



Template Attack of LWE/LWR-Based Schemes with Cyclic Message Rotation

Abstract
1. Introduction
- Considering the vulnerability proposed in [11], we present a message recovery attack of LWE/LWR-based schemes. Our method aims at the decoding operation in the decapsulation procedure and recovers the secret message, as well as the shared key, using the cyclic message rotation property in template style.
- We use the Hamming weight (HW) model to construct a classifier for the templates and construct specific ciphertexts using cyclic message rotation to reduce the number of power traces needed in the template-matching phase.
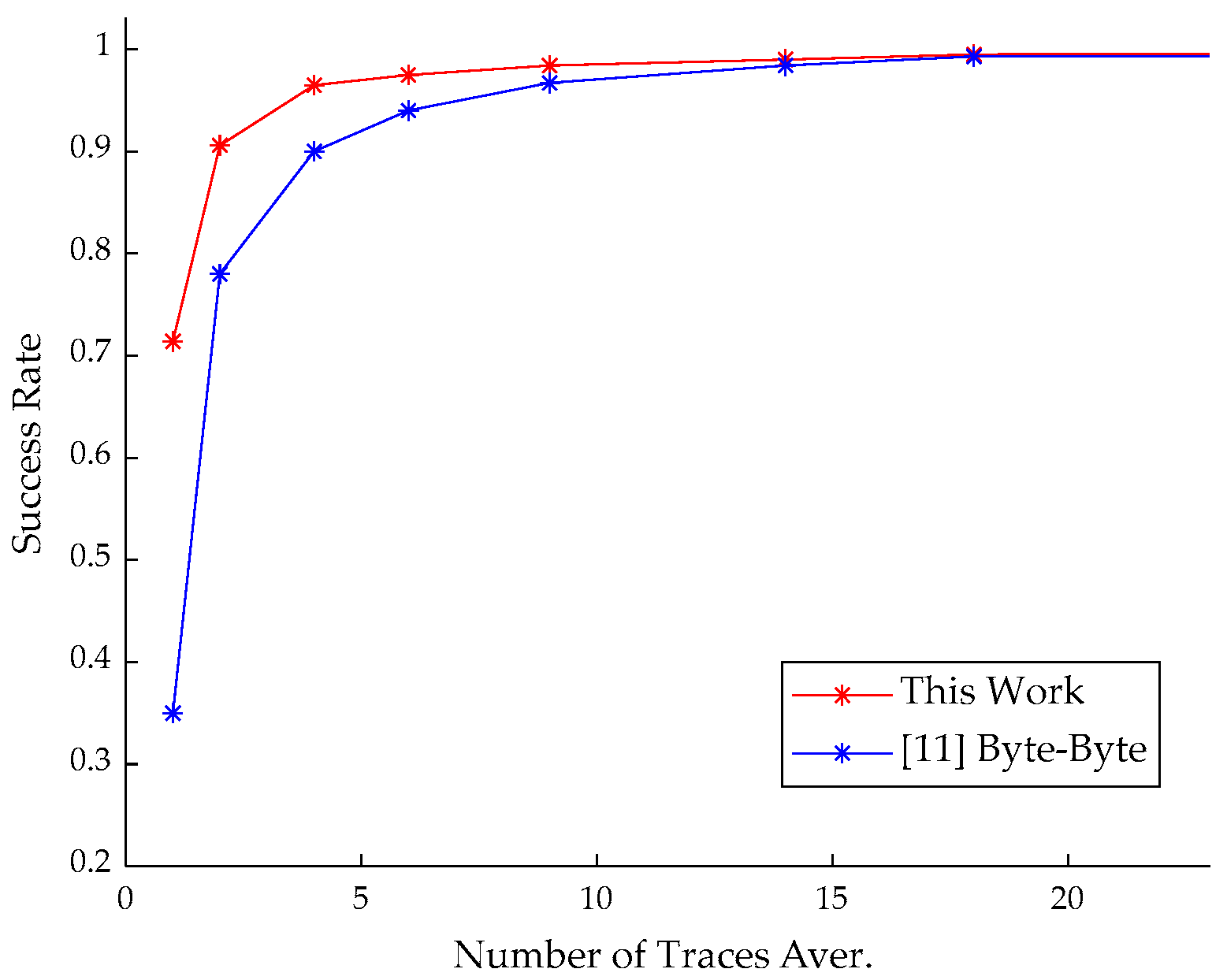
- We provided details of the specific attack and implemented the message recovery attack for CRYSTAL-Kyber with an ARM Cortex-M4 microprocessor. Compared with previous results, the power traces required for constructing the templates were reduced and the success rate for recovery of the message was greatly improved with the same signal-to-noise ratio (SNR), indicating better performance at lower cost.
