
A Novel Method to Determine Basic Probability Assignment Based on Adaboost and Its Application in Classification


Abstract
:1. Introduction
2. Preliminaries
2.1. The Basic Theories of DSET
2.2. Adaboost
| Algorithm 1. The process of generating strong classifiers based on Adaboost |
| Input: The training set: , the number of classes in the dataset: , the number of weak classifiers: . Output: strong classifiers. 1: For i = 1: 2: For j = i + 1: 3: Attribute i and attribute j of the original training set are selected as the new training set . 4: The weight of the training sample is initialized to . 5: For t = 1: 6: Use the of , the optimal weak classifier is trained from (6). 7: Calculate the error rate of from (7). 8: Based on (9), calculate the weight of . 9: Based on (10), the weight distribution of the sample is updated. 10: End For 11: Based on (11), a strong classifier belonging to attribute i and j is obtained. 12: End For 13: End For 14: Return All the Strong classifiers . |
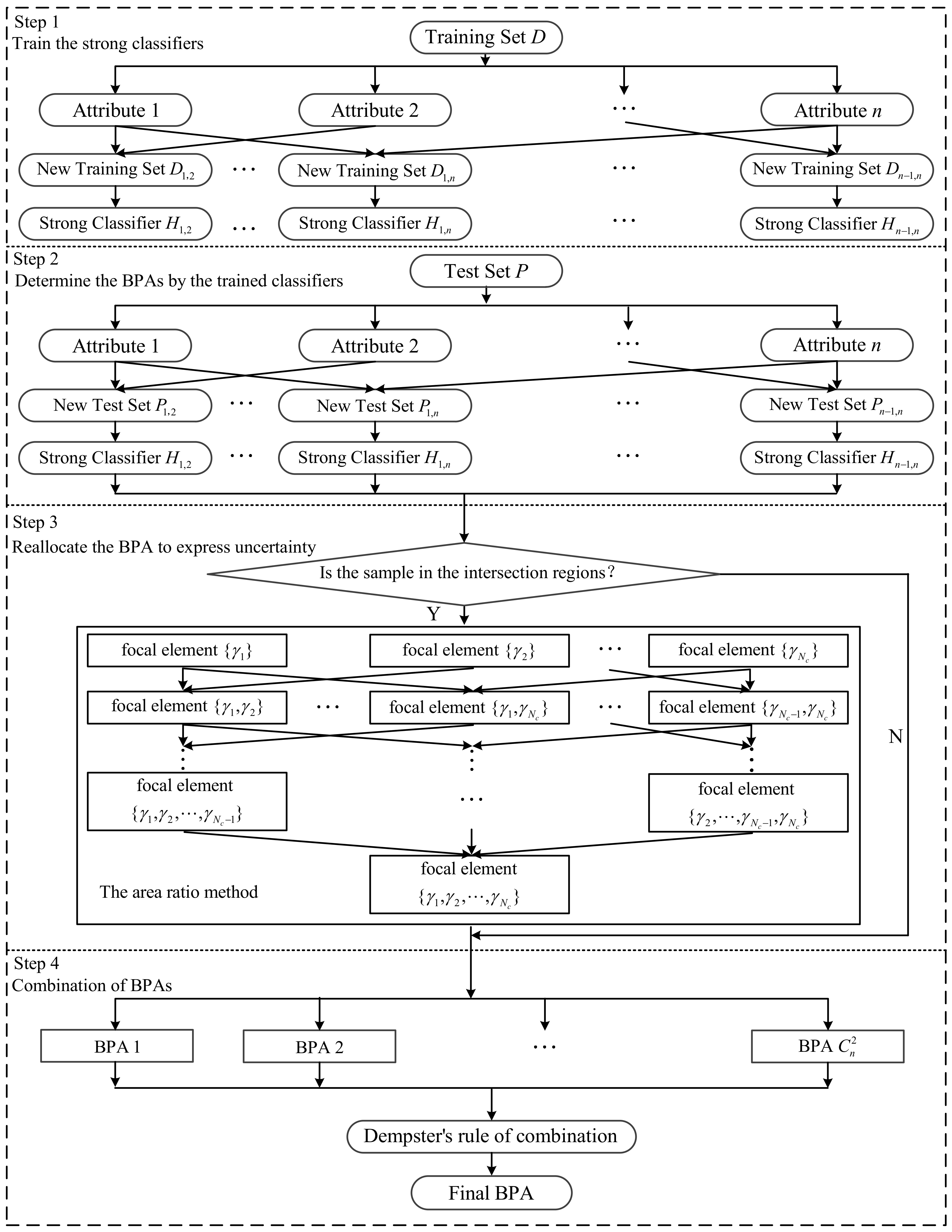
3. The Proposed Method for Determining BPA
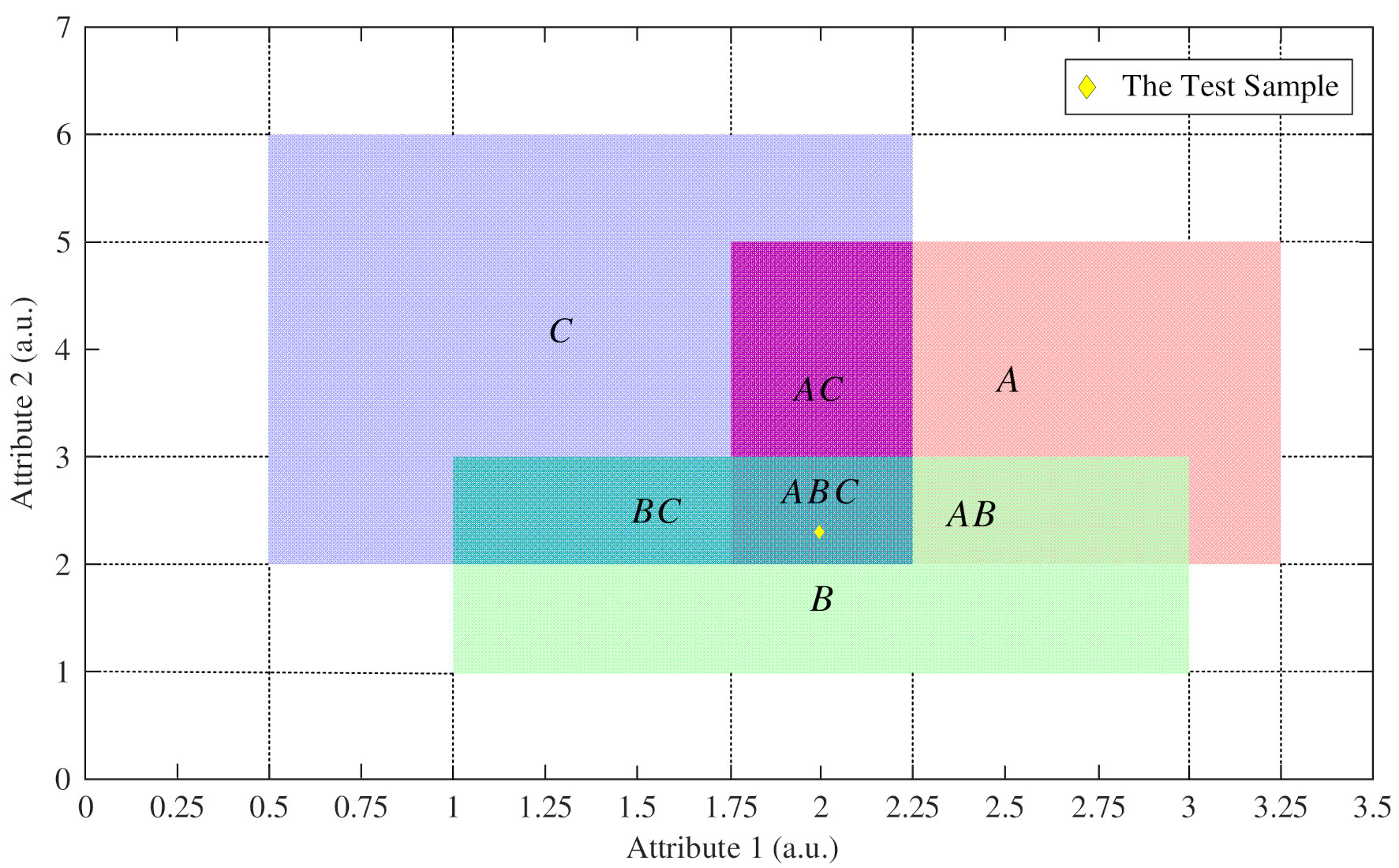
3.1. Determine the BPA of the Singleton Proposition
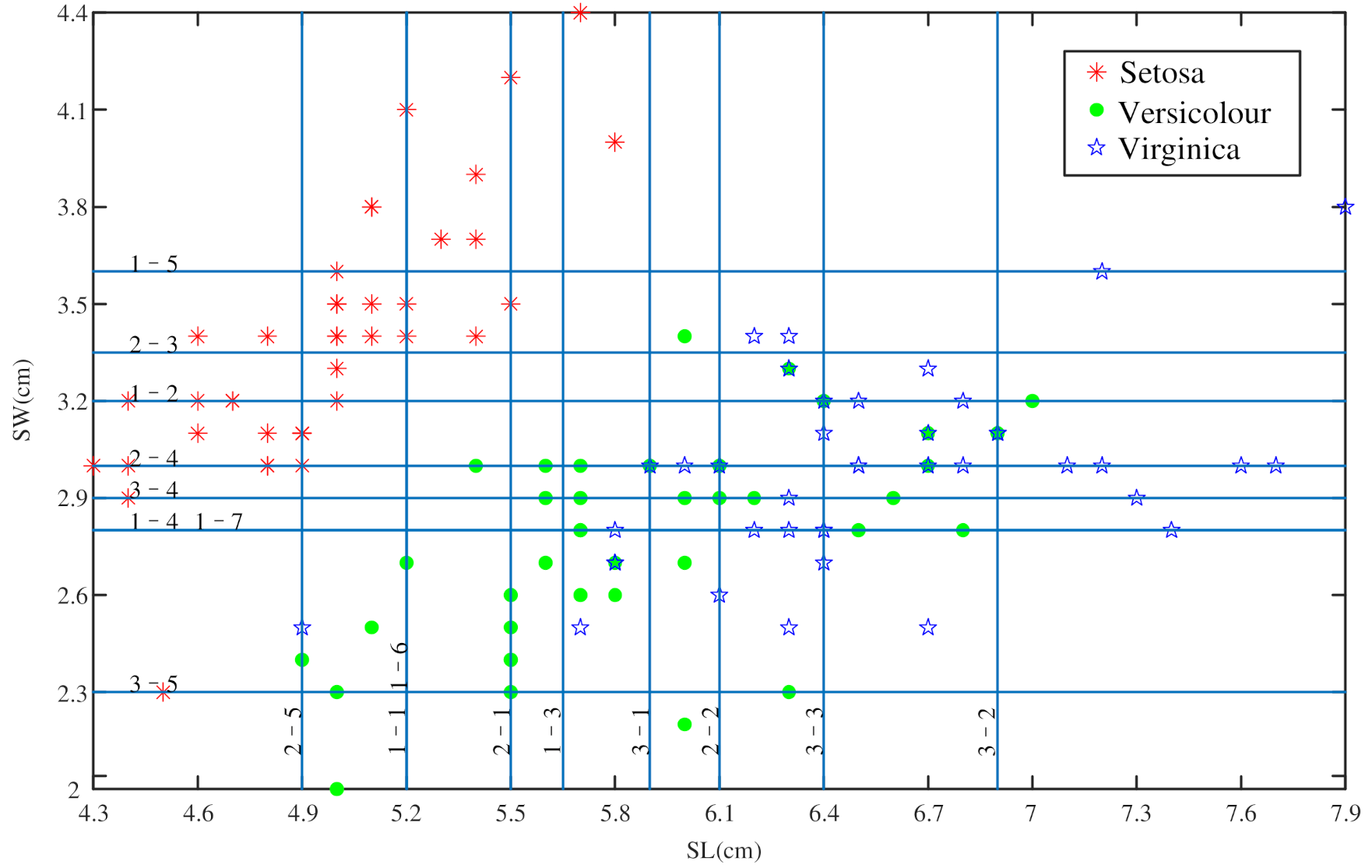
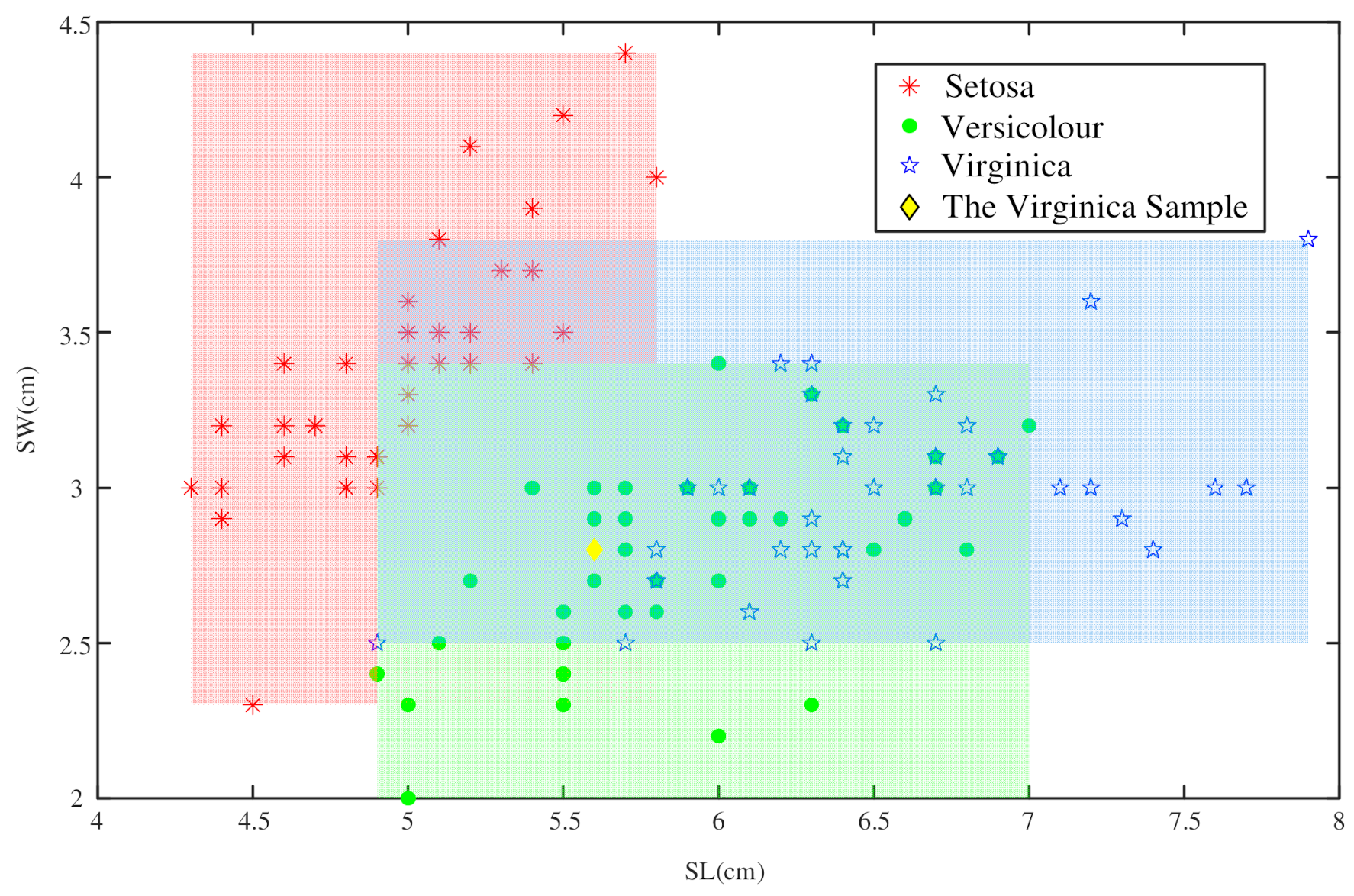
3.2. Determine the BPA of the Composite Proposition
| Algorithm 2. The method to determine BPA |
| Input: The training set: , the number of classes in the dataset: , the number of attributes in the dataset: , the number of iterations: . The test set and the number of the test samples . Output: BPAs of all samples in . 1: For i = 1: 2: For j = i + 1: 3: Set the new training set based on the attribute i and j of . 4: Put into Algorithm 1 for training the strong classifiers . 5: Set the new test set . 6: For = 1: 7: For = 1: 8: , where is the weak classifier of , is the weight of . 9: . 10: End For 11: . 12: If belongs to any intersection region 13: Use (17) to reallocate the mass. 14: End If 15: End For 16: End For 17: End For 18: Fuse all BPAs using Dempster’s rule of combination to get the BPA of , . 19: Return BPAs of all samples in . |
