
Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection


Abstract
:1. Introduction
2. Related Works
3. Problem Statement
- directed multigraph , where is a set of vertexes, and is a set of edges,
- available units function , which gives the set of available units of edge , which do not have to be contiguous,
- s and t are the source and target vertexes of the demand,
- a cost function , which returns the cost of path p,
- a monotonically nondecreasing cost function , which returns the (real or integer) cost of path pair l,
- a decision function of monotonically increasing requirements, which returns true if path p can support the demand, otherwise false,
- the set of all units on every edge.
- a cheapest (i.e., of the lowest cost) pair of edge-disjoint paths (a path is a sequence of edges), the cheaper being the working path, and the more expensive the protecting path,
- continuous and contiguous units for each of the two paths separately: the working path and the protecting path (i.e., each path can have different spectrum).
4. Proposed Algorithm
4.1. Preliminaries
4.1.1. Search Graph
4.1.2. Path Trait
4.1.3. Solution Label
4.1.4. Search Tree
4.1.5. Priority Queue
4.2. Algorithm
| Algorithm 1 Dedicated Path Protection Algorithm |
| In: graph G, source vertex s, target vertex t |
| Out: a cheapest pair of paths, and their CUs |
| Here, we concentrate on permanent solutions . |
|
| Algorithm 2 relax |
| In: edge , const vertex , const trait , other trait , |
| previous search-tree node |
| Here, we concentrate on tentative solutions . |
|
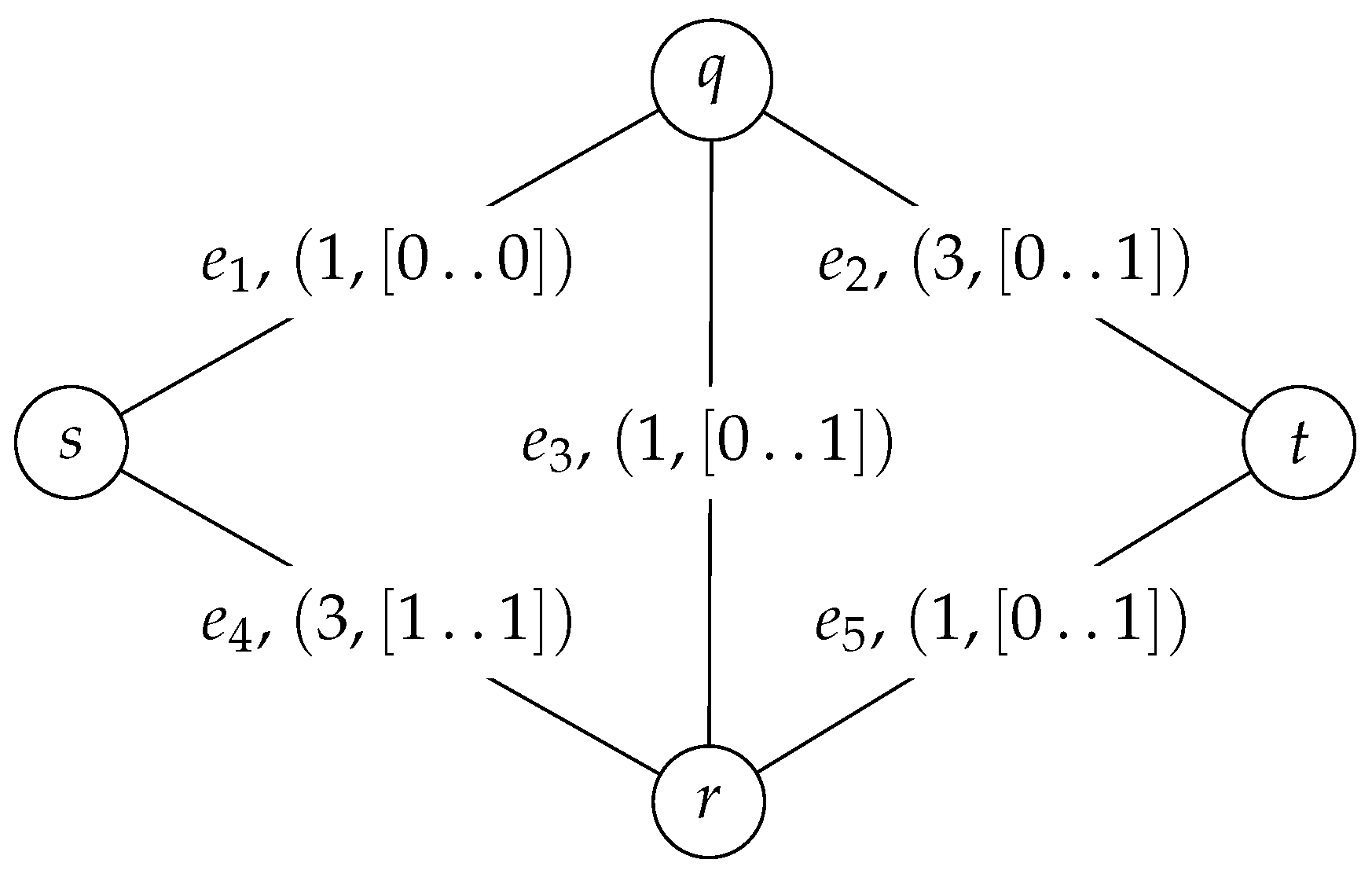
4.3. Example
4.4. Worst-Case Analysis
5. Simulations
5.1. Simulation Setting
5.1.1. Network Model
5.1.2. Traffic Model
5.1.3. Signal Modulation Model
5.1.4. The Cost and Decision Functions
5.2. Runs and Populations
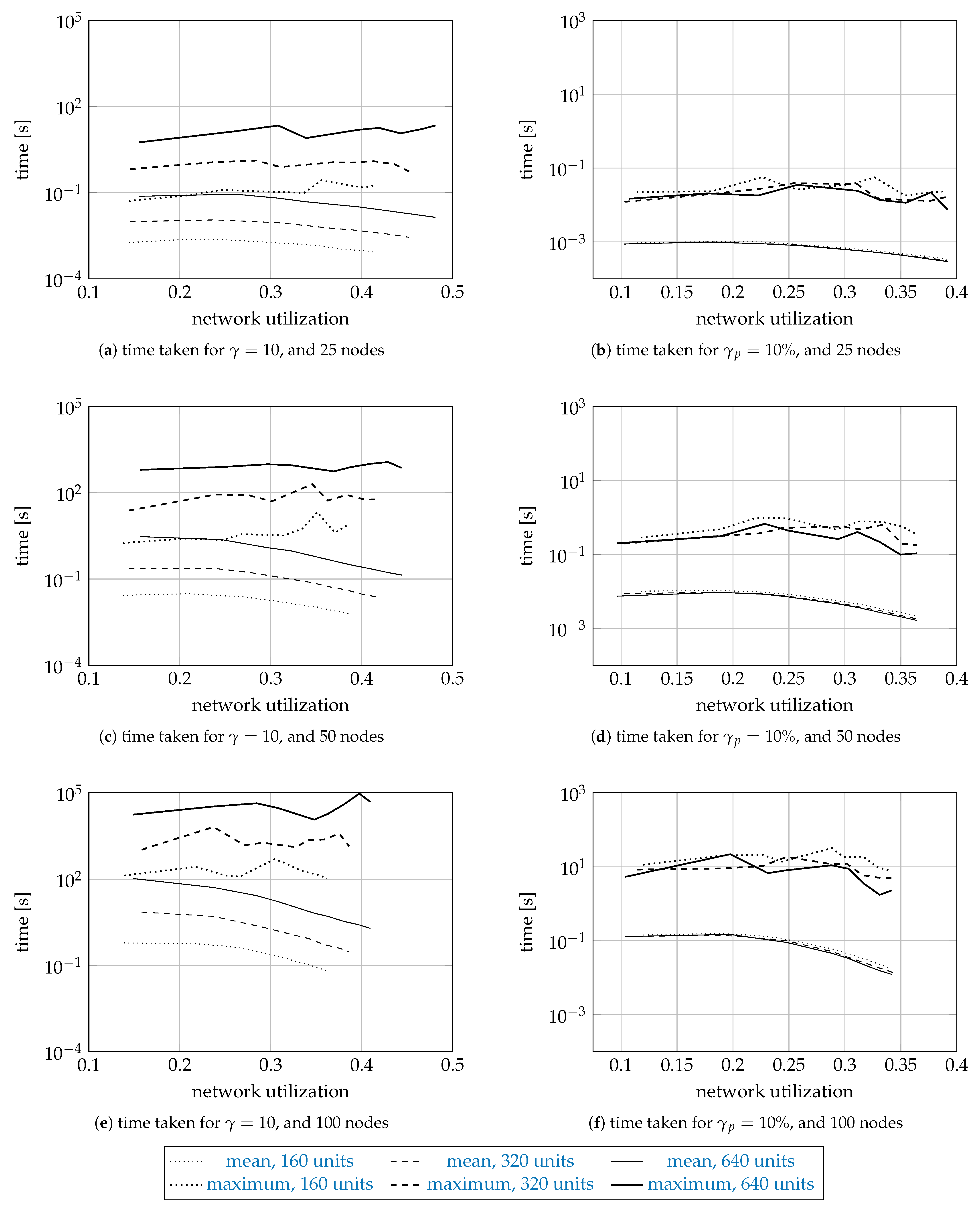
