
Lossless Image Steganography Based on Invertible Neural Networks

Abstract
1. Introduction
2. Related Work
2.1. Steganography
2.2. Invertible Neural Networks
3. Methods
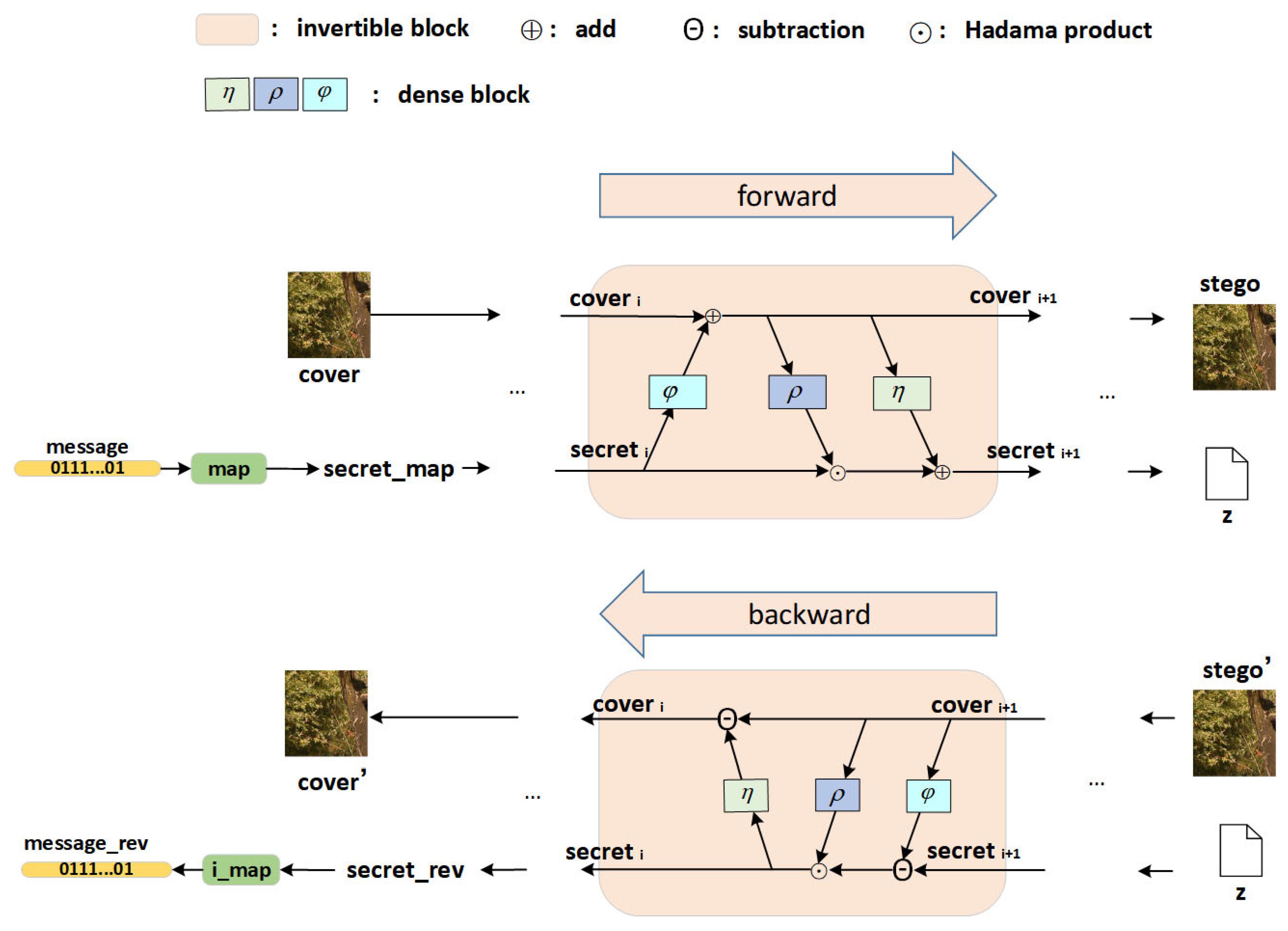
3.1. Overview
3.2. Network Architecture
| Algorithm 1: Mapping module map |
| Input: message Output: secret_map Initialization t = 0.25; turn = false; If(sum(message) > len(message)/2) then secret_map = message < t turn = True else secret_map = message end if secret_map = secret_map/2 |
| Algorithm 2: Inverse mapping module i_map |
| Input: secret_rev Output: message_rev If(turn) then message_rev = secret_rev < t else message_rev = secret_rev >= t end if |
3.3. Loss Function
4. Experiments
4.1. Experimental Settings
4.2. Comparison
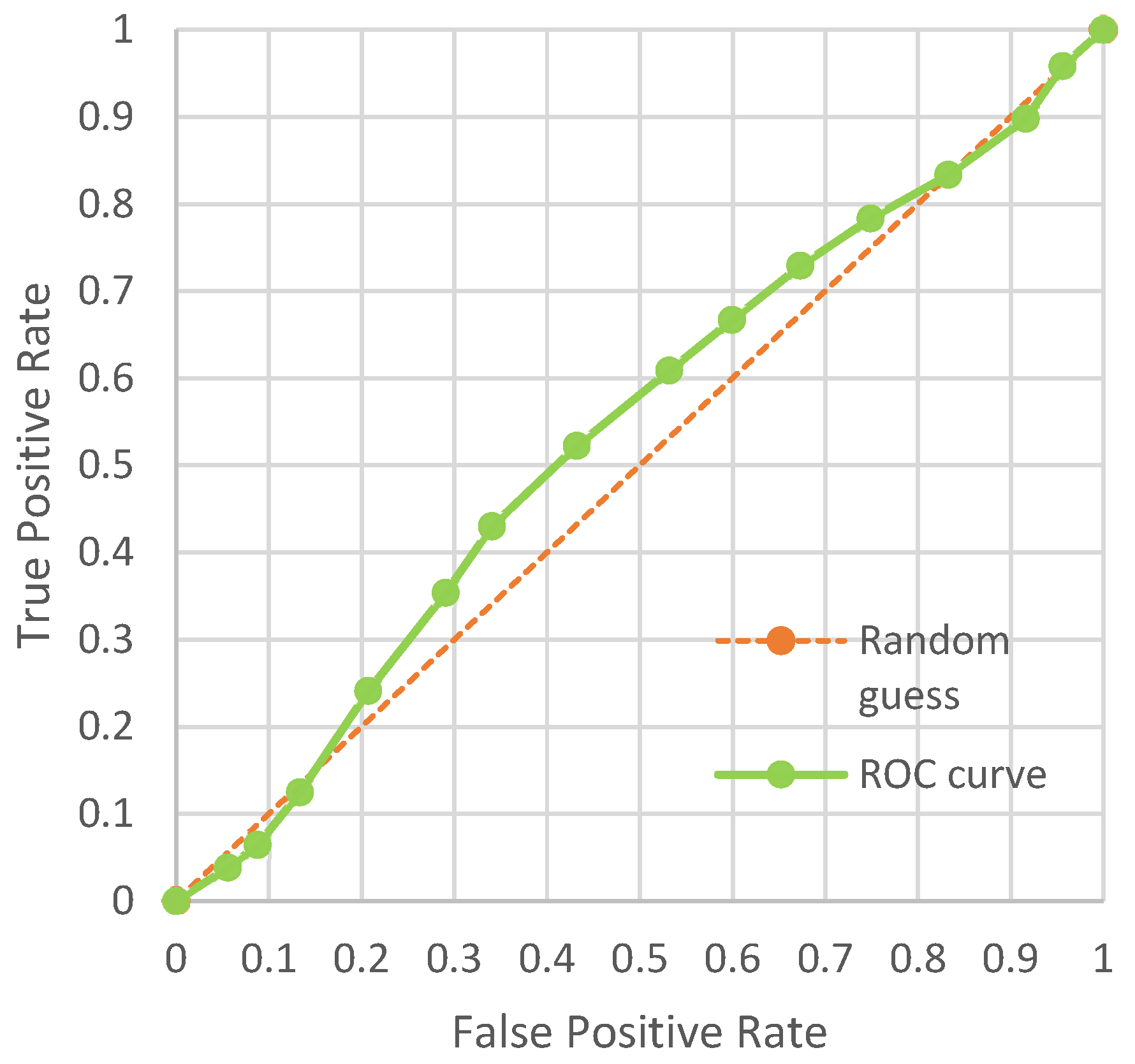
4.3. Steganalysis
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Subramanian, N.; Elharrouss, O.; Al-Maadeed, S.; Bouridane, A. Image Steganography: A Review of the Recent Advances. IEEE Access 2021, 9, 23409–23423. [Google Scholar] [CrossRef]
- Cheddad, A.; Condell, J.; Curran, K.; Mc Kevitt, P. Digital image steganography: Survey and analysis of current methods. Signal Process. 2010, 90, 727–752. [Google Scholar] [CrossRef]
- Saravanan, M.; Priya, A. An Algorithm for Security Enhancement in Image Transmission Using Steganography. J. Inst. Electron. Comput. 2019, 1, 1–8. [Google Scholar] [CrossRef]
- Tamimi, A.A.; Abdalla, A.M.; Al-Allaf, O. Hiding an image inside another image using variable-rate steganography. Int. J. Adv. Comput. Sci. Appl. 2013, 4, 18–21. [Google Scholar]
- Asad, M.; Gilani, J.; Khalid, A. An enhanced least significant bit modification technique for audio steganography. In Proceedings of the International Conference on Computer Networks and Information Technology, Abbottabad, Pakistan, 11–13 July 2011. [Google Scholar]
- Kumar, V.; Kumar, D. A modified DWT-based image steganography technique. Multimed. Tools Appl. 2017, 77, 13279–13308. [Google Scholar] [CrossRef]
- Hassaballah, M.; Hameed, M.A.; Awad, A.I.; Muhammad, K. A Novel Image Steganography Method for Industrial Internet of Things Security. IEEE Trans. Ind. Inform. 2021, 17, 7743–7751. [Google Scholar] [CrossRef]
- Zhu, Z.; Zheng, N.; Qiao, T.; Xu, M. Robust Steganography by Modifying Sign of DCT Coefficients. IEEE Access 2019, 7, 168613–168628. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 1, 1. [Google Scholar] [CrossRef]
