
Inferring a Property of a Large System from a Small Number of Samples


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- -
- A new method to construct Bayesian estimators is proposed;
- -
- The method is applicable to arbitrary quantities ;
- -
- A conceptual framework is provided, in which the one-dimensional nature of the problem is exploited;
- -
- The search of the prior is restricted to the level surfaces of ;
- -
- The Maxentropy principle is employed to capitalize both what we know and what we do not know about the prior;
- -
- The performance of the method is tested in known examples;
- -
- The conceptual connection with equilibrium statistical mechanics is highlighted.
2. Rationale of the Inference Process
2.1. A Bayesian Approach to the Inference Problem
2.2. Defining the Prior on the Level Surfaces of the Property
2.3. Decomposing the Prior as a Linear Combination of a Family of Base Priors
2.4. A Maxentropy Strategy to Select the Base of Functions to Expand the Prior
2.5. The Estimation of the Property for Each Member of the Base
2.6. Considering Different Values
3. Applications to Different Properties
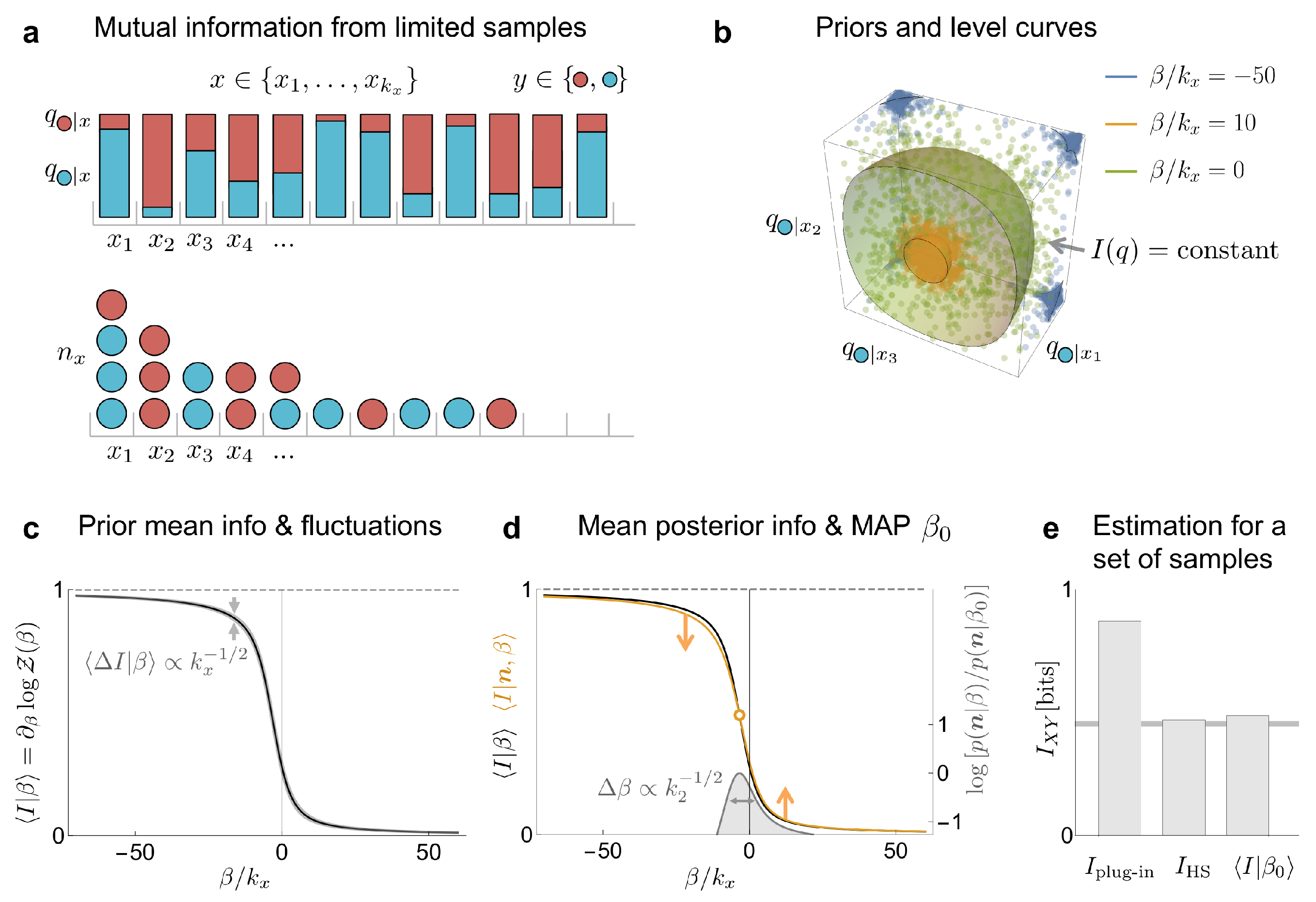
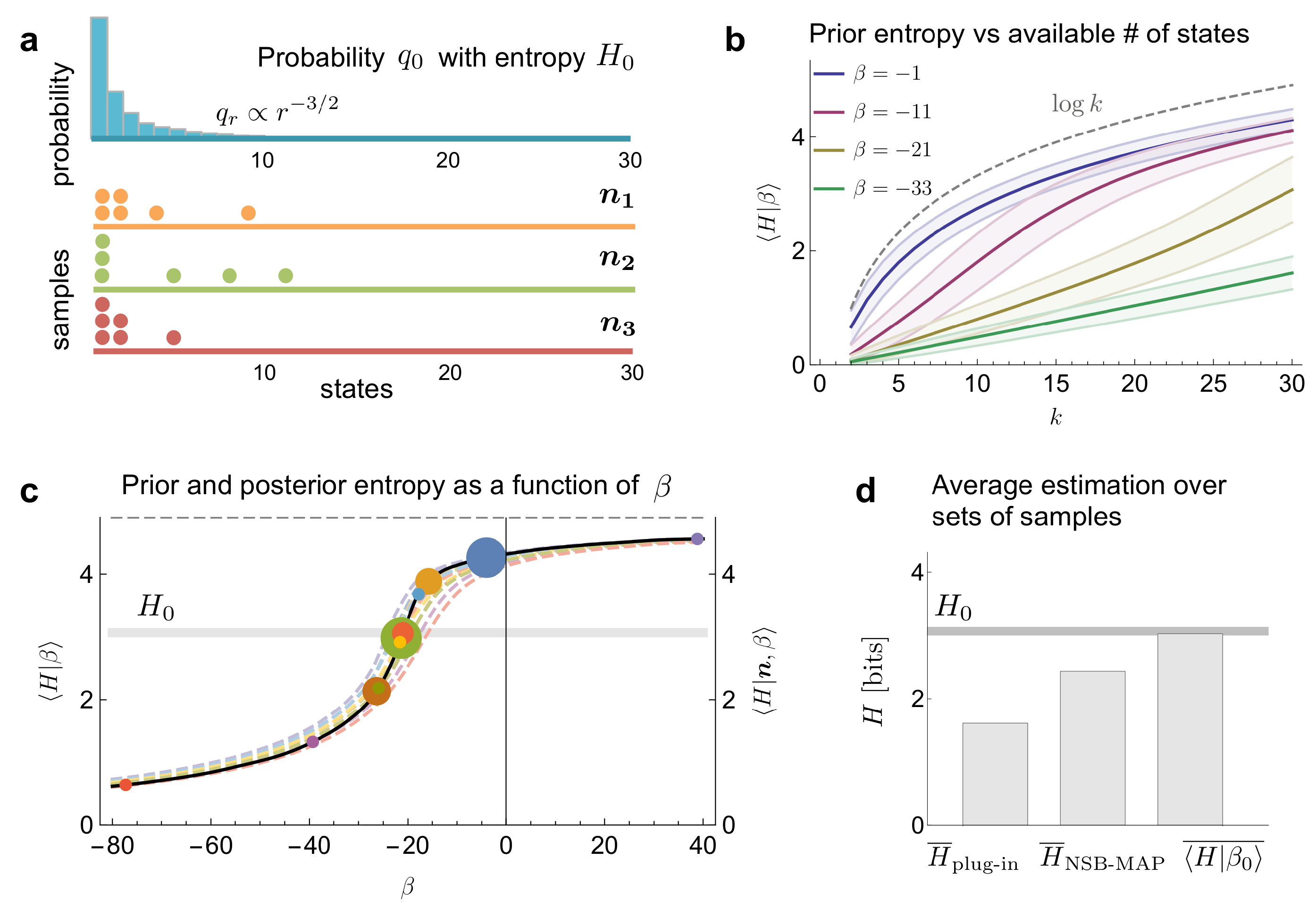
3.1. Marginal Probability
3.2. Mutual Information
3.3. Entropy
4. Discussion
Conditions of Validity
Identifying the Factors That Matter When Searching for the Prior
The Core of the Approach: Decomposing the Prior in a Conveniently Chosen Base of Priors
Assessing the Effectiveness of the Method
Future Perspectives
Conclusions
- (a)
- It offers a general framework to select priors that is valid for arbitrary properties ;
- (b)
- It performs well in the estimation of well-known quantities, as marginal distributions, mutual information and entropy, with performance comparable or even better than previous estimators individually tailored for each property;
- (c)
- It reveals the formal similarity between inference problems and equilibrium statistical mechanics. In particular, the parameter is analogous to the inverse temperature of statistical physics, and the two alternative expansions of the prior (in a delta-like or an exponential-like base) correspond to the microcanonical and the canonical ensembles, respectively.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nemenman, I. Coincidences and estimation of entropies of random variables with large cardinalities. Entropy 2011, 13, 2013–2023. [Google Scholar] [CrossRef] [Green Version]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [Green Version]