- The main findings of this paper are summarized and compared to the existing literature. We also briefly illustrate the feasibility and validity of applying our message recovery attack to other schemes.
2. Preliminaries
2.1. Notations
2.2. LWE/LWR Problem
| Algorithm 1 IND-CPA PKE Encryption (simple ver.) |
| Input public key pk = (||seedA); message m; randomness r Output ciphertext c 1: A = GenerateA(seedA) 2: sample s, e1, e2 3: u = A × s + e1 4: v = × s + e2 + Encode(m) 5: c1 = Decode(u), c2 = Decode(v) 6: return c = (c1c2) |
| Algorithm 2 IND-CPA PKE Decryption (simple ver.) |
| Input private key sk; ciphertext c = (c1c2) Output message m′ 1: u = Encode(c1), v = Encode(c2) 2: = Encode(sk) 3: m′ = Decode(v − ( × u)) 4: return m′ |
| Algorithm 3 IND-CCA KEM Encapsulation |
| Input public key pk Output ciphertext c; shared key K 1: randomly chosen m 2: m = H(m) 3: (, r)= G(m, pk) 4: c = IND-CPA PKE Encryption(pk, m, r) 5: K = KDF(||H(c)) 6: return K |
| Algorithm 4 IND-CCA KEM Decapsulation |
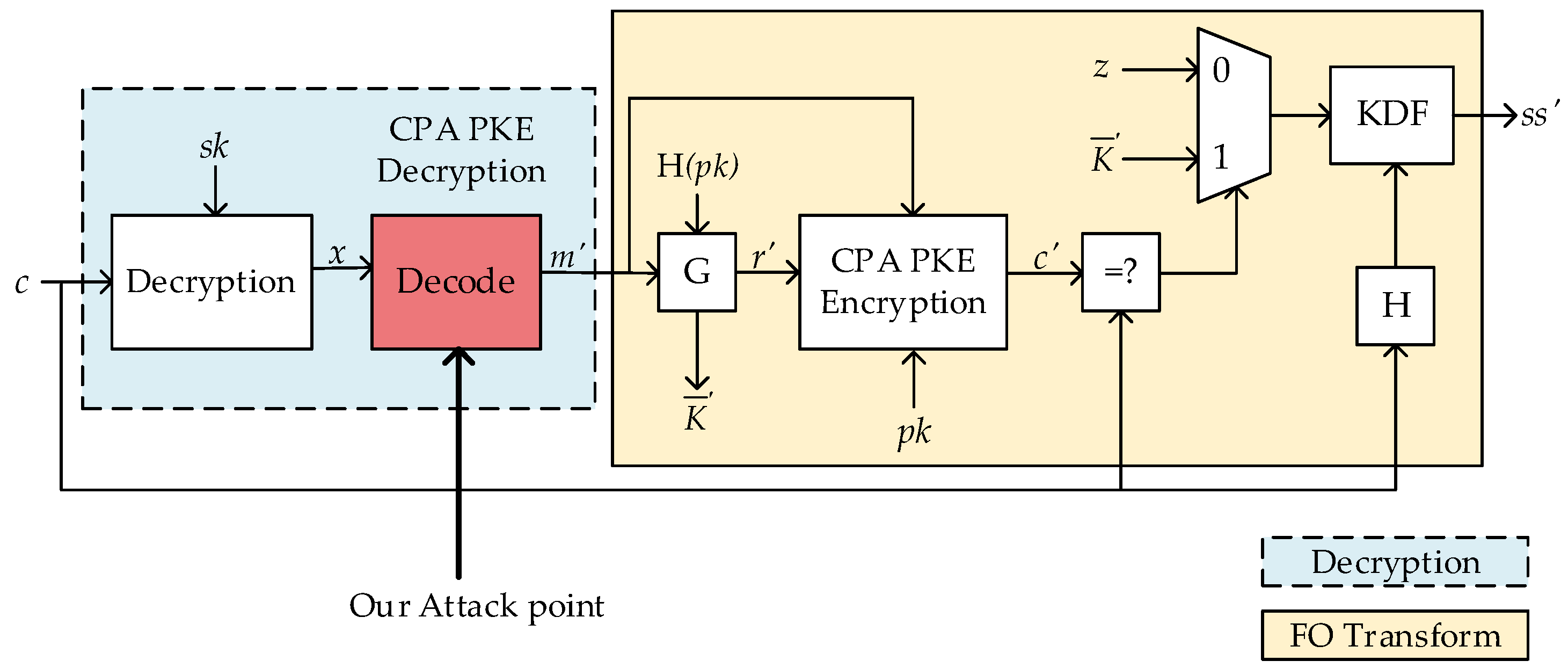
