1. Introduction
During the last years, ordinal data in general [
1] and ordinal time series in particular [
2] received a great amount of interest in research and applications. Here, a random variable
X is said to be ordinal if
X has a bounded qualitative range exhibiting a natural order among the categories. We denote the range as
with some
, and we assume that
. The realized data are denoted as
with
. They are assumed to stem either from independent and identically distributed (i. i. d.) replications of
X (then, we refer to
as an ordinal random sample), or from a stationary ordinal stochastic process
(then,
are said to be an ordinal time series).
In what follows, we take up several recent works on measures of dispersion and serial dependence in ordinal (time series) data. Regarding ordinal dispersion, the well-known measures such as variance or mean absolute deviation cannot be used as the data are not quantitative. Therefore, several tailor-made measures for ordinal dispersion have been developed and investigated in the literature, see, among others, [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. The unique feature of all these measures is that they rely on the cumulative distribution function (CDF) of
X, i.e., on
with
for
(
is omitted in
f as it necessarily equals one). They classify any one-point distribution on
as a scenario of minimal dispersion, i.e., if all probability mass concentrates on one category from
(maximal consensus):
By contrast, maximal dispersion is achieved exactly in the case of the extreme two-point distribution (polarized distribution),
, where we have 50 % probability mass in each of the outermost categories (maximal dissent). Further details on ordinal dispersion measures are presented in
Section 2 below.
Building upon earlier works by Klein [
16], Yager [
17], it was recently shown by Klein Doll [
18], Klein et al. [
19] that the aforementioned ordinal dispersion measures can be subsumed under the family of so-called “cumulative paired
-entropies” (see
Section 2), abbreviated as
, which constitutes the starting point of the present article. Our first main task is to derive the asymptotic distribution of the corresponding sample version,
, for both i. i. d. and time series data, and to check the finite sample performance of the resulting approximate distribution, see
Section 3 and
Section 5.
In the recent paper by Weiß [
20] on the asymptotics of some well-known dispersion measures for nominal data (i.e., qualitative data without a natural ordering), it turned out that the corresponding dispersion measures—if these are applied to time series data—are related to specific measures of serial dependence. Therefore, our second main task is to explore for a similar relation in the ordinal case, if considering the
-family for measuring dispersion. Ordinal dependence measures can be defined in analogy to the popular autocorrelation function (ACF) for quantitative time series, namely by using the lagged bivariate CDF
for time lags
as their base [
14]. For the novel family of
measures, which cover the existing ordinal Cohen’s
[
14,
15] as a special case, we derive the asymptotics under the null hypothesis of i. i. d. time series data, see
Section 4. This result is used in
Section 5 to test for significant serial dependence, in analogy to the application of the sample ACF to quantitative time series. In
Section 6, we discuss an illustrative real-world data example from an environmental application, namely regarding the daily level of air quality. The article concludes in
Section 7.
2. The Family of Cumulative Paired -Entropies
Klein Doll [
18], Klein et al. [
19] proposed and investigated a family of cumulative paired
-entropies. Although their main focus was on continuously distributed random variables, they also referred to the ordinal case and pointed out that many well-known ordinal dispersion measures are included in this family. Here, we exclusively concentrate on the ordinal case as introduced in
Section 1, and we define the (normalized) cumulative paired
-entropy as (see Section 2.3 in Klein et al. [
19])
The entropy generating function (EGF)
is defined on
, it satisfies
, and it is assumed to be concave on
. Later in
Section 3, when deriving the asymptotic distribution of the sample counterpart
, we shall also require that
is (twice) differentiable. As pointed out in Section 2.3 and 3.1 of Klein et al. [
19], several well-known measures of ordinal dispersion can be expressed by (
1) with an appropriate choice of
.
Leik’s ordinal variation [
11] corresponds to the choice
(which is not differentiable in
) because of the equality
:
An analogous argument applies to the whole family of ordinal variation measures,
with
[
3,
9,
10,
13]. Choosing
with
, we have the relation
Note that
leads to the LOV, and the case
is known as the coefficient of ordinal variation,
[
4,
8].
Related to the previous case
with
,
becomes the widely-used index of ordinal variation [
3,
7,
8] if choosing
:
The cumulative paired (Shannon) entropy [
12] corresponds to the choice
(with the convention
):
can be embedded into the family of
a-entropies [
21,
22],
as the boundary case
. Plugging-in (
6) into (
1), one obtains
Note that both
and
in (
7) lead to the IOV (
4).
