1. Introduction
Risk parity is an approach to investing that aims to balance risk evenly across a diversified range of assets. Risk parity portfolios have been shown to be more diversified than traditional 60/40 portfolios [
1]. Risk parity is a sensible choice for investors who know which assets to buy but do not wish to express views on expected returns across these assets. This approach can also be applied to baskets of systematic investment strategies [
2].
Risk parity can be defined in various ways. In their simplest form, risk parity portfolios weight investments according to an estimate of their volatility. A more advanced approach considers the contribution of each asset to the risk of the portfolio [
3]. Links have been established between three important approaches. Equal weights and minimum variance are limit cases of a constrained risk-minimization problem that includes risk budgeting [
3]. Starting with equal weights and iteratively applying risk budgeting leads to minimum variance [
4]. Conversely, starting with minimum variance and applying covariance shrinkage leads to equal weights [
5,
6,
7,
8].
This study investigates these links using techniques from information theory and geometry. Using entropy as a measure of portfolio diversity was proposed in [
9] and has been subject to further research. The entropy of portfolio returns has also been considered as a possible risk measure [
10]. The two approaches differ. One considers the distribution of weights across assets, the other is based on the statistical distribution of financial returns.
Alpha risk parity is a generalization of the equal risk contribution approach of Maillard, Teiletche, and Roncalli [
3]. A generalized log-barrier based on Tsallis’
q-logarithm [
7] ensures a minimum level of diversity in the allocation. The contribution of each asset to the risk of the portfolio is given by a closed-form formula. A key parameter that is related to Tsallis’s entropic index determines how much weights can diverge from risk budgets. Adjusting the parameters leads to equal weights or minimum variance as the two ends of the spectrum, and to risk budgeting as a compromise.
Alpha risk parity is applied to a selection of major equity, bond, and commodity futures. Equal-weighted portfolios are the least invariant to duplication [
11] and the most diversified across assets. Minimum-variance portfolios are at the other end of the spectrum. Equal risk-contribution portfolios are a compromise between these two extremes; however, they are much closer to equal weights than they are to minimum risk. Increasing the alpha parameter is a sensible way to loosen the diversity constraint and give a greater role to risk minimization.
2. Theoretical Framework
2.1. Literature Review
2.1.1. Risk Parity
Naive risk parity consists of scaling individual assets by their estimated risk. Why this approach makes sense has been a subject of debate. Risk parity portfolios may benefit from investors’ aversion to financial leverage [
12], although the cost of leverage and rebalancing may offset these benefits [
13]. Although most studies on risk parity focus on allocation across asset classes, the approach may be applied to single shares [
14], equity sectors [
15], and corporate bonds [
16]. Equal risk contributions extends naive risk parity to the correlated case [
3]. This approach can be extended further to any risk budgets [
17].
Minimizing risk under constrained exposure is another way to allocate a portfolio without expressing views on future returns [
18,
19]. When assets are uncorrelated, minimum variance is achieved by scaling individual assets by their variance. Some authors [
20] use the term of ‘risk-based portfolios’ for any approach that relies solely on risk. Naive risk parity, equal risk contributions, minimum variance, and maximum diversification portfolios [
11] are risk-based portfolios.
Risk criteria are usually selected from two main classes [
21]. Volatility and downside volatility are deviation measures [
22]. Conditional value-at-risk [
23] and the power-spectrum measure [
2] are spectral risk measures [
24] that can be applied to risk parity portfolios after proper centering. See [
2] for a review of tail-risk measures and their application to risk parity portfolios with and without dependencies.
There is no precise definition of risk parity in the general case. In the literature on hierarchical allocation, risk parity across clusters is achieved by using equal risk contributions [
25,
26], or minimum variance [
27]. In [
25], portfolios are allocated across clusters using equal weights. Following [
3,
4], this study proposes a unified framework for these approaches.
Some approaches to risk parity are dramatically impacted by misspecification in the investment universe. Duplication invariance is introduced in [
11] and discussed in [
4]. A construction process is invariant to duplication if portfolios remain the same when an asset is listed twice in the investment universe. Minimum variance are duplication-invariant and highly concentrated. Equal-weighted portfolios are sensitive to duplication, although they consider correlations between assets. Measures of concentration and diversity are reviewed in [
20].
2.1.2. Using Entropy and Information Geometry for Portfolio Allocation
This study is related to the literature on using the entropy of the weights of a portfolio as a measure of diversification. Concentration measures, Shannon, Rényi and Tsallis entropy, and various divergence measures are reviewed in [
20] in the context of portfolio allocation. Controlling the Tsallis entropy of a portfolio allocation is a way to consider missing information [
9]. Shannon’s cross-entropy can be used in order to shrink an optimal portfolio towards a predetermined allocation [
28]. It can be used for optimizing portfolios based on their expected return [
29] or on higher-order moments [
30].
Another strand of the literature applies entropies to the distribution of financial returns. The Shannon entropy of the returns of a portfolio may be considered as a risk measure [
10]. Entropies of returns and weights may also be combined into a single optimization problem [
31,
32].
Optimal transport can be applied in order to measure the distance between the distribution of returns of a portfolio and a target distribution [
33,
34,
35]. It is also possible to use classical, Euclidean distances for controlling the tracking error of a portfolio [
36]; however, Euclidean distances do not account for the fact that weights of long-only portfolios cannot be negative.
2.2. Notations and Assumptions
In this study, portfolios are long-only. They are represented by n-dimensional vectors of positive weights . means that for all assets i. The sum of weights of a portfolio is called exposure. A fully-invested portfolio has an exposure of without financial leverage. In this case, x is an element of the -dimensional probability simplex . In this paper, is called ‘the simplex’. The open probability simplex—or open simplex—is the topological interior of the simplex. .
