are
which defines a parabola (denoted by
)
in
. The underlying distribution (
28) can also be represented in the expectation parameter space
with expectation coordinates
which also defines a parabola (denoted by
)
in
.
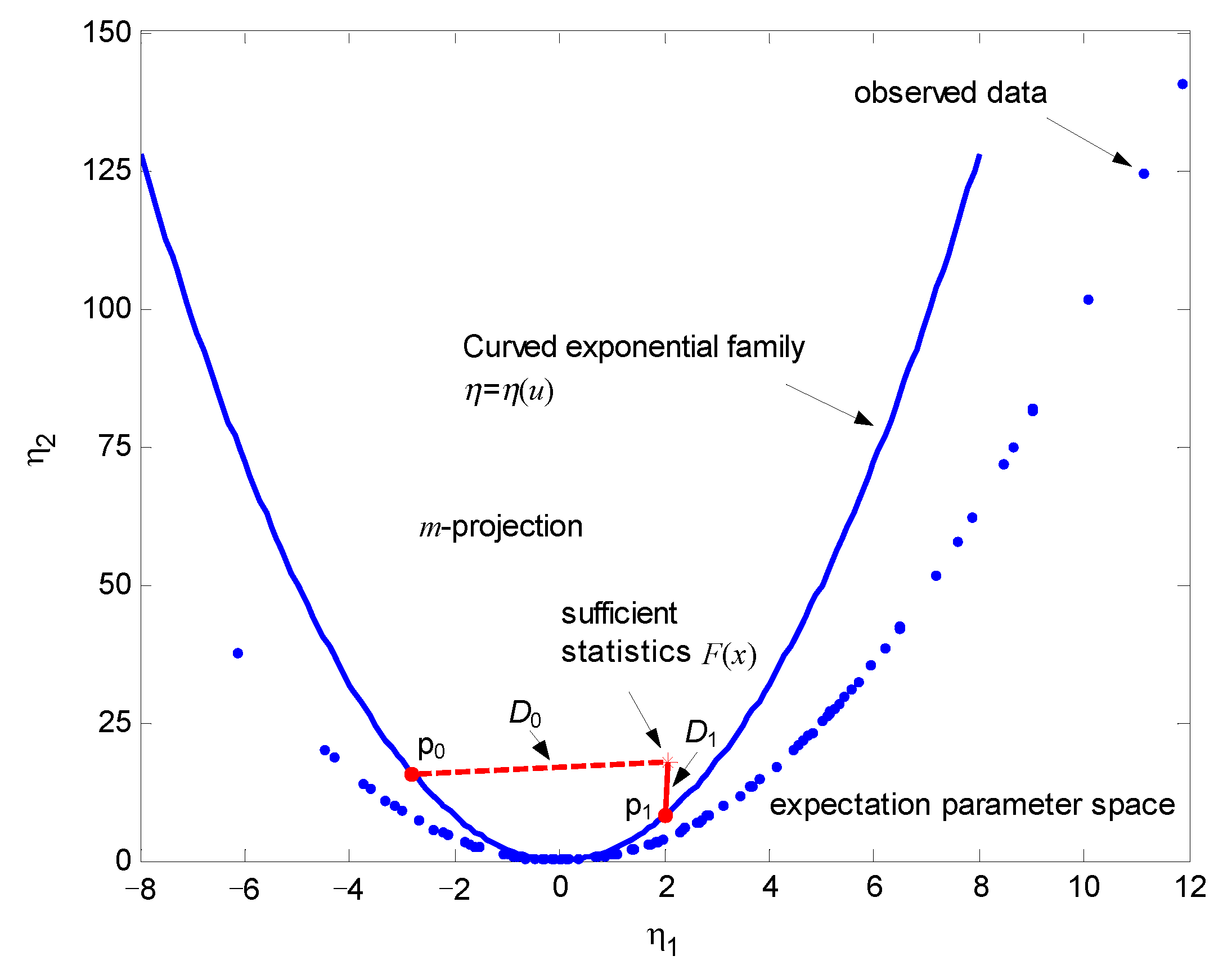
The sufficient statistics
obtained from samples x can be represented by
Figure 4 shows the expectation parameter space and illustrates geometric interpretation of the underlying GLRT, where the blue parabola in the figure denotes embedding of the curved Gaussian distribution with parameter
u. The submanifolds associated with two hypotheses can be geometrically represented by the blue parabolas (specified by
and
, respectively). Without loss of generality, assume that
. The blue dots signify
observations (measurements) in the expectation parameter space with the coordinates
. The statistical mean of the measurements are used to calculate the sufficient statistics
which are denoted by a red asterisk. The MLEs of parameter
u under two hypotheses are obtained by finding the points on the two submanifolds which are closest to the data point in the sense of KLD. According to (
22), the GLRT can be geometrically performed by comparing the difference between the minimum KLDs
and
with a threshold
.
4.4. Discussions
The geometric formulation of the GLRT presented above provides additional insights into the GLRT. To the best of our knowledge, there is no general analytical result associated with the performance of the GLRT in the literature [
1]. The asymptotic analysis is only valid under the conditions that (1) the data sample size is large; and (2) the MLE asymptotically attains the Cramér-Rao lower bound (CRLB) of the underlying estimation problems.
It is known that the MLE with natural parameters is a sufficient statistic for an exponential family, and achieves the CRLB if a suitable measurement function is chosen for the estimation [
8]. For the curved exponential families the MLE is not, in general, an efficient estimator, which means that the variance of MLE may not achieve CRLB with a finite number of samples. This indicates that when using a finite number of samples there will be a deterioration in performance for both MLE and GLRT when the underlying statistical model is a curved exponential family. There will be an inherent information loss (compared with the Fisher information) when implementingan estimation process if the statistical model is of nonlinearity. Roughly speaking, if the embedded submanifold
in
Figure 2a and
,
in
Figure 2b are curved, the MLEs will not achieve the CRLB due to the inherent information loss caused by the non-flatness of the statistical model. The information loss may be quantitatively calculated using the
e-curvature of the statistical model [
9].
Consequently, if the statistical model associated with a GLRT is not flat, i.e., the submanifolds shown in
Figure 2 are curved, there will be a deterioration in performance for the GLRT using a finite number of samples. As sample size
N increases, the sufficient statistics
will be better matched to the statistical model and thus closer to the submanifolds (see
Figure 2), and the divergence from data to the submanifold associated with the true hypothesis
will be shorter. Asymptotically, as
, the sufficient statistics will fall onto the submanifold associated with the true hypothesis
, so that the corresponding divergence
reduces to zero. By then, the GLRT achieves a perfect performance.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