The EGFs
involved in (
2)–(
4) are symmetric around
, i.e., they satisfy
. This is also illustrated by
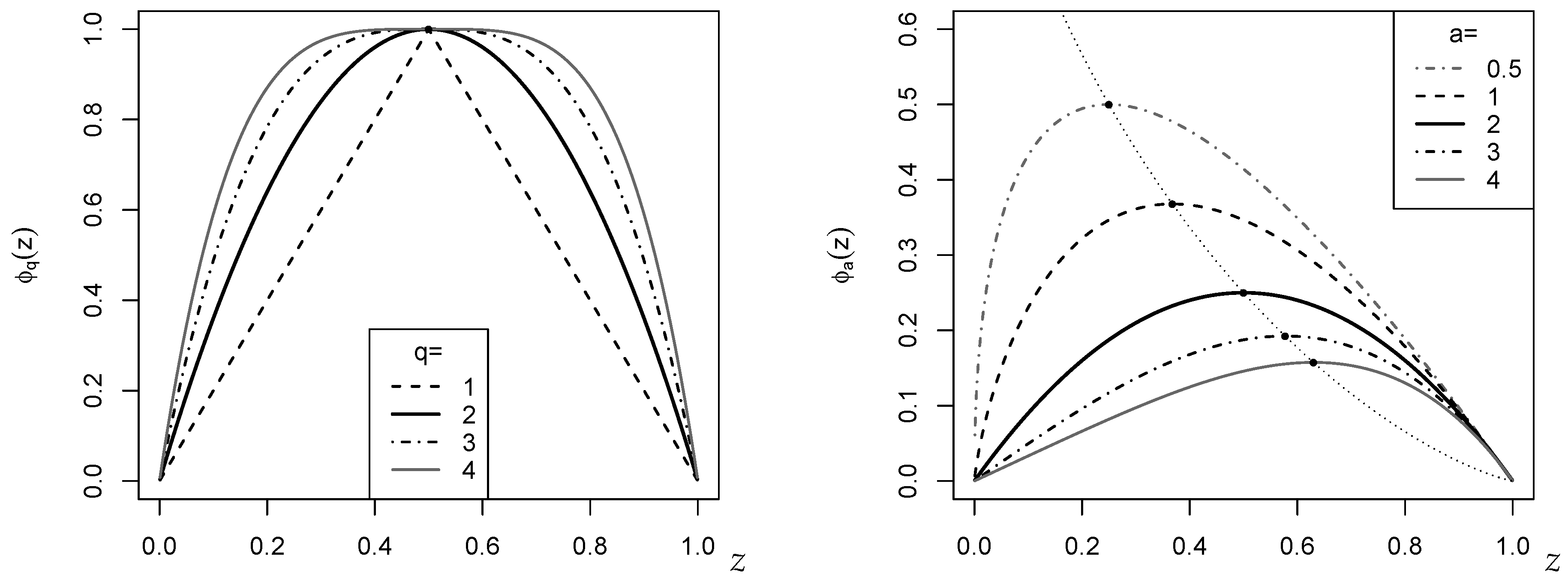
Figure 1, where the cases
(left) and
(right; both in bold black) agree with each other except a scaling factor. The plotted EGFs
are maximal in
with
. The EGF
is maximal in
with
for
, whereas in the boundary case
,
takes its maximal value
at
. However, since
in (
1) is normalized, it is not necessary to care for a possible rescaling of
if computing
.
Remark 1. The dotted curve in the right part of Figure 1, which connects the maxima of for different a, is computed by using the Lambert W function (also referred to as the product logarithm). This can be seen as follows: is maximal in with . It holds thatUsing that , this implies thatThe Lambert W function is defined to solve the equation as , so we getThus, since , the dotted curve in Figure 1 follows the function . More precisely, since is minimal in with minimal value , we have to use the principal branch for , and the secondary branch for . Let us conclude this section with some examples of
measures (see
Figure 2). For all examples, we set
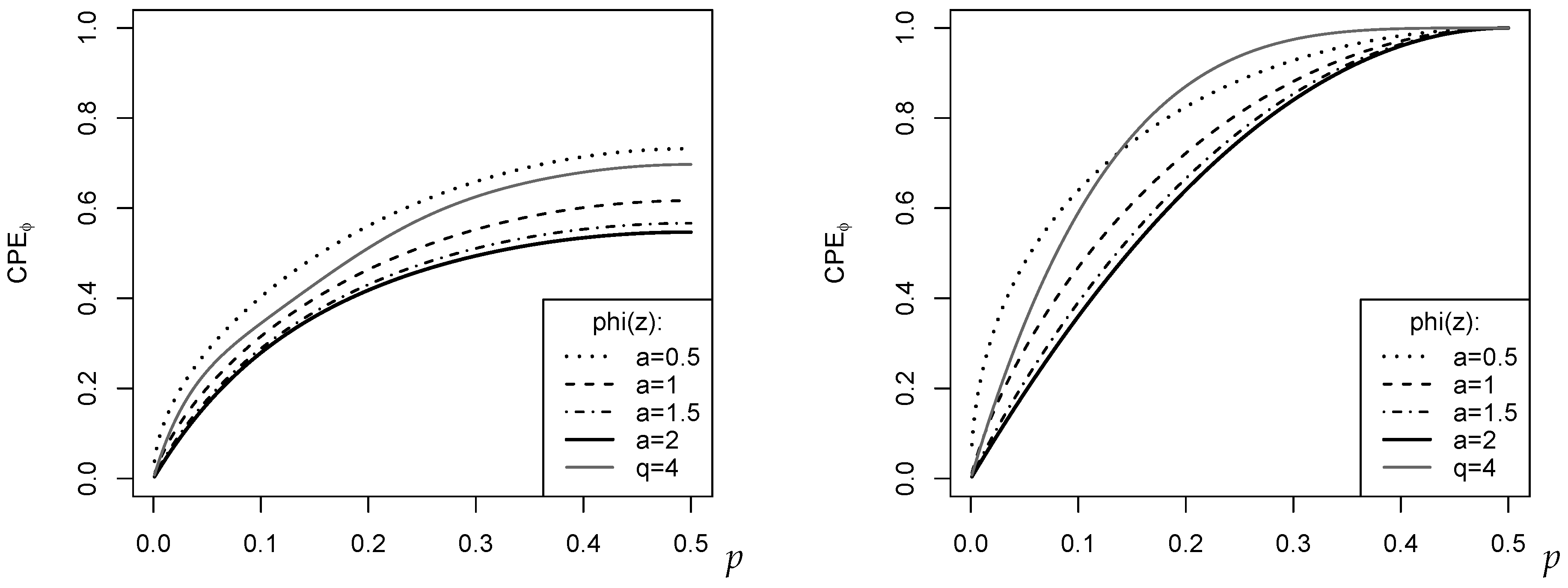
, i.e., we have five ordinal categories like, for example, in the case of a simple Likert scale. In the left part of
Figure 2,
f was computed according to the binomial distribution
, which has maximal dispersion for
. This is also recognized by any of the plotted measures
, with their maximal dispersion values varying around 0.6. This medium level of dispersion is plausible because
is far away from the extreme two-point distribution. The right part of
Figure 2, by contrast, shows the
for the two-point distribution with
(
). So
corresponds to a one-point distribution in
(minimal dispersion), and
to the extreme two-point distribution (maximal dispersion). Accordingly, all measures reach their extreme values 0 and 1, respectively. It is interesting to note that outside these extreme cases, the dispersion measures judge the actual dispersion level quite differently; see the related discussion in Kvålseth [
10], Weiß [
13].
3. Asymptotic Distribution of Sample
From now on, we focus on the sample version of
from (
1), i.e., on
, where
denotes the vector of cumulative relative frequencies computed from
. To derive the asymptotic distribution of
, which is to be used as an approximation to the true distribution of
, we recall the following results from Weiß [
14]. Provided that the data-generating process (DGP) satisfies appropriate mixing conditions, e.g.,
-mixing with exponentially decreasing weights (which includes the i. i. d.-case), it holds that
For an analogous result in the presence of missing data, see Theorem 1 in Weiß [
15]. In (
8), finite (co)variances are ensured if we require that
holds for all
(“short memory”). In particular, all sums
vanish in the i. i. d.-case. Otherwise, they account for the serial dependence of the DGP. This can be seen by considering the trace of
, which equals
Here, the term
agrees with the IOV in (
