
Visual Recognition of Traffic Signs in Natural Scenes Based on Improved RetinaNet

Abstract
:1. Introduction
2. Related Work
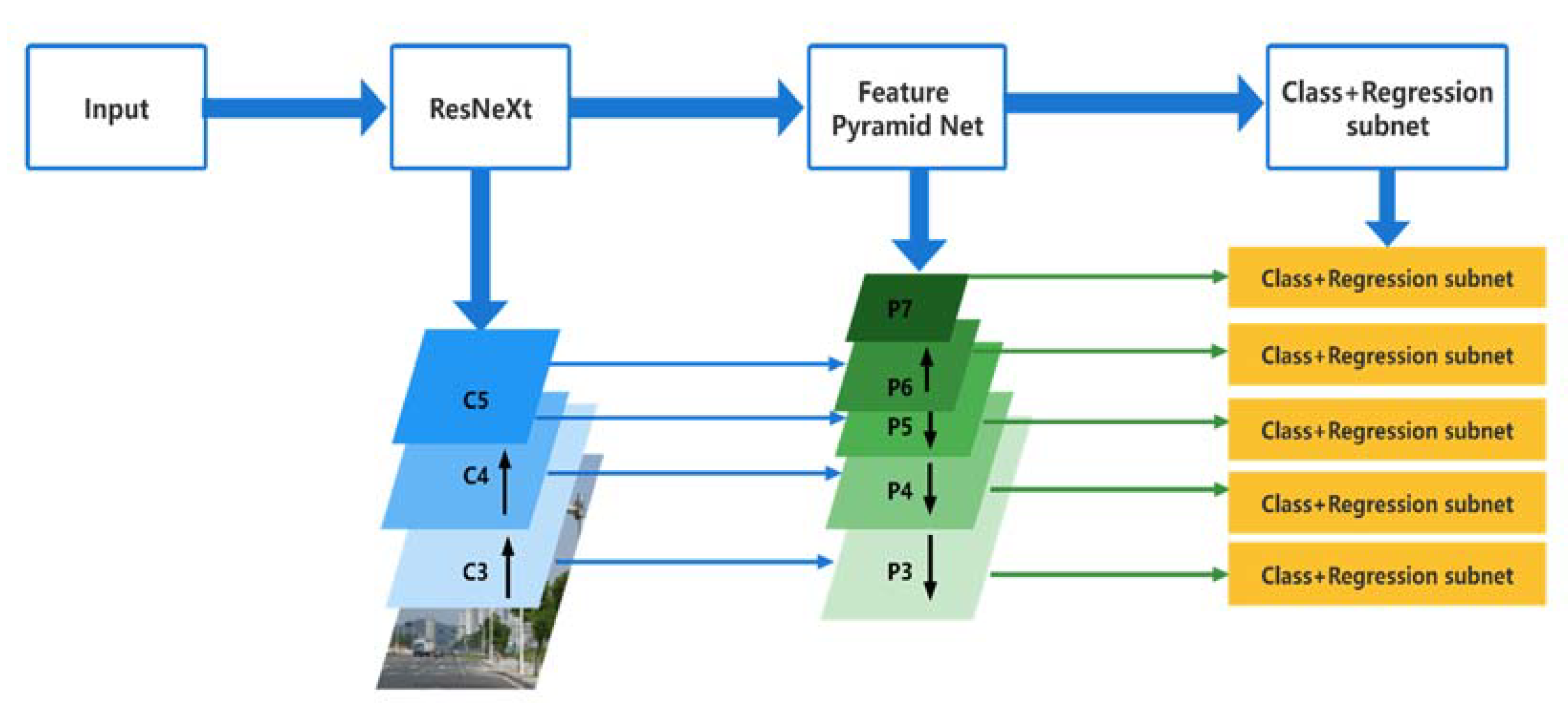
3. The Proposed Methods
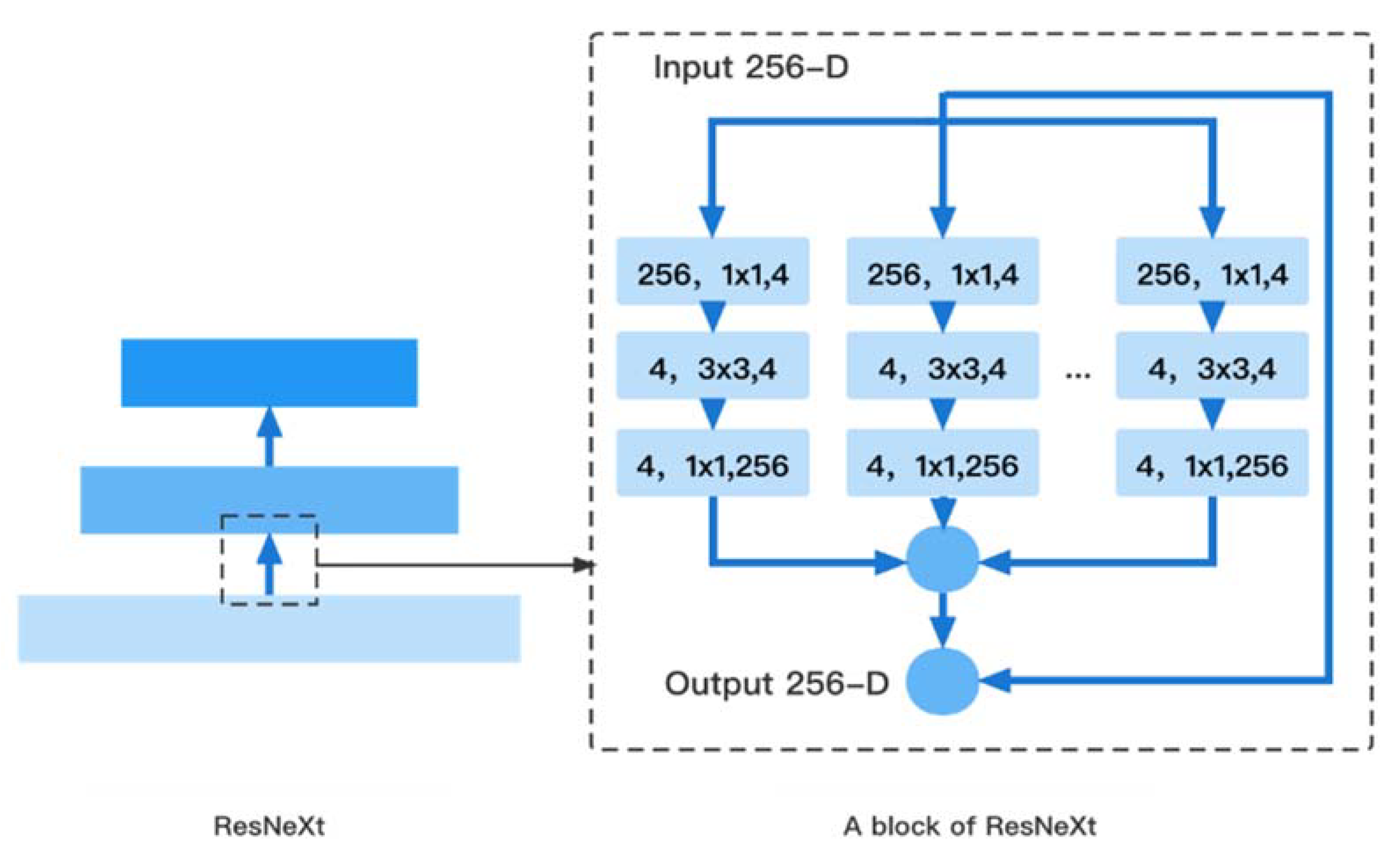
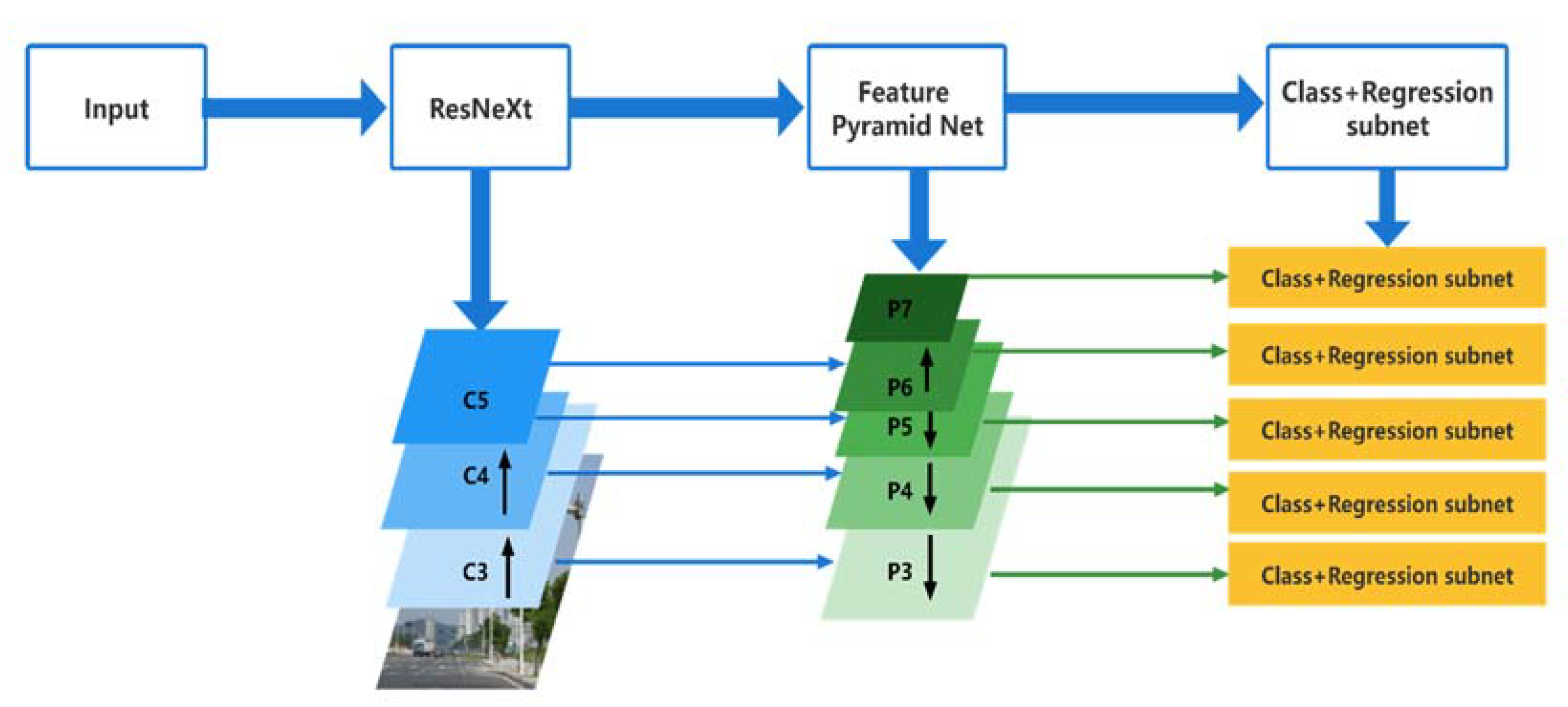
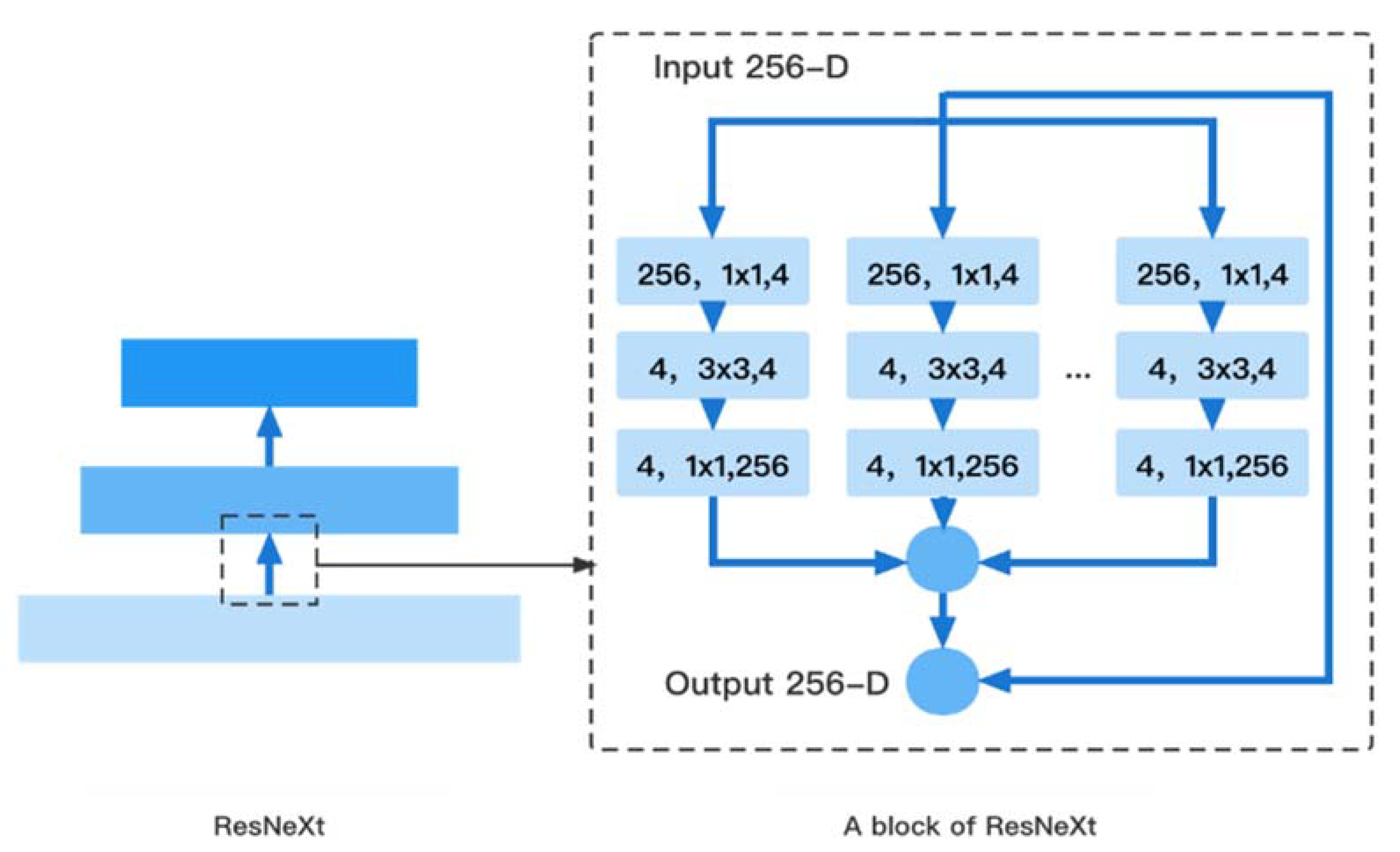
3.1. Feature Extraction Network
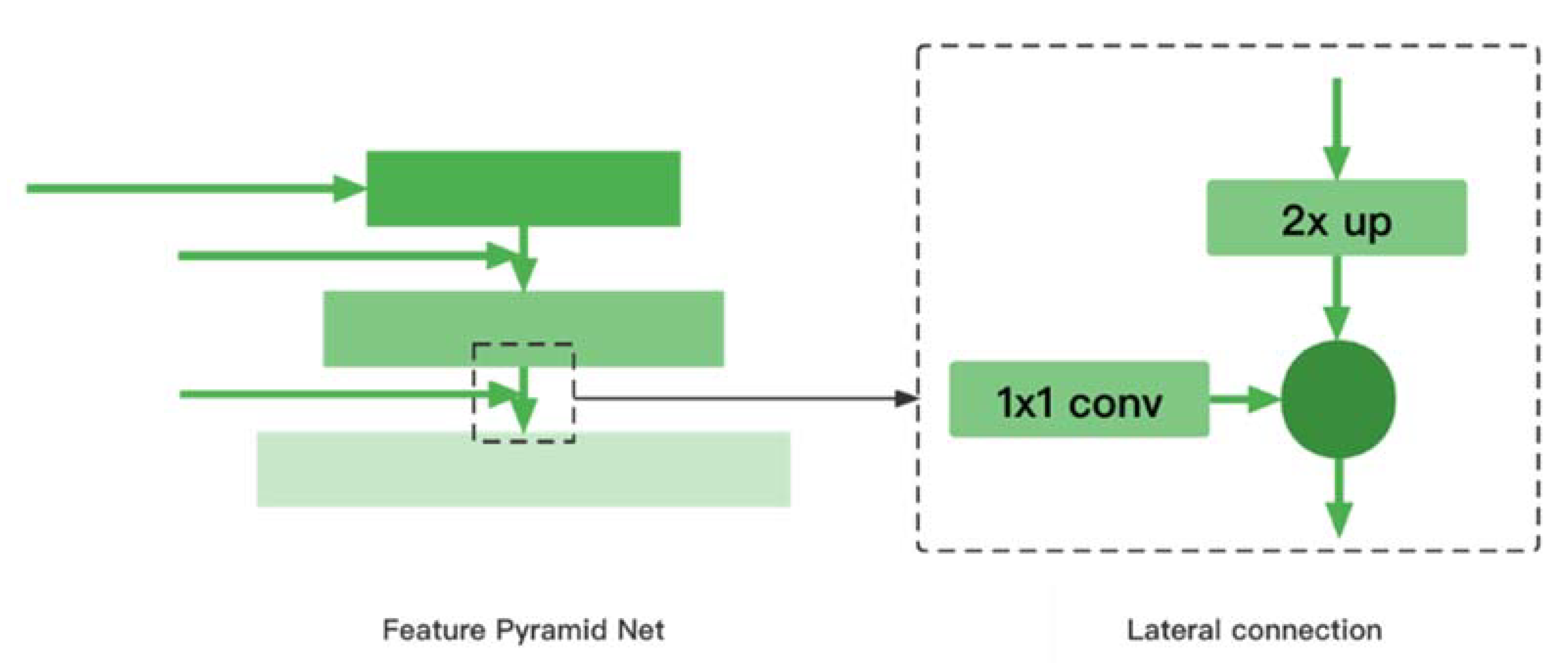
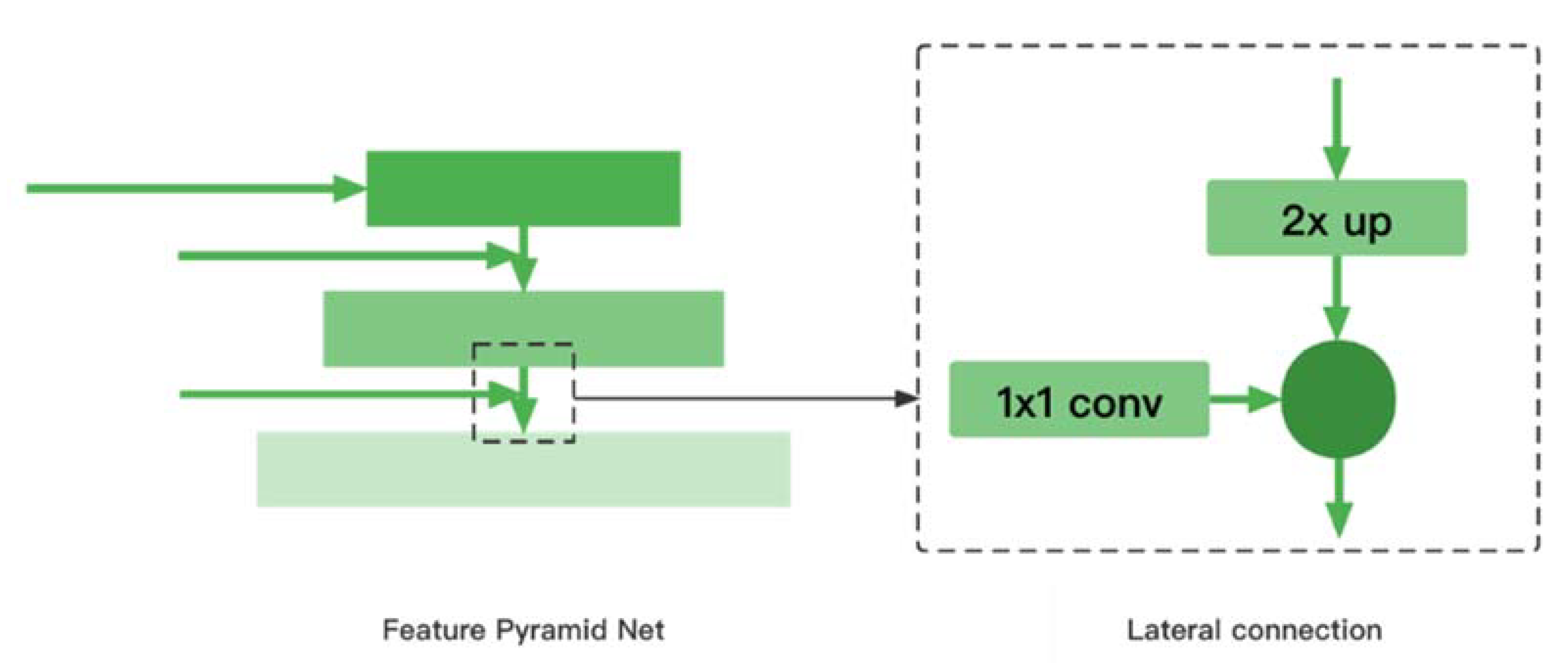
3.2. Feature Pyramid Network
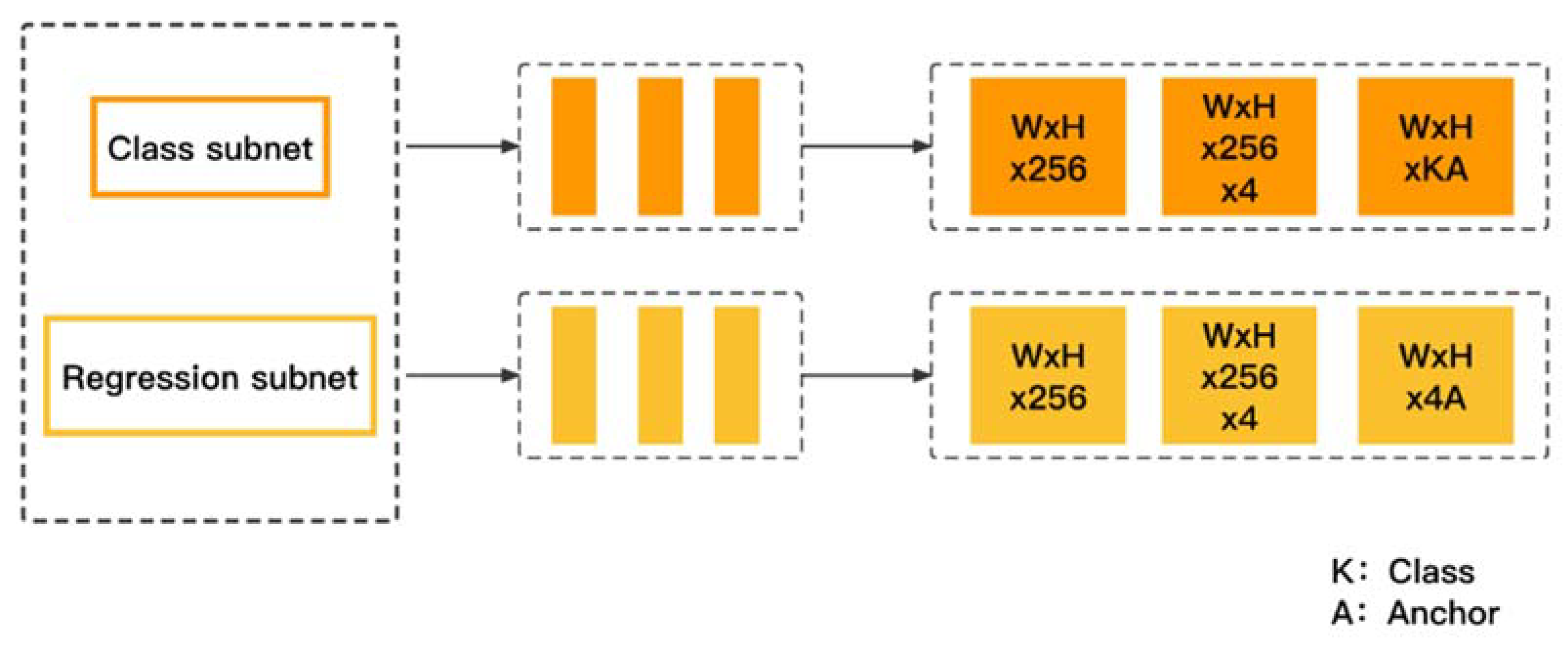
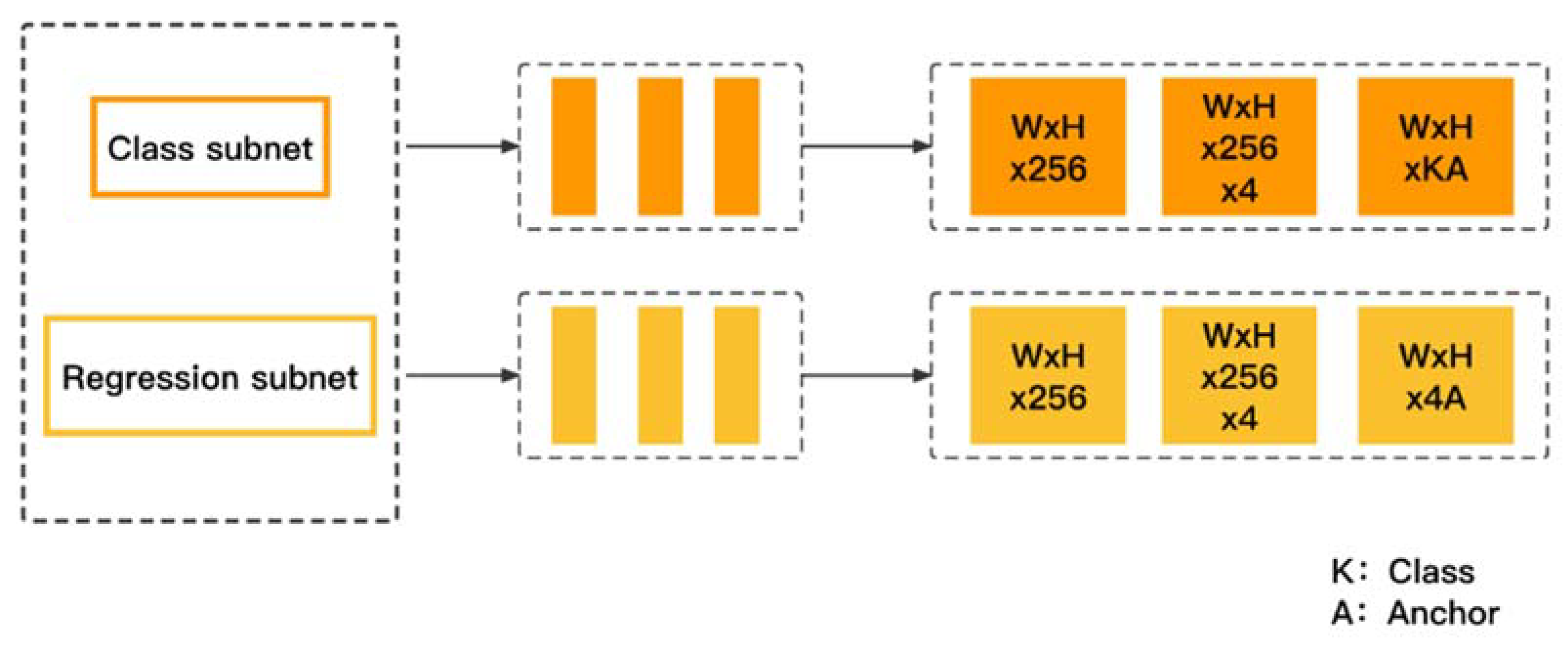
3.3. Classification and Regression Subnets
3.4. Group Normalization
3.5. Focal Loss
4. Experiments and Results
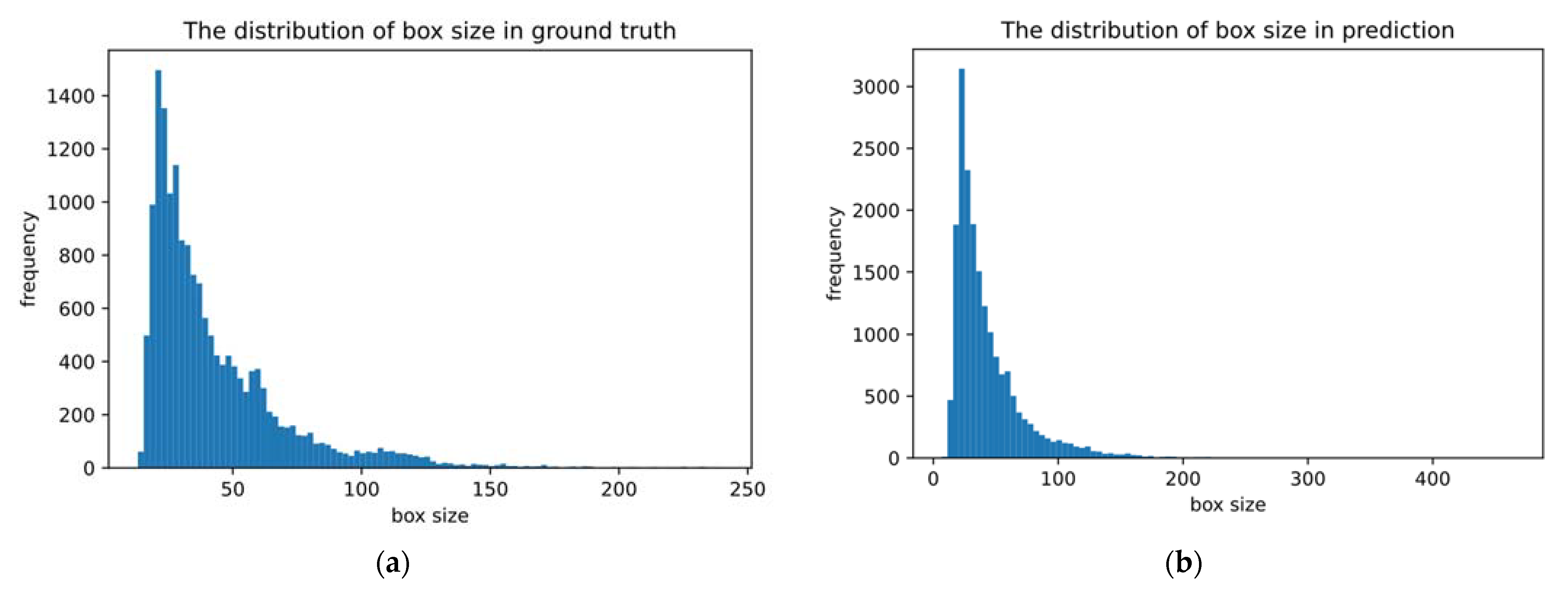
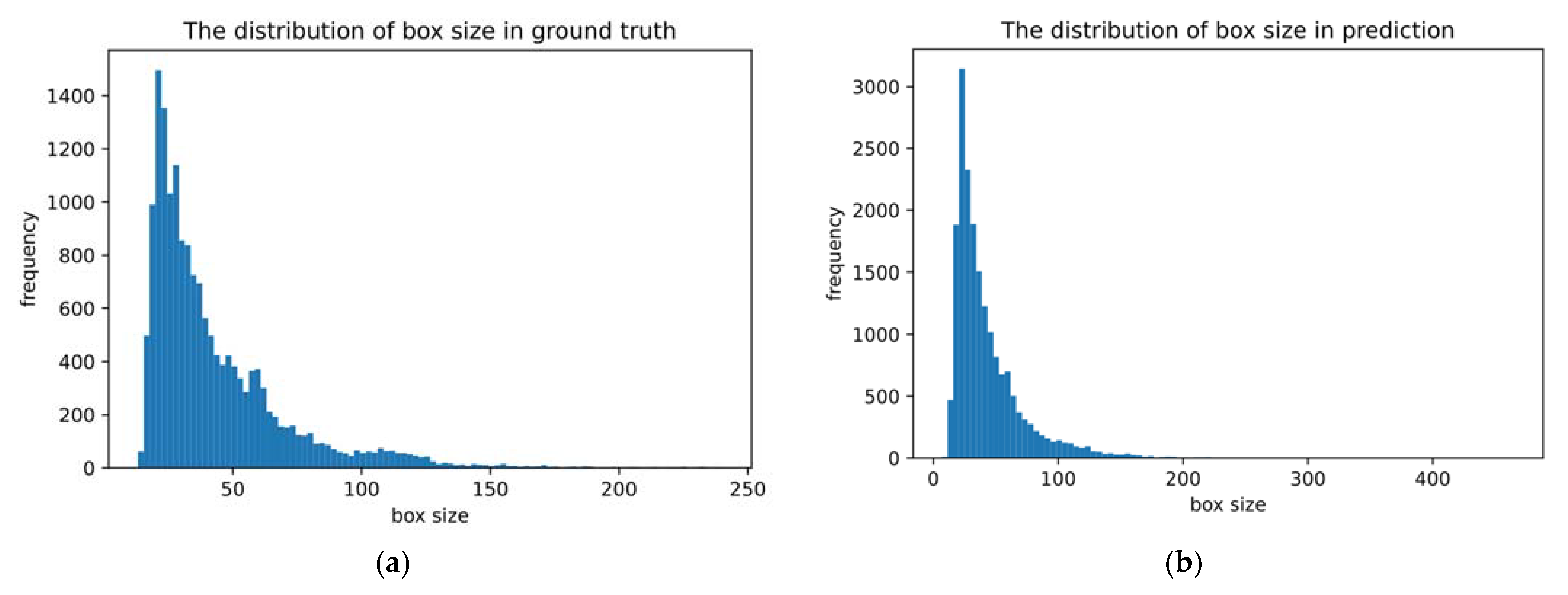
4.1. Dataset and Augmentation Methods
4.2. Evaluation Metrics
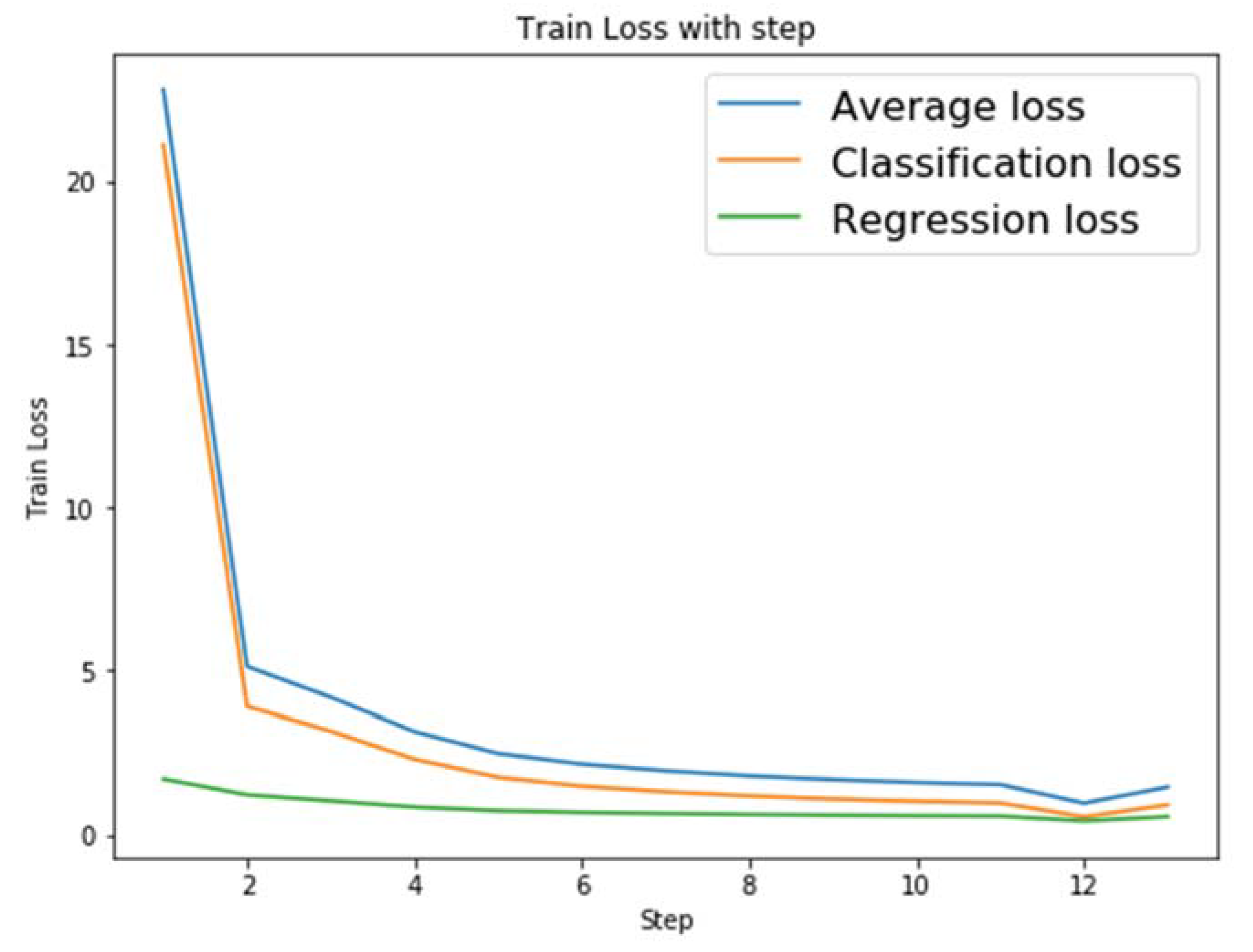
4.3. Effectiveness Experiments
4.4. Comparison and Analysis of Different Detection Frameworks
4.5. Comparison and Analysis of Different Models
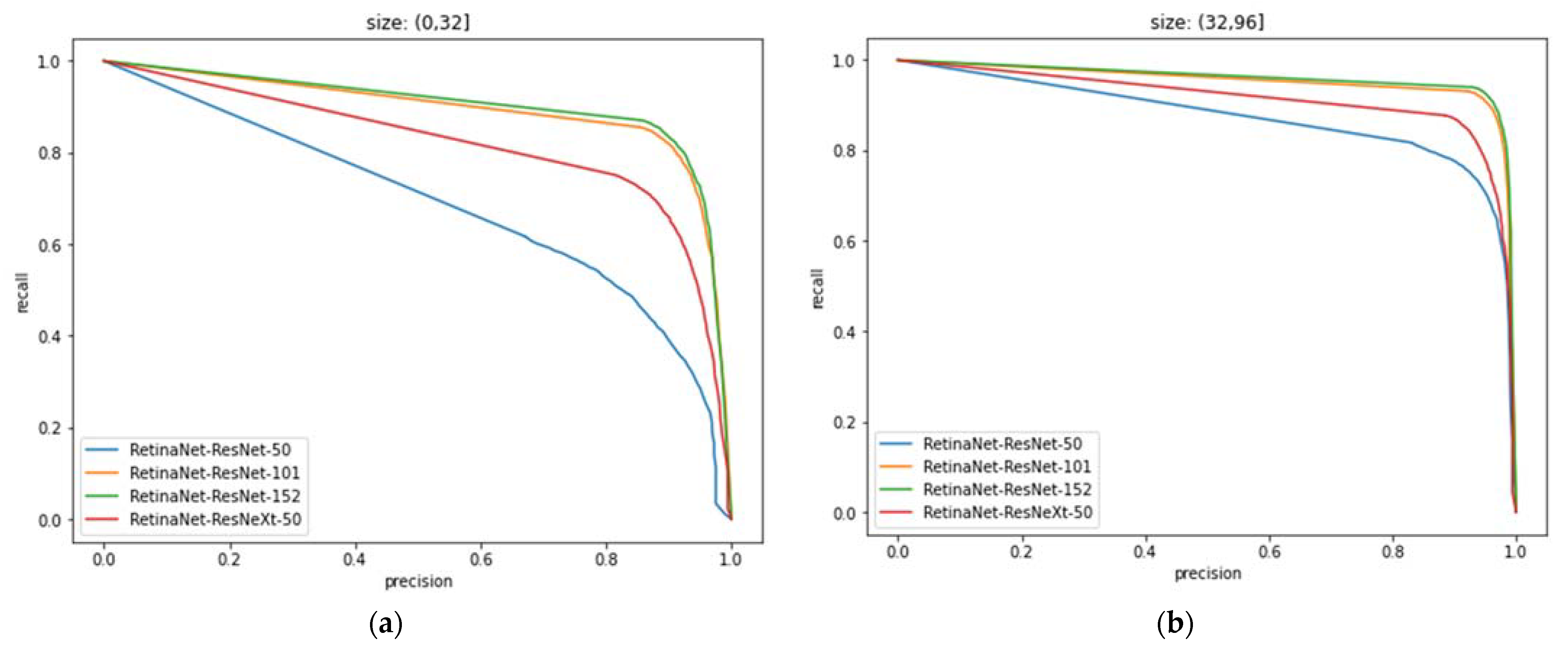
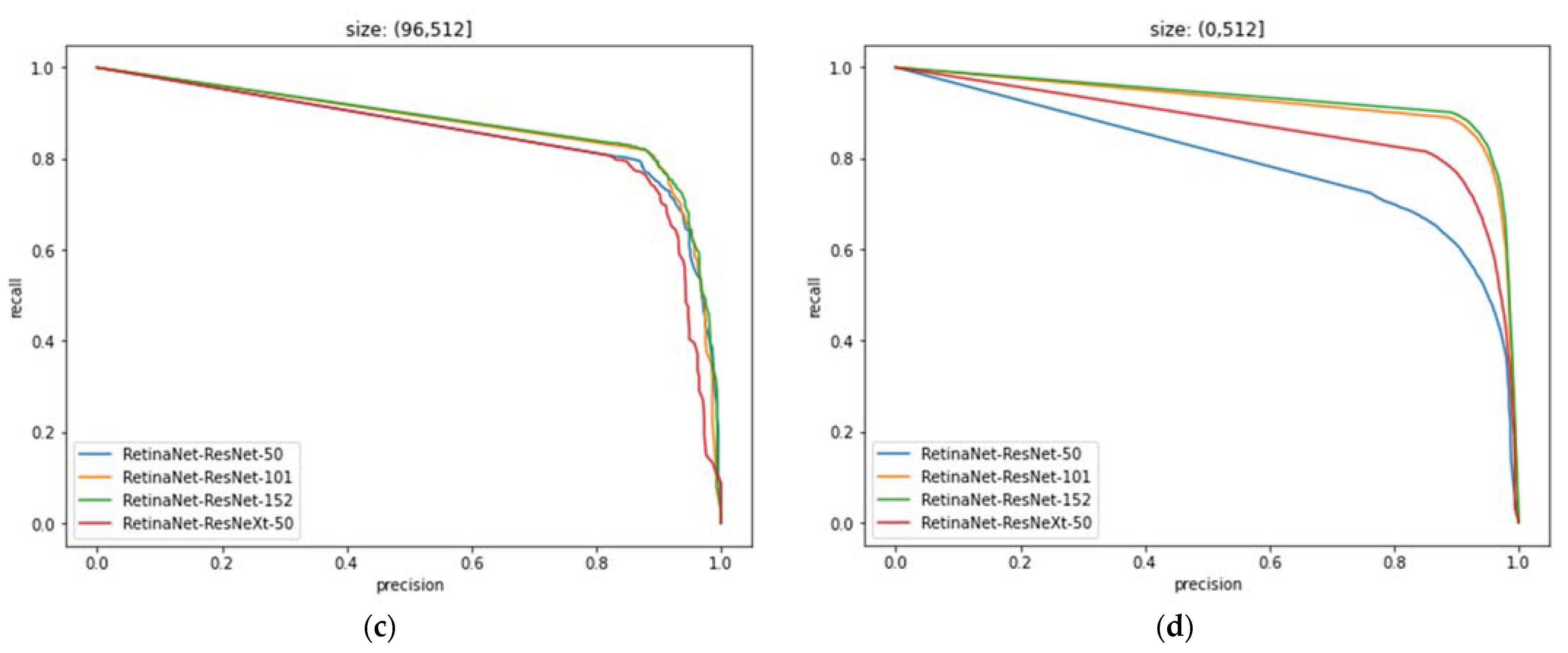
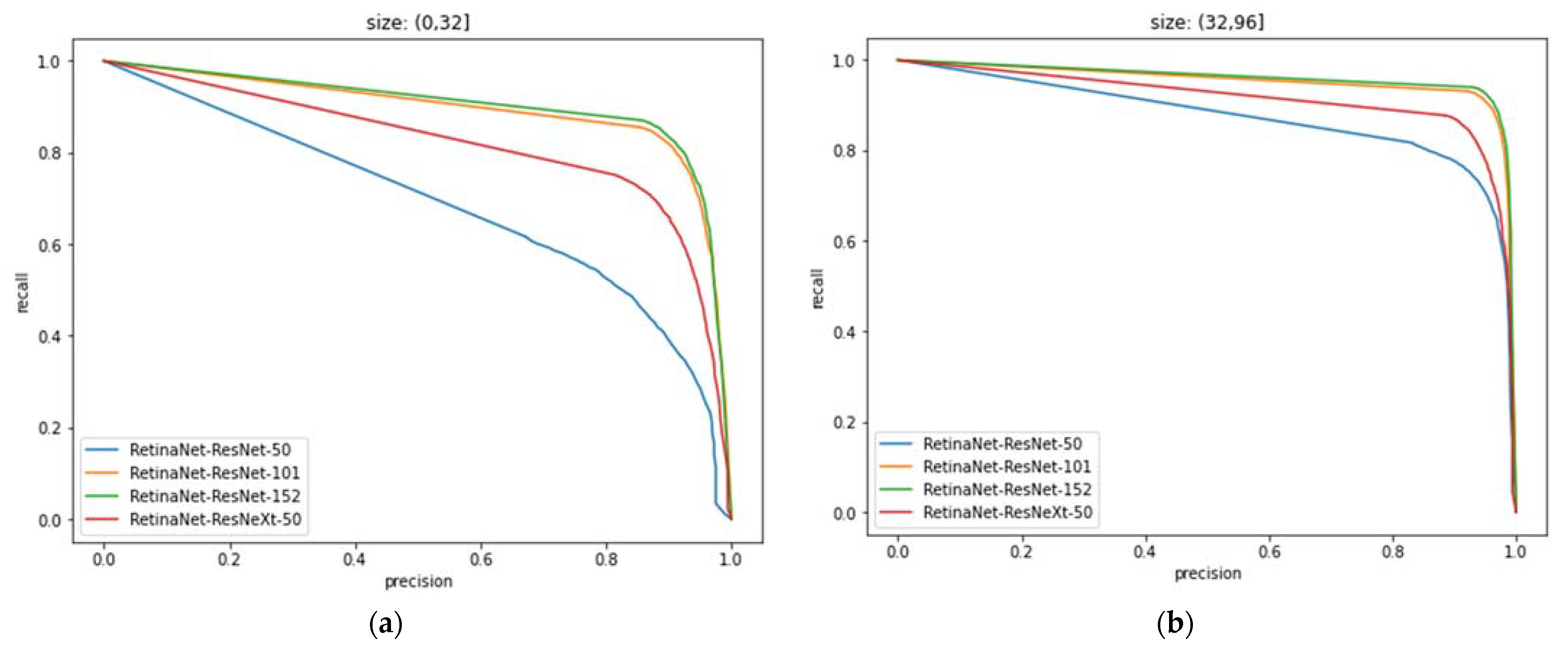
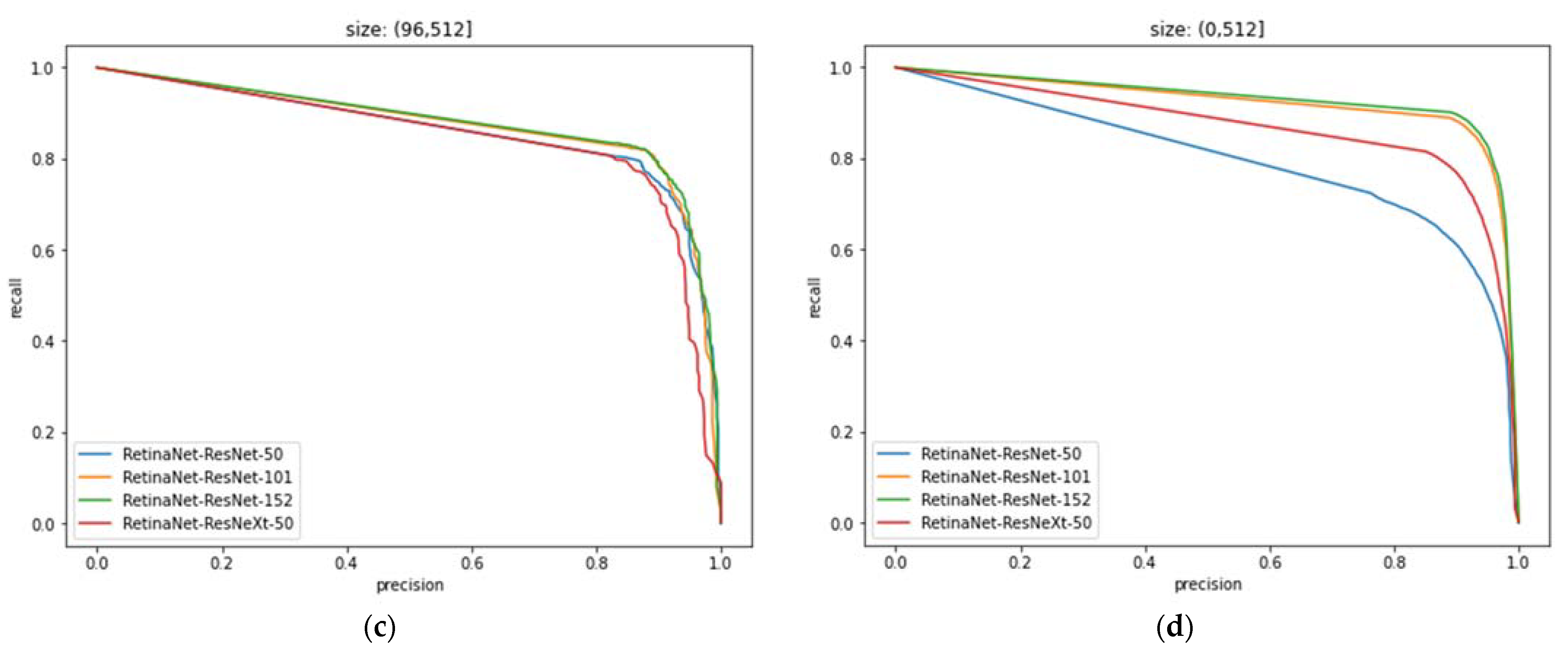
4.6. PR Curves and Analysis of Different Models under the Effect of Anchor
