
A Decision Probability Transformation Method Based on the Neural Network

Abstract
1. Introduction
- (1).
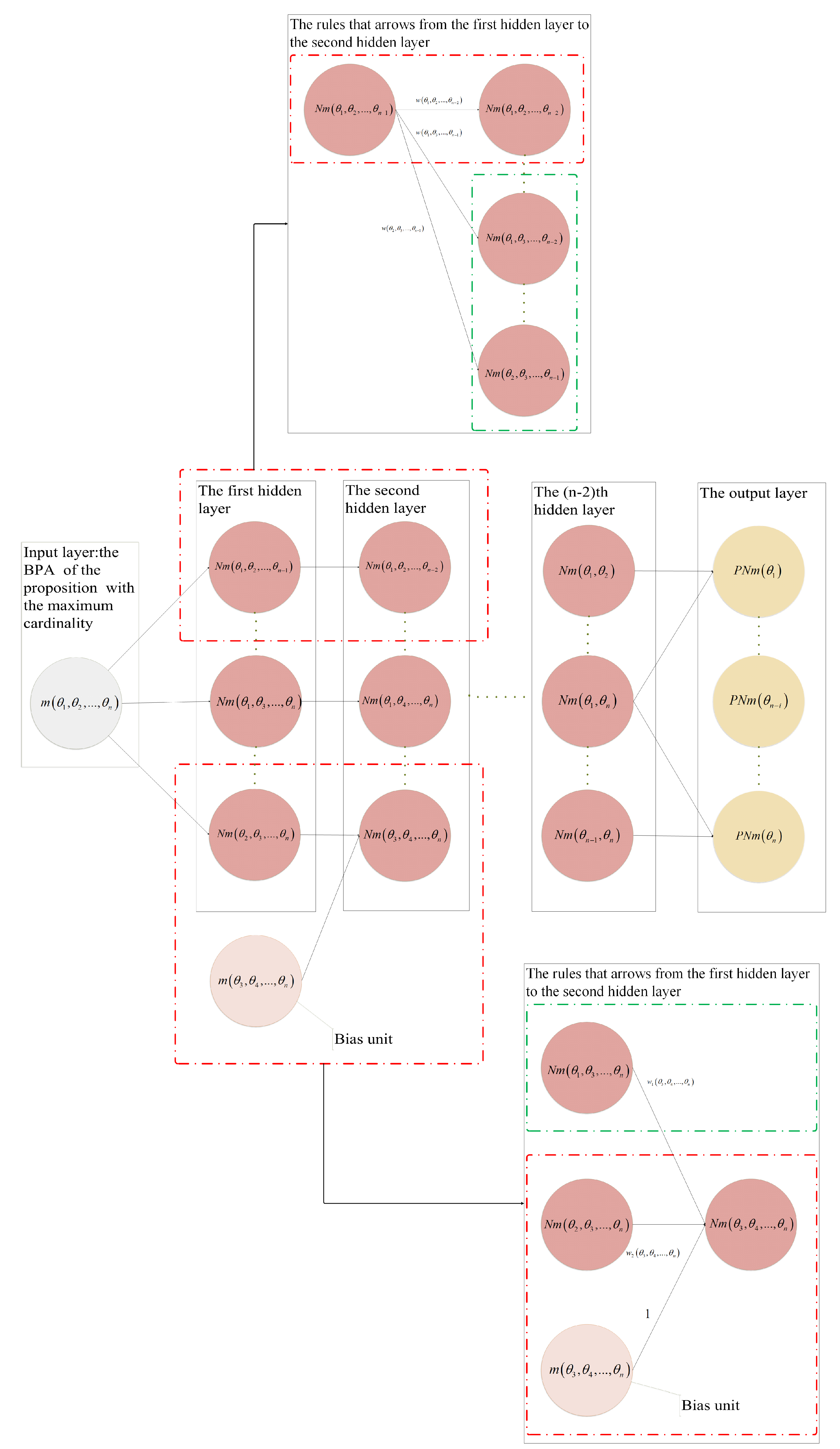
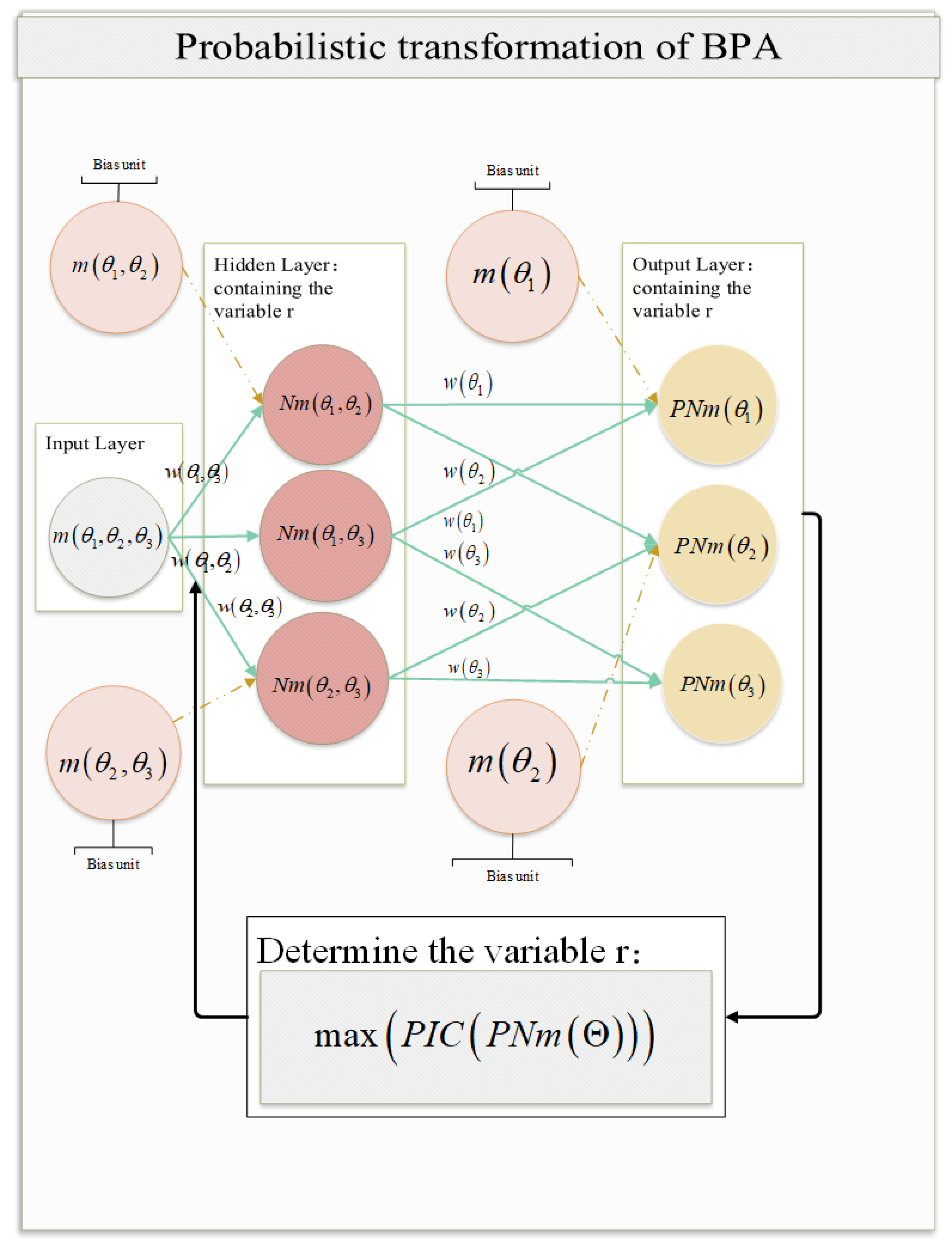
- The BPA of a multi-element proposition with the largest cardinality is used as an input layer of a neural network, and the BPAs of the remaining existing propositions are used as bias units of the neural network. The hidden network layers are constructed according to decreasing order of cardinality for the proposition subset of the input layer and bias units. Finally, the probability of each single-element proposition is output by the output layer.
- (2).
- The interval information content (IIC) and average information content (AIC) are introduced to quantify the information contained in each proposition subset and combined to construct a weighting function containing the parameter. The weighting function reaches its extreme value at a certain point, in preparation for the use of the constraints below. After obtaining the PIC of the change based on the probability of each single-element proposition, the maximum PIC value is taken as a constraint to obtain the optimal transformation results.
2. Preliminaries
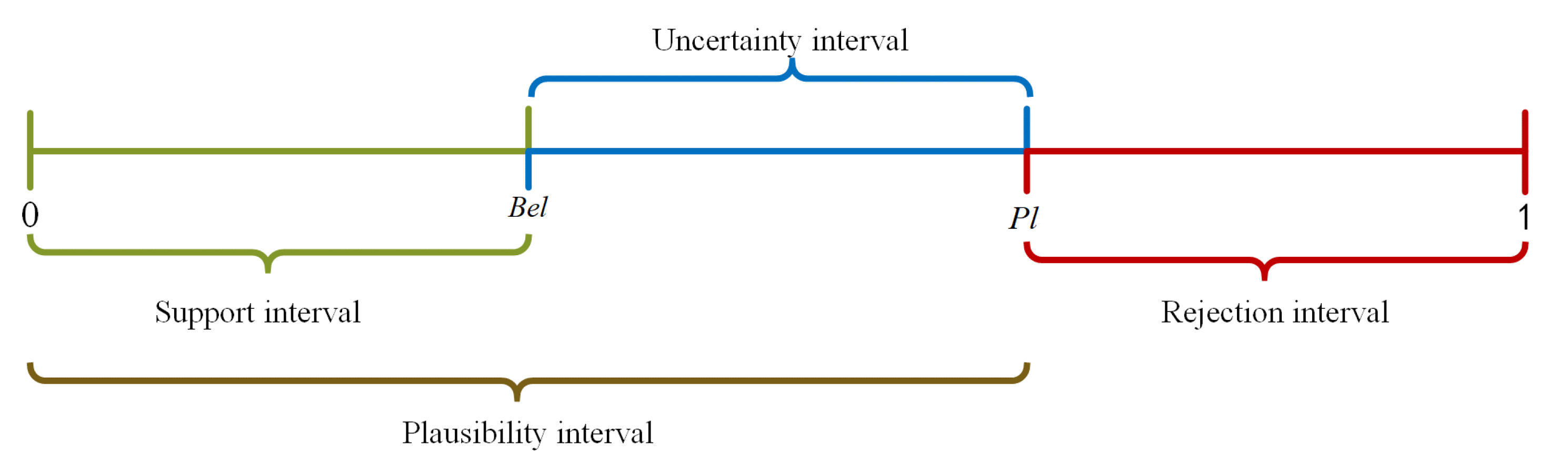
2.1. DS Evidence Theory
2.2. Probability Transformation Methods
3. Shannon Entropy and Probabilistic Information Content
3.1. Shannon Entropy
3.2. Probabilistic Information Content
4. Probability Transformation Based on the Neural Network
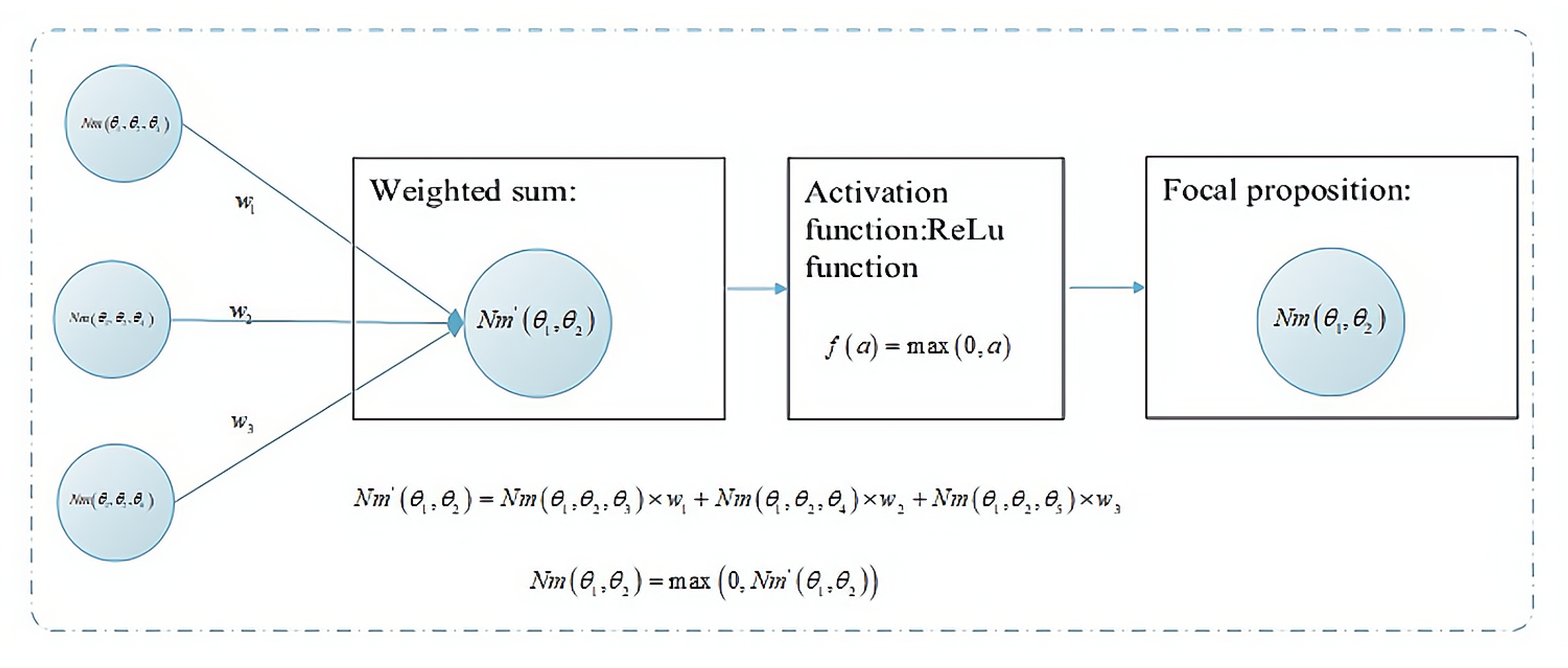
4.1. Neural Network Construction
4.2. AIC and IIC Values
