
Graph Multihead Attention Pooling with Self-Supervised Learning


Abstract
1. Introduction
- We considered the graph pooling as a node clustering assignment problem. For accurate clustering assignment, a multihead attention mechanism based on GNN was introduced to sufficiently consider the connections between nodes in terms of features and the structure. Then, we derived Q and K in the attention model to generate the topology of the coarsened graph.
- Self-supervised learning was adopted to maximize the mutual information between the cluster representations and hierarchically global representations, which further optimized the node representation in the coarsened graph.
- Finally, the experimental results showed that the proposed GMAPS significantly outperformed baseline methods in the graph classification task on six publicly available datasets from the biological and social domains.
2. Related Work
2.1. Graph Neural Networks
2.2. Graph Pooling
3. Proposed Model
3.1. Preliminaries
3.1.1. Graph Neural Networks
3.1.2. Graph Pooling
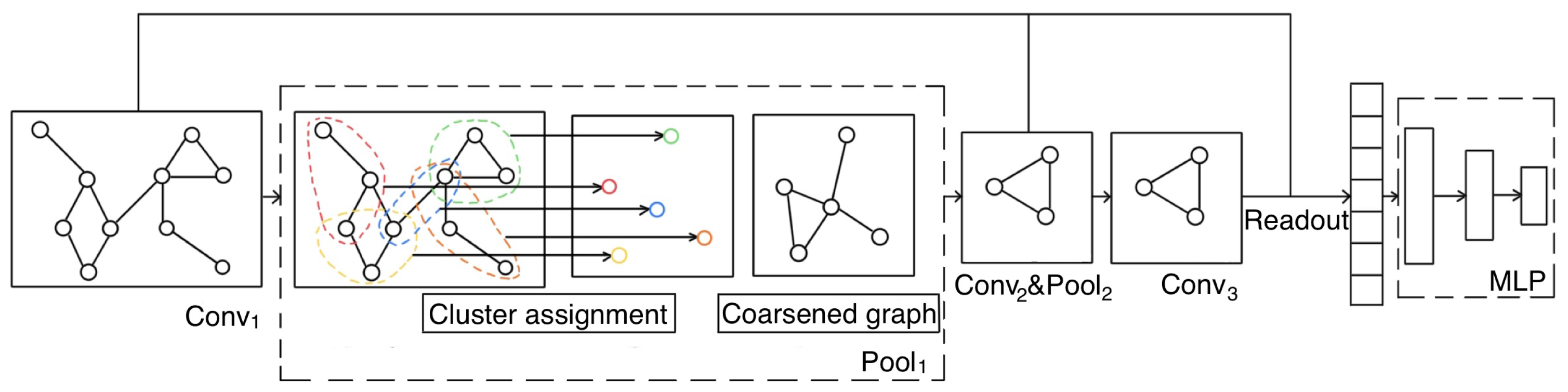
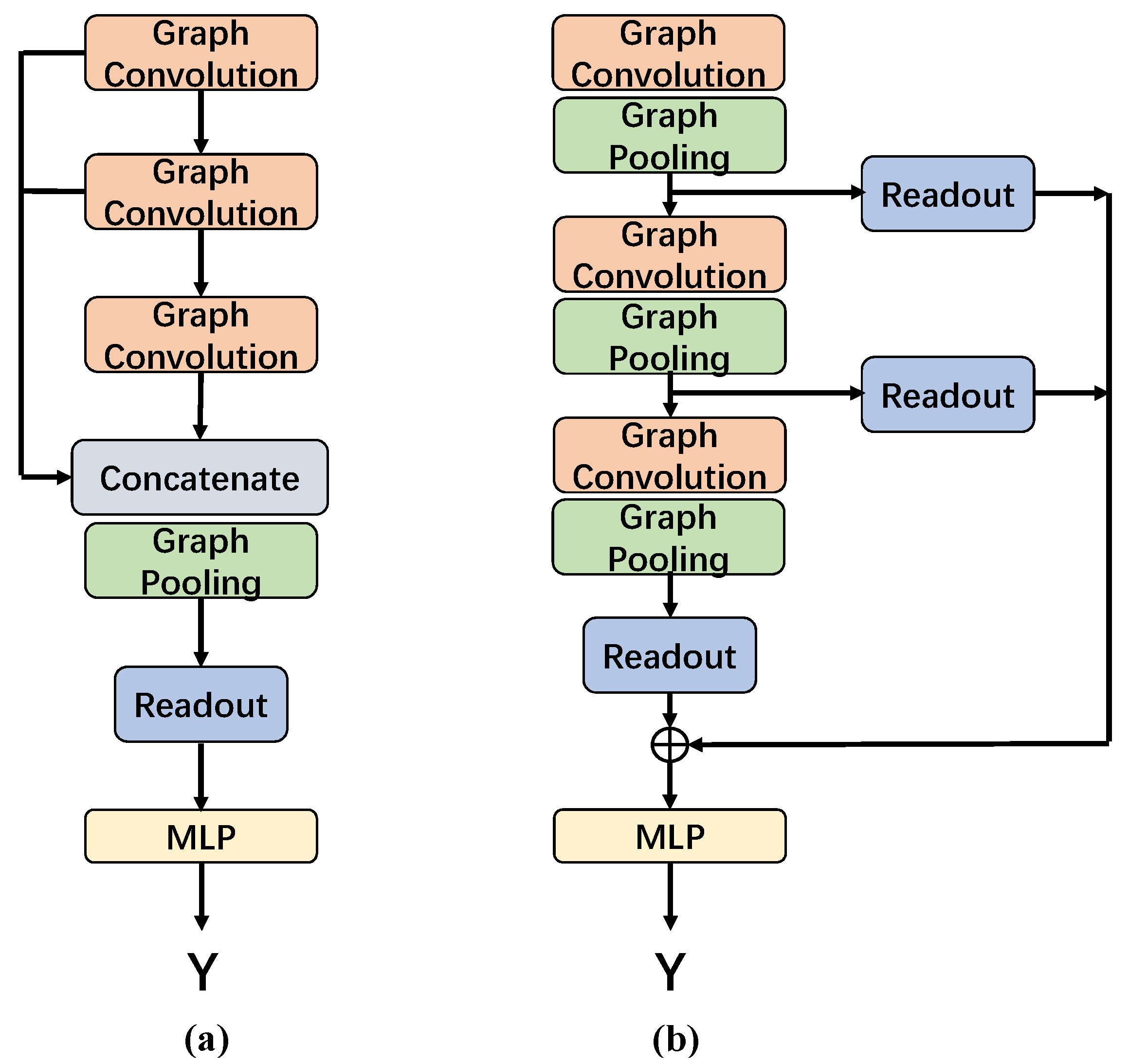
3.2. Overall Neural Network Architecture
3.3. Node Clustering Assignment
3.4. Coarsened Graph Construction
3.5. Self-Supervised Mutual Information Module
3.6. Computational Complexity
4. Experiments
4.1. Datasets
4.2. Baselines
4.3. Implementation Details
4.4. Graph Classification
4.5. Graph Reconstruction
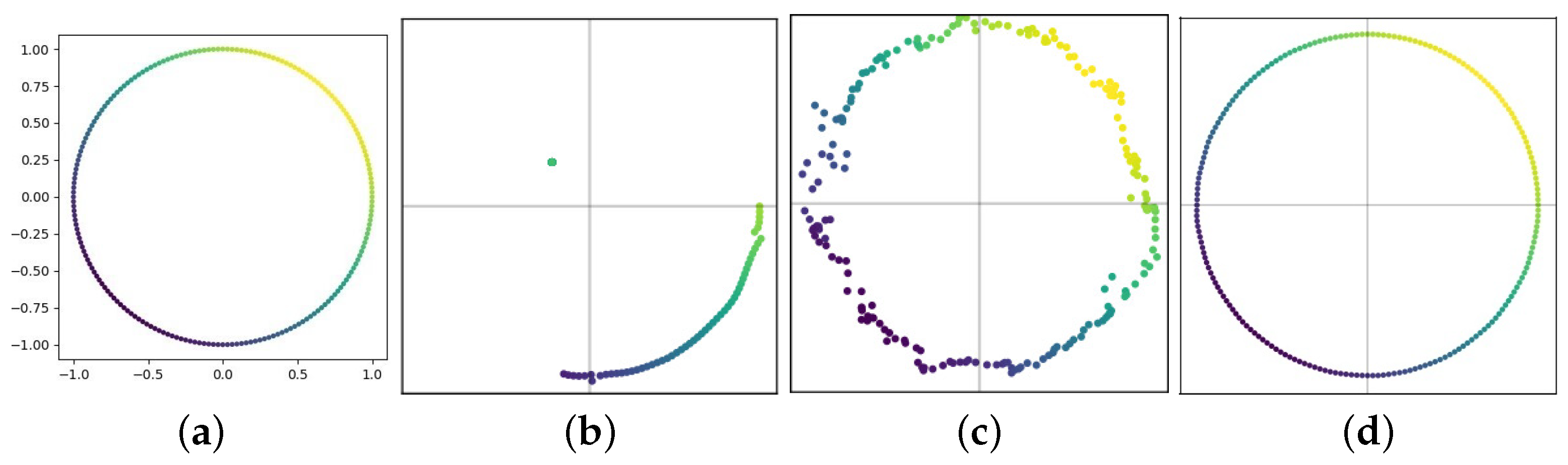
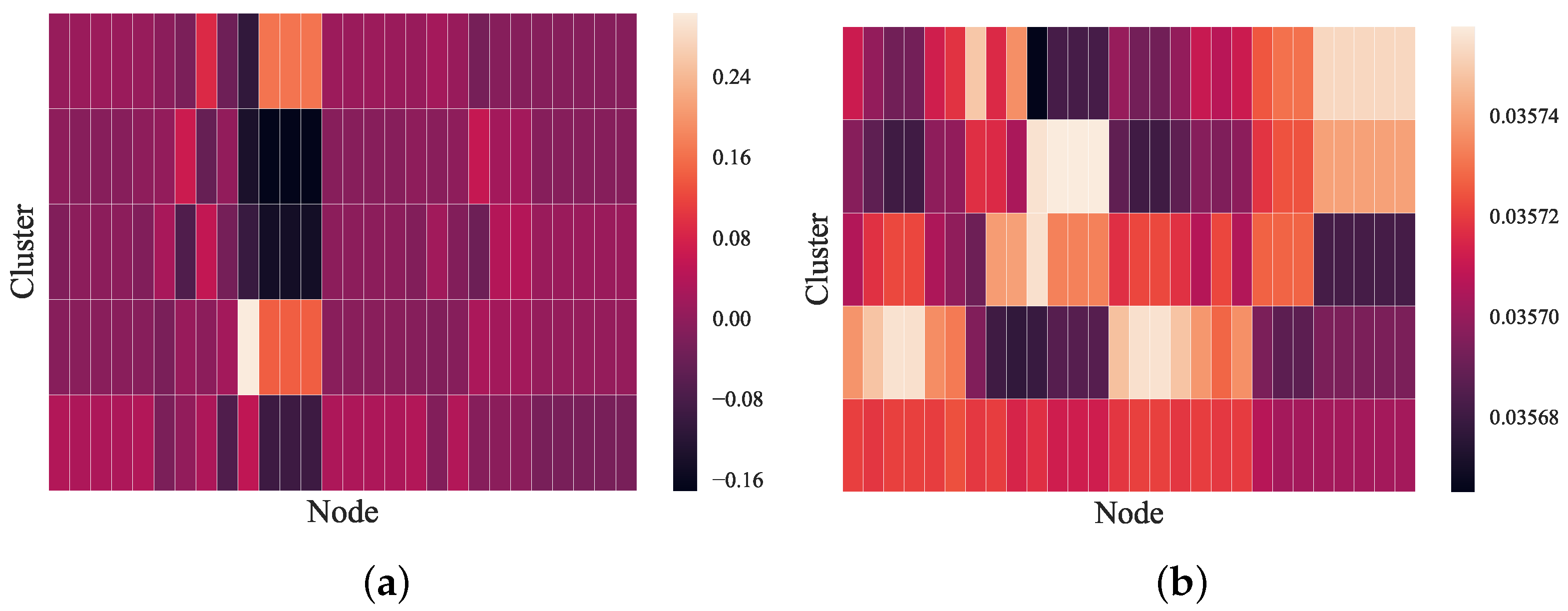
4.6. Ablation Studies and Visualization
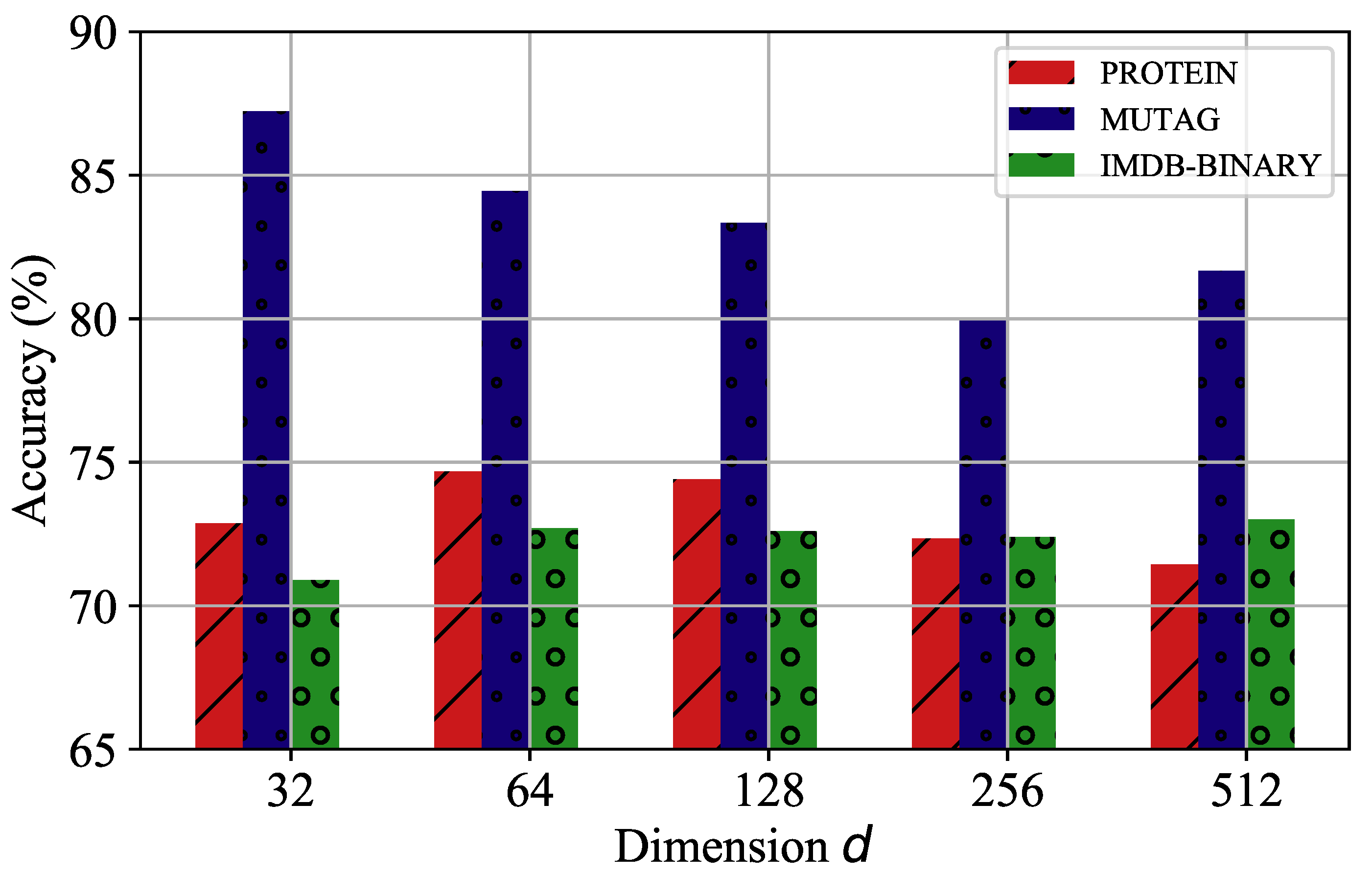
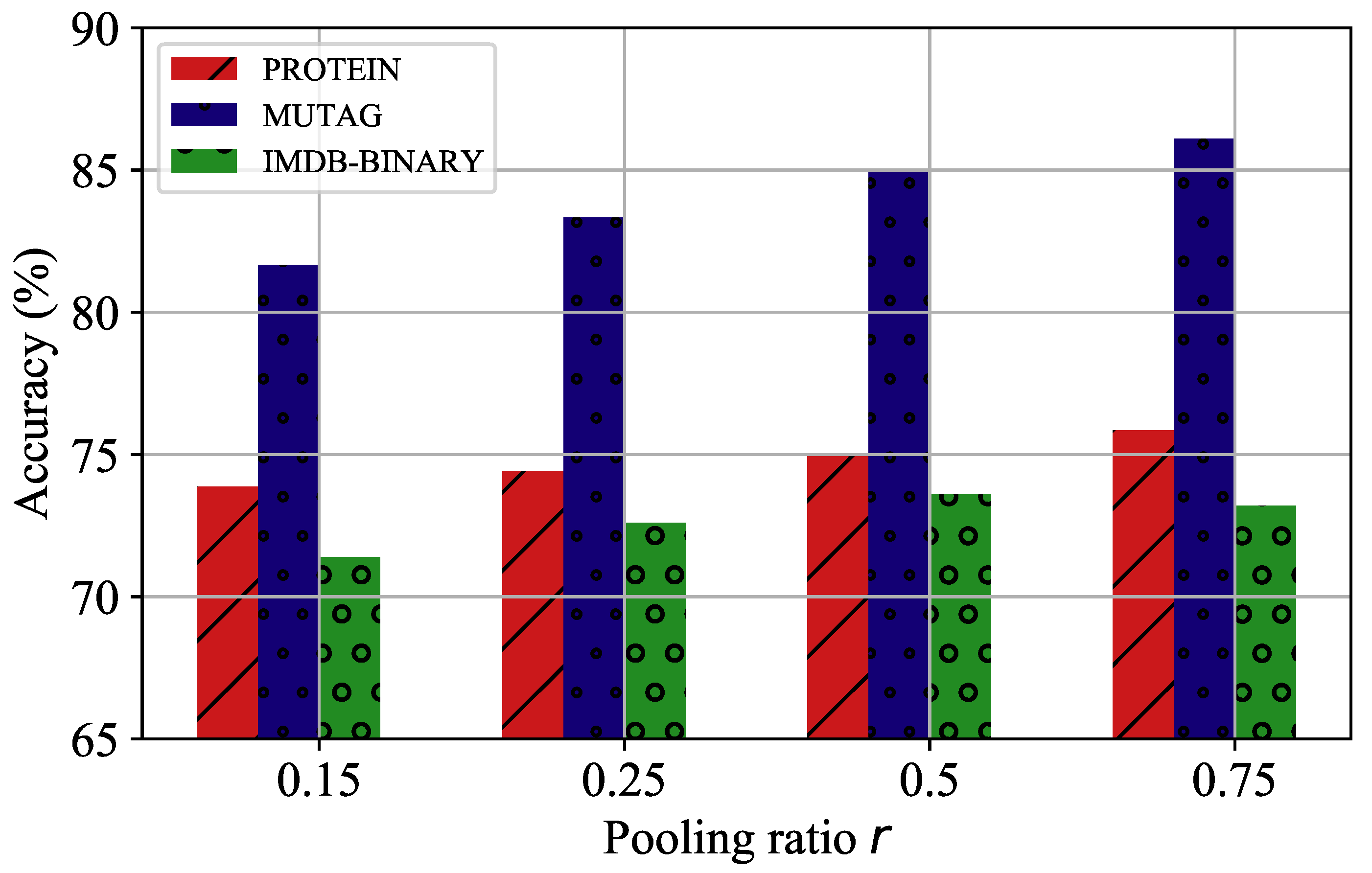