- Nemenman, I.; Bialek, W.; van Steveninck, R.d.R. Entropy and information in neural spike trains: Progress on the sampling problem. Phys. Rev. E 2004, 69, 056111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Archer, E.; Park, I.M.; Pillow, J.W. Bayesian entropy estimation for countable discrete distributions. J. Mach. Learn. Res. 2014, 15, 2833–2868. [Google Scholar]
- Chao, A.; Wang, Y.; Jost, L. Entropy and the species accumulation curve: A novel entropy estimator via discovery rates of new species. Methods Ecol. Evol. 2013, 4, 1091–1100. [Google Scholar] [CrossRef]
- Grassberger, P. Entropy estimates from insufficient samplings. arXiv 2003, arXiv:physics/0307138. [Google Scholar]
- Archer, E.; Park, I.M.; Pillow, J.W. Bayesian and quasi-Bayesian estimators for mutual information from discrete data. Entropy 2013, 15, 1738–1755. [Google Scholar] [CrossRef]
- Hernández, D.G.; Samengo, I. Estimating the Mutual Information between Two Discrete, Asymmetric Variables with Limited Samples. Entropy 2019, 21, 623. [Google Scholar] [CrossRef] [Green Version]
- Contreras-Reyes, J.E. Mutual information matrix based on asymmetric Shannon entropy for nonlinear interactions of time series. Nonlinear Dyn. 2021, 104, 3913–3924. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 108, 171–190. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics II. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Amari, S.I.; Hiroshi, N. Methods of Information Geometry; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Amari, S.I. Information Geometry on Hierarchy of Probability Distributions. IEEE Trans. Inf. Theory 2001, 47, 1701–1711. [Google Scholar] [CrossRef] [Green Version]
- Panzeri, S.; Treves, A. Analytical estimates of limited sampling biases in different information measures. Netw. Comput. Neural Syst. 1996, 7, 87. [Google Scholar] [CrossRef] [PubMed]
- Samengo, I. Estimating probabilities from experimental frequencies. Phys. Rev. E 2002, 65, 046124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef] [Green Version]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables; Dover Publications: New York, NY, USA, 1965. [Google Scholar]