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Muhammad, K.; Ullah, A.; Lloret, J.; Ser, J.D.; de Albuquerque, V.H.C. Deep Learning for Safe Autonomous Driving: Current Challenges and Future Directions. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4316–4336. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-Sign Detection and Classification in the Wild. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2110–2118. [Google Scholar]
- Wan, H.; Gao, L.; Su, M.; You, Q.; Qu, H.; Sun, Q. A Novel Neural Network Model for Traffic Sign Detection and Recognition under Extreme Conditions. J. Sens. 2021, 2021, 9984787. [Google Scholar] [CrossRef]
- Song, G. An Improved Traffic Sign Recognition Algorithm Based on Deep Learning. In Proceedings of the 2021 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Xi’an, China, 27–28 March 2021; pp. 1–4. [Google Scholar]
- Lodhi, A.; Singhal, S.; Massoudi, M. Car Traffic Sign Recognizer Using Convolutional Neural Network CNN. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 577–582. [Google Scholar]
- Liu, Z.; Qi, M.; Shen, C.; Fang, Y.; Zhao, X. Cascade Saccade Machine Learning Network with Hierarchical Classes for Traffic Sign Detection. Sustain. Cities Soc. 2021, 67, 102700. [Google Scholar] [CrossRef]
- Tabernik, D.; Skočaj, D. Deep Learning for Large-Scale Traffic-Sign Detection and Recognition. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1427–1440. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Wang, Z.; Song, R.; Yan, C.; Qi, Y. Detection-by-Tracking of Traffic Signs in Videos. Appl. Intell. 2021. [Google Scholar] [CrossRef]
