
Revisiting Chernoff Information with Likelihood Ratio Exponential Families


Abstract
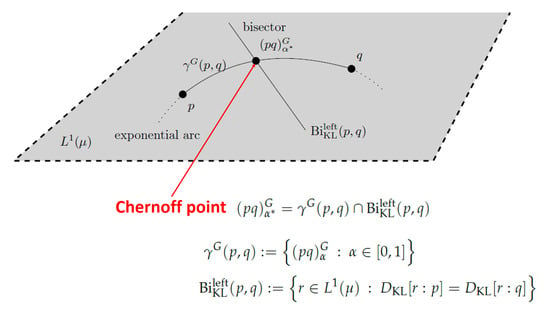
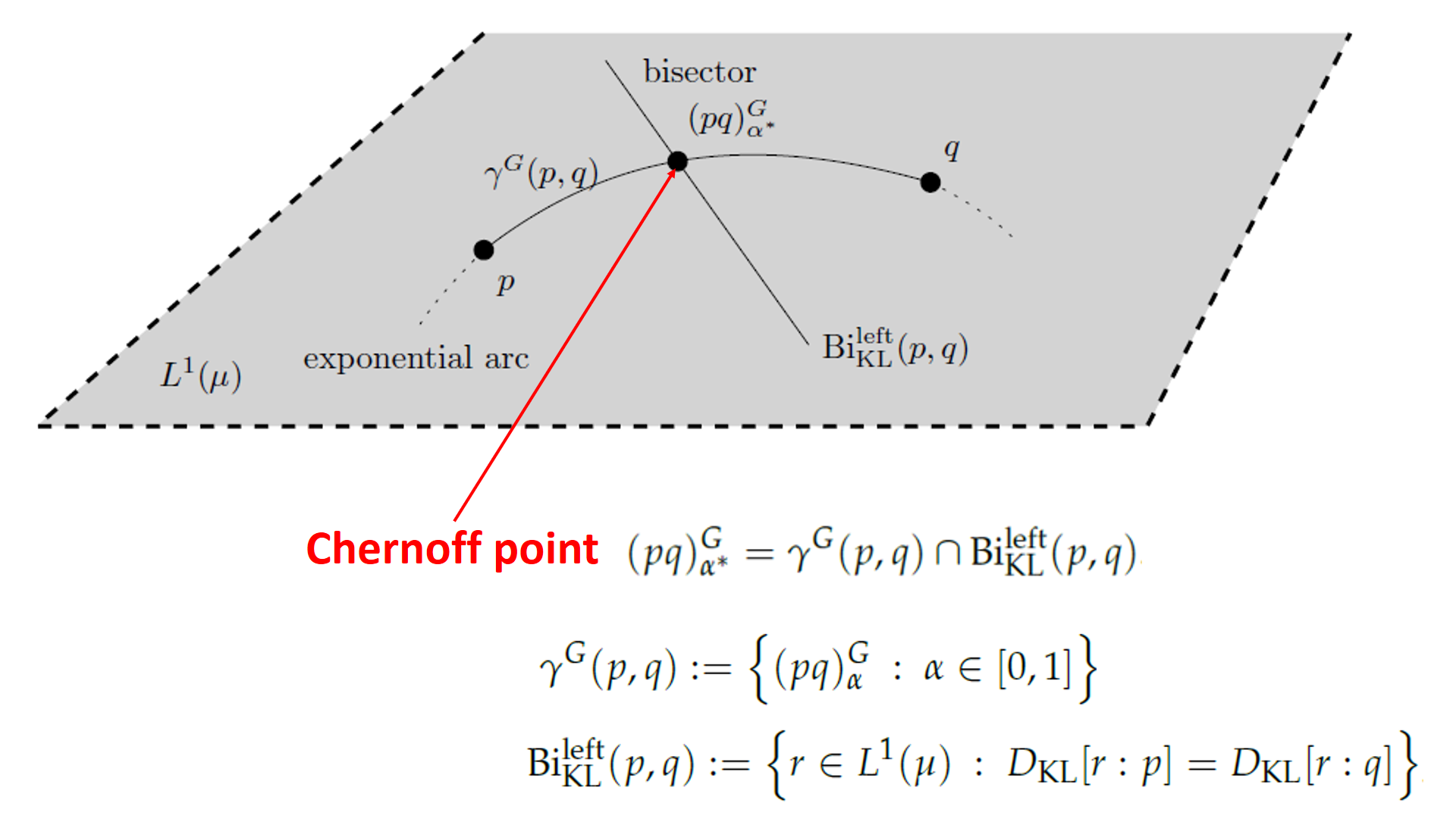
1. Introduction
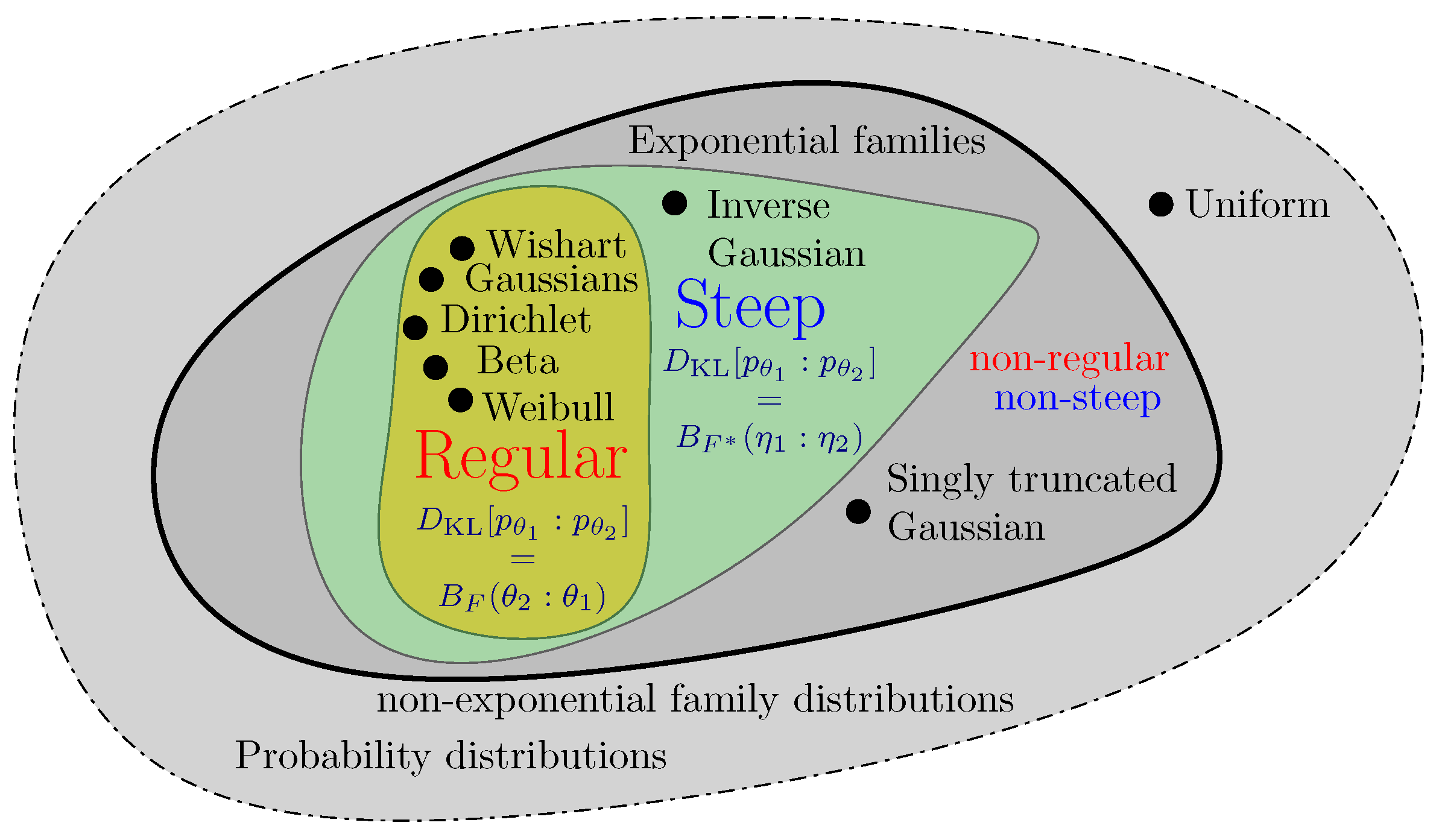
1.1. Chernoff Information: Definition and Related Statistical Divergences
1.2. Prior Work and Contributions
2. Chernoff Information from the Viewpoint of Likelihood Ratio Exponential Families
2.1. LREFs and the Chernoff Information
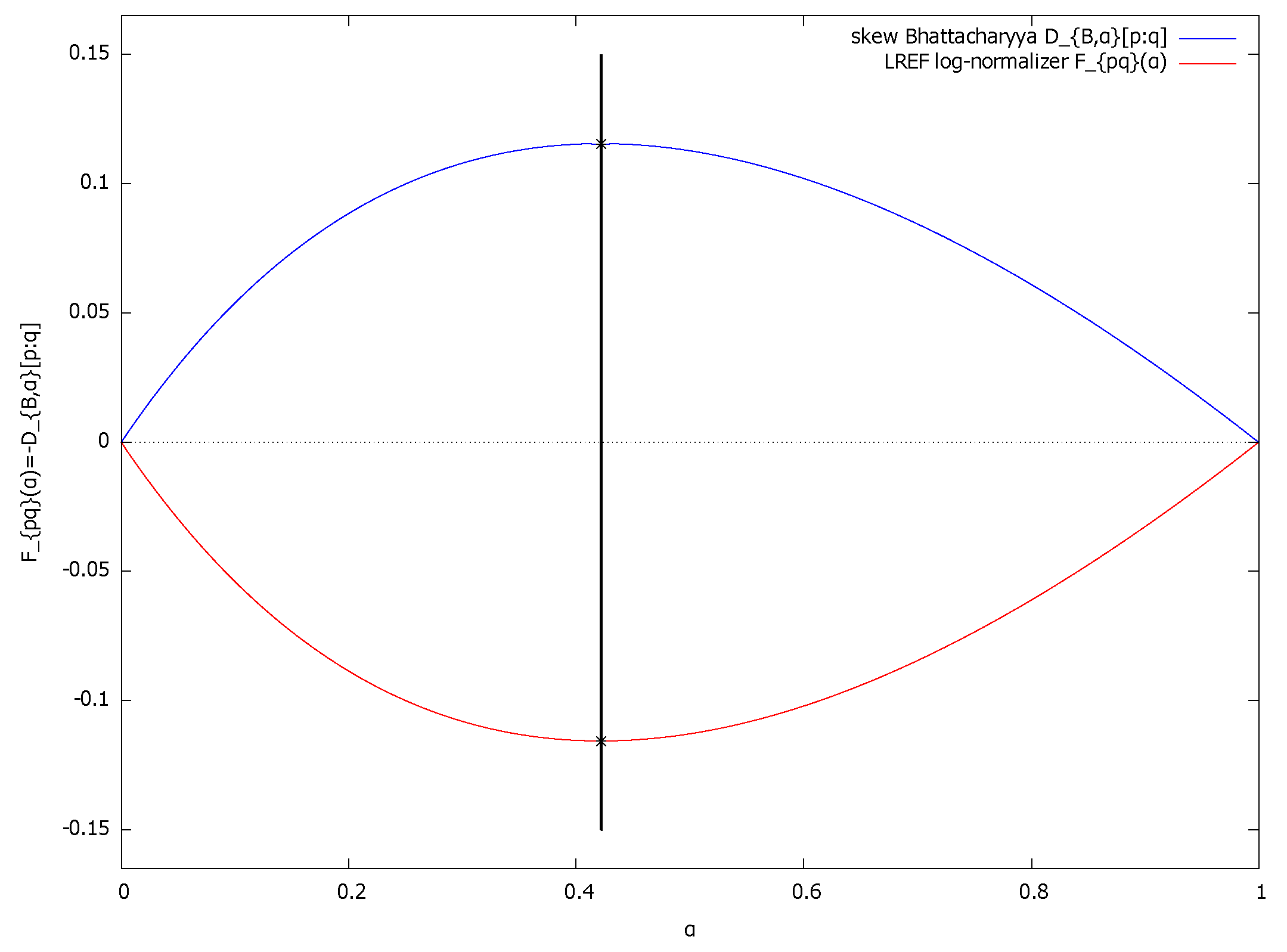
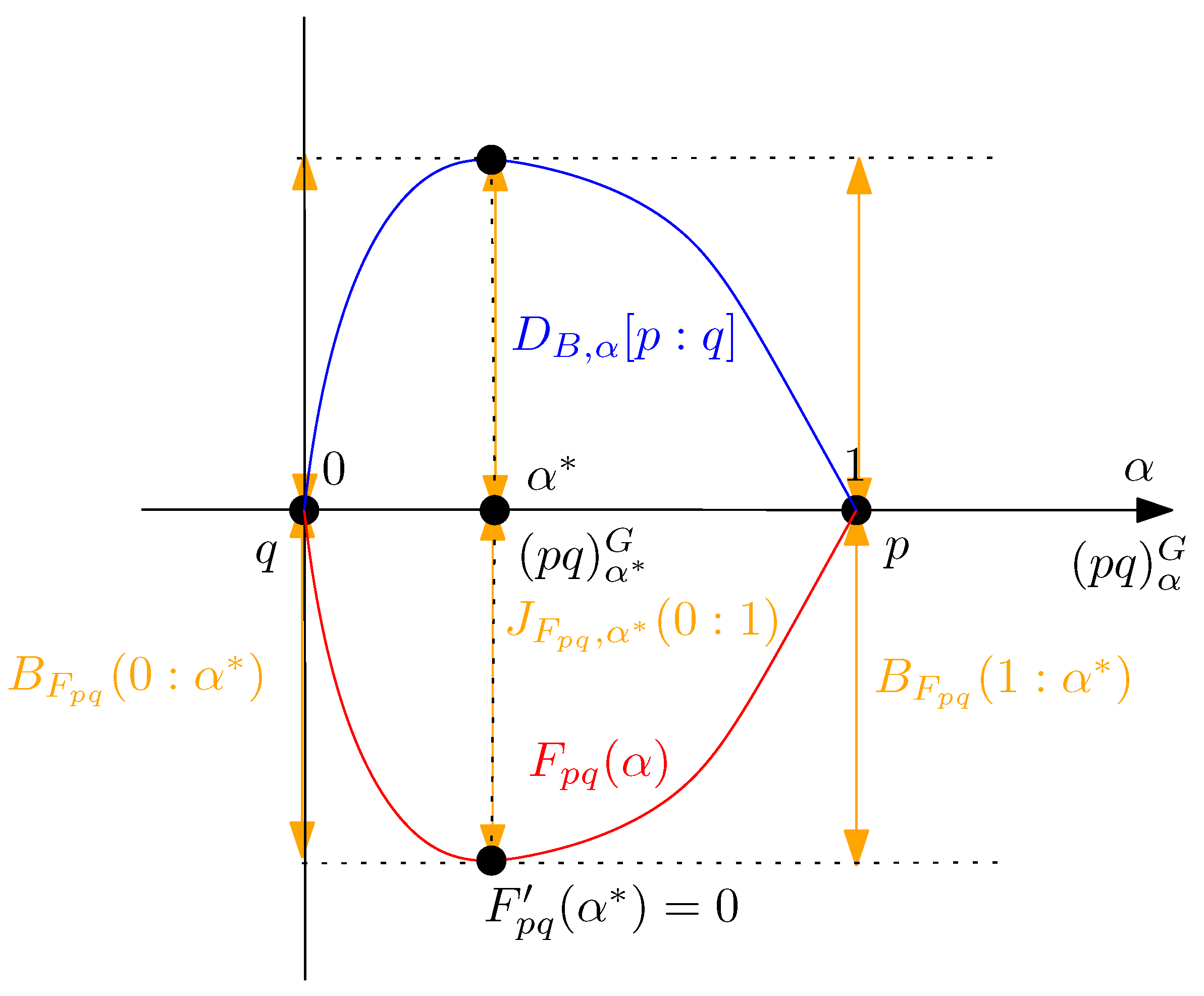
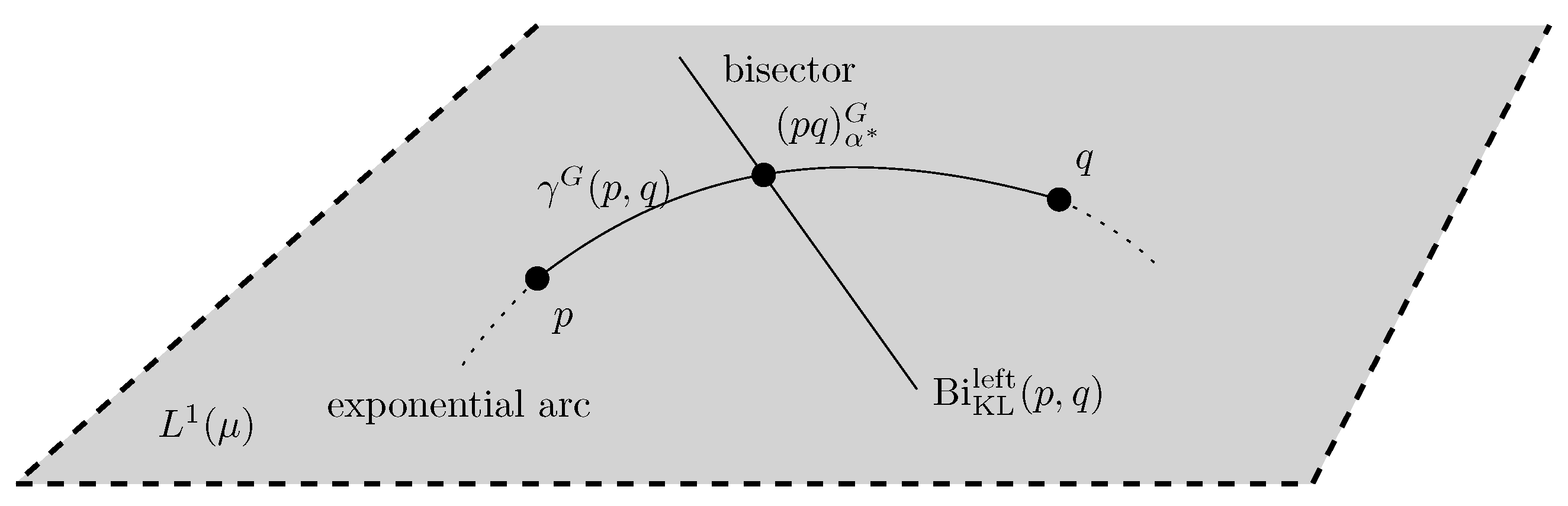
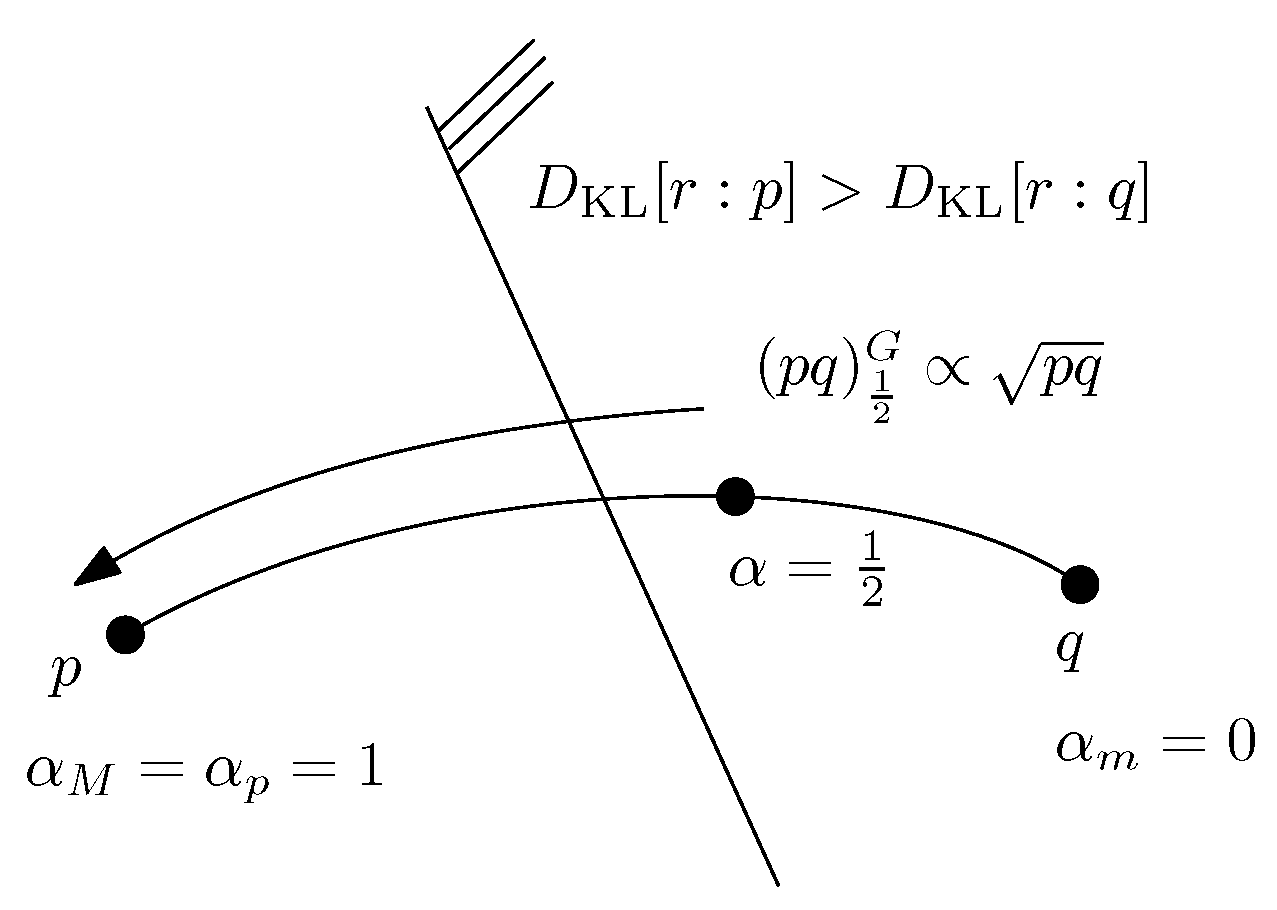
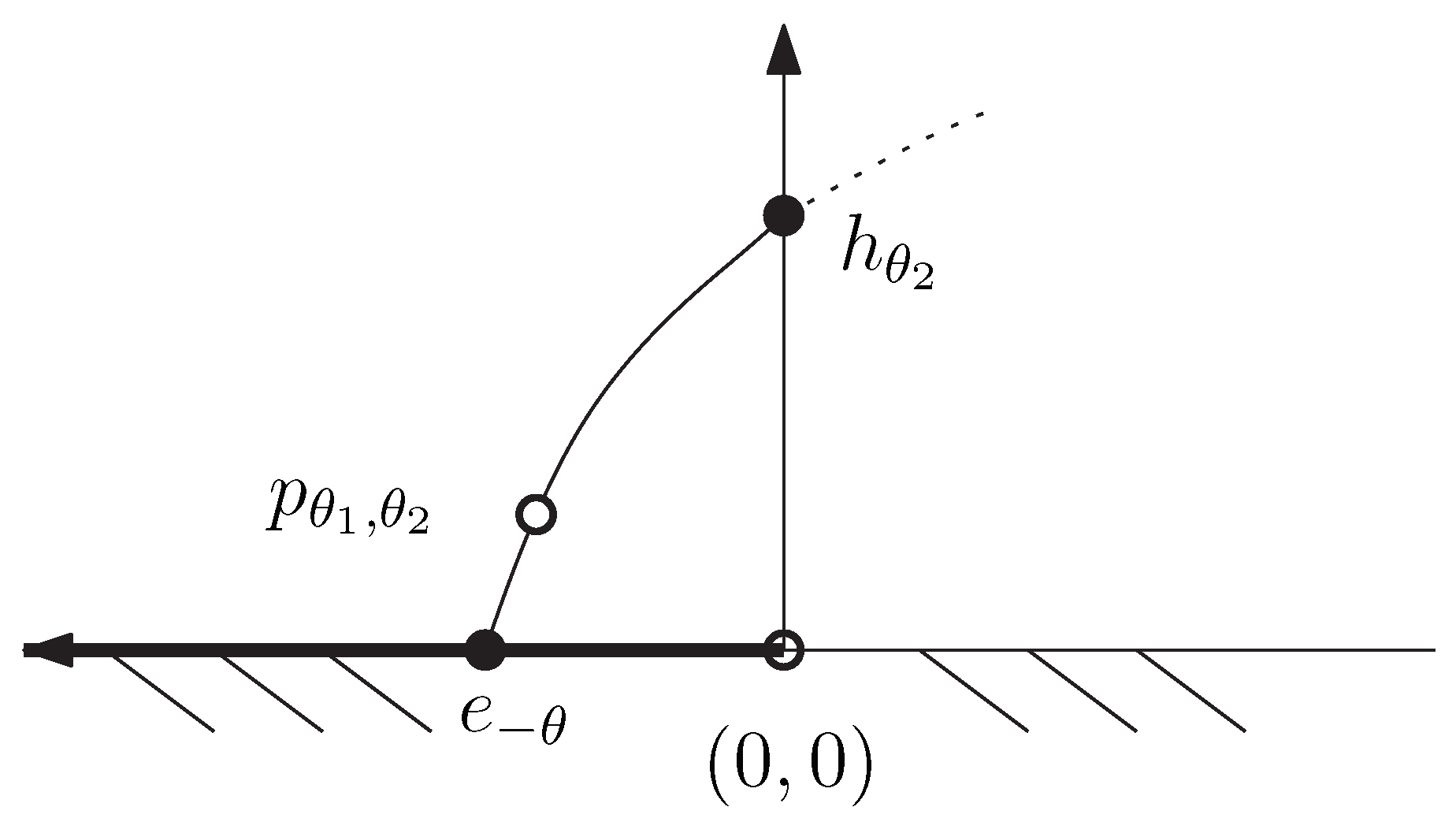