A long-only portfolio that is exposed to all assets with unconstrained exposure belongs to the set of positive measures. Normalizing portfolio means defining a new portfolio within the simplex as for all . Assets with positive weights are the support of the portfolio.
Risk budgets
b are elements of the simplex. Weights
are supposed to be positive. The case when
is discussed in
Section 2.7 and
Section 4.2. A divergence from portfolio
x to portfolio
b is noted
.
R is any risk measure that is differentiable on
, (positively) homogeneous of degree 1 and convex. The homogeneity condition means that risk must be proportional to portfolio exposure.
is assumed to be positive if
. Deviation risk measures [
22] are good candidates if they verify the differentiability criterion. Volatility is a deviation measure. Other risk measures, such as the conditional value-at-risk, can be used provided they are adjusted in such a way that
.
For any and positive numbers , ‘’ means that for all , .
2.3. Equal Risk Contributions and Risk Budgeting
This section is a more detailed review of the literature about the risk-budgeting approach to risk parity.
2.3.1. The Direct Approach
Risk budgeting aims to control the contribution of each asset to the risk of the portfolio. This approach is introduced in [
17] and thoroughly investigated in [
4]. For any allocation
y, let
be the risk of the corresponding portfolio. Euler’s decomposition applied to the homogeneous risk criterion implies that
, where risk contribution
is defined as:
Risk contributions are proportional to the exposure of the portfolio.
In equal risk contribution portfolios, the contributions equal each other. This approach can be extended to any percentage breakdown
of risk. For any weights
b from the open simplex, the risk-budgeting portfolio is defined for each asset
i by:
The weights
are the risk budgets. The risk-budgeting portfolio is the portfolio of exposure 1 that solves Equation (
2).
b is called the budget-weighted portfolio. When the budgets equal each other,
b is the equal-weighted portfolio.
In contrast, the risk contributions in minimum-risk portfolios are determined by the weights of the portfolio rather than by any risk budgets.
Equation (
3) is true even when the portfolio is long-only (see [
4] or
Appendix A). In this study, minimum-risk portfolios are always long-only. There may be multiple minimum-risk portfolios, unless risk measure
R is strictly convex on the simplex. This property is verified if volatility is the risk measure and if no assets are
-correlated.
Risk-budgeting portfolios can be found by numerically minimizing any differences between risk contributions and risk budgets under constrained exposure [
37]. They can also can be found by solving a variational problem.
2.3.2. The Variational Approach
As shown in [
3,
4], the solution
to the following optimization problem also solves the risk-budgeting Equation (
2):
This surprising property is established by minimizing the Lagrangian function:
As portfolios in problem (
4) have an unconstrained exposure, optimal portfolio
must be normalized. The resulting portfolio
also solves the risk-budgeting equation. Constraint
c can take any value, and all such values lead to the same normalized portfolio
(see
Appendix G for a proof in a more general setting).
There is an intuitive side to variational problem (
4). The nonlinear constraint involves a log-barrier function which increases to infinity when weights are too small [
38]. The variational approach to risk budgeting minimizes risk under a constraint that makes it impossible to leave any asset unallocated.
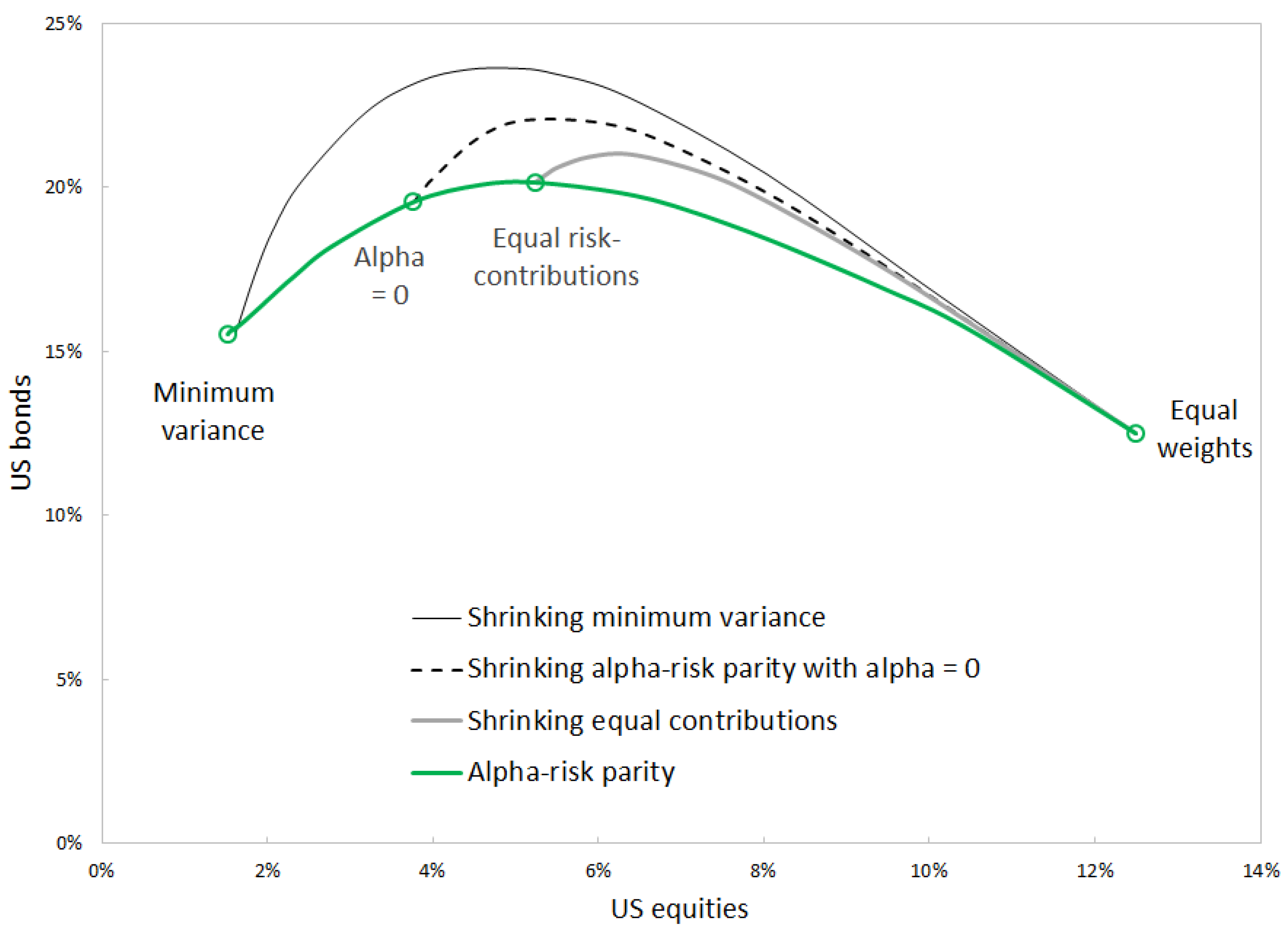
Starting with given risk budgets and iteratively applying the risk-budgeting procedure leads to the minimum-risk portfolio after an infinite number of iterations [
4]. When volatility is the risk measure, shrinking the covariance matrix forces equal risk contribution portfolios towards equal weights [
5]. The impact of shrinkage in risk parity portfolios and other portfolio construction processes is reviewed in [
39].