4.7. Parameters Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Shang, Y. Consensus formation in networks with neighbor-dependent synergy and observer effect. Commun. Nonlinear Sci. Numer. Simul. 2021, 95, 105632. [Google Scholar] [CrossRef]
- Min, S.; Gao, Z.; Peng, J.; Wang, L.; Qin, K.; Fang, B. STGSN—A Spatial–Temporal Graph Neural Network framework for time-evolving social networks. Knowl.-Based Syst. 2021, 214, 106746. [Google Scholar] [CrossRef]
- Duvenaud, D.; Maclaurin, D.; Aguilera-Iparraguirre, J.; Gómez-Bombarelli, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional Networks on Graphs for Learning Molecular Fingerprints. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2224–2232. [Google Scholar]
- Jiang, D.; Wang, R.; Yang, J.; Xue, L. Kernel multi-attention neural network for knowledge graph embedding. Knowl.-Based Syst. 2021, 227, 107188. [Google Scholar] [CrossRef]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning Convolutional Neural Networks for Graphs. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York, NY, USA, 19–24 June 2016; pp. 2014–2023. [Google Scholar]
- Wu, Y.; Song, Y.; Huang, H.; Ye, F.; Xie, X.; Jin, H. Enhancing Graph Neural Networks via auxiliary training for semi-supervised node classification. Knowl.-Based Syst. 2021, 220, 106884. [Google Scholar] [CrossRef]
- Yin, R.; Li, K.; Zhang, G.; Lu, J. A deeper graph neural network for recommender systems. Knowl.-Based Syst. 2019, 185, 105020. [Google Scholar] [CrossRef]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral Networks and Locally Connected Networks on Graphs. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep Convolutional Networks on Graph-Structured Data. CoRR 2015. Available online: http://xxx.lanl.gov/abs/1506.05163 (accessed on 25 March 2022).