2.2. Geometric Characterization of the Chernoff Information and the Chernoff Information Distribution
| Algorithm 1 Dichotomic search for approximating the Chernoff information by approximating the optimal skewing parameter value and reporting . The search requires iterations to guarantee . |
 |
2.3. Dual Parameterization of LREFs
- , we have and
- , we have and
3. Chernoff Information between Densities of an Exponential Family
3.1. General Case
3.2. Case of One-Dimensional Parameters
4. Forward and Reverse Chernoff–Bregman Divergences
4.1. Chernoff–Bregman Divergence
| Algorithm 2 Approximating the circumcenter of the Bregman smallest enclosing ball of two parameters and . |
 |
4.2. Reverse Chernoff–Bregman Divergence and Universal Coding
5. Chernoff Information between Gaussian Distributions
5.1. Invariance of Chernoff Information under the Action of the Affine Group
5.2. Closed-Form Formula for the Chernoff Information between Univariate Gaussian Distributions
- First, let us consider the Gaussian subfamily with prescribed variance. When , we always have , and the Chernoff information isNotice that it amounts to one eight of the squared Mahalanobis distance (see [60] for a detailed explanation).
- Second, let us consier Gaussian subfamily with prescribed mean. When , we get the optimal skewing value independent of the mean :where and . The Chernoff information is
- Third, consider the Chernoff information between the standard normal distribution and another normal distribution. When and , we get
5.3. Fast Approximation of the Chernoff Information of Multivariate Gaussian Distributions
- When the Gaussians have the same covariance matrix , the Chernoff information optimal skewing parameter is and the Chernoff information iswhere is the squared Mahalanobis distance. The Mahalanobis distance enjoys the following property by congruence transformation:Notice that we can rewrite the (squared) Mahalanobis distance asusing the matrix trace cyclic property. Then we check that
- The Chernoff information for the special case of centered multivariate Gaussians distributions was studied in [62]. The KLD between two centered Gaussians and is half of the matrix Burg distance:When , the Burg distance corresponds to the well-known Itakura–Saito divergence. The matrix Burg distance is a matrix spectral distance [62]:where the ’s are the eigenvalues of . The reverse KLD divergence is obtained by replacing :More generally, the f-divergences between centered Gaussian distributions are always matrix spectral divergences [60].