| Input private key skKEM = (sk, pk, H(pk), z); ciphertext c Output shared key K 1: m′ = IND-CPA PKE Decryption(sk, c) 2: (, r′) = G(m′, H(pk)) 3: c′ = IND-CPA PKE Encryption(pk, m′, r′) 4: if c′ = c return K = KDF(||H(c)) 5: else return K = KDF(zH(c)) |
2.3. Test Vector Leakage Assessment (TVLA)
2.4. Normalized Inter-Class Variance (NICV)
3. Vulnerability in Message Decoding of LWE/LWR-Based KEM
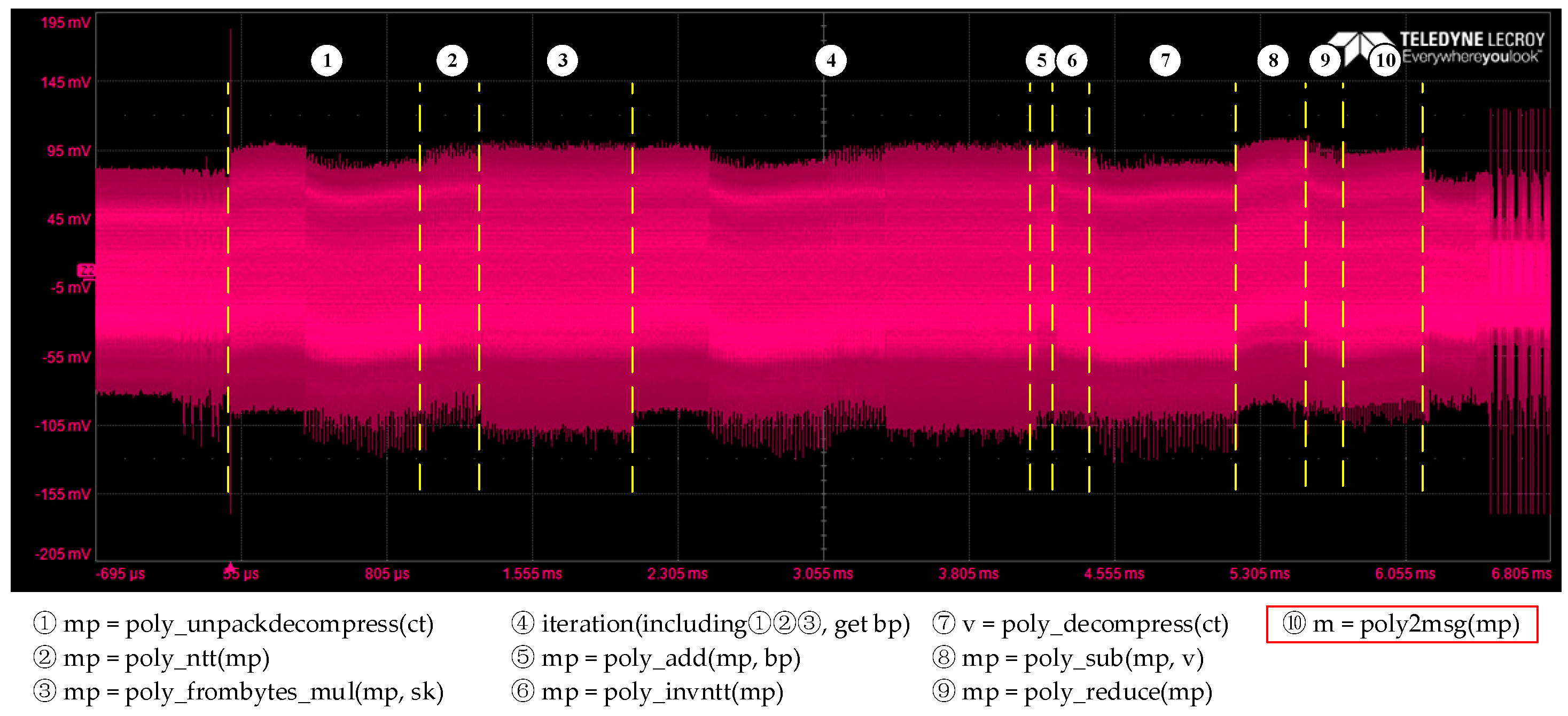
| Algorithm 5 CRYSTAL-Kyber poly2msg |
| 1 void poly2msg(uint8_t *m, const poly *a) 2 { 3 size_t i, j; 4 uint16_t t; 5 for (i = 0; i < CRYSTAL-KYBER_N / 8; i++) 6 { 7 m[i] = 0; 8 for (j = 0; j < 8; j++) 9 { 10 t = a->coeffs[8 * i + j]; 11 t += ((int16_t)t >> 15) & CRYSTAL-KYBER_Q; 12 t = (((t << 1) + CRYSTAL-KYBER_Q / 2) / CRYSTAL-KYBER_Q) & 1; 13 m[i] |= t << j; 14 } 15 } 16 } |
4. Message Recovery Attack Method
4.1. Data Preprocessing
4.1.1. Leakage Detection
- Collect the power traces. Collect two sets of l power traces for CT0 and CT1, denoted as T0 and T1, respectively, with T = T0∪T1.