If volatility is the risk measure and assets are uncorrelated, the equal risk contribution portfolio is found by weighting each asset according to its volatility and normalizing the resulting portfolio. This rule also holds when correlation is constant across all pairs of assets (see [
4] or
Appendix D). With general risk budgets, risk-budgeting portfolios that involve uncorrelated assets are given by [
17]:
This formula does not extend to correlated assets unless all risk budgets are equal.
2.4. A Generalized Approach to Risk Budgeting
2.4.1. Using a Generalized Logarithm
Alpha risk parity is based on replacing the logarithm in program (
4) with the
q-logarithm, which was introduced by Tsallis in [
7]. For any entropic index
and any
, the
q-logarithm is defined by
if
and by
if
. If
and
, this definition can be extended to a finite value. If
, the
q-logarithm is defined for any value of
y. For any other values of
q and
y, the
q-logarithm is
. The same convention is applied to the natural logarithm.
In this study, the
q-logarithm is parametrized by
The reason for this change of parameter is related to self-duality and compatibility to Amari’s divergences, as discussed in Proposition 5 and in
Section 2.6.3.
The negative
q-log is always strictly decreasing. It is a closed and strictly convex function if
or equivalently if
. As shown in
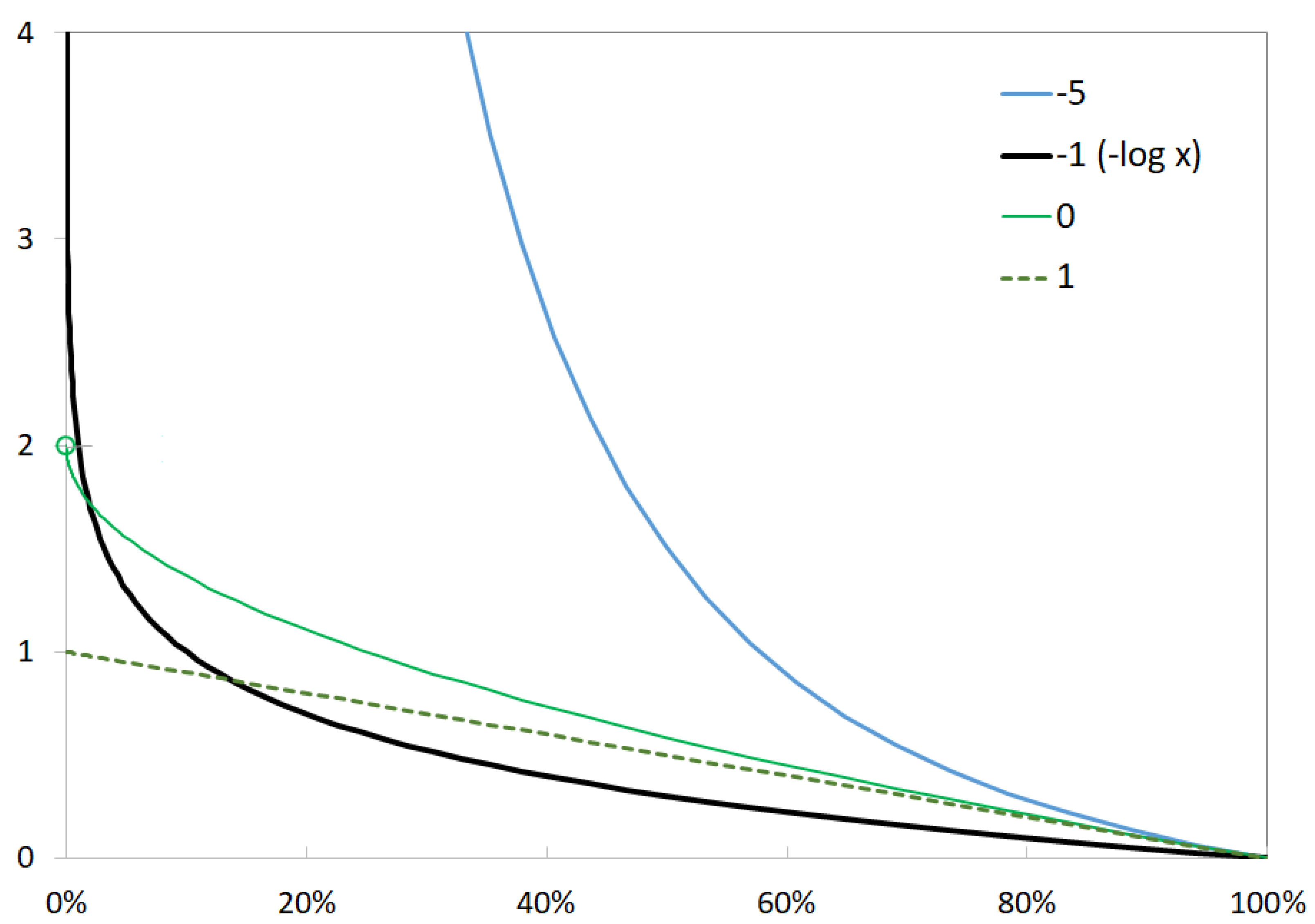
Figure 1, the negative
q-logarithm can be used as a log-barrier. With the parametrization in
, the function takes a finite value when
. It is affine when
.