4.3. Weighting Function with Variable
4.4. Optimal Probability Calculation of Single-Element Propositions
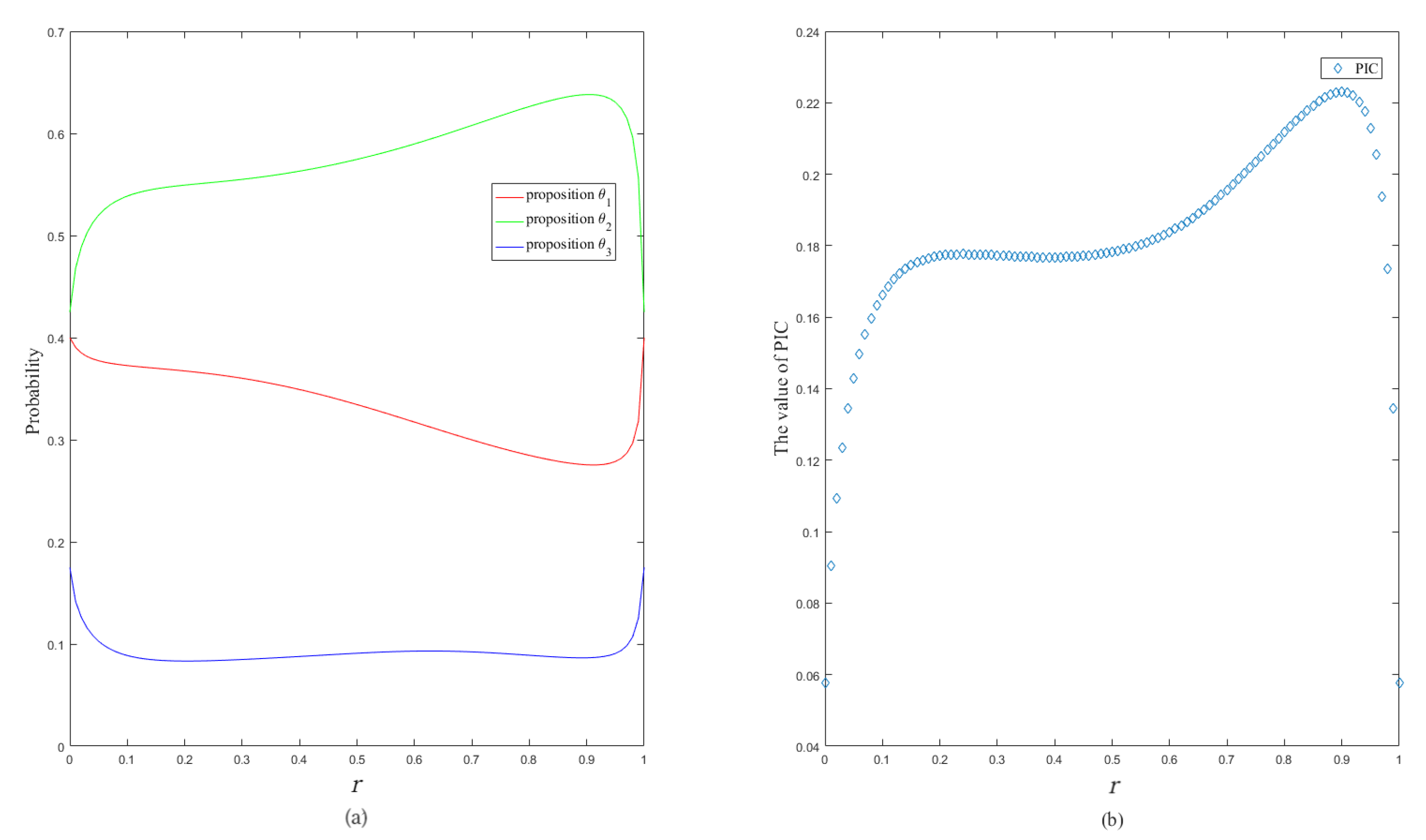
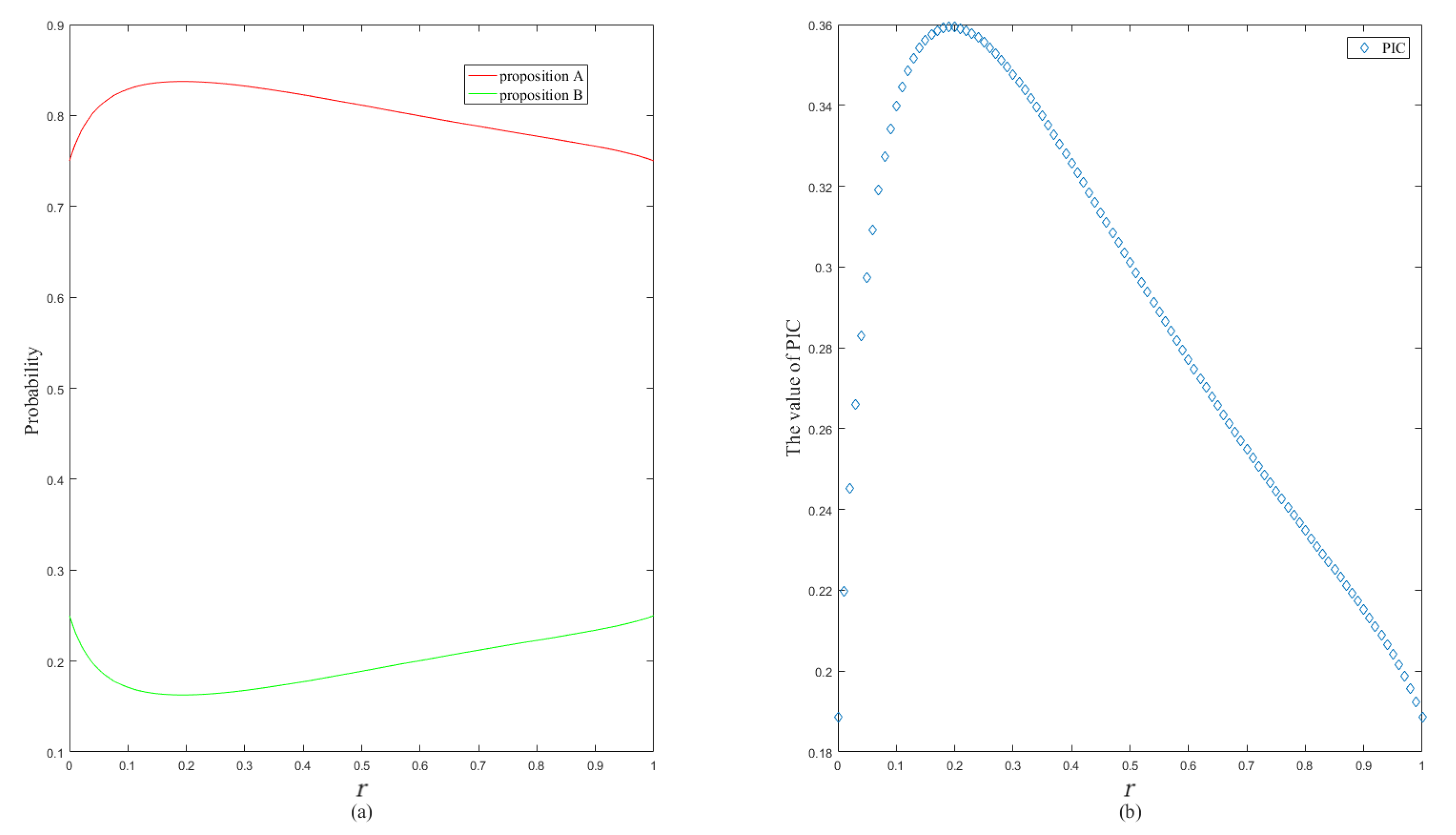
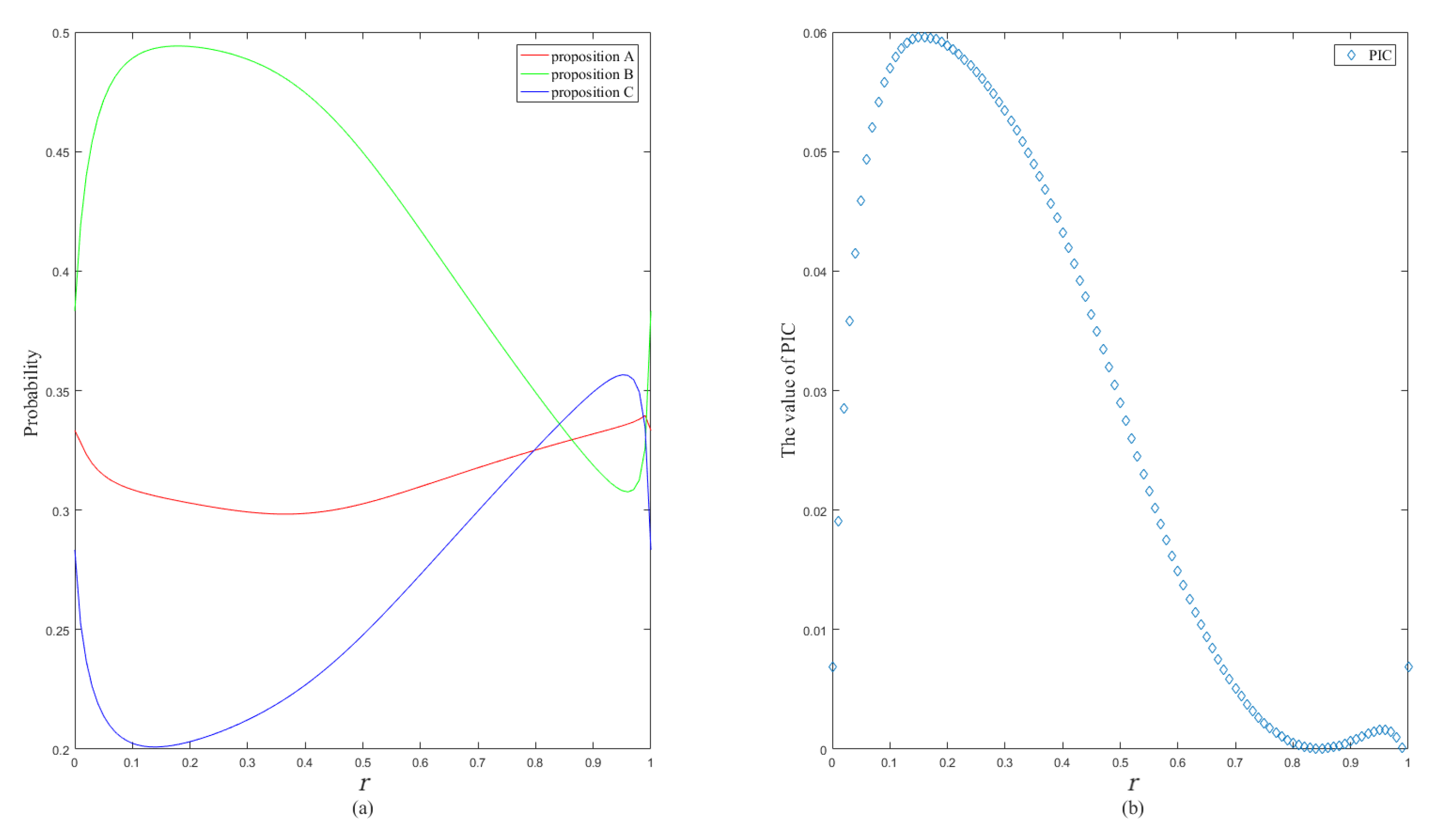
5. Analysis and Numerical Examples
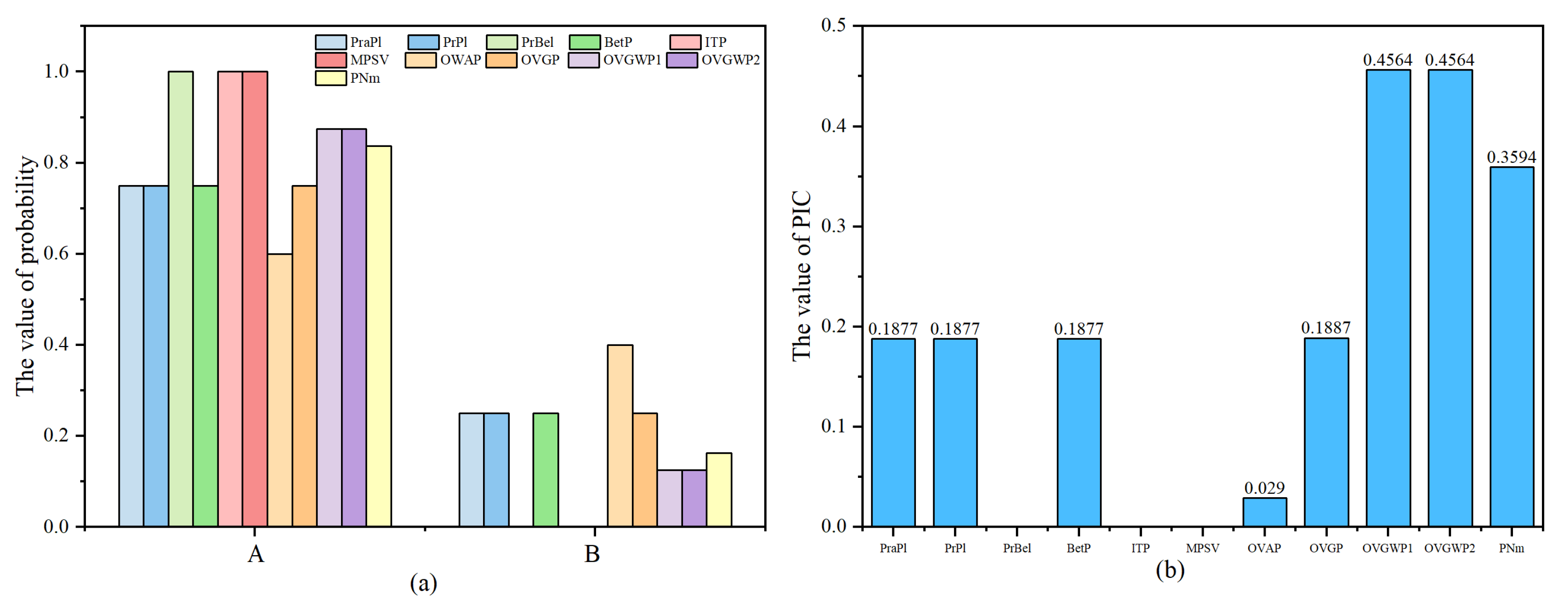
6. Practical Application
7. Conslusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, J.; Deng, Z.; Song, Q.; Chi, Q.; Wu, T.; Huang, Y.; Liu, D.; Gao, M. Multi-UAV counter-game model based on uncertain information. Appl. Math. Comput. 2020, 366, 124684. [Google Scholar] [CrossRef]
- Xiao, F.; Wen, J.; Pedrycz, W. Generalized divergence-based decision making method with an application to pattern classification. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Liu, P.; Diao, H.; Zou, L.; Deng, A. Uncertain multi-attribute group decision making based on linguistic-valued intuitionistic fuzzy preference relations. Inf. Sci. 2019, 508, 293–308. [Google Scholar] [CrossRef]
- Yan, M.; Wang, J.; Dai, Y.; Han, H. A method of multiple-attribute group decision making problem for 2-dimension uncertain linguistic variables based on cloud model. Optim. Eng. 2021, 22, 2403–2427. [Google Scholar] [CrossRef]
- Zhu, D.; Cheng, X.; Yang, L.; Chen, Y.; Yang, S. Information fusion fault diagnosis method for deep-sea human occupied vehicle thruster based on deep belief network. IEEE Trans. Cybern. 2021, 52, 9414–9427. [Google Scholar] [CrossRef]