- Jung, S.W.; Ko, S.J. A New Histogram Modification Based Reversible Data Hiding Algorithm Considering the Human Visual System. IEEE Signal Process. Lett. 2010, 18, 95–98. [Google Scholar] [CrossRef]
- Nagarju, P.; Naskar, R.; Chakraborty, R.S. Improved histogram bin shifting based reversible watermarking. In Proceedings of the International Conference on Intelligent Systems and Signal Processing (ISSP), Vallabh Vidyanagar, India, 1–2 March 2013. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Krogh, A. What are artificial neural networks. Nat. Biotechnol. 2008, 26, 195–197. [Google Scholar] [CrossRef] [PubMed]
- Hopfield, J.J. Artificial neural networks. IEEE Circuits Devices Mag. 1988, 4, 3–10. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.H.; Zhou, J. A survey of convolutional neural networks: Analysis, applications and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Baluja, S. Hiding images in plain sight: Deep steganography. In Advances in Neural Information Processing Systems; Guyon, I., Von Luxburg, U., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 3, pp. 2069–2079. [Google Scholar]
- Baluja, S. Hiding images within images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1685–1697. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Zhang, R.; Dong, S.; Liu, J. Invisible steganography via generative adversarial networks. Multimed. Tools Appl. 2019, 78, 8559–8575. [Google Scholar] [CrossRef]
- Liu, J.; Ke, Y.; Zhang, Z.; Lei, Y.; Li, J.; Zhang, M.; Yang, X. Recent Advances of Image Steganography with Generative Adversarial Networks. IEEE Access 2020, 8, 60575–60597. [Google Scholar] [CrossRef]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei-Fei, L. Hidden: Hiding data with deep networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, F.; Yu, Z.; Qin, C. GAN-based spatial image steganography with cross feedback mechanism. Signal Process. 2022, 190, 108341. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ahmadi, M.; Norouzi, A.; Karimi, N.; Samavi, S.; Emami, A. Redmark: Framework for Residual Diffusion Watermarking Based on Deep Networks. Expert Syst. Appl. 2020, 146, 113157. [Google Scholar] [CrossRef]
- Liu, Q.; Xiang, X.; Qin, J.; Tan, Y.; Qiu, Y. Coverless image steganography based on DenseNet feature mapping. EURASIP J. Image Video Process. 2020, 1, 39. [Google Scholar] [CrossRef]
- Luo, Y.; Qin, J.; Xiang, X.; Tan, Y. Coverless Image Steganography Based on Multi-Object Recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2779–2791. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, Z.; Qiu, A.; Xia, Z.; Xiong, N. Novel Coverless Steganography Method Based on Image Selection and StarGAN. IEEE Trans. Netw. Sci. Eng. 2022, 9, 219–230. [Google Scholar] [CrossRef]