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 3837–3845. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, Y.; Hu, L.; Gao, W. Learning flexible network representation via anonymous walks. Knowl. Based Syst. 2021, 222, 107021. [Google Scholar] [CrossRef]
- Schlichtkrull, M.S.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the Semantic Web—15th International Conference, ESWC 2018, Heraklion, Greece, 3–7 June 2018; Volume 10843, pp. 593–607. [Google Scholar] [CrossRef]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P.P. Composition-based Multi-Relational Graph Convolutional Networks. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Ying, Z.; You, J.; Morris, C.; Ren, X.; Hamilton, W.L.; Leskovec, J. Hierarchical Graph Representation Learning with Differentiable Pooling. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 4805–4815. [Google Scholar]
- Gao, H.; Ji, S. Graph U-Nets. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 2083–2092. [Google Scholar]
- Lee, J.; Lee, I.; Kang, J. Self-Attention Graph Pooling. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3734–3743. [Google Scholar]
- Gao, X.; Xiong, H.; Frossard, P. iPool—Information-based Pooling in Hierarchical Graph Neural Networks. CoRR 2019. Available online: http://xxx.lanl.gov/abs/1907.00832 (accessed on 23 May 2022). [CrossRef] [PubMed]
- Bianchi, F.M.; Grattarola, D.; Alippi, C. Spectral Clustering with Graph Neural Networks for Graph Pooling. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; Volume 119, pp. 874–883. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Jin, W.; Derr, T.; Liu, H.; Wang, Y.; Wang, S.; Liu, Z.; Tang, J. Self-supervised Learning on Graphs: Deep Insights and New Direction. CoRR 2020. Available online: http://xxx.lanl.gov/abs/2006.10141 (accessed on 23 May 2022).