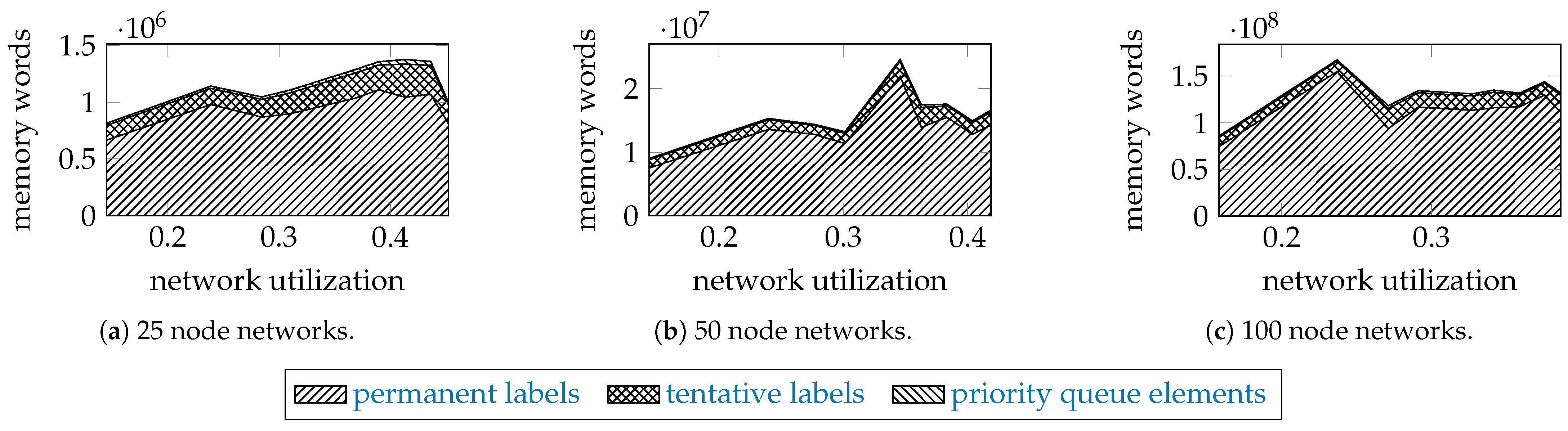
5.3. Simulation Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Shen, G.; Guo, H.; Bose, S.K. Survivable elastic optical networks: Survey and perspective. Photonic Netw. Commun. 2016, 31, 71–87. [Google Scholar] [CrossRef]
- Goścień, R.; Walkowiak, K.; Klinkowski, M.; Rak, J. Protection in elastic optical networks. IEEE Netw. 2015, 29, 88–96. [Google Scholar] [CrossRef]
- Simmons, J.M. Optical Network Design and Planning; Optical Networks; Springer: New York, NY, USA, 2014. [Google Scholar]
- Gerstel, O.; Jinno, M.; Lord, A.; Yoo, S. Elastic optical networking: A new dawn for the optical layer? IEEE Commun. Mag. 2012, 50, s12–s20. [Google Scholar] [CrossRef]
- Szcześniak, I. The Implementation of the Efficient and Optimal Algorithm for the Dynamic Dedicated Path Protection. 2019. Available online: http://www.irkos.org/ddpp (accessed on 26 August 2021).