- Zhou, Z.; Mu, Y.; Wu, Q.M. Coverless image steganography using partial-duplicate image retrieval. Soft Comput. 2019, 23, 4927–4938. [Google Scholar] [CrossRef]
- Hu, D.; Wang, L.; Jiang, W.; Zheng, S.; Li, B. A Novel Image Steganography Method via Deep Convolutional Generative Adversarial Networks. IEEE Access 2018, 6, 38303–38314. [Google Scholar] [CrossRef]
- Yu, C.; Hu, D.; Zheng, S.; Jiang, W.; Li, M.; Zhao, Z.Q. An improved steganography without embedding based on attention GAN. Peer-Peer Netw. Appl. 2021, 14, 1446–1457. [Google Scholar] [CrossRef]
- Emad, E.; Safey, A.; Refaat, A.; Osama, Z.; Sayed, E.; Mohamed, E. A secure image steganography algorithm based on least significant bit and integer wavelet transform. J. Syst. Eng. Electron. 2018, 29, 639–649. [Google Scholar]
- Chan, C.K.; Cheng, L.M. Hiding data in images by simple LSB substitution. Pattern Recognit. 2004, 37, 469–474. [Google Scholar] [CrossRef]
- Karampidis, K.; Kavallieratou, E.; Papadourakis, G. A review of image steganalysis techniques for digital forensics. J. Inf. Secur. Appl. 2018, 40, 217–235. [Google Scholar] [CrossRef]
- Zhang, X.; Peng, F.; Long, M. Robust Coverless Image Steganography Based on DCT and LDA Topic Classification. IEEE Trans. Multimed. 2018, 20, 3223–3238. [Google Scholar] [CrossRef]
- Hu, X.; Ni, J.; Shi, Y.Q. Efficient JPEG Steganography Using Domain Transformation of Embedding Entropy. IEEE Signal Process. Lett. 2018, 25, 773–777. [Google Scholar] [CrossRef]
- Xiong, L.; Xu, Z.; Shi, Y.Q. An integer wavelet transform based scheme for reversible data hiding in encrypted images. Multidimens. Syst. Signal Process. 2018, 29, 1191–1202. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Y.; Du, J.; Liao, S.; Lou, J.; Zou, B. Robust hybrid image watermarking scheme based on KAZE features and IWT-SVD. Multimed. Tools Appl. 2019, 78, 6355–6384. [Google Scholar] [CrossRef]
- Liao, X.; Yin, J.; Chen, M.; Qin, Z. Adaptive Payload Distribution in Multiple Images Steganography Based on Image Texture Features. IEEE Trans. Dependable Secur. Comput. 2022, 19, 897–911. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Costa Adeje, Spain, 2–5 December 2012. [Google Scholar]
- Li, B.; Wang, M.; Huang, J.; Li, X. A new cost function for spatial image steganography. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014. [Google Scholar]