- Yao, L.; Wu, Y. Robust fault diagnosis and fault-tolerant control for uncertain multiagent systems. Int. J. Robust Nonlinear Control. 2020, 30, 8192–8205. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, Y. An improved approach of incomplete information fusion and its application in sensor data-based fault diagnosis. Mathematics 2021, 9, 1292. [Google Scholar] [CrossRef]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A novel fast single image dehazing algorithm based on artificial multiexposure image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 500153. [Google Scholar] [CrossRef]
- Zhang, Y.; Hua, C. A new adaptive visual tracking scheme for robotic system without image-space velocity information. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 5249–5258. [Google Scholar] [CrossRef]
- Li, L.; Xie, Y.; Chen, X.; Yue, W.; Zeng, Z. Dynamic uncertain causality graph based on cloud model theory for knowledge representation and reasoning. Int. J. Mach. Learn. Cybern. 2020, 11, 1781–1799. [Google Scholar] [CrossRef]
- Legner, C.; Pentek, T.; Otto, B. Accumulating design knowledge with reference models: Insights from 12 years’ research into data management. J. Assoc. Inf. Syst. 2020, 21, 735–770. [Google Scholar] [CrossRef]
- Chen, J.; Wang, C.; He, K.; Zhao, Z.; Chen, M.; Du, R.; Ahn, G. Semantics-aware privacy risk assessment using self-learning weight assignment for mobile apps. IEEE Trans. Dependable Secur. Comput. 2021, 18, 15–29. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, Q.; Ruiz, R.; Zhang, L. Ergonomic risk and cycle time minimization for the U-shaped worker assignment assembly line balancing problem: A multi-objective approach. Comput. Oper. Res. 2020, 118, 104905. [Google Scholar] [CrossRef]