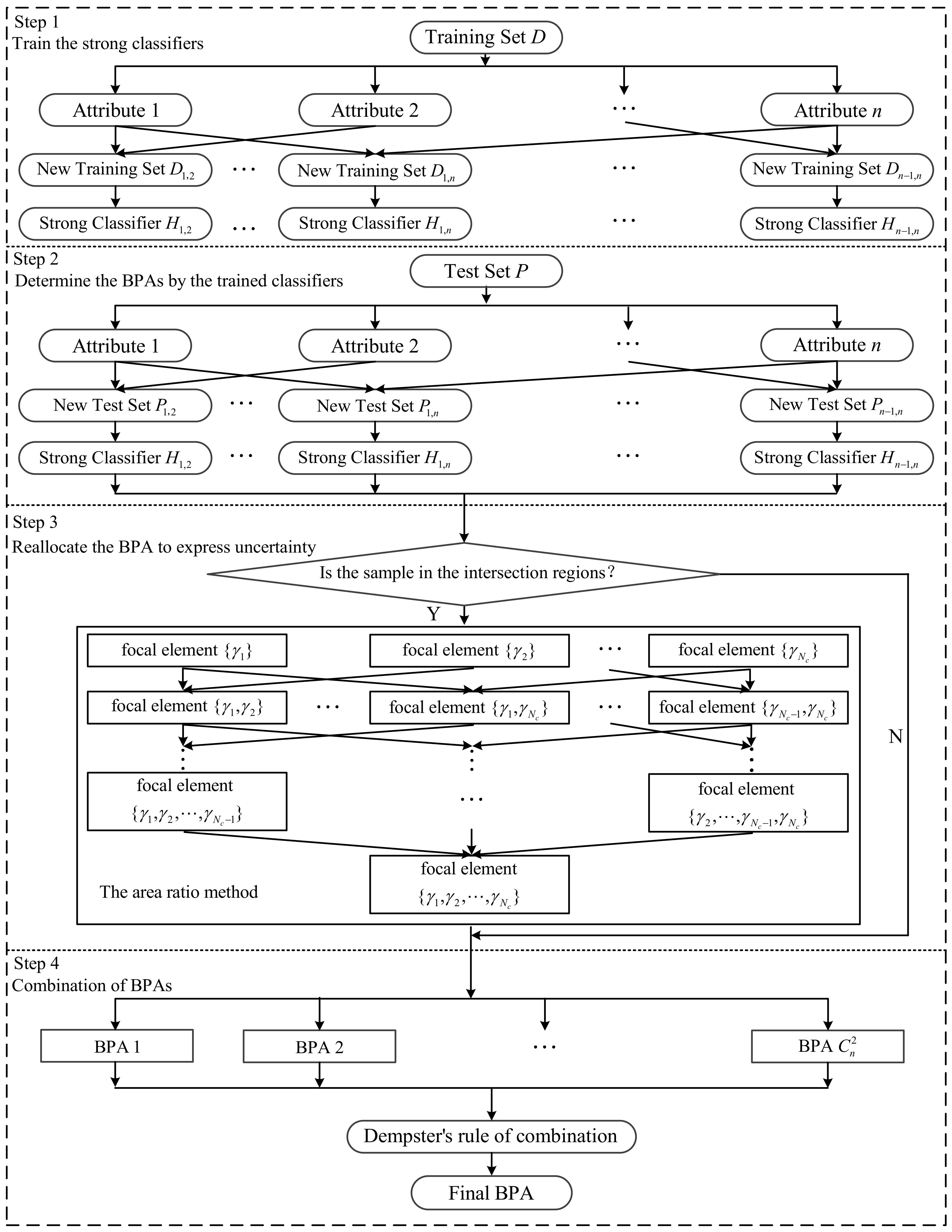
3.3. The Architecture of the Proposed Method
4. Experiments
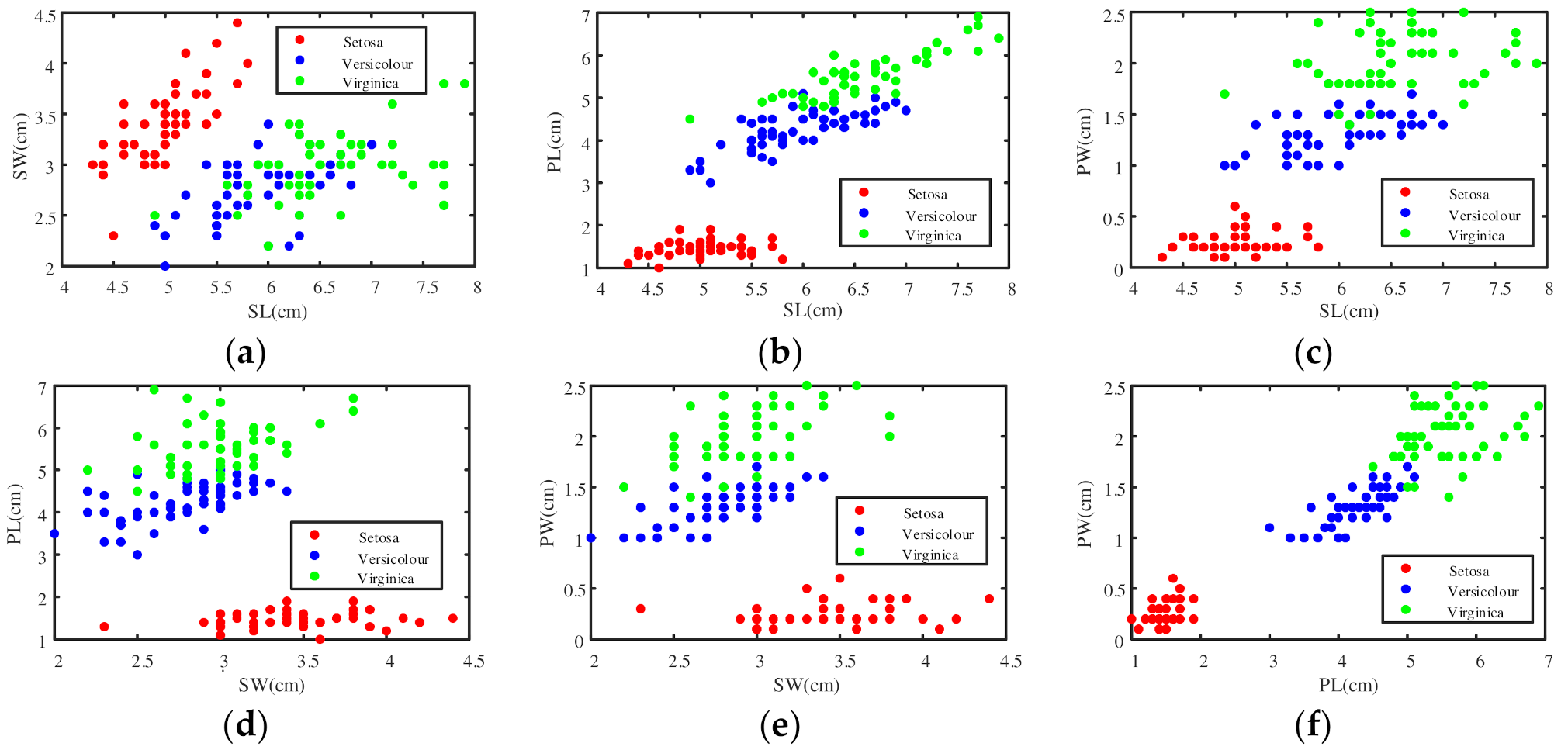
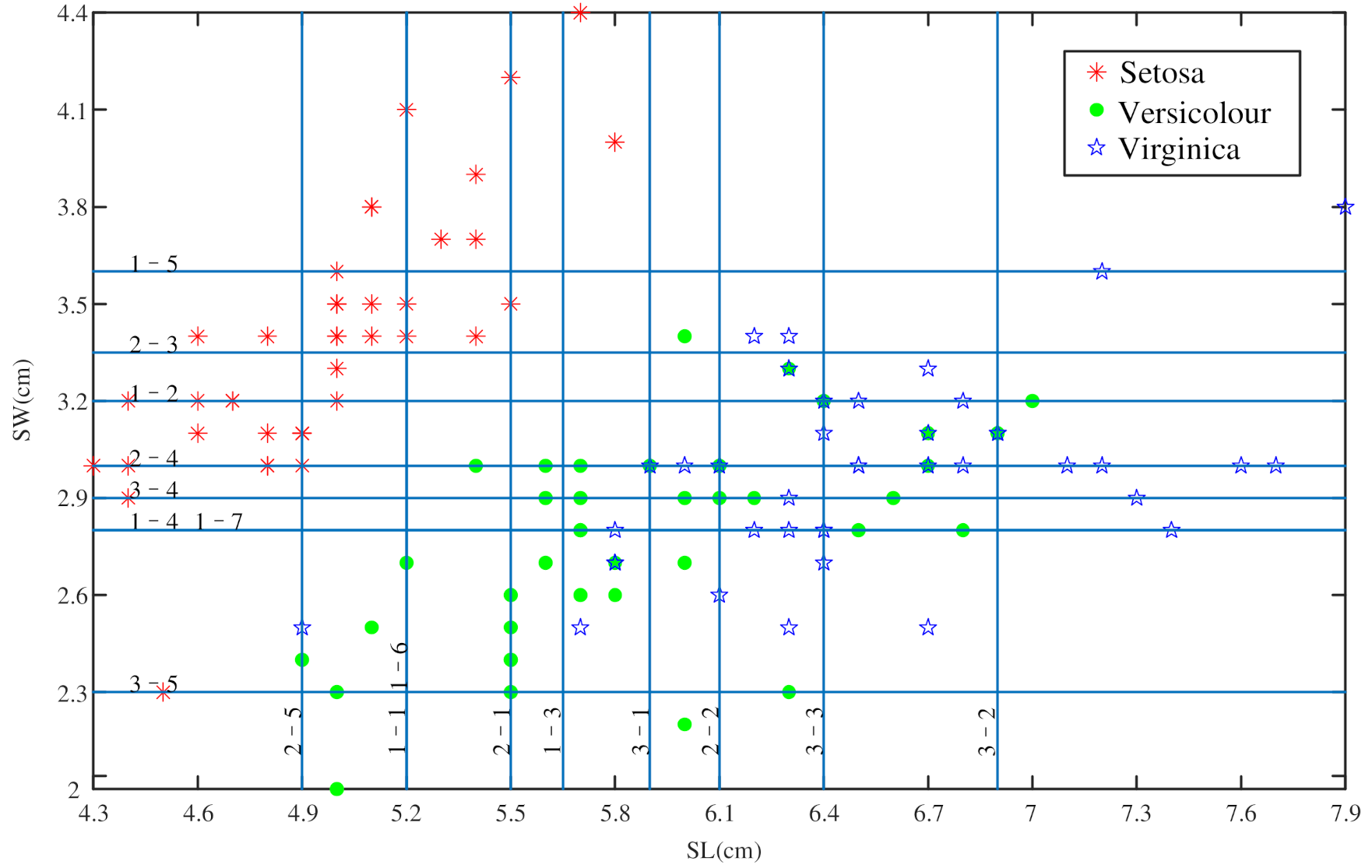
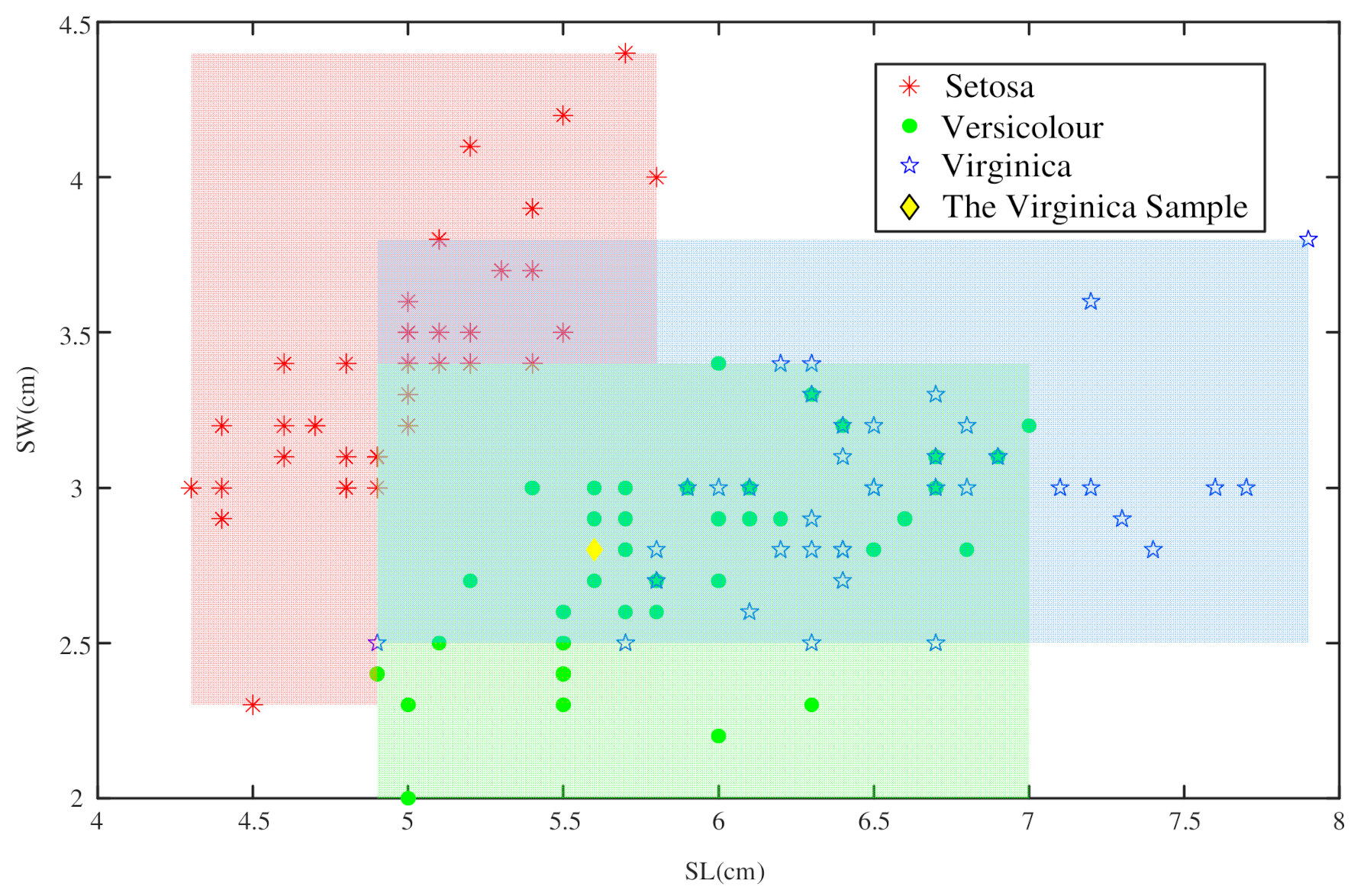
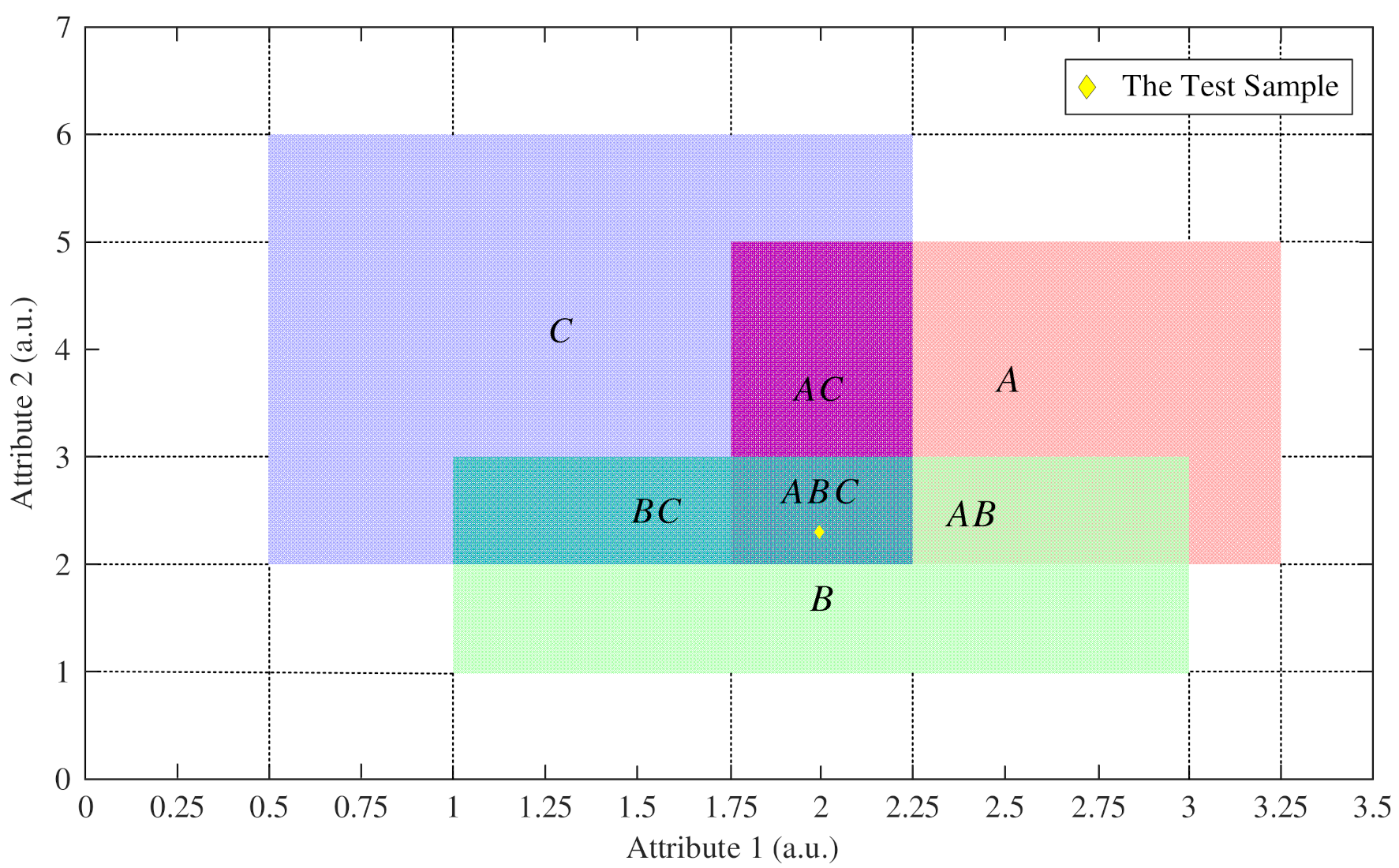
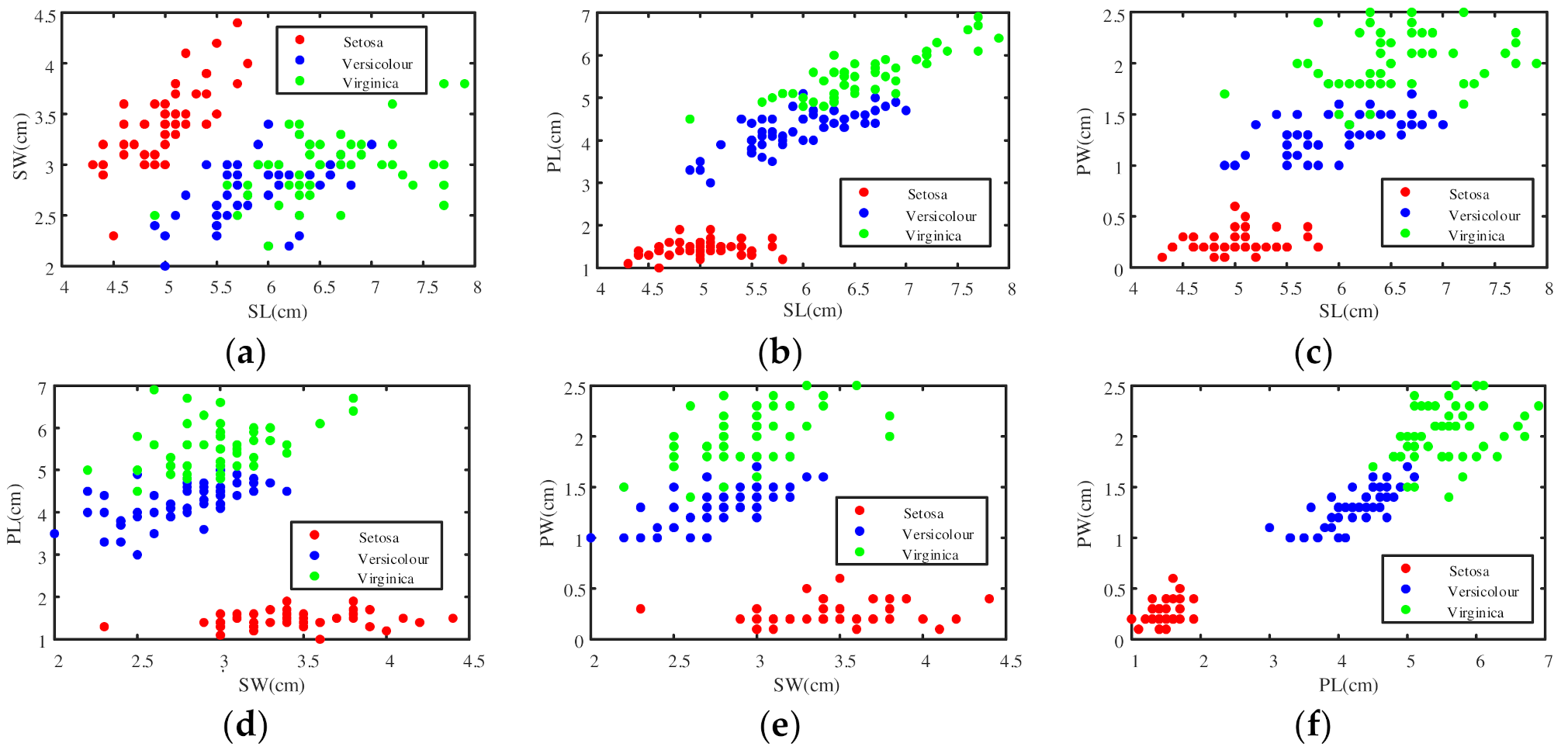
4.1. An Example of Iris Dataset to Determine BPA
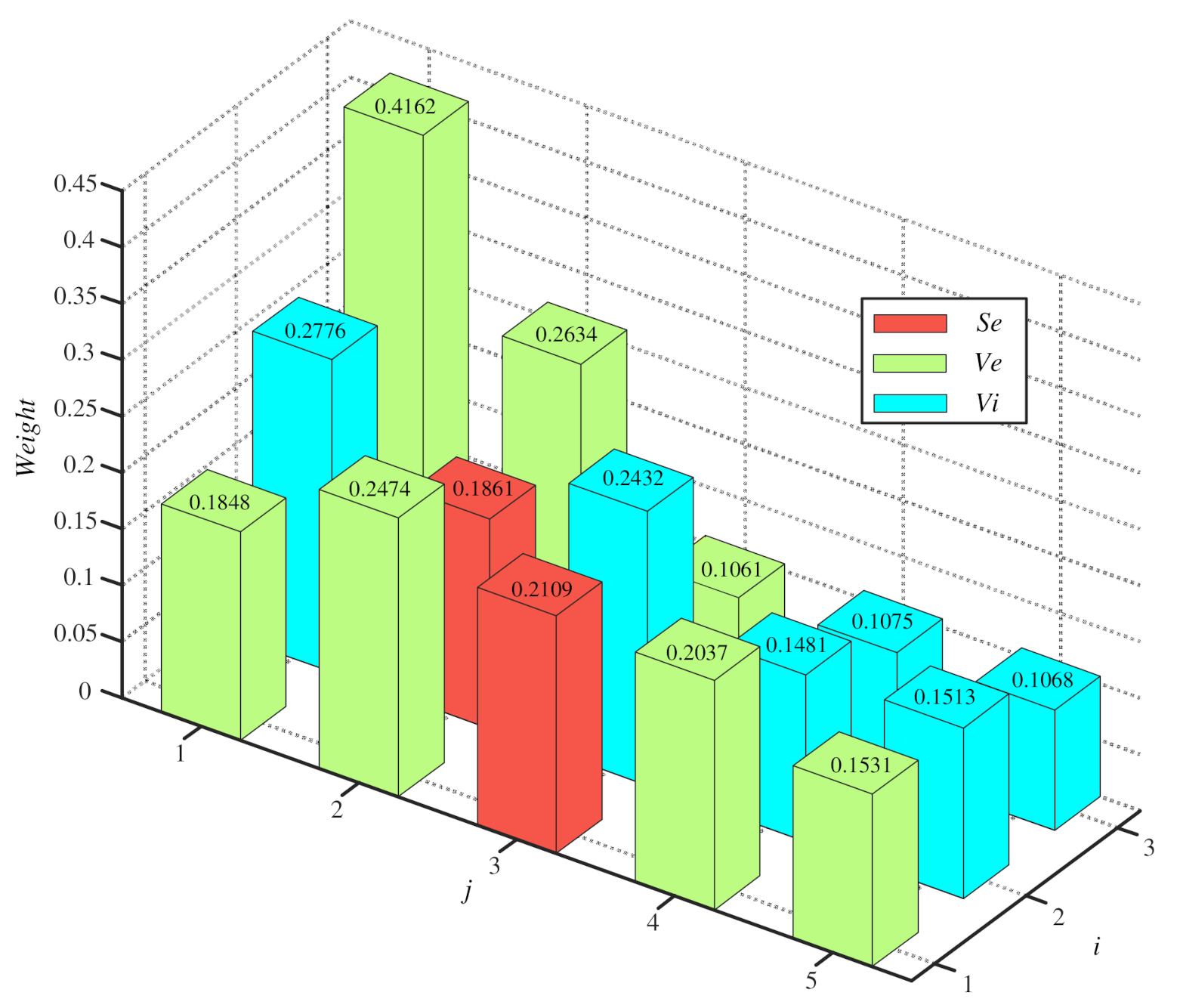
4.1.1. Determine the BPA of the Singleton Proposition
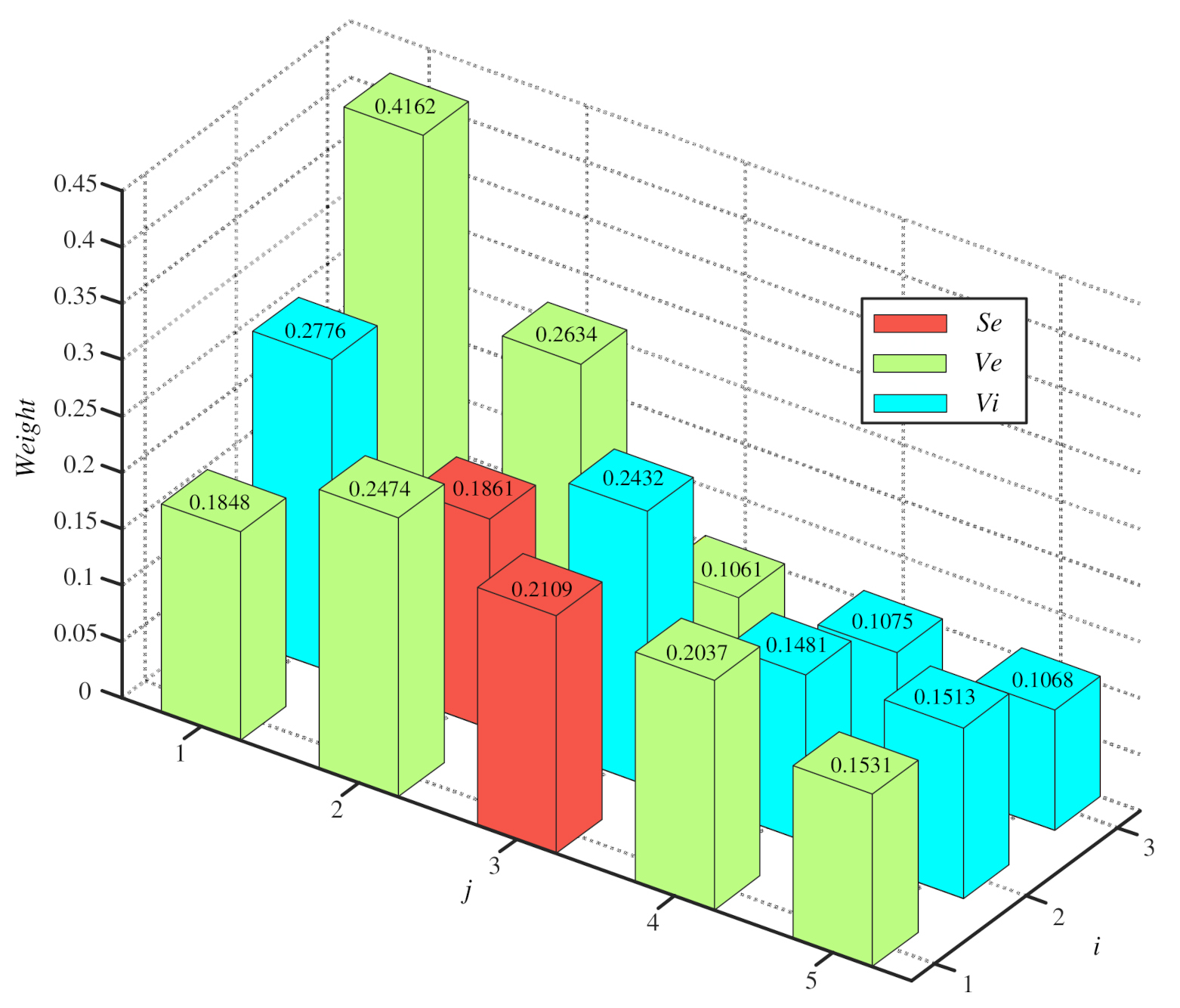
4.1.2. Determine the BPA of the Composite Proposition
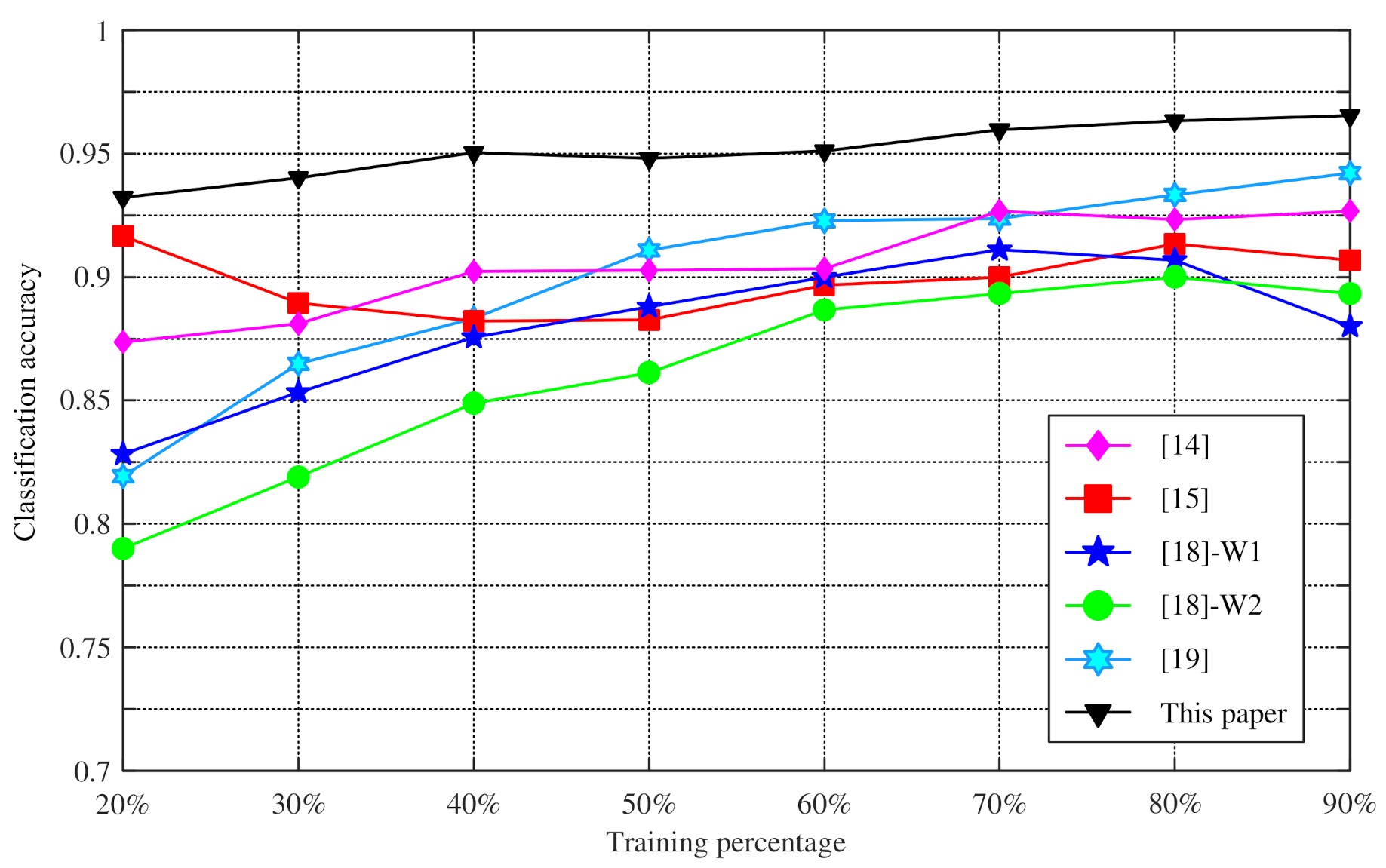
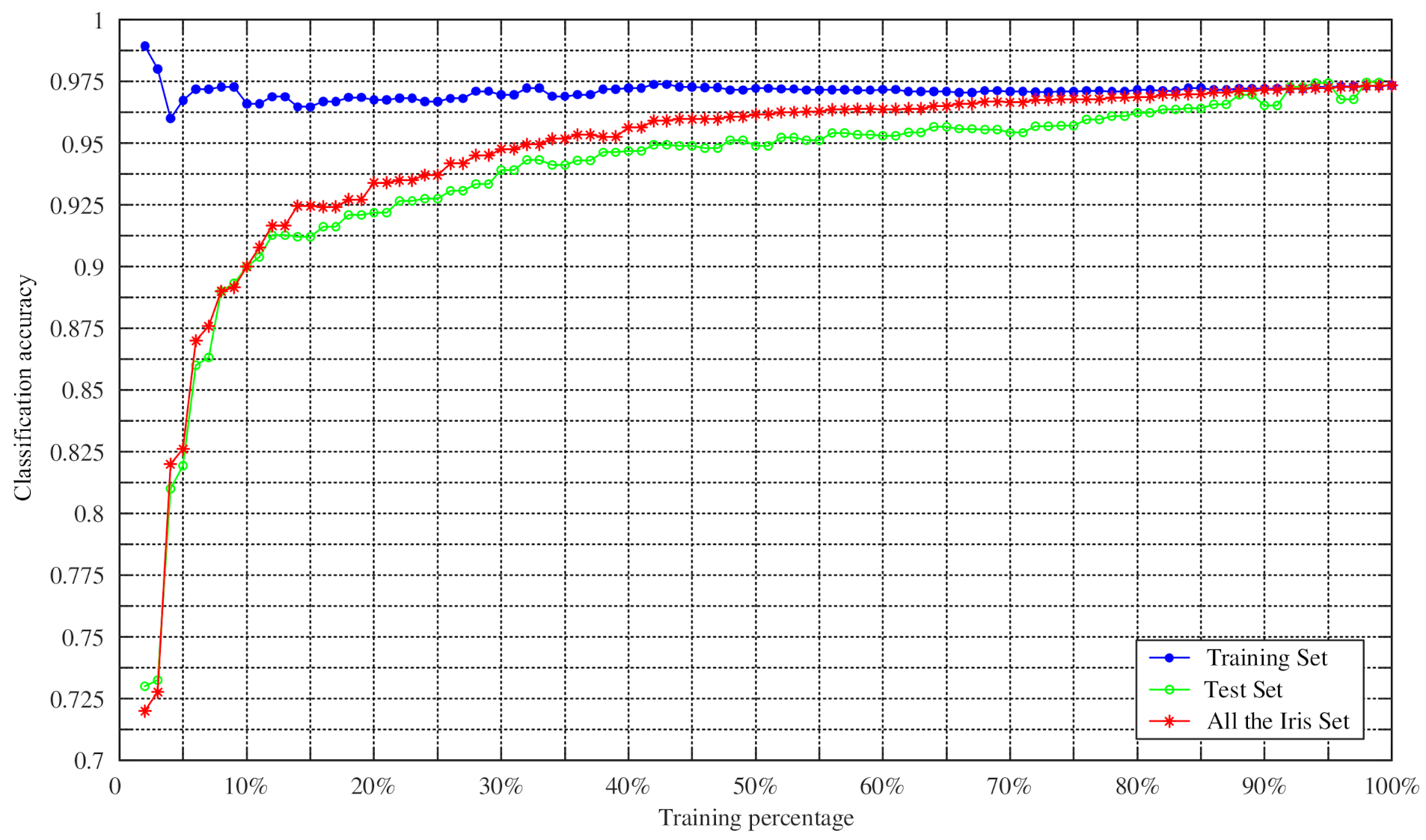
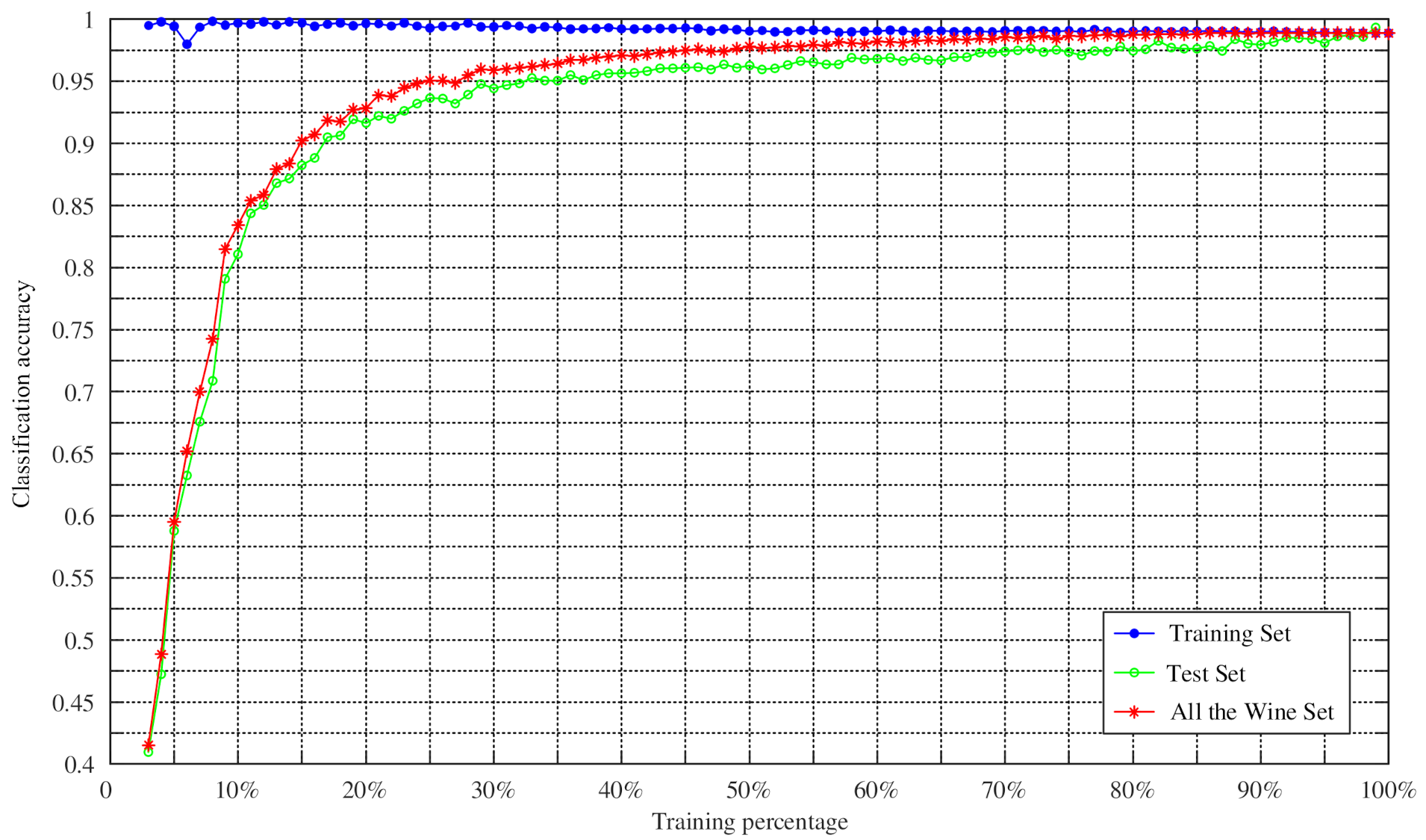
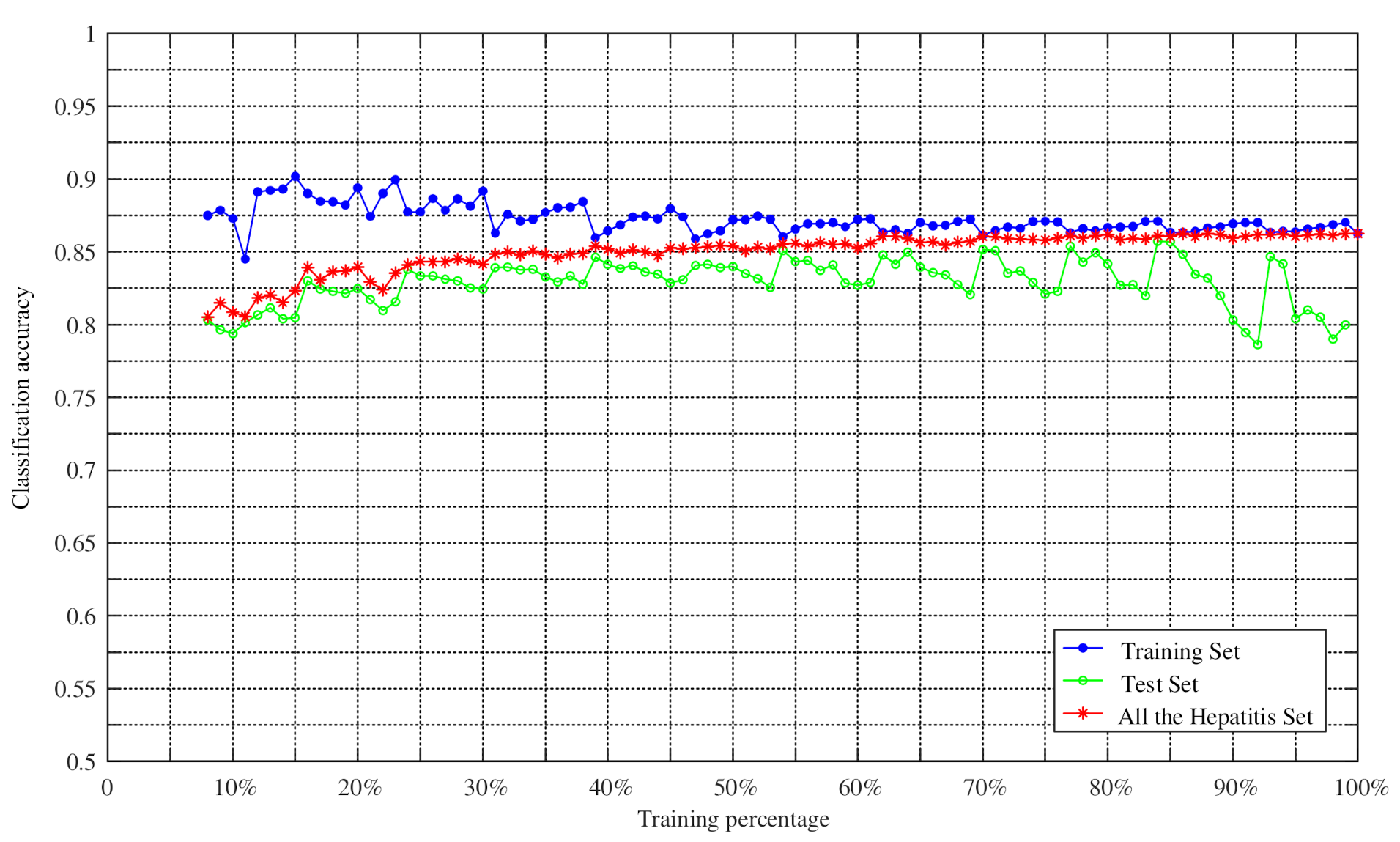
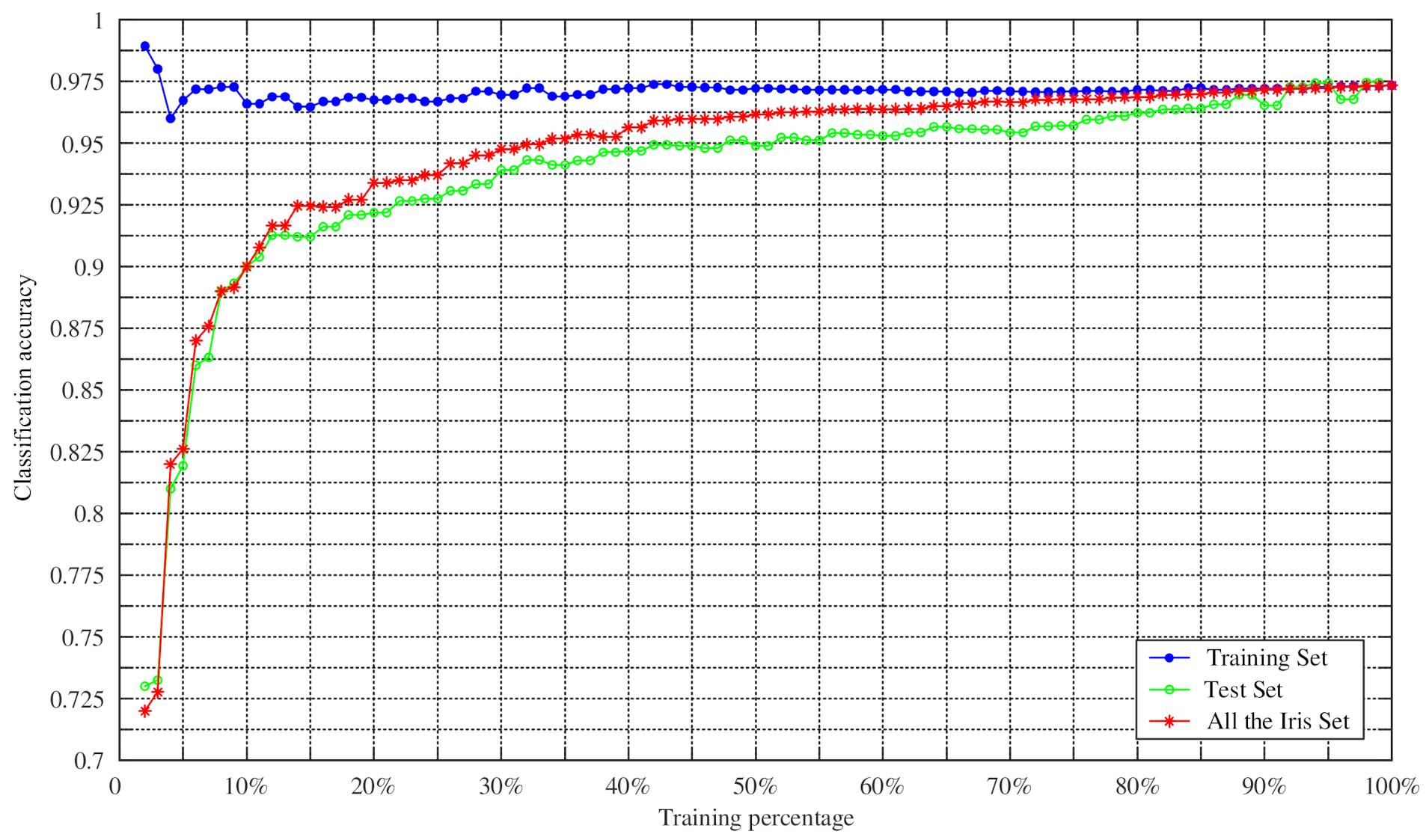
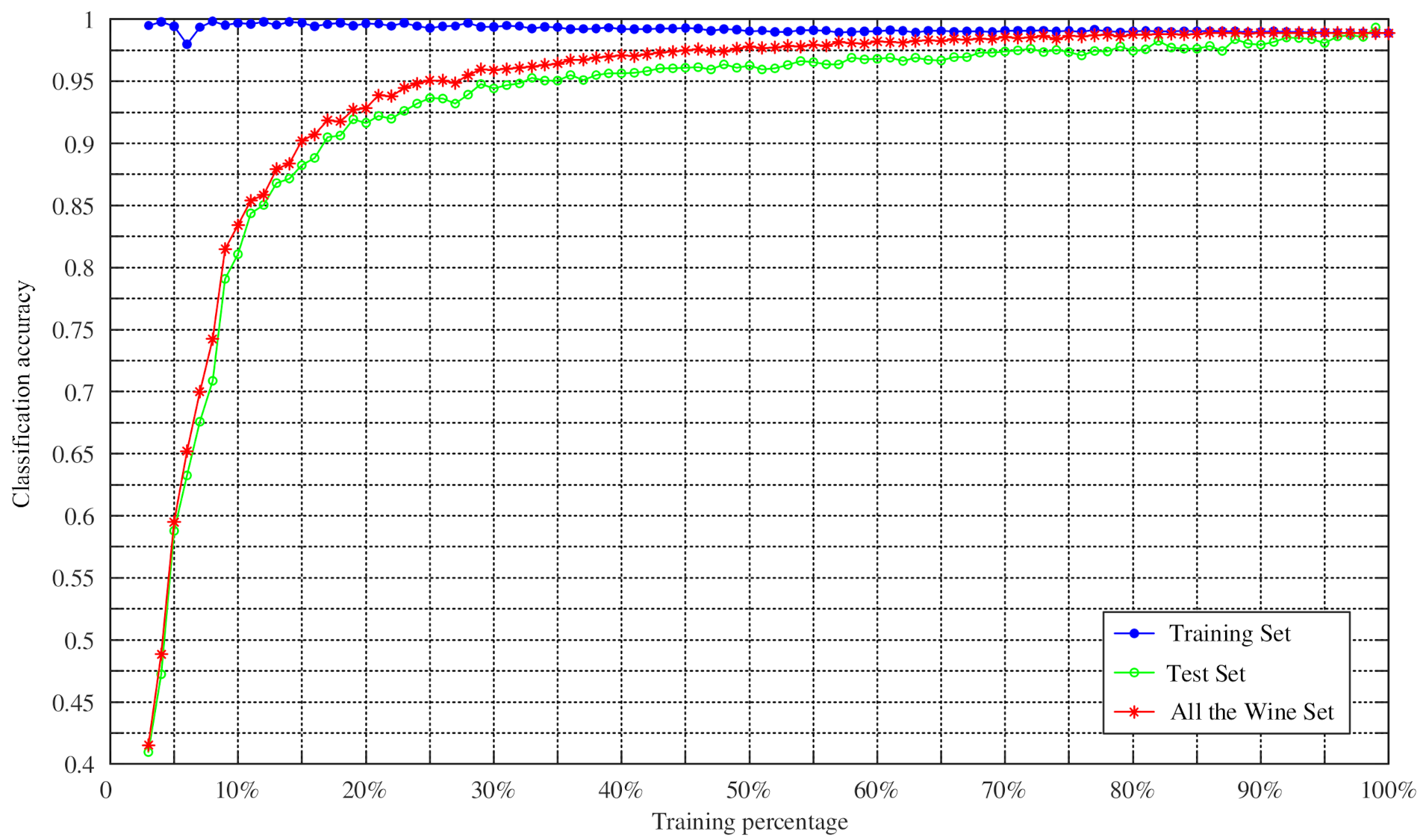
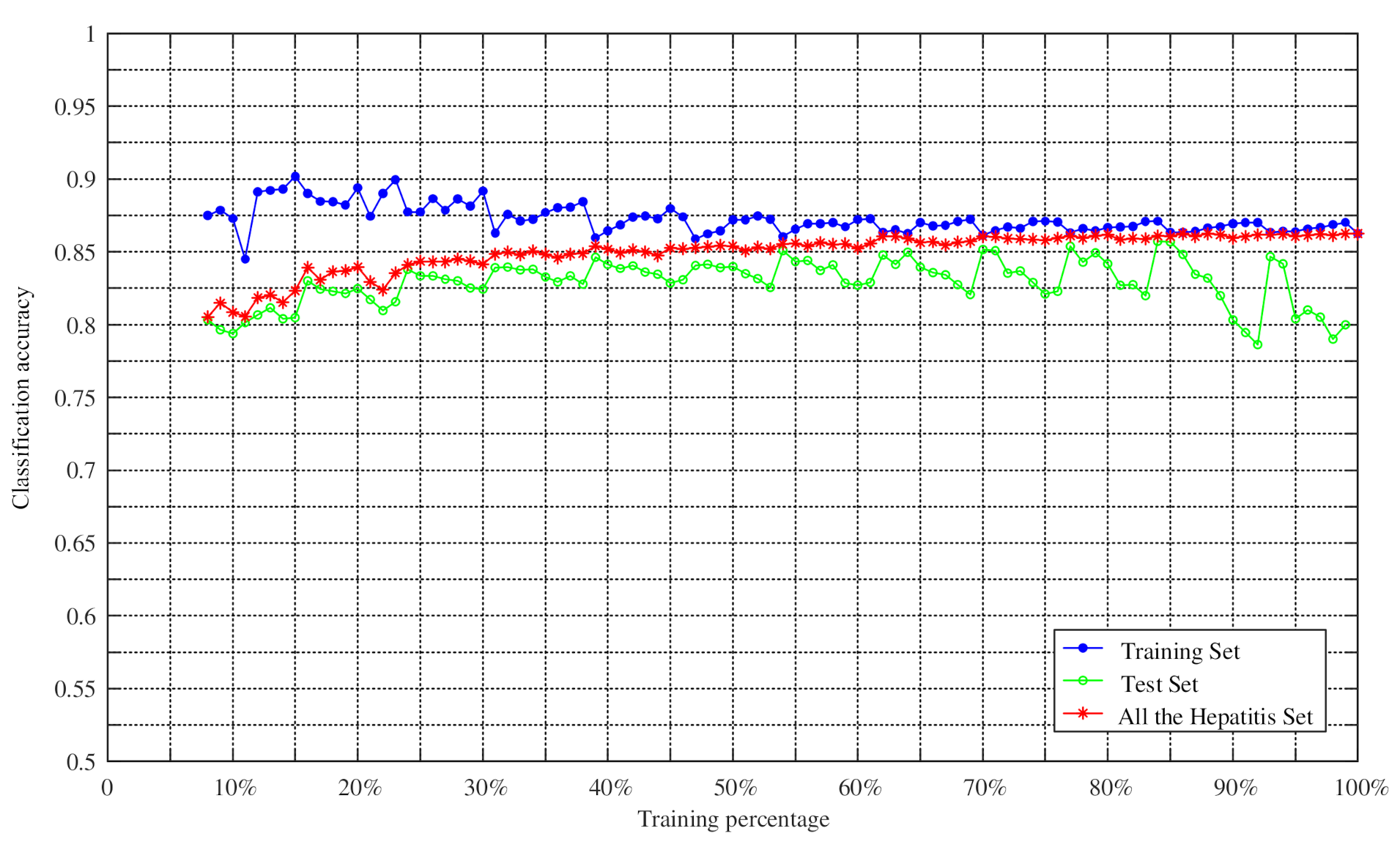
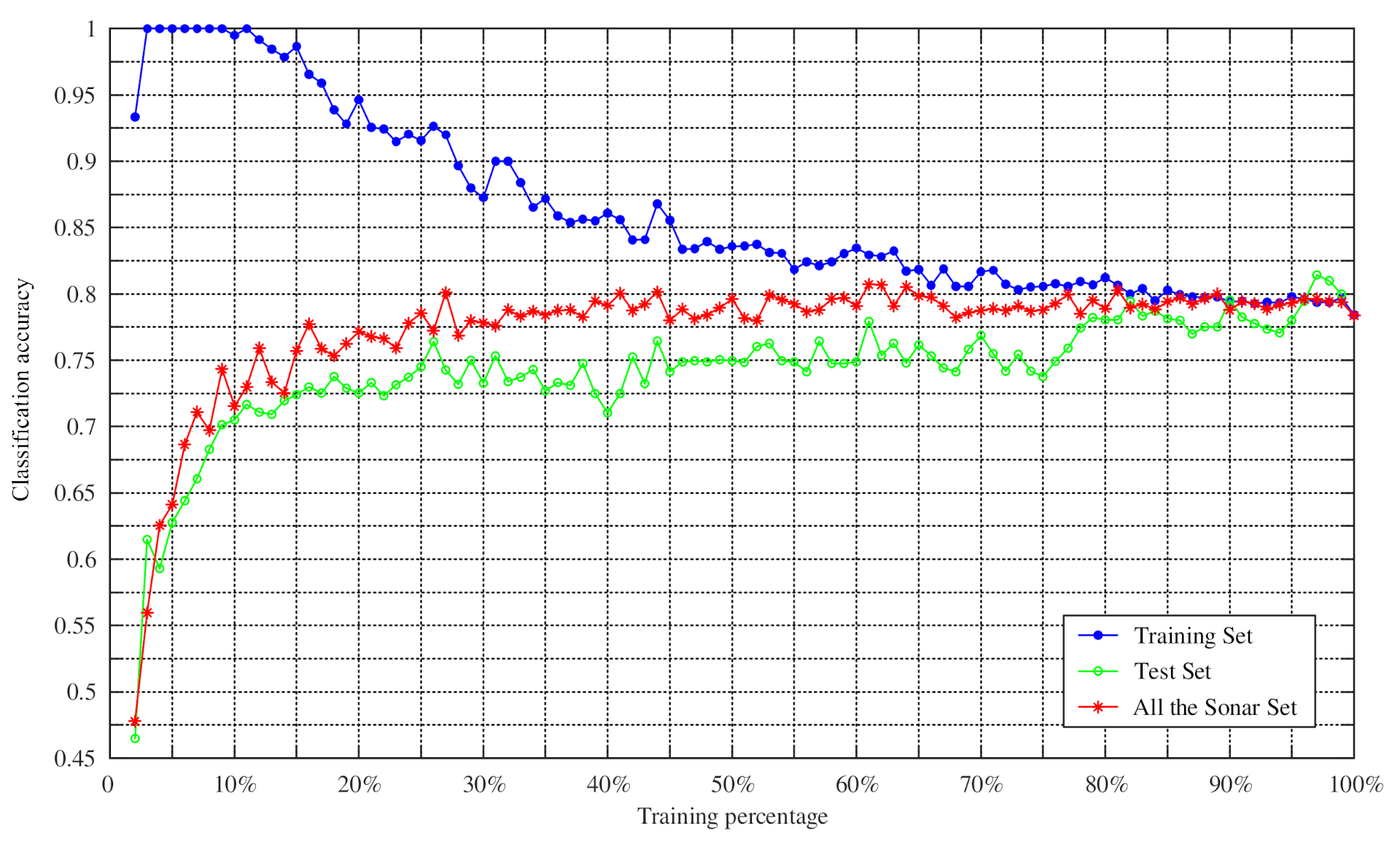
4.2. Experiments on Changing the Training Percentage of Four UCI Datasets
5. Conclusions
- The proposed method in this paper is data-driven so that the uncertainty caused by subjectivity is reduced.
- No assumption is made about the training data distribution, which allows the method to be applied in many different fields.
- The area ratio method is proposed to improve the ability of BPA to deal with uncertain information and increase the accuracy and precision of classification.
- The method is simple and practical and it can determine BPA in the case of a small number of training samples. Using the proposed method to classify the Iris dataset, the experiment concludes that the total recognition rate is 96.53% and the average classification accuracy of 90% can be reached when the training percentage is 10%.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chmielewski, M.; Kukiełka, M.; Pieczonka, P.; Gutowski, T. Methods and analytical tools for assessing tactical situation in military operations using potential approach and sensor data fusion. Procedia Manuf. 2020, 44, 559–566. [Google Scholar] [CrossRef]