4) except the normalizing factor
, i.e., it corresponds to
with
. The term
, in turn, is the ordinal Cohen’s
[
14] defined by
It is a measure of signed serial dependence, which evaluates the extent of (dis)agreement between
and
by positive (negative) values.
Based on Taylor expansions of in f, we shall now study its asymptotic behavior. To establish asymptotic normality and to derive the asymptotic variance of , we need to be differentiable. For an asymptotic bias correction, which relies on a second-order Taylor expansion, even has to be twice differentiable (then, the concavity of implies that ).
Remark 2. From the examples discussed in Section 2, the EGF corresponding to the LOV (i.e., with ) is not differentiable (in ). is only once differentiable for , while ensures to be at least twice differentiable; see Example 1 below. Accordingly, in these cases, it is not possible to establish asymptotic normality () or an asymptotic bias correction (), respectively. In fact, Weiß [13] was faced with the same problem when studying the asymptotics of the sample , and a solution to it was not possible. In simulations, he showed that even modified asymptotics (using a folded-normal distribution) did not lead to an acceptable approximation quality. We shall therefore exclude such cases from our further discussion. If, in applications, the cases or appear to be relevant, a bootstrap approach might be an option to gain insight into the sample distribution of . Assuming
to be (twice) differentiable, the partial derivatives of
according to (
1) are
We denote the gradient (Jacobian) of
by
, and the Hessian equals
. Note that if
is symmetric around
, i.e., if
, then
and
.
Example 1. Let us compute the derivatives required in (10) for the EGF examples presented in Section 2. For , the constant factor becomes , and the derivatives are and . Here, exists in the boundary value only if , and if . Important special cases areand for ,Note that both lead to the same expressions for in (10); see Table 1. This is in accordance with the equivalence of these cases as discussed after (7). For with , the derivatives are expressed using the sign function, , which is not continuous at 0. Note that the following relations hold:For , it then follows by applying the chain rule and the product rule thatNote that these derivatives are continuous in for , using that . The final expressions for (10) are summarized in Table 1.
Table 1.
Partial derivatives (
10) for EGFs discussed in Example 1.
Table 1.
Partial derivatives (
10) for EGFs discussed in Example 1.
| EGF | | |
|---|
| | |
| | |
| | |
| | |
Using (
10), the second-order Taylor expansion equals
According to (
8), the linear term in (
11) is asymptotically normally distributed (“Delta method”), provided that
does not vanish (see Remark 3 below). Then, we conclude from (
8) that
The approximate bias correction relies on the quadratic term in (
11), because
. Using (
8), we conclude that
Let us summarize the results implied by (
12) and (
13) in the following theorem.