| Algorithm 3 Dichotomic search for approximating the Chernoff information between two multivariate normal distributions and by approximating the optimal skewing parameter value . |
 |
5.4. Chernoff Information between Centered Multivariate Normal Distributions
6. Chernoff Information between Densities of Different Exponential Families
7. Conclusions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Background on Statistical Divergences
Appendix B. Exponential Family of Univariate Gaussian Distributions
Appendix C. Code Snippets in MAXIMA
| Listing A1: Plot the cumulant function of a log ratio exponential family induced by two normal distributions. |
|
| Listing A2: Calculate symbolically the exact Chernoff information between two univariate normal distributions. |
|
| Listing A3: Plot the skewed Bhattacharrya divergences between two normal distributions as an equivalent skewed Jensen divergence between two normal distributions. |
|
| Listing A4: Calculate the Chernoff information between two 4D centered normal distributions based on their eigenvalues. |
|
| Listing A5: Calculate symbolically the Kullback–Leibler divergence and the Bhattacharyya coefficient between a half normal distribution and an exponential distribution. |
|
References
- Keener, R.W. Theoretical Statistics: Topics for a Core Course; Springer Science & Business Media: New York, NY, USA, 2010. [Google Scholar]
- Chernoff, H. A measure of asymptotic efficiency for tests of a hypothesis based on the sum of observations. Ann. Math. Stat. 1952, 23, 493–507. [Google Scholar] [CrossRef]
- Csiszár, I. A class of measures of informativity of observation channels. Period. Math. Hung. 1972, 2, 191–213. [Google Scholar] [CrossRef]
- Torgersen, E. Comparison of Statistical Experiments; Cambridge University Press: Cambridge, UK, 1991; Volume 36. [Google Scholar]
- Audenaert, K.M.; Calsamiglia, J.; Munoz-Tapia, R.; Bagan, E.; Masanes, L.; Acin, A.; Verstraete, F. Discriminating states: The quantum Chernoff bound. Phys. Rev. Lett. 2007, 98, 160501. [Google Scholar] [PubMed]
- Audenaert, K.M.; Nussbaum, M.; Szkoła, A.; Verstraete, F. Asymptotic error rates in quantum hypothesis testing. Commun. Math. Phys. 2008, 279, 251–283. [Google Scholar] [CrossRef]
- Bhattacharyya, A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943, 35, 99–109. [Google Scholar]
- Nielsen, F.; Boltz, S. The Burbea-Rao and Bhattacharyya centroids. IEEE Trans. Inf. Theory 2011, 57, 5455–5466. [Google Scholar] [CrossRef]
- Grünwald, P.D. The Minimum Description Length Principle; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Grünwald, P.D. Information-Theoretic Properties of Exponential Families. In The Minimum Description Length Principle; MIT Press: Cambridge, MA, USA, 2007; pp. 623–650. [Google Scholar]
- Van Erven, T.; Harremos, P. Rényi divergence and Kullback–Leibler divergence. IEEE Trans. Inf. Theory 2014, 60, 3797–3820. [Google Scholar] [CrossRef]
- Nakiboğlu, B. The Rényi capacity and center. IEEE Trans. Inf. Theory 2018, 65, 841–860. [Google Scholar] [CrossRef]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Borade, S.; Zheng, L. I-projection and the geometry of error exponents. In Proceedings of the Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 27–29 September 2006. [Google Scholar]
- Boyer, R.; Nielsen, F. On the error exponent of a random tensor with orthonormal factor matrices. In International Conference on Geometric Science of Information; Springer: Cham, Switzerland, 2017; pp. 657–664. [Google Scholar]
- D’Costa, A.; Ramachandran, V.; Sayeed, A.M. Distributed classification of Gaussian space-time sources in wireless sensor networks. IEEE J. Sel. Areas Commun. 2004, 22, 1026–1036. [Google Scholar] [CrossRef]
- Yu, N.; Zhou, L. Comments on and Corrections to “When Is the Chernoff Exponent for Quantum Operations Finite?”. IEEE Trans. Inf. Theory 2022, 68, 3989–3990. [Google Scholar] [CrossRef]
- Konishi, S.; Yuille, A.L.; Coughlan, J.; Zhu, S.C. Fundamental bounds on edge detection: An information theoretic evaluation of different edge cues. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 1, pp. 573–579. [Google Scholar]
- Julier, S.J. An empirical study into the use of Chernoff information for robust, distributed fusion of Gaussian mixture models. In Proceedings of the 2006 9th International Conference on Information Fusion, Florence, Italy, 10–13 July 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 1–8. [Google Scholar]
- Kakizawa, Y.; Shumway, R.H.; Taniguchi, M. Discrimination and clustering for multivariate time series. J. Am. Stat. Assoc. 1998, 93, 328–340. [Google Scholar] [CrossRef]
- Dutta, S.; Wei, D.; Yueksel, H.; Chen, P.Y.; Liu, S.; Varshney, K. Is there a trade-off between fairness and accuracy? A perspective using mismatched hypothesis testing. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 2803–2813. [Google Scholar]