- Normalize the measured power traces. The influence of the environment is reduced by removing the mean of each trace in the measurement sets, i.e., , where represents the mean of ti with ti ∈ Tj for i ∈ [0, l-1] and j ∈ {0,1}.
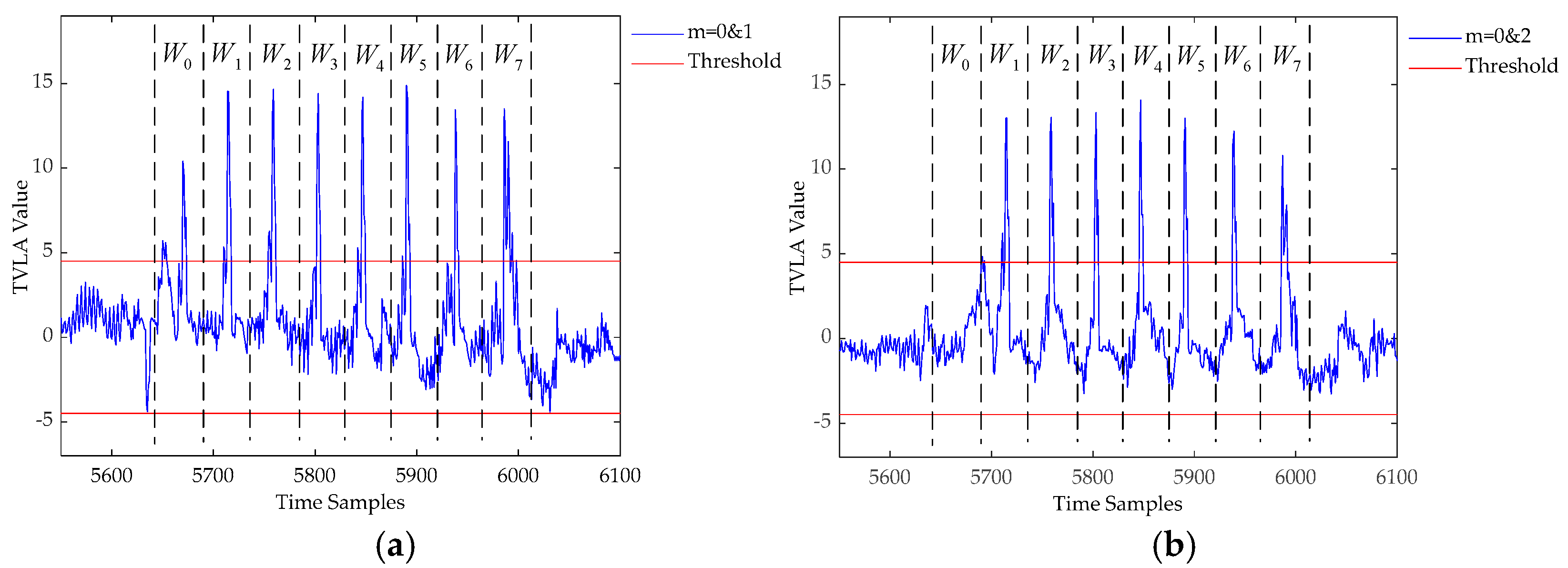
- Identify the PoIs of the measurement sets. Use Equation (1) to calculate the TVLA between the two measurement sets. If the absolute value of the calculated TVLA is greater than the threshold Thsel, then there is a considerable discrepancy between the two measurement sets at this point, which may have leakage.