The natural logarithm maps products into sums. This morphism property explains why risk-budgeting portfolios do not depend on the exact value of constraint
c in problem (
4). The
q-logarithm satisfies a quasimorphism property that is detailed in
Appendix B. The inverse of the
q-logarithm is the
q-exponential function
.
2.4.2. Introducing Alpha Risk Parity
Definition 1. For any and associated entropic index , for any constraint c such thatalpha risk parity is achieved by normalizing solutions toAlpha risk parity portfolios are given by . The set of admissible portfolios is denoted by . Strict convexity ensures uniqueness of and the alpha risk parity portfolio when . If , alpha risk parity leads to the minimum-risk approach. Risk budgeting is a particular case for .
In this definition, condition (
9) guarantees that the generalized constraint in problem (
10) is active. If this condition is not satisfied, the null portfolio is a solution to the optimization problem.
Constraint
c can be any negative number, because the negative
q-logarithm takes arbitrarily large negative values for large weights. As noted in
Appendix C, the properties of the
q-logarithm at 0 ensure that solutions to problem (
10) have positive weights. From a theoretical standpoint, constraints
may be taken out of the problem. However, these constraints can play a helpful role in numerical optimization.
For any
such that
, the alpha log-barrier is explicitly given for all
by:
can be extended by continuity on
respective to
y if
.
2.5. Properties of Alpha Risk Parity
2.5.1. A Simple Case
Proposition 1. Let be the volatility of asset i. When volatility is the risk measure and assets are uncorrelated, the alpha risk parity portfolio is Using
leads to the inverse-variance portfolio, which is also the minimum-variance portfolio. Risk budgeting corresponds to the case
, and Equation (
12) implies Equation (
6). If
, alpha risk parity converges to budget weighting
b.
With equal risk budgets, the alpha risk parity portfolio is determined by
Naive risk parity, which is achieved by taking
, amounts to volatility scaling. As observed in [
3], equal risk contribution is a compromise between equal weights and minimum variance. Alpha risk parity, which scales assets by a power of their volatility, connects the three portfolios by moving
from
to 1 in Equation (
13).
With equal risk budgets, alpha risk parity leads to equal weights if correlation and volatility are constant. When
, the optimal portfolio is given by Equation (
6) if the correlation is constant. Otherwise, no simple solution emerges—as noted in [
4,
17] in the case of risk budgeting.
2.5.2. Independence from the Constraint
As shown in Proposition A1, admissible sets associated with various constraints c can be uniformly scaled into each other.
Proposition 2. For any and associated entropic index , the optimal portfolios are proportional to each other. If c verifies condition (9),In the particular case of , there may be multiple solutions. Equation (14) establishes a mapping between the sets of solutions associated with constraints c and 0. After normalization, alpha risk parity portfolios do not depend on the exact value of constraint c.
Proposition 3. All constraints c that verify condition (9) lead to the same alpha risk parity portfolios. Proofs of Propositions 2 and 3 are detailed in
Appendix E. Proposition (3) shows that any admissible value of
c may be used for finding an alpha risk parity portfolio. In practical applications, using
is a sensible choice. The resulting optimization problem is summed up in the following proposition.
Proposition 4. Here is an explicit formulation of the alpha risk parity problem using :
For any , the alpha risk parity portfolios are found by normalizing the solution to optimization problem: For , the alpha risk parity portfolio is the risk-budgeting portfolio. It is found by normalizing the solution to: For , alpha risk parity portfolios are found by normalizing solutions to:
The exposure of the nonnormalized portfolio verifies for any value of α if .
The last assertion in Proposition 4 is a consequence of the strict convexity of the alpha log.
Proposition 5. Alpha risk parity portfolios satisfy a self-duality property for . Within this range, alpha risk parity portfolios associated with parameter are solutions to Changing the sign of α amounts to inverting the role of portfolios b and y in the optimization problem.
Proposition 5 follows from Proposition 3 and from the fact that if and are within the open simplex.
2.5.3. A Risk-Budgeting Equation for Alpha Risk Parity
The next proposition clarifies the link between risk budgets and reference weights
and extends risk-budgeting Equation (
2) beyond
.
Proposition 6. The risk contribution of any asset i in an alpha risk parity portfolio is given by:If , Equation (19) can be written as: The proof of this proposition is shown in
Appendix F. It follows the same line of reasoning as the one presented in
Section 2.3 for risk budgeting. Proposition 6 has a few interesting consequences:
If
, Equation (
19)
. This is the risk-budgeting Equation (
3) of minimum-risk portfolios.
If
, Equation (
19)
. Alpha risk parity amounts to risk budgeting (see Equation (
2)).
If
, Equation (
20) converges to
. Budget weighting is a limit case of alpha risk parity.