- Belghazi, M.I.; Baratin, A.; Rajeswar, S.; Ozair, S.; Bengio, Y.; Hjelm, R.D.; Courville, A.C. Mutual Information Neural Estimation. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; pp. 530–539. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Schütt, K.; Kindermans, P.; Felix, H.E.S.; Chmiela, S.; Tkatchenko, A.; Müller, K. SchNet: A continuous-filter convolutional neural network for modeling quantum interactions. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 991–1001. [Google Scholar]
- Zhang, Z.; Bu, J.; Ester, M.; Zhang, J.; Yao, C.; Yu, Z.; Wang, C. Hierarchical Graph Pooling with Structure Learning. CoRR 2019. Available online: http://xxx.lanl.gov/abs/1911.05954 (accessed on 23 May 2022).
- Hammond, D.K.; Vandergheynst, P.; Gribonval, R. Wavelets on Graphs via Spectral Graph Theory. CoRR 2009. Available online: http://xxx.lanl.gov/abs/0912.3848 (accessed on 23 May 2022). [CrossRef]
- Shang, Y. Generalized k-core percolation on correlated and uncorrelated multiplex networks. Phys. Rev. E 2020, 101, 042306. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Cui, Z.; Neumann, M.; Chen, Y. An End-to-End Deep Learning Architecture for Graph Classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LA, USA, 2–7 February 2018; McIlraith, S.A., Weinberger, K.Q., Eds.; AAAI Press: Palo Alto, CA, USA, 2018; pp. 4438–4445. [Google Scholar]
- Wu, L.; Chen, Y.; Shen, K.; Guo, X.; Gao, H.; Li, S.; Pei, J.; Long, B. Graph Neural Networks for Natural Language Processing: A Survey. CoRR 2021. Available online: http://xxx.lanl.gov/abs/2106.06090 (accessed on 24 May 2022).
- Yao, S.; Wang, T.; Wan, X. Heterogeneous Graph Transformer for Graph-to-Sequence Learning. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; pp. 7145–7154. [Google Scholar] [CrossRef]
- Cai, D.; Lam, W. Graph Transformer for Graph-to-Sequence Learning. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, the Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, the Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 7464–7471. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Sato, R. A Survey on The Expressive Power of Graph Neural Networks. CoRR 2020. Available online: http://xxx.lanl.gov/abs/2003.04078 (accessed on 25 May 2022).
- Errica, F.; Podda, M.; Bacciu, D.; Micheli, A. A Fair Comparison of Graph Neural Networks for Graph Classification. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Ranjan, E.; Sanyal, S.; Talukdar, P.P. ASAP: Adaptive Structure Aware Pooling for Learning Hierarchical Graph Representations. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, the Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, the Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 5470–5477. [Google Scholar]
- Dhillon, I.S.; Guan, Y.; Kulis, B. Kernel k-means: Spectral clustering and normalized cuts. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; Kim, W., Kohavi, R., Gehrke, J., DuMouchel, W., Eds.; ACM: New York, NY, USA, 2004; pp. 551–556. [Google Scholar] [CrossRef]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Morris, C.; Kriege, N.M.; Bause, F.; Kersting, K.; Mutzel, P.; Neumann, M. TUDataset: A collection of benchmark datasets for learning with graphs. CoRR 2020. Available online: http://xxx.lanl.gov/abs/2007.08663 (accessed on 23 May 2022).
- Ma, Y.; Wang, S.; Aggarwal, C.C.; Tang, J. Graph Convolutional Networks with EigenPooling. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, 4–8 August 2019; Teredesai, A., Kumar, V., Li, Y., Rosales, R., Terzi, E., Karypis, G., Eds.; ACM: New York, NY, USA, 2019; pp. 723–731. [Google Scholar] [CrossRef]
- Fey, M.; Lenssen, J.E. Fast Graph Representation Learning with PyTorch Geometric. CoRR 2019. Available online: http://xxx.lanl.gov/abs/1903.02428 (accessed on 21 May 2022).