- Nagarani, N.; Venkatakrishnan, P.; Balaji, N. Unmanned aerial vehicle’s runway landing system with efficient target detection by using morphological fusion for military surveillance system. Comput. Commun. 2020, 151, 463–472. [Google Scholar] [CrossRef]
- Muzammal, M.; Talat, R.; Sodhro, A.H.; Pirbhulal, S. A multi-sensor data fusion enabled ensemble approach for medical data from body sensor networks. Inf. Fusion 2020, 53, 155–164. [Google Scholar] [CrossRef]
- Magsi, H.; Sodhro, A.H.; Al-Rakhami, M.S.; Zahid, N.; Pirbhulal, S.; Wang, L. A novel adaptive battery-aware algorithm for data transmission in IoT-based healthcare applications. Electronics 2021, 10, 367. [Google Scholar] [CrossRef]
- Jiang, M.Q.; Liu, J.P.; Zhang, L.; Liu, C.Y. An improved stacking framework for stock index prediction by leveraging tree-based ensemble models and deep learning algorithms. Phys. A Stat. Mech. Its Appl. 2020, 541, 122272. [Google Scholar] [CrossRef]
- Himeur, Y.; Alsalemi, A.; Al-Kababji, A.; Bensaali, F.; Amira, A. Data fusion strategies for energy efficiency in buildings: Overview, challenges and novel orientations. Inf. Fusion 2020, 64, 99–120. [Google Scholar] [CrossRef]
- Makkawi, K.; Ait-Tmazirte, N.; el Najjar, M.E.; Moubayed, N. Adaptive Diagnosis for Fault Tolerant Data Fusion Based on α-Rényi Divergence Strategy for Vehicle Localization. Entropy 2021, 23, 463. [Google Scholar] [CrossRef]
- Li, G.F.; Deng, Y. A new divergence measure for basic probability assignment and its applications in extremely uncertain environments. Int. J. Intell. Syst. 2019, 34, 584–600. [Google Scholar]
- Denœux, T.; Shenoy, P.P. An interval-valued utility theory for decision making with Dempster-Shafer belief functions. Int. J. Approx. Reason. 2020, 124, 194–216. [Google Scholar] [CrossRef]
- Song, Y.T.; Deng, Y. A new method to measure the divergence in evidential sensor data fusion. Int. J. Distrib. Sens. Netw. 2019, 15, 1–8. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L.M.; Wu, X.G.; Skibniewski, M.J. Multi-classifier information fusion in risk analysis. Inf. Fusion 2020, 60, 121–136. [Google Scholar] [CrossRef]