- Liu, M.; Liang, B.; Zheng, F.; Chu, F. Stochastic airline fleet assignment with risk aversion. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3081–3090. [Google Scholar] [CrossRef]
- Mahmood, N.; Butalia, T.; Qin, R.; Manasrah, M. Concurrent events risk assessment generic models with enhanced reliability using Fault tree analysis and expanded rotational fuzzy sets. Expert Syst. Appl. 2022, 197, 116681. [Google Scholar] [CrossRef]
- Xiao, F.; Pedrycz, W. Negation of the quantum mass function for multisource quantum information fusion with its application to pattern classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]
- Xiao, F.; Cao, Z.; Lin, T. A complex weighted discounting multisource information fusion with its application in pattern classification. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Xiao, F. On the maximum entropy negation of a complex-valued distribution. IEEE Trans. Fuzzy Syst. 2021, 29, 3259–3269. [Google Scholar] [CrossRef]
- Cui, H.; Zhou, L.; Li, Y.; Kang, B. Belief entropy-of-entropy and its application in the cardiac interbeat interval time series analysis. Chaos Solitons Fractals 2022, 155, 111736. [Google Scholar] [CrossRef]
- Zhang, H.; Deng, Y. Entropy measure for orderable sets. Inf. Sci. 2021, 561, 141–151. [Google Scholar] [CrossRef]
- Xiao, F. GIQ: A generalized intelligent quality-based approach for fusing multi-source information. IEEE Trans. Fuzzy Syst. 2021, 2021 29, 2018–2031. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W.; Wang, Z. Zero-sum polymatrix games with link uncertainty: A Dempster-Shafer theory solution. Appl. Math. Comput. 2019, 340, 101–112. [Google Scholar] [CrossRef]