Theorem 1. Under the mixing assumptions stated before (8), assuming the EGF ϕ to be twice differentiable, and recalling the from (10) where must not vanish, it holds thatIn addition, the bias-corrected mean of is Note that the second-order derivatives are negative due to the concavity of
, so
exhibits a negative bias.
expresses the effect of serial dependence on
. For i. i. d. ordinal data,
, so Theorem 1 simplifies considerably in this case, namely to
. The bias of
is affected by serial dependence via
, which is a
-type measure reflecting the extent of (dis)agreement between lagged observations, recall (
9). More precisely,
can be interpreted as weighted type of
, where the weights
depend on the particular choice of
. It thus provides a novel family of measures of signed serial dependence, the asymptotics of which are analyzed in
Section 4 below.
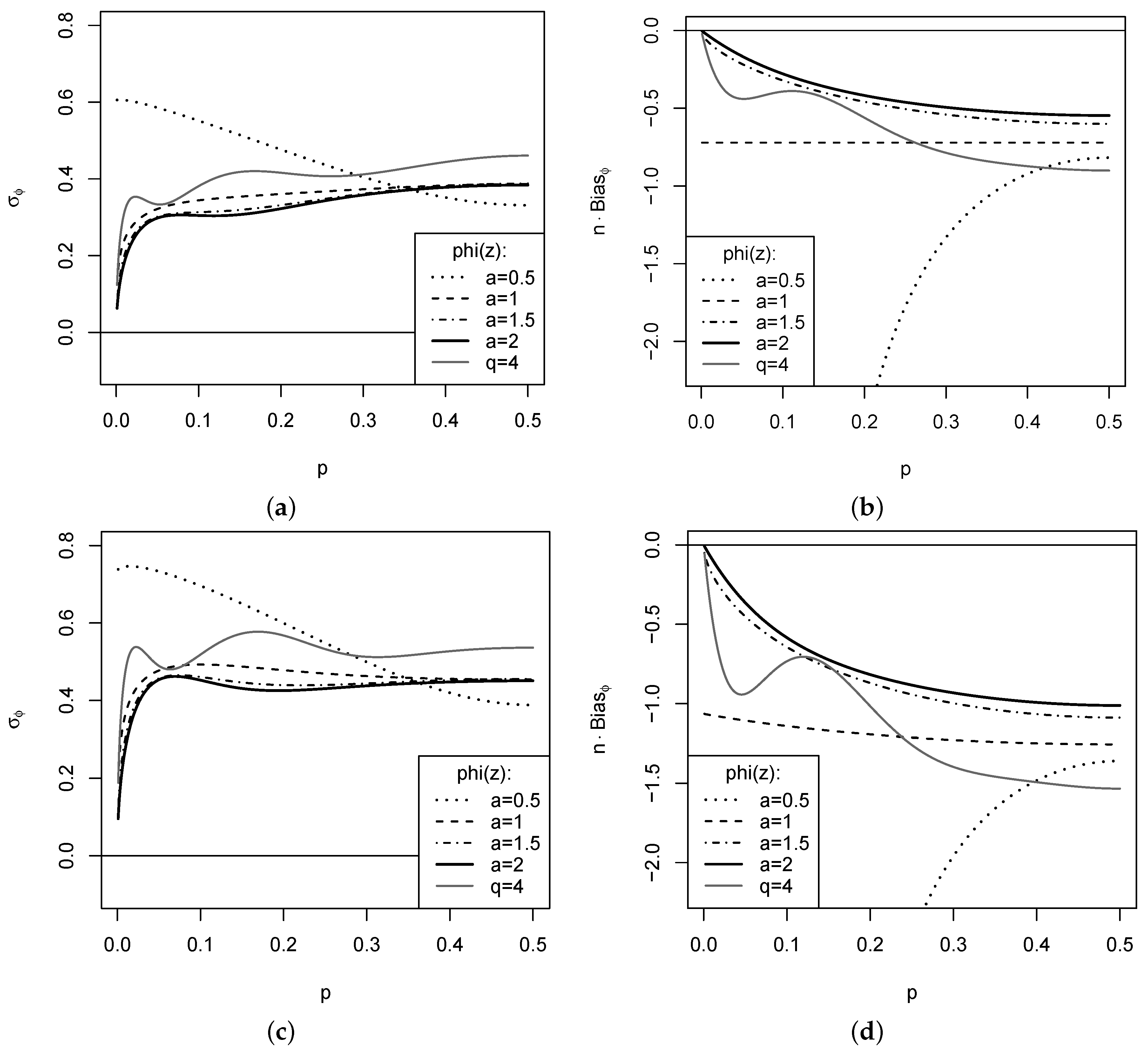
Example 2. In the special case (as well as for ), which corresponds to the IOV in (4), is constant (see Table 1). Thus, in this case (see (9)). Furthermore, the first factor of the bias in Theorem 1 becomesHence, the bias is determined by both the serial dependence and the dispersion of the process. As another simple example, consider the choice for the in (5). Then, using from Table 1, we getThus, we have a unique i. i. d.-bias, independent of the actual marginal CDF f. Under serial dependence, we getSo, besides the pair , also belongs to the -family. A few examples are plotted in Figure 3, where the DGP assumes the rank counts to have -marginals. In the top panel, the DGP is i. i. d., whereas follows a so-called first-order binomial autoregressive (BAR) model with dependence parameter ([2] Section 3.3) in the lower panel, i.e., the DGP exhibits a medium level of positive dependence. While the resulting dependence structure is investigated in more detail in Section 4, Figure 3 considers the asymptotic standard error (SE) and bias according to Theorem 1. Obviously, an increase of serial dependence causes an increase of both SE and bias. While most