- Boukezzoula, R.; Coquin, D.; Nguyen, T.L.; Perrin, S. Multi-sensor information fusion: Combination of fuzzy systems and evidence theory approaches in color recognition for the NAO humanoid robot. Robot. Auton. Syst. 2018, 100, 302–316. [Google Scholar] [CrossRef]
- Xiao, Y.C.; Xue, J.Y.; Zhang, L.; Wang, Y.J.; Li, M.D. Misalignment Fault Diagnosis for Wind Turbines Based on Information Fusion. Entropy 2021, 23, 243. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.D.; Liu, Z.J.; Tang, Y.C. A new classification method based on the negation of a basic probability assignment in the evidence theory. Eng. Appl. Artif. Intell. 2020, 96, 0952–1976. [Google Scholar] [CrossRef]
- Kang, B.Y.; Li, Y.; Deng, Y.; Zhang, Y.J.; Deng, X.Y. Determination of basic probability assignment based on interval numbers and its application. Acta Electron. Sin. 2012, 40, 1092–1096. [Google Scholar]
- Xu, P.D.; Deng, Y.; Su, X.Y.; Mahadevan, S. A new method to determine basic probability assignment from training data. Knowl. Based Syst. 2013, 46, 69–80. [Google Scholar] [CrossRef]
- Chen, H.F.; Wang, X. Determination of basic probability assignment based on probability distribution. In Proceedings of the 2020 39th Chinese Control Conference, Shenyang, China, 9 September 2020; pp. 2941–2945. [Google Scholar]
- Xiao, J.Y.; Tong, M.M.; Zhu, C.J.; Wang, X.L. Basic probability assignment construction method based on generalized triangular fuzzy number. Chin. J. Sci. Instrum. 2012, 32, 191–196. [Google Scholar]
- Zhang, J.F.; Deng, Y. A method to determine basic probability assignment in the open world and its application in data fusion and classification. Appl. Intell. 2017, 46, 934–951. [Google Scholar] [CrossRef]
- Jiang, W.; Zhan, J.; Zhou, D.; Li, X. A method to determine generalized basic probability assignment in the open world. Math. Probl. Eng. 2016, 2016, 3878634. [Google Scholar] [CrossRef]