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.; Jegelka, S. Representation Learning on Graphs with Jumping Knowledge Networks. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5449–5458. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ||||
|---|---|---|---|---|
| D&D | 1178 | 284.32 | 715.66 | 2 |
| PROTEINS | 1113 | 39.06 | 72.82 | 2 |
| MUTAG | 188 | 17.93 | 19.79 | 2 |
| IMDB-Binary | 1000 | 19.77 | 96.53 | 2 |
| IMDB-Multi | 1500 | 13.00 | 65.94 | 3 |
| COLLAB | 5000 | 74.49 | 2457.78 | 3 |
| Method | D&D | PROTEINS | MUTAG | IMDB-B | IMDB-M | COLLAB |
|---|---|---|---|---|---|---|
| GCN-mean | 71.96 ± 4.78 | 73.24 ± 3.62 | 70.55 ± 10.25 | 72.51 ± 3.91 | 51.13 ± 3.16 | 80.51 ± 1.39 |
| SAGE-mean | 72.13 ± 2.62 | 71.44 ± 3.88 | 68.88 ± 15.15 | 72.21 ± 2.63 | 49.81 ± 3.93 | 79.66 ± 1.49 |
| GAT-mean | 71.36 ± 4.31 | 72.61 ± 4.91 | 69.44 ± 14.95 | 72.59 ± 2.83 | 50.46 ± 4.31 | 79.36 ± 1.67 |
| gPool | 74.87 ± 3.82 | 72.52 ± 3.81 | 72.77 ± 9.76 | 71.91 ± 3.36 | 50.26 ± 3.33 | 79.11 ± 2.15 |
| ASAP | 72.82 ± 3.17 | 71.17 ± 4.81 | 80.55 ± 10.01 | 72.51 ± 4.29 | 50.21 ± 5.23 | 77.52 ± 2.38 |
| SAGPool | 70.59 ± 3.11 | 70.36 ± 3.81 | 78.33 ± 8.76 | 70.41 ± 5.93 | 51.26 ± 3.59 | 78.89 ± 1.63 |
| DiffPool | 77.35 ± 3.41 | 72.97 ± 5.76 | 77.77 ± 9.29 | 70.59 ± 4.65 | 50.66 ± 3.67 | 79.43 ± 1.42 |
| GMAP | 77.61 ± 3.41 | 74.23 ± 4.32 | 81.67 ± 11.12 | 72.09 ± 4.01 | 51.33 ± 4.67 | 80.72 ± 1.38 |
| GMAPS | 78.81 ± 4.05 | 74.41 ± 3.58 | 83.33 ± 8.95 | 72.61 ± 4.38 | 51.67 ± 5.41 | 80.97 ± 1.41 |
| Method | D&D | PROTEINS | MUTAG |
|---|---|---|---|
| GMAP-GCN | 77.61 ± 3.41 | 74.23 ± 4.32 | 81.67 ± 11.12 |
| GMAP-GraphSAGE | 76.92 ± 3.48 | 72.07 ± 4.36 | 80.42 ± 10.58 |
| GMAP-GAT | 76.79 ± 4.15 | 72.97 ± 4.91 | 80.11 ± 11.62 |
| GMAPS-GCN | 78.81 ± 4.05 | 74.41 ± 3.58 | 83.33 ± 8.95 |
| GMAPS-GraphSAGE | 78.63 ± 3.11 | 72.97 ± 3.75 | 81.96 ± 9.72 |
| GMAPS-GAT | 78.37 ± 3.19 | 73.87 ± 4.88 | 81.25 ± 10.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Hu, L.; Wu, Y.; Gao, W. Graph Multihead Attention Pooling with Self-Supervised Learning. Entropy 2022, 24, 1745. https://doi.org/10.3390/e24121745
Wang Y, Hu L, Wu Y, Gao W. Graph Multihead Attention Pooling with Self-Supervised Learning. Entropy. 2022; 24(12):1745. https://doi.org/10.3390/e24121745
Chicago/Turabian StyleWang, Yu, Liang Hu, Yang Wu, and Wanfu Gao. 2022. "Graph Multihead Attention Pooling with Self-Supervised Learning" Entropy 24, no. 12: 1745. https://doi.org/10.3390/e24121745
APA StyleWang, Y., Hu, L., Wu, Y., & Gao, W. (2022). Graph Multihead Attention Pooling with Self-Supervised Learning. Entropy, 24(12), 1745. https://doi.org/10.3390/e24121745