measures have a rather stable SE for varying p (except for extremely small p, where we are close to a one-point distribution), the EGF with varies a lot. In particular, the bias takes rather extreme values with decreasing p for this case, which can be explained by the strongly negative exponents at in from Table 1. Thus, choices seem not advisable for practice. The boundary case has a constant bias for an i. i. d. DGP. For with , we note an oscillating behavior of both bias and SE. The lowest bias and SE are achieved for the cases with . The newly obtained measure
from (
14) constitutes a counterpart to the nominal measures
in Weiß [
20]. It is worth pointing out that the latter measures were derived from the nominal entropy and extropy, respectively, while the
in (
5) can be interpreted as a combination of cumulative entropy and extropy. It has to be noted that
also shares a disadvantage with
: if only one of the
equals 0 or 1, we suffer from a division by 0 in (
14). For
according to (
9), by contrast, a division by 0 only happens in the (deterministic) case of a one-point distribution. As a workaround when computing
, it is recommended to replace the affected summands in (
14) by 0.
Remark 3. If , then all in (10). Therefore, the linear term in (11) vanishes. In fact, for any two-point distribution on and , we necessarily have and . Therefore, reduces to , and the quadratic term in (11) to . Hence, in this special case,For example, plugging-in for corresponding to the IOV in (4), we obtain the result in Remark 7.1.2 in Weiß [
14].
4. Asymptotic Distribution of Sample
The bias equation in Theorem 1 gives rise to a novel family of serial dependence measures for ordinal time series, namely
for a given EGF
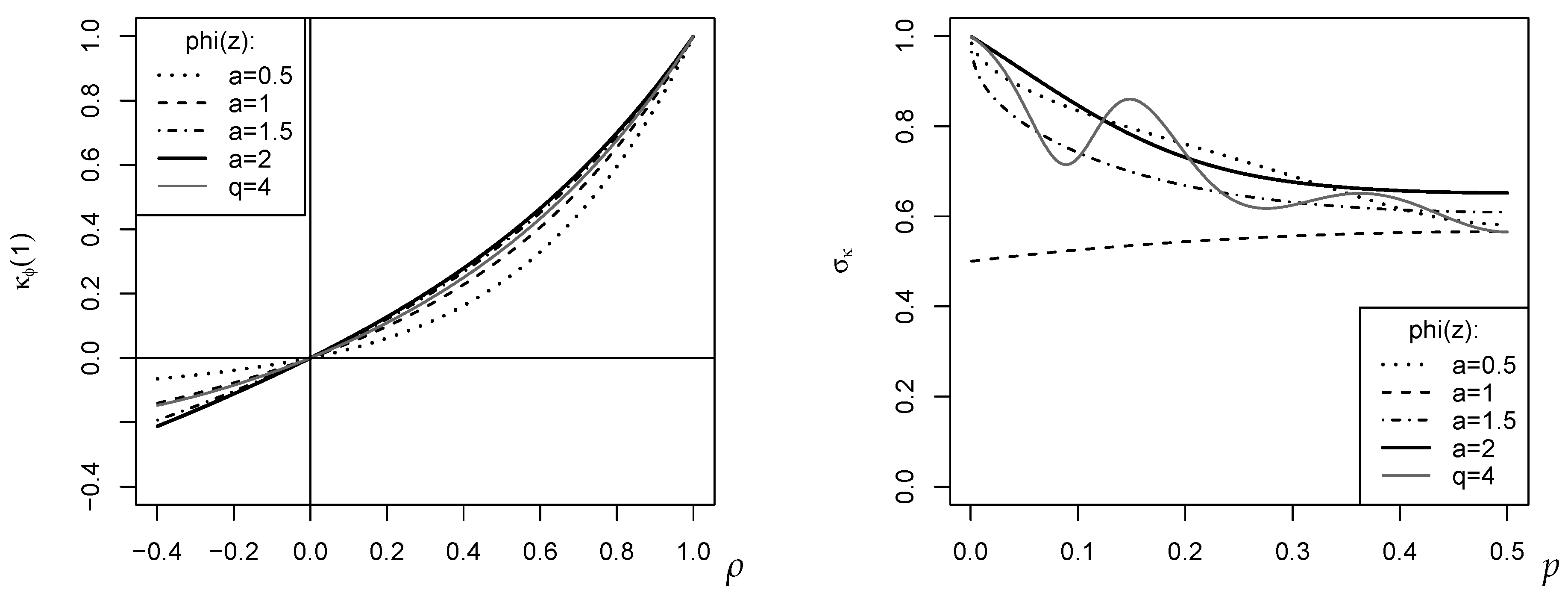
. Some examples are plotted in the left part of
Figure 4, where the DGP
assumes that the rank counts
follow the BAR
model with marginal distribution
and dependence parameter
; recall the discussion of
Figure 3. So, the rank counts
have the first-order ACF
, whereas the plotted
have absolute value
.