4.1.2. Template Construction
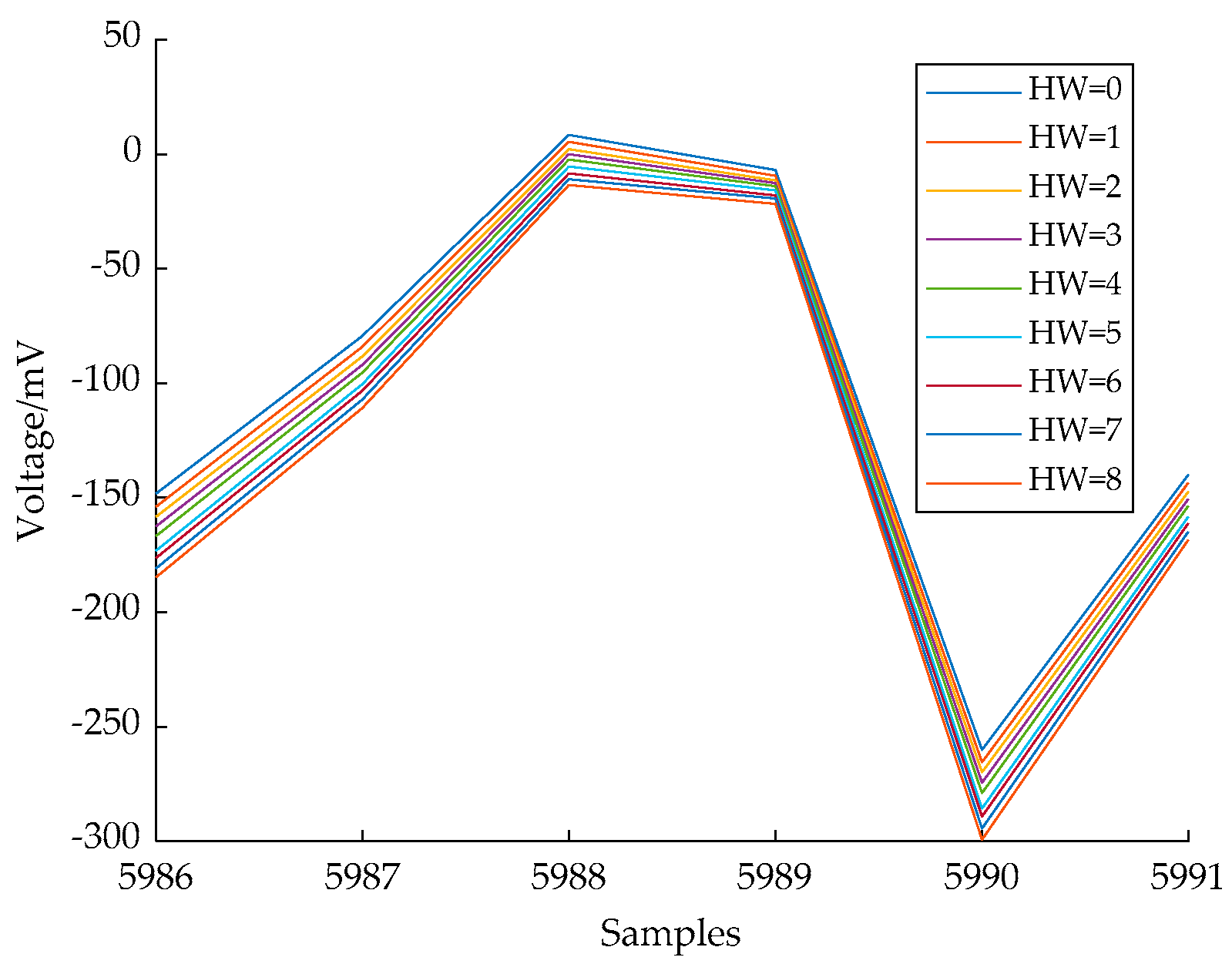
- Build the ciphertext sets for k ∈ [0, j + 1] and j ∈ [0, 7] with m[0] satisfying HW(m[0, j]) = k for decapsulation, while the remaining bytes except m[0] are chosen randomly. Denote the collected power traces as .