- Montemurro, M.A.; Senatore, R.; Panzeri, S. Tight data-robust bounds to mutual information combining shuffling and model selection techniques. Neural Comput. 2007, 19, 2913–2957. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Tracey, B.D. Estimating mixture entropy with pairwise distances. Entropy 2017, 19, 361. [Google Scholar] [CrossRef] [Green Version]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual information neural estimation. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 531–540. [Google Scholar]
- Safaai, H.; Onken, A.; Harvey, C.D.; Panzeri, S. Information estimation using nonparametric copulas. Phys. Rev. E 2018, 98, 053302. [Google Scholar] [CrossRef] [Green Version]
- Holmes, C.M.; Nemenman, I. Estimation of mutual information for real-valued data with error bars and controlled bias. Phys. Rev. E 2019, 100, 022404. [Google Scholar] [CrossRef] [Green Version]
- Miller, G. Note on the bias of information estimates. In Information Theory in Psychology: Problems and Methods; Free Press: Glencoe, IL, USA, 1955. [Google Scholar]
- Chao, A.; Shen, T.J. Nonparametric estimation of Shannon’s index of diversity when there are unseen species in sample. Environ. Ecol. Stat. 2003, 10, 429–443. [Google Scholar] [CrossRef]
- Berry II, M.J.; Tkačik, G.; Dubuis, J.; Marre, O.; da Silveira, R.A. A simple method for estimating the entropy of neural activity. J. Stat. Mech. Theory Exp. 2013, 2013, P03015. [Google Scholar] [CrossRef]
- MacKay, D. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Zdeborová, L.; Krzakala, F. Statistical physics of inference: Thresholds and algorithms. Adv. Phys. 2016, 65, 453–552. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–22. [Google Scholar]
- Staniek, M.; Lehnertz, K. Symbolic transfer entropy. Phys. Rev. Lett. 2008, 100, 158101. [Google Scholar] [CrossRef] [PubMed]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernández, D.G.; Samengo, I. Inferring a Property of a Large System from a Small Number of Samples. Entropy 2022, 24, 125. https://doi.org/10.3390/e24010125
Hernández DG, Samengo I. Inferring a Property of a Large System from a Small Number of Samples. Entropy. 2022; 24(1):125. https://doi.org/10.3390/e24010125
Chicago/Turabian StyleHernández, Damián G., and Inés Samengo. 2022. "Inferring a Property of a Large System from a Small Number of Samples" Entropy 24, no. 1: 125. https://doi.org/10.3390/e24010125
APA StyleHernández, D. G., & Samengo, I. (2022). Inferring a Property of a Large System from a Small Number of Samples. Entropy, 24(1), 125. https://doi.org/10.3390/e24010125