- Szcześniak, I.; Jajszczyk, A.; Woźna-Szcześniak, B. Generic Dijkstra for optical networks. IEEE/OSA J. Opt. Commun. Netw. 2019, 11, 568–577. [Google Scholar] [CrossRef] [Green Version]
- Andersen, R.; Chung, F.; Sen, A.; Xue, G. On disjoint path pairs with wavelength continuity constraint in WDM networks. In Proceedings of the IEEE INFOCOM 2004, Hong Kong, China, 7–11 March 2004; pp. 524–535. [Google Scholar]
- Kishi, Y.; Kitsuwan, N.; Ito, H.; Chatterjee, B.C.; Oki, E. Modulation-Adaptive Link-Disjoint Path Selection Model for 1 + 1 Protected Elastic Optical Networks. IEEE Access 2019, 7, 25422–25437. [Google Scholar] [CrossRef]
- Christodoulopoulos, K.; Kokkinos, P.; Varvarigos, E.M. Indirect and direct multicost algorithms for online impairment-aware RWA. Trans. Netw. 2011, 19, 1759–1772. [Google Scholar] [CrossRef]
- Wang, X.; Kuang, K.; Wang, S.; Xu, S.; Liu, H.; Liu, G.N. Dynamic routing and spectrum allocation in elastic optical networks with mixed line rates. J. Opt. Commun. Netw. 2014, 6, 1115–1127. [Google Scholar] [CrossRef]
- Yang, L.; Nan, H.; Xiaoping, Z.; Hanyi, Z.; Bingkun, Z. Polynomial-time adaptive routing algorithm based on spectrum scan in dynamic flexible optical networks. China Commun. 2013, 10, 49–58. [Google Scholar] [CrossRef]
- Liu, Y.; Hua, N.; Wan, X.; Zheng, X.; Liu, Z. A spectrum-scan routing scheme in flexible optical networks. In Proceedings of the 2011 Asia Communications and Photonics Conference and Exhibition, Shanghai, China, 13–16 November 2011; pp. 1–6. [Google Scholar]
- Shen, G.; Bose, S.; Cheng, T.; Lu, C.; Chai, T. Efficient heuristic algorithms for light-path routing and wavelength assignment in WDM networks under dynamically varying loads. Comput. Commun. 2001, 24, 364–373. [Google Scholar] [CrossRef]
- Wang, C.; Shen, G.; Bose, S.K. Distance adaptive dynamic routing and spectrum allocation in elastic optical networks with shared backup path protection. J. Light. Technol. 2015, 33, 2955–2964. [Google Scholar] [CrossRef]
- Chen, C.; Banerjee, S. A new model for optimal routing in all-optical networks with scalable number of wavelength converters. In Proceedings of the GLOBECOM ’95, Singapore, 14–16 November 1995; Volume 2, pp. 993–997. [Google Scholar]
- Hsu, C.F.; Chang, Y.C.; Sie, S.C. Graph-model-based dynamic routing and spectrum assignment in elastic optical networks. J. Opt. Commun. Netw. 2016, 8, 507–520. [Google Scholar] [CrossRef]
- Ehrgott, M.; Gandibleux, X. A survey and annotated bibliography of multiobjective combinatorial optimization. OR Spektrum 2000, 22, 425–460. [Google Scholar] [CrossRef]
- Varvarigos, E.M.; Sourlas, V.; Christodoulopoulos, K. Routing and scheduling connections in networks that support advance reservations. Comput. Netw. 2008, 52, 2988–3006. [Google Scholar] [CrossRef] [Green Version]
- Mieghem, P.V.; Kuipers, F.A. Concepts of exact QoS routing algorithms. IEEE/ACM Trans. Netw. 2004, 12, 851–864. [Google Scholar]
- Wang, Z.; Crowcroft, J. Quality-of-service routing for supporting multimedia applications. IEEE J. Sel. Areas Commun. 1996, 14, 1228–1234. [Google Scholar] [CrossRef] [Green Version]
- Hansen, P. Bicriterion path problems. In Multiple Criteria Decision Making Theory and Application; Lecture Notes in Economics and Mathematical Systems; Springer: Berlin/Heidelberg, Germany, 1980; Volume 177, pp. 109–127. [Google Scholar]
- Martins, E.Q.V. On a multicriteria shortest path problem. Eur. J. Oper. Res. 1984, 16, 236–245. [Google Scholar] [CrossRef]
- Tarapata, Z. Selected multicriteria shortest path problems: An analysis of complexity, models and adaptation of standard algorithms. Int. J. Appl. Math. Comput. Sci. 2007, 17, 269–287. [Google Scholar] [CrossRef] [Green Version]
- Suurballe, J.W. Disjoint paths in a network. Networks 1974, 4, 125–145. [Google Scholar] [CrossRef]
- Bhandari, R. Survivable Networks: Algorithms for Diverse Routing; Kluwer Academic Publishers: Boston, MA, USA, 1999. [Google Scholar]