In practice, the sample version of this measure,
, is particularly important, where the cumulative (bivariate) probabilities are replaced by the corresponding relative frequencies. For uncovering significant deviations from the null hypothesis of serial independence (then,
), the asymptotic distribution of
under the null of i. i. d. time series data is required. For its derivation, we proceed in an analogous way as in
Section 3. As the starting point, we have to extend the asymptotics of the marginal sample CDF in (
8) by also considering the bivariate sample CDF
. Let
, and denote its sample version by
. Then, under the same mixing conditions as in
Section 3, Weiß [
14] established the asymptotic normality
and he derived general expressions for the asymptotic (co)variances
. Analogous results for the case of missing data can be found in Supplement S.3 of Weiß [
15]. For the present task, the asymptotics of the i. i. d.-case are sufficient. Then,
for all
, and the covariances in (
16) are given by
see Weiß [
14] (as well as p. 8 in Supplement S.3 of Weiß [
15] if being concerned with missing data).
Next, we derive the asymptotics of
under the i. i. d.-null, and this requires to derive the second-order Taylor expansion for
; details are postponed to
Appendix A.1. As higher-order derivatives of
, which are initially used while deriving a bias correction of
, cancel out, the final result still relies on derivatives of
up to order 2 only.
Theorem 2. Under the null hypothesis of i. i. d. data, i.e., if for all lags , and assuming the EGF ϕ to be twice differentiable, it holds that In addition, the bias-corrected mean of is .
Note that we have a unique bias correction for any of the measures
, independent of the choice of the EGF
. Thus, for application in practice, it remains to compute the asymptotic variance
in Theorem 2. This only requires knowledge about
to evaluate the
, but not about higher-order derivatives of the EGF
(see Example 3 for illustration). Further examples are plotted in the right part of
Figure 4, where
was computed for the marginal distribution
. The oscillating behavior of
for
with
is quite striking. It is also interesting to note that among the plotted
-measures, the novel
(case
) has the lowest variance.
Example 3. While we have a unique bias correction for , the asymptotic variance according to Theorem 2 differs for different choices of the EGF ϕ, as the involved depend on . For example,
for , we have according to Example 1,
while for with , we have .
Important special cases are:
For , i.e., for the basic according to (9), we have see Theorem 7.2.1 in Weiß [14]. For , i.e., for the novel according to (14), we have
For any other choice of and , is easily computed using the aforementioned expressions for and from Example 1. Since the obtained closed-form formulae do not much simplify, further details are omitted here.
5. Simulation Results
In what follows, we discuss results from a simulation study, being tabulated in
Appendix B, where
replications per scenario were used throughout. In view of our previous findings, achieved when discussing the asymptotics plotted in
Figure 3 and
Figure 4, we do not further consider the choice
for the EGF
, but we use
instead. The latter choice, in turn, was not presented before as the resulting asymptotic curves could hardly be distinguished from the case
. So, altogether,
as well as
were taken into account for simulations. The ordinal data were generated via binomial rank counts,
with
, which either exhibit serial dependence caused by a BAR
DGP with dependence parameter
, or which are i. i. d. (corresponding to
).
Let us start with the ordinal dispersion measures
.
Table A1 presents the simulated means (upper part) and SEs (lower part) for the case of i. i. d. ordinal data, and these are compared to the asymptotic values obtained from Theorem 1. Generally, we have an excellent agreement between simulated and asymptotic values, i.e., the derived asymptotic approximation to the true distribution of
works well in practice. This is even more remarkable as also the low sample size
is included. There is a somewhat larger deviation only for the mean in the case
, i.e., for the CPE (
5), if
and
. In this specific case, the simulated sample distribution might be quite close to a one-point distribution, which might cause computational issues for (
5); recall that the convention
has to be used. However, as the approximation quality is good throughout, a pivotal argument for the choice of
in practice might be that the least SEs are observed if using
with
.
Table A2 considers exactly the same marginals as before, but now in the presence of additional serial dependence (
). Comparing
Table A1 and
Table A2, it becomes clear that the additional dependence causes increased bias and SE. However, and this is the crucial point for practice, the asymptotic approximations from Theorem 1 work as well as they do in the i. i. d.-case. If there are visible deviations at all, then these happen again mainly for
and low sample sizes. Overall, we have an excellent approximation quality throughout, but with least SEs again for
.