- Fan, Y.; Ma, T.S.; Xiao, F.Y. An improved approach to generate generalized basic probability assignment based on fuzzy sets in the open world and its application in multi-source information fusion. Appl. Intell. 2020, 51, 3718–3735. [Google Scholar] [CrossRef]
- Li, L.; Wang, C.Y.; Li, W.; Chen, J.B. Hyperspectral image classification by adaboost weighted composite kernel extreme learning machines. Neurocomputing 2018, 275, 1725–1733. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X.C.; Zhang, X.T. Pwadaboost: Possible world based adaboost algorithm for classifying uncertain data. Knowl. Based Syst. 2019, 186, 104930. [Google Scholar] [CrossRef]
- Tang, D.; Tang, L.; Dai, R.; Chen, J.W.; Li, X.; Rodrigues, J.J.P.C. MF-Adaboost: LDoS attack detection based on multi-features and improved adaboost. Future Gener. Comput. Syst. 2020, 106, 347–359. [Google Scholar] [CrossRef]
- Li, J.L.; Sun, L.J.; Li, R.N. Nondestructive detection of frying times for soybean oil by NIR-spectroscopy technology with adaboost-SVM (RBF). Optik 2020, 206, 164248. [Google Scholar] [CrossRef]
- Wu, Y.L.; Ke, Y.T.; Chen, Z.; Liang, S.Y.; Zhao, H.L.; Hong, H.Y. Application of alternating decision tree with adaboost and bagging ensembles for landslide susceptibility mapping. CATENA 2020, 187, 104396. [Google Scholar] [CrossRef]
- Hu, G.S.; Yin, C.J.; Wan, M.Z.; Zhang, Y.; Fang, Y. Recognition of diseased Pinus trees in UAV images using deep learning and adaboost classifier. Biosyst. Eng. 2020, 194, 138–151. [Google Scholar] [CrossRef]
- He, Y.L.; Zhao, Y.; Hu, X.; Yan, X.N.; Zhu, Q.X.; Xu, Y. Fault diagnosis using novel adaboost based discriminant locality preserving projection with resamples. Eng. Appl. Artif. Intell. 2020, 91, 103631. [Google Scholar] [CrossRef]
- Zhao, B.; Zhang, X.M.; Li, H.; Yang, Z.B. Intelligent fault diagnosis of rolling bearings based on normalized CNN considering data imbalance and variable working conditions. Knowl. Based Syst. 2020, 199, 105971. [Google Scholar] [CrossRef]
- Messai, O.; Hachouf, F.; Seghir, Z.A. Adaboost neural network and cyclopean view for no-reference stereoscopic image quality assessment. Signal Process. Image Commun. 2020, 82, 115772. [Google Scholar] [CrossRef]