The weights
play a double role in risk-budgeting Equation (
19). They are risk budgets that partially control risk contributions. If
and
, they also act as a reference portfolio because weights
are compared with the
. This point is clarified in
Section 2.6. Using
strengthens the role of
b as a reference portfolio because any below-budget allocation leads to explosive risk contributions. Using
weakens the role of
b as a reference portfolio and as risk budgets. By adjusting
, investors can determine how much they want to control portfolio weights and risk budgets.
Risk-budgeting Equation (
19) may be used as a starting point to finding an alpha risk parity portfolio. However, the variational approach makes it possible to use numerical convex optimization and makes it easier to establish the uniqueness of the solution.
2.6. Utility Maximization under Divergence Constraint
2.6.1. Risk Budgeting Portfolios and Maximum Utility
As noted in [
40], ‘risk parity is not a traditional mean-variance objective function’. However, the risk parity—or risk-budgeting—problem is a form of utility maximization because the variational approach (
4) minimizes a risk criterion. If this criterion is compatible with a utility function, then risk budgeting maximizes a utility function. Minimizing volatility amounts to maximizing a quadratic von Neumann–Morgenstern expected utility function with
expected returns. Minimizing a spectral risk measure amounts to maximizing an expected rank-based utility function [
2,
41].
Risk budgeting differs from traditional utility maximization because the portfolio in a variational problem (
4) is optimized with unconstrained exposure. Optimizing with unconstrained exposure and normalizing afterwards implicitly assumes unlimited financial leverage. However, Refs. [
3,
4] show that equal risk contributions and risk budgeting solve a risk-minimization problem with constrained exposure.
Here is an outline of the proof. The portfolio
that solves problem (
4) is optimal among admissible portfolios of all exposures. It is also optimal among those whose exposure is equal to
. Using change of variable
, normalized portfolio
solves the following problem among portfolios of exposure 1:
In this problem, constraint
d must be set to
. Using
leads to:
In problem (
21), the portfolio is optimized over the probability simplex. Therefore, using the logarithmic constraint amounts to controlling the Kullback–Leibler divergence
from portfolio
x to portfolio
b.
In the theory of divergence functions, the Kullback–Leibler divergence is the
f-divergence associated with the negative logarithm.
Appendix H contains a brief summary on this account.
Formulation (
21) is of little practical use because determining the divergence constraint requires prior knowledge of the exposure of the optimal portfolio. However, this formulation shows that risk budgeting is a rational approach to investing. When using the right risk criterion, risk budgeting maximizes a utility function with constrained exposure and constrained divergence to portfolio
b. The risk budgets
play the role of a reference portfolio, and divergence is constrained using a nonsymmetric statistical divergence function.
As noted in [
3,
17], the risk of optimal portfolio defined by (
21) decreases with constraint
d. It is maximal when
and the portfolio is equal to the budget-weighted portfolio
b. It is minimal when
. Risk budgeting is a compromise between these two extremes.
2.6.2. Beyond Kullback–Leibler
The reasoning of
Section 2.6.1 can be extended to alpha risk parity.
Proposition 7. For any and associated entropic index q, let the exposure of optimal, nonnormalized portfolio andAlpha risk parity portfolios solve the following risk-minimization problem with constrained exposure: Proofs of these propositions are detailed in
Appendix G.
Using the
q-logarithmic constraint in problem (
25) amounts to controlling the
q-divergence
from portfolio
x to portfolio
b.
The
q-divergence [
42], which is also known as quantum
q-divergence [
43], is the
f-divergence associated with
for
. For
, the
q-divergence is formally defined as
. It is not a divergence function due to a lack of strict convexity.
The
q-divergence associated with
—or
—is symmetric. For
, it is related to the Hellinger distance
h (see Equation (
A14)) by
When using the right risk criterion, alpha risk parity maximizes a utility function with constrained exposure. If , deviations respective to portfolio b are controlled using a statistical divergence. In this case, the risk budgets play the role of a reference portfolio.
2.6.3. Alpha Risk Parity and Alpha Divergences
For
, multiplying both sides of Equation (
26) by
shows that alpha risk parity is constrained according to
is an extension of the negative logarithm that was introduced by Amari [
8]. If
,
. If
, for all
,
For any value of
,
is a strictly convex function.
is the
f-divergence associated with
. It is known as Amari’s alpha divergence.
Therefore, alpha risk parity also minimizes risk under constrained alpha divergence. Why this matters is twofold. Alpha divergences are the only flat divergences defined on the set of positive measures (see
Appendix H). In comparison, the Kullback–Leibler divergence and its dual are the only flat divergences defined on the simplex. Alpha risk parity, which is based on the alpha divergence, is a natural extension of risk budgeting.
Furthermore, alpha divergences are also defined for . In contrast, q-divergences are only defined for in the -parametrization. In the particular case of alpha risk parity, using functions instead of the negative q-logarithm does not bring much because is a strictly increasing function when . In this case, the null portfolio is the only solution to problem .
However, alpha divergences can be useful tools for controlling the allocation of more general maximum-utility portfolios. Some authors have proposed penalizing portfolios by the sum of squared weights [
9,
31]. This constraint does not belong to the family of
q-divergences. However, taking
and using equal risk budgets leads to
. Therefore, Amari’s alpha divergences can be used in order to extend the approach proposed in [
9] to more general reference portfolios. The cross-entropy used in [
28] can also be extended using an alpha divergence.
2.7. What Happens if Some Risk Budgets Are Equal to Zero?
It may be interesting to consider an investment universe that goes beyond the list of assets with a positive risk budget [
4]. This problem can be approached by allocating a risk budget
to some—but not all—assets in the universe. Divergences and log-barriers are based on assets with a positive risk budget. The variational approach to alpha risk parity combines one portfolio that is constrained by an alpha log-barrier with another that is managed similar to a minimum-risk portfolio. A common risk criterion is applied to the two portfolios.