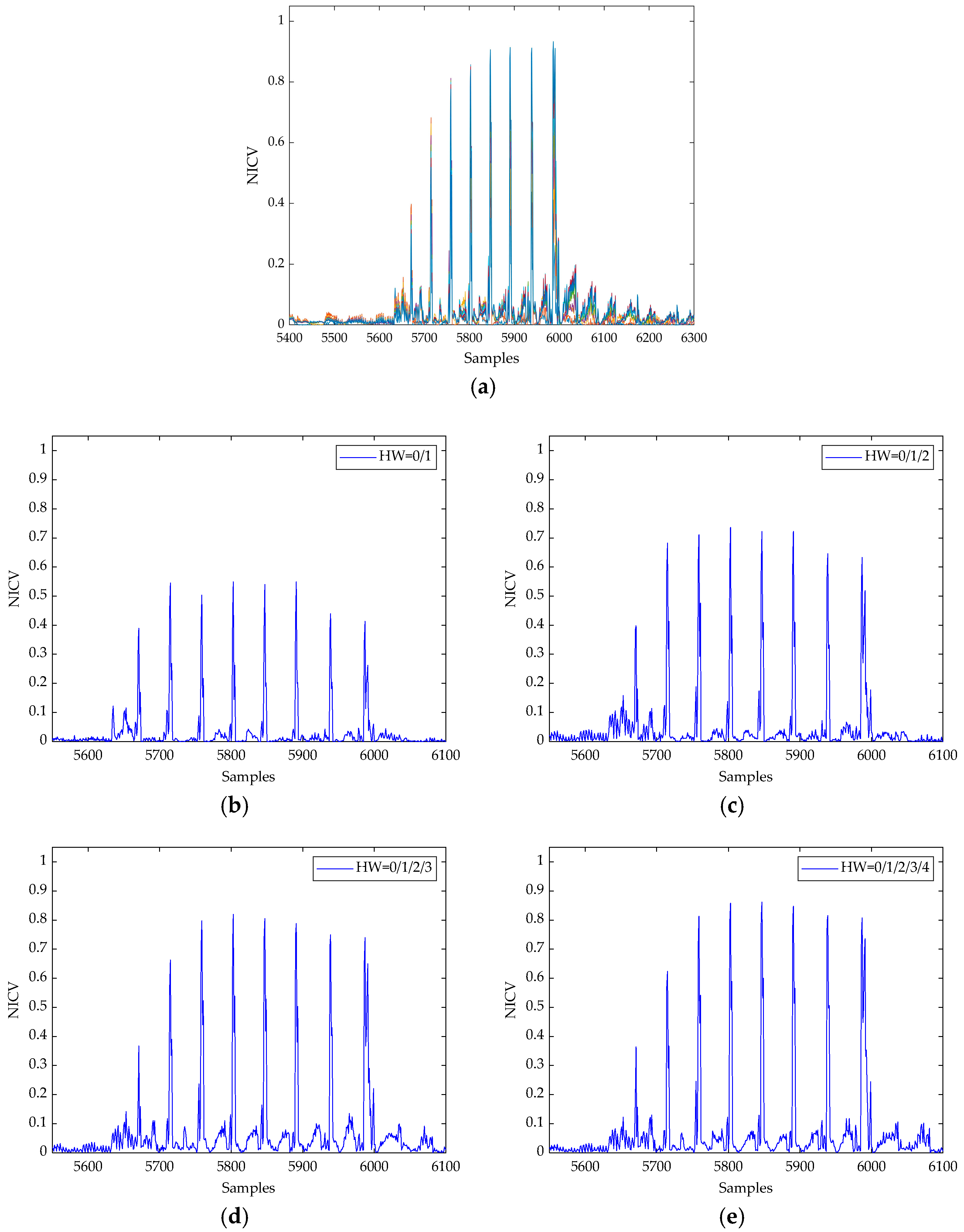
- Calculate the NICV over to distinguish different HW(m[0, j]), and select the points whose value of NICV in Wj is greater than a certain threshold of PoIs denoted as p(0, j).
- Construct the reduced trace sets according to p(0, j) and calculate the mean of , denoted as , which is the reduced template of each classification, so (j + 2) templates will be constructed at the jth iteration.
4.2. Template Matching
4.2.1. Cyclic Message Rotation
4.2.2. Template Matching
- Decapsulate the given ciphertext c and collect the corresponding power trace denoted as tr. Normalize tr according to the template-construction process (see Setp2 in Section 4.1.1) and establish the reduced traces denoted as trj′ according to the p(0, j) for j ∈ [0, 7].
- Calculate the sum of squared difference (SOSD) between trj′ and the reduced templates of each class , denoted as SOSDk:We can assign HW(m[0, j]) = k based on the smallest value of SOSDk and then derive mj according to Equation (4).