- Pevný, T.; Filler, T.; Bas, P. Using High-Dimensional Image Models to Perform Highly Undetectable Steganography. In Proceedings of the International Workshop on Information Hiding, Calgary, AB, Canada, 28–30 June 2010. [Google Scholar]
- Rehman, A.U.; Rahim, R.; Nadeem, S.; Hussain, S.U. End-to-end trained CNN encoder-decoder networks for image steganography. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hayes, J.; Danezis, G. Generating steganographic images via adversarial training. In Advances in Neural Information Processing Systems; Guyon, I., Von Luxburg, U., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 3, pp. 1954–1963. [Google Scholar]
- Tang, W.; Li, B.; Tan, S.; Barni, M.; Huang, J. CNN-based adversarial embedding for image steganography. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2074–2087. [Google Scholar] [CrossRef]
- Yang, J.; Ruan, D.; Huang, J.; Kang, X.; Shi, Y.Q. An Embedding Cost Learning Framework Using GAN. IEEE Trans. Inf. Forensics Secur. 2019, 15, 839–851. [Google Scholar] [CrossRef]
- Liao, X.; Yu, Y.; Li, B.; Li, Z.; Qin, Z. A New Payload Partition Strategy in Color Image Steganography. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 685–696. [Google Scholar] [CrossRef]
- Dinh, L.; Krueger, D.; Bengio, Y. Nice: Non-linear independent components estimation. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density Estimation Using Real NVP. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1 × 1 convolutions. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018. [Google Scholar]
- Xu, Y.; Mou, C.; Hu, Y.; Xie, J.; Zhang, J. Robust Invertible Image Steganography. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Jing, J.; Deng, X.; Xu, M.; Wang, J.; Guan, Z. HiNet: Deep Image Hiding by Invertible Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Lu, S.P.; Wang, R.; Zhong, T.; Rosin, P.L. Large-Capacity Image Steganography Based on Invertible Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Guan, Z.; Jing, J.; Deng, X.; Xu, M.; Jiang, L.; Zhang, Z.; Li, Y. DeepMIH: Deep Invertible Network for Multiple Image Hiding. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 372–390. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, J. Invertible Resampling-Based Layered Image Compression. In Proceedings of the Data Compression Conference (DCC), Data Compression Conference, 23–26 March 2021. [Google Scholar]