Due to the logarithmic barrier, the allocation to assets with a positive risk budget cannot be too small. Assets with no risk budget are essentially allocated without any constraint. They enter the portfolio only if they contribute to a decrease in risk.
In terms of risk-budgeting formulas, assets with a positive risk budget verify the equation of alpha risk parity portfolio (
19). Other assets verify minimum-variance Equation (
3). Risk budgets must be summed over all assets.
3. Materials and Methods
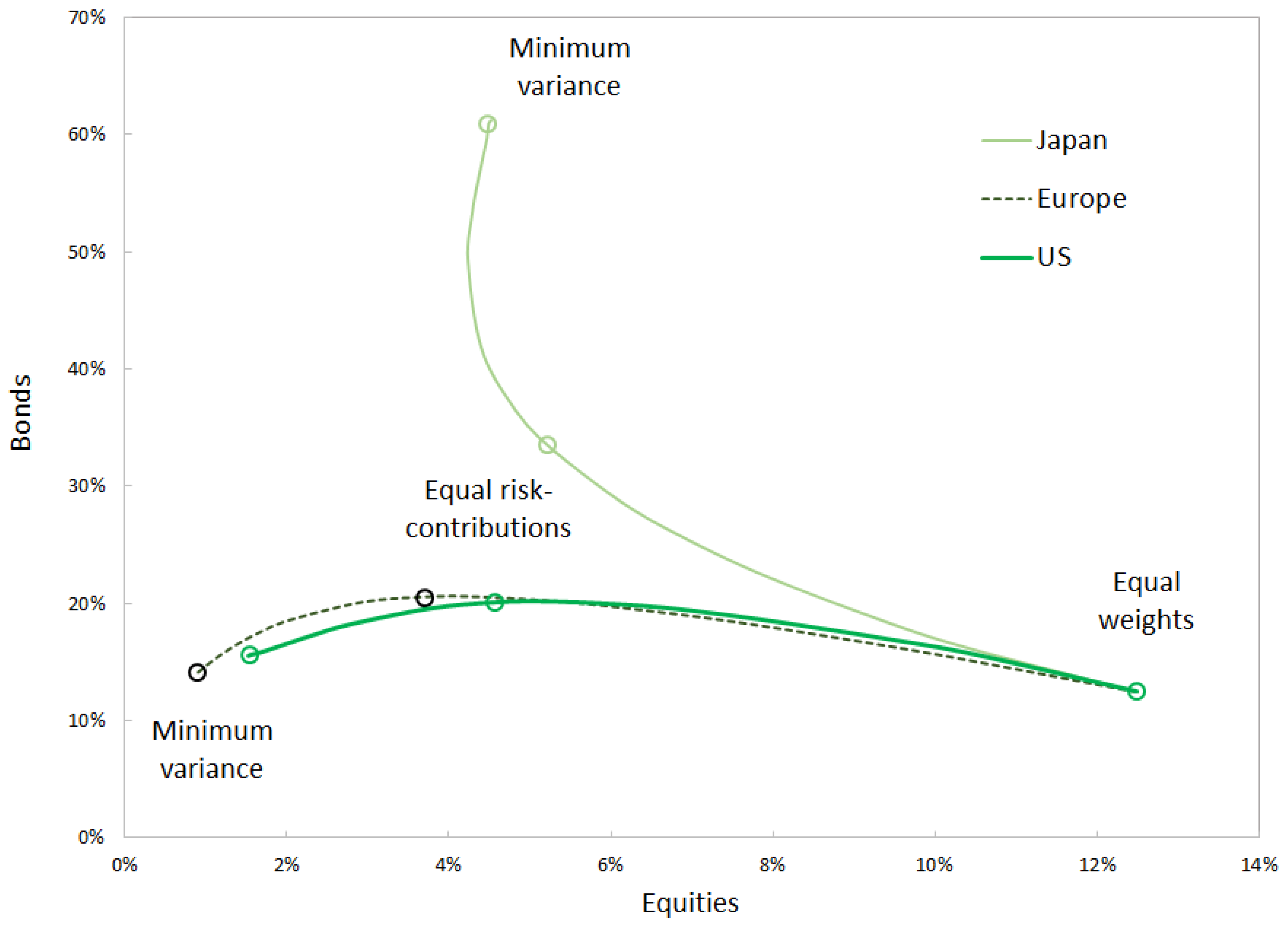
The alpha risk parity algorithm is applied to a dataset that starts in January 1994 and ends on 10 August 2022. At each trading date, a risk-budget portfolio
b is constructed by applying equal weights to the multi-asset reference universe shown in
Table 1.
The indices represent the return received or paid when rolling financial futures. All returns are excess returns in US dollars. They do not consider the additional return that may be earned by investing the capital in money markets.
Portfolios are constructed using the optimization problem described in Proposition 4 with equal risk budgets. Any remarks about equal weights and equal risk contributions also apply to more general budget-weighting and risk-budgeting portfolios.
Calculations are run using Python 3.7.6. Numerical optimization relies on the SLSQP algorithm as implemented in the SciPy library. The variance of the portfolio is the optimization criterion. Its Jacobian is used in the algorithm. The maximum number of iterations is and the algorithm is stopped using a precision of .
If , the negative alpha-log takes a finite value at 0 with an infinite slope. This combination may lead to numerical instabilities when using gradient methods. When is close to , the derivative exerts a repulsion force as soon as any weight decreases too much. When is close to 1, the constraint becomes almost linear. Numerical instabilities arise in the middle, when alpha is close to 0. Portfolio weights are constrained to be higher than in order to avoid numerical instability.