- Shen, L.; You, L.; Peng, B.; Zhang, C. Group Multi-Scale Attention Pyramid Network for Traffic Sign Detection. Neurocomputing 2021, 452, 1–14. [Google Scholar] [CrossRef]
- Chen, E.; Rohit, M.; Fasfous, N.; Frickenstein, A.; Mzid, A.; Nagaraja, N.; Zeisler, J.; Stechele, W. Investigating Binary Neural Networks for Traffic Sign Detection and Recognition. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1400–1405. [Google Scholar]
- Zhou, K.; Zhan, Y.; Fu, D. Learning Region-Based Attention Network for Traffic Sign Recognition. Sensors 2021, 21, 686. [Google Scholar] [CrossRef]
- Gámez Serna, C.; Ruichek, Y. Traffic Signs Detection and Classification for European Urban Environments. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4388–4399. [Google Scholar] [CrossRef]
- Liu, Y.; Peng, J.; Xue, J.-H.; Chen, Y.; Fu, Z.-H. TSingNet: Scale-Aware and Context-Rich Feature Learning for Traffic Sign Detection and Recognition in the Wild. Neurocomputing 2021, 447, 10–22. [Google Scholar] [CrossRef]
- Bayoudh, K.; Hamdaoui, F.; Mtibaa, A. Transfer Learning Based Hybrid 2D-3D CNN for Traffic Sign Recognition and Semantic Road Detection Applied in Advanced Driver Assistance Systems. Appl. Intell. 2021, 51, 124–142. [Google Scholar] [CrossRef]