- Agbele, T.; Ojeme, B.; Jiang, R. Application of local binary patterns and cascade adaboost classifier for mice behavioural patterns detection and analysis. Procedia Comput. Sci. 2019, 159, 1375–1386. [Google Scholar] [CrossRef]
- Lin, G.C.; Zou, X.J. Citrus segmentation for automatic harvester combined with adaboost classifier and Leung-Malik filter bank. IFAC-Pap. 2018, 51, 379–383. [Google Scholar] [CrossRef]
- Yang, H.; Liu, S.L.; Lu, R.X.; Zhu, J.Y. Prediction of component content in rare earth extraction process based on ESNs-adaboost. IFAC-Pap. 2018, 51, 42–47. [Google Scholar]
- Li, H.H.; Liu, S.S.; Hassan, M.M.; Ali, S.; Ouyang, Q.; Chen, Q.S.; Wu, X.Y.; Xu, Z.L. Rapid quantitative analysis of Hg2+ residue in dairy products using SERS coupled with ACO-BP-adaboost algorithm. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 233, 117281. [Google Scholar] [CrossRef]
- Asim, K.M.; Idris, A.; Iqbal, T.; Martínez-Álvarez, F. Seismic indicators based earthquake predictor system using genetic programming and adaboost classification. Soil Dyn. Earthq. Eng. 2018, 111, 1–7. [Google Scholar] [CrossRef]
- Xiao, C.J.; Chen, N.C.; Hu, C.L.; Wang, K.; Gong, J.Y.; Chen, Z.Q. Short and mid-term sea surface temperature prediction using time-series satellite data and LSTM-Adaboost combination approach. Remote Sens. Environ. 2019, 233, 111358. [Google Scholar] [CrossRef]
- Sun, W.; Gao, Q. Exploration of energy saving potential in China power industry based on adaboost back propagation neural network. J. Clean. Prod. 2019, 217, 257–266. [Google Scholar] [CrossRef]
- Xu, X.B.; Duan, H.B.; Guo, Y.J.; Deng, Y.M. A cascade adaboost and CNN algorithm for drogue detection in UAV autonomous aerial refueling. Neurocomputing 2020, 408, 121–134. [Google Scholar] [CrossRef]
- Jiménez-García, J.; Gutiérrez-Tobal, G.C.; García, M.; Kheirandish-Gozal, L.; Martín-Montero, A.; Álvarez, D.; del Campo, F.; Gozal, D.; Hornero, R. Assessment of airflow and oximetry signals to detect pediatric sleep apnea-hypopnea syndrome using adaboost. Entropy 2020, 22, 670. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposition | A | B | C | AB | AC | BC | ABC |