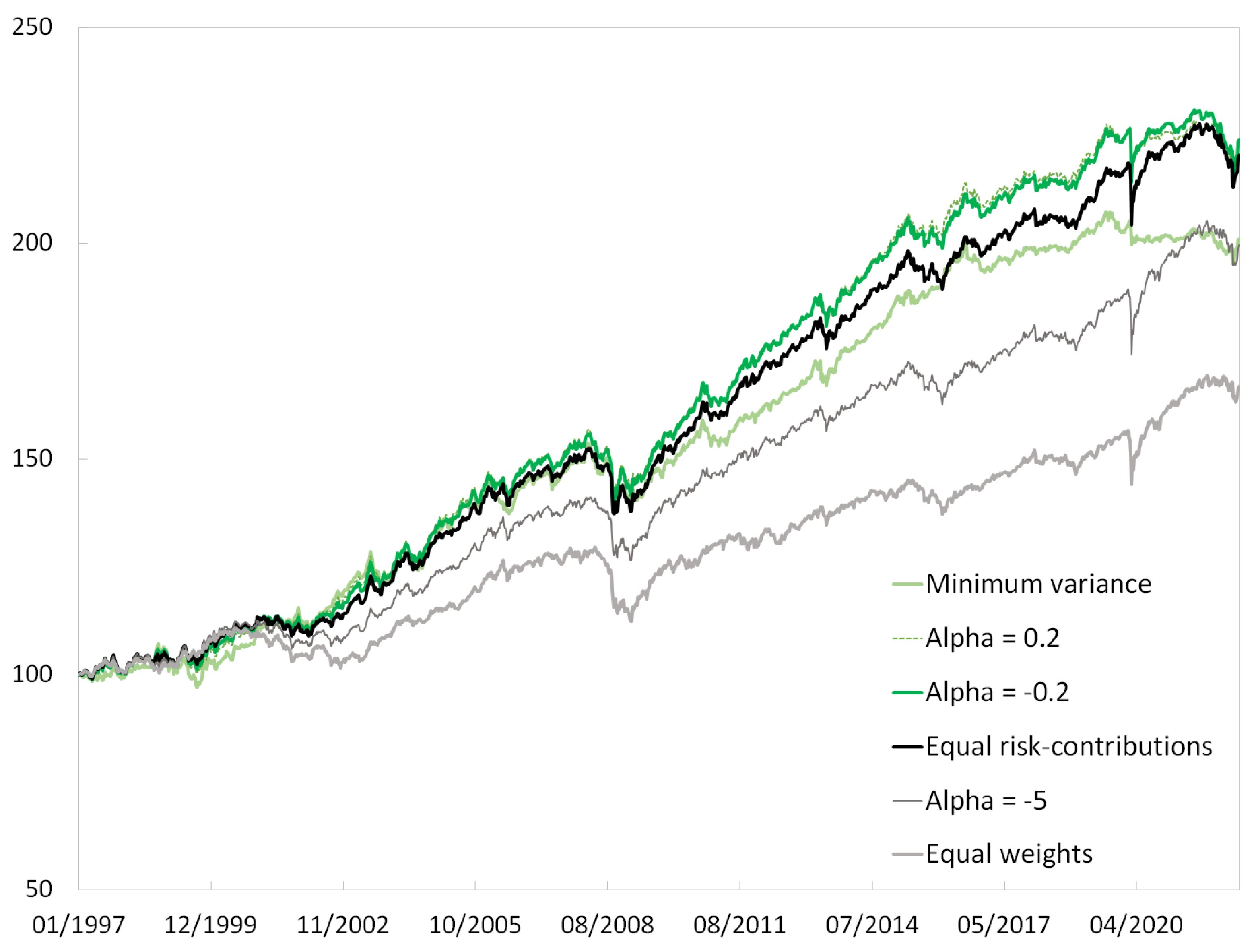
This study relies on weekly returns. For some figures and tables that illustrate portfolio weights, covariances are estimated over a period of time that is specified in the title or footnotes. For simulating risk and returns, portfolios are rebalanced every four weeks with a lag of one week. A first portfolio is selected on Wednesday 1 January 1997 and traded one week later at the close. Volatility is the risk measure, and sample covariance matrices are estimated on data from the previous 156 weeks—approximately 3 years. Portfolios are simulated iteratively with no look-ahead bias.
The risk and return of a simulated portfolio are measured using data from the start of the simulation in January 1997 to the end, in August 2022. The Sharpe ratio is the ratio of excess returns to annualized volatility. CVaR is the conditional value-at-risk for a quantile of
[
2]. Max drawdown is the maximum observed loss from peak to trough as a percentage of peak value [
44]. Turnover is the average of absolute rebalancing as a percentage of the notional of the portfolio and over all monthly trading dates.
The diversity of a portfolio is measured using the negative Shannon entropy of weights. Duplication invariance, or lack of it, is identified using the following indicator:
Definition 2. For any portfolio construction process that leads to a portfolio y and for any asset i in a universe of n assets, the individual sensitivity to duplication is defined by duplicating asset i in the universe and finding an optimal portfolio in the universe of assets. The weights respective to the asset and its duplicate are then added. This new portfolio of n assets is noted . The individual sensitivity to duplication is the Hellinger distance (see Equation (A14)) between the two portfolios. The duplication sensitivity of the portfolio is the average of these individual sensitivities: In the case of alpha risk parity with , the optimization problems with duplication have a unique solution because the constraint on is strictly convex. In the case of minimum-risk portfolios, the solution is not unique. However, all solutions lead to the same allocations once exposures to duplicated assets are merged.
Covariance shrinkage—when applied—refers to measuring covariance using the following formula:
.
is the matrix of covariances measured over a given time window.
is the identity matrix with as many entries as assets in the investment universe. An optimal estimator for
k is proposed in [
45]. Following [
5], covariance is shrunk towards the identity matrix by increasing
k from 0 to 1.