- Xue, Y.; Deng, Y. Mobius transformation in generalized evidence theory. Appl. Intell. 2021, 52, 7818–7831. [Google Scholar] [CrossRef]
- Xiao, F. A new divergence measure for belief functions in D–S evidence theory for multisensor data fusion. Inf. Sci. 2020, 514, 462–483. [Google Scholar] [CrossRef]
- Deng, J.; Deng, Y.; Cheong, K. Combining conflicting evidence based on Pearson correlation coefficient and weighted graph. Int. J. Intell. Syst. 2020, 36, 7443–7460. [Google Scholar] [CrossRef]
- Wang, Z.; Xiao, F. An improved multi-Source data fusion method based on the belief entropy and divergence measure. Entropy 2019, 21, 611. [Google Scholar] [CrossRef] [PubMed]
- Deng, Z.; Wang, J. Measuring total uncertainty in evidence theory. Int. J. Intell. Syst. 2021, 36, 1721–1745. [Google Scholar] [CrossRef]
- Zhao, K.; Li, L.; Chen, Z.; Sun, R.; Yuan, G.; Li, J. A survey: Optimization and applications of evidence fusion algorithm based on Dempster-Shafer theory. Appl. Soft Comput. 2022, 124, 106075. [Google Scholar] [CrossRef]
- Li, R.; Chen, Z.; Li, H.; Tang, Y. A new distance-based total uncertainty measure in Dempster-Shafer evidence theory. Appl. Intell. 2021, 52, 1209–1237. [Google Scholar] [CrossRef]
- Qiang, C.; Deng, Y. A new correlation coefficient of mass function in evidence theory and its application in fault diagnosis. Appl. Intell. 2021, 52, 7832–7842. [Google Scholar] [CrossRef]