- Construct different ciphertexts denoted as cti for i ∈ [1, n−1] for a given valid ciphertext ct with cycle message rotation and repeat Step1 and Step2 to obtain HW(m[i, j]) and then derive m[i].
| Algorithm 6 Our Message Recovery Attack |
| 1 Preprocessing Stage 2 for j = 0 to 7 do //collect traces for template construction 3 for k = 0 to j + 1 do 4 = IND-CCA KEM Decapsulation() 5 end for //leakage detection 6 Wj = TVLA(,) //choose PoIs 7 p(0, j) = NICV(Wj, ,…, ) //template construction 8 for k = 0 to j + 1 do 9 =(p(0, j)) 10 = mean() 11 end for 12 end for 13 Template Matching Stage 14 for i = 0 to n -1 do //construct special ciphertexts 15 cti = Construct(ct, i) //collect traces for attack 16 tri = IND-CCA KEM Decapsulation(cti) 17 for j = 0 to 7 do //reduced traces 18 tr(i, j)′ = tri(p(0, j)) 19 for k = 0 to j + 1 do 20 = SOSD(tr(i, j)′, ) 21 end for //calculate the HW of intermediate value 22 HW(m[i, j]) = min() //recover the message byte 23 m[i]j = F(HW(m[i, j]), HW(m[i, j] − 1)) 24 end for 25 end for |
5. Experiments and Evaluation
5.1. Experimental Setup
5.2. Leakage Detection
5.3. Template Construction and Matching
5.4. Experimental Results
6. Possible Countermeasures
- Masking: Masking splits the secret information into multiple independent variables to achieve security. Masking the decapsulation stage can protect against our attack. However, masking the decapsulation stage may be costly in performance, so low-cost, but efficient, masking strategies are needed.
- Shuffling: Shuffling uses a random permutation of a finite sequence to scramble the order of process, which removes the linear correlation between the process sequence and time.
- Dummy Steps or Random Jitter: Adding dummy steps or random jitter will disturb the alignment of PoIs, thus, more attack costs are implied.
- Combination of above methods: A combination of methods increases the trace requirement for the attack and may result in a better protection effect.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- NIST. Post-Quantum Cryptography: Post-Quantum Cryptography Standardization. Available online: https://csrc.nist.gov/Projects/Post-Quantum-Cryptography/Post-Quantum-Cryptography-Standardization (accessed on 3 January 2021).
- Kocher, P.; Jaffe, J.; Jun, B. Differential Power Analysis. In Advances in Cryptology—CRYPTO’ 99. CRYPTO 1999. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1666. [Google Scholar] [CrossRef]
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. J. ACM 2009, 56, 1–40. [Google Scholar] [CrossRef]
- Banerjee, A.; Peikert, C.; Rosen, A. Pseudorandom Functions and Lattices. In Advances in Cryptology—EUROCRYPT 2012; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 7237. [Google Scholar] [CrossRef]
- Primas, R.; Pessl, P.; Mangard, S. Single-Trace Side-Channel Attacks on Masked Lattice-Based Encryption. In Cryptographic Hardware and Embedded Systems—CHES 2017. CHES 2017; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10529. [Google Scholar] [CrossRef]
- Pessl, P.; Primas, R. More Practical Single-Trace Attacks on the Number Theoretic Transform. In Progress in Cryptology—LATINCRYPT 2019. LATINCRYPT 2019; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11774. [Google Scholar] [CrossRef]
- Aydin, F.; Aysu, A.; Tiwari, M.; Gerstlauer, A.; Orshansky, M. Horizontal Side-Channel Vulnerabilities of Post-Quantum Key Exchange and Encapsulation Protocols. ACM Trans. Embed. Comput. Syst. 2021, 20, 1–22. [Google Scholar] [CrossRef]
- Ravi, P.; Sinha Roy, S.; Chattopadhyay, A.; Bhasin, S. Generic Side-channel attacks on CCA-secure lattice-based PKE and KEMs. IACR Transac. Cryptogr. Hardw. Embed. Syst. 2020, 3, 307–335. [Google Scholar] [CrossRef]
- Hamburg, M.; Hermelink, J.; Primas, R.; Samardjiska, S.; Schamberger, T.; Streit, S.; Strieder, E.; Vredendaal, C. Chosen Ciphertext k-Trace Attacks on Masked CCA2 Secure Kyber. IACR Transac. Cryptogr. Hardw. Embed. Syst. 2021, 4, 88–113. [Google Scholar] [CrossRef]
- Ngo, K.; Dubrova, E.; Guo, Q.; Johansson, T. A Side-Channel Attack on a Masked IND-CCA Secure Saber KEM Implementation. IACR Transac. Cryptogr. Hardw. Embed. Syst. 2021, 4, 676–707. [Google Scholar] [CrossRef]
- Ravi, P.; Bhasin, S.; Sinha Roy, S. Drop by Drop You Break the Rock—Exploiting Generic Vulnerabilities in Lattice-Based PKE/KEMs Using EM-Based Physical Attacks. Available online: https://eprint.iacr.org/2020/549 (accessed on 23 December 2021).