- Pan, Z. Learning Adjustable Image Rescaling with Joint Optimization of Perception and Distortion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar]
- Xiao, M.; Zheng, S.; Liu, C.; Wang, Y.; He, D.; Ke, G.; Liu, T.Y. Invertible image rescaling. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Van der Ouderaa, T.F.; Worrall, D.E. Reversible gans for memory efficient image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhu, X.; Li, Z.; Zhang, X.Y.; Li, C.; Liu, Y.; Xue, Z. Residual invertible spatio-temporal network for video super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European conference on computer vision (ECCV), Zurich, Switzerland, 5–12 September 2014. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.L.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Boroumand, M.; Chen, M.; Fridrich, J. Deep Residual Network for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1181–1193. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Cover/Stego | |||
|---|---|---|---|---|
| coco2017 | pascalvoc2012 | |||
| PSNR | SSIM | PSNR | SSIM | |
| LSB-1bit | 55.8896 | 0.9993 | 55.9129 | 0.9994 |
| Rehman [43] | 41.4314 | 0.9982 | 38.7726 | 0.9976 |
| HiNet [52] | 43.7672 | 0.9923 | 42.7289 | 0.9948 |
| Ours | 67.3010 | 0.9999 | 69.2142 | 0.9999 |
| Methods | Secret/Secret_rev | ||
|---|---|---|---|
| C (bpp) | RA (%) | ||
| coco2017 | pascalvoc2012 | ||
| LSB-1bit | 1 | 100 | 100 |
| Rehman [43] | 1 | 99.83 | 99.84 |
| HiNet [52] | 3 | 78.59 | 78.33 |
| Ours | 3 | 100 | 100 |
| Methods | DA (%) | |
|---|---|---|
| Coco2017 | pascalvoc2012 | |
| LSB-1bit | 97.15 | 96.79 |
| Rehman [43] | 98.67 | 99.75 |
| HiNet [52] | 99.84 | 99.77 |
| Ours | 51.62 | 51.81 |
| Methods | w/ Mapping | w/o Mapping |
|---|---|---|
| RA (%) | RA (%) | |
| Ours (1 bpp) | 100 | 100 |
| Ours (3 bpp) | 100 | 99.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Tang, L.; Zheng, W. Lossless Image Steganography Based on Invertible Neural Networks. Entropy 2022, 24, 1762. https://doi.org/10.3390/e24121762
Liu L, Tang L, Zheng W. Lossless Image Steganography Based on Invertible Neural Networks. Entropy. 2022; 24(12):1762. https://doi.org/10.3390/e24121762
Chicago/Turabian StyleLiu, Lianshan, Li Tang, and Weimin Zheng. 2022. "Lossless Image Steganography Based on Invertible Neural Networks" Entropy 24, no. 12: 1762. https://doi.org/10.3390/e24121762
APA StyleLiu, L., Tang, L., & Zheng, W. (2022). Lossless Image Steganography Based on Invertible Neural Networks. Entropy, 24(12), 1762. https://doi.org/10.3390/e24121762