- Sudano, J. Pignistic probability transforms for mixes of low- and high-probability events. Comput. Sci. 2015, 23–27. [Google Scholar]
- Smets, P.; Kennes, R. The transferable belief model. Artif. Intell. 1994, 66, 191–234. [Google Scholar] [CrossRef]
- Pan, L.; Deng, Y. Probability transform based on the ordered weighted averaging and entropy difference. Int. J. Comput. Commun. Control. 2020, 15, 3743. [Google Scholar] [CrossRef]
- Deng, Z.; Wang, J. A novel decision probability transformation method based on belief interval. Knowl.-Based Syst. 2020, 208, 106427. [Google Scholar] [CrossRef]
- Huang, C.; Mi, X.; Kang, B. Basic probability assignment to probability distribution function based on the Shapley value approach. Int. J. Intell. Syst. 2021, 36, 4210–4236. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Q.; Deng, Y. A new probability transformation based on the ordered visibility graph. Int. J. Comput. Int. Syst. 2016, 31, 44–67. [Google Scholar] [CrossRef]
- Chen, L.; Deng, Y.; Cheong, K. Probability transformation of mass function: A weighted network method based on the ordered visibility graph. Eng. Appl. Artif. Intell. 2021, 105, 104438. [Google Scholar] [CrossRef]
- Rathipriya, R.; Rahman, A.; Dhamodharavadhani, S.; Meero, A.; Yoganandan, G. Demand forecasting model for time-series pharmaceutical data using shallow and deep neural network model. Neural. Comput. Appl. 2022, 1–13. [Google Scholar] [CrossRef]