- Li, H.J.; Wang, S.F.; He, J.J.; Zhou, Y.; Li, W.; Dou, Y.X. Pseudo Sample Regularization Faster R-CNN for Traffic Sign Detection. J. Jilin Univ. (Eng. Technol. Ed.) 2021, 51, 1251. [Google Scholar] [CrossRef]
- Lopez-Montiel, M.; Rubio, Y.; Sánchez-Adame, M.; Orozco-Rosas, U. Evaluation of Algorithms for Traffic Sign Detection. In Proceedings of the Optics and Photonics for Information Processing XIII., International Society for Optics and Photonics, San Diego, California, USA, 13–14 August 2019; Volume 11136, p. 111360M. [Google Scholar]
- Dai, X.; Yuan, X.; Yue, G.; Zhang, L. Detection Method of Traffic Signs Based on Color Pair and MSER in the Complex Environment. Beijing Jiaotong Daxue Xuebao/J. Beijing Jiaotong Univ. 2018, 42, 107–115. [Google Scholar] [CrossRef]
- Wu, X.; Wei, Z.; Hu, Y.; Wang, L. Traffic Sign Detection Method Using Multi-Color Space Fusion. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 314–319. [Google Scholar]
- Jin, Y.; Fu, Y.; Wang, W.; Guo, J.; Ren, C.; Xiang, X. Multi-Feature Fusion and Enhancement Single Shot Detector for Traffic Sign Recognition. IEEE Access 2020, 8, 38931–38940. [Google Scholar] [CrossRef]