5. Discussion
Alpha risk parity leads to a continuum of portfolio optimization problems that includes risk budgeting (or equal risk contributions in the particular case of equal reference weights), minimum risk, and converges to the budget-weighted portfolio as a limit case. This observation confirms and complements earlier findings on risk budgeting being a compromise between the two other approaches [
3,
4]. Within the framework of alpha risk parity, all portfolios from the continuum verify a closed-form risk-budgeting equation. Moreover, risk budgeting is associated with a well-identified parameter—
.
Another continuum was identified in [
5]. That continuum results from covariance shrinkage and does not connect the three portfolios. Any alpha risk parity portfolio can be brought closer to a reference portfolio by using covariance shrinkage or by decreasing the value of
. While optimal levels of covariance shrinkage have been proposed [
45], a theory for determining the optimal level of
remains to be built. However, optimal covariance shrinkage relies on a number of assumptions that are not always verified in practice. Determining how to exactly determine optimal shrinkage has been subject to debate [
46].
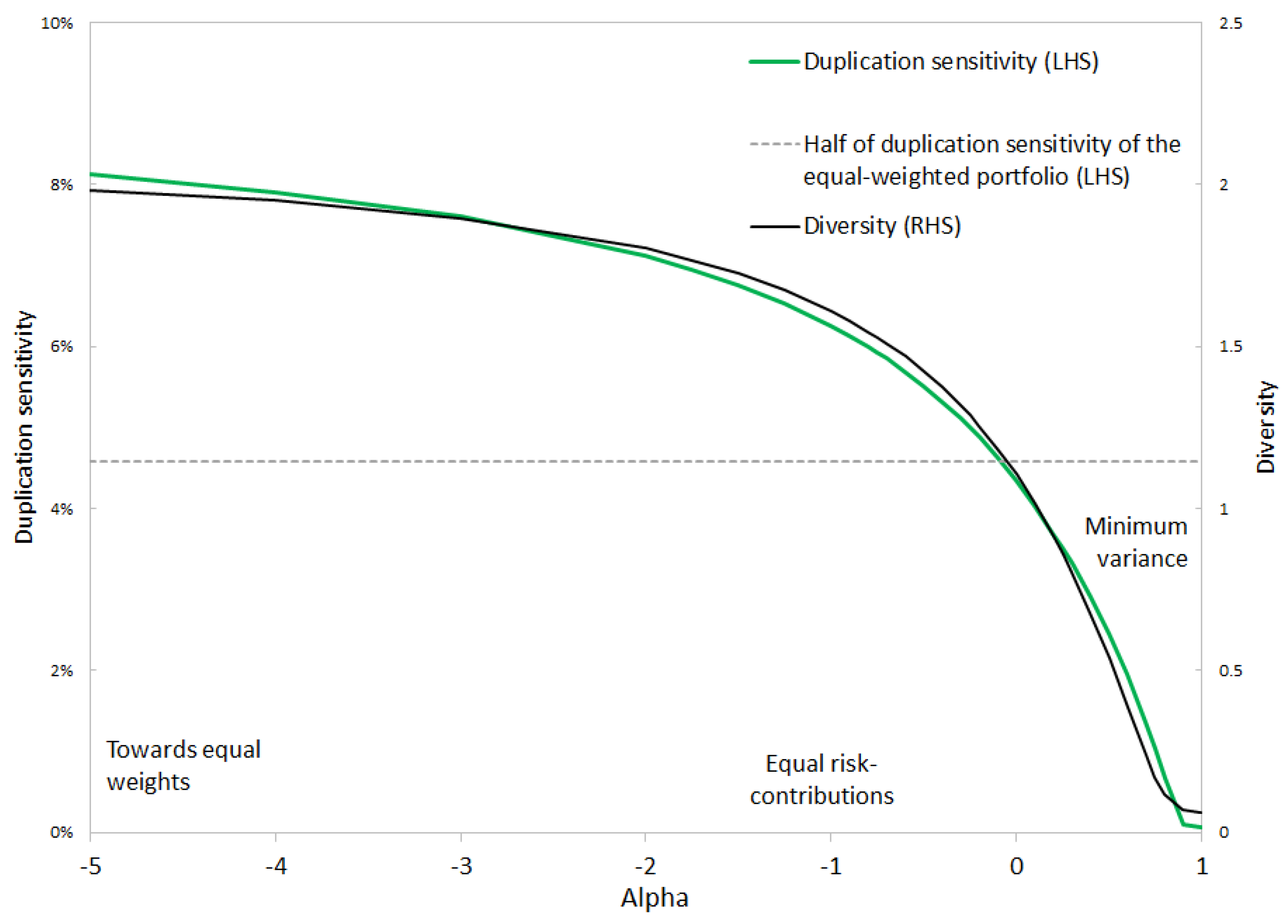
Within the framework of alpha risk parity, optimal alpha can be determined geometrically—for example, by starting with the minimum-variance portfolio and looking for the value of that reduces entropy by half. Alternatively, duplication sensitivity may be used as a criterion.
From this standpoint, it is interesting to note that the risk-budgeting portfolio is not an entirely balanced compromise between minimum risk and the budget-weighted portfolio. If the latter portfolio is not optimal in terms of risk and returns—and the odds are that it is not—then the risk-budgeting portfolio may not be optimal either. Within the framework of alpha risk parity, increasing
is a simple means of decreasing aversion to small weights and giving a bigger role to risk optimization. At the other end of the scale, unfettered risk minimization leads to excessive concentration and high tail risk. As mentioned in [
9], the available statistical information is not likely to be perfect. Therefore, some form of compromise is needed.
Following [
4], another alternative may be to apply the risk-budgeting algorithm iteratively. It may be interesting to compare this approach with that of alpha risk parity. Lack of granularity in the iterative allocation may make it difficult to identify the right level of
. Moreover, iteration comes at a cost in terms of numerical complexity. In contrast, alpha risk parity is easily solved using the same numerical techniques that are involved in risk budgeting.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}