- Ahuja, R.K.; Magnanti, T.L.; Orlin, J.B. Network Flows: Theory, Algorithms, and Applications; Prentice Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Szcześniak, I.; Woźna-Szcześniak, B. Adapted and constrained Dijkstra for elastic optical networks. In Proceedings of the 2016 International Conference on Optical Network Design and Modeling (ONDM), Cartagena, Spain, 9–12 May 2016; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Cetinkaya, E.; Alenazi, M.; Cheng, Y.; Peck, A.; Sterbenz, J. On the fitness of geographic graph generators for modelling physical level topologies. In Proceedings of the 2013 5th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Almaty, Kazakhstan, 10–13 September 2013; pp. 38–45. [Google Scholar] [CrossRef]
- Wan, X.; Hua, N.; Zheng, X. Dynamic routing and spectrum assignment in spectrum-flexible transparent optical networks. J. Opt. Commun. Netw. 2012, 4, 603–613. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Number | Solution Cost | Search-Tree Node Name | Search-Graph Vertex | Solution Label | Edge | Action |
|---|---|---|---|---|---|---|
| 0 | 0 | push into queue | ||||
| 1 | 0 | make permanent | ||||
| 2 | 1 | push into queue | ||||
| 3 | 3 | push into queue | ||||
| 4 | 1 | drop (worse or equal) | ||||
| 5 | 3 | drop (worse or equal) | ||||
| 6 | 1 | make permanent | ||||
| 7 | 2 | drop (edge reuse) | ||||
| 8 | 4 | push into queue | ||||
| 9 | 2 | drop (worse or equal) | ||||
| 10 | 4 | push into queue | ||||
| 11 | 2 | push into queue | ||||
| 12 | 2 | make permanent | ||||
| 13 | 3 | drop (edge reuse) | ||||
| 14 | 5 | push into queue | ||||
| 15 | 3 | drop (worse or equal) | ||||
| 16 | 3 | push into queue | ||||
| 17 | 4 | discard from queue | ||||
| 18 | 3 | make permanent | ||||
| 19 | 4 | drop (edge reuse) | ||||
| 20 | 6 | push into queue | ||||
| 21 | 3 | make permanent | ||||
| 22 | 4 | drop (worse or equal) | ||||
| 23 | 6 | drop (edge reuse) | ||||
| 24 | 4 | push into queue | ||||
| 25 | 6 | drop (worse or equal) | ||||
| 26 | 4 | push into queue | ||||
| 27 | 4 | make permanent | ||||
| 28 | 5 | push into queue | ||||
| 29 | 7 | drop (edge reuse) | ||||
| 30 | 4 | make permanent | ||||
| 31 | 5 | drop (worse or equal) | ||||
| 32 | 7 | drop (worse or equal) | ||||
| 33 | 5 | drop (worse or equal) | ||||
| 34 | 5 | push into queue | ||||
| 35 | 7 | drop (worse or equal) | ||||
| 36 | 5 | drop (worse or equal) | ||||
| 37 | 4 | make permanent | ||||
| 38 | 5 | drop (worse or equal) | ||||
| 39 | 7 | drop (edge reuse) | ||||
| 40 | 7 | drop (worse or equal) | ||||
| 41 | 5 | drop (worse or equal) | ||||
| 42 | 5 | make permanent | ||||
| 43 | 6 | drop (worse or equal) | ||||
| 44 | 8 | push into queue | ||||
| 45 | 6 | push into queue | ||||
| 46 | 5 | make permanent | ||||
| 47 | 6 | drop (worse or equal) | ||||
| 48 | 8 | push into queue | ||||
| 49 | 6 | drop (edge reuse) | ||||
| 50 | 8 | drop (worse or equal) | ||||
| 51 | 6 | drop (worse or equal) | ||||
| 52 | 5 | make permanent | ||||
| 53 | 6 | drop (worse or equal) | ||||
| 54 | 6 | drop (worse or equal) | ||||
| 55 | 6 | drop (edge reuse) | ||||
| 56 | 8 | drop (worse or equal) | ||||
| 57 | 6 | drop (worse or equal) | ||||
| 58 | 6 | make permanent | ||||
| 59 | 7 | drop (worse or equal) | ||||
| 60 | 7 | drop (edge reuse) | ||||
| 61 | 6 | make permanent | ||||
| 62 | 7 | drop (edge reuse) | ||||
| 63 | 9 | drop (worse or equal) | ||||
| 64 | 7 | drop (edge reuse) | ||||
| 65 | 8 | make permanent |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szcześniak, I.; Olszewski, I.; Woźna-Szcześniak, B. Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection. Entropy 2021, 23, 1116. https://doi.org/10.3390/e23091116
Szcześniak I, Olszewski I, Woźna-Szcześniak B. Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection. Entropy. 2021; 23(9):1116. https://doi.org/10.3390/e23091116
Chicago/Turabian StyleSzcześniak, Ireneusz, Ireneusz Olszewski, and Bożena Woźna-Szcześniak. 2021. "Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection" Entropy 23, no. 9: 1116. https://doi.org/10.3390/e23091116
APA StyleSzcześniak, I., Olszewski, I., & Woźna-Szcześniak, B. (2021). Towards an Efficient and Exact Algorithm for Dynamic Dedicated Path Protection. Entropy, 23(9), 1116. https://doi.org/10.3390/e23091116