- Amiet, D.; Curiger, A.; Leuenberger, L.; Zbinden, P. Defeating NEWHOPE with a Single Trace. In Post-Quantum Cryptography. PQCrypto 2020; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12100. [Google Scholar] [CrossRef]
- Sim, B.; Kwon, J.; Lee, J. Single-Trace Attacks on Message Encoding in Lattice-Based KEMs. IEEE Access 2020, 8, 183175–183191. [Google Scholar] [CrossRef]
- Ravi, P.; Bhasin, S.; Sinha Roy, S.; Chattopadhyay, A. On Exploiting Message Leakage in (Few) NIST PQC Candidates for Practical Message Recovery Attacks. IEEE Transac. Inform. Forensics Secur. 2022, 17, 684–699. [Google Scholar] [CrossRef]
- Nejatollahi, H.; Dutt, N.; Ray, S.; Regazzoni, F.; Banerjee, I.; Cammarota, R. Post-Quantum Lattice-Based Cryptography Implementations: A Survey. ACM Comput. Surv. 2019, 51, 1–41. [Google Scholar] [CrossRef]
- Lyubashevsky, V.; Peikert, C.; Regev, O. On Ideal Lattices and Learning with Errors over Rings. J. ACM 2013, 60, 1–35. [Google Scholar] [CrossRef]
- Fujisaki, E.; Okamoto, T. Secure Integration of Asymmetric and Symmetric Encryption Schemes. J. Cryptol. 2013, 26, 80–101. [Google Scholar] [CrossRef]
- Goodwill, G.; Jun, B.; Jaffe, J. A testing methodology for side channel resistance validation. Proc. NIAT 2011, 17, 115–136. [Google Scholar]
- Bhasin, S.; Danger, J.L.; Guilley, S.; Najm, Z. NICV: Normalized inter-class variance for detection of side-channel leakage. In Proceedings of the 2014 International Symposium on Electromagnetic Compatibility, Tokyo, Japan, 13–16 May 2014; pp. 310–313. [Google Scholar]
- Schwabe, P.; Avanzi, R.; Bos, J. CRYSTALS—CRYSTAL-Kyber—Algorithm Specifications And Supporting Documentation. 2017. Available online: https://pq-crystals.org/kyber/index.shtml (accessed on 8 May 2021).
- Kannwischer, M.J.; Rijneveld, J.; Schwabe, P. PQM4: Post-Quantum Crypto Library for the ARM Cortex-M4. 2020. Available online: http://github.com/mupq/pqm4 (accessed on 18 September 2022).
- NewAE Technology Inc. Chipwhisperer. Available online: http://rtfm.newae.com (accessed on 6 May 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target | Method | Number of Traces in Preprocessing | Number of Traces for Attacking | Sum of Traces | Success Rate (Best Case) | |
|---|---|---|---|---|---|---|
| [6] | NTT | Belief Propagation | 1900 | 100 | 2000 | ≥95% |
| [11] * | Decode | EM | 200 | 256 | 456 | ≈100% |
| 25,600 | 32 | 25,856 | ≈100% | |||
| EM + FIA | 12,800 | 1280 | 14,080 | ≈100% | ||
| [12] | Encode | EM | 25,600 | 1 (32 segments) | 25,601 | ≥96% |
| This Work | Decode | Power | 900 | 32 | 932 | ≈99.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Y.; Yan, Y.; Zhu, C.; Guo, P. Template Attack of LWE/LWR-Based Schemes with Cyclic Message Rotation. Entropy 2022, 24, 1489. https://doi.org/10.3390/e24101489
Chang Y, Yan Y, Zhu C, Guo P. Template Attack of LWE/LWR-Based Schemes with Cyclic Message Rotation. Entropy. 2022; 24(10):1489. https://doi.org/10.3390/e24101489
Chicago/Turabian StyleChang, Yajing, Yingjian Yan, Chunsheng Zhu, and Pengfei Guo. 2022. "Template Attack of LWE/LWR-Based Schemes with Cyclic Message Rotation" Entropy 24, no. 10: 1489. https://doi.org/10.3390/e24101489
APA StyleChang, Y., Yan, Y., Zhu, C., & Guo, P. (2022). Template Attack of LWE/LWR-Based Schemes with Cyclic Message Rotation. Entropy, 24(10), 1489. https://doi.org/10.3390/e24101489