- Xu, J.; Zhao, T.; Feng, G.; Ou, S. Image Segmentation Algorithm Based on Context Fuzzy C-Means Clustering. Dianzi Yu Xinxi Xuebao/J. Electron. Inform. Technol. 2021, 43, 2079–2086. [Google Scholar] [CrossRef]
- Prakash, A.; Vigneshwaran, D.; Ayyalu, R.; Sree, S. Traffic Sign Recognition Using Deeplearning for Autonomous Driverless Vehicles. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 8–10 April 2021; pp. 1569–1572. [Google Scholar]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. The German Traffic Sign Recognition Benchmark: A Multi-Class Classification Competition. In Proceedings of the International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 1453–1460. [Google Scholar]
- Lv, H.; Dang, X.; Yang, D.; Zhu, Q. Research and Design of Traffic Recognition System Based on Hilens. In Proceedings of the Tenth International Symposium on Precision Mechanical Measurements, Qingdao, China, 15–17 October 2021; p. 26. [Google Scholar]
- Zhu, H.; Zhang, C. Real-Time Traffic Sign Detection Based on YOLOv2. In Proceedings of the 2018 International Conference on Image and Video Processing, and Artificial Intelligence, Shanghai, China, 15–17 August 2018; p. 53. [Google Scholar]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. Computer: Benchmarking Machine Learning Algorithms for Traffic Sign Recognition. Neural Netw. Off. J. Int. Neural Netw. Soc. 2012, 32, 323–332. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Xiao, Z.; Yan, Z. Traffic Sign Recognition Based on Convolutional Neural Network Model. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 155–158. [Google Scholar]