- Jagtap, A.; Shin, Y.; Kawaguchi, K.; Karniadakis, G. Deep Kronecker neural networks: A general framework for neural networks with adaptive activation functions. Neurocomputing 2021, 468, 165–180. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Sigmobile Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Boob, D.; Dey, S.; Lan, G. Complexity of training ReLU neural network. Discret. Optim 2022, 44, 100620. [Google Scholar] [CrossRef]
- Xiao, F. Evidence combination based on prospect theory for multi-sensor data fusion. ISA Trans. 2020, 106, 253–261. [Google Scholar] [CrossRef] [PubMed]
- Xiao, F. Multi-sensor data fusion based on the belief divergence measure of evidences and the belief entropy. Inf. Fusion 2019, 46, 23–32. [Google Scholar] [CrossRef]
- Jiang, W.; Hu, W.; Xie, C. A new engine fault diagnosis method based on multi-sensor data fusion. Appl. Sci. 2017, 7, 280. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | A | B | C |
|---|---|---|---|
| PraPl [31] | 0.2 | 0.4 | 0.4 |
| PrPl [31] | 0.2 | 0.4 | 0.4 |
| PrBel [31] | 0.2 | NaN | NaN |
| BetP [32] | 0.2 | 0.4 | 0.4 |
| ITP [34] | 0.2 | 0.4 | 0.4 |
| MPSV [35] | 0.2 | 0.4 | 0.4 |
| OWAP [33] | 0.3230 | 0.3756 | 0.3014 |
| OVGP [36] | 0.2 | 0.4 | 0.4 |
| OVGWP1 [37] | 0.2 | 0.4 | 0.4 |
| OVGWP2 [37] | 0.2 | 0.4 | 0.4 |
| PNm | 0.2 | 0.4 | 0.4 |
| Method | A | B | |
|---|---|---|---|
| PraPl [31] | 0.75 | 0.25 | 0.1877 |
| PrPl [31] | 0.75 | 0.25 | 0.1877 |
| PrBel [31] | 1 | NaN | NaN |
| BetP [32] | 0.75 | 0.25 | 0.1877 |
| ITP [34] | 1 | 0 | NaN |
| MPSV [35] | 1 | 0 | NaN |
| OWAP [33] | 0.6 | 0.4 | 0.0290 |
| OVGP [36] | 0.75 | 0.25 | 0.1887 |
| OVGWP1 [37] | 0.875 | 0.125 | 0.4564 |
| OVGWP2 [37] | 0.875 | 0.125 | 0.4564 |
| PNm | 0.837 | 0.163 | 0.3594 |