While the
-type dispersion measures and their asymptotics perform well, essentially for any choice of
, the gap becomes wider when looking at the serial dependence measure
. The asymptotics in Theorem 2 refer to the i. i. d.-case, which is used as the null hypothesis (
) if testing for significant serial dependence. Thus, let us start by investigating again the mean and SE of
for i. i. d. data (same DGPs as in
Table A1); see the results in
Table A3. For the asymptotic mean, we have the unique approximation
, and this works well except for
and low sample sizes. In particular, for
with
, i.e., for
, we get notable deviations. The reason is given by the computation of
, where division by zero might happen (in the simulations, this was circumvented by replacing a zero by
). In a weakened form, we observe a similar issue for the case
; generally, we are faced with the zero problem if
because of the second-order derivatives of
. Analogous deviations are observed for the SEs. Here, generally, the simulated SEs tend to be larger than the asymptotic ones. As a consequence, if using the asymptotic SEs for calculating the critical values when testing
, we expect a tendency to oversizing.
If looking at the simulated rejection rates in
Table A4, first at the size values (
) being printed in italic font, we indeed see sizes being slightly larger than the nominal 5%-level, as long as
. For larger sample sizes, by contrast, the
-test satisfies the given size requirement quite precisely. Here, we computed the critical values by plugging-in the respective sample CDF
into the formula for
. In
Table A4, power values for
are also shown. Note that for a BAR
process,
can take any positive value in
, but the attainable range of negative values is bounded from below by
[
2]. Thus, only
are considered in
Table A4. Generally, the
-tests are powerful regarding both positive and negative dependencies, but the actual power performance differs a lot for different
. The worst power is observed for
with
, followed by
with
. Regarding the remaining
-cases,
does slightly worse than
, and we often have a slight advantage for
, especially for negative dependencies.
To sum up, while the whole
-family is theoretically appealing, and while there are hardly any noteworthy problems with the sample dispersion measures
, the performance of
clearly depends on the choice of
. It is recommended to use the family of
a-entropies (
6), and there,
is preferable. The measure
from (
14), for example, although theoretically appealing as a combination of entropy and extropy, has a relatively bad finite-sample performance. The probably most well-known pair,
, has a good performance, although there appears to be a slight advantage if choosing
a somewhat larger than 2, such as
(recall that
leads back to the case
).
6. Data Application
Ordinal time series are observed in quite diverse application areas. Economic examples include time series on credit ratings [
14] or on fear states at the stock market [
20], and a climatological example is the level of cloudiness of the sky [
23]. Health-related examples are time series of electroencephalographic (EEG) sleep states [
24], the pain severity of migraine attacks, and the level of perceived stress [
15]. In this section, we are concerned with an environmental application, namely the level of air quality. Different definitions of air quality have been reported in the literature. In Chen Chiu [
25], the air quality index (AQI) is used for expressing the daily air quality, with levels ranging from
to
. Another case study is reported by Liu et al. [
26], who use the classification of the Chinese government, which again distinguishes
levels, but now ranging from
to
. The latter article investigates daily time series from thirty Chinese cities for the period December 2013–July 2019, i.e., the sample size equals
. In what follows, we use one of the time series studied by Liu et al. [
26], namely the daily air quality levels
in Shanghai, for illustrating our novel results about cumulative paired
-entropies.
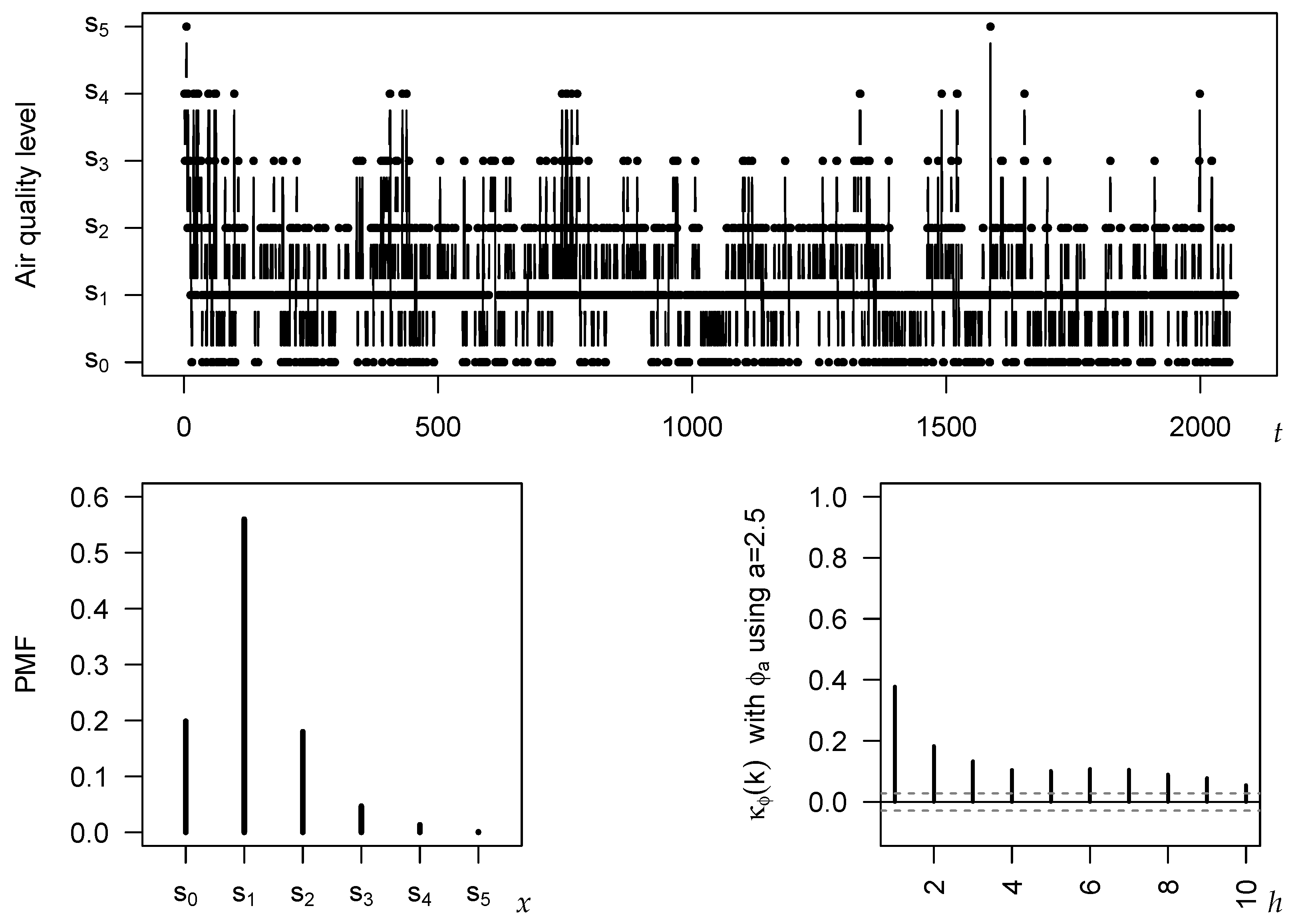