- Zhao, Q.; Shen, Y.; Zhang, Y. Video-Based Traffic Sign Detection and Recognition. In Proceedings of the 2019 International Conference on Image and Video Processing, and Artificial Intelligence, Shanghai, China, 23–25 August 2019; p. 129. [Google Scholar]
- Chen, J.; Jia, K.; Chen, W.; Lv, Z.; Zhang, R. A Real-Time and High-Precision Method for Small Traffic-Signs Recognition. Neural Comput. Appl. 2021, 1–13. [Google Scholar] [CrossRef]
- Zha, M.; Qian, W.; Yi, W.; Hua, J. A Lightweight YOLOv4-Based Forestry Pest Detection Method Using Coordinate Attention and Feature Fusion. Entropy 2021, 23, 1587. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Yang, L.; Luo, J.; Song, X.; Menglong, L.; Wen, P.; Xiong, Z. Robust Vehicle Speed Measurement Based on Feature Information Fusion for Vehicle Multi-Characteristic Detection. Entropy 2021, 23, 910. [Google Scholar] [CrossRef]
- Wu, Y.; He, K. Group Normalization. Int. J. Comput. Vis. 2020, 128, 742–755. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Wang, W.; Yang, Y. Development of Convolutional Neural Network and Its Application in Image Classification: A Survey. Opt. Eng. 2019, 58, 040901. [Google Scholar] [CrossRef] [Green Version]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Xie, T.; Kwon, Y.; Michael, K.; Changyu, L.; Fang, J. Ultralytics/Yolov5 V6.0—YOLOv5n ‘Nano’ Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support on GitHub. 2021. Available online: https://newreleases.io/project/github/ultralytics/yolov5/release/v6.0 (accessed on 1 December 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Size | Total |
|---|---|---|
| Train | 2048 × 2048 | 7196 |
| Test | 3071 |
| IOU | Size | Precision (%) | Recall (%) |
|---|---|---|---|
| 0.5 | (0, 32] | 83.39 | 73.88 |
| 0.5 | (32, 96] | 90.79 | 86.22 |
| 0.5 | (96, 512] | 90.29 | 71.90 |
| 0.5 | (0, 512] | 87.45 | 79.65 |
| Frameworks | Precision (%) | Recall (%) | F1-Score (%) | mAP (%) |
|---|---|---|---|---|
| Faster RCNN [2] | 74.32 | 55.08 | 63.26 | 74.02 |
| YOLOv5 [41] | 78.80 | 75.00 | 76.85 | 81.70 |
| RetinaNet [5] | 78.37 | 70.56 | 78.37 | 79.39 |
| RetinaNet-NeXt (Ours) | 87.45 | 79.65 | 83.37 | 86.71 |
| Backbone | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|
| ResNet50 | 78.37 | 70.56 | 79.39 |
| ResNet101 | 89.95 | 88.22 | 92.02 |
| ResNet152 | 90.54 | 89.29 | 92.80 |
| ResNeXt50 | 87.45 | 79.65 | 86.71 |
| Backbone | Precision (%) | Anchor | |||
|---|---|---|---|---|---|