|---|---|---|---|---|---|---|---|
| Area | 4.5 | 4 | 7 | 1.25 | 1.5 | 1.25 | 0.5 |
| Attribute | ||||
|---|---|---|---|---|
| Value | 5.6 | 2.8 | 4.9 | 2 |
| Area | |||||
|---|---|---|---|---|---|
| 4.3 | 5.8 | 2.3 | 4.4 | 3.15 | |
| 4.9 | 7.0 | 2.0 | 3.4 | 2.94 | |
| 4.9 | 7.9 | 2.5 | 3.8 | 3.90 | |
| 4.9 | 5.8 | 2.3 | 3.4 | 0.99 | |
| 4.9 | 5.8 | 2.5 | 3.8 | 1.17 | |
| 4.9 | 7.0 | 2.5 | 3.4 | 1.89 | |
| 4.9 | 5.8 | 2.5 | 3.4 | 0.81 |
| Attributes | |||||||
|---|---|---|---|---|---|---|---|
| 0.0872 | 0.2680 | 0.2267 | 0.0201 | 0.0321 | 0.1160 | 0.2498 | |
| 0 | 0.4195 | 0.5035 | 0 | 0 | 0.0770 | 0 | |
| 0 | 0.3533 | 0.6467 | 0 | 0 | 0 | 0 | |
| 0 | 0.4331 | 0.5027 | 0 | 0 | 0.0642 | 0 | |
| 0 | 0.3333 | 0.6667 | 0 | 0 | 0 | 0 | |
| 0 | 0.3631 | 0.6369 | 0 | 0 | 0 | 0 | |
| Combined BPA | 0 | 0.1088 | 0.8912 | 0 | 0 | 0 | 0 |
| Percentage | [14] | [15] | [18]-W1 | [18]-W2 | [19] | This Paper |
|---|---|---|---|---|---|---|
| 20% | 87.37% | 91.67% | 82.83% | 79.00% | 81.93% | 93.23% |
| 30% | 88.10% | 88.95% | 85.33% | 81.90% | 86.49% | 94.02% |
| 40% | 90.22% | 88.22% | 87.56% | 84.89% | 88.33% | 95.04% |
| 50% | 90.27% | 88.27% | 88.80% | 86.13% | 91.09% | 94.80% |
| 60% | 90.33% | 89.67% | 90.00% | 88.67% | 92.27% | 95.10% |
| 70% | 92.67% | 90.00% | 91.11% | 89.33% | 92.36% | 95.96% |
| 80% | 92.33% | 91.33% | 90.67% | 90.00% | 93.33% | 96.33% |
| 90% | 92.67% | 90.67% | 88.00% | 89.33% | 94.20% | 96.53% |
| Dataset | Instance | Class | Attribute | Missing Value |
|---|---|---|---|---|
| Iris | 150 | 3 | 4 | No |
| Wine | 178 | 3 | 13 | No |
| Hepatitis | 155 | 2 | 19 | Yes |
| Sonar | 208 | 2 | 60 | No |
| Data | SVM-RBF | REPTree | MP | NB | SVM | RBFN | Adaboost | This Paper |
|---|---|---|---|---|---|---|---|---|
| Iris | 92.7 | 94.7 | 96 | 96 | 96.7 | 96.7 | 93.6 | 96.2 |
| Wine | 39.9 | 93.3 | 95.5 | 95.5 | 94.4 | 97.2 | 96.1 | 97.4 |