The considered time series is plotted in the top panel of
Figure 5. The bottom left graph shows the sample version of the probability mass function (PMF)
, i.e., the relative frequencies of the categories. It exhibits a unimodal shape with mode (=median) in
. The serial dependence structure is analyzed in the bottom right graph, where
with
a-entropy having
is used, as this is the recommended choice according to
Section 5. All of the plotted
-values are significantly different from 0 at the 5 %-level, where the critical values (plotted as dashed lines in
Figure 5) are computed as
according to Theorem 2 (and by plugging-in the sample CDF). We recognize a medium level of dependence (
), which quickly decreases with increasing time lag
h, similar to an AR-type process.
Let us now have a closer look at the dispersion properties of the Shanghai series. The different choices of the
-measure considered so far provide slightly different results regarding the extent of dispersion. In accordance with
Figure 2, the largest point estimates are computed for
(0.514) and
(0.465), followed by
with 0.394, whereas
(0.349),
(0.332), and
(0.328) lead to similar but clearly lower values. Comparing the sample PMF in
Figure 5 to the extreme scenarios of a one-point and an extreme two-point distribution, the PMF appears to be more close to a one-point than to a two-point distribution, i.e., the lower ones among the above dispersion values seem to be more realistic here.
The novel asymptotics of Theorem 1 allow to judge the estimation uncertainty for the above point estimates. To keep the discussion simple, let us focus again on the case
. In the first step, we compute the i. i. d.-approximations of bias and SE,
and
, respectively. By plugging-in the sample CDF, these are obtained as
and
, respectively. However, these i. i. d.-results are misleading in the present example as the data exhibit significant serial dependence (recall
Figure 5). As we know from Theorem 1, the bias has to be increased by the factor
, and the SE by
. These factors shall now be computed based on the so-called “ZOBPAR model” proposed by Liu et al. [
26], which constitutes a rank-count approach,
. In view of the AR
-like dependence structure and the high frequency for
, namely 0.560, the conditional distribution of
is assumed to be a truncated Poisson distribution, truncated to the range
, with time-varying Poisson parameter
and additional one-inflation parameter 0.3463 ([
26] Table III). For this model fit, we compute
Thus, an approximate 95 %-confidence interval (CI) for
is given by
. CIs for the remaining
-measures are computed analogously, leading to
for
, to
for
, to
for
, to
for
, and to
for
.
7. Conclusions
In this article, we considered the family of cumulative paired -entropies. For each appropriate choice of the EGF , an ordinal dispersion measure is implied. For example, particular choices from the families of a-entropies or q-entropies, respectively, lead to well-known dispersion measures from the literature. The first main contribution of this work was the derivation of the asymptotic distribution of the sample version for ordinal time series data. These asymptotics can be used to approximate the true distribution of , e.g., to compute approximate confidence intervals. Simulations showed that these asymptotics lead to an excellent finite-sample performance. Based on the obtained expression for the asymptotic bias of , we recognized that each EGF also implies a -type serial dependence measures, i.e., altogether, we have a matched pair for each EGF . Again, we analyzed the asymptotics of the sample version , and these can be utilized for testing for significant serial dependence in the given ordinal time series. This time, however, the finite-sample performance clearly depends on the choice of . Choosing based on an a-entropy with , such as , ensures good finite-sample properties. The practical application of the measures and their asymptotics was demonstrated with an ordinal time series on the daily level of air quality in Shanghai.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}