| Recall (%) | (0, 32] | (32, 96] | (96, 512] | (0, 512] | |
| ResNet50 | Precision (%) | 68.73 | 85.85 | 88.94 | 78.37 |
| Recall (%) | 60.22 | 79.83 | 75.81 | 70.56 | |
| ResNet101 | Precision (%) | 86.32 | 93.37 | 90.49 | 89.95 |
| Recall (%) | 85.14 | 92.58 | 77.62 | 88.22 | |
| ResNet152 | Precision (%) | 86.85 | 94.09 | 90.58 | 90.54 |
| Recall (%) | 86.53 | 93.50 | 77.53 | 89.29 | |
| ResNeXt50 | Precision (%) | 83.39 | 90.79 | 90.29 | 87.45 |
| Recall (%) | 73.88 | 86.22 | 71.64 | 79.63 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Cai, T.; Tang, X.; Zhang, Y.; Wang, C. Visual Recognition of Traffic Signs in Natural Scenes Based on Improved RetinaNet. Entropy 2022, 24, 112. https://doi.org/10.3390/e24010112
Liu S, Cai T, Tang X, Zhang Y, Wang C. Visual Recognition of Traffic Signs in Natural Scenes Based on Improved RetinaNet. Entropy. 2022; 24(1):112. https://doi.org/10.3390/e24010112
Chicago/Turabian StyleLiu, Shangwang, Tongbo Cai, Xiufang Tang, Yangyang Zhang, and Changgeng Wang. 2022. "Visual Recognition of Traffic Signs in Natural Scenes Based on Improved RetinaNet" Entropy 24, no. 1: 112. https://doi.org/10.3390/e24010112
APA StyleLiu, S., Cai, T., Tang, X., Zhang, Y., & Wang, C. (2022). Visual Recognition of Traffic Signs in Natural Scenes Based on Improved RetinaNet. Entropy, 24(1), 112. https://doi.org/10.3390/e24010112