| Hepatitis | 79.4 | 79.4 | 79.4 | 84.5 | 81.9 | 84.5 | 84.1 | 84.2 |
| Sonar | 74.4 | 75.5 | 80.8 | 69.2 | 78.8 | 75.5 | 74.8 | 78.0 |
| Average | 71.60 | 85.73 | 87.93 | 86.30 | 87.95 | 88.48 | 87.15 | 88.95 |
| Proportion | Iris | Wine | Hepatitis | Sonar | Average |
|---|---|---|---|---|---|
| 10% | 90.0% | 81.1% | 79.4% | 70.5% | 80.25% |
| 15% | 91.2% | 88.2% | 80.5% | 72.4% | 83.08% |
| 20% | 92.2% | 91.7% | 82.5% | 72.5% | 84.73% |
| 25% | 92.7% | 93.6% | 83.3% | 74.5% | 86.03% |
| 30% | 93.9% | 94.4% | 82.4% | 73.3% | 86.00% |
| 35% | 94.1% | 95.1% | 83.3% | 72.7% | 86.30% |
| 40% | 94.7% | 95.7% | 84.1% | 71.0% | 86.38% |
| 45% | 94.9% | 96.1% | 82.8% | 74.1% | 86.98% |
| 50% | 94.9% | 96.3% | 84.0% | 75.0% | 87.55% |
| 55% | 95.1% | 96.6% | 84.3% | 74.9% | 87.73% |
| 60% | 95.3% | 96.8% | 82.7% | 74.9% | 87.43% |
| 65% | 95.7% | 96.7% | 83.9% | 76.2% | 88.13% |
| 70% | 95.4% | 97.4% | 85.1% | 76.8% | 88.68% |
| 75% | 95.7% | 97.4% | 82.1% | 73.8% | 87.25% |
| 80% | 96.2% | 97.4% | 84.2% | 78.0% | 88.95% |
| 85% | 96.4% | 97.6% | 85.7% | 78.1% | 89.45% |
| 90% | 96.5% | 98.0% | 80.3% | 78.8% | 88.40% |
| 95% | 97.4% | 98.1% | 80.4% | 78.0% | 88.48% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, W.; Yu, S.; Wang, X. A Novel Method to Determine Basic Probability Assignment Based on Adaboost and Its Application in Classification. Entropy 2021, 23, 812. https://doi.org/10.3390/e23070812
Fu W, Yu S, Wang X. A Novel Method to Determine Basic Probability Assignment Based on Adaboost and Its Application in Classification. Entropy. 2021; 23(7):812. https://doi.org/10.3390/e23070812
Chicago/Turabian StyleFu, Wei, Shuang Yu, and Xin Wang. 2021. "A Novel Method to Determine Basic Probability Assignment Based on Adaboost and Its Application in Classification" Entropy 23, no. 7: 812. https://doi.org/10.3390/e23070812
APA StyleFu, W., Yu, S., & Wang, X. (2021). A Novel Method to Determine Basic Probability Assignment Based on Adaboost and Its Application in Classification. Entropy, 23(7), 812. https://doi.org/10.3390/e23070812