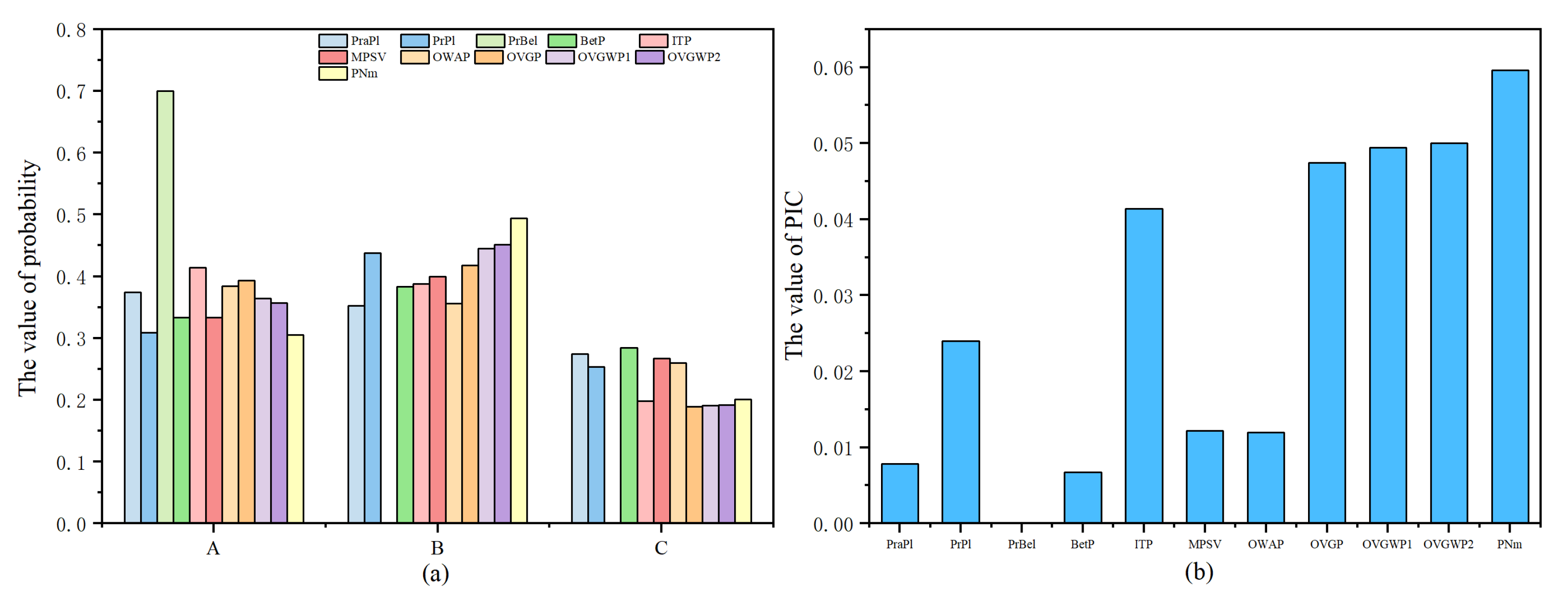
| Method | A | B | C | |
|---|---|---|---|---|
| PraPl [31] | 0.374 | 0.352 | 0.274 | 0.0078 |
| PrPl [31] | 0.309 | 0.438 | 0.253 | 0.0240 |
| PrBel [31] | 0.7 | NaN | NaN | NaN |
| BetP [32] | 0.333 | 0.383 | 0.284 | 0.0067 |
| ITP [34] | 0.414 | 0.388 | 0.198 | 0.0414 |
| MPSV [35] | 0.333 | 0.400 | 0.267 | 0.0122 |
| OWAP [33] | 0.384 | 0.356 | 0.260 | 0.0120 |
| OVGP [36] | 0.393 | 0.418 | 0.189 | 0.0474 |
| OVGWP1 [37] | 0.364 | 0.445 | 0.191 | 0.0494 |
| OVGWP2 [37] | 0.357 | 0.451 | 0.192 | 0.0500 |
| PNm | 0.305 | 0.494 | 0.201 | 0.0596 |
| BPA | ||||
|---|---|---|---|---|
| 0.0437 | 0.0865 | |||
| 0.3346 | 0.2879 | 0.6570 | 0.6616 | |
| 0.2916 | 0.1839 | 0.1726 | 0.1692 | |
| 0.0437 | 0.0863 | |||
| 0.0239 | 0.0865 | |||
| 0.2385 | 0.1825 | 0.1704 | 0.1692 | |
| 0.0239 | 0.0863 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhao, A.; Liu, H. A Decision Probability Transformation Method Based on the Neural Network. Entropy 2022, 24, 1638. https://doi.org/10.3390/e24111638
Li J, Zhao A, Liu H. A Decision Probability Transformation Method Based on the Neural Network. Entropy. 2022; 24(11):1638. https://doi.org/10.3390/e24111638
Chicago/Turabian StyleLi, Junwei, Aoxiang Zhao, and Huanyu Liu. 2022. "A Decision Probability Transformation Method Based on the Neural Network" Entropy 24, no. 11: 1638. https://doi.org/10.3390/e24111638
APA StyleLi, J., Zhao, A., & Liu, H. (2022). A Decision Probability Transformation Method Based on the Neural Network. Entropy, 24(11), 1638. https://doi.org/10.3390/e24111638