- Agarwal, S.; Varshney, L.R. Limits of deepfake detection: A robust estimation viewpoint. arXiv 2019, arXiv:1905.03493. [Google Scholar]
- Maherin, I.; Liang, Q. Radar sensor network for target detection using Chernoff information and relative entropy. Phys. Commun. 2014, 13, 244–252. [Google Scholar] [CrossRef]
- Nielsen, F. An information-geometric characterization of Chernoff information. IEEE Signal Process. Lett. 2013, 20, 269–272. [Google Scholar] [CrossRef]
- Nielsen, F. Generalized Bhattacharyya and Chernoff upper bounds on Bayes error using quasi-arithmetic means. Pattern Recognit. Lett. 2014, 42, 25–34. [Google Scholar] [CrossRef][Green Version]
- Westover, M.B. Asymptotic geometry of multiple hypothesis testing. IEEE Trans. Inf. Theory 2008, 54, 3327–3329. [Google Scholar] [CrossRef]
- Nielsen, F. Hypothesis testing, information divergence and computational geometry. In International Conference on Geometric Science of Information; Springer: Berlin/Heidelberg, Germany, 2013; pp. 241–248. [Google Scholar]
- Leang, C.C.; Johnson, D.H. On the asymptotics of M-hypothesis Bayesian detection. IEEE Trans. Inf. Theory 1997, 43, 280–282. [Google Scholar] [CrossRef]
- Cena, A.; Pistone, G. Exponential statistical manifold. Ann. Inst. Stat. Math. 2007, 59, 27–56. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O. Information and Exponential Families: In Statistical Theory; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Brekelmans, R.; Nielsen, F.; Makhzani, A.; Galstyan, A.; Steeg, G.V. Likelihood Ratio Exponential Families. arXiv 2020, arXiv:2012.15480. [Google Scholar]
- De Andrade, L.H.; Vieira, F.L.; Vigelis, R.F.; Cavalcante, C.C. Mixture and exponential arcs on generalized statistical manifold. Entropy 2018, 20, 147. [Google Scholar] [CrossRef]
- Siri, P.; Trivellato, B. Minimization of the Kullback–Leibler Divergence over a Log-Normal Exponential Arc. In International Conference on Geometric Science of Information; Springer: Cham, Switzerland, 2019; pp. 453–461. [Google Scholar]
- Azoury, K.S.; Warmuth, M.K. Relative loss bounds for on-line density estimation with the exponential family of distributions. Mach. Learn. 2001, 43, 211–246. [Google Scholar] [CrossRef]
- Collins, M.; Dasgupta, S.; Schapire, R.E. A generalization of principal components analysis to the exponential family. Adv. Neural Inf. Process. Syst. 2001, 14, 617–624. [Google Scholar]
- Banerjee, A.; Merugu, S.; Dhillon, I.S.; Ghosh, J. Clustering with Bregman divergences. J. Mach. Learn. Res. 2005, 6. [Google Scholar] [CrossRef]
- Nielsen, F.; Nock, R. Sided and symmetrized Bregman centroids. IEEE Trans. Inf. Theory 2009, 55, 2882–2904. [Google Scholar] [CrossRef]
- Sundberg, R. Statistical Modelling by Exponential Families; Cambridge University Press: Cambridge, UK, 2019; Volume 12. [Google Scholar]
- Nielsen, F.; Okamura, K. On f-divergences between Cauchy distributions. arXiv 2021, arXiv:2101.12459. [Google Scholar]
- Chyzak, F.; Nielsen, F. A closed-form formula for the Kullback–Leibler divergence between Cauchy distributions. arXiv 2019, arXiv:1905.10965. [Google Scholar]
- Huzurbazar, V.S. Exact forms of some invariants for distributions admitting sufficient statistics. Biometrika 1955, 42, 533–537. [Google Scholar] [CrossRef]
- Burbea, J.; Rao, C. On the convexity of some divergence measures based on entropy functions. IEEE Trans. Inf. Theory 1982, 28, 489–495. [Google Scholar] [CrossRef]
- Chen, P.; Chen, Y.; Rao, M. Metrics defined by Bregman divergences: Part 2. Commun. Math. Sci. 2008, 6, 927–948. [Google Scholar] [CrossRef]
- Nielsen, F. On the Jensen–Shannon symmetrization of distances relying on abstract means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef]
- Han, Q.; Kato, K. Berry–Esseen bounds for Chernoff-type nonstandard asymptotics in isotonic regression. Ann. Appl. Probab. 2022, 32, 1459–1498. [Google Scholar] [CrossRef]
- Neal, R.M. Annealed importance sampling. Stat. Comput. 2001, 11, 125–139. [Google Scholar] [CrossRef]
- Grosse, R.B.; Maddison, C.J.; Salakhutdinov, R. Annealing between distributions by averaging moments. In Advances in Neural Information Processing Systems 26, Proceedings of the 27th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–10 December 2013; Citeseer: La Jolla, CA, USA, 2013; pp. 2769–2777. [Google Scholar]
- Takenouchi, T. Parameter Estimation with Generalized Empirical Localization. In International Conference on Geometric Science of Information; Springer: Cham, Switzerland, 2019; pp. 368–376. [Google Scholar]
- Rockafellar, R.T. Conjugates and Legendre transforms of convex functions. Can. J. Math. 1967, 19, 200–205. [Google Scholar] [CrossRef]
- Del Castillo, J. The singly truncated normal distribution: A non-steep exponential family. Ann. Inst. Stat. Math. 1994, 46, 57–66. [Google Scholar] [CrossRef]
- Amari, S.I. Information Geometry and Its Applications; Springer: Tokyo, Japan, 2016; Volume 194. [Google Scholar]
- Boissonnat, J.D.; Nielsen, F.; Nock, R. Bregman Voronoi diagrams. Discret. Comput. Geom. 2010, 44, 281–307. [Google Scholar] [CrossRef]
- Lê, H.V. Statistical manifolds are statistical models. J. Geom. 2006, 84, 83–93. [Google Scholar] [CrossRef]
- Nielsen, F. On a Variational Definition for the Jensen–Shannon Symmetrization of Distances Based on the Information Radius. Entropy 2021, 23, 464. [Google Scholar] [CrossRef]
- Nock, R.; Nielsen, F. Fitting the smallest enclosing Bregman ball. In Proceedings of the European Conference on Machine Learning, Porto, Portugal, 3–7 October 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 649–656. [Google Scholar]
- Nielsen, F.; Nock, R. On the smallest enclosing information disk. Inf. Process. Lett. 2008, 105, 93–97. [Google Scholar] [CrossRef]
- Costa, R. Information Geometric Probability Models in Statistical Signal Processing. Ph.D. Thesis, University of Rhode Island, Kingston, RI, USA, 2016. [Google Scholar]
- Nielsen, F.; Garcia, V. Statistical exponential families: A digest with flash cards. arXiv 2009, arXiv:0911.4863. [Google Scholar]
- Ali, S.M.; Silvey, S.D. A general class of coefficients of divergence of one distribution from another. J. R. Stat. Soc. Ser. B (Methodol.) 1966, 28, 131–142. [Google Scholar] [CrossRef]
- Nielsen, F.; Okamura, K. A note on the f-divergences between multivariate location-scale families with either prescribed scale matrices or location parameters. arXiv 2022, arXiv:2204.10952. [Google Scholar]
- Athreya, A.; Fishkind, D.E.; Tang, M.; Priebe, C.E.; Park, Y.; Vogelstein, J.T.; Levin, K.; Lyzinski, V.; Qin, Y. Statistical inference on random dot product graphs: A survey. J. Mach. Learn. Res. 2017, 18, 8393–8484. [Google Scholar]
- Li, B.; Wei, S.; Wang, Y.; Yuan, J. Topological and algebraic properties of Chernoff information between Gaussian graphs. In Proceedings of the 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 670–675. [Google Scholar]
- Tang, M.; Priebe, C.E. Limit theorems for eigenvectors of the normalized Laplacian for random graphs. Ann. Stat. 2018, 46, 2360–2415. [Google Scholar] [CrossRef]
- Calvo, M.; Oller, J.M. An explicit solution of information geodesic equations for the multivariate normal model. Stat. Risk Model. 1991, 9, 119–138. [Google Scholar] [CrossRef]
- Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Chen, P.; Chen, Y.; Rao, M. Metrics defined by Bregman divergences. Commun. Math. Sci. 2008, 6, 915–926. [Google Scholar] [CrossRef]
- Kailath, T. The divergence and Bhattacharyya distance measures in signal selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar] [CrossRef]
- Csiszar, I. Eine information’s theoretische Ungleichung und ihre Anwendung auf den Beweis der Ergodizitat von Markoschen Ketten. Publ. Math. Inst. Hung. Acad. Sc. 1963, 3, 85–107. [Google Scholar]
- Deza, M.M.; Deza, E. Encyclopedia of distances. In Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–583. [Google Scholar]
- Gibbs, A.L.; Su, F.E. On choosing and bounding probability metrics. Int. Stat. Rev. 2002, 70, 419–435. [Google Scholar] [CrossRef]
- Jian, B.; Vemuri, B.C. Robust point set registration using Gaussian mixture models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1633–1645. [Google Scholar] [CrossRef]
- Nielsen, F.; Nock, R. Entropies and cross-entropies of exponential families. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 3621–3624. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
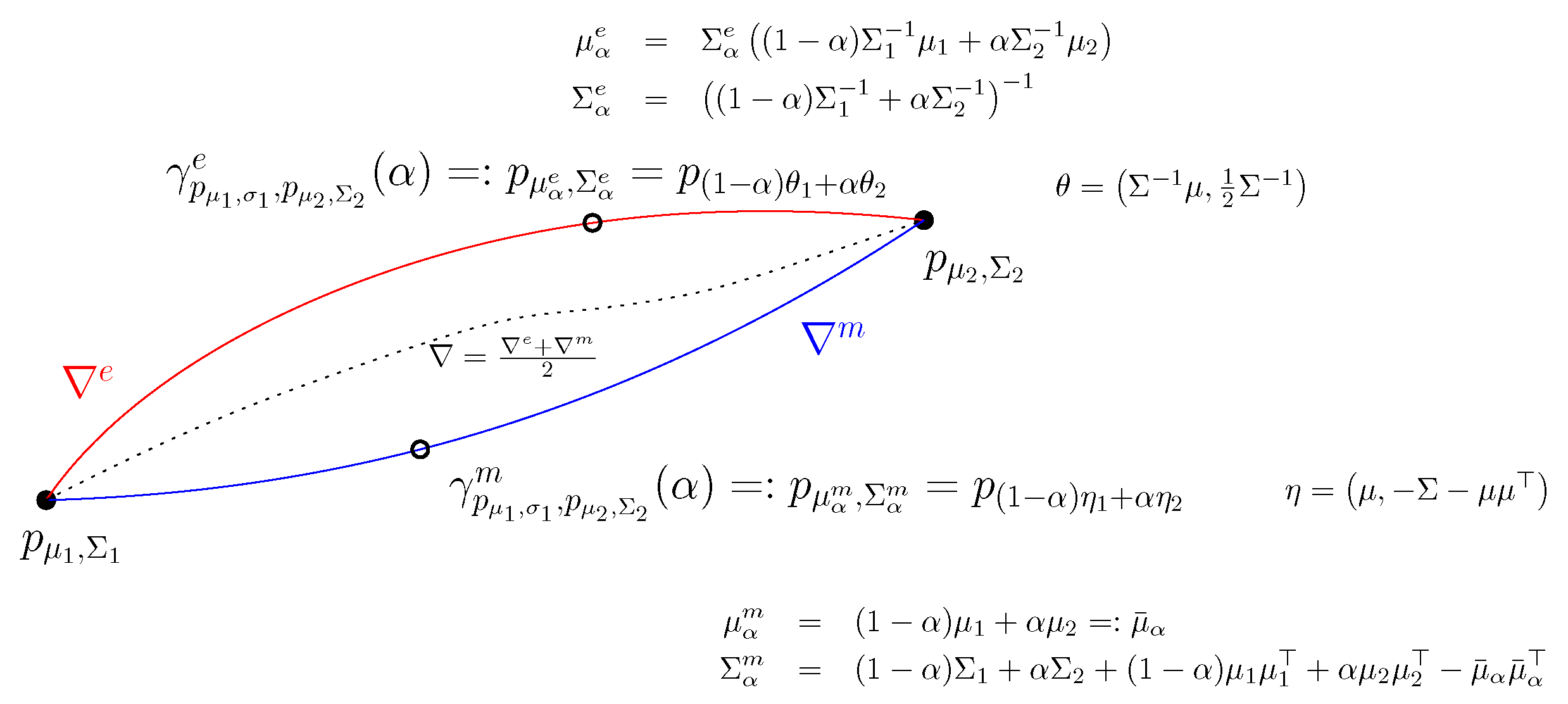{kind=link}
{kind=link}
| Generic case | |
| Primal LREF | |
| Dual LREF | |
| Geometric OC | |
| Case of exponential families | |
| Bregman | |
| Fenchel–Young | |
| Simplified | |
| Geometric OC | |
| 1D EF | |
| Gaussian case | |
| 1D Gaussians | |
| is root of quadratic polynomial in | |
| Centered Gaussians | |
| where is the i-th eigenvalue of | |
| Centered Gaussians | |
| scaled covariances | when |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nielsen, F. Revisiting Chernoff Information with Likelihood Ratio Exponential Families. Entropy 2022, 24, 1400. https://doi.org/10.3390/e24101400
Nielsen F. Revisiting Chernoff Information with Likelihood Ratio Exponential Families. Entropy. 2022; 24(10):1400. https://doi.org/10.3390/e24101400
Chicago/Turabian StyleNielsen, Frank. 2022. "Revisiting Chernoff Information with Likelihood Ratio Exponential Families" Entropy 24, no. 10: 1400. https://doi.org/10.3390/e24101400
APA StyleNielsen, F. (2022). Revisiting Chernoff Information with Likelihood Ratio Exponential Families. Entropy, 24(10), 1400. https://doi.